 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
An audio-quality-based multi-strategy approach for target speaker extraction in the MISP 2023 Challenge
Jan 08, 2024
This paper describes our audio-quality-based multi-strategy approach for the audio-visual target speaker extraction (AVTSE) task in the Multi-modal Information based Speech Processing (MISP) 2023 Challenge. Specifically, our approach adopts different extraction strategies based on the audio quality, striking a balance between interference removal and speech preservation, which benifits the back-end automatic speech recognition (ASR) systems. Experiments show that our approach achieves a character error rate (CER) of 24.2% and 33.2% on the Dev and Eval set, respectively, obtaining the second place in the challenge.
A comparative analysis between Conformer-Transducer, Whisper, and wav2vec2 for improving the child speech recognition
Nov 07, 2023Automatic Speech Recognition (ASR) systems have progressed significantly in their performance on adult speech data; however, transcribing child speech remains challenging due to the acoustic differences in the characteristics of child and adult voices. This work aims to explore the potential of adapting state-of-the-art Conformer-transducer models to child speech to improve child speech recognition performance. Furthermore, the results are compared with those of self-supervised wav2vec2 models and semi-supervised multi-domain Whisper models that were previously finetuned on the same data. We demonstrate that finetuning Conformer-transducer models on child speech yields significant improvements in ASR performance on child speech, compared to the non-finetuned models. We also show Whisper and wav2vec2 adaptation on different child speech datasets. Our detailed comparative analysis shows that wav2vec2 provides the most consistent performance improvements among the three methods studied.
Personalization of CTC-based End-to-End Speech Recognition Using Pronunciation-Driven Subword Tokenization
Oct 16, 2023Recent advances in deep learning and automatic speech recognition have improved the accuracy of end-to-end speech recognition systems, but recognition of personal content such as contact names remains a challenge. In this work, we describe our personalization solution for an end-to-end speech recognition system based on connectionist temporal classification. Building on previous work, we present a novel method for generating additional subword tokenizations for personal entities from their pronunciations. We show that using this technique in combination with two established techniques, contextual biasing and wordpiece prior normalization, we are able to achieve personal named entity accuracy on par with a competitive hybrid system.
End to end Hindi to English speech conversion using Bark, mBART and a finetuned XLSR Wav2Vec2
Jan 11, 2024Speech has long been a barrier to effective communication and connection, persisting as a challenge in our increasingly interconnected world. This research paper introduces a transformative solution to this persistent obstacle an end-to-end speech conversion framework tailored for Hindi-to-English translation, culminating in the synthesis of English audio. By integrating cutting-edge technologies such as XLSR Wav2Vec2 for automatic speech recognition (ASR), mBART for neural machine translation (NMT), and a Text-to-Speech (TTS) synthesis component, this framework offers a unified and seamless approach to cross-lingual communication. We delve into the intricate details of each component, elucidating their individual contributions and exploring the synergies that enable a fluid transition from spoken Hindi to synthesized English audio.
FAT-HuBERT: Front-end Adaptive Training of Hidden-unit BERT for Distortion-Invariant Robust Speech Recognition
Nov 29, 2023Advancements in monaural speech enhancement (SE) techniques have greatly improved the perceptual quality of speech. However, integrating these techniques into automatic speech recognition (ASR) systems has not yielded the expected performance gains, primarily due to the introduction of distortions during the SE process. In this paper, we propose a novel approach called FAT-HuBERT, which leverages distortion-invariant self-supervised learning (SSL) to enhance the robustness of ASR. To address the distortions introduced by the SE frontends, we introduce layer-wise fusion modules that incorporate features extracted from both observed noisy signals and enhanced signals. During training, the SE frontend is randomly selected from a pool of models. We evaluate the performance of FAT-HuBERT on simulated noisy speech generated from LibriSpeech as well as real-world noisy speech from the CHiME-4 1-channel dataset. The experimental results demonstrate a significant relative reduction in word error rate (WER).
Intuitive Multilingual Audio-Visual Speech Recognition with a Single-Trained Model
Oct 23, 2023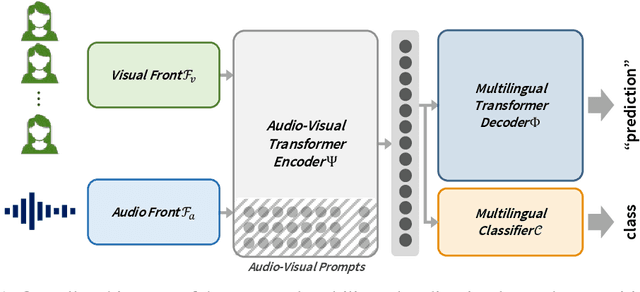
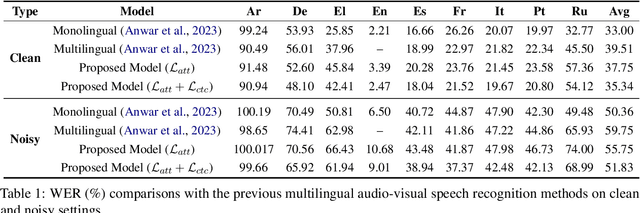
We present a novel approach to multilingual audio-visual speech recognition tasks by introducing a single model on a multilingual dataset. Motivated by a human cognitive system where humans can intuitively distinguish different languages without any conscious effort or guidance, we propose a model that can capture which language is given as an input speech by distinguishing the inherent similarities and differences between languages. To do so, we design a prompt fine-tuning technique into the largely pre-trained audio-visual representation model so that the network can recognize the language class as well as the speech with the corresponding language. Our work contributes to developing robust and efficient multilingual audio-visual speech recognition systems, reducing the need for language-specific models.
Improving ASR Contextual Biasing with Guided Attention
Jan 16, 2024In this paper, we propose a Guided Attention (GA) auxiliary training loss, which improves the effectiveness and robustness of automatic speech recognition (ASR) contextual biasing without introducing additional parameters. A common challenge in previous literature is that the word error rate (WER) reduction brought by contextual biasing diminishes as the number of bias phrases increases. To address this challenge, we employ a GA loss as an additional training objective besides the Transducer loss. The proposed GA loss aims to teach the cross attention how to align bias phrases with text tokens or audio frames. Compared to studies with similar motivations, the proposed loss operates directly on the cross attention weights and is easier to implement. Through extensive experiments based on Conformer Transducer with Contextual Adapter, we demonstrate that the proposed method not only leads to a lower WER but also retains its effectiveness as the number of bias phrases increases. Specifically, the GA loss decreases the WER of rare vocabularies by up to 19.2% on LibriSpeech compared to the contextual biasing baseline, and up to 49.3% compared to a vanilla Transducer.
Revisiting Self-supervised Learning of Speech Representation from a Mutual Information Perspective
Jan 16, 2024Existing studies on self-supervised speech representation learning have focused on developing new training methods and applying pre-trained models for different applications. However, the quality of these models is often measured by the performance of different downstream tasks. How well the representations access the information of interest is less studied. In this work, we take a closer look into existing self-supervised methods of speech from an information-theoretic perspective. We aim to develop metrics using mutual information to help practical problems such as model design and selection. We use linear probes to estimate the mutual information between the target information and learned representations, showing another insight into the accessibility to the target information from speech representations. Further, we explore the potential of evaluating representations in a self-supervised fashion, where we estimate the mutual information between different parts of the data without using any labels. Finally, we show that both supervised and unsupervised measures echo the performance of the models on layer-wise linear probing and speech recognition.
Punctuation Restoration Improves Structure Understanding without Supervision
Feb 13, 2024Unsupervised learning objectives like language modeling and de-noising constitute a significant part in producing pre-trained models that perform various downstream applications from natural language understanding to conversational tasks. However, despite impressive conversational capabilities of recent large language model, their abilities to capture syntactic or semantic structure within text lag behind. We hypothesize that the mismatch between linguistic performance and competence in machines is attributable to insufficient transfer of linguistic structure knowledge to computational systems with currently popular pre-training objectives. We show that punctuation restoration transfers to improvements in in- and out-of-distribution performance on structure-related tasks like named entity recognition, open information extraction, chunking, and part-of-speech tagging. Punctuation restoration is an effective learning objective that can improve structure understanding and yield a more robust structure-aware representations of natural language.
XLS-R Deep Learning Model for Multilingual ASR on Low- Resource Languages: Indonesian, Javanese, and Sundanese
Jan 12, 2024This research paper focuses on the development and evaluation of Automatic Speech Recognition (ASR) technology using the XLS-R 300m model. The study aims to improve ASR performance in converting spoken language into written text, specifically for Indonesian, Javanese, and Sundanese languages. The paper discusses the testing procedures, datasets used, and methodology employed in training and evaluating the ASR systems. The results show that the XLS-R 300m model achieves competitive Word Error Rate (WER) measurements, with a slight compromise in performance for Javanese and Sundanese languages. The integration of a 5-gram KenLM language model significantly reduces WER and enhances ASR accuracy. The research contributes to the advancement of ASR technology by addressing linguistic diversity and improving performance across various languages. The findings provide insights into optimizing ASR accuracy and applicability for diverse linguistic contexts.