 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Multi-stage Large Language Model Correction for Speech Recognition
Oct 17, 2023
In this paper, we investigate the usage of large language models (LLMs) to improve the performance of competitive speech recognition systems. Different from traditional language models that focus on one single data domain, the rise of LLMs brings us the opportunity to push the limit of state-of-the-art ASR performance, and at the same time to achieve higher robustness and generalize effectively across multiple domains. Motivated by this, we propose a novel multi-stage approach to combine traditional language model re-scoring and LLM prompting. Specifically, the proposed method has two stages: the first stage uses a language model to re-score an N-best list of ASR hypotheses and run a confidence check; The second stage uses prompts to a LLM to perform ASR error correction on less confident results from the first stage. Our experimental results demonstrate the effectiveness of the proposed method by showing a 10% ~ 20% relative improvement in WER over a competitive ASR system -- across multiple test domains.
ToPro: Token-Level Prompt Decomposition for Cross-Lingual Sequence Labeling Tasks
Jan 29, 2024Prompt-based methods have been successfully applied to multilingual pretrained language models for zero-shot cross-lingual understanding. However, most previous studies primarily focused on sentence-level classification tasks, and only a few considered token-level labeling tasks such as Named Entity Recognition (NER) and Part-of-Speech (POS) tagging. In this paper, we propose Token-Level Prompt Decomposition (ToPro), which facilitates the prompt-based method for token-level sequence labeling tasks. The ToPro method decomposes an input sentence into single tokens and applies one prompt template to each token. Our experiments on multilingual NER and POS tagging datasets demonstrate that ToPro-based fine-tuning outperforms Vanilla fine-tuning and Prompt-Tuning in zero-shot cross-lingual transfer, especially for languages that are typologically different from the source language English. Our method also attains state-of-the-art performance when employed with the mT5 model. Besides, our exploratory study in multilingual large language models shows that ToPro performs much better than the current in-context learning method. Overall, the performance improvements show that ToPro could potentially serve as a novel and simple benchmarking method for sequence labeling tasks.
Generative Context-aware Fine-tuning of Self-supervised Speech Models
Dec 15, 2023When performing tasks like automatic speech recognition or spoken language understanding for a given utterance, access to preceding text or audio provides contextual information can improve performance. Considering the recent advances in generative large language models (LLM), we hypothesize that an LLM could generate useful context information using the preceding text. With appropriate prompts, LLM could generate a prediction of the next sentence or abstractive text like titles or topics. In this paper, we study the use of LLM-generated context information and propose an approach to distill the generated information during fine-tuning of self-supervised speech models, which we refer to as generative context-aware fine-tuning. This approach allows the fine-tuned model to make improved predictions without access to the true surrounding segments or to the LLM at inference time, while requiring only a very small additional context module. We evaluate the proposed approach using the SLUE and Libri-light benchmarks for several downstream tasks: automatic speech recognition, named entity recognition, and sentiment analysis. The results show that generative context-aware fine-tuning outperforms a context injection fine-tuning approach that accesses the ground-truth previous text, and is competitive with a generative context injection fine-tuning approach that requires the LLM at inference time.
Voxtlm: unified decoder-only models for consolidating speech recognition/synthesis and speech/text continuation tasks
Sep 14, 2023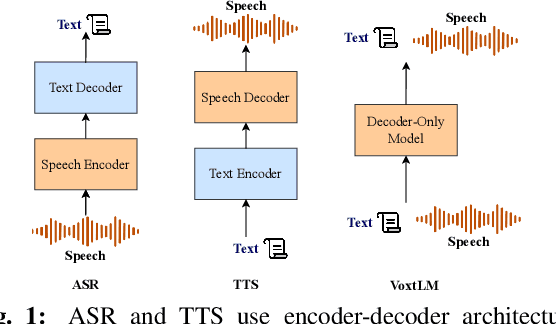


We propose a decoder-only language model, VoxtLM, that can perform four tasks: speech recognition, speech synthesis, text generation, and speech continuation. VoxtLM integrates text vocabulary with discrete speech tokens from self-supervised speech features and uses special tokens to enable multitask learning. Compared to a single-task model, VoxtLM exhibits a significant improvement in speech synthesis, with improvements in both speech intelligibility from 28.9 to 5.6 and objective quality from 2.68 to 3.90. VoxtLM also improves speech generation and speech recognition performance over the single-task counterpart. VoxtLM is trained with publicly available data and training recipes and model checkpoints will be open-sourced to make fully reproducible work.
Decoupling and Interacting Multi-Task Learning Network for Joint Speech and Accent Recognition
Nov 17, 2023Accents, as variations from standard pronunciation, pose significant challenges for speech recognition systems. Although joint automatic speech recognition (ASR) and accent recognition (AR) training has been proven effective in handling multi-accent scenarios, current multi-task ASR-AR approaches overlook the granularity differences between tasks. Fine-grained units capture pronunciation-related accent characteristics, while coarse-grained units are better for learning linguistic information. Moreover, an explicit interaction of two tasks can also provide complementary information and improve the performance of each other, but it is rarely used by existing approaches. In this paper, we propose a novel Decoupling and Interacting Multi-task Network (DIMNet) for joint speech and accent recognition, which is comprised of a connectionist temporal classification (CTC) branch, an AR branch, an ASR branch, and a bottom feature encoder. Specifically, AR and ASR are first decoupled by separated branches and two-granular modeling units to learn task-specific representations. The AR branch is from our previously proposed linguistic-acoustic bimodal AR model and the ASR branch is an encoder-decoder based Conformer model. Then, for the task interaction, the CTC branch provides aligned text for the AR task, while accent embeddings extracted from our AR model are incorporated into the ASR branch's encoder and decoder. Finally, during ASR inference, a cross-granular rescoring method is introduced to fuse the complementary information from the CTC and attention decoder after the decoupling. Our experiments on English and Chinese datasets demonstrate the effectiveness of the proposed model, which achieves 21.45%/28.53% AR accuracy relative improvement and 32.33%/14.55% ASR error rate relative reduction over a published standard baseline, respectively.
Enhancing Multilingual Speech Recognition through Language Prompt Tuning and Frame-Level Language Adapter
Sep 19, 2023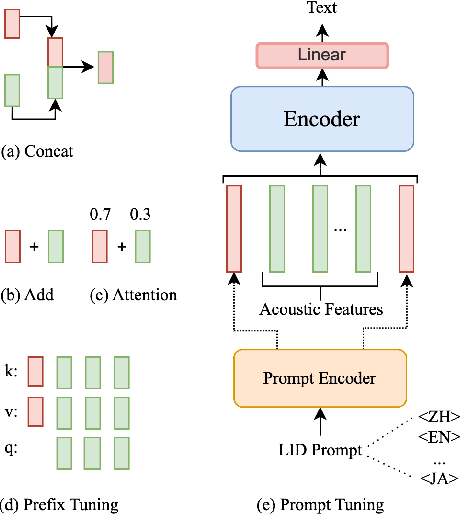
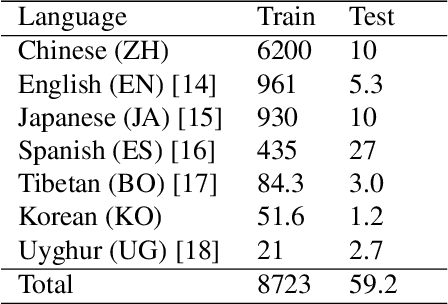
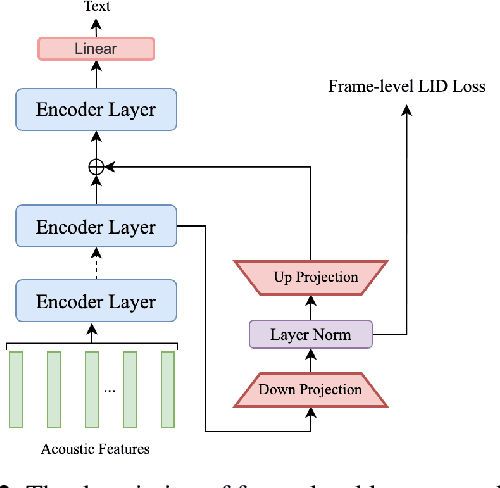
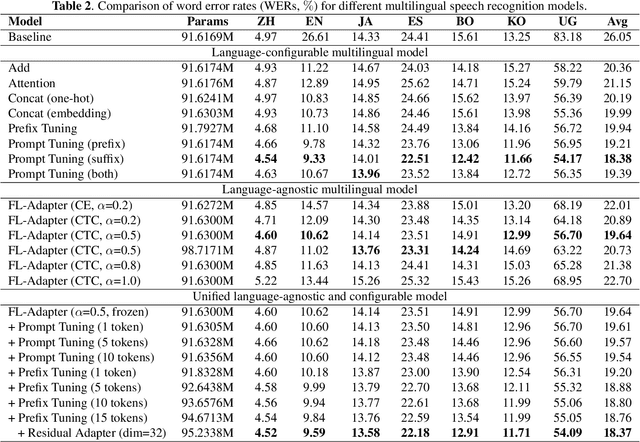
Multilingual intelligent assistants, such as ChatGPT, have recently gained popularity. To further expand the applications of multilingual artificial intelligence assistants and facilitate international communication, it is essential to enhance the performance of multilingual speech recognition, which is a crucial component of speech interaction. In this paper, we propose two simple and parameter-efficient methods: language prompt tuning and frame-level language adapter, to respectively enhance language-configurable and language-agnostic multilingual speech recognition. Additionally, we explore the feasibility of integrating these two approaches using parameter-efficient fine-tuning methods. Our experiments demonstrate significant performance improvements across seven languages using our proposed methods.
Conversational Speech Recognition by Learning Audio-textual Cross-modal Contextual Representation
Oct 22, 2023Automatic Speech Recognition (ASR) in conversational settings presents unique challenges, including extracting relevant contextual information from previous conversational turns. Due to irrelevant content, error propagation, and redundancy, existing methods struggle to extract longer and more effective contexts. To address this issue, we introduce a novel Conversational ASR system, extending the Conformer encoder-decoder model with cross-modal conversational representation. Our approach leverages a cross-modal extractor that combines pre-trained speech and text models through a specialized encoder and a modal-level mask input. This enables the extraction of richer historical speech context without explicit error propagation. We also incorporate conditional latent variational modules to learn conversational level attributes such as role preference and topic coherence. By introducing both cross-modal and conversational representations into the decoder, our model retains context over longer sentences without information loss, achieving relative accuracy improvements of 8.8% and 23% on Mandarin conversation datasets HKUST and MagicData-RAMC, respectively, compared to the standard Conformer model.
Towards Domain-Specific Cross-Corpus Speech Emotion Recognition Approach
Dec 11, 2023Cross-corpus speech emotion recognition (SER) poses a challenge due to feature distribution mismatch, potentially degrading the performance of established SER methods. In this paper, we tackle this challenge by proposing a novel transfer subspace learning method called acoustic knowledgeguided transfer linear regression (AKTLR). Unlike existing approaches, which often overlook domain-specific knowledge related to SER and simply treat cross-corpus SER as a generic transfer learning task, our AKTLR method is built upon a well-designed acoustic knowledge-guided dual sparsity constraint mechanism. This mechanism emphasizes the potential of minimalistic acoustic parameter feature sets to alleviate classifier overadaptation, which is empirically validated acoustic knowledge in SER, enabling superior generalization in cross-corpus SER tasks compared to using large feature sets. Through this mechanism, we extend a simple transfer linear regression model to AKTLR. This extension harnesses its full capability to seek emotiondiscriminative and corpus-invariant features from established acoustic parameter feature sets used for describing speech signals across two scales: contributive acoustic parameter groups and constituent elements within each contributive group. Our proposed method is evaluated through extensive cross-corpus SER experiments on three widely-used speech emotion corpora: EmoDB, eNTERFACE, and CASIA. The results confirm the effectiveness and superior performance of our method, outperforming recent state-of-the-art transfer subspace learning and deep transfer learning-based cross-corpus SER methods. Furthermore, our work provides experimental evidence supporting the feasibility and superiority of incorporating domain-specific knowledge into the transfer learning model to address cross-corpus SER tasks.
Discriminative Speech Recognition Rescoring with Pre-trained Language Models
Oct 10, 2023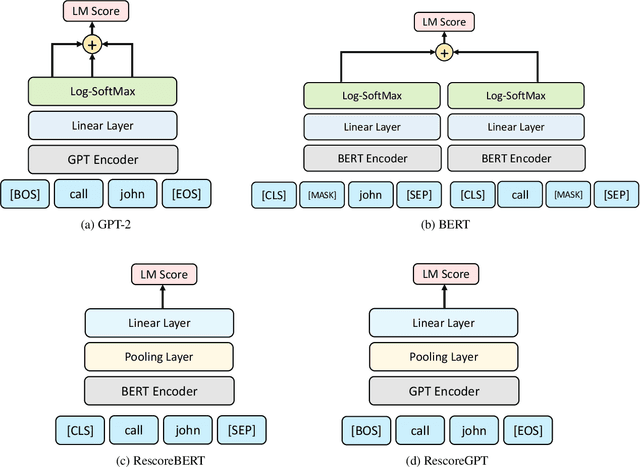
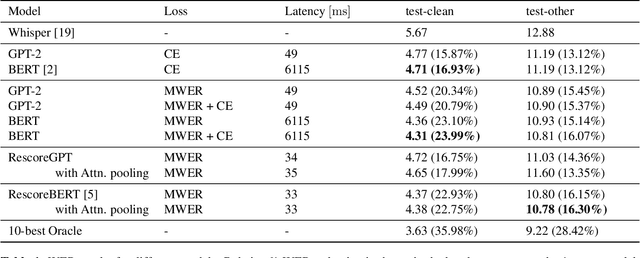
Second pass rescoring is a critical component of competitive automatic speech recognition (ASR) systems. Large language models have demonstrated their ability in using pre-trained information for better rescoring of ASR hypothesis. Discriminative training, directly optimizing the minimum word-error-rate (MWER) criterion typically improves rescoring. In this study, we propose and explore several discriminative fine-tuning schemes for pre-trained LMs. We propose two architectures based on different pooling strategies of output embeddings and compare with probability based MWER. We conduct detailed comparisons between pre-trained causal and bidirectional LMs in discriminative settings. Experiments on LibriSpeech demonstrate that all MWER training schemes are beneficial, giving additional gains upto 8.5\% WER. Proposed pooling variants achieve lower latency while retaining most improvements. Finally, our study concludes that bidirectionality is better utilized with discriminative training.
TorchAudio 2.1: Advancing speech recognition, self-supervised learning, and audio processing components for PyTorch
Oct 27, 2023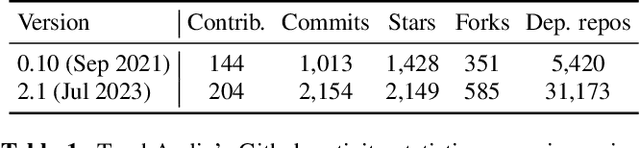


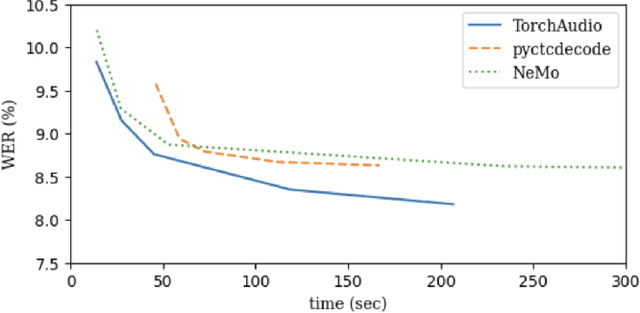
TorchAudio is an open-source audio and speech processing library built for PyTorch. It aims to accelerate the research and development of audio and speech technologies by providing well-designed, easy-to-use, and performant PyTorch components. Its contributors routinely engage with users to understand their needs and fulfill them by developing impactful features. Here, we survey TorchAudio's development principles and contents and highlight key features we include in its latest version (2.1): self-supervised learning pre-trained pipelines and training recipes, high-performance CTC decoders, speech recognition models and training recipes, advanced media I/O capabilities, and tools for performing forced alignment, multi-channel speech enhancement, and reference-less speech assessment. For a selection of these features, through empirical studies, we demonstrate their efficacy and show that they achieve competitive or state-of-the-art performance.