 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A meta learning scheme for fast accent domain expansion in Mandarin speech recognition
Jul 23, 2023
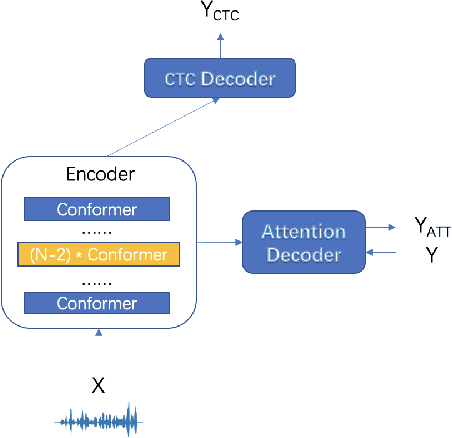

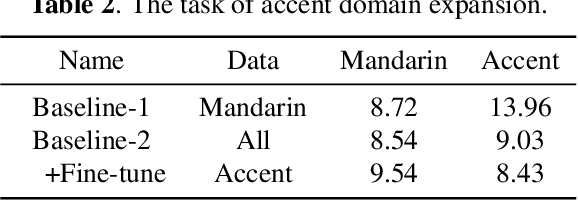
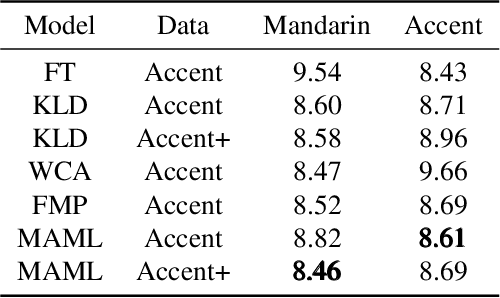
Spoken languages show significant variation across mandarin and accent. Despite the high performance of mandarin automatic speech recognition (ASR), accent ASR is still a challenge task. In this paper, we introduce meta-learning techniques for fast accent domain expansion in mandarin speech recognition, which expands the field of accents without deteriorating the performance of mandarin ASR. Meta-learning or learn-to-learn can learn general relation in multi domains not only for over-fitting a specific domain. So we select meta-learning in the domain expansion task. This more essential learning will cause improved performance on accent domain extension tasks. We combine the methods of meta learning and freeze of model parameters, which makes the recognition performance more stable in different cases and the training faster about 20%. Our approach significantly outperforms other methods about 3% relatively in the accent domain expansion task. Compared to the baseline model, it improves relatively 37% under the condition that the mandarin test set remains unchanged. In addition, it also proved this method to be effective on a large amount of data with a relative performance improvement of 4% on the accent test set.
MixRep: Hidden Representation Mixup for Low-Resource Speech Recognition
Oct 27, 2023In this paper, we present MixRep, a simple and effective data augmentation strategy based on mixup for low-resource ASR. MixRep interpolates the feature dimensions of hidden representations in the neural network that can be applied to both the acoustic feature input and the output of each layer, which generalizes the previous MixSpeech method. Further, we propose to combine the mixup with a regularization along the time axis of the input, which is shown as complementary. We apply MixRep to a Conformer encoder of an E2E LAS architecture trained with a joint CTC loss. We experiment on the WSJ dataset and subsets of the SWB dataset, covering reading and telephony conversational speech. Experimental results show that MixRep consistently outperforms other regularization methods for low-resource ASR. Compared to a strong SpecAugment baseline, MixRep achieves a +6.5\% and a +6.7\% relative WER reduction on the eval92 set and the Callhome part of the eval'2000 set.
End-to-End Single-Channel Speaker-Turn Aware Conversational Speech Translation
Nov 01, 2023Conventional speech-to-text translation (ST) systems are trained on single-speaker utterances, and they may not generalize to real-life scenarios where the audio contains conversations by multiple speakers. In this paper, we tackle single-channel multi-speaker conversational ST with an end-to-end and multi-task training model, named Speaker-Turn Aware Conversational Speech Translation, that combines automatic speech recognition, speech translation and speaker turn detection using special tokens in a serialized labeling format. We run experiments on the Fisher-CALLHOME corpus, which we adapted by merging the two single-speaker channels into one multi-speaker channel, thus representing the more realistic and challenging scenario with multi-speaker turns and cross-talk. Experimental results across single- and multi-speaker conditions and against conventional ST systems, show that our model outperforms the reference systems on the multi-speaker condition, while attaining comparable performance on the single-speaker condition. We release scripts for data processing and model training.
Adapting Large Language Model with Speech for Fully Formatted End-to-End Speech Recognition
Jul 17, 2023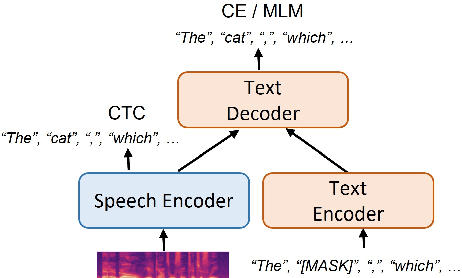
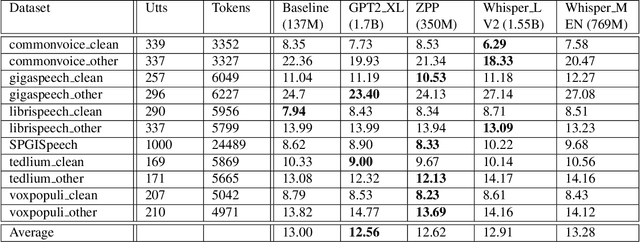
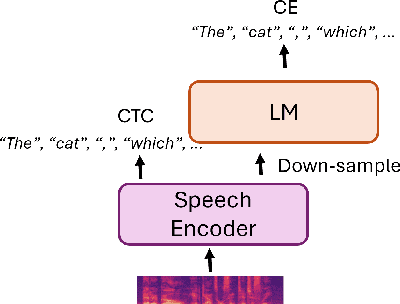

Most end-to-end (E2E) speech recognition models are composed of encoder and decoder blocks that perform acoustic and language modeling functions. Pretrained large language models (LLMs) have the potential to improve the performance of E2E ASR. However, integrating a pretrained language model into an E2E speech recognition model has shown limited benefits due to the mismatches between text-based LLMs and those used in E2E ASR. In this paper, we explore an alternative approach by adapting a pretrained LLMs to speech. Our experiments on fully-formatted E2E ASR transcription tasks across various domains demonstrate that our approach can effectively leverage the strengths of pretrained LLMs to produce more readable ASR transcriptions. Our model, which is based on the pretrained large language models with either an encoder-decoder or decoder-only structure, surpasses strong ASR models such as Whisper, in terms of recognition error rate, considering formats like punctuation and capitalization as well.
Differential Evolution Algorithm based Hyper-Parameters Selection of Convolutional Neural Network for Speech Command Recognition
Oct 13, 2023Speech Command Recognition (SCR), which deals with identification of short uttered speech commands, is crucial for various applications, including IoT devices and assistive technology. Despite the promise shown by Convolutional Neural Networks (CNNs) in SCR tasks, their efficacy relies heavily on hyper-parameter selection, which is typically laborious and time-consuming when done manually. This paper introduces a hyper-parameter selection method for CNNs based on the Differential Evolution (DE) algorithm, aiming to enhance performance in SCR tasks. Training and testing with the Google Speech Command (GSC) dataset, the proposed approach showed effectiveness in classifying speech commands. Moreover, a comparative analysis with Genetic Algorithm based selections and other deep CNN (DCNN) models highlighted the efficiency of the proposed DE algorithm in hyper-parameter selection for CNNs in SCR tasks.
The timing bottleneck: Why timing and overlap are mission-critical for conversational user interfaces, speech recognition and dialogue systems
Jul 28, 2023
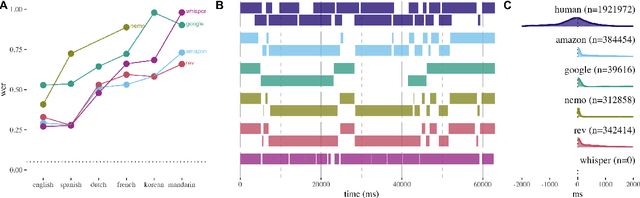
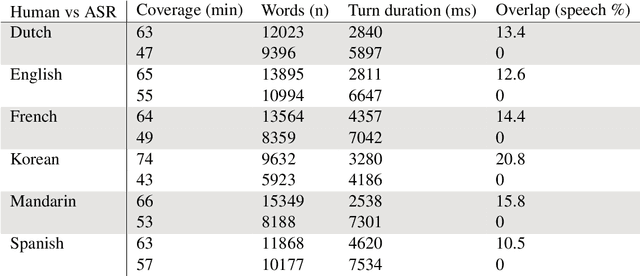
Speech recognition systems are a key intermediary in voice-driven human-computer interaction. Although speech recognition works well for pristine monologic audio, real-life use cases in open-ended interactive settings still present many challenges. We argue that timing is mission-critical for dialogue systems, and evaluate 5 major commercial ASR systems for their conversational and multilingual support. We find that word error rates for natural conversational data in 6 languages remain abysmal, and that overlap remains a key challenge (study 1). This impacts especially the recognition of conversational words (study 2), and in turn has dire consequences for downstream intent recognition (study 3). Our findings help to evaluate the current state of conversational ASR, contribute towards multidimensional error analysis and evaluation, and identify phenomena that need most attention on the way to build robust interactive speech technologies.
Gammatonegram Representation for End-to-End Dysarthric Speech Processing Tasks: Speech Recognition, Speaker Identification, and Intelligibility Assessment
Jul 06, 2023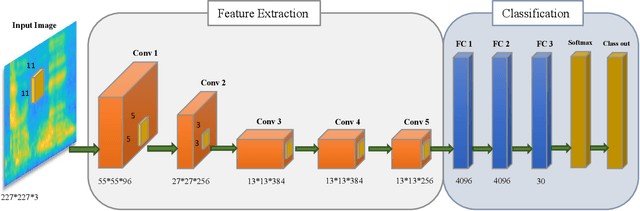
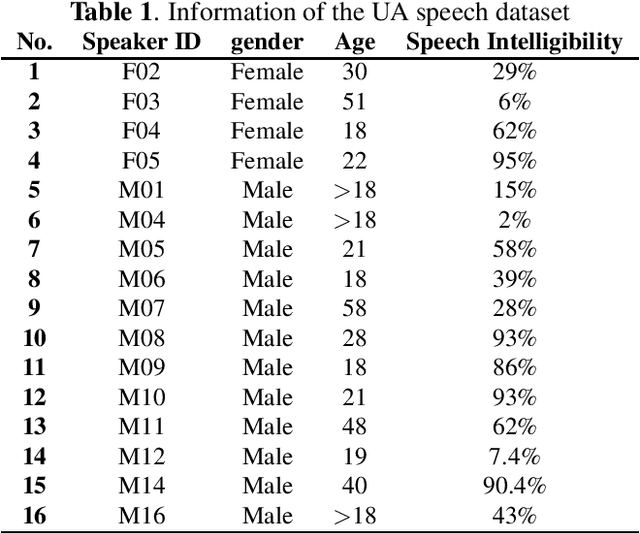
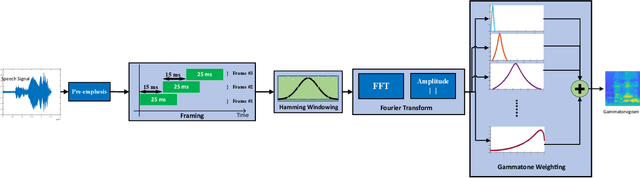

Dysarthria is a disability that causes a disturbance in the human speech system and reduces the quality and intelligibility of a person's speech. Because of this effect, the normal speech processing systems can not work properly on impaired speech. This disability is usually associated with physical disabilities. Therefore, designing a system that can perform some tasks by receiving voice commands in the smart home can be a significant achievement. In this work, we introduce gammatonegram as an effective method to represent audio files with discriminative details, which is used as input for the convolutional neural network. On the other word, we convert each speech file into an image and propose image recognition system to classify speech in different scenarios. Proposed CNN is based on the transfer learning method on the pre-trained Alexnet. In this research, the efficiency of the proposed system for speech recognition, speaker identification, and intelligibility assessment is evaluated. According to the results on the UA dataset, the proposed speech recognition system achieved 91.29% accuracy in speaker-dependent mode, the speaker identification system acquired 87.74% accuracy in text-dependent mode, and the intelligibility assessment system achieved 96.47% accuracy in two-class mode. Finally, we propose a multi-network speech recognition system that works fully automatically. This system is located in a cascade arrangement with the two-class intelligibility assessment system, and the output of this system activates each one of the speech recognition networks. This architecture achieves an accuracy of 92.3% WRR. The source code of this paper is available.
Noise robust speech emotion recognition with signal-to-noise ratio adapting speech enhancement
Sep 03, 2023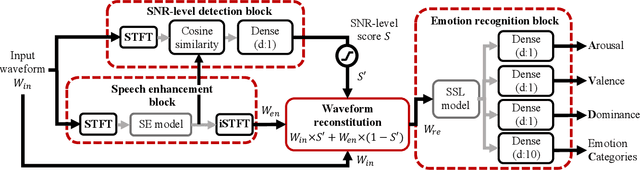

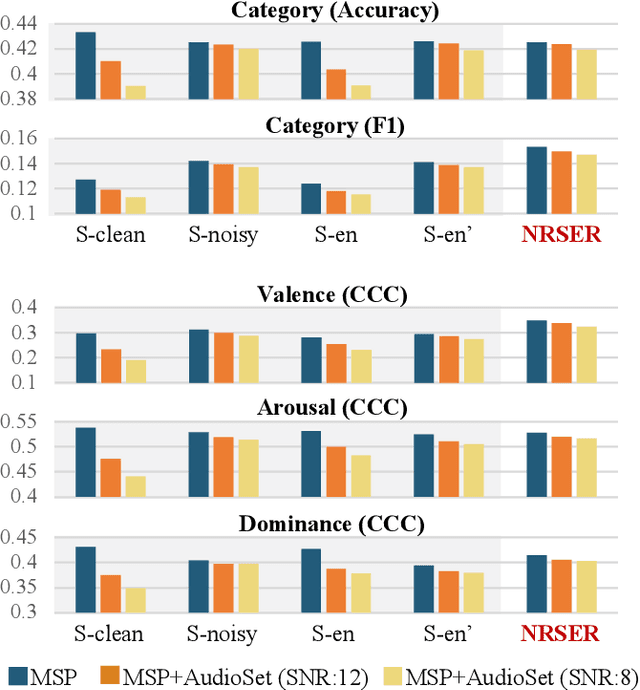
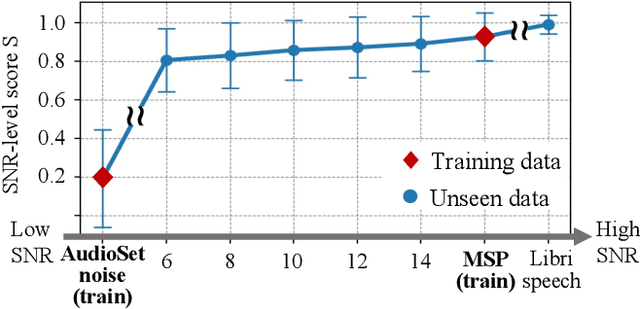
Speech emotion recognition (SER) often experiences reduced performance due to background noise. In addition, making a prediction on signals with only background noise could undermine user trust in the system. In this study, we propose a Noise Robust Speech Emotion Recognition system, NRSER. NRSER employs speech enhancement (SE) to effectively reduce the noise in input signals. Then, the signal-to-noise-ratio (SNR)-level detection structure and waveform reconstitution strategy are introduced to reduce the negative impact of SE on speech signals with no or little background noise. Our experimental results show that NRSER can effectively improve the noise robustness of the SER system, including preventing the system from making emotion recognition on signals consisting solely of background noise. Moreover, the proposed SNR-level detection structure can be used individually for tasks such as data selection.
Globally Normalising the Transducer for Streaming Speech Recognition
Jul 20, 2023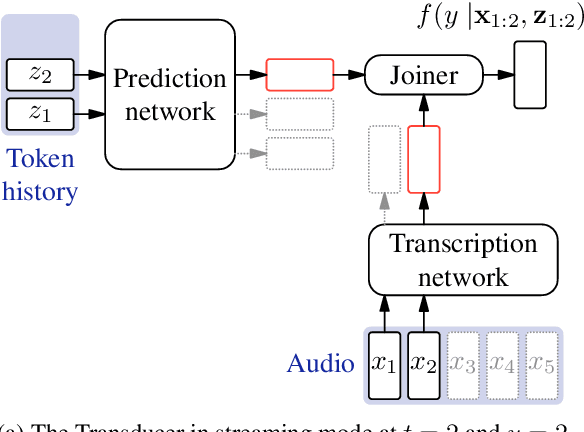
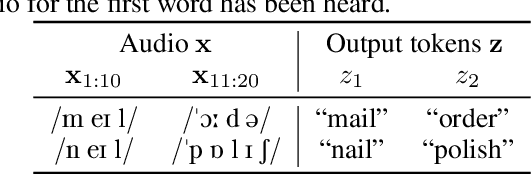
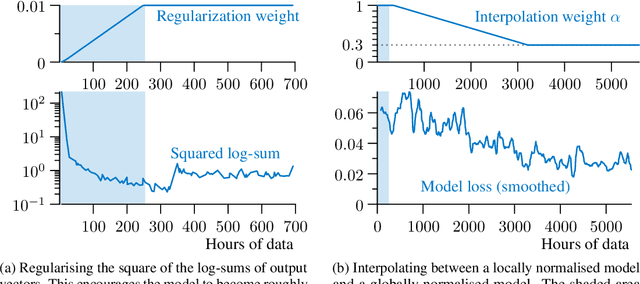
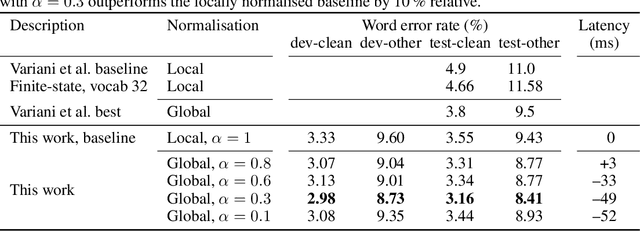
The Transducer (e.g. RNN-Transducer or Conformer-Transducer) generates an output label sequence as it traverses the input sequence. It is straightforward to use in streaming mode, where it generates partial hypotheses before the complete input has been seen. This makes it popular in speech recognition. However, in streaming mode the Transducer has a mathematical flaw which, simply put, restricts the model's ability to change its mind. The fix is to replace local normalisation (e.g. a softmax) with global normalisation, but then the loss function becomes impossible to evaluate exactly. A recent paper proposes to solve this by approximating the model, severely degrading performance. Instead, this paper proposes to approximate the loss function, allowing global normalisation to apply to a state-of-the-art streaming model. Global normalisation reduces its word error rate by 9-11% relative, closing almost half the gap between streaming and lookahead mode.
Investigating the Emergent Audio Classification Ability of ASR Foundation Models
Nov 15, 2023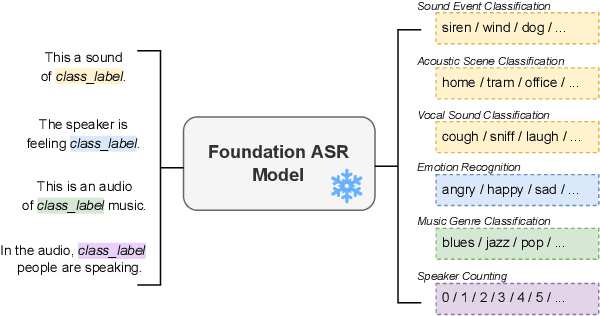
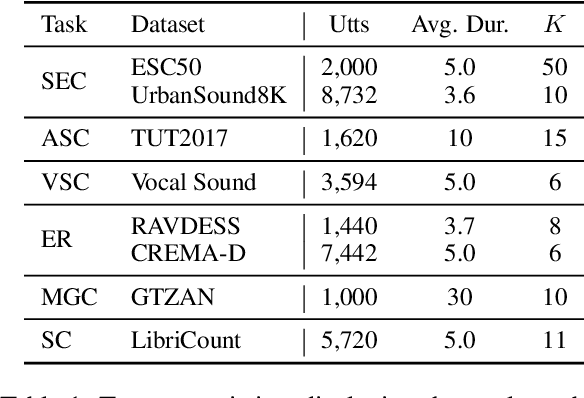


Text and vision foundation models can perform many tasks in a zero-shot setting, a desirable property that enables these systems to be applied in general and low-resource settings. However, there has been significantly less work on the zero-shot abilities of ASR foundation models, with these systems typically fine-tuned to specific tasks or constrained to applications that match their training criterion and data annotation. In this work we investigate the ability of Whisper and MMS, ASR foundation models trained primarily for speech recognition, to perform zero-shot audio classification. We use simple template-based text prompts at the decoder and use the resulting decoding probabilities to generate zero-shot predictions. Without training the model on extra data or adding any new parameters, we demonstrate that Whisper shows promising zero-shot classification performance on a range of 8 audio-classification datasets, outperforming existing state-of-the-art zero-shot baseline's accuracy by an average of 9%. One important step to unlock the emergent ability is debiasing, where a simple unsupervised reweighting method of the class probabilities yields consistent significant performance gains. We further show that performance increases with model size, implying that as ASR foundation models scale up, they may exhibit improved zero-shot performance.