 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Whisper-KDQ: A Lightweight Whisper via Guided Knowledge Distillation and Quantization for Efficient ASR
May 18, 2023
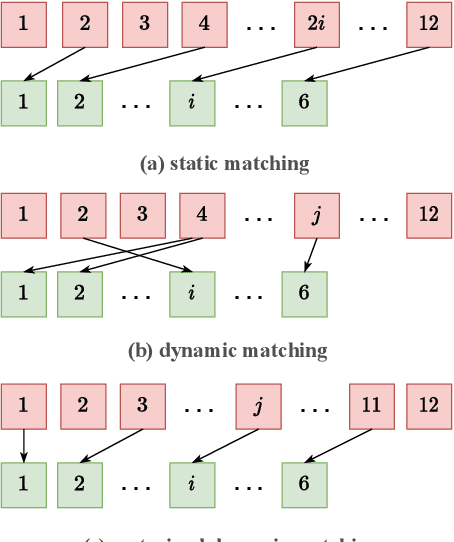
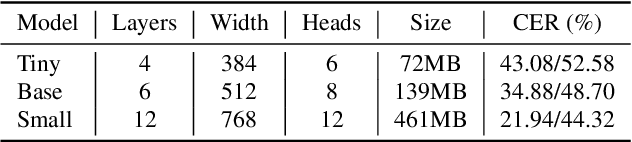
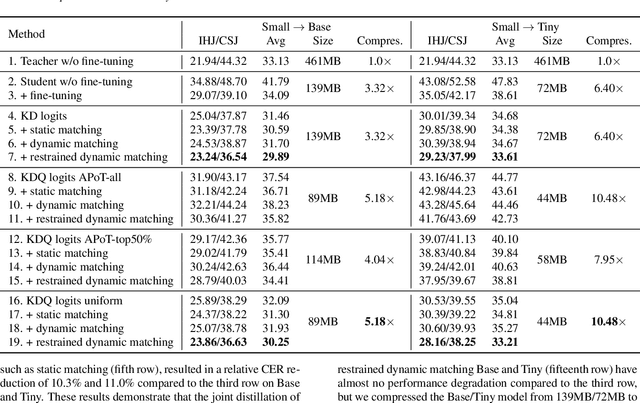
Due to the rapid development of computing hardware resources and the dramatic growth of data, pre-trained models in speech recognition, such as Whisper, have significantly improved the performance of speech recognition tasks. However, these models usually have a high computational overhead, making it difficult to execute effectively on resource-constrained devices. To speed up inference and reduce model size while maintaining performance, we propose a novel guided knowledge distillation and quantization for large pre-trained model Whisper. The student model selects distillation and quantization layers based on quantization loss and distillation loss, respectively. We compressed $\text{Whisper}_\text{small}$ to $\text{Whisper}_\text{base}$ and $\text{Whisper}_\text{tiny}$ levels, making $\text{Whisper}_\text{small}$ 5.18x/10.48x smaller, respectively. Moreover, compared to the original $\text{Whisper}_\text{base}$ and $\text{Whisper}_\text{tiny}$, there is also a relative character error rate~(CER) reduction of 11.3% and 14.0% for the new compressed model respectively.
Pretraining Conformer with ASR or ASV for Anti-Spoofing Countermeasure
Jul 04, 2023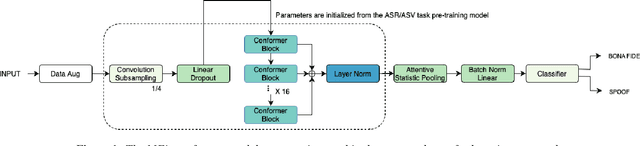
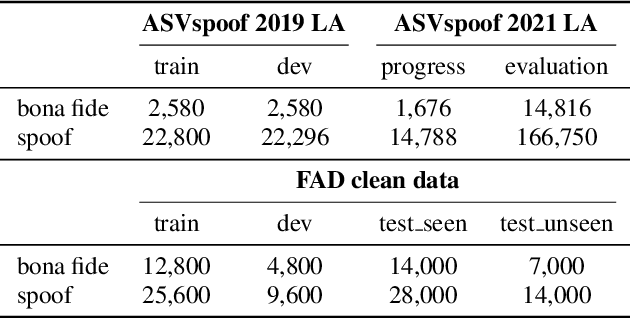
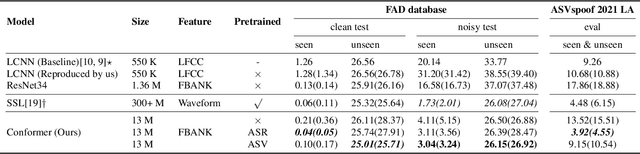
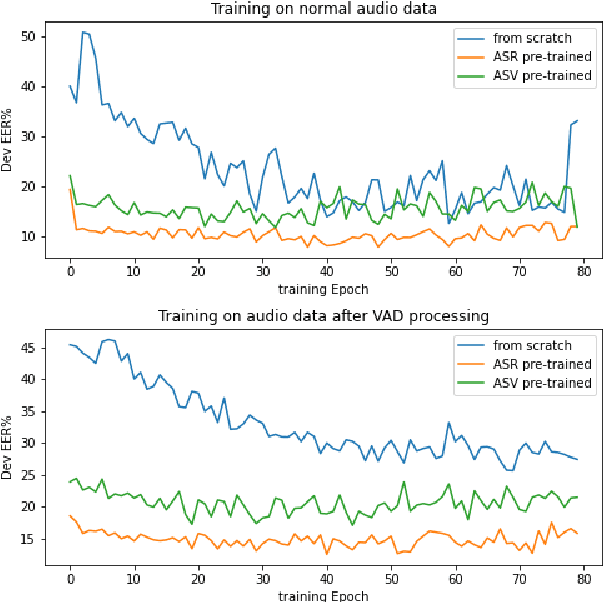
This paper introduces the Multi-scale Feature Aggregation Conformer (MFA-Conformer) structure for audio anti-spoofing countermeasure (CM). MFA-Conformer combines a convolutional neural networkbased on the Transformer, allowing it to aggregate global andlocal information. This may benefit the anti-spoofing CM system to capture the synthetic artifacts hidden both locally and globally. In addition, given the excellent performance of MFA Conformer on automatic speech recognition (ASR) and automatic speaker verification (ASV) tasks, we present a transfer learning method that utilizes pretrained Conformer models on ASR or ASV tasks to enhance the robustness of CM systems. The proposed method is evaluated on both Chinese and Englishs poofing detection databases. On the FAD clean set, the MFA-Conformer model pretrained on the ASR task achieves an EER of 0.038%, which dramatically outperforms the baseline. Moreover, experimental results demonstrate that proposed transfer learning method on Conformer is effective on pure speech segments after voice activity detection processing.
Modeling Spoken Information Queries for Virtual Assistants: Open Problems, Challenges and Opportunities
Apr 25, 2023Virtual assistants are becoming increasingly important speech-driven Information Retrieval platforms that assist users with various tasks. We discuss open problems and challenges with respect to modeling spoken information queries for virtual assistants, and list opportunities where Information Retrieval methods and research can be applied to improve the quality of virtual assistant speech recognition. We discuss how query domain classification, knowledge graphs and user interaction data, and query personalization can be helpful to improve the accurate recognition of spoken information domain queries. Finally, we also provide a brief overview of current problems and challenges in speech recognition.
An Empirical Study and Improvement for Speech Emotion Recognition
Apr 08, 2023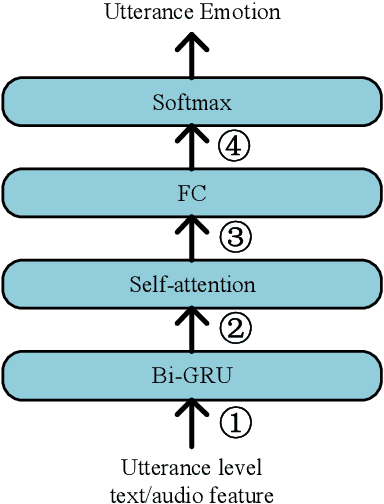

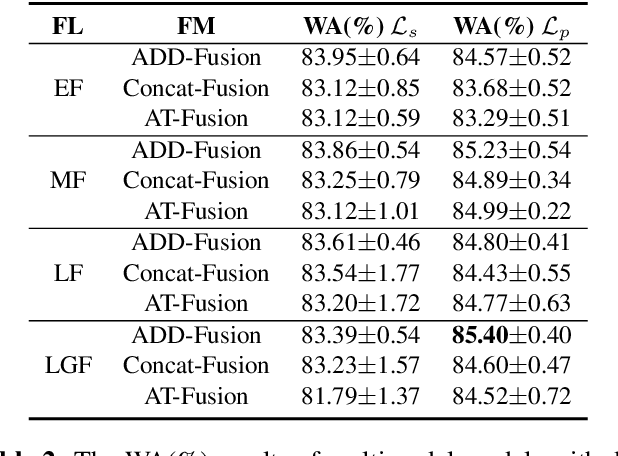
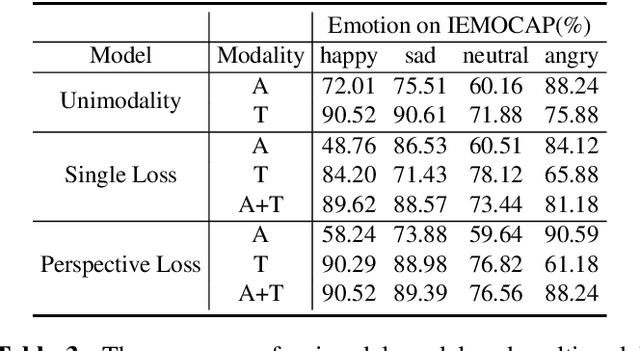
Multimodal speech emotion recognition aims to detect speakers' emotions from audio and text. Prior works mainly focus on exploiting advanced networks to model and fuse different modality information to facilitate performance, while neglecting the effect of different fusion strategies on emotion recognition. In this work, we consider a simple yet important problem: how to fuse audio and text modality information is more helpful for this multimodal task. Further, we propose a multimodal emotion recognition model improved by perspective loss. Empirical results show our method obtained new state-of-the-art results on the IEMOCAP dataset. The in-depth analysis explains why the improved model can achieve improvements and outperforms baselines.
Accelerating Transducers through Adjacent Token Merging
Jun 28, 2023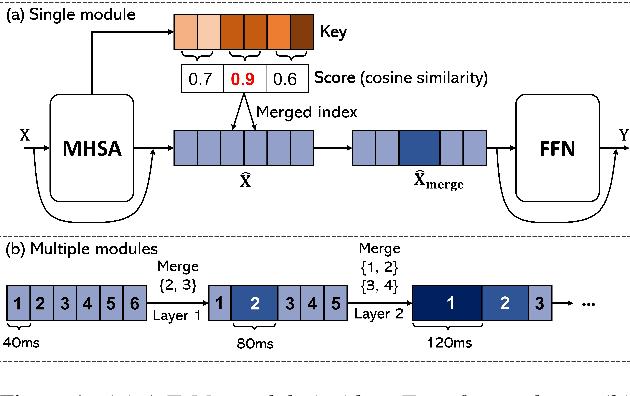
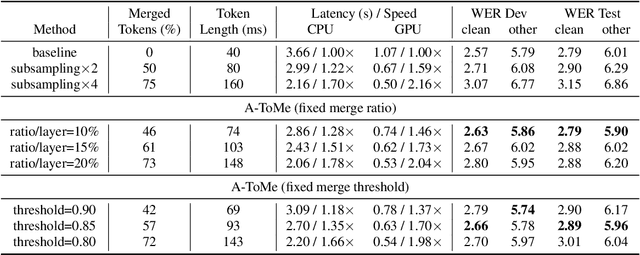
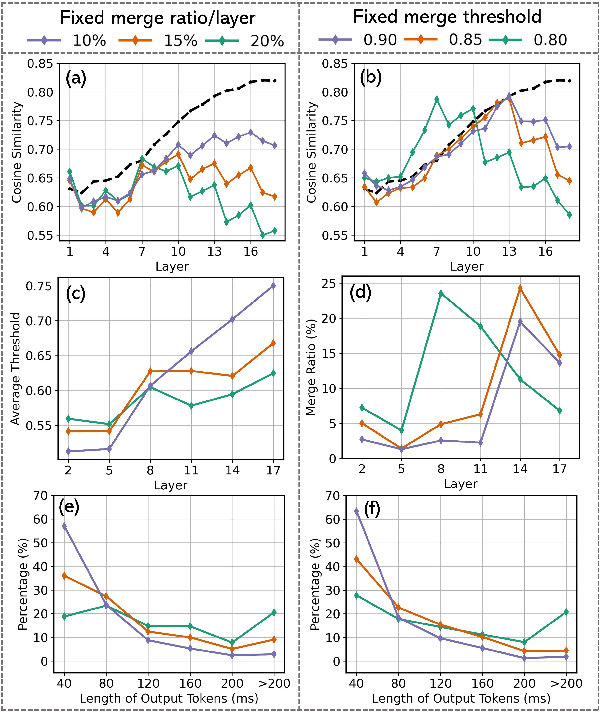
Recent end-to-end automatic speech recognition (ASR) systems often utilize a Transformer-based acoustic encoder that generates embedding at a high frame rate. However, this design is inefficient, particularly for long speech signals due to the quadratic computation of self-attention. To address this, we propose a new method, Adjacent Token Merging (A-ToMe), which gradually combines adjacent tokens with high similarity scores between their key values. In this way, the total time step could be reduced, and the inference of both the encoder and joint network is accelerated. Experiments on LibriSpeech show that our method can reduce 57% of tokens and improve the inference speed on GPU by 70% without any notable loss of accuracy. Additionally, we demonstrate that A-ToMe is also an effective solution to reduce tokens in long-form ASR, where the input speech consists of multiple utterances.
Towards Improved Room Impulse Response Estimation for Speech Recognition
Nov 08, 2022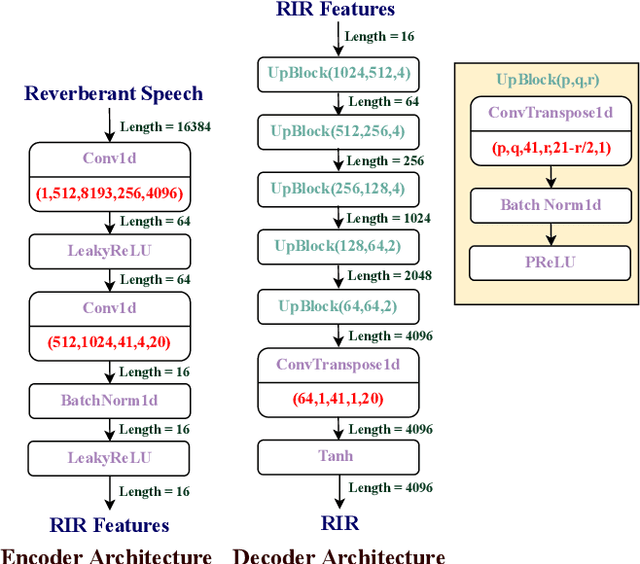
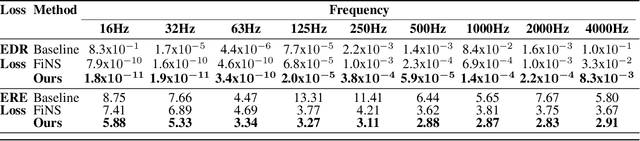
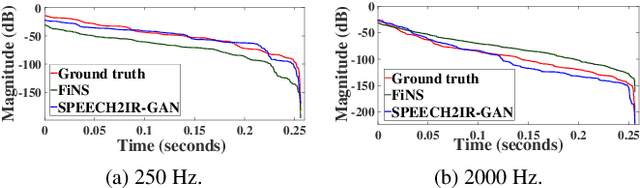
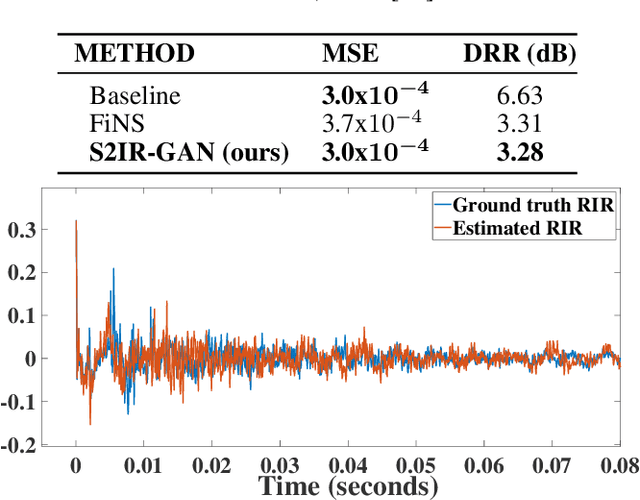
We propose to characterize and improve the performance of blind room impulse response (RIR) estimation systems in the context of a downstream application scenario, far-field automatic speech recognition (ASR). We first draw the connection between improved RIR estimation and improved ASR performance, as a means of evaluating neural RIR estimators. We then propose a GAN-based architecture that encodes RIR features from reverberant speech and constructs an RIR from the encoded features, and uses a novel energy decay relief loss to optimize for capturing energy-based properties of the input reverberant speech. We show that our model outperforms the state-of-the-art baselines on acoustic benchmarks (by 72% on the energy decay relief and 22% on an early-reflection energy metric), as well as in an ASR evaluation task (by 6.9% in word error rate).
Speech-dependent Modeling of Own Voice Transfer Characteristics for In-ear Microphones in Hearables
Sep 15, 2023Many hearables contain an in-ear microphone, which may be used to capture the own voice of its user in noisy environments. Since the in-ear microphone mostly records body-conducted speech due to ear canal occlusion, it suffers from band-limitation effects while only capturing a limited amount of external noise. To enhance the quality of the in-ear microphone signal using algorithms aiming at joint bandwidth extension, equalization, and noise reduction, it is desirable to have an accurate model of the own voice transfer characteristics between the entrance of the ear canal and the in-ear microphone. Such a model can be used, e.g., to simulate a large amount of in-ear recordings to train supervised learning-based algorithms. Since previous research on ear canal occlusion suggests that own voice transfer characteristics depend on speech content, in this contribution we propose a speech-dependent system identification model based on phoneme recognition. We assess the accuracy of simulating own voice speech by speech-dependent and speech-independent modeling and investigate how well modeling approaches are able to generalize to different talkers. Simulation results show that using the proposed speech-dependent model is preferable for simulating in-ear recordings compared to using a speech-independent model.
TEVR: Improving Speech Recognition by Token Entropy Variance Reduction
Jun 25, 2022



This paper presents TEVR, a speech recognition model designed to minimize the variation in token entropy w.r.t. to the language model. This takes advantage of the fact that if the language model will reliably and accurately predict a token anyway, then the acoustic model doesn't need to be accurate in recognizing it. We train German ASR models with 900 million parameters and show that on CommonVoice German, TEVR scores a very competitive 3.64% word error rate, which outperforms the best reported results by a relative 16.89% reduction in word error rate. We hope that releasing our fully trained speech recognition pipeline to the community will lead to privacy-preserving offline virtual assistants in the future.
A vector quantized masked autoencoder for speech emotion recognition
Apr 21, 2023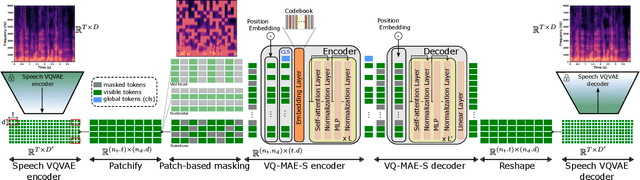
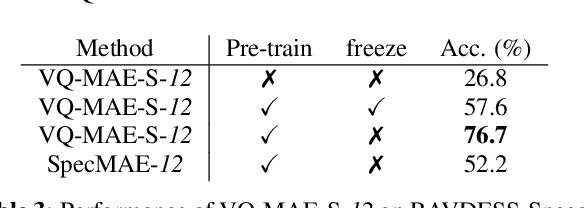

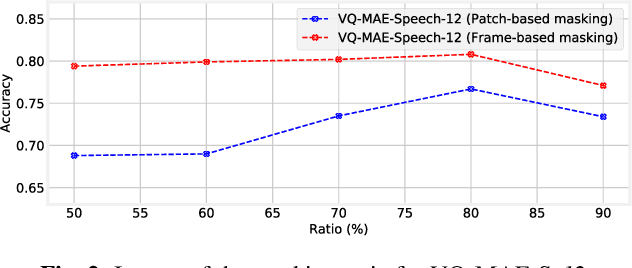
Recent years have seen remarkable progress in speech emotion recognition (SER), thanks to advances in deep learning techniques. However, the limited availability of labeled data remains a significant challenge in the field. Self-supervised learning has recently emerged as a promising solution to address this challenge. In this paper, we propose the vector quantized masked autoencoder for speech (VQ-MAE-S), a self-supervised model that is fine-tuned to recognize emotions from speech signals. The VQ-MAE-S model is based on a masked autoencoder (MAE) that operates in the discrete latent space of a vector-quantized variational autoencoder. Experimental results show that the proposed VQ-MAE-S model, pre-trained on the VoxCeleb2 dataset and fine-tuned on emotional speech data, outperforms an MAE working on the raw spectrogram representation and other state-of-the-art methods in SER.
Generating gender-ambiguous voices for privacy-preserving speech recognition
Jul 03, 2022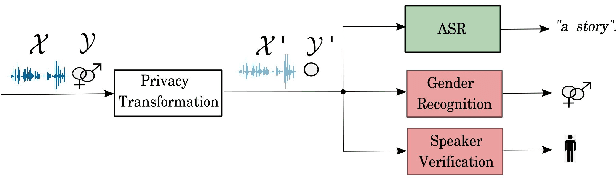
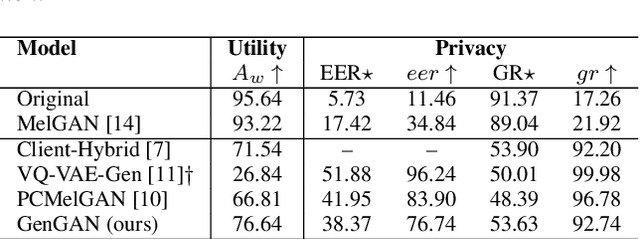
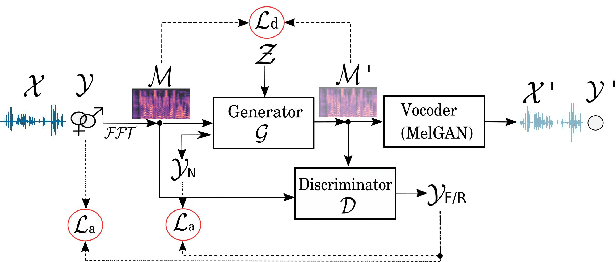
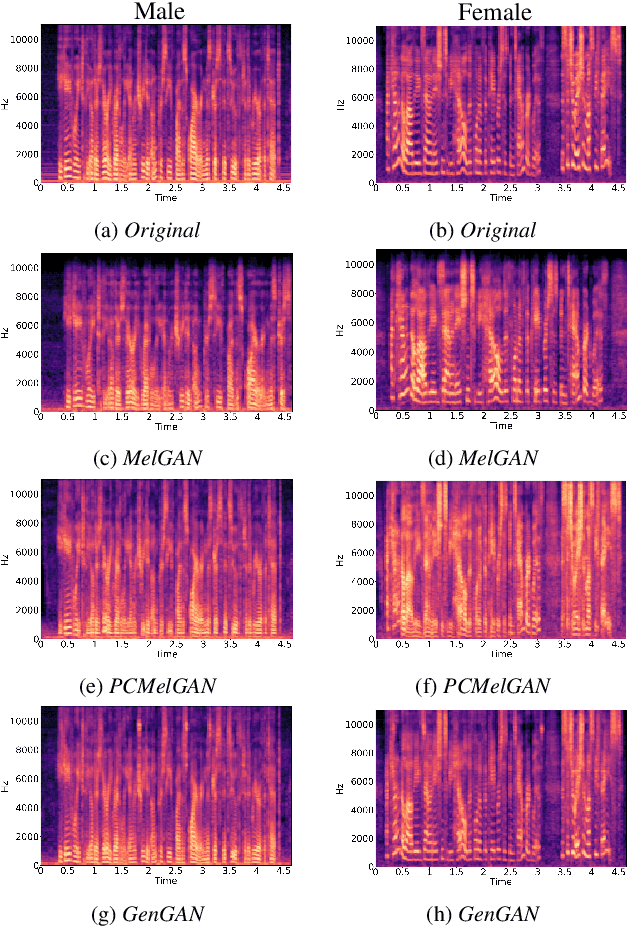
Our voice encodes a uniquely identifiable pattern which can be used to infer private attributes, such as gender or identity, that an individual might wish not to reveal when using a speech recognition service. To prevent attribute inference attacks alongside speech recognition tasks, we present a generative adversarial network, GenGAN, that synthesises voices that conceal the gender or identity of a speaker. The proposed network includes a generator with a U-Net architecture that learns to fool a discriminator. We condition the generator only on gender information and use an adversarial loss between signal distortion and privacy preservation. We show that GenGAN improves the trade-off between privacy and utility compared to privacy-preserving representation learning methods that consider gender information as a sensitive attribute to protect.