 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Advancing VAD Systems Based on Multi-Task Learning with Improved Model Structures
Dec 19, 2023
In a speech recognition system, voice activity detection (VAD) is a crucial frontend module. Addressing the issues of poor noise robustness in traditional binary VAD systems based on DFSMN, the paper further proposes semantic VAD based on multi-task learning with improved models for real-time and offline systems, to meet specific application requirements. Evaluations on internal datasets show that, compared to the real-time VAD system based on DFSMN, the real-time semantic VAD system based on RWKV achieves relative decreases in CER of 7.0\%, DCF of 26.1\% and relative improvement in NRR of 19.2\%. Similarly, when compared to the offline VAD system based on DFSMN, the offline VAD system based on SAN-M demonstrates relative decreases in CER of 4.4\%, DCF of 18.6\% and relative improvement in NRR of 3.5\%.
Acoustic Model Fusion for End-to-end Speech Recognition
Oct 10, 2023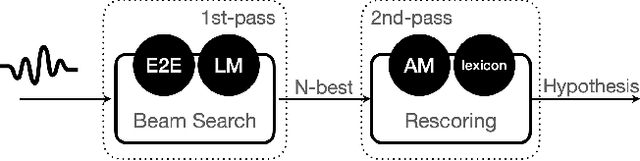

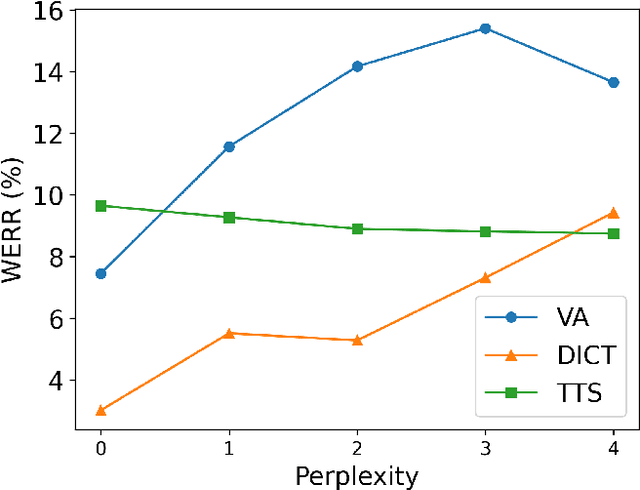
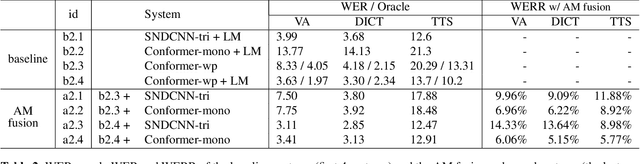
Recent advances in deep learning and automatic speech recognition (ASR) have enabled the end-to-end (E2E) ASR system and boosted the accuracy to a new level. The E2E systems implicitly model all conventional ASR components, such as the acoustic model (AM) and the language model (LM), in a single network trained on audio-text pairs. Despite this simpler system architecture, fusing a separate LM, trained exclusively on text corpora, into the E2E system has proven to be beneficial. However, the application of LM fusion presents certain drawbacks, such as its inability to address the domain mismatch issue inherent to the internal AM. Drawing inspiration from the concept of LM fusion, we propose the integration of an external AM into the E2E system to better address the domain mismatch. By implementing this novel approach, we have achieved a significant reduction in the word error rate, with an impressive drop of up to 14.3% across varied test sets. We also discovered that this AM fusion approach is particularly beneficial in enhancing named entity recognition.
On the Impact of Quantization and Pruning of Self-Supervised Speech Models for Downstream Speech Recognition Tasks "In-the-Wild''
Sep 25, 2023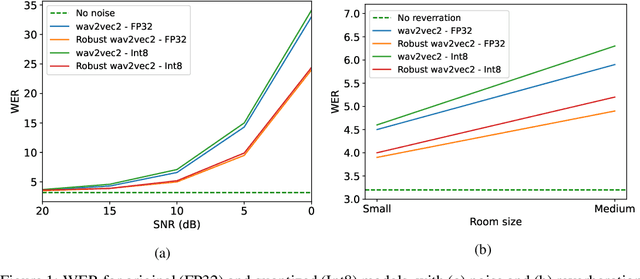

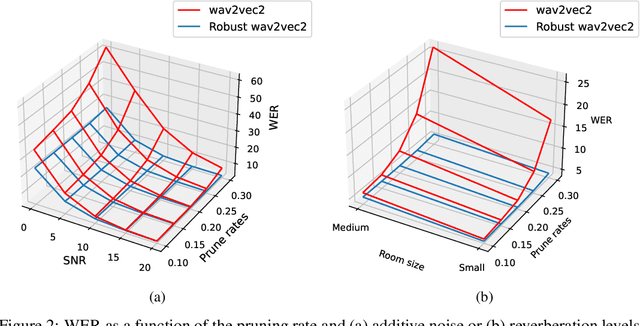
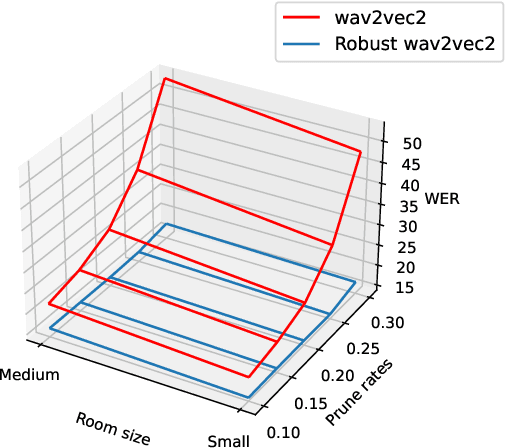
Recent advances with self-supervised learning have allowed speech recognition systems to achieve state-of-the-art (SOTA) word error rates (WER) while requiring only a fraction of the labeled training data needed by its predecessors. Notwithstanding, while such models achieve SOTA performance in matched train/test conditions, their performance degrades substantially when tested in unseen conditions. To overcome this problem, strategies such as data augmentation and/or domain shift training have been explored. Available models, however, are still too large to be considered for edge speech applications on resource-constrained devices, thus model compression tools are needed. In this paper, we explore the effects that train/test mismatch conditions have on speech recognition accuracy based on compressed self-supervised speech models. In particular, we report on the effects that parameter quantization and model pruning have on speech recognition accuracy based on the so-called robust wav2vec 2.0 model under noisy, reverberant, and noise-plus-reverberation conditions.
kNN-CTC: Enhancing ASR via Retrieval of CTC Pseudo Labels
Dec 21, 2023The success of retrieval-augmented language models in various natural language processing (NLP) tasks has been constrained in automatic speech recognition (ASR) applications due to challenges in constructing fine-grained audio-text datastores. This paper presents kNN-CTC, a novel approach that overcomes these challenges by leveraging Connectionist Temporal Classification (CTC) pseudo labels to establish frame-level audio-text key-value pairs, circumventing the need for precise ground truth alignments. We further introduce a skip-blank strategy, which strategically ignores CTC blank frames, to reduce datastore size. kNN-CTC incorporates a k-nearest neighbors retrieval mechanism into pre-trained CTC ASR systems, achieving significant improvements in performance. By incorporating a k-nearest neighbors retrieval mechanism into pre-trained CTC ASR systems and leveraging a fine-grained, pruned datastore, kNN-CTC consistently achieves substantial improvements in performance under various experimental settings. Our code is available at https://github.com/NKU-HLT/KNN-CTC.
Improved Contextual Recognition In Automatic Speech Recognition Systems By Semantic Lattice Rescoring
Oct 17, 2023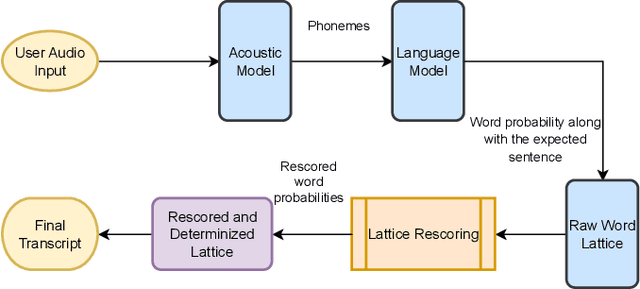
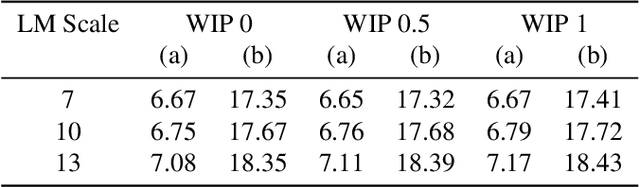
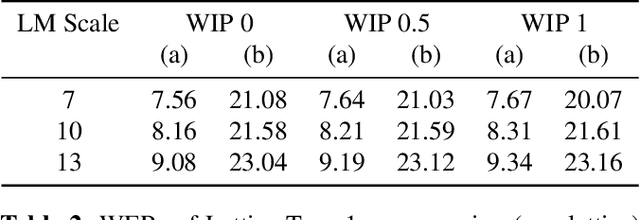
Automatic Speech Recognition (ASR) has witnessed a profound research interest. Recent breakthroughs have given ASR systems different prospects such as faithfully transcribing spoken language, which is a pivotal advancement in building conversational agents. However, there is still an imminent challenge of accurately discerning context-dependent words and phrases. In this work, we propose a novel approach for enhancing contextual recognition within ASR systems via semantic lattice processing leveraging the power of deep learning models in accurately delivering spot-on transcriptions across a wide variety of vocabularies and speaking styles. Our solution consists of using Hidden Markov Models and Gaussian Mixture Models (HMM-GMM) along with Deep Neural Networks (DNN) models integrating both language and acoustic modeling for better accuracy. We infused our network with the use of a transformer-based model to properly rescore the word lattice achieving remarkable capabilities with a palpable reduction in Word Error Rate (WER). We demonstrate the effectiveness of our proposed framework on the LibriSpeech dataset with empirical analyses.
Visual Speech Recognition for Low-resource Languages with Automatic Labels From Whisper Model
Sep 15, 2023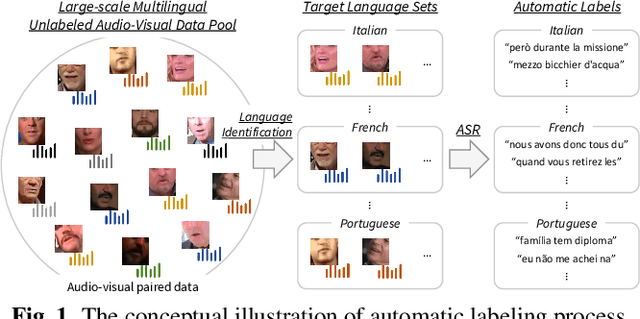
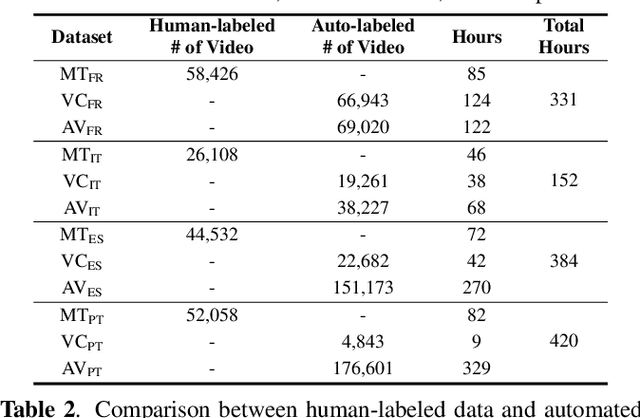
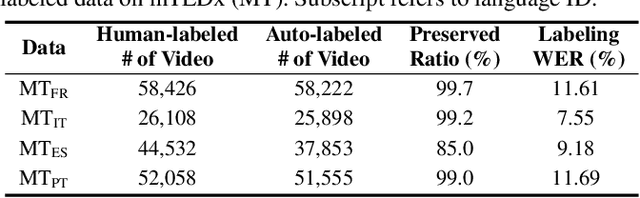
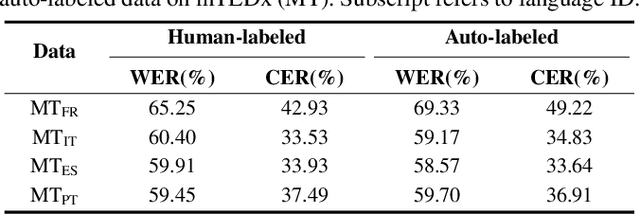
This paper proposes a powerful Visual Speech Recognition (VSR) method for multiple languages, especially for low-resource languages that have a limited number of labeled data. Different from previous methods that tried to improve the VSR performance for the target language by using knowledge learned from other languages, we explore whether we can increase the amount of training data itself for the different languages without human intervention. To this end, we employ a Whisper model which can conduct both language identification and audio-based speech recognition. It serves to filter data of the desired languages and transcribe labels from the unannotated, multilingual audio-visual data pool. By comparing the performances of VSR models trained on automatic labels and the human-annotated labels, we show that we can achieve similar VSR performance to that of human-annotated labels even without utilizing human annotations. Through the automated labeling process, we label large-scale unlabeled multilingual databases, VoxCeleb2 and AVSpeech, producing 1,002 hours of data for four low VSR resource languages, French, Italian, Spanish, and Portuguese. With the automatic labels, we achieve new state-of-the-art performance on mTEDx in four languages, significantly surpassing the previous methods. The automatic labels are available online: https://github.com/JeongHun0716/Visual-Speech-Recognition-for-Low-Resource-Languages
PhasePerturbation: Speech Data Augmentation via Phase Perturbation for Automatic Speech Recognition
Dec 13, 2023Most of the current speech data augmentation methods operate on either the raw waveform or the amplitude spectrum of speech. In this paper, we propose a novel speech data augmentation method called PhasePerturbation that operates dynamically on the phase spectrum of speech. Instead of statically rotating a phase by a constant degree, PhasePerturbation utilizes three dynamic phase spectrum operations, i.e., a randomization operation, a frequency masking operation, and a temporal masking operation, to enhance the diversity of speech data. We conduct experiments on wav2vec2.0 pre-trained ASR models by fine-tuning them with the PhasePerturbation augmented TIMIT corpus. The experimental results demonstrate 10.9\% relative reduction in the word error rate (WER) compared with the baseline model fine-tuned without any augmentation operation. Furthermore, the proposed method achieves additional improvements (12.9\% and 15.9\%) in WER by complementing the Vocal Tract Length Perturbation (VTLP) and the SpecAug, which are both amplitude spectrum-based augmentation methods. The results highlight the capability of PhasePerturbation to improve the current amplitude spectrum-based augmentation methods.
Enhancing Code-switching Speech Recognition with Interactive Language Biases
Sep 29, 2023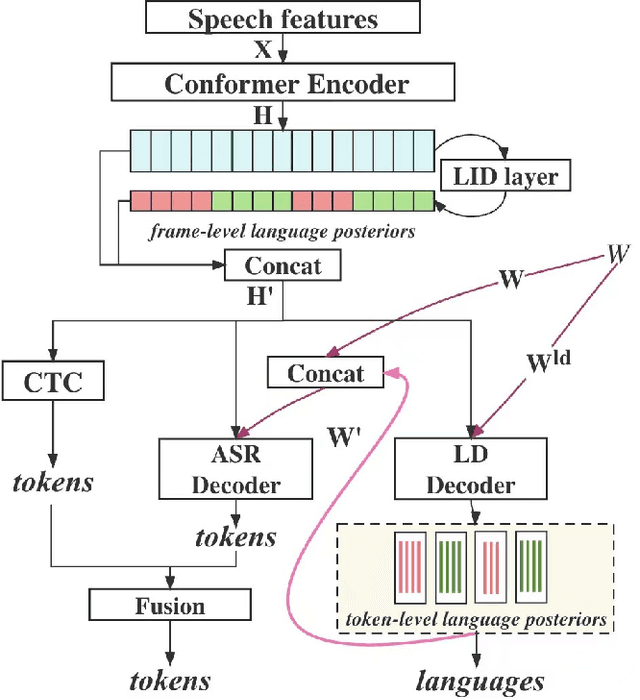

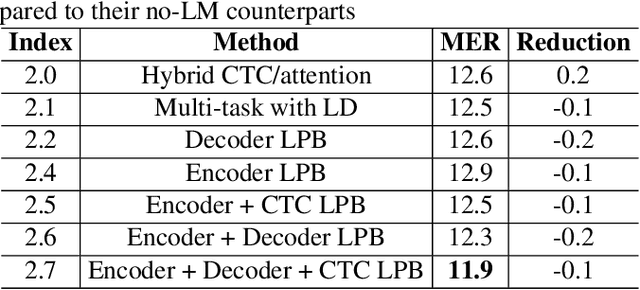
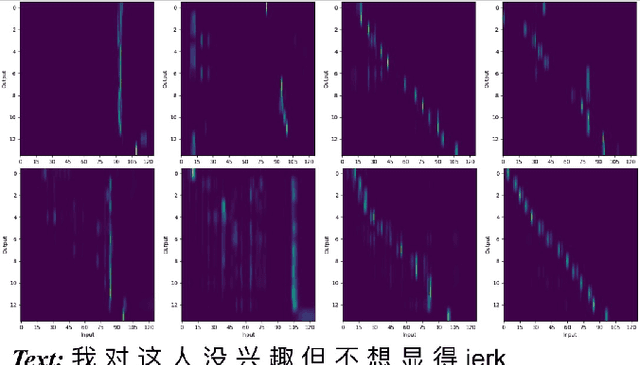
Languages usually switch within a multilingual speech signal, especially in a bilingual society. This phenomenon is referred to as code-switching (CS), making automatic speech recognition (ASR) challenging under a multilingual scenario. We propose to improve CS-ASR by biasing the hybrid CTC/attention ASR model with multi-level language information comprising frame- and token-level language posteriors. The interaction between various resolutions of language biases is subsequently explored in this work. We conducted experiments on datasets from the ASRU 2019 code-switching challenge. Compared to the baseline, the proposed interactive language biases (ILB) method achieves higher performance and ablation studies highlight the effects of different language biases and their interactions. In addition, the results presented indicate that language bias implicitly enhances internal language modeling, leading to performance degradation after employing an external language model.
Towards Probing Contact Center Large Language Models
Dec 26, 2023Fine-tuning large language models (LLMs) with domain-specific instructions has emerged as an effective method to enhance their domain-specific understanding. Yet, there is limited work that examines the core characteristics acquired during this process. In this study, we benchmark the fundamental characteristics learned by contact-center (CC) specific instruction fine-tuned LLMs with out-of-the-box (OOB) LLMs via probing tasks encompassing conversational, channel, and automatic speech recognition (ASR) properties. We explore different LLM architectures (Flan-T5 and Llama), sizes (3B, 7B, 11B, 13B), and fine-tuning paradigms (full fine-tuning vs PEFT). Our findings reveal remarkable effectiveness of CC-LLMs on the in-domain downstream tasks, with improvement in response acceptability by over 48% compared to OOB-LLMs. Additionally, we compare the performance of OOB-LLMs and CC-LLMs on the widely used SentEval dataset, and assess their capabilities in terms of surface, syntactic, and semantic information through probing tasks. Intriguingly, we note a relatively consistent performance of probing classifiers on the set of probing tasks. Our observations indicate that CC-LLMs, while outperforming their out-of-the-box counterparts, exhibit a tendency to rely less on encoding surface, syntactic, and semantic properties, highlighting the intricate interplay between domain-specific adaptation and probing task performance opening up opportunities to explore behavior of fine-tuned language models in specialized contexts.
Spike-Triggered Contextual Biasing for End-to-End Mandarin Speech Recognition
Oct 07, 2023The attention-based deep contextual biasing method has been demonstrated to effectively improve the recognition performance of end-to-end automatic speech recognition (ASR) systems on given contextual phrases. However, unlike shallow fusion methods that directly bias the posterior of the ASR model, deep biasing methods implicitly integrate contextual information, making it challenging to control the degree of bias. In this study, we introduce a spike-triggered deep biasing method that simultaneously supports both explicit and implicit bias. Moreover, both bias approaches exhibit significant improvements and can be cascaded with shallow fusion methods for better results. Furthermore, we propose a context sampling enhancement strategy and improve the contextual phrase filtering algorithm. Experiments on the public WenetSpeech Mandarin biased-word dataset show a 32.0% relative CER reduction compared to the baseline model, with an impressively 68.6% relative CER reduction on contextual phrases.