 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Investigating the Emergent Audio Classification Ability of ASR Foundation Models
Nov 15, 2023
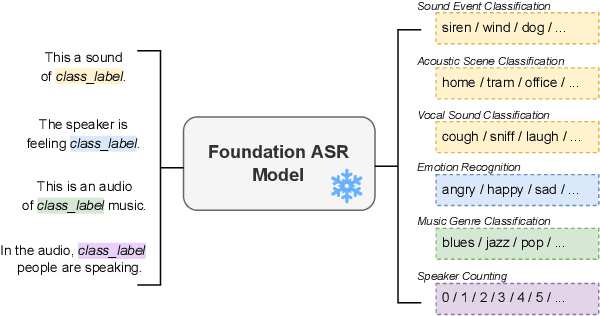
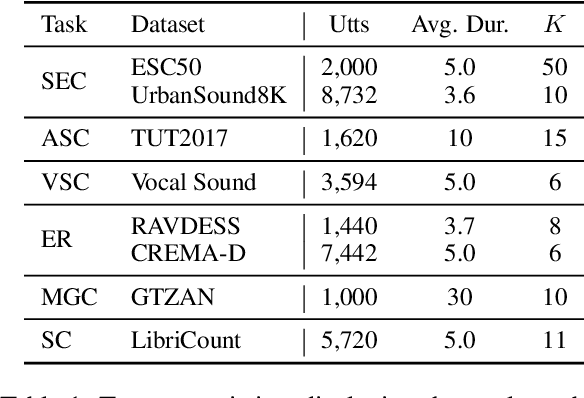


Text and vision foundation models can perform many tasks in a zero-shot setting, a desirable property that enables these systems to be applied in general and low-resource settings. However, there has been significantly less work on the zero-shot abilities of ASR foundation models, with these systems typically fine-tuned to specific tasks or constrained to applications that match their training criterion and data annotation. In this work we investigate the ability of Whisper and MMS, ASR foundation models trained primarily for speech recognition, to perform zero-shot audio classification. We use simple template-based text prompts at the decoder and use the resulting decoding probabilities to generate zero-shot predictions. Without training the model on extra data or adding any new parameters, we demonstrate that Whisper shows promising zero-shot classification performance on a range of 8 audio-classification datasets, outperforming existing state-of-the-art zero-shot baseline's accuracy by an average of 9%. One important step to unlock the emergent ability is debiasing, where a simple unsupervised reweighting method of the class probabilities yields consistent significant performance gains. We further show that performance increases with model size, implying that as ASR foundation models scale up, they may exhibit improved zero-shot performance.
TST: Time-Sparse Transducer for Automatic Speech Recognition
Jul 17, 2023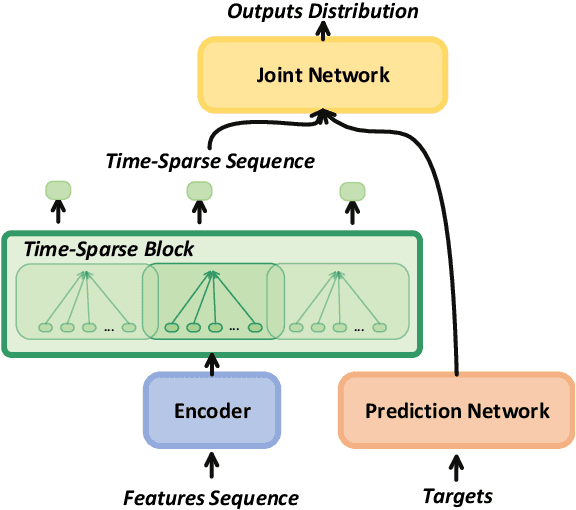

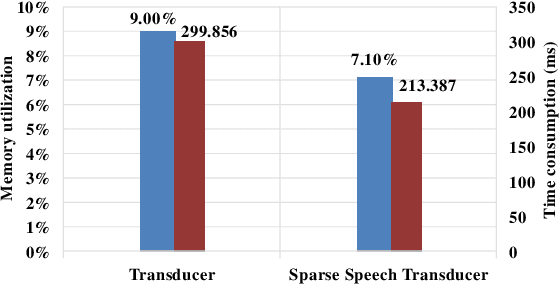
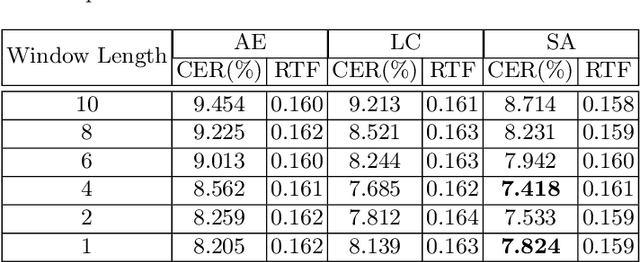
End-to-end model, especially Recurrent Neural Network Transducer (RNN-T), has achieved great success in speech recognition. However, transducer requires a great memory footprint and computing time when processing a long decoding sequence. To solve this problem, we propose a model named time-sparse transducer, which introduces a time-sparse mechanism into transducer. In this mechanism, we obtain the intermediate representations by reducing the time resolution of the hidden states. Then the weighted average algorithm is used to combine these representations into sparse hidden states followed by the decoder. All the experiments are conducted on a Mandarin dataset AISHELL-1. Compared with RNN-T, the character error rate of the time-sparse transducer is close to RNN-T and the real-time factor is 50.00% of the original. By adjusting the time resolution, the time-sparse transducer can also reduce the real-time factor to 16.54% of the original at the expense of a 4.94% loss of precision.
* 10 pages
Robust Automatic Speech Recognition via WavAugment Guided Phoneme Adversarial Training
Jul 24, 2023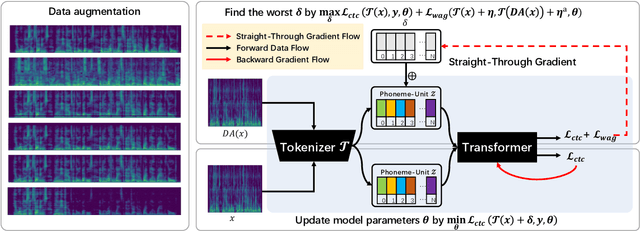
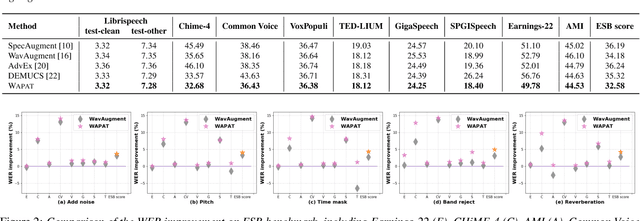
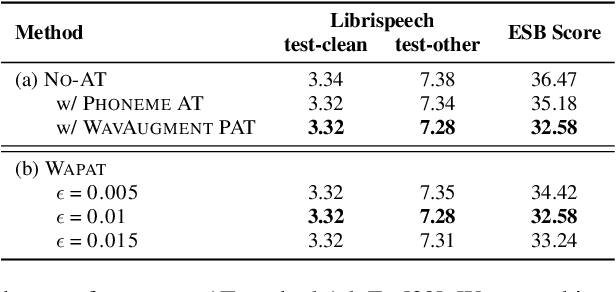
Developing a practically-robust automatic speech recognition (ASR) is challenging since the model should not only maintain the original performance on clean samples, but also achieve consistent efficacy under small volume perturbations and large domain shifts. To address this problem, we propose a novel WavAugment Guided Phoneme Adversarial Training (wapat). wapat use adversarial examples in phoneme space as augmentation to make the model invariant to minor fluctuations in phoneme representation and preserve the performance on clean samples. In addition, wapat utilizes the phoneme representation of augmented samples to guide the generation of adversaries, which helps to find more stable and diverse gradient-directions, resulting in improved generalization. Extensive experiments demonstrate the effectiveness of wapat on End-to-end Speech Challenge Benchmark (ESB). Notably, SpeechLM-wapat outperforms the original model by 6.28% WER reduction on ESB, achieving the new state-of-the-art.
Alternative Pseudo-Labeling for Semi-Supervised Automatic Speech Recognition
Aug 12, 2023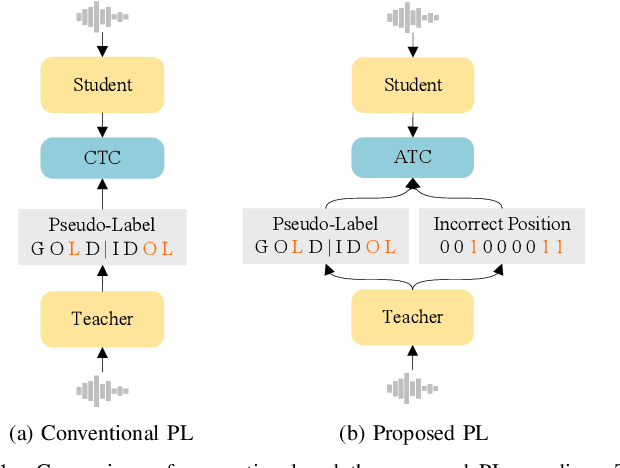

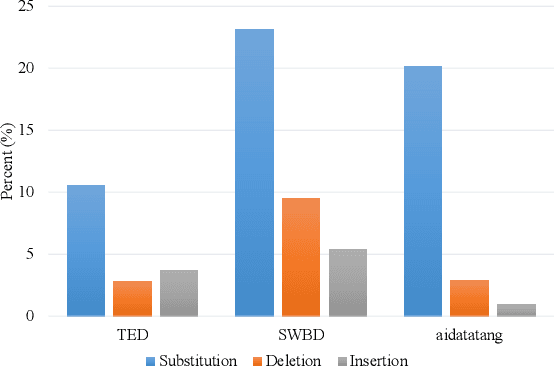
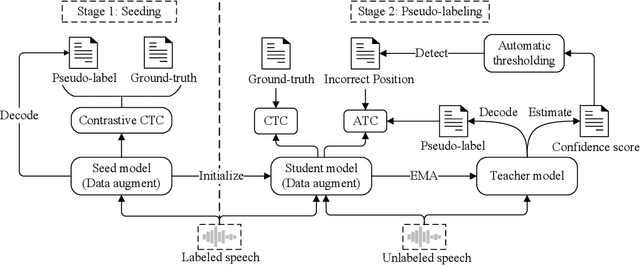
When labeled data is insufficient, semi-supervised learning with the pseudo-labeling technique can significantly improve the performance of automatic speech recognition. However, pseudo-labels are often noisy, containing numerous incorrect tokens. Taking noisy labels as ground-truth in the loss function results in suboptimal performance. Previous works attempted to mitigate this issue by either filtering out the nosiest pseudo-labels or improving the overall quality of pseudo-labels. While these methods are effective to some extent, it is unrealistic to entirely eliminate incorrect tokens in pseudo-labels. In this work, we propose a novel framework named alternative pseudo-labeling to tackle the issue of noisy pseudo-labels from the perspective of the training objective. The framework comprises several components. Firstly, a generalized CTC loss function is introduced to handle noisy pseudo-labels by accepting alternative tokens in the positions of incorrect tokens. Applying this loss function in pseudo-labeling requires detecting incorrect tokens in the predicted pseudo-labels. In this work, we adopt a confidence-based error detection method that identifies the incorrect tokens by comparing their confidence scores with a given threshold, thus necessitating the confidence score to be discriminative. Hence, the second proposed technique is the contrastive CTC loss function that widens the confidence gap between the correctly and incorrectly predicted tokens, thereby improving the error detection ability. Additionally, obtaining satisfactory performance with confidence-based error detection typically requires extensive threshold tuning. Instead, we propose an automatic thresholding method that uses labeled data as a proxy for determining the threshold, thus saving the pain of manual tuning.
Personalization for BERT-based Discriminative Speech Recognition Rescoring
Jul 13, 2023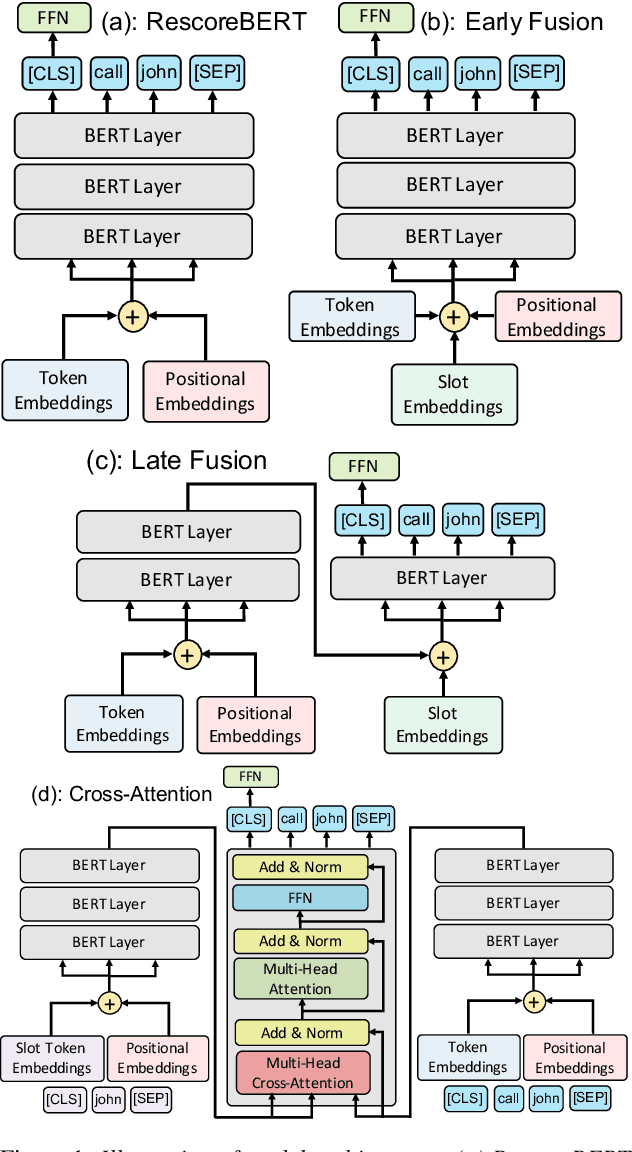

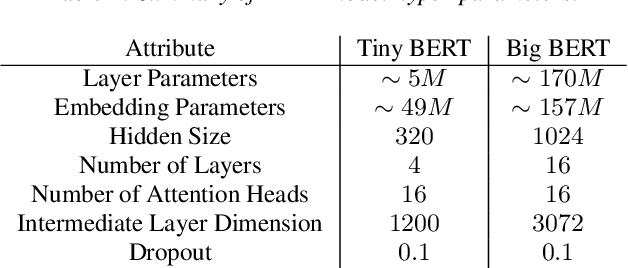
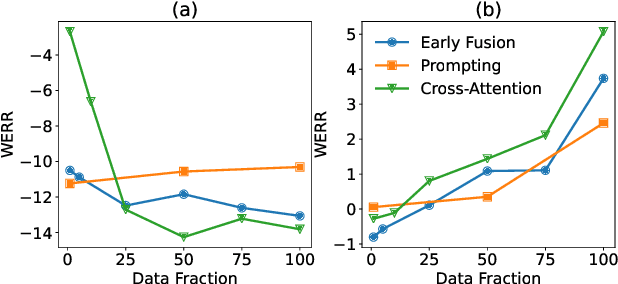
Recognition of personalized content remains a challenge in end-to-end speech recognition. We explore three novel approaches that use personalized content in a neural rescoring step to improve recognition: gazetteers, prompting, and a cross-attention based encoder-decoder model. We use internal de-identified en-US data from interactions with a virtual voice assistant supplemented with personalized named entities to compare these approaches. On a test set with personalized named entities, we show that each of these approaches improves word error rate by over 10%, against a neural rescoring baseline. We also show that on this test set, natural language prompts can improve word error rate by 7% without any training and with a marginal loss in generalization. Overall, gazetteers were found to perform the best with a 10% improvement in word error rate (WER), while also improving WER on a general test set by 1%.
RIR-SF: Room Impulse Response Based Spatial Feature for Multi-channel Multi-talker ASR
Oct 31, 2023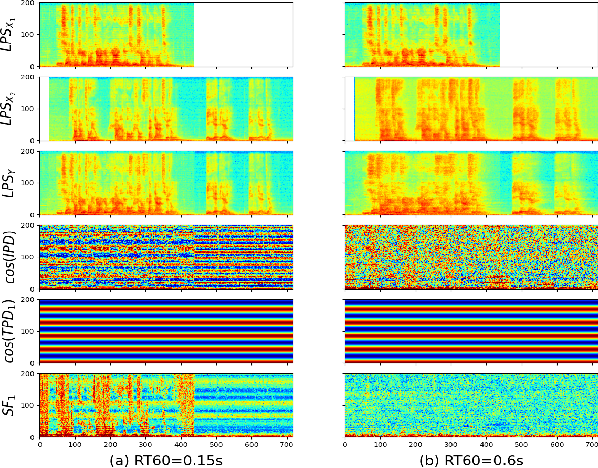
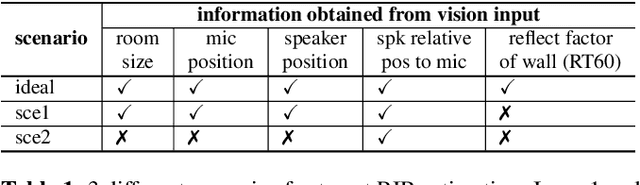
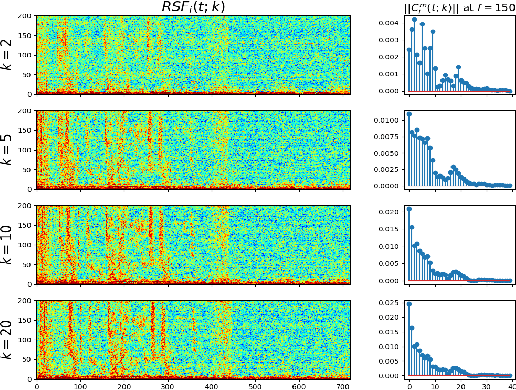
Multi-channel multi-talker automatic speech recognition (ASR) presents ongoing challenges within the speech community, particularly when confronted with significant reverberation effects. In this study, we introduce a novel approach involving the convolution of overlapping speech signals with the room impulse response (RIR) corresponding to the target speaker's transmission to a microphone array. This innovative technique yields a novel spatial feature known as the RIR-SF. Through a comprehensive comparison with the previously established state-of-the-art 3D spatial feature, both theoretical analysis and experimental results substantiate the superiority of our proposed RIR-SF. We demonstrate that the RIR-SF outperforms existing methods, leading to a remarkable 21.3\% relative reduction in the Character Error Rate (CER) in multi-channel multi-talker ASR systems. Importantly, this novel feature exhibits robustness in the face of strong reverberation, surpassing the limitations of previous approaches.
Research on an improved Conformer end-to-end Speech Recognition Model with R-Drop Structure
Jun 14, 2023
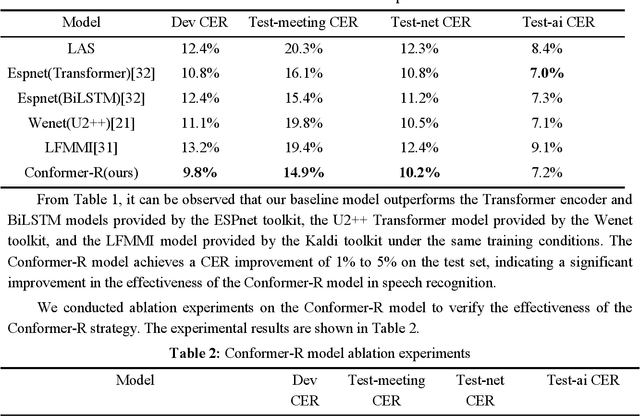
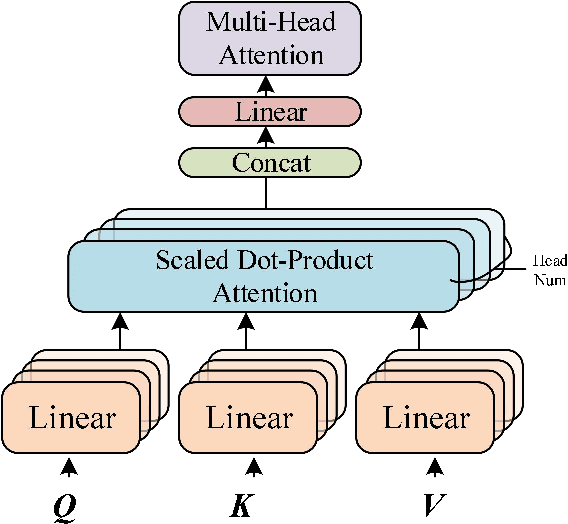

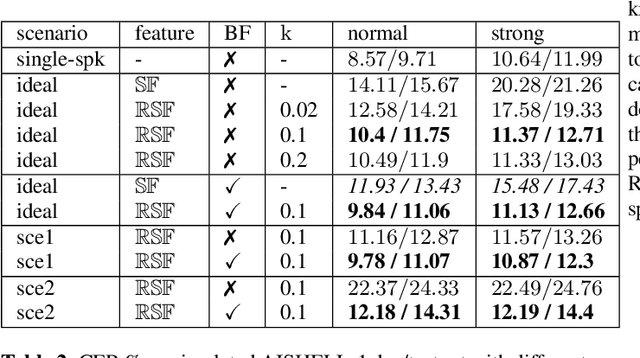
To address the issue of poor generalization ability in end-to-end speech recognition models within deep learning, this study proposes a new Conformer-based speech recognition model called "Conformer-R" that incorporates the R-drop structure. This model combines the Conformer model, which has shown promising results in speech recognition, with the R-drop structure. By doing so, the model is able to effectively model both local and global speech information while also reducing overfitting through the use of the R-drop structure. This enhances the model's ability to generalize and improves overall recognition efficiency. The model was first pre-trained on the Aishell1 and Wenetspeech datasets for general domain adaptation, and subsequently fine-tuned on computer-related audio data. Comparison tests with classic models such as LAS and Wenet were performed on the same test set, demonstrating the Conformer-R model's ability to effectively improve generalization.
Multi-channel Conversational Speaker Separation via Neural Diarization
Nov 15, 2023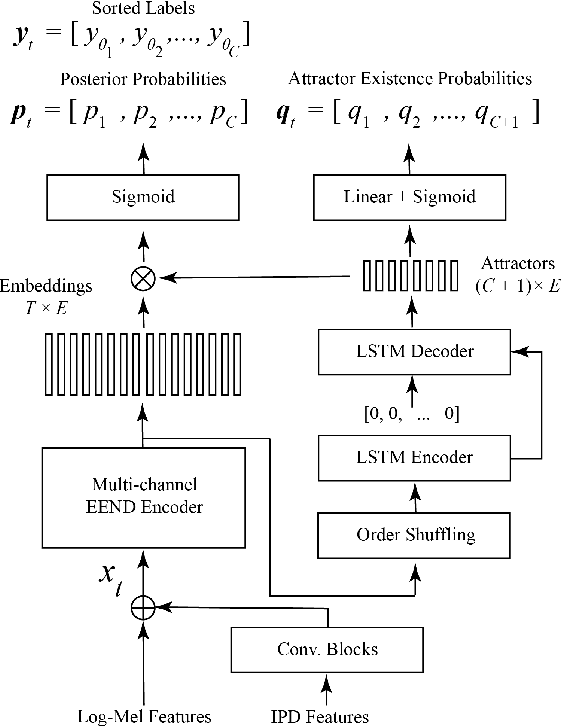
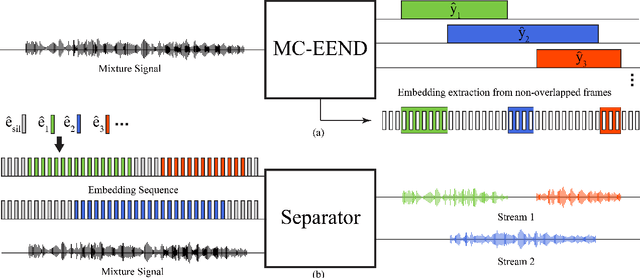
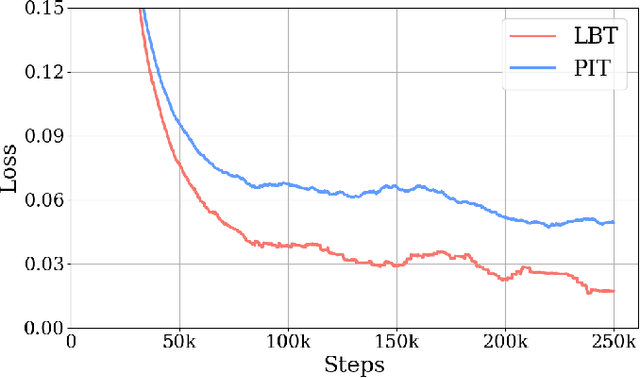
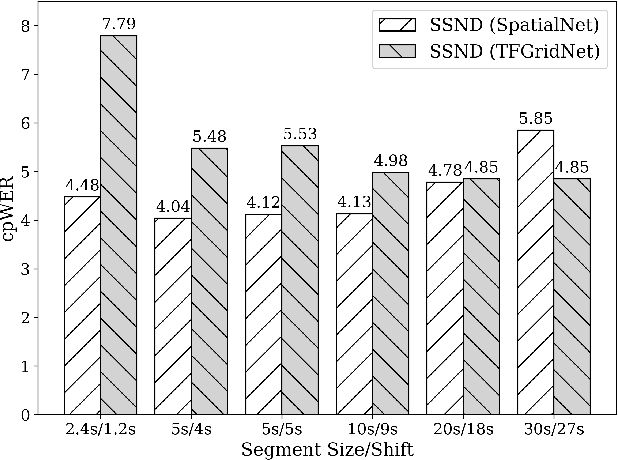
When dealing with overlapped speech, the performance of automatic speech recognition (ASR) systems substantially degrades as they are designed for single-talker speech. To enhance ASR performance in conversational or meeting environments, continuous speaker separation (CSS) is commonly employed. However, CSS requires a short separation window to avoid many speakers inside the window and sequential grouping of discontinuous speech segments. To address these limitations, we introduce a new multi-channel framework called "speaker separation via neural diarization" (SSND) for meeting environments. Our approach utilizes an end-to-end diarization system to identify the speech activity of each individual speaker. By leveraging estimated speaker boundaries, we generate a sequence of embeddings, which in turn facilitate the assignment of speakers to the outputs of a multi-talker separation model. SSND addresses the permutation ambiguity issue of talker-independent speaker separation during the diarization phase through location-based training, rather than during the separation process. This unique approach allows multiple non-overlapped speakers to be assigned to the same output stream, making it possible to efficiently process long segments-a task impossible with CSS. Additionally, SSND is naturally suitable for speaker-attributed ASR. We evaluate our proposed diarization and separation methods on the open LibriCSS dataset, advancing state-of-the-art diarization and ASR results by a large margin.
Contextualized End-to-End Speech Recognition with Contextual Phrase Prediction Network
May 21, 2023
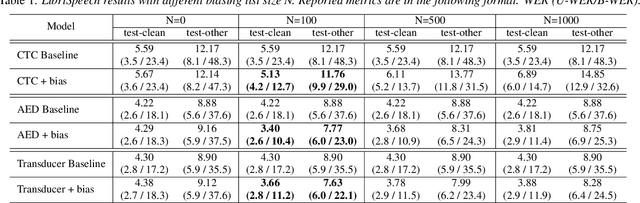
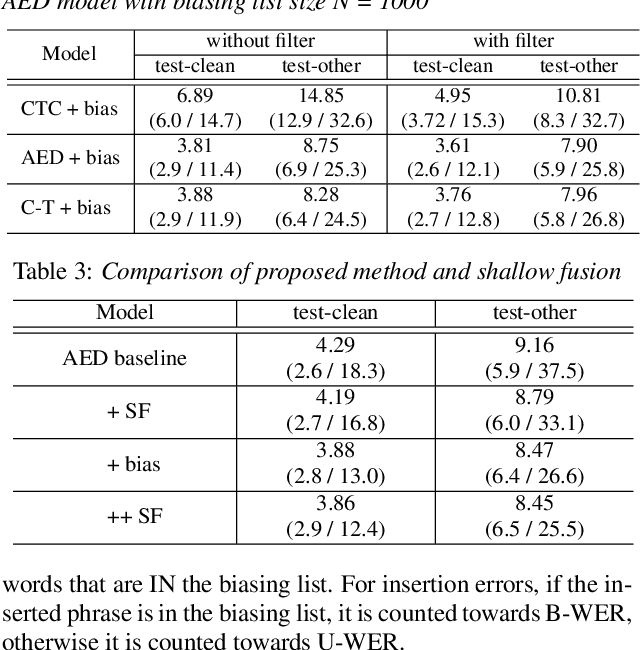
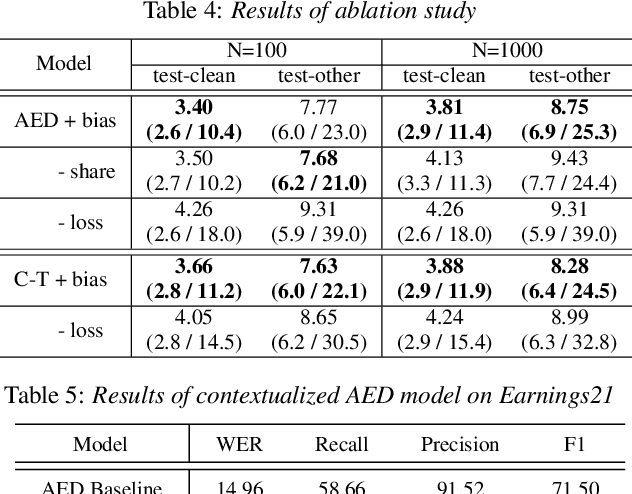
Contextual information plays a crucial role in speech recognition technologies and incorporating it into the end-to-end speech recognition models has drawn immense interest recently. However, previous deep bias methods lacked explicit supervision for bias tasks. In this study, we introduce a contextual phrase prediction network for an attention-based deep bias method. This network predicts context phrases in utterances using contextual embeddings and calculates bias loss to assist in the training of the contextualized model. Our method achieved a significant word error rate (WER) reduction across various end-to-end speech recognition models. Experiments on the LibriSpeech corpus show that our proposed model obtains a 12.1% relative WER improvement over the baseline model, and the WER of the context phrases decreases relatively by 40.5%. Moreover, by applying a context phrase filtering strategy, we also effectively eliminate the WER degradation when using a larger biasing list.
Whisper in Focus: Enhancing Stuttered Speech Classification with Encoder Layer Optimization
Nov 09, 2023In recent years, advancements in the field of speech processing have led to cutting-edge deep learning algorithms with immense potential for real-world applications. The automated identification of stuttered speech is one of such applications that the researchers are addressing by employing deep learning techniques. Recently, researchers have utilized Wav2vec2.0, a speech recognition model to classify disfluency types in stuttered speech. Although Wav2vec2.0 has shown commendable results, its ability to generalize across all disfluency types is limited. In addition, since its base model uses 12 encoder layers, it is considered a resource-intensive model. Our study unravels the capabilities of Whisper for the classification of disfluency types in stuttered speech. We have made notable contributions in three pivotal areas: enhancing the quality of SEP28-k benchmark dataset, exploration of Whisper for classification, and introducing an efficient encoder layer freezing strategy. The optimized Whisper model has achieved the average F1-score of 0.81, which proffers its abilities. This study also unwinds the significance of deeper encoder layers in the identification of disfluency types, as the results demonstrate their greater contribution compared to initial layers. This research represents substantial contributions, shifting the emphasis towards an efficient solution, thereby thriving towards prospective innovation.