 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Pretraining Conformer with ASR or ASV for Anti-Spoofing Countermeasure
Jul 04, 2023
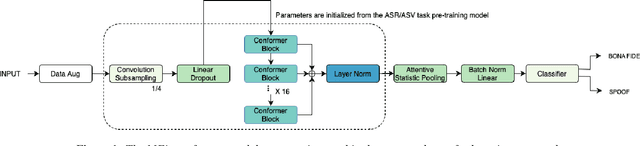
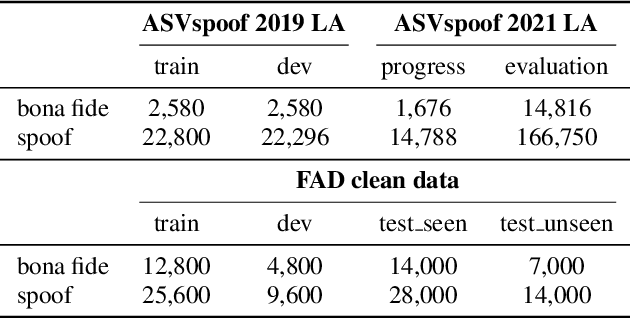
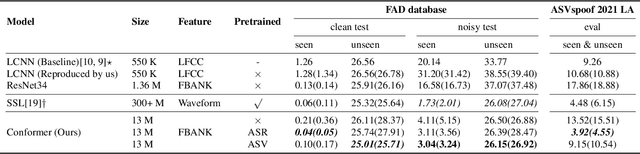
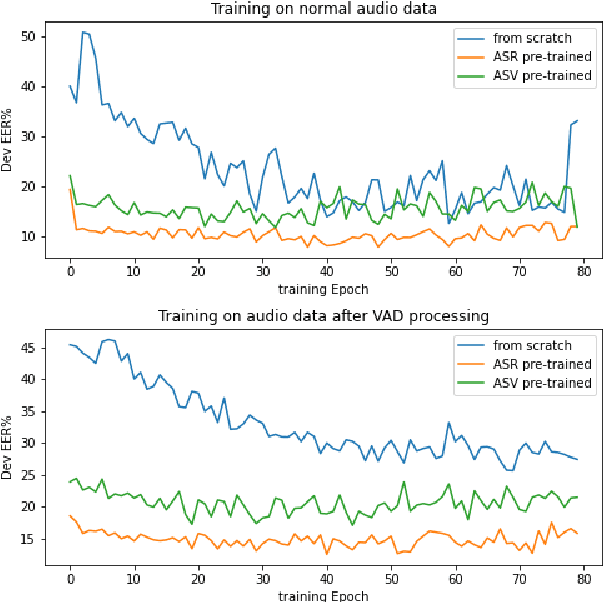
This paper introduces the Multi-scale Feature Aggregation Conformer (MFA-Conformer) structure for audio anti-spoofing countermeasure (CM). MFA-Conformer combines a convolutional neural networkbased on the Transformer, allowing it to aggregate global andlocal information. This may benefit the anti-spoofing CM system to capture the synthetic artifacts hidden both locally and globally. In addition, given the excellent performance of MFA Conformer on automatic speech recognition (ASR) and automatic speaker verification (ASV) tasks, we present a transfer learning method that utilizes pretrained Conformer models on ASR or ASV tasks to enhance the robustness of CM systems. The proposed method is evaluated on both Chinese and Englishs poofing detection databases. On the FAD clean set, the MFA-Conformer model pretrained on the ASR task achieves an EER of 0.038%, which dramatically outperforms the baseline. Moreover, experimental results demonstrate that proposed transfer learning method on Conformer is effective on pure speech segments after voice activity detection processing.
Whisper-KDQ: A Lightweight Whisper via Guided Knowledge Distillation and Quantization for Efficient ASR
May 18, 2023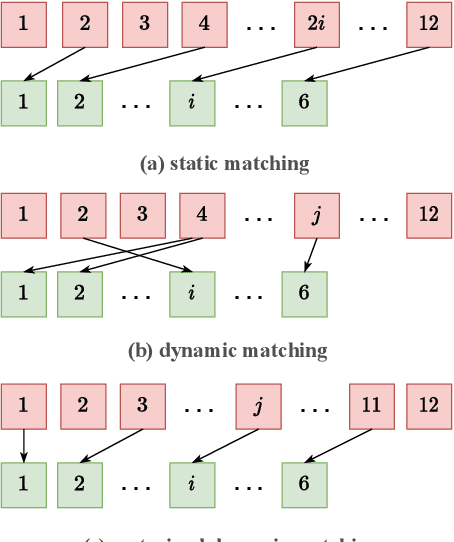
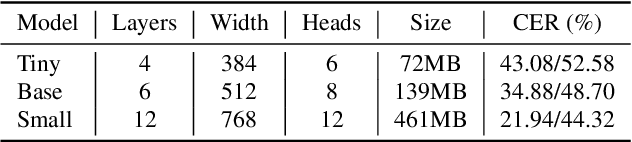
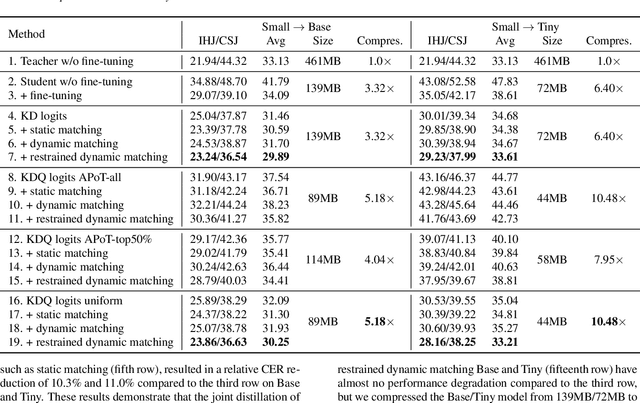
Due to the rapid development of computing hardware resources and the dramatic growth of data, pre-trained models in speech recognition, such as Whisper, have significantly improved the performance of speech recognition tasks. However, these models usually have a high computational overhead, making it difficult to execute effectively on resource-constrained devices. To speed up inference and reduce model size while maintaining performance, we propose a novel guided knowledge distillation and quantization for large pre-trained model Whisper. The student model selects distillation and quantization layers based on quantization loss and distillation loss, respectively. We compressed $\text{Whisper}_\text{small}$ to $\text{Whisper}_\text{base}$ and $\text{Whisper}_\text{tiny}$ levels, making $\text{Whisper}_\text{small}$ 5.18x/10.48x smaller, respectively. Moreover, compared to the original $\text{Whisper}_\text{base}$ and $\text{Whisper}_\text{tiny}$, there is also a relative character error rate~(CER) reduction of 11.3% and 14.0% for the new compressed model respectively.
Cross-Modal Mutual Learning for Cued Speech Recognition
Dec 02, 2022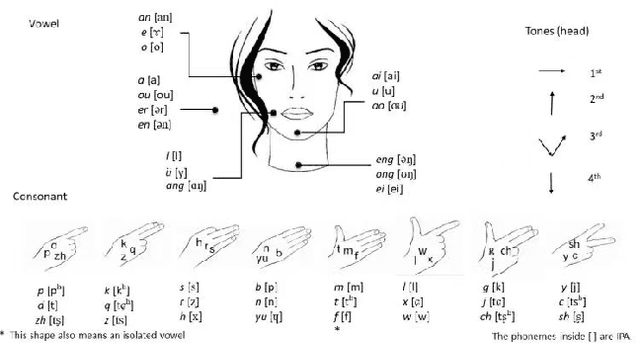
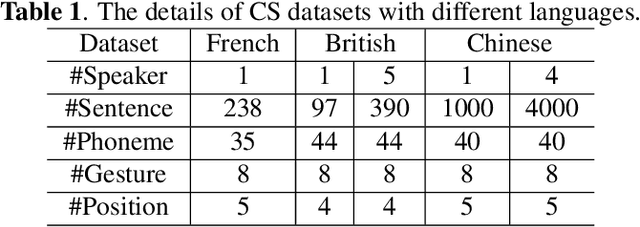
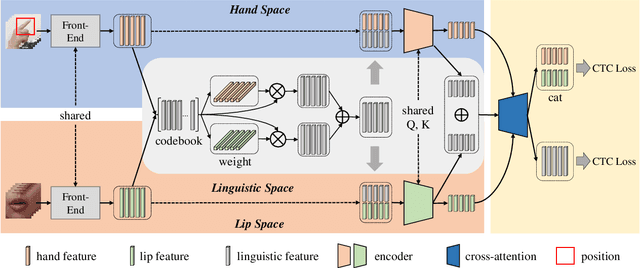
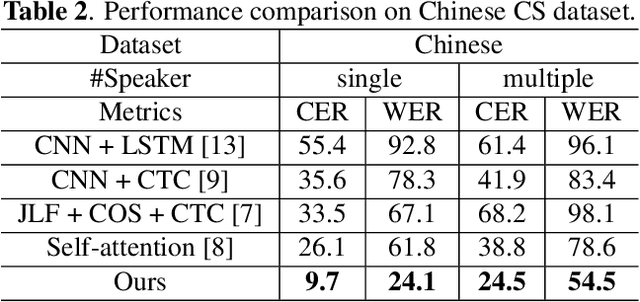
Automatic Cued Speech Recognition (ACSR) provides an intelligent human-machine interface for visual communications, where the Cued Speech (CS) system utilizes lip movements and hand gestures to code spoken language for hearing-impaired people. Previous ACSR approaches often utilize direct feature concatenation as the main fusion paradigm. However, the asynchronous modalities (\textit{i.e.}, lip, hand shape and hand position) in CS may cause interference for feature concatenation. To address this challenge, we propose a transformer based cross-modal mutual learning framework to prompt multi-modal interaction. Compared with the vanilla self-attention, our model forces modality-specific information of different modalities to pass through a modality-invariant codebook, collating linguistic representations for tokens of each modality. Then the shared linguistic knowledge is used to re-synchronize multi-modal sequences. Moreover, we establish a novel large-scale multi-speaker CS dataset for Mandarin Chinese. To our knowledge, this is the first work on ACSR for Mandarin Chinese. Extensive experiments are conducted for different languages (\textit{i.e.}, Chinese, French, and British English). Results demonstrate that our model exhibits superior recognition performance to the state-of-the-art by a large margin.
Accelerating Transducers through Adjacent Token Merging
Jun 28, 2023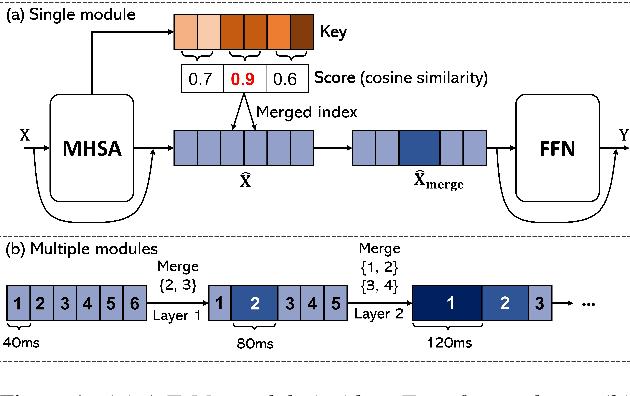
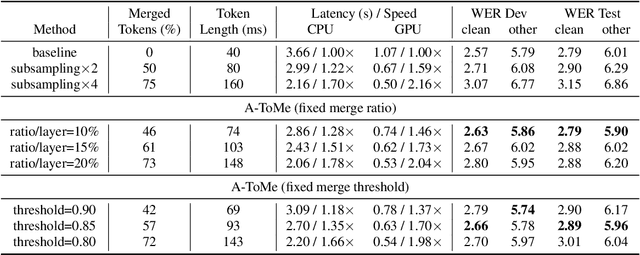
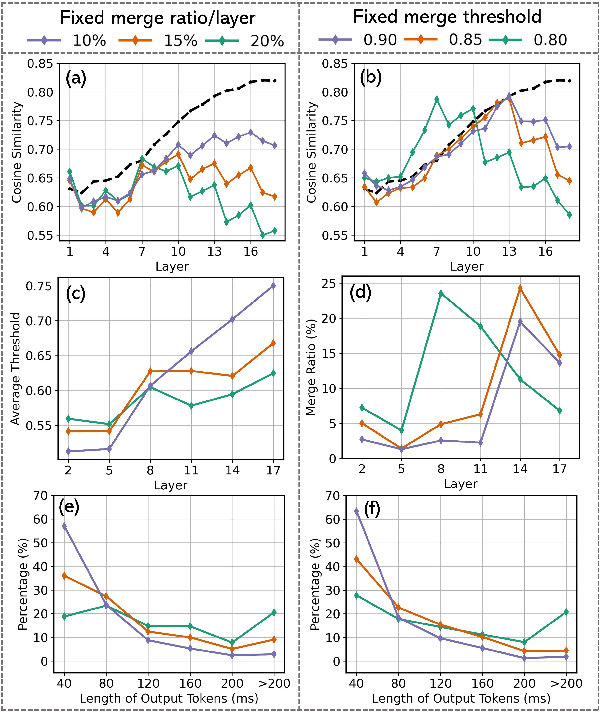
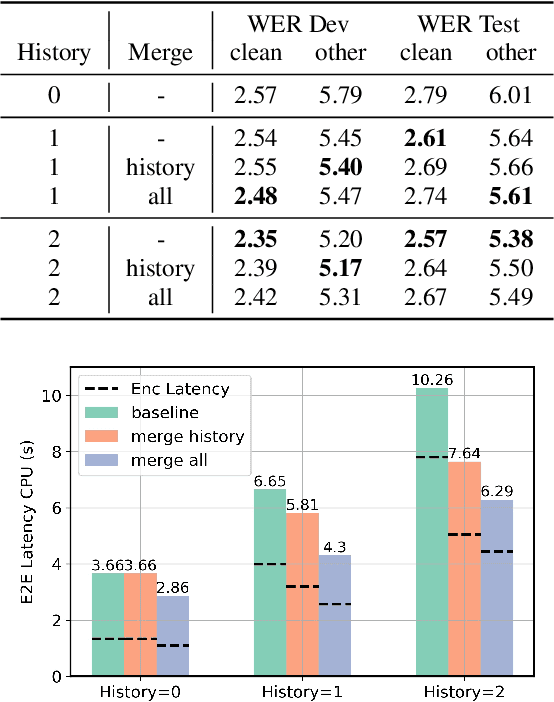
Recent end-to-end automatic speech recognition (ASR) systems often utilize a Transformer-based acoustic encoder that generates embedding at a high frame rate. However, this design is inefficient, particularly for long speech signals due to the quadratic computation of self-attention. To address this, we propose a new method, Adjacent Token Merging (A-ToMe), which gradually combines adjacent tokens with high similarity scores between their key values. In this way, the total time step could be reduced, and the inference of both the encoder and joint network is accelerated. Experiments on LibriSpeech show that our method can reduce 57% of tokens and improve the inference speed on GPU by 70% without any notable loss of accuracy. Additionally, we demonstrate that A-ToMe is also an effective solution to reduce tokens in long-form ASR, where the input speech consists of multiple utterances.
LyricWhiz: Robust Multilingual Zero-shot Lyrics Transcription by Whispering to ChatGPT
Jul 07, 2023

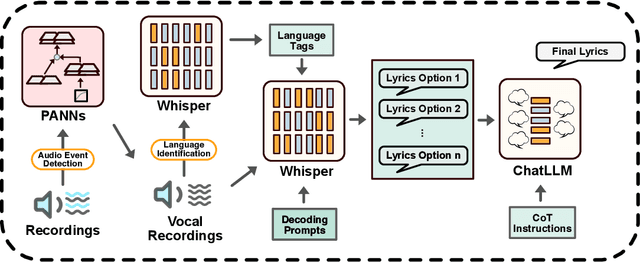
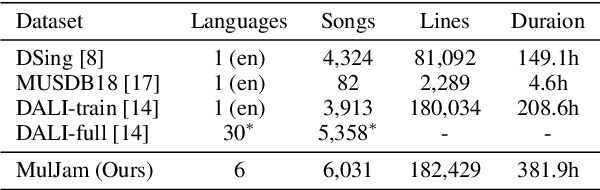
We introduce LyricWhiz, a robust, multilingual, and zero-shot automatic lyrics transcription method achieving state-of-the-art performance on various lyrics transcription datasets, even in challenging genres such as rock and metal. Our novel, training-free approach utilizes Whisper, a weakly supervised robust speech recognition model, and GPT-4, today's most performant chat-based large language model. In the proposed method, Whisper functions as the "ear" by transcribing the audio, while GPT-4 serves as the "brain," acting as an annotator with a strong performance for contextualized output selection and correction. Our experiments show that LyricWhiz significantly reduces Word Error Rate compared to existing methods in English and can effectively transcribe lyrics across multiple languages. Furthermore, we use LyricWhiz to create the first publicly available, large-scale, multilingual lyrics transcription dataset with a CC-BY-NC-SA copyright license, based on MTG-Jamendo, and offer a human-annotated subset for noise level estimation and evaluation. We anticipate that our proposed method and dataset will advance the development of multilingual lyrics transcription, a challenging and emerging task.
Blind Signal Dereverberation for Machine Speech Recognition
Sep 30, 2022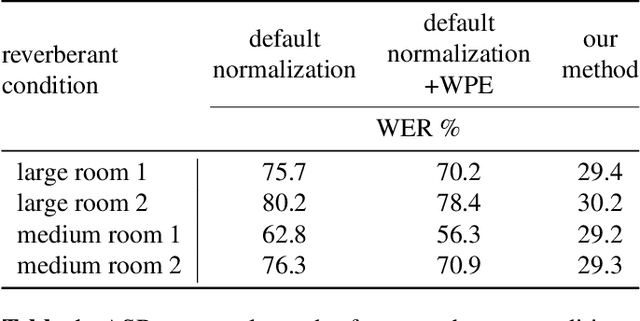
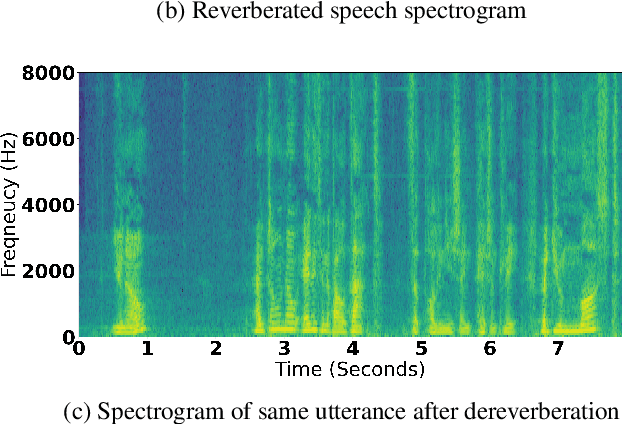
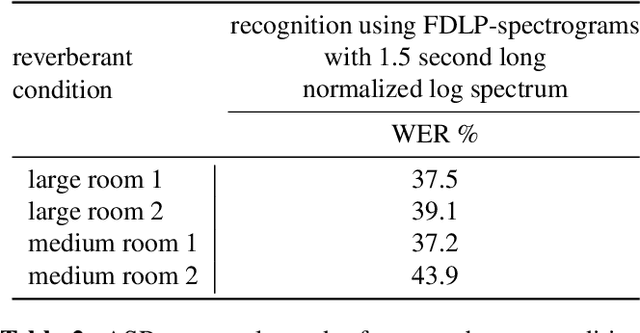
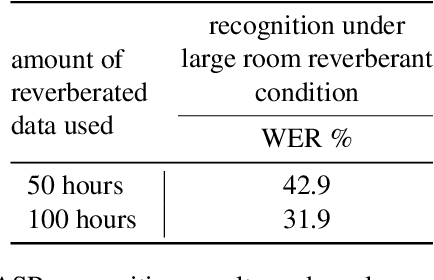
We present a method to remove unknown convolutive noise introduced to speech by reverberations of recording environments, utilizing some amount of training speech data from the reverberant environment, and any available non-reverberant speech data. Using Fourier transform computed over long temporal windows, which ideally cover the entire room impulse response, we convert room induced convolution to additions in the log spectral domain. Next, we compute a spectral normalization vector from statistics gathered over reverberated as well as over clean speech in the log spectral domain. During operation, this normalization vectors are used to alleviate reverberations from complex speech spectra recorded under the same reverberant conditions . Such dereverberated complex speech spectra are used to compute complex FDLP-spectrograms for use in automatic speech recognition.
Modeling Spoken Information Queries for Virtual Assistants: Open Problems, Challenges and Opportunities
Apr 25, 2023Virtual assistants are becoming increasingly important speech-driven Information Retrieval platforms that assist users with various tasks. We discuss open problems and challenges with respect to modeling spoken information queries for virtual assistants, and list opportunities where Information Retrieval methods and research can be applied to improve the quality of virtual assistant speech recognition. We discuss how query domain classification, knowledge graphs and user interaction data, and query personalization can be helpful to improve the accurate recognition of spoken information domain queries. Finally, we also provide a brief overview of current problems and challenges in speech recognition.
Don't Stop Self-Supervision: Accent Adaptation of Speech Representations via Residual Adapters
Jul 02, 2023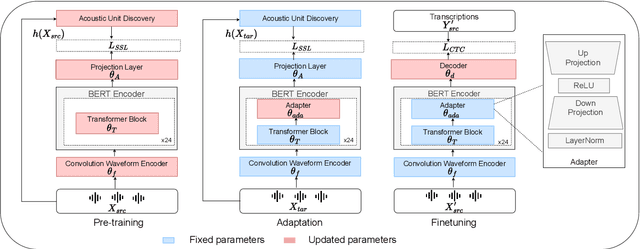
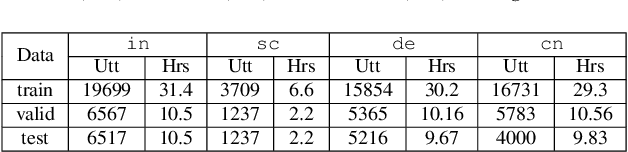
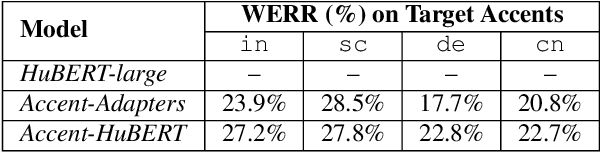
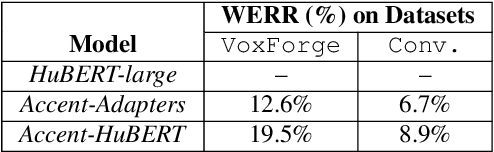
Speech representations learned in a self-supervised fashion from massive unlabeled speech corpora have been adapted successfully toward several downstream tasks. However, such representations may be skewed toward canonical data characteristics of such corpora and perform poorly on atypical, non-native accented speaker populations. With the state-of-the-art HuBERT model as a baseline, we propose and investigate self-supervised adaptation of speech representations to such populations in a parameter-efficient way via training accent-specific residual adapters. We experiment with 4 accents and choose automatic speech recognition (ASR) as the downstream task of interest. We obtain strong word error rate reductions (WERR) over HuBERT-large for all 4 accents, with a mean WERR of 22.7% with accent-specific adapters and a mean WERR of 25.1% if the entire encoder is accent-adapted. While our experiments utilize HuBERT and ASR as the downstream task, our proposed approach is both model and task-agnostic.
An Empirical Study and Improvement for Speech Emotion Recognition
Apr 08, 2023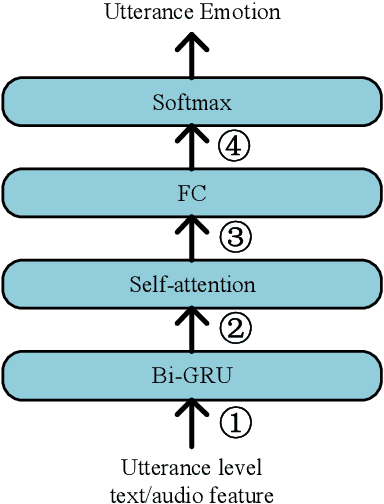

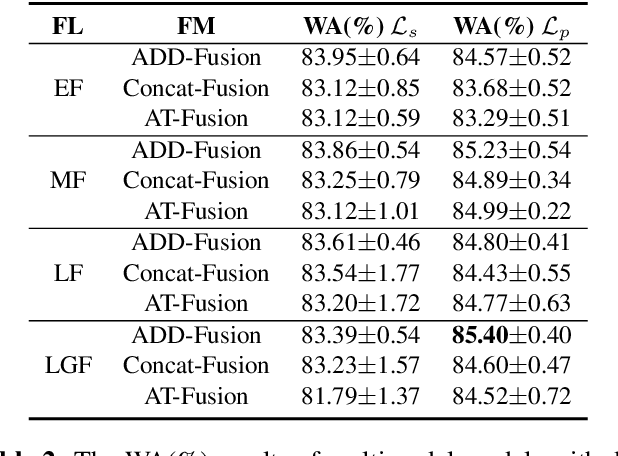
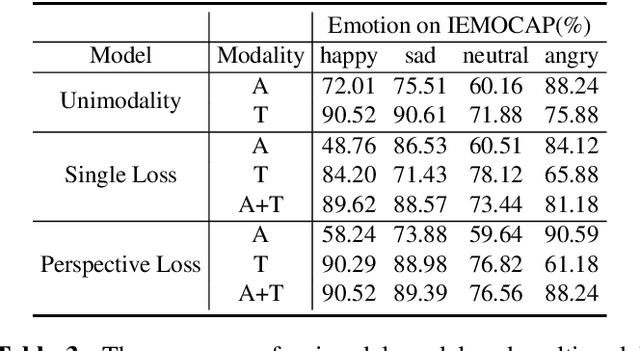
Multimodal speech emotion recognition aims to detect speakers' emotions from audio and text. Prior works mainly focus on exploiting advanced networks to model and fuse different modality information to facilitate performance, while neglecting the effect of different fusion strategies on emotion recognition. In this work, we consider a simple yet important problem: how to fuse audio and text modality information is more helpful for this multimodal task. Further, we propose a multimodal emotion recognition model improved by perspective loss. Empirical results show our method obtained new state-of-the-art results on the IEMOCAP dataset. The in-depth analysis explains why the improved model can achieve improvements and outperforms baselines.
TALCS: An Open-Source Mandarin-English Code-Switching Corpus and a Speech Recognition Baseline
Jun 27, 2022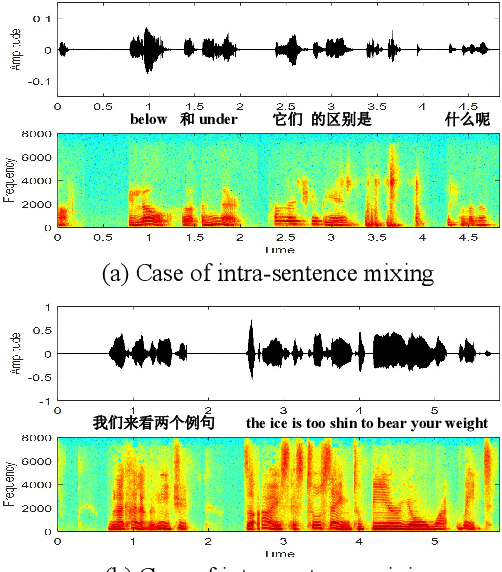
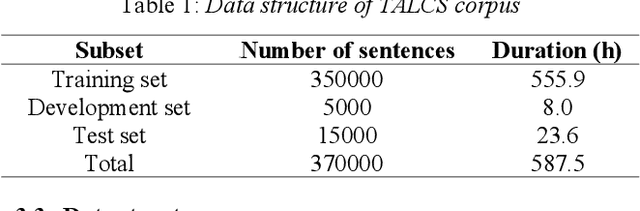
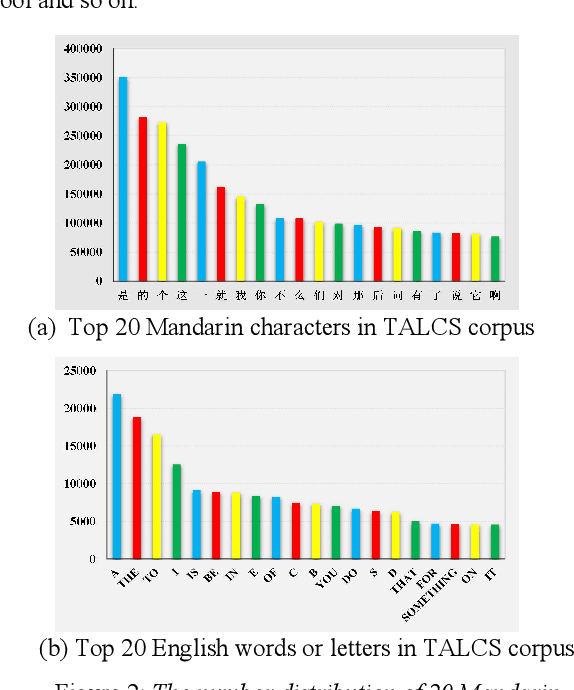
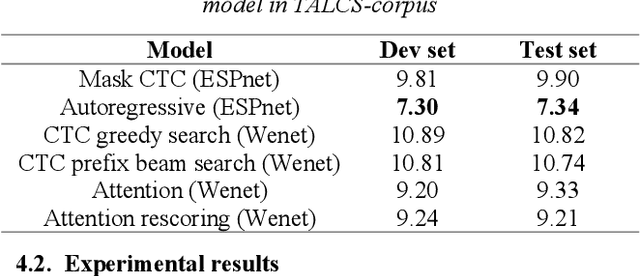
This paper introduces a new corpus of Mandarin-English code-switching speech recognition--TALCS corpus, suitable for training and evaluating code-switching speech recognition systems. TALCS corpus is derived from real online one-to-one English teaching scenes in TAL education group, which contains roughly 587 hours of speech sampled at 16 kHz. To our best knowledge, TALCS corpus is the largest well labeled Mandarin-English code-switching open source automatic speech recognition (ASR) dataset in the world. In this paper, we will introduce the recording procedure in detail, including audio capturing devices and corpus environments. And the TALCS corpus is freely available for download under the permissive license1. Using TALCS corpus, we conduct ASR experiments in two popular speech recognition toolkits to make a baseline system, including ESPnet and Wenet. The Mixture Error Rate (MER) performance in the two speech recognition toolkits is compared in TALCS corpus. The experimental results implies that the quality of audio recordings and transcriptions are promising and the baseline system is workable.