 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
BA-MoE: Boundary-Aware Mixture-of-Experts Adapter for Code-Switching Speech Recognition
Oct 04, 2023
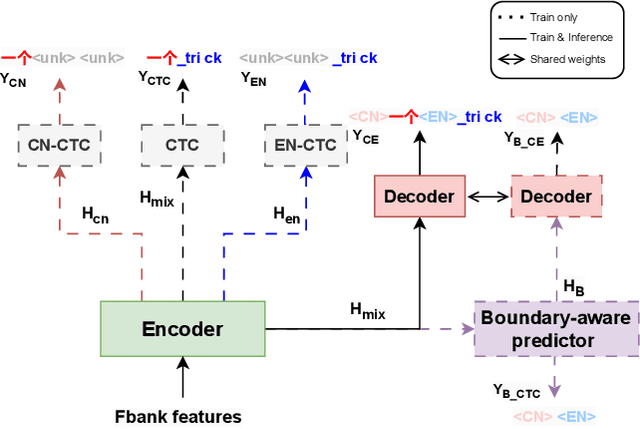
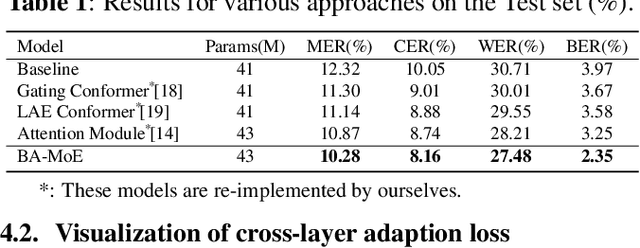
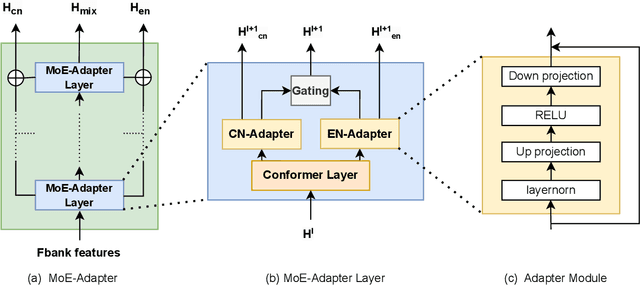
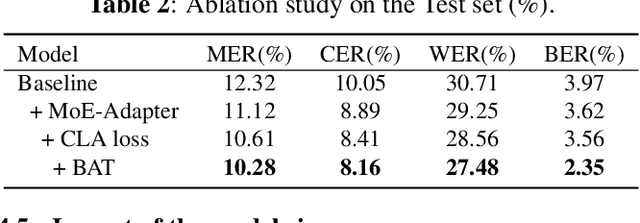
Mixture-of-experts based models, which use language experts to extract language-specific representations effectively, have been well applied in code-switching automatic speech recognition. However, there is still substantial space to improve as similar pronunciation across languages may result in ineffective multi-language modeling and inaccurate language boundary estimation. To eliminate these drawbacks, we propose a cross-layer language adapter and a boundary-aware training method, namely Boundary-Aware Mixture-of-Experts (BA-MoE). Specifically, we introduce language-specific adapters to separate language-specific representations and a unified gating layer to fuse representations within each encoder layer. Second, we compute language adaptation loss of the mean output of each language-specific adapter to improve the adapter module's language-specific representation learning. Besides, we utilize a boundary-aware predictor to learn boundary representations for dealing with language boundary confusion. Our approach achieves significant performance improvement, reducing the mixture error rate by 16.55\% compared to the baseline on the ASRU 2019 Mandarin-English code-switching challenge dataset.
HyPoradise: An Open Baseline for Generative Speech Recognition with Large Language Models
Oct 16, 2023
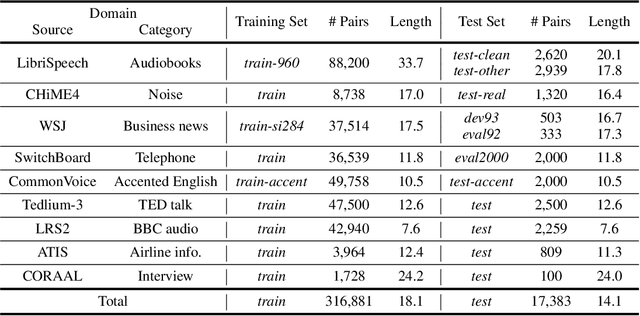

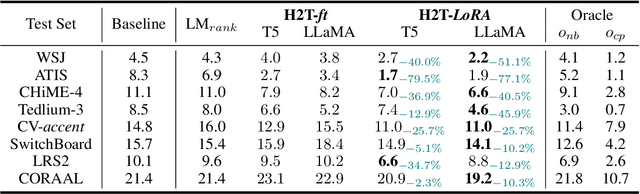
Advancements in deep neural networks have allowed automatic speech recognition (ASR) systems to attain human parity on several publicly available clean speech datasets. However, even state-of-the-art ASR systems experience performance degradation when confronted with adverse conditions, as a well-trained acoustic model is sensitive to variations in the speech domain, e.g., background noise. Intuitively, humans address this issue by relying on their linguistic knowledge: the meaning of ambiguous spoken terms is usually inferred from contextual cues thereby reducing the dependency on the auditory system. Inspired by this observation, we introduce the first open-source benchmark to utilize external large language models (LLMs) for ASR error correction, where N-best decoding hypotheses provide informative elements for true transcription prediction. This approach is a paradigm shift from the traditional language model rescoring strategy that can only select one candidate hypothesis as the output transcription. The proposed benchmark contains a novel dataset, HyPoradise (HP), encompassing more than 334,000 pairs of N-best hypotheses and corresponding accurate transcriptions across prevalent speech domains. Given this dataset, we examine three types of error correction techniques based on LLMs with varying amounts of labeled hypotheses-transcription pairs, which gains a significant word error rate (WER) reduction. Experimental evidence demonstrates the proposed technique achieves a breakthrough by surpassing the upper bound of traditional re-ranking based methods. More surprisingly, LLM with reasonable prompt and its generative capability can even correct those tokens that are missing in N-best list. We make our results publicly accessible for reproducible pipelines with released pre-trained models, thus providing a new evaluation paradigm for ASR error correction with LLMs.
Batched Low-Rank Adaptation of Foundation Models
Dec 09, 2023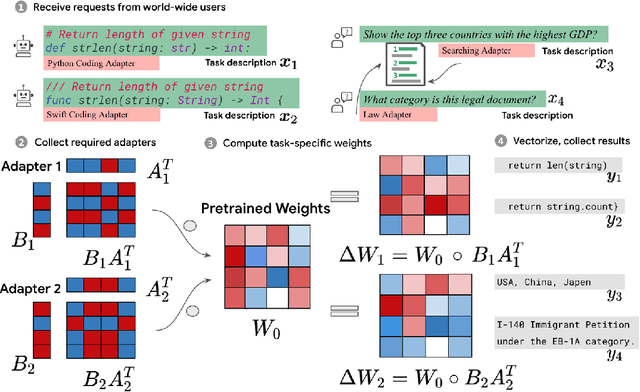
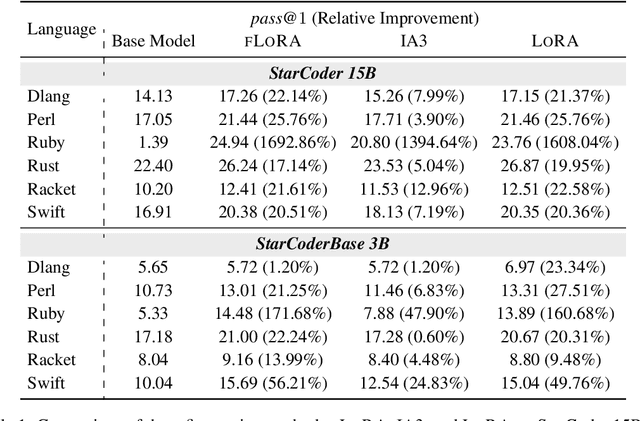
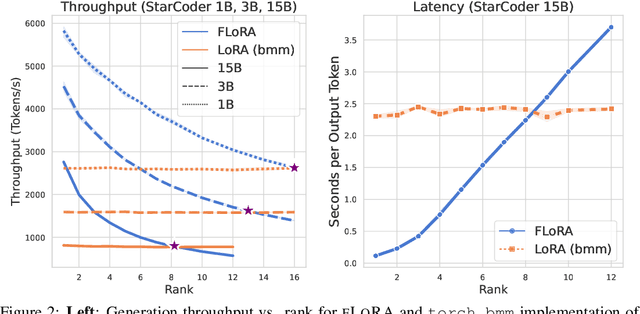

Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Low-rank Adaptation of Large Language Model Rescoring for Parameter-Efficient Speech Recognition
Sep 26, 2023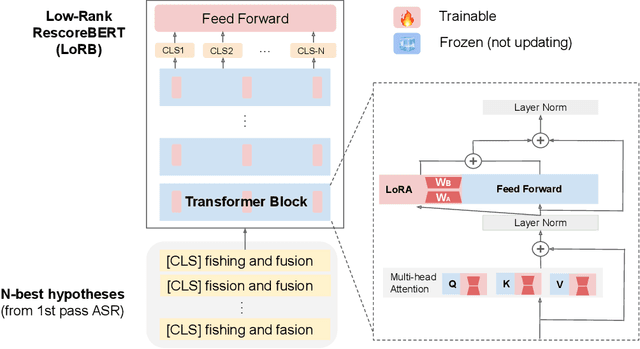
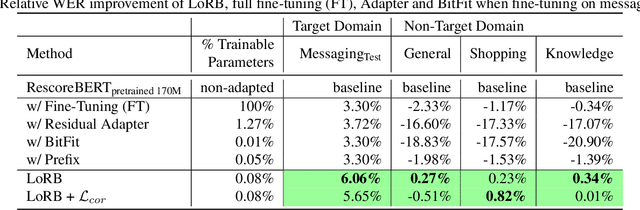
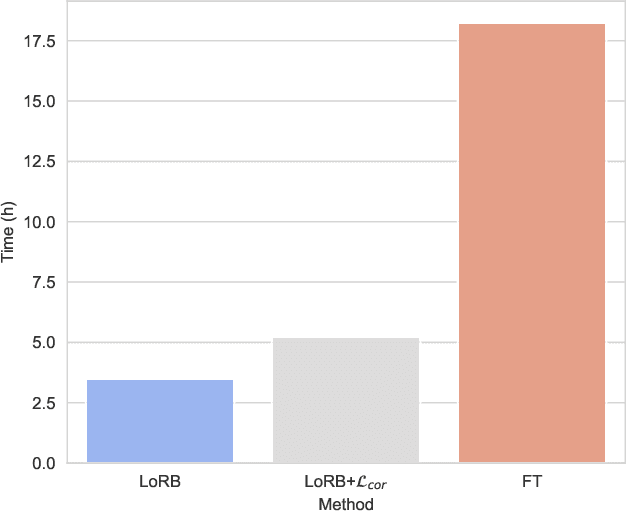
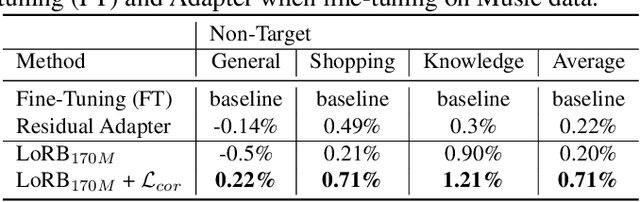
We propose a neural language modeling system based on low-rank adaptation (LoRA) for speech recognition output rescoring. Although pretrained language models (LMs) like BERT have shown superior performance in second-pass rescoring, the high computational cost of scaling up the pretraining stage and adapting the pretrained models to specific domains limit their practical use in rescoring. Here we present a method based on low-rank decomposition to train a rescoring BERT model and adapt it to new domains using only a fraction (0.08%) of the pretrained parameters. These inserted matrices are optimized through a discriminative training objective along with a correlation-based regularization loss. The proposed low-rank adaptation Rescore-BERT (LoRB) architecture is evaluated on LibriSpeech and internal datasets with decreased training times by factors between 5.4 and 3.6.
Acoustic characterization of speech rhythm: going beyond metrics with recurrent neural networks
Jan 22, 2024Languages have long been described according to their perceived rhythmic attributes. The associated typologies are of interest in psycholinguistics as they partly predict newborns' abilities to discriminate between languages and provide insights into how adult listeners process non-native languages. Despite the relative success of rhythm metrics in supporting the existence of linguistic rhythmic classes, quantitative studies have yet to capture the full complexity of temporal regularities associated with speech rhythm. We argue that deep learning offers a powerful pattern-recognition approach to advance the characterization of the acoustic bases of speech rhythm. To explore this hypothesis, we trained a medium-sized recurrent neural network on a language identification task over a large database of speech recordings in 21 languages. The network had access to the amplitude envelopes and a variable identifying the voiced segments, assuming that this signal would poorly convey phonetic information but preserve prosodic features. The network was able to identify the language of 10-second recordings in 40% of the cases, and the language was in the top-3 guesses in two-thirds of the cases. Visualization methods show that representations built from the network activations are consistent with speech rhythm typologies, although the resulting maps are more complex than two separated clusters between stress and syllable-timed languages. We further analyzed the model by identifying correlations between network activations and known speech rhythm metrics. The findings illustrate the potential of deep learning tools to advance our understanding of speech rhythm through the identification and exploration of linguistically relevant acoustic feature spaces.
Optimizing Two-Pass Cross-Lingual Transfer Learning: Phoneme Recognition and Phoneme to Grapheme Translation
Dec 06, 2023This research optimizes two-pass cross-lingual transfer learning in low-resource languages by enhancing phoneme recognition and phoneme-to-grapheme translation models. Our approach optimizes these two stages to improve speech recognition across languages. We optimize phoneme vocabulary coverage by merging phonemes based on shared articulatory characteristics, thus improving recognition accuracy. Additionally, we introduce a global phoneme noise generator for realistic ASR noise during phoneme-to-grapheme training to reduce error propagation. Experiments on the CommonVoice 12.0 dataset show significant reductions in Word Error Rate (WER) for low-resource languages, highlighting the effectiveness of our approach. This research contributes to the advancements of two-pass ASR systems in low-resource languages, offering the potential for improved cross-lingual transfer learning.
Directional Source Separation for Robust Speech Recognition on Smart Glasses
Sep 20, 2023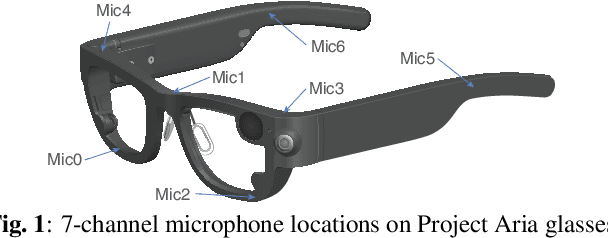
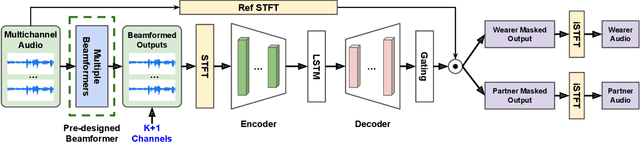
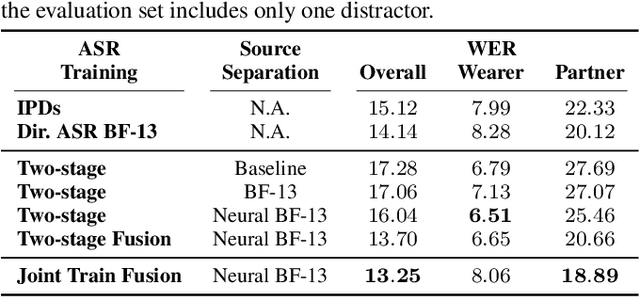
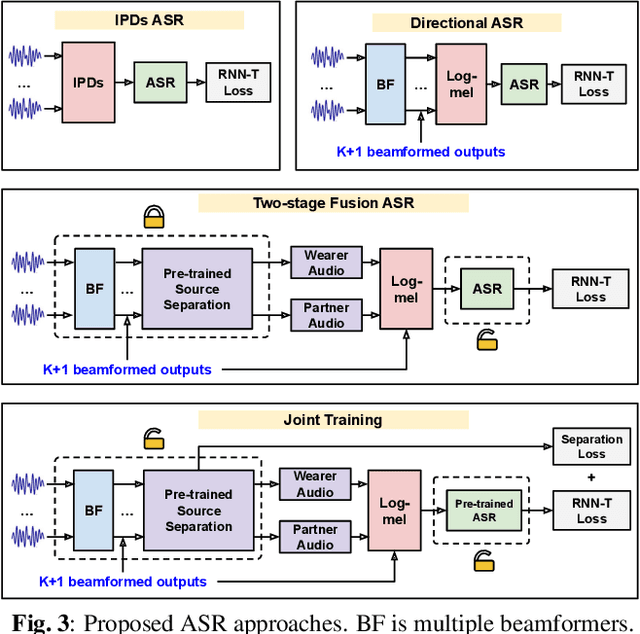
Modern smart glasses leverage advanced audio sensing and machine learning technologies to offer real-time transcribing and captioning services, considerably enriching human experiences in daily communications. However, such systems frequently encounter challenges related to environmental noises, resulting in degradation to speech recognition and speaker change detection. To improve voice quality, this work investigates directional source separation using the multi-microphone array. We first explore multiple beamformers to assist source separation modeling by strengthening the directional properties of speech signals. In addition to relying on predetermined beamformers, we investigate neural beamforming in multi-channel source separation, demonstrating that automatic learning directional characteristics effectively improves separation quality. We further compare the ASR performance leveraging separated outputs to noisy inputs. Our results show that directional source separation benefits ASR for the wearer but not for the conversation partner. Lastly, we perform the joint training of the directional source separation and ASR model, achieving the best overall ASR performance.
Advanced accent/dialect identification and accentedness assessment with multi-embedding models and automatic speech recognition
Oct 17, 2023Accurately classifying accents and assessing accentedness in non-native speakers are both challenging tasks due to the complexity and diversity of accent and dialect variations. In this study, embeddings from advanced pre-trained language identification (LID) and speaker identification (SID) models are leveraged to improve the accuracy of accent classification and non-native accentedness assessment. Findings demonstrate that employing pre-trained LID and SID models effectively encodes accent/dialect information in speech. Furthermore, the LID and SID encoded accent information complement an end-to-end accent identification (AID) model trained from scratch. By incorporating all three embeddings, the proposed multi-embedding AID system achieves superior accuracy in accent identification. Next, we investigate leveraging automatic speech recognition (ASR) and accent identification models to explore accentedness estimation. The ASR model is an end-to-end connectionist temporal classification (CTC) model trained exclusively with en-US utterances. The ASR error rate and en-US output of the AID model are leveraged as objective accentedness scores. Evaluation results demonstrate a strong correlation between the scores estimated by the two models. Additionally, a robust correlation between the objective accentedness scores and subjective scores based on human perception is demonstrated, providing evidence for the reliability and validity of utilizing AID-based and ASR-based systems for accentedness assessment in non-native speech.
Graph Convolutions Enrich the Self-Attention in Transformers!
Dec 07, 2023Transformers, renowned for their self-attention mechanism, have achieved state-of-the-art performance across various tasks in natural language processing, computer vision, time-series modeling, etc. However, one of the challenges with deep Transformer models is the oversmoothing problem, where representations across layers converge to indistinguishable values, leading to significant performance degradation. We interpret the original self-attention as a simple graph filter and redesign it from a graph signal processing (GSP) perspective. We propose graph-filter-based self-attention (GFSA) to learn a general yet effective one, whose complexity, however, is slightly larger than that of the original self-attention mechanism. We demonstrate that GFSA improves the performance of Transformers in various fields, including computer vision, natural language processing, graph pattern classification, speech recognition, and code classification.
A Review of Hybrid and Ensemble in Deep Learning for Natural Language Processing
Dec 09, 2023This review presents a comprehensive exploration of hybrid and ensemble deep learning models within Natural Language Processing (NLP), shedding light on their transformative potential across diverse tasks such as Sentiment Analysis, Named Entity Recognition, Machine Translation, Question Answering, Text Classification, Generation, Speech Recognition, Summarization, and Language Modeling. The paper systematically introduces each task, delineates key architectures from Recurrent Neural Networks (RNNs) to Transformer-based models like BERT, and evaluates their performance, challenges, and computational demands. The adaptability of ensemble techniques is emphasized, highlighting their capacity to enhance various NLP applications. Challenges in implementation, including computational overhead, overfitting, and model interpretation complexities, are addressed alongside the trade-off between interpretability and performance. Serving as a concise yet invaluable guide, this review synthesizes insights into tasks, architectures, and challenges, offering a holistic perspective for researchers and practitioners aiming to advance language-driven applications through ensemble deep learning in NLP.