 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Mi-Go: Test Framework which uses YouTube as Data Source for Evaluating Speech Recognition Models like OpenAI's Whisper
Sep 01, 2023
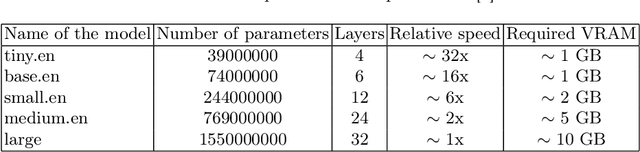
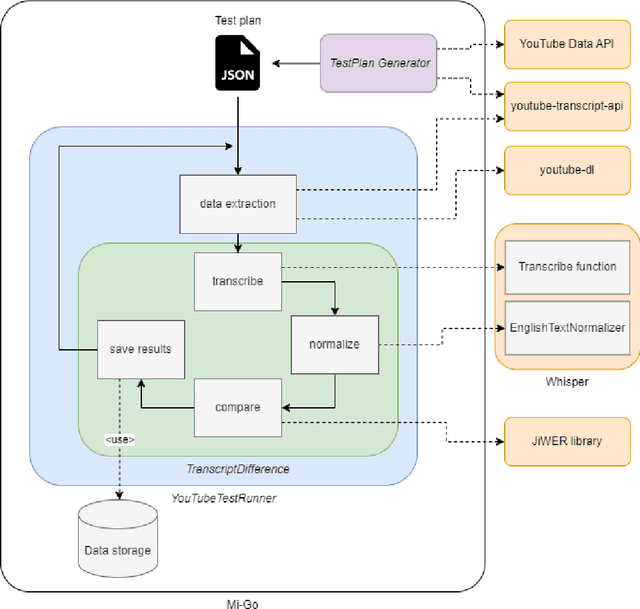
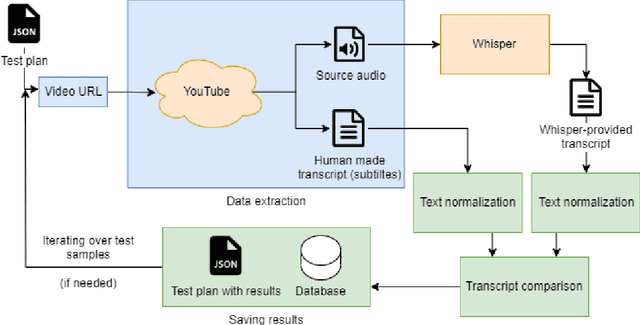
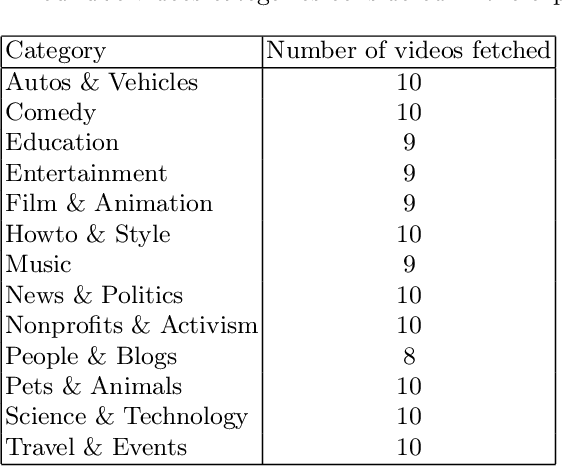
This article introduces Mi-Go, a novel testing framework aimed at evaluating the performance and adaptability of general-purpose speech recognition machine learning models across diverse real-world scenarios. The framework leverages YouTube as a rich and continuously updated data source, accounting for multiple languages, accents, dialects, speaking styles, and audio quality levels. To demonstrate the effectiveness of the framework, the Whisper model, developed by OpenAI, was employed as a test object. The tests involve using a total of 124 YouTube videos to test all Whisper model versions. The results underscore the utility of YouTube as a valuable testing platform for speech recognition models, ensuring their robustness, accuracy, and adaptability to diverse languages and acoustic conditions. Additionally, by contrasting the machine-generated transcriptions against human-made subtitles, the Mi-Go framework can help pinpoint potential misuse of YouTube subtitles, like Search Engine Optimization.
FlowMur: A Stealthy and Practical Audio Backdoor Attack with Limited Knowledge
Dec 15, 2023Speech recognition systems driven by DNNs have revolutionized human-computer interaction through voice interfaces, which significantly facilitate our daily lives. However, the growing popularity of these systems also raises special concerns on their security, particularly regarding backdoor attacks. A backdoor attack inserts one or more hidden backdoors into a DNN model during its training process, such that it does not affect the model's performance on benign inputs, but forces the model to produce an adversary-desired output if a specific trigger is present in the model input. Despite the initial success of current audio backdoor attacks, they suffer from the following limitations: (i) Most of them require sufficient knowledge, which limits their widespread adoption. (ii) They are not stealthy enough, thus easy to be detected by humans. (iii) Most of them cannot attack live speech, reducing their practicality. To address these problems, in this paper, we propose FlowMur, a stealthy and practical audio backdoor attack that can be launched with limited knowledge. FlowMur constructs an auxiliary dataset and a surrogate model to augment adversary knowledge. To achieve dynamicity, it formulates trigger generation as an optimization problem and optimizes the trigger over different attachment positions. To enhance stealthiness, we propose an adaptive data poisoning method according to Signal-to-Noise Ratio (SNR). Furthermore, ambient noise is incorporated into the process of trigger generation and data poisoning to make FlowMur robust to ambient noise and improve its practicality. Extensive experiments conducted on two datasets demonstrate that FlowMur achieves high attack performance in both digital and physical settings while remaining resilient to state-of-the-art defenses. In particular, a human study confirms that triggers generated by FlowMur are not easily detected by participants.
Bigger is not Always Better: The Effect of Context Size on Speech Pre-Training
Dec 03, 2023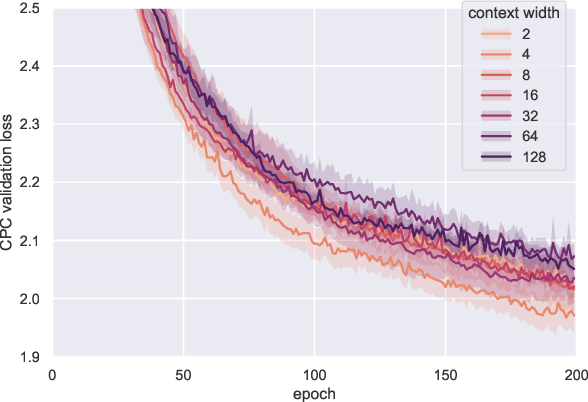
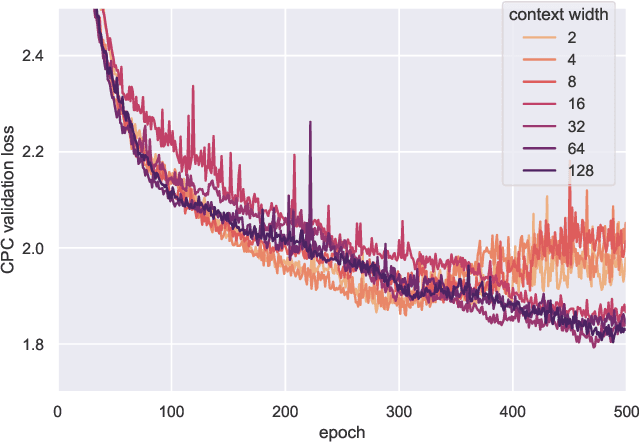
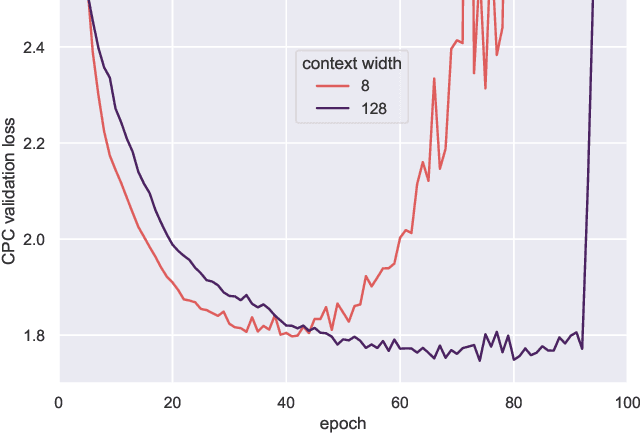
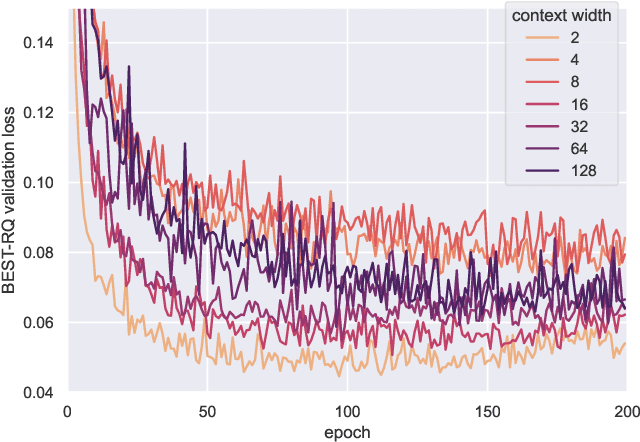
It has been generally assumed in the automatic speech recognition (ASR) literature that it is better for models to have access to wider context windows. Yet, many of the potential reasons this might be true in the supervised setting do not necessarily transfer over to the case of unsupervised learning. We investigate how much context is necessary to achieve high-quality pre-trained acoustic models using self-supervised learning. We principally investigate contrastive predictive coding (CPC), which we adapt to be able to precisely control the amount of context visible to the model during training and inference. We find that phone discriminability in the resulting model representations peaks at around 40~ms of preceding context, and that having too much context (beyond around 320 ms) substantially degrades the quality of the representations. Surprisingly, we find that this pattern also transfers to supervised ASR when the pre-trained representations are used as frozen input features. Our results point to potential changes in the design of current upstream architectures to better facilitate a variety of downstream tasks.
Leveraging Data Collection and Unsupervised Learning for Code-switched Tunisian Arabic Automatic Speech Recognition
Sep 20, 2023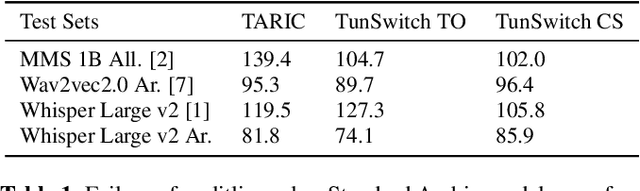
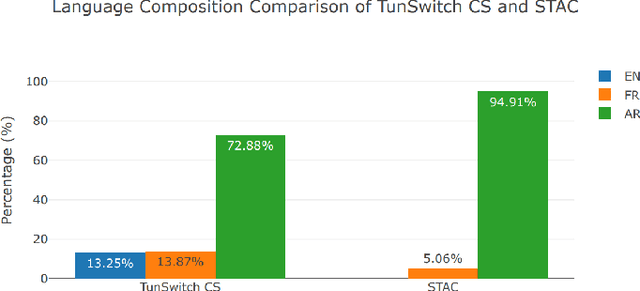

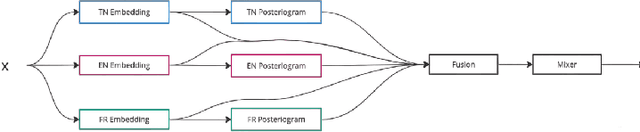
Crafting an effective Automatic Speech Recognition (ASR) solution for dialects demands innovative approaches that not only address the data scarcity issue but also navigate the intricacies of linguistic diversity. In this paper, we address the aforementioned ASR challenge, focusing on the Tunisian dialect. First, textual and audio data is collected and in some cases annotated. Second, we explore self-supervision, semi-supervision and few-shot code-switching approaches to push the state-of-the-art on different Tunisian test sets; covering different acoustic, linguistic and prosodic conditions. Finally, and given the absence of conventional spelling, we produce a human evaluation of our transcripts to avoid the noise coming from spelling inadequacies in our testing references. Our models, allowing to transcribe audio samples in a linguistic mix involving Tunisian Arabic, English and French, and all the data used during training and testing are released for public use and further improvements.
End-to-end Transfer Learning for Speaker-independent Cross-language Speech Emotion Recognition
Nov 22, 2023Data-driven models achieve successful results in Speech Emotion Recognition (SER). However, these models, which are based on general acoustic features or end-to-end approaches, show poor performance when the testing set has a different language (i.e., the cross-language setting) than the training set or when they come from a different dataset (i.e., the cross-corpus setting). To alleviate this problem, this paper presents an end-to-end Deep Neural Network (DNN) model based on transfer learning for cross-language SER. We use the wav2vec 2.0 pre-trained model to transform audio time-domain waveforms from different languages, different speakers and different recording conditions into a feature space shared by multiple languages, thereby it reduces the language variabilities in the speech features. Next, we propose a new Deep-Within-Class Co-variance Normalisation (Deep-WCCN) layer that can be inserted into the DNN model and it aims to reduce other variabilities including speaker variability, channel variability and so on. The whole model is fine-tuned in an end-to-end manner on a combined loss and is validated on datasets from three languages (i.e., English, German, Chinese). Experiment results show that our proposed method not only outperforms the baseline model that is based on common acoustic feature sets for SER in the within-language setting, but also significantly outperforms the baseline model for cross-language setting. In addition, we also experimentally validate the effectiveness of Deep-WCCN, which can further improve the model performance. Finally, to comparing the results in the recent literatures that use the same testing datasets, our proposed model shows significantly better performance than other state-of-the-art models in cross-language SER.
SER_AMPEL: A multi-source dataset for SER of Italian older adults
Nov 24, 2023In this paper, SER_AMPEL, a multi-source dataset for speech emotion recognition (SER) is presented. The peculiarity of the dataset is that it is collected with the aim of providing a reference for speech emotion recognition in case of Italian older adults. The dataset is collected following different protocols, in particular considering acted conversations, extracted from movies and TV series, and recording natural conversations where the emotions are elicited by proper questions. The evidence of the need for such a dataset emerges from the analysis of the state of the art. Preliminary considerations on the critical issues of SER are reported analyzing the classification results on a subset of the proposed dataset.
Unsupervised Pre-Training for Vietnamese Automatic Speech Recognition in the HYKIST Project
Sep 26, 2023In today's interconnected globe, moving abroad is more and more prevalent, whether it's for employment, refugee resettlement, or other causes. Language difficulties between natives and immigrants present a common issue on a daily basis, especially in medical domain. This can make it difficult for patients and doctors to communicate during anamnesis or in the emergency room, which compromises patient care. The goal of the HYKIST Project is to develop a speech translation system to support patient-doctor communication with ASR and MT. ASR systems have recently displayed astounding performance on particular tasks for which enough quantities of training data are available, such as LibriSpeech. Building a good model is still difficult due to a variety of speaking styles, acoustic and recording settings, and a lack of in-domain training data. In this thesis, we describe our efforts to construct ASR systems for a conversational telephone speech recognition task in the medical domain for Vietnamese language to assist emergency room contact between doctors and patients across linguistic barriers. In order to enhance the system's performance, we investigate various training schedules and data combining strategies. We also examine how best to make use of the little data that is available. The use of publicly accessible models like XLSR-53 is compared to the use of customized pre-trained models, and both supervised and unsupervised approaches are utilized using wav2vec 2.0 as architecture.
* Bachelor Thesis
Federated Learning with Differential Privacy for End-to-End Speech Recognition
Sep 29, 2023While federated learning (FL) has recently emerged as a promising approach to train machine learning models, it is limited to only preliminary explorations in the domain of automatic speech recognition (ASR). Moreover, FL does not inherently guarantee user privacy and requires the use of differential privacy (DP) for robust privacy guarantees. However, we are not aware of prior work on applying DP to FL for ASR. In this paper, we aim to bridge this research gap by formulating an ASR benchmark for FL with DP and establishing the first baselines. First, we extend the existing research on FL for ASR by exploring different aspects of recent $\textit{large end-to-end transformer models}$: architecture design, seed models, data heterogeneity, domain shift, and impact of cohort size. With a $\textit{practical}$ number of central aggregations we are able to train $\textbf{FL models}$ that are \textbf{nearly optimal} even with heterogeneous data, a seed model from another domain, or no pre-trained seed model. Second, we apply DP to FL for ASR, which is non-trivial since DP noise severely affects model training, especially for large transformer models, due to highly imbalanced gradients in the attention block. We counteract the adverse effect of DP noise by reviving per-layer clipping and explaining why its effect is more apparent in our case than in the prior work. Remarkably, we achieve user-level ($7.2$, $10^{-9}$)-$\textbf{DP}$ (resp. ($4.5$, $10^{-9}$)-$\textbf{DP}$) with a 1.3% (resp. 4.6%) absolute drop in the word error rate for extrapolation to high (resp. low) population scale for $\textbf{FL with DP in ASR}$.
Multimodal Data and Resource Efficient Device-Directed Speech Detection with Large Foundation Models
Dec 06, 2023Interactions with virtual assistants typically start with a trigger phrase followed by a command. In this work, we explore the possibility of making these interactions more natural by eliminating the need for a trigger phrase. Our goal is to determine whether a user addressed the virtual assistant based on signals obtained from the streaming audio recorded by the device microphone. We address this task by combining 1-best hypotheses and decoder signals from an automatic speech recognition system with acoustic representations from an audio encoder as input features to a large language model (LLM). In particular, we are interested in data and resource efficient systems that require only a small amount of training data and can operate in scenarios with only a single frozen LLM available on a device. For this reason, our model is trained on 80k or less examples of multimodal data using a combination of low-rank adaptation and prefix tuning. We compare the proposed system to unimodal baselines and show that the multimodal approach achieves lower equal-error-rates (EERs), while using only a fraction of the training data. We also show that low-dimensional specialized audio representations lead to lower EERs than high-dimensional general audio representations.
CDSD: Chinese Dysarthria Speech Database
Oct 24, 2023We present the Chinese Dysarthria Speech Database (CDSD) as a valuable resource for dysarthria research. This database comprises speech data from 24 participants with dysarthria. Among these participants, one recorded an additional 10 hours of speech data, while each recorded one hour, resulting in 34 hours of speech material. To accommodate participants with varying cognitive levels, our text pool primarily consists of content from the AISHELL-1 dataset and speeches by primary and secondary school students. When participants read these texts, they must use a mobile device or the ZOOM F8n multi-track field recorder to record their speeches. In this paper, we elucidate the data collection and annotation processes and present an approach for establishing a baseline for dysarthric speech recognition. Furthermore, we conducted a speaker-dependent dysarthric speech recognition experiment using an additional 10 hours of speech data from one of our participants. Our research findings indicate that, through extensive data-driven model training, fine-tuning limited quantities of specific individual data yields commendable results in speaker-dependent dysarthric speech recognition. However, we observe significant variations in recognition results among different dysarthric speakers. These insights provide valuable reference points for speaker-dependent dysarthric speech recognition.