 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Decoder-only Architecture for Speech Recognition with CTC Prompts and Text Data Augmentation
Sep 16, 2023
Collecting audio-text pairs is expensive; however, it is much easier to access text-only data. Unless using shallow fusion, end-to-end automatic speech recognition (ASR) models require architecture modifications or additional training schemes to use text-only data. Inspired by recent advances in decoder-only language models (LMs), such as GPT-3 and PaLM adopted for speech-processing tasks, we propose using a decoder-only architecture for ASR with simple text augmentation. To provide audio information, encoder features compressed by CTC prediction are used as prompts for the decoder, which can be regarded as refining CTC prediction using the decoder-only model. Because the decoder architecture is the same as an autoregressive LM, it is simple to enhance the model by leveraging external text data with LM training. An experimental comparison using LibriSpeech and Switchboard shows that our proposed models with text augmentation training reduced word error rates from ordinary CTC by 0.3% and 1.4% on LibriSpeech test-clean and testother set, respectively, and 2.9% and 5.0% on Switchboard and CallHome. The proposed model had advantage on computational efficiency compared with conventional encoder-decoder ASR models with a similar parameter setup, and outperformed them on the LibriSpeech 100h and Switchboard training scenarios.
Soft Random Sampling: A Theoretical and Empirical Analysis
Nov 24, 2023Soft random sampling (SRS) is a simple yet effective approach for efficient training of large-scale deep neural networks when dealing with massive data. SRS selects a subset uniformly at random with replacement from the full data set in each epoch. In this paper, we conduct a theoretical and empirical analysis of SRS. First, we analyze its sampling dynamics including data coverage and occupancy. Next, we investigate its convergence with non-convex objective functions and give the convergence rate. Finally, we provide its generalization performance. We empirically evaluate SRS for image recognition on CIFAR10 and automatic speech recognition on Librispeech and an in-house payload dataset to demonstrate its effectiveness. Compared to existing coreset-based data selection methods, SRS offers a better accuracy-efficiency trade-off. Especially on real-world industrial scale data sets, it is shown to be a powerful training strategy with significant speedup and competitive performance with almost no additional computing cost.
A Theory of Unsupervised Speech Recognition
Jun 09, 2023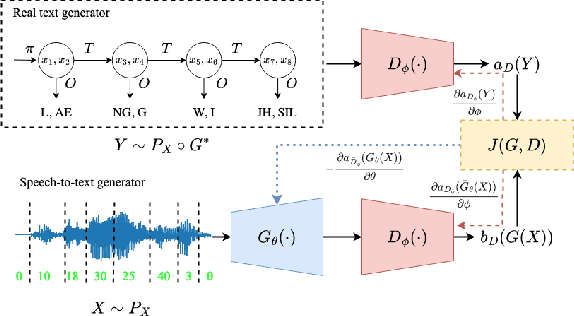
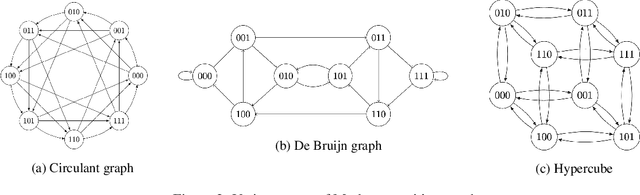
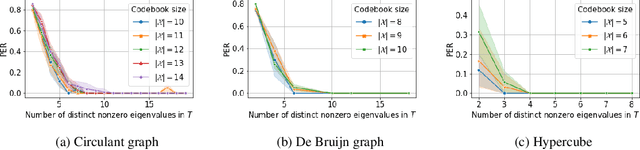
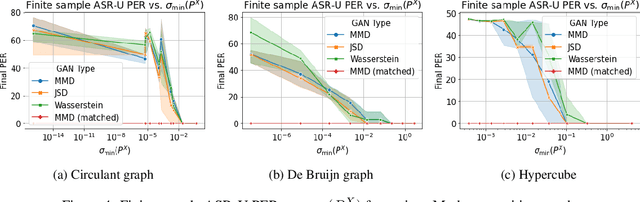
Unsupervised speech recognition (ASR-U) is the problem of learning automatic speech recognition (ASR) systems from unpaired speech-only and text-only corpora. While various algorithms exist to solve this problem, a theoretical framework is missing from studying their properties and addressing such issues as sensitivity to hyperparameters and training instability. In this paper, we proposed a general theoretical framework to study the properties of ASR-U systems based on random matrix theory and the theory of neural tangent kernels. Such a framework allows us to prove various learnability conditions and sample complexity bounds of ASR-U. Extensive ASR-U experiments on synthetic languages with three classes of transition graphs provide strong empirical evidence for our theory (code available at cactuswiththoughts/UnsupASRTheory.git).
Replay to Remember: Continual Layer-Specific Fine-tuning for German Speech Recognition
Jul 14, 2023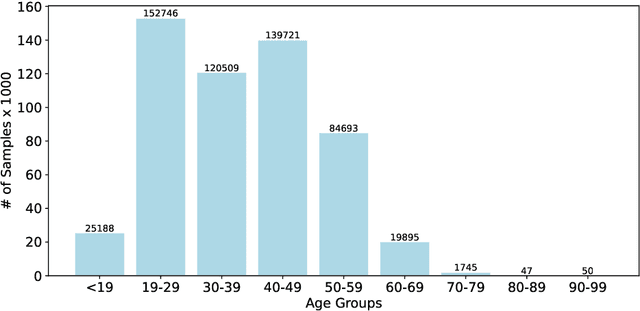
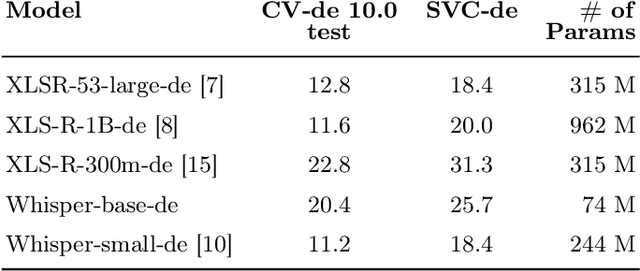

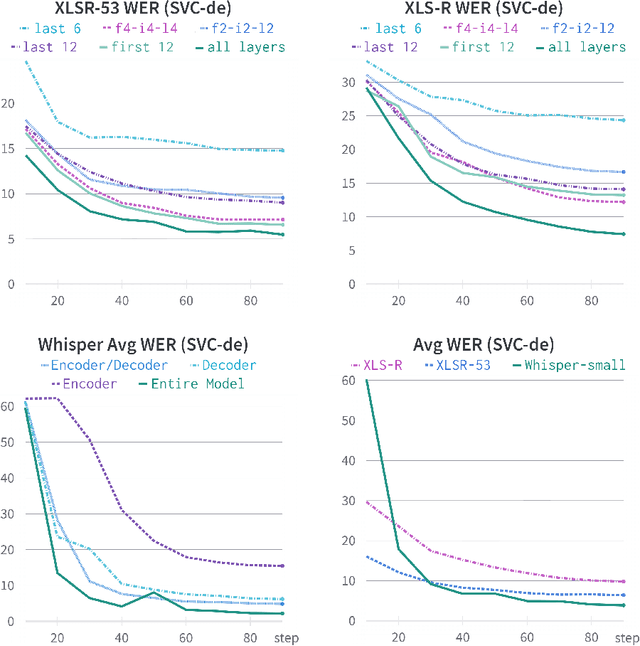
While Automatic Speech Recognition (ASR) models have shown significant advances with the introduction of unsupervised or self-supervised training techniques, these improvements are still only limited to a subsection of languages and speakers. Transfer learning enables the adaptation of large-scale multilingual models to not only low-resource languages but also to more specific speaker groups. However, fine-tuning on data from new domains is usually accompanied by a decrease in performance on the original domain. Therefore, in our experiments, we examine how well the performance of large-scale ASR models can be approximated for smaller domains, with our own dataset of German Senior Voice Commands (SVC-de), and how much of the general speech recognition performance can be preserved by selectively freezing parts of the model during training. To further increase the robustness of the ASR model to vocabulary and speakers outside of the fine-tuned domain, we apply Experience Replay for continual learning. By adding only a fraction of data from the original domain, we are able to reach Word-Error-Rates (WERs) below 5\% on the new domain, while stabilizing performance for general speech recognition at acceptable WERs.
Federated Representation Learning for Automatic Speech Recognition
Aug 07, 2023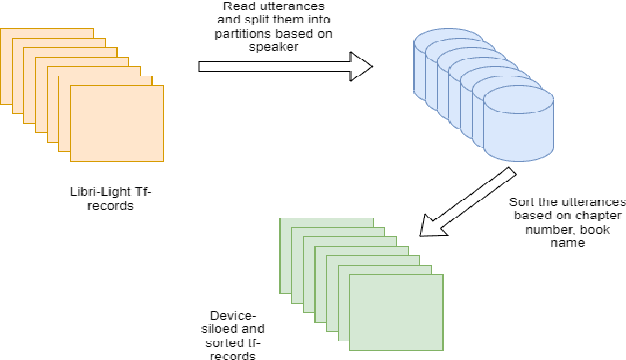
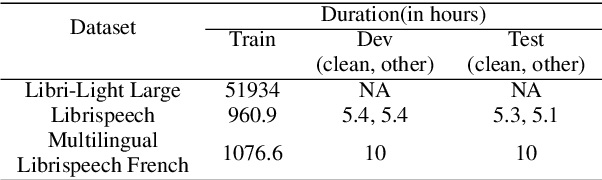
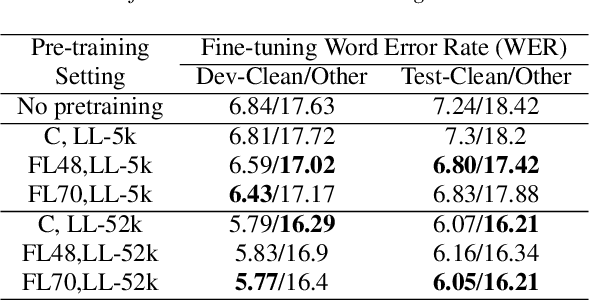
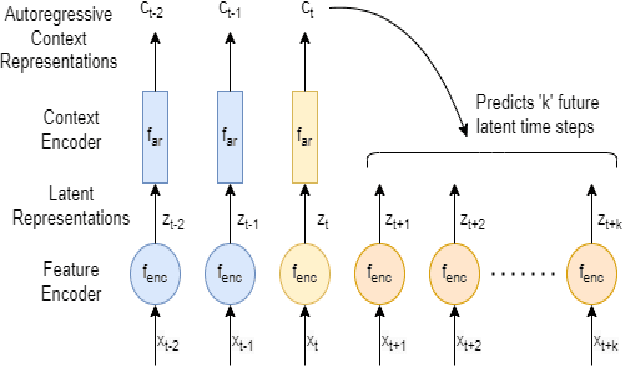
Federated Learning (FL) is a privacy-preserving paradigm, allowing edge devices to learn collaboratively without sharing data. Edge devices like Alexa and Siri are prospective sources of unlabeled audio data that can be tapped to learn robust audio representations. In this work, we bring Self-supervised Learning (SSL) and FL together to learn representations for Automatic Speech Recognition respecting data privacy constraints. We use the speaker and chapter information in the unlabeled speech dataset, Libri-Light, to simulate non-IID speaker-siloed data distributions and pre-train an LSTM encoder with the Contrastive Predictive Coding framework with FedSGD. We show that the pre-trained ASR encoder in FL performs as well as a centrally pre-trained model and produces an improvement of 12-15% (WER) compared to no pre-training. We further adapt the federated pre-trained models to a new language, French, and show a 20% (WER) improvement over no pre-training.
Do VSR Models Generalize Beyond LRS3?
Nov 23, 2023The Lip Reading Sentences-3 (LRS3) benchmark has primarily been the focus of intense research in visual speech recognition (VSR) during the last few years. As a result, there is an increased risk of overfitting to its excessively used test set, which is only one hour duration. To alleviate this issue, we build a new VSR test set named WildVSR, by closely following the LRS3 dataset creation processes. We then evaluate and analyse the extent to which the current VSR models generalize to the new test data. We evaluate a broad range of publicly available VSR models and find significant drops in performance on our test set, compared to their corresponding LRS3 results. Our results suggest that the increase in word error rates is caused by the models inability to generalize to slightly harder and in the wild lip sequences than those found in the LRS3 test set. Our new test benchmark is made public in order to enable future research towards more robust VSR models.
Adapting Large Language Model with Speech for Fully Formatted End-to-End Speech Recognition
Aug 03, 2023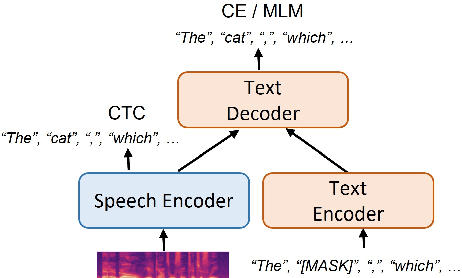
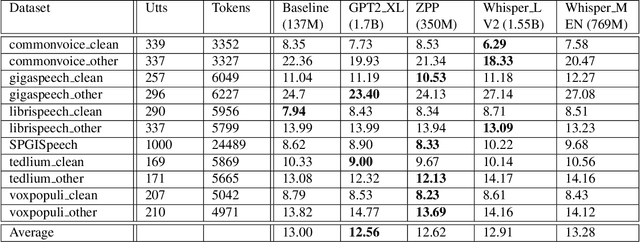

Most end-to-end (E2E) speech recognition models are composed of encoder and decoder blocks that perform acoustic and language modeling functions. Pretrained large language models (LLMs) have the potential to improve the performance of E2E ASR. However, integrating a pretrained language model into an E2E speech recognition model has shown limited benefits due to the mismatches between text-based LLMs and those used in E2E ASR. In this paper, we explore an alternative approach by adapting a pretrained LLMs to speech. Our experiments on fully-formatted E2E ASR transcription tasks across various domains demonstrate that our approach can effectively leverage the strengths of pretrained LLMs to produce more readable ASR transcriptions. Our model, which is based on the pretrained large language models with either an encoder-decoder or decoder-only structure, surpasses strong ASR models such as Whisper, in terms of recognition error rate, considering formats like punctuation and capitalization as well.
Multilingual self-supervised speech representations improve the speech recognition of low-resource African languages with codeswitching
Nov 25, 2023While many speakers of low-resource languages regularly code-switch between their languages and other regional languages or English, datasets of codeswitched speech are too small to train bespoke acoustic models from scratch or do language model rescoring. Here we propose finetuning self-supervised speech representations such as wav2vec 2.0 XLSR to recognize code-switched data. We find that finetuning self-supervised multilingual representations and augmenting them with n-gram language models trained from transcripts reduces absolute word error rates by up to 20% compared to baselines of hybrid models trained from scratch on code-switched data. Our findings suggest that in circumstances with limited training data finetuning self-supervised representations is a better performing and viable solution.
Bring the Noise: Introducing Noise Robustness to Pretrained Automatic Speech Recognition
Sep 05, 2023
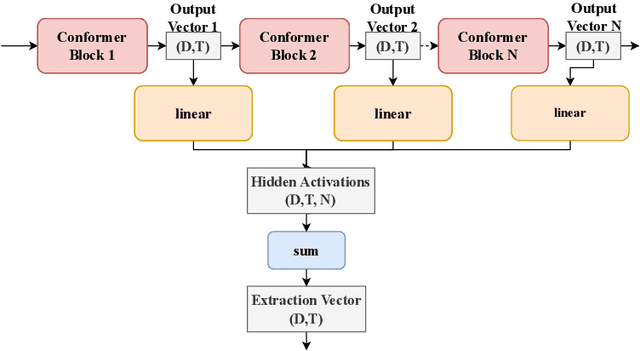
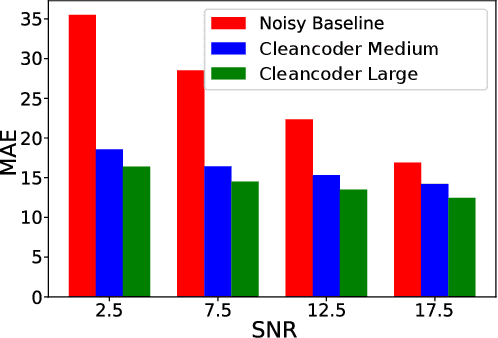
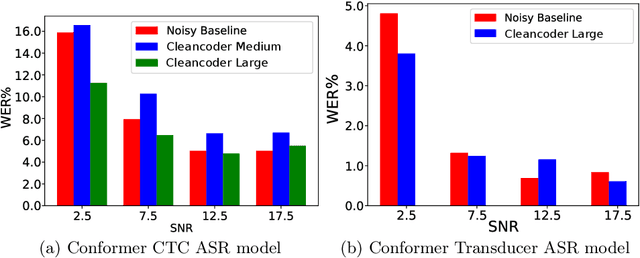
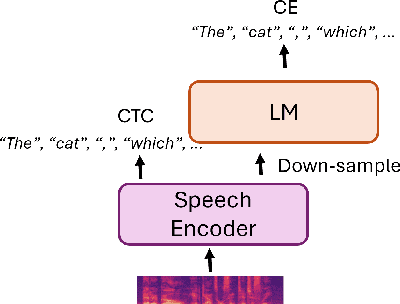
In recent research, in the domain of speech processing, large End-to-End (E2E) systems for Automatic Speech Recognition (ASR) have reported state-of-the-art performance on various benchmarks. These systems intrinsically learn how to handle and remove noise conditions from speech. Previous research has shown, that it is possible to extract the denoising capabilities of these models into a preprocessor network, which can be used as a frontend for downstream ASR models. However, the proposed methods were limited to specific fully convolutional architectures. In this work, we propose a novel method to extract the denoising capabilities, that can be applied to any encoder-decoder architecture. We propose the Cleancoder preprocessor architecture that extracts hidden activations from the Conformer ASR model and feeds them to a decoder to predict denoised spectrograms. We train our pre-processor on the Noisy Speech Database (NSD) to reconstruct denoised spectrograms from noisy inputs. Then, we evaluate our model as a frontend to a pretrained Conformer ASR model as well as a frontend to train smaller Conformer ASR models from scratch. We show that the Cleancoder is able to filter noise from speech and that it improves the total Word Error Rate (WER) of the downstream model in noisy conditions for both applications.
Whisper-MCE: Whisper Model Finetuned for Better Performance with Mixed Languages
Oct 27, 2023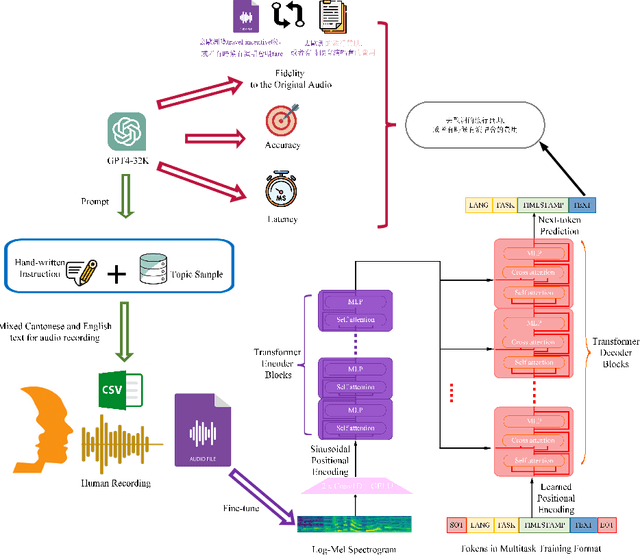
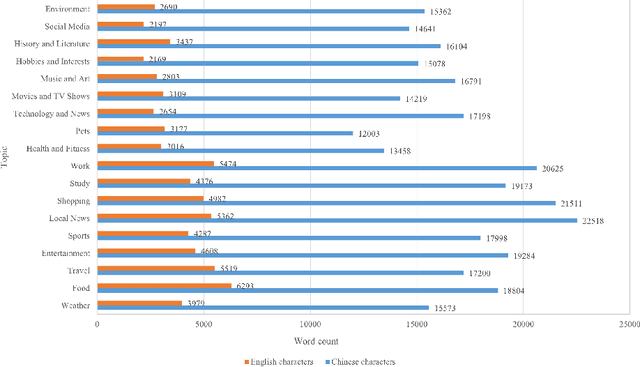
Recently Whisper has approached human-level robustness and accuracy in English automatic speech recognition (ASR), while in minor language and mixed language speech recognition, there remains a compelling need for further improvement. In this work, we present the impressive results of Whisper-MCE, our finetuned Whisper model, which was trained using our self-collected dataset, Mixed Cantonese and English audio dataset (MCE). Meanwhile, considering word error rate (WER) poses challenges when it comes to evaluating its effectiveness in minor language and mixed-language contexts, we present a novel rating mechanism. By comparing our model to the baseline whisper-large-v2 model, we demonstrate its superior ability to accurately capture the content of the original audio, achieve higher recognition accuracy, and exhibit faster recognition speed. Notably, our model outperforms other existing models in the specific task of recognizing mixed language.