 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A Quantitative Approach to Understand Self-Supervised Models as Cross-lingual Feature Extractors
Nov 27, 2023
In this work, we study the features extracted by English self-supervised learning (SSL) models in cross-lingual contexts and propose a new metric to predict the quality of feature representations. Using automatic speech recognition (ASR) as a downstream task, we analyze the effect of model size, training objectives, and model architecture on the models' performance as a feature extractor for a set of topologically diverse corpora. We develop a novel metric, the Phonetic-Syntax Ratio (PSR), to measure the phonetic and synthetic information in the extracted representations using deep generalized canonical correlation analysis. Results show the contrastive loss in the wav2vec2.0 objective facilitates more effective cross-lingual feature extraction. There is a positive correlation between PSR scores and ASR performance, suggesting that phonetic information extracted by monolingual SSL models can be used for downstream tasks in cross-lingual settings. The proposed metric is an effective indicator of the quality of the representations and can be useful for model selection.
Phonetic-aware speaker embedding for far-field speaker verification
Nov 27, 2023When a speaker verification (SV) system operates far from the sound sourced, significant challenges arise due to the interference of noise and reverberation. Studies have shown that incorporating phonetic information into speaker embedding can improve the performance of text-independent SV. Inspired by this observation, we propose a joint-training speech recognition and speaker recognition (JTSS) framework to exploit phonetic content for far-field SV. The framework encourages speaker embeddings to preserve phonetic information by matching the frame-based feature maps of a speaker embedding network with wav2vec's vectors. The intuition is that phonetic information can preserve low-level acoustic dynamics with speaker information and thus partly compensate for the degradation due to noise and reverberation. Results show that the proposed framework outperforms the standard speaker embedding on the VOiCES Challenge 2019 evaluation set and the VoxCeleb1 test set. This indicates that leveraging phonetic information under far-field conditions is effective for learning robust speaker representations.
The CHiME-7 Challenge: System Description and Performance of NeMo Team's DASR System
Oct 18, 2023We present the NVIDIA NeMo team's multi-channel speech recognition system for the 7th CHiME Challenge Distant Automatic Speech Recognition (DASR) Task, focusing on the development of a multi-channel, multi-speaker speech recognition system tailored to transcribe speech from distributed microphones and microphone arrays. The system predominantly comprises of the following integral modules: the Speaker Diarization Module, Multi-channel Audio Front-End Processing Module, and the ASR Module. These components collectively establish a cascading system, meticulously processing multi-channel and multi-speaker audio input. Moreover, this paper highlights the comprehensive optimization process that significantly enhanced our system's performance. Our team's submission is largely based on NeMo toolkits and will be publicly available.
End-to-end Joint Rich and Normalized ASR with a limited amount of rich training data
Nov 29, 2023Joint rich and normalized automatic speech recognition (ASR), that produces transcriptions both with and without punctuation and capitalization, remains a challenge. End-to-end (E2E) ASR models offer both convenience and the ability to perform such joint transcription of speech. Training such models requires paired speech and rich text data, which is not widely available. In this paper, we compare two different approaches to train a stateless Transducer-based E2E joint rich and normalized ASR system, ready for streaming applications, with a limited amount of rich labeled data. The first approach uses a language model to generate pseudo-rich transcriptions of normalized training data. The second approach uses a single decoder conditioned on the type of the output. The first approach leads to E2E rich ASR which perform better on out-of-domain data, with up to 9% relative reduction in errors. The second approach demonstrates the feasibility of an E2E joint rich and normalized ASR system using as low as 5% rich training data with moderate (2.42% absolute) increase in errors.
Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model
Dec 02, 2023The big language model represented by ChatGPT has had a disruptive impact on the field of artificial intelligence. But it mainly focuses on Natural language processing, speech recognition, machine learning and natural-language understanding. This paper innovatively applies the big language model to the field of intelligent decision-making, places the big language model in the decision-making center, and constructs an agent architecture with the big language model as the core. Based on this, it further proposes a two-layer agent task planning, issues and executes decision commands through the interaction of natural language, and carries out simulation verification through the wargame simulation environment. Through the game confrontation simulation experiment, it is found that the intelligent decision-making ability of the big language model is significantly stronger than the commonly used reinforcement learning AI and rule AI, and the intelligence, understandability and generalization are all better. And through experiments, it was found that the intelligence of the large language model is closely related to prompt. This work also extends the large language model from previous human-computer interaction to the field of intelligent decision-making, which has important reference value and significance for the development of intelligent decision-making.
Convoifilter: A case study of doing cocktail party speech recognition
Aug 22, 2023
This paper presents an end-to-end model designed to improve automatic speech recognition (ASR) for a particular speaker in a crowded, noisy environment. The model utilizes a single-channel speech enhancement module that isolates the speaker's voice from background noise, along with an ASR module. Through this approach, the model is able to decrease the word error rate (WER) of ASR from 80% to 26.4%. Typically, these two components are adjusted independently due to variations in data requirements. However, speech enhancement can create anomalies that decrease ASR efficiency. By implementing a joint fine-tuning strategy, the model can reduce the WER from 26.4% in separate tuning to 14.5% in joint tuning.
Indonesian Automatic Speech Recognition with XLSR-53
Aug 20, 2023
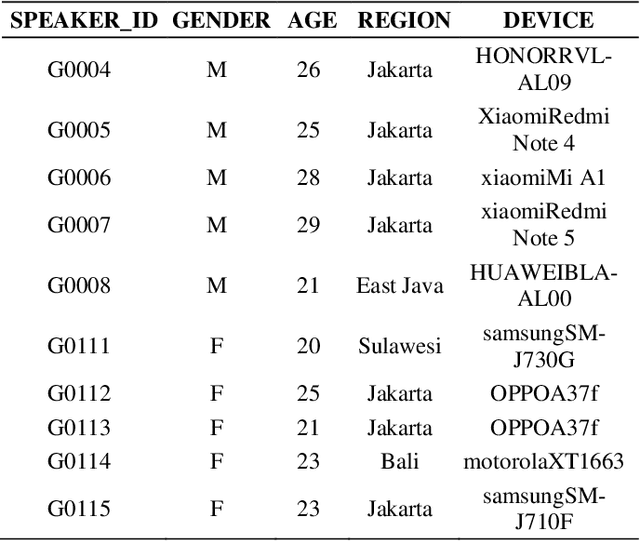
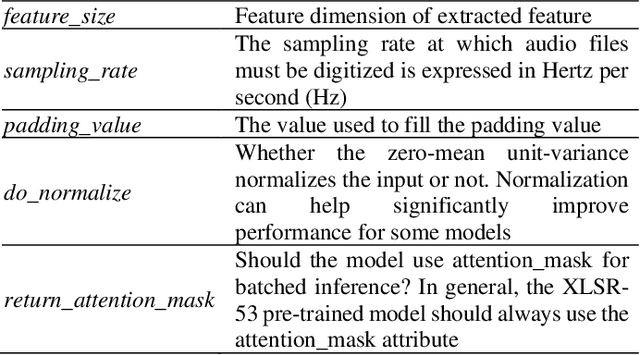
This study focuses on the development of Indonesian Automatic Speech Recognition (ASR) using the XLSR-53 pre-trained model, the XLSR stands for cross-lingual speech representations. The use of this XLSR-53 pre-trained model is to significantly reduce the amount of training data in non-English languages required to achieve a competitive Word Error Rate (WER). The total amount of data used in this study is 24 hours, 18 minutes, and 1 second: (1) TITML-IDN 14 hours and 31 minutes; (2) Magic Data 3 hours and 33 minutes; and (3) Common Voice 6 hours, 14 minutes, and 1 second. With a WER of 20%, the model built in this study can compete with similar models using the Common Voice dataset split test. WER can be decreased by around 8% using a language model, resulted in WER from 20% to 12%. Thus, the results of this study have succeeded in perfecting previous research in contributing to the creation of a better Indonesian ASR with a smaller amount of data.
HyPoradise: An Open Baseline for Generative Speech Recognition with Large Language Models
Sep 27, 2023
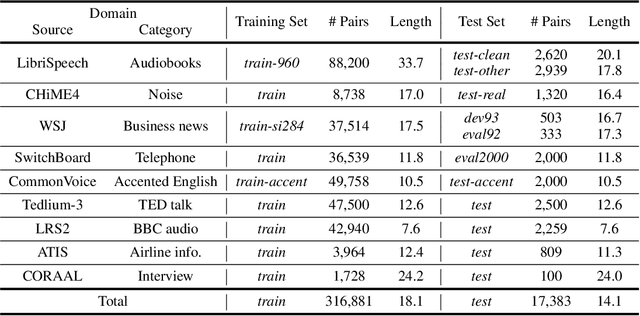

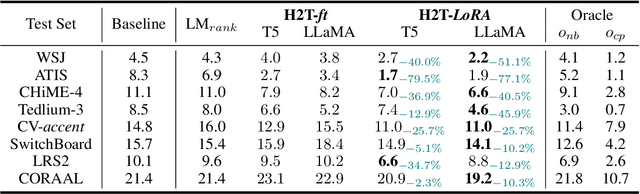
Advancements in deep neural networks have allowed automatic speech recognition (ASR) systems to attain human parity on several publicly available clean speech datasets. However, even state-of-the-art ASR systems experience performance degradation when confronted with adverse conditions, as a well-trained acoustic model is sensitive to variations in the speech domain, e.g., background noise. Intuitively, humans address this issue by relying on their linguistic knowledge: the meaning of ambiguous spoken terms is usually inferred from contextual cues thereby reducing the dependency on the auditory system. Inspired by this observation, we introduce the first open-source benchmark to utilize external large language models (LLMs) for ASR error correction, where N-best decoding hypotheses provide informative elements for true transcription prediction. This approach is a paradigm shift from the traditional language model rescoring strategy that can only select one candidate hypothesis as the output transcription. The proposed benchmark contains a novel dataset, HyPoradise (HP), encompassing more than 334,000 pairs of N-best hypotheses and corresponding accurate transcriptions across prevalent speech domains. Given this dataset, we examine three types of error correction techniques based on LLMs with varying amounts of labeled hypotheses-transcription pairs, which gains a significant word error rate (WER) reduction. Experimental evidence demonstrates the proposed technique achieves a breakthrough by surpassing the upper bound of traditional re-ranking based methods. More surprisingly, LLM with reasonable prompt and its generative capability can even correct those tokens that are missing in N-best list. We make our results publicly accessible for reproducible pipelines with released pre-trained models, thus providing a new evaluation paradigm for ASR error correction with LLMs.
Improving Audio-Visual Speech Recognition by Lip-Subword Correlation Based Visual Pre-training and Cross-Modal Fusion Encoder
Aug 14, 2023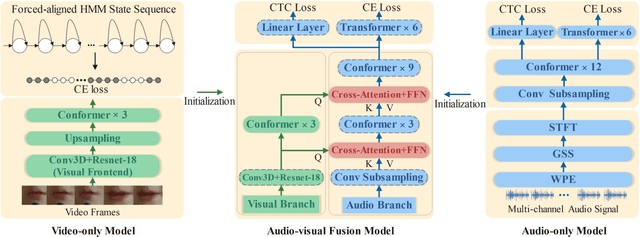
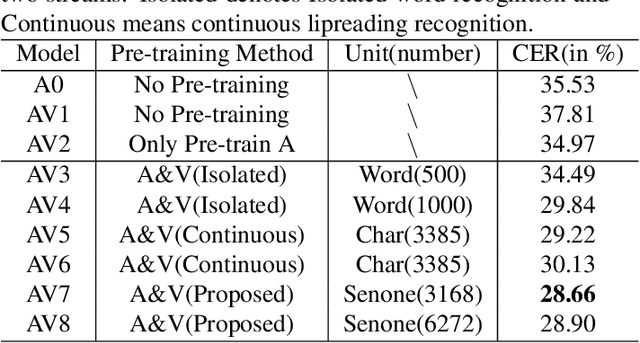
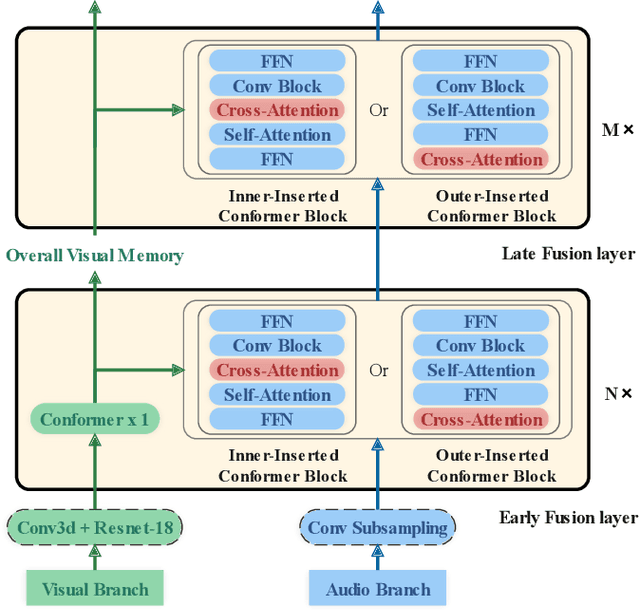
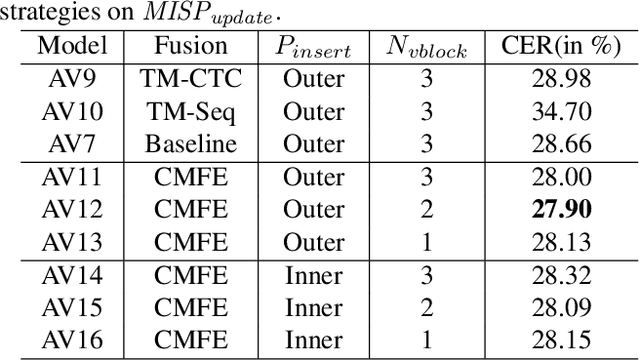
In recent research, slight performance improvement is observed from automatic speech recognition systems to audio-visual speech recognition systems in the end-to-end framework with low-quality videos. Unmatching convergence rates and specialized input representations between audio and visual modalities are considered to cause the problem. In this paper, we propose two novel techniques to improve audio-visual speech recognition (AVSR) under a pre-training and fine-tuning training framework. First, we explore the correlation between lip shapes and syllable-level subword units in Mandarin to establish good frame-level syllable boundaries from lip shapes. This enables accurate alignment of video and audio streams during visual model pre-training and cross-modal fusion. Next, we propose an audio-guided cross-modal fusion encoder (CMFE) neural network to utilize main training parameters for multiple cross-modal attention layers to make full use of modality complementarity. Experiments on the MISP2021-AVSR data set show the effectiveness of the two proposed techniques. Together, using only a relatively small amount of training data, the final system achieves better performances than state-of-the-art systems with more complex front-ends and back-ends.
Sumformer: A Linear-Complexity Alternative to Self-Attention for Speech Recognition
Jul 12, 2023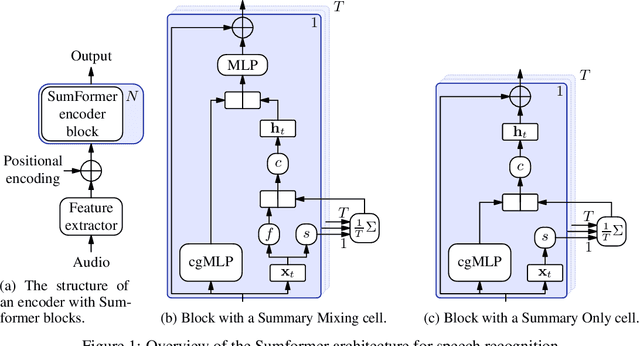
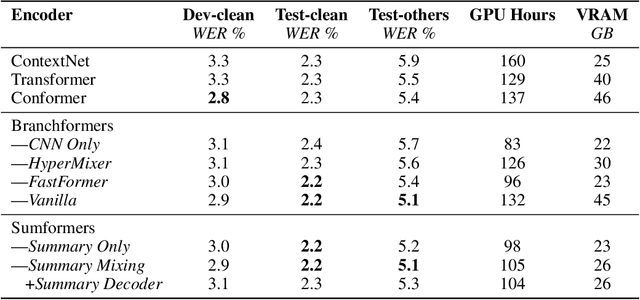
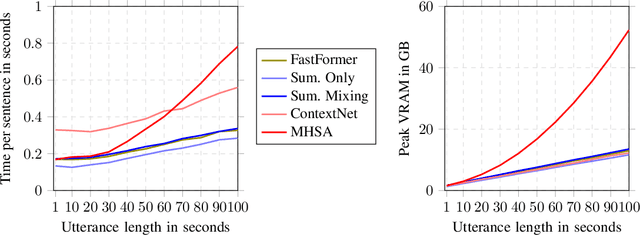
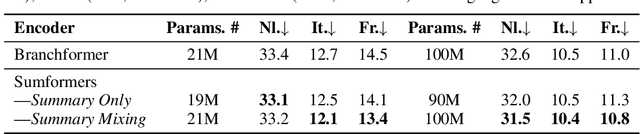
Modern speech recognition systems rely on self-attention. Unfortunately, token mixing with self-attention takes quadratic time in the length of the speech utterance, slowing down inference as well as training and increasing memory consumption. Cheaper alternatives to self-attention for ASR have been developed, but fail to consistently reach the same level of accuracy. In practice, however, the self-attention weights of trained speech recognizers take the form of a global average over time. This paper, therefore, proposes a linear-time alternative to self-attention for speech recognition. It summarises a whole utterance with the mean over vectors for all time steps. This single summary is then combined with time-specific information. We call this method ``Summary Mixing''. Introducing Summary Mixing in state-of-the-art ASR models makes it feasible to preserve or exceed previous speech recognition performance while lowering the training and inference times by up to 27% and reducing the memory budget by a factor of two.