 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
One model to rule them all ? Towards End-to-End Joint Speaker Diarization and Speech Recognition
Oct 02, 2023
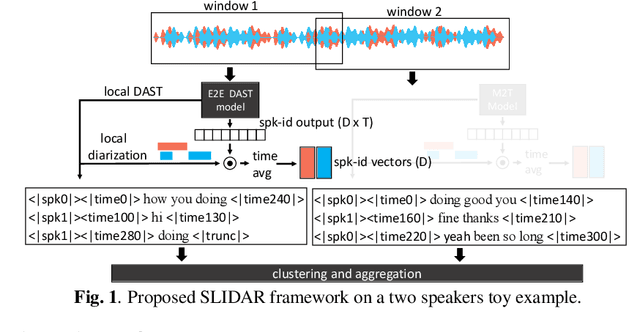

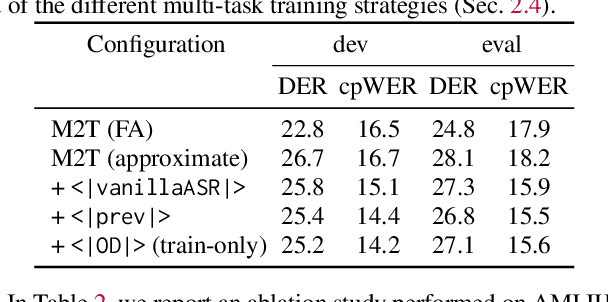
This paper presents a novel framework for joint speaker diarization (SD) and automatic speech recognition (ASR), named SLIDAR (sliding-window diarization-augmented recognition). SLIDAR can process arbitrary length inputs and can handle any number of speakers, effectively solving ``who spoke what, when'' concurrently. SLIDAR leverages a sliding window approach and consists of an end-to-end diarization-augmented speech transcription (E2E DAST) model which provides, locally, for each window: transcripts, diarization and speaker embeddings. The E2E DAST model is based on an encoder-decoder architecture and leverages recent techniques such as serialized output training and ``Whisper-style" prompting. The local outputs are then combined to get the final SD+ASR result by clustering the speaker embeddings to get global speaker identities. Experiments performed on monaural recordings from the AMI corpus confirm the effectiveness of the method in both close-talk and far-field speech scenarios.
AudioFool: Fast, Universal and synchronization-free Cross-Domain Attack on Speech Recognition
Sep 20, 2023Automatic Speech Recognition systems have been shown to be vulnerable to adversarial attacks that manipulate the command executed on the device. Recent research has focused on exploring methods to create such attacks, however, some issues relating to Over-The-Air (OTA) attacks have not been properly addressed. In our work, we examine the needed properties of robust attacks compatible with the OTA model, and we design a method of generating attacks with arbitrary such desired properties, namely the invariance to synchronization, and the robustness to filtering: this allows a Denial-of-Service (DoS) attack against ASR systems. We achieve these characteristics by constructing attacks in a modified frequency domain through an inverse Fourier transform. We evaluate our method on standard keyword classification tasks and analyze it in OTA, and we analyze the properties of the cross-domain attacks to explain the efficiency of the approach.
Sparsely Shared LoRA on Whisper for Child Speech Recognition
Sep 21, 2023Whisper is a powerful automatic speech recognition (ASR) model. Nevertheless, its zero-shot performance on low-resource speech requires further improvement. Child speech, as a representative type of low-resource speech, is leveraged for adaptation. Recently, parameter-efficient fine-tuning (PEFT) in NLP was shown to be comparable and even better than full fine-tuning, while only needing to tune a small set of trainable parameters. However, current PEFT methods have not been well examined for their effectiveness on Whisper. In this paper, only parameter composition types of PEFT approaches such as LoRA and Bitfit are investigated as they do not bring extra inference costs. Different popular PEFT methods are examined. Particularly, we compare LoRA and AdaLoRA and figure out the learnable rank coefficient is a good design. Inspired by the sparse rank distribution allocated by AdaLoRA, a novel PEFT approach Sparsely Shared LoRA (S2-LoRA) is proposed. The two low-rank decomposed matrices are globally shared. Each weight matrix only has to maintain its specific rank coefficients that are constrained to be sparse. Experiments on low-resource Chinese child speech show that with much fewer trainable parameters, S2-LoRA can achieve comparable in-domain adaptation performance to AdaLoRA and exhibit better generalization ability on out-of-domain data. In addition, the rank distribution automatically learned by S2-LoRA is found to have similar patterns to AdaLoRA's allocation.
Investigating salient representations and label Variance in Dimensional Speech Emotion Analysis
Dec 17, 2023Representations derived from models such as BERT (Bidirectional Encoder Representations from Transformers) and HuBERT (Hidden units BERT), have helped to achieve state-of-the-art performance in dimensional speech emotion recognition. Despite their large dimensionality, and even though these representations are not tailored for emotion recognition tasks, they are frequently used to train large speech emotion models with high memory and computational costs. In this work, we show that there exist lower-dimensional subspaces within the these pre-trained representational spaces that offer a reduction in downstream model complexity without sacrificing performance on emotion estimation. In addition, we model label uncertainty in the form of grader opinion variance, and demonstrate that such information can improve the models generalization capacity and robustness. Finally, we compare the robustness of the emotion models against acoustic degradations and observed that the reduced dimensional representations were able to retain the performance similar to the full-dimensional representations without significant regression in dimensional emotion performance.
* 5 pages
Active Learning Based Fine-Tuning Framework for Speech Emotion Recognition
Sep 30, 2023Speech emotion recognition (SER) has drawn increasing attention for its applications in human-machine interaction. However, existing SER methods ignore the information gap between the pre-training speech recognition task and the downstream SER task, leading to sub-optimal performance. Moreover, they require much time to fine-tune on each specific speech dataset, restricting their effectiveness in real-world scenes with large-scale noisy data. To address these issues, we propose an active learning (AL) based Fine-Tuning framework for SER that leverages task adaptation pre-training (TAPT) and AL methods to enhance performance and efficiency. Specifically, we first use TAPT to minimize the information gap between the pre-training and the downstream task. Then, AL methods are used to iteratively select a subset of the most informative and diverse samples for fine-tuning, reducing time consumption. Experiments demonstrate that using only 20\%pt. samples improves 8.45\%pt. accuracy and reduces 79\%pt. time consumption.
Leveraging Data Collection and Unsupervised Learning for Code-switched Tunisian Arabic Automatic Speech Recognition
Sep 25, 2023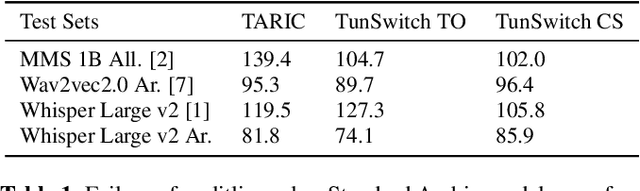
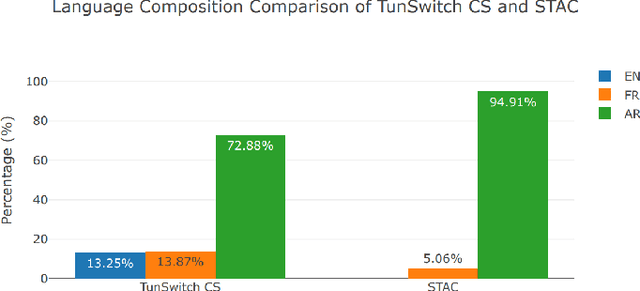

Crafting an effective Automatic Speech Recognition (ASR) solution for dialects demands innovative approaches that not only address the data scarcity issue but also navigate the intricacies of linguistic diversity. In this paper, we address the aforementioned ASR challenge, focusing on the Tunisian dialect. First, textual and audio data is collected and in some cases annotated. Second, we explore self-supervision, semi-supervision and few-shot code-switching approaches to push the state-of-the-art on different Tunisian test sets; covering different acoustic, linguistic and prosodic conditions. Finally, and given the absence of conventional spelling, we produce a human evaluation of our transcripts to avoid the noise coming from spelling inadequacies in our testing references. Our models, allowing to transcribe audio samples in a linguistic mix involving Tunisian Arabic, English and French, and all the data used during training and testing are released for public use and further improvements.
Improving Speech Recognition for African American English With Audio Classification
Sep 16, 2023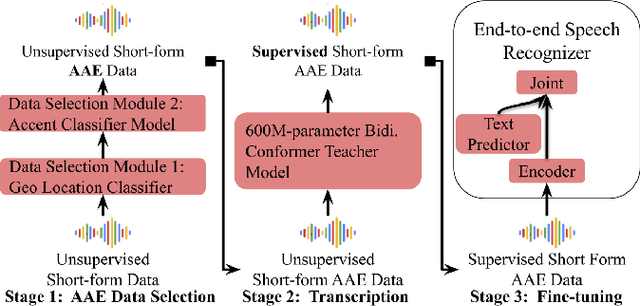
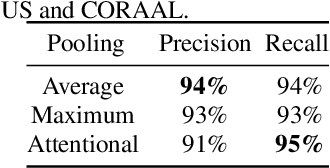
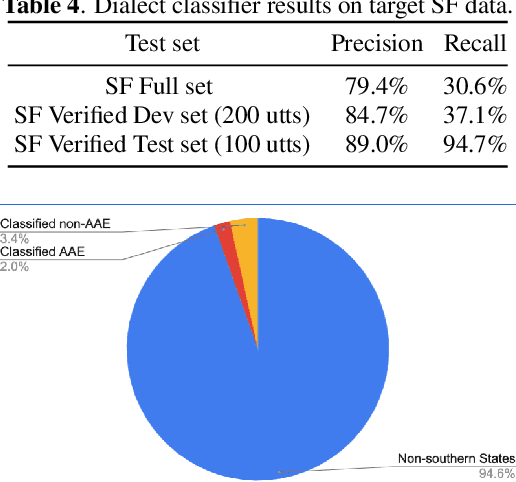

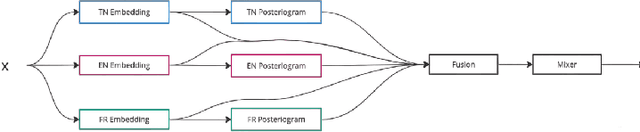
Automatic speech recognition (ASR) systems have been shown to have large quality disparities between the language varieties they are intended or expected to recognize. One way to mitigate this is to train or fine-tune models with more representative datasets. But this approach can be hindered by limited in-domain data for training and evaluation. We propose a new way to improve the robustness of a US English short-form speech recognizer using a small amount of out-of-domain (long-form) African American English (AAE) data. We use CORAAL, YouTube and Mozilla Common Voice to train an audio classifier to approximately output whether an utterance is AAE or some other variety including Mainstream American English (MAE). By combining the classifier output with coarse geographic information, we can select a subset of utterances from a large corpus of untranscribed short-form queries for semi-supervised learning at scale. Fine-tuning on this data results in a 38.5% relative word error rate disparity reduction between AAE and MAE without reducing MAE quality.
Prompting Large Language Models with Speech Recognition Abilities
Jul 21, 2023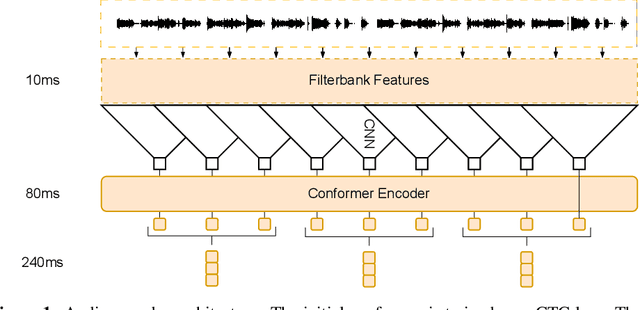
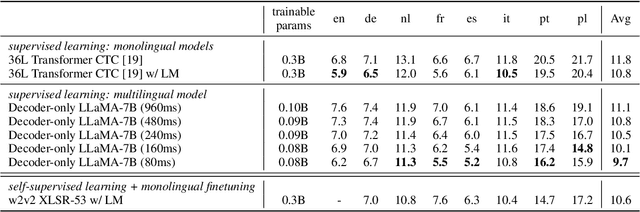
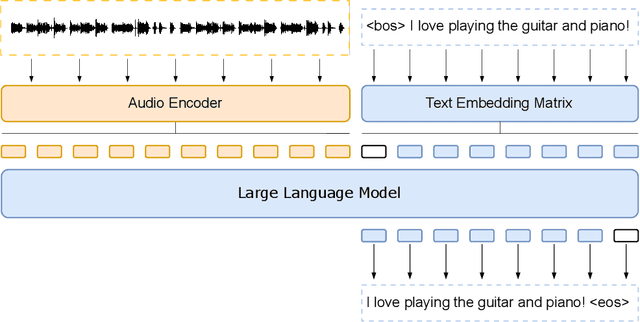

Large language models have proven themselves highly flexible, able to solve a wide range of generative tasks, such as abstractive summarization and open-ended question answering. In this paper we extend the capabilities of LLMs by directly attaching a small audio encoder allowing it to perform speech recognition. By directly prepending a sequence of audial embeddings to the text token embeddings, the LLM can be converted to an automatic speech recognition (ASR) system, and be used in the exact same manner as its textual counterpart. Experiments on Multilingual LibriSpeech (MLS) show that incorporating a conformer encoder into the open sourced LLaMA-7B allows it to outperform monolingual baselines by 18% and perform multilingual speech recognition despite LLaMA being trained overwhelmingly on English text. Furthermore, we perform ablation studies to investigate whether the LLM can be completely frozen during training to maintain its original capabilities, scaling up the audio encoder, and increasing the audio encoder striding to generate fewer embeddings. The results from these studies show that multilingual ASR is possible even when the LLM is frozen or when strides of almost 1 second are used in the audio encoder opening up the possibility for LLMs to operate on long-form audio.
Beyond Boundaries: A Comprehensive Survey of Transferable Attacks on AI Systems
Nov 20, 2023Artificial Intelligence (AI) systems such as autonomous vehicles, facial recognition, and speech recognition systems are increasingly integrated into our daily lives. However, despite their utility, these AI systems are vulnerable to a wide range of attacks such as adversarial, backdoor, data poisoning, membership inference, model inversion, and model stealing attacks. In particular, numerous attacks are designed to target a particular model or system, yet their effects can spread to additional targets, referred to as transferable attacks. Although considerable efforts have been directed toward developing transferable attacks, a holistic understanding of the advancements in transferable attacks remains elusive. In this paper, we comprehensively explore learning-based attacks from the perspective of transferability, particularly within the context of cyber-physical security. We delve into different domains -- the image, text, graph, audio, and video domains -- to highlight the ubiquitous and pervasive nature of transferable attacks. This paper categorizes and reviews the architecture of existing attacks from various viewpoints: data, process, model, and system. We further examine the implications of transferable attacks in practical scenarios such as autonomous driving, speech recognition, and large language models (LLMs). Additionally, we outline the potential research directions to encourage efforts in exploring the landscape of transferable attacks. This survey offers a holistic understanding of the prevailing transferable attacks and their impacts across different domains.
CPPF: A contextual and post-processing-free model for automatic speech recognition
Sep 14, 2023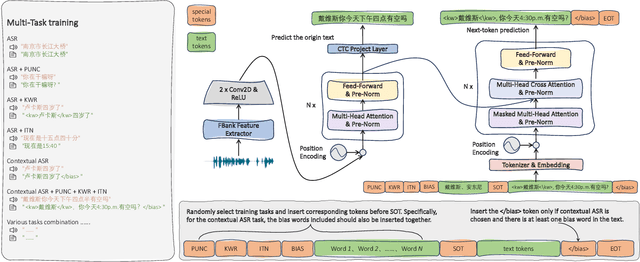
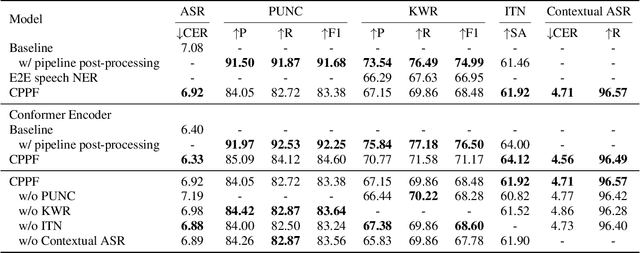

ASR systems have become increasingly widespread in recent years. However, their textual outputs often require post-processing tasks before they can be practically utilized. To address this issue, we draw inspiration from the multifaceted capabilities of LLMs and Whisper, and focus on integrating multiple ASR text processing tasks related to speech recognition into the ASR model. This integration not only shortens the multi-stage pipeline, but also prevents the propagation of cascading errors, resulting in direct generation of post-processed text. In this study, we focus on ASR-related processing tasks, including Contextual ASR and multiple ASR post processing tasks. To achieve this objective, we introduce the CPPF model, which offers a versatile and highly effective alternative to ASR processing. CPPF seamlessly integrates these tasks without any significant loss in recognition performance.