 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
XLS-R Deep Learning Model for Multilingual ASR on Low- Resource Languages: Indonesian, Javanese, and Sundanese
Jan 12, 2024
This research paper focuses on the development and evaluation of Automatic Speech Recognition (ASR) technology using the XLS-R 300m model. The study aims to improve ASR performance in converting spoken language into written text, specifically for Indonesian, Javanese, and Sundanese languages. The paper discusses the testing procedures, datasets used, and methodology employed in training and evaluating the ASR systems. The results show that the XLS-R 300m model achieves competitive Word Error Rate (WER) measurements, with a slight compromise in performance for Javanese and Sundanese languages. The integration of a 5-gram KenLM language model significantly reduces WER and enhances ASR accuracy. The research contributes to the advancement of ASR technology by addressing linguistic diversity and improving performance across various languages. The findings provide insights into optimizing ASR accuracy and applicability for diverse linguistic contexts.
DSNet: Disentangled Siamese Network with Neutral Calibration for Speech Emotion Recognition
Dec 25, 2023One persistent challenge in deep learning based speech emotion recognition (SER) is the unconscious encoding of emotion-irrelevant factors (e.g., speaker or phonetic variability), which limits the generalization of SER in practical use. In this paper, we propose DSNet, a Disentangled Siamese Network with neutral calibration, to meet the demand for a more robust and explainable SER model. Specifically, we introduce an orthogonal feature disentanglement module to explicitly project the high-level representation into two distinct subspaces. Later, we propose a novel neutral calibration mechanism to encourage one subspace to capture sufficient emotion-irrelevant information. In this way, the other one can better isolate and emphasize the emotion-relevant information within speech signals. Experimental results on two popular benchmark datasets demonstrate the superiority of DSNet over various state-of-the-art methods for speaker-independent SER.
Towards Automatic Data Augmentation for Disordered Speech Recognition
Dec 14, 2023Automatic recognition of disordered speech remains a highly challenging task to date due to data scarcity. This paper presents a reinforcement learning (RL) based on-the-fly data augmentation approach for training state-of-the-art PyChain TDNN and end-to-end Conformer ASR systems on such data. The handcrafted temporal and spectral mask operations in the standard SpecAugment method that are task and system dependent, together with additionally introduced minimum and maximum cut-offs of these time-frequency masks, are now automatically learned using an RNN-based policy controller and tightly integrated with ASR system training. Experiments on the UASpeech corpus suggest the proposed RL-based data augmentation approach consistently produced performance superior or comparable that obtained using expert or handcrafted SpecAugment policies. Our RL auto-augmented PyChain TDNN system produced an overall WER of 28.79% on the UASpeech test set of 16 dysarthric speakers.
BS-PLCNet: Band-split Packet Loss Concealment Network with Multi-task Learning Framework and Multi-discriminators
Jan 08, 2024Packet loss is a common and unavoidable problem in voice over internet phone (VoIP) systems. To deal with the problem, we propose a band-split packet loss concealment network (BS-PLCNet). Specifically, we split the full-band signal into wide-band (0-8kHz) and high-band (8-24kHz). The wide-band signals are processed by a gated convolutional recurrent network (GCRN), while the high-band counterpart is processed by a simple GRU network. To ensure high speech quality and automatic speech recognition (ASR) compatibility, multi-task learning (MTL) framework including fundamental frequency (f0) prediction, linguistic awareness, and multi-discriminators are used. The proposed approach tied for 1st place in the ICASSP 2024 PLC Challenge.
Punctuation Restoration Improves Structure Understanding without Supervision
Feb 13, 2024Unsupervised learning objectives like language modeling and de-noising constitute a significant part in producing pre-trained models that perform various downstream applications from natural language understanding to conversational tasks. However, despite impressive conversational capabilities of recent large language model, their abilities to capture syntactic or semantic structure within text lag behind. We hypothesize that the mismatch between linguistic performance and competence in machines is attributable to insufficient transfer of linguistic structure knowledge to computational systems with currently popular pre-training objectives. We show that punctuation restoration transfers to improvements in in- and out-of-distribution performance on structure-related tasks like named entity recognition, open information extraction, chunking, and part-of-speech tagging. Punctuation restoration is an effective learning objective that can improve structure understanding and yield a more robust structure-aware representations of natural language.
Enhancing Pre-trained ASR System Fine-tuning for Dysarthric Speech Recognition using Adversarial Data Augmentation
Jan 01, 2024Automatic recognition of dysarthric speech remains a highly challenging task to date. Neuro-motor conditions and co-occurring physical disabilities create difficulty in large-scale data collection for ASR system development. Adapting SSL pre-trained ASR models to limited dysarthric speech via data-intensive parameter fine-tuning leads to poor generalization. To this end, this paper presents an extensive comparative study of various data augmentation approaches to improve the robustness of pre-trained ASR model fine-tuning to dysarthric speech. These include: a) conventional speaker-independent perturbation of impaired speech; b) speaker-dependent speed perturbation, or GAN-based adversarial perturbation of normal, control speech based on their time alignment against parallel dysarthric speech; c) novel Spectral basis GAN-based adversarial data augmentation operating on non-parallel data. Experiments conducted on the UASpeech corpus suggest GAN-based data augmentation consistently outperforms fine-tuned Wav2vec2.0 and HuBERT models using no data augmentation and speed perturbation across different data expansion operating points by statistically significant word error rate (WER) reductions up to 2.01% and 0.96% absolute (9.03% and 4.63% relative) respectively on the UASpeech test set of 16 dysarthric speakers. After cross-system outputs rescoring, the best system produced the lowest published WER of 16.53% (46.47% on very low intelligibility) on UASpeech.
Dementia Assessment Using Mandarin Speech with an Attention-based Speech Recognition Encoder
Oct 06, 2023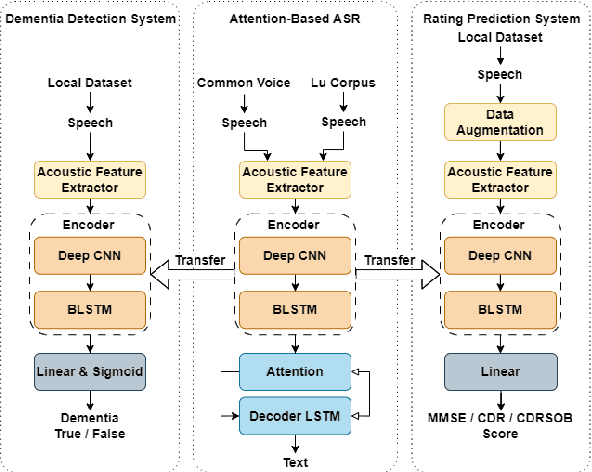
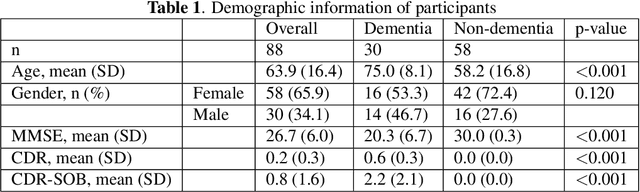
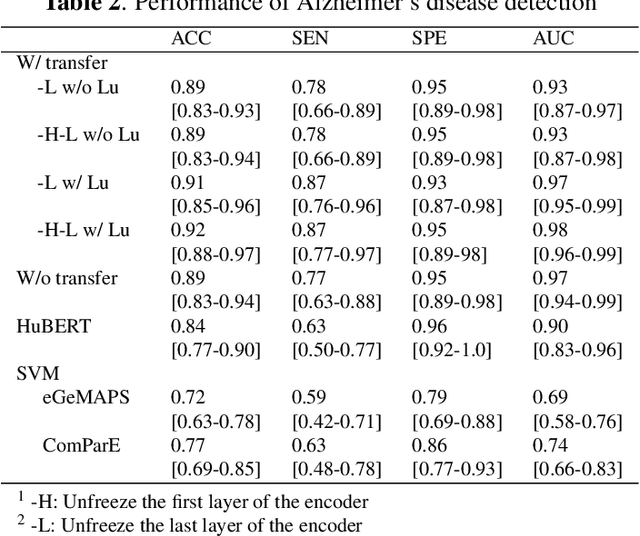
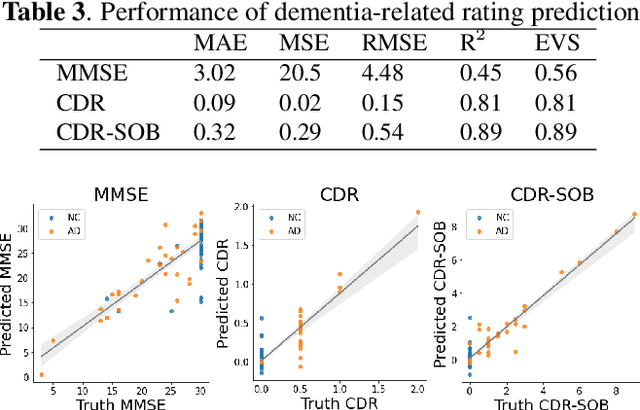
Dementia diagnosis requires a series of different testing methods, which is complex and time-consuming. Early detection of dementia is crucial as it can prevent further deterioration of the condition. This paper utilizes a speech recognition model to construct a dementia assessment system tailored for Mandarin speakers during the picture description task. By training an attention-based speech recognition model on voice data closely resembling real-world scenarios, we have significantly enhanced the model's recognition capabilities. Subsequently, we extracted the encoder from the speech recognition model and added a linear layer for dementia assessment. We collected Mandarin speech data from 99 subjects and acquired their clinical assessments from a local hospital. We achieved an accuracy of 92.04% in Alzheimer's disease detection and a mean absolute error of 9% in clinical dementia rating score prediction.
Analysis of Self-Supervised Speech Models on Children's Speech and Infant Vocalizations
Feb 10, 2024To understand why self-supervised learning (SSL) models have empirically achieved strong performances on several speech-processing downstream tasks, numerous studies have focused on analyzing the encoded information of the SSL layer representations in adult speech. Limited work has investigated how pre-training and fine-tuning affect SSL models encoding children's speech and vocalizations. In this study, we aim to bridge this gap by probing SSL models on two relevant downstream tasks: (1) phoneme recognition (PR) on the speech of adults, older children (8-10 years old), and younger children (1-4 years old), and (2) vocalization classification (VC) distinguishing cry, fuss, and babble for infants under 14 months old. For younger children's PR, the superiority of fine-tuned SSL models is largely due to their ability to learn features that represent older children's speech and then adapt those features to the speech of younger children. For infant VC, SSL models pre-trained on large-scale home recordings learn to leverage phonetic representations at middle layers, and thereby enhance the performance of this task.
Pseudo-Labeling for Domain-Agnostic Bangla Automatic Speech Recognition
Nov 06, 2023One of the major challenges for developing automatic speech recognition (ASR) for low-resource languages is the limited access to labeled data with domain-specific variations. In this study, we propose a pseudo-labeling approach to develop a large-scale domain-agnostic ASR dataset. With the proposed methodology, we developed a 20k+ hours labeled Bangla speech dataset covering diverse topics, speaking styles, dialects, noisy environments, and conversational scenarios. We then exploited the developed corpus to design a conformer-based ASR system. We benchmarked the trained ASR with publicly available datasets and compared it with other available models. To investigate the efficacy, we designed and developed a human-annotated domain-agnostic test set composed of news, telephony, and conversational data among others. Our results demonstrate the efficacy of the model trained on psuedo-label data for the designed test-set along with publicly-available Bangla datasets. The experimental resources will be publicly available.(https://github.com/hishab-nlp/Pseudo-Labeling-for-Domain-Agnostic-Bangla-ASR)
Multi-Input Multi-Output Target-Speaker Voice Activity Detection For Unified, Flexible, and Robust Audio-Visual Speaker Diarization
Jan 16, 2024Audio-visual learning has demonstrated promising results in many classical speech tasks (e.g., speech separation, automatic speech recognition, wake-word spotting). We believe that introducing visual modality will also benefit speaker diarization. To date, target-speaker voice activity detection (TS-VAD) plays an essential role in highly accurate speaker diarization. However, previous TS-VAD models take audio features and utilize the speaker's acoustic footprint to distinguish his or her personal speech activities, which is susceptible to overlapped speaking in multi-speaker scenarios. Although visual information naturally tolerates overlapped speech, it easily suffers from spatial occlusion. The potential modality-missing problem blocks TS-VAD towards an audio-visual approach. This paper proposes a multi-input multi-output target-speaker voice activity detection (MIMO-TSVAD) framework for speaker diarization. The proposed method can take audio-visual input and leverage the speaker's acoustic footprint or lip track to flexibly conduct audio-based, video-based, and audio-visual speaker diarization in a unified sequence-to-sequence architecture. Experimental results show that the MIMO-TSVAD framework demonstrates state-of-the-art performance on the VoxConverse, DIHARD-III, and MISP 2022 datasets under corresponding evaluation metrics, obtaining the diarization error rates (DERs) of 4.18%, 10.10%, and 8.15%, respectively. In addition, it can perform robustly in heavy lip-missing scenarios.