 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Can you Remove the Downstream Model for Speaker Recognition with Self-Supervised Speech Features?
Feb 01, 2024
Self-supervised features are typically used in place of filter-banks in speaker verification models. However, these models were originally designed to ingest filter-banks as inputs, and thus, training them on top of self-supervised features assumes that both feature types require the same amount of learning for the task. In this work, we observe that pre-trained self-supervised speech features inherently include information required for downstream speaker verification task, and therefore, we can simplify the downstream model without sacrificing performance. To this end, we revisit the design of the downstream model for speaker verification using self-supervised features. We show that we can simplify the model to use 97.51% fewer parameters while achieving a 29.93% average improvement in performance on SUPERB. Consequently, we show that the simplified downstream model is more data efficient compared to baseline--it achieves better performance with only 60% of the training data.
TeLeS: Temporal Lexeme Similarity Score to Estimate Confidence in End-to-End ASR
Jan 06, 2024Confidence estimation of predictions from an End-to-End (E2E) Automatic Speech Recognition (ASR) model benefits ASR's downstream and upstream tasks. Class-probability-based confidence scores do not accurately represent the quality of overconfident ASR predictions. An ancillary Confidence Estimation Model (CEM) calibrates the predictions. State-of-the-art (SOTA) solutions use binary target scores for CEM training. However, the binary labels do not reveal the granular information of predicted words, such as temporal alignment between reference and hypothesis and whether the predicted word is entirely incorrect or contains spelling errors. Addressing this issue, we propose a novel Temporal-Lexeme Similarity (TeLeS) confidence score to train CEM. To address the data imbalance of target scores while training CEM, we use shrinkage loss to focus on hard-to-learn data points and minimise the impact of easily learned data points. We conduct experiments with ASR models trained in three languages, namely Hindi, Tamil, and Kannada, with varying training data sizes. Experiments show that TeLeS generalises well across domains. To demonstrate the applicability of the proposed method, we formulate a TeLeS-based Acquisition (TeLeS-A) function for sampling uncertainty in active learning. We observe a significant reduction in the Word Error Rate (WER) as compared to SOTA methods.
SpokesBiz -- an Open Corpus of Conversational Polish
Dec 19, 2023This paper announces the early release of SpokesBiz, a freely available corpus of conversational Polish developed within the CLARIN-BIZ project and comprising over 650 hours of recordings. The transcribed recordings have been diarized and manually annotated for punctuation and casing. We outline the general structure and content of the corpus, showcasing selected applications in linguistic research, evaluation and improvement of automatic speech recognition (ASR) systems
Keyword spotting -- Detecting commands in speech using deep learning
Dec 09, 2023
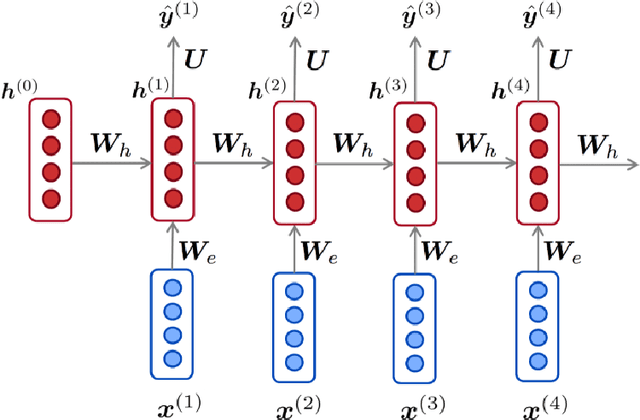
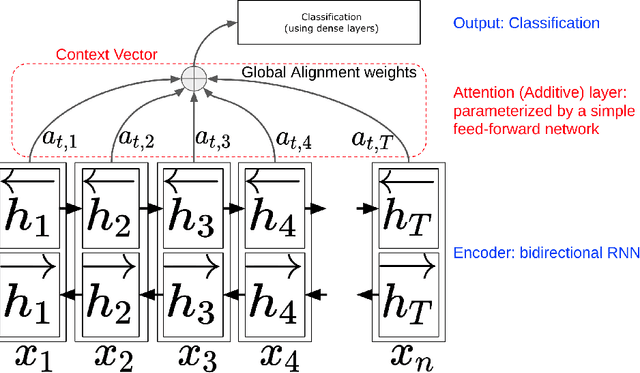
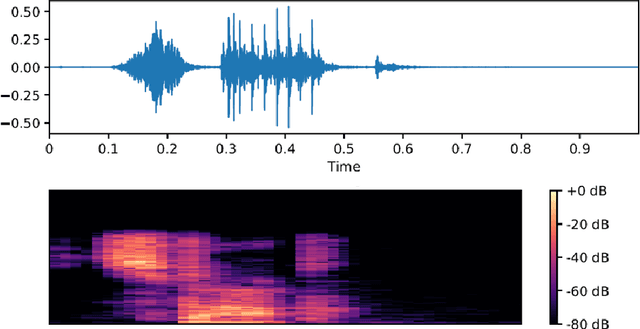
Speech recognition has become an important task in the development of machine learning and artificial intelligence. In this study, we explore the important task of keyword spotting using speech recognition machine learning and deep learning techniques. We implement feature engineering by converting raw waveforms to Mel Frequency Cepstral Coefficients (MFCCs), which we use as inputs to our models. We experiment with several different algorithms such as Hidden Markov Model with Gaussian Mixture, Convolutional Neural Networks and variants of Recurrent Neural Networks including Long Short-Term Memory and the Attention mechanism. In our experiments, RNN with BiLSTM and Attention achieves the best performance with an accuracy of 93.9 %
Multimodal Speech Emotion Recognition Using Modality-specific Self-Supervised Frameworks
Dec 04, 2023Emotion recognition is a topic of significant interest in assistive robotics due to the need to equip robots with the ability to comprehend human behavior, facilitating their effective interaction in our society. Consequently, efficient and dependable emotion recognition systems supporting optimal human-machine communication are required. Multi-modality (including speech, audio, text, images, and videos) is typically exploited in emotion recognition tasks. Much relevant research is based on merging multiple data modalities and training deep learning models utilizing low-level data representations. However, most existing emotion databases are not large (or complex) enough to allow machine learning approaches to learn detailed representations. This paper explores modalityspecific pre-trained transformer frameworks for self-supervised learning of speech and text representations for data-efficient emotion recognition while achieving state-of-the-art performance in recognizing emotions. This model applies feature-level fusion using nonverbal cue data points from motion capture to provide multimodal speech emotion recognition. The model was trained using the publicly available IEMOCAP dataset, achieving an overall accuracy of 77.58% for four emotions, outperforming state-of-the-art approaches
Leveraged Mel spectrograms using Harmonic and Percussive Components in Speech Emotion Recognition
Dec 18, 2023Speech Emotion Recognition (SER) affective technology enables the intelligent embedded devices to interact with sensitivity. Similarly, call centre employees recognise customers' emotions from their pitch, energy, and tone of voice so as to modify their speech for a high-quality interaction with customers. This work explores, for the first time, the effects of the harmonic and percussive components of Mel spectrograms in SER. We attempt to leverage the Mel spectrogram by decomposing distinguishable acoustic features for exploitation in our proposed architecture, which includes a novel feature map generator algorithm, a CNN-based network feature extractor and a multi-layer perceptron (MLP) classifier. This study specifically focuses on effective data augmentation techniques for building an enriched hybrid-based feature map. This process results in a function that outputs a 2D image so that it can be used as input data for a pre-trained CNN-VGG16 feature extractor. Furthermore, we also investigate other acoustic features such as MFCCs, chromagram, spectral contrast, and the tonnetz to assess our proposed framework. A test accuracy of 92.79% on the Berlin EMO-DB database is achieved. Our result is higher than previous works using CNN-VGG16.
* 12 pages
Nonlinear functional regression by functional deep neural network with kernel embedding
Jan 05, 2024With the rapid development of deep learning in various fields of science and technology, such as speech recognition, image classification, and natural language processing, recently it is also widely applied in the functional data analysis (FDA) with some empirical success. However, due to the infinite dimensional input, we need a powerful dimension reduction method for functional learning tasks, especially for the nonlinear functional regression. In this paper, based on the idea of smooth kernel integral transformation, we propose a functional deep neural network with an efficient and fully data-dependent dimension reduction method. The architecture of our functional net consists of a kernel embedding step: an integral transformation with a data-dependent smooth kernel; a projection step: a dimension reduction by projection with eigenfunction basis based on the embedding kernel; and finally an expressive deep ReLU neural network for the prediction. The utilization of smooth kernel embedding enables our functional net to be discretization invariant, efficient, and robust to noisy observations, capable of utilizing information in both input functions and responses data, and have a low requirement on the number of discrete points for an unimpaired generalization performance. We conduct theoretical analysis including approximation error and generalization error analysis, and numerical simulations to verify these advantages of our functional net.
The GUA-Speech System Description for CNVSRC Challenge 2023
Dec 12, 2023This study describes our system for Task 1 Single-speaker Visual Speech Recognition (VSR) fixed track in the Chinese Continuous Visual Speech Recognition Challenge (CNVSRC) 2023. Specifically, we use intermediate connectionist temporal classification (Inter CTC) residual modules to relax the conditional independence assumption of CTC in our model. Then we use a bi-transformer decoder to enable the model to capture both past and future contextual information. In addition, we use Chinese characters as the modeling units to improve the recognition accuracy of our model. Finally, we use a recurrent neural network language model (RNNLM) for shallow fusion in the inference stage. Experiments show that our system achieves a character error rate (CER) of 38.09% on the Eval set which reaches a relative CER reduction of 21.63% over the official baseline, and obtains a second place in the challenge.
Ms-senet: Enhancing Speech Emotion Recognition Through Multi-scale Feature Fusion With Squeeze-and-excitation Blocks
Dec 19, 2023Speech Emotion Recognition (SER) has become a growing focus of research in human-computer interaction. Spatiotemporal features play a crucial role in SER, yet current research lacks comprehensive spatiotemporal feature learning. This paper focuses on addressing this gap by proposing a novel approach. In this paper, we employ Convolutional Neural Network (CNN) with varying kernel sizes for spatial and temporal feature extraction. Additionally, we introduce Squeeze-and-Excitation (SE) modules to capture and fuse multi-scale features, facilitating effective information fusion for improved emotion recognition and a deeper understanding of the temporal evolution of speech emotion. Moreover, we employ skip connections and Spatial Dropout (SD) layers to prevent overfitting and increase the model's depth. Our method outperforms the previous state-of-the-art method, achieving an average UAR and WAR improvement of 1.62% and 1.32%, respectively, across six benchmark SER datasets. Further experiments demonstrated that our method can fully extract spatiotemporal features in low-resource conditions.
End-to-End Speech Recognition Contextualization with Large Language Models
Sep 19, 2023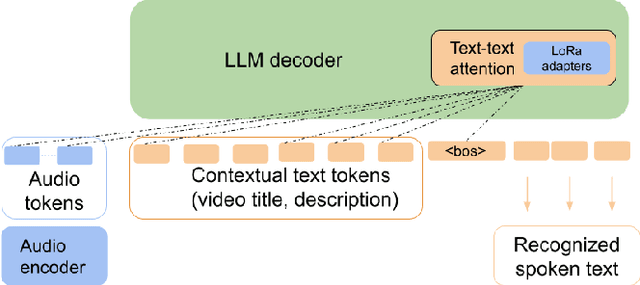

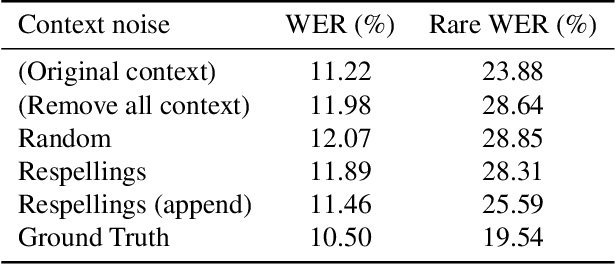

In recent years, Large Language Models (LLMs) have garnered significant attention from the research community due to their exceptional performance and generalization capabilities. In this paper, we introduce a novel method for contextualizing speech recognition models incorporating LLMs. Our approach casts speech recognition as a mixed-modal language modeling task based on a pretrained LLM. We provide audio features, along with optional text tokens for context, to train the system to complete transcriptions in a decoder-only fashion. As a result, the system is implicitly incentivized to learn how to leverage unstructured contextual information during training. Our empirical results demonstrate a significant improvement in performance, with a 6% WER reduction when additional textual context is provided. Moreover, we find that our method performs competitively and improve by 7.5% WER overall and 17% WER on rare words against a baseline contextualized RNN-T system that has been trained on more than twenty five times larger speech dataset. Overall, we demonstrate that by only adding a handful number of trainable parameters via adapters, we can unlock contextualized speech recognition capability for the pretrained LLM while keeping the same text-only input functionality.