 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
No Pitch Left Behind: Addressing Gender Unbalance in Automatic Speech Recognition through Pitch Manipulation
Oct 10, 2023
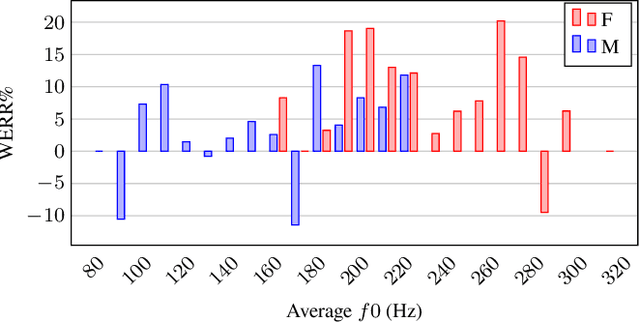
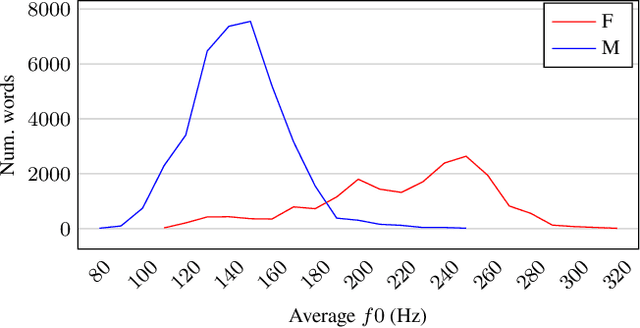

Automatic speech recognition (ASR) systems are known to be sensitive to the sociolinguistic variability of speech data, in which gender plays a crucial role. This can result in disparities in recognition accuracy between male and female speakers, primarily due to the under-representation of the latter group in the training data. While in the context of hybrid ASR models several solutions have been proposed, the gender bias issue has not been explicitly addressed in end-to-end neural architectures. To fill this gap, we propose a data augmentation technique that manipulates the fundamental frequency (f0) and formants. This technique reduces the data unbalance among genders by simulating voices of the under-represented female speakers and increases the variability within each gender group. Experiments on spontaneous English speech show that our technique yields a relative WER improvement up to 9.87% for utterances by female speakers, with larger gains for the least-represented f0 ranges.
On the Relevance of Phoneme Duration Variability of Synthesized Training Data for Automatic Speech Recognition
Oct 12, 2023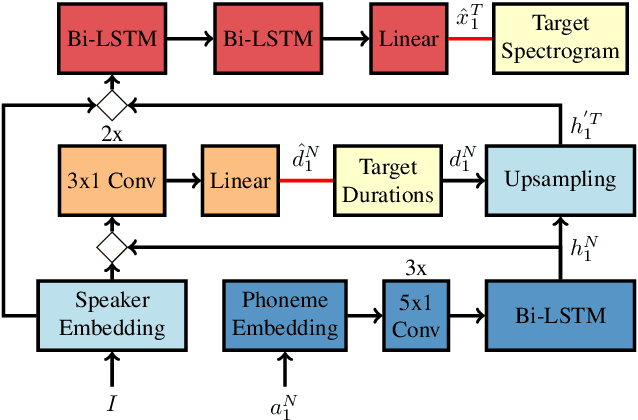
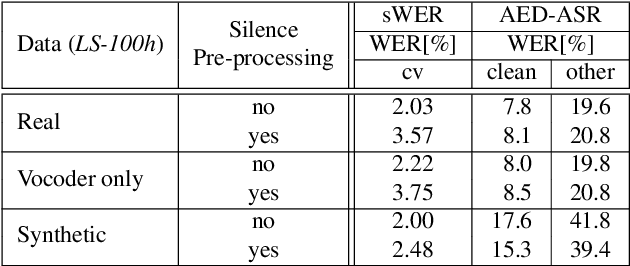
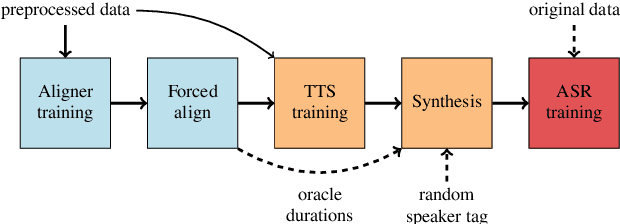
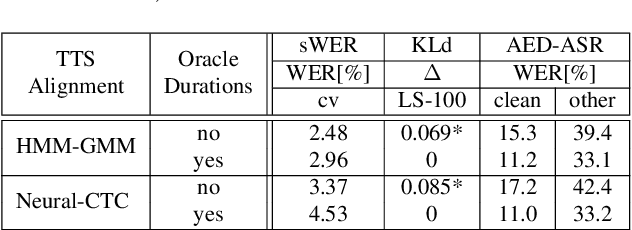
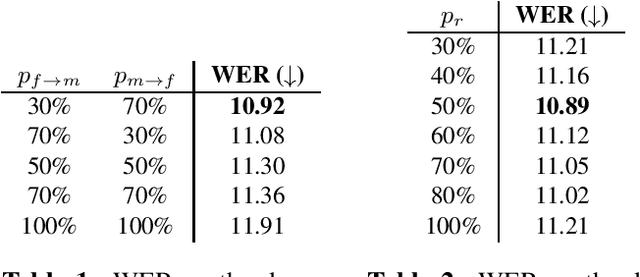
Synthetic data generated by text-to-speech (TTS) systems can be used to improve automatic speech recognition (ASR) systems in low-resource or domain mismatch tasks. It has been shown that TTS-generated outputs still do not have the same qualities as real data. In this work we focus on the temporal structure of synthetic data and its relation to ASR training. By using a novel oracle setup we show how much the degradation of synthetic data quality is influenced by duration modeling in non-autoregressive (NAR) TTS. To get reference phoneme durations we use two common alignment methods, a hidden Markov Gaussian-mixture model (HMM-GMM) aligner and a neural connectionist temporal classification (CTC) aligner. Using a simple algorithm based on random walks we shift phoneme duration distributions of the TTS system closer to real durations, resulting in an improvement of an ASR system using synthetic data in a semi-supervised setting.
Acoustic characterization of speech rhythm: going beyond metrics with recurrent neural networks
Jan 22, 2024Languages have long been described according to their perceived rhythmic attributes. The associated typologies are of interest in psycholinguistics as they partly predict newborns' abilities to discriminate between languages and provide insights into how adult listeners process non-native languages. Despite the relative success of rhythm metrics in supporting the existence of linguistic rhythmic classes, quantitative studies have yet to capture the full complexity of temporal regularities associated with speech rhythm. We argue that deep learning offers a powerful pattern-recognition approach to advance the characterization of the acoustic bases of speech rhythm. To explore this hypothesis, we trained a medium-sized recurrent neural network on a language identification task over a large database of speech recordings in 21 languages. The network had access to the amplitude envelopes and a variable identifying the voiced segments, assuming that this signal would poorly convey phonetic information but preserve prosodic features. The network was able to identify the language of 10-second recordings in 40% of the cases, and the language was in the top-3 guesses in two-thirds of the cases. Visualization methods show that representations built from the network activations are consistent with speech rhythm typologies, although the resulting maps are more complex than two separated clusters between stress and syllable-timed languages. We further analyzed the model by identifying correlations between network activations and known speech rhythm metrics. The findings illustrate the potential of deep learning tools to advance our understanding of speech rhythm through the identification and exploration of linguistically relevant acoustic feature spaces.
SememeASR: Boosting Performance of End-to-End Speech Recognition against Domain and Long-Tailed Data Shift with Sememe Semantic Knowledge
Sep 04, 2023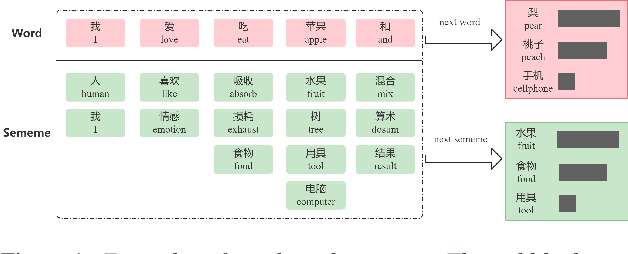
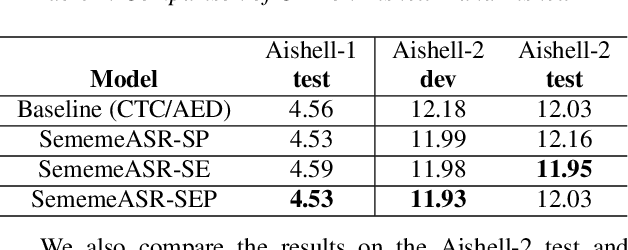
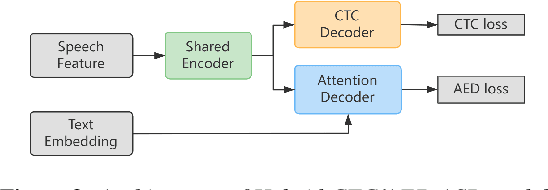
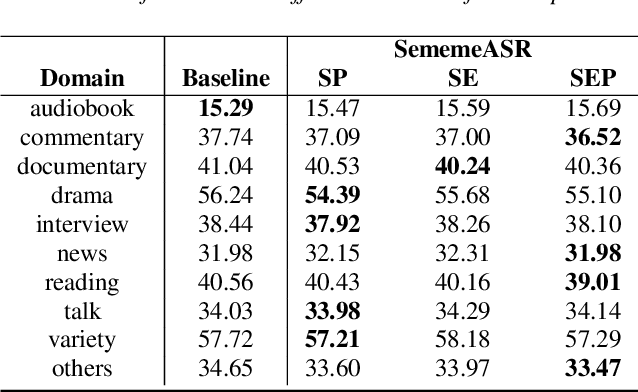
Recently, excellent progress has been made in speech recognition. However, pure data-driven approaches have struggled to solve the problem in domain-mismatch and long-tailed data. Considering that knowledge-driven approaches can help data-driven approaches alleviate their flaws, we introduce sememe-based semantic knowledge information to speech recognition (SememeASR). Sememe, according to the linguistic definition, is the minimum semantic unit in a language and is able to represent the implicit semantic information behind each word very well. Our experiments show that the introduction of sememe information can improve the effectiveness of speech recognition. In addition, our further experiments show that sememe knowledge can improve the model's recognition of long-tailed data and enhance the model's domain generalization ability.
SSHR: Leveraging Self-supervised Hierarchical Representations for Multilingual Automatic Speech Recognition
Sep 29, 2023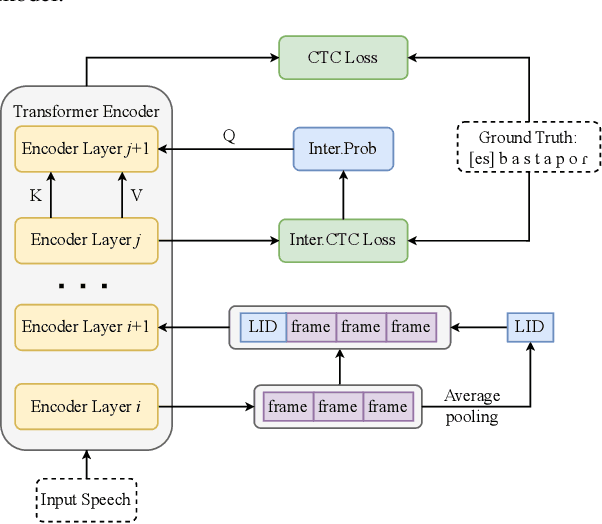
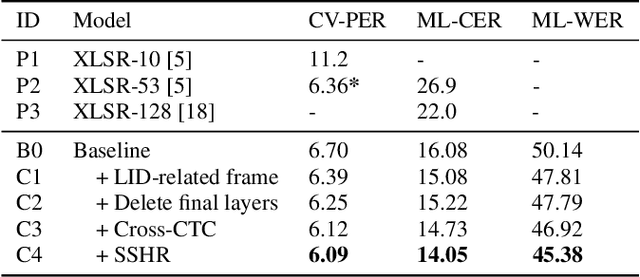

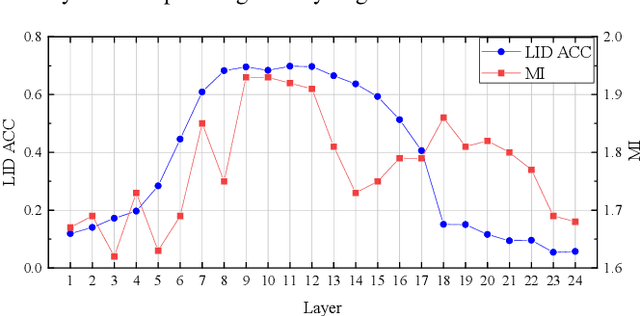
Multilingual automatic speech recognition (ASR) systems have garnered attention for their potential to extend language coverage globally. While self-supervised learning (SSL) has demonstrated its effectiveness in multilingual ASR, it is worth noting that the various layers' representations of SSL potentially contain distinct information that has not been fully leveraged. In this study, we propose a novel method that leverages self-supervised hierarchical representations (SSHR) to fine-tune multilingual ASR. We first analyze the different layers of the SSL model for language-related and content-related information, uncovering layers that show a stronger correlation. Then, we extract a language-related frame from correlated middle layers and guide specific content extraction through self-attention mechanisms. Additionally, we steer the model toward acquiring more content-related information in the final layers using our proposed Cross-CTC. We evaluate SSHR on two multilingual datasets, Common Voice and ML-SUPERB, and the experimental results demonstrate that our method achieves state-of-the-art performance to the best of our knowledge.
Batched Low-Rank Adaptation of Foundation Models
Dec 09, 2023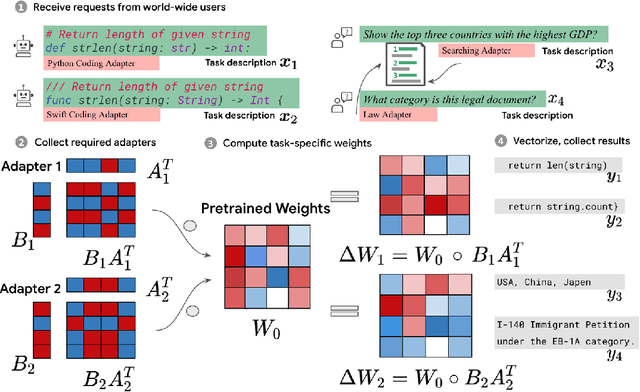
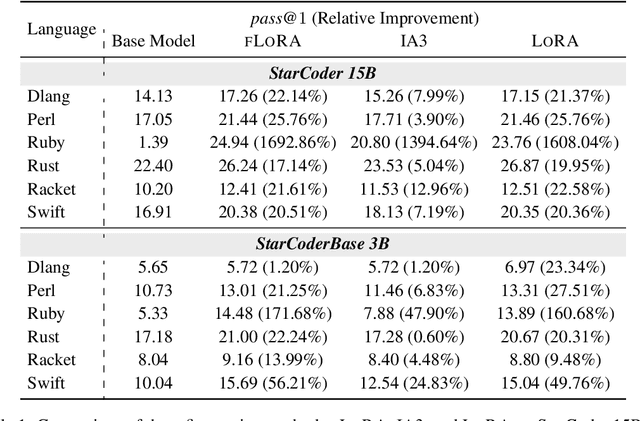
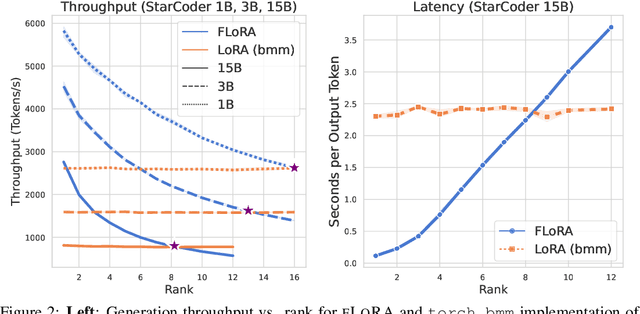

Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
BA-MoE: Boundary-Aware Mixture-of-Experts Adapter for Code-Switching Speech Recognition
Oct 04, 2023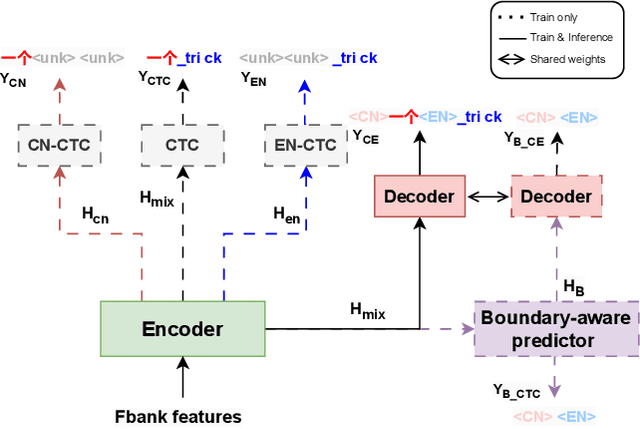
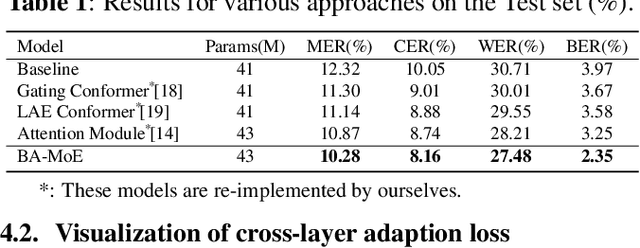
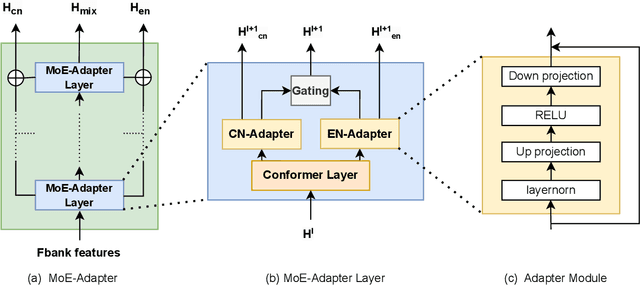
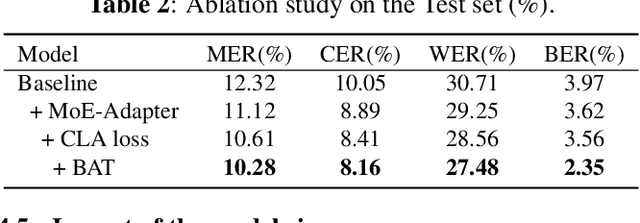
Mixture-of-experts based models, which use language experts to extract language-specific representations effectively, have been well applied in code-switching automatic speech recognition. However, there is still substantial space to improve as similar pronunciation across languages may result in ineffective multi-language modeling and inaccurate language boundary estimation. To eliminate these drawbacks, we propose a cross-layer language adapter and a boundary-aware training method, namely Boundary-Aware Mixture-of-Experts (BA-MoE). Specifically, we introduce language-specific adapters to separate language-specific representations and a unified gating layer to fuse representations within each encoder layer. Second, we compute language adaptation loss of the mean output of each language-specific adapter to improve the adapter module's language-specific representation learning. Besides, we utilize a boundary-aware predictor to learn boundary representations for dealing with language boundary confusion. Our approach achieves significant performance improvement, reducing the mixture error rate by 16.55\% compared to the baseline on the ASRU 2019 Mandarin-English code-switching challenge dataset.
Optimizing Two-Pass Cross-Lingual Transfer Learning: Phoneme Recognition and Phoneme to Grapheme Translation
Dec 06, 2023This research optimizes two-pass cross-lingual transfer learning in low-resource languages by enhancing phoneme recognition and phoneme-to-grapheme translation models. Our approach optimizes these two stages to improve speech recognition across languages. We optimize phoneme vocabulary coverage by merging phonemes based on shared articulatory characteristics, thus improving recognition accuracy. Additionally, we introduce a global phoneme noise generator for realistic ASR noise during phoneme-to-grapheme training to reduce error propagation. Experiments on the CommonVoice 12.0 dataset show significant reductions in Word Error Rate (WER) for low-resource languages, highlighting the effectiveness of our approach. This research contributes to the advancements of two-pass ASR systems in low-resource languages, offering the potential for improved cross-lingual transfer learning.
Graph Convolutions Enrich the Self-Attention in Transformers!
Dec 07, 2023Transformers, renowned for their self-attention mechanism, have achieved state-of-the-art performance across various tasks in natural language processing, computer vision, time-series modeling, etc. However, one of the challenges with deep Transformer models is the oversmoothing problem, where representations across layers converge to indistinguishable values, leading to significant performance degradation. We interpret the original self-attention as a simple graph filter and redesign it from a graph signal processing (GSP) perspective. We propose graph-filter-based self-attention (GFSA) to learn a general yet effective one, whose complexity, however, is slightly larger than that of the original self-attention mechanism. We demonstrate that GFSA improves the performance of Transformers in various fields, including computer vision, natural language processing, graph pattern classification, speech recognition, and code classification.
Large Language Models for Autonomous Driving: Real-World Experiments
Dec 14, 2023Autonomous driving systems are increasingly popular in today's technological landscape, where vehicles with partial automation have already been widely available on the market, and the full automation era with ``driverless'' capabilities is near the horizon. However, accurately understanding humans' commands, particularly for autonomous vehicles that have only passengers instead of drivers, and achieving a high level of personalization remain challenging tasks in the development of autonomous driving systems. In this paper, we introduce a Large Language Model (LLM)-based framework Talk-to-Drive (Talk2Drive) to process verbal commands from humans and make autonomous driving decisions with contextual information, satisfying their personalized preferences for safety, efficiency, and comfort. First, a speech recognition module is developed for Talk2Drive to interpret verbal inputs from humans to textual instructions, which are then sent to LLMs for reasoning. Then, appropriate commands for the Electrical Control Unit (ECU) are generated, achieving a 100\% success rate in executing codes. Real-world experiments show that our framework can substantially reduce the takeover rate for a diverse range of drivers by up to 90.1\%. To the best of our knowledge, Talk2Drive marks the first instance of employing an LLM-based system in a real-world autonomous driving environment.