 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Kaggle Competition: Cantonese Audio-Visual Speech Recognition for In-car Commands
Jul 06, 2022

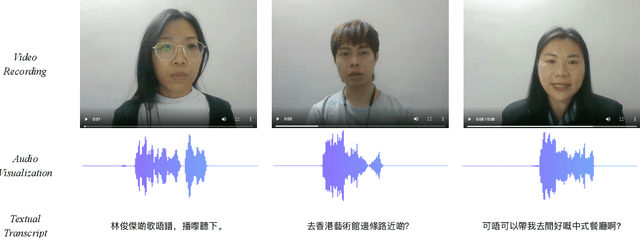

With the rise of deep learning and intelligent vehicles, the smart assistant has become an essential in-car component to facilitate driving and provide extra functionalities. In-car smart assistants should be able to process general as well as car-related commands and perform corresponding actions, which eases driving and improves safety. However, in this research field, most datasets are in major languages, such as English and Chinese. There is a huge data scarcity issue for low-resource languages, hindering the development of research and applications for broader communities. Therefore, it is crucial to have more benchmarks to raise awareness and motivate the research in low-resource languages. To mitigate this problem, we collect a new dataset, namely Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR), for in-car speech recognition in the Cantonese language with video and audio data. Together with it, we propose Cantonese Audio-Visual Speech Recognition for In-car Commands as a new challenge for the community to tackle low-resource speech recognition under in-car scenarios.
Bengali Common Voice Speech Dataset for Automatic Speech Recognition
Jun 29, 2022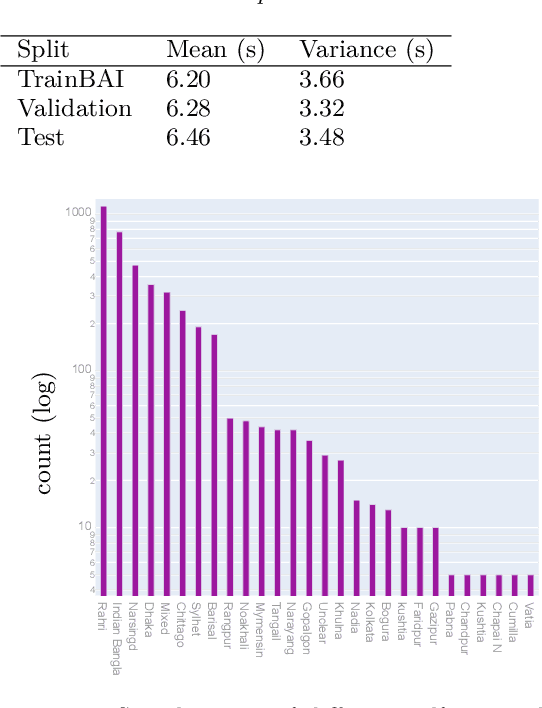
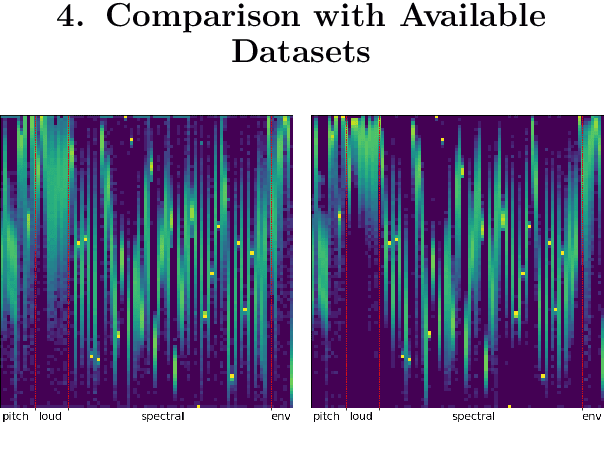

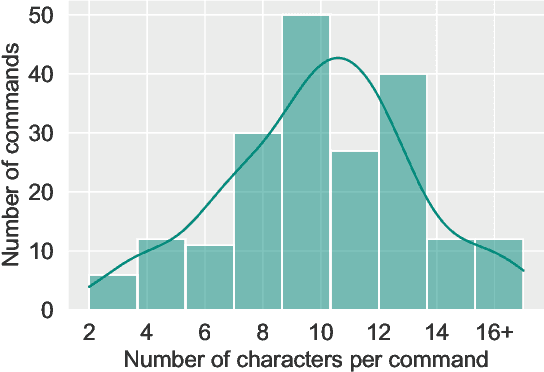
Bengali is one of the most spoken languages in the world with over 300 million speakers globally. Despite its popularity, research into the development of Bengali speech recognition systems is hindered due to the lack of diverse open-source datasets. As a way forward, we have crowdsourced the Bengali Common Voice Speech Dataset, which is a sentence-level automatic speech recognition corpus. Collected on the Mozilla Common Voice platform, the dataset is part of an ongoing campaign that has led to the collection of over 400 hours of data in 2 months and is growing rapidly. Our analysis shows that this dataset has more speaker, phoneme, and environmental diversity compared to the OpenSLR Bengali ASR dataset, the largest existing open-source Bengali speech dataset. We present insights obtained from the dataset and discuss key linguistic challenges that need to be addressed in future versions. Additionally, we report the current performance of a few Automatic Speech Recognition (ASR) algorithms and set a benchmark for future research.
DIVERSIFY: A General Framework for Time Series Out-of-distribution Detection and Generalization
Aug 04, 2023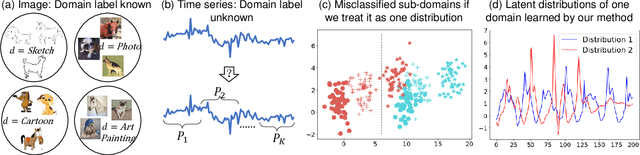
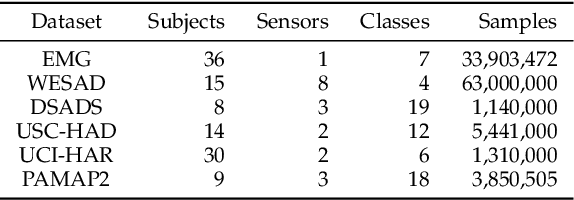

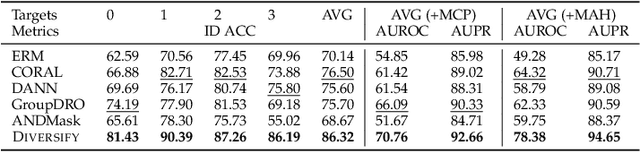
Time series remains one of the most challenging modalities in machine learning research. The out-of-distribution (OOD) detection and generalization on time series tend to suffer due to its non-stationary property, i.e., the distribution changes over time. The dynamic distributions inside time series pose great challenges to existing algorithms to identify invariant distributions since they mainly focus on the scenario where the domain information is given as prior knowledge. In this paper, we attempt to exploit subdomains within a whole dataset to counteract issues induced by non-stationary for generalized representation learning. We propose DIVERSIFY, a general framework, for OOD detection and generalization on dynamic distributions of time series. DIVERSIFY takes an iterative process: it first obtains the "worst-case" latent distribution scenario via adversarial training, then reduces the gap between these latent distributions. We implement DIVERSIFY via combining existing OOD detection methods according to either extracted features or outputs of models for detection while we also directly utilize outputs for classification. In addition, theoretical insights illustrate that DIVERSIFY is theoretically supported. Extensive experiments are conducted on seven datasets with different OOD settings across gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition. Qualitative and quantitative results demonstrate that DIVERSIFY learns more generalized features and significantly outperforms other baselines.
Automatic Speech recognition for Speech Assessment of Preschool Children
Mar 24, 2022
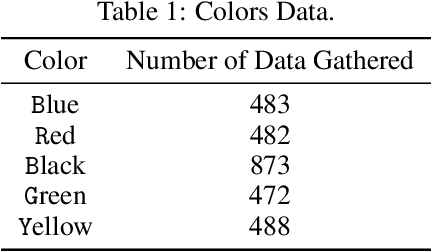

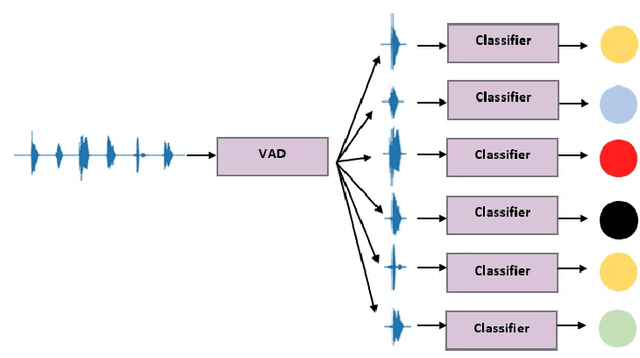
The acoustic and linguistic features of preschool speech are investigated in this study to design an automated speech recognition (ASR) system. Acoustic fluctuation has been highlighted as a significant barrier to developing high-performance ASR applications for youngsters. Because of the epidemic, preschool speech assessment should be conducted online. Accordingly, there is a need for an automatic speech recognition system. We were confronted with new challenges in our cognitive system, including converting meaningless words from speech to text and recognizing word sequence. After testing and experimenting with several models we obtained a 3.1\% phoneme error rate in Persian. Wav2Vec 2.0 is a paradigm that could be used to build a robust end-to-end speech recognition system.
Toward Fairness in Speech Recognition: Discovery and mitigation of performance disparities
Jul 22, 2022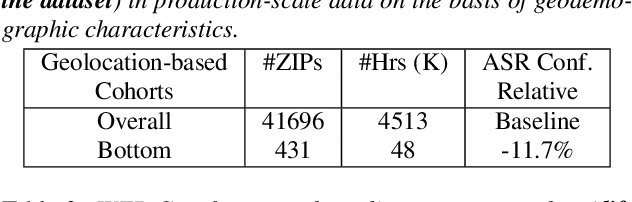
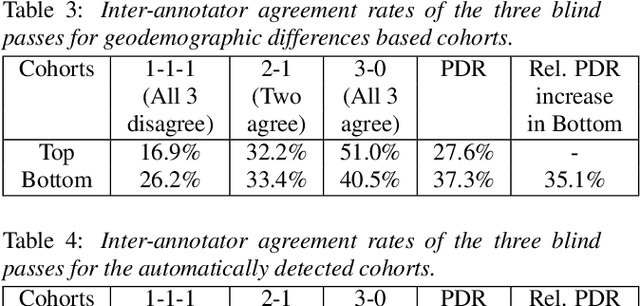
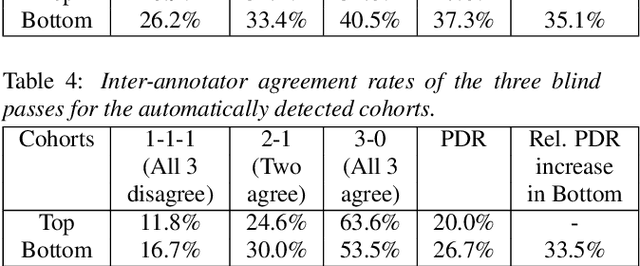

As for other forms of AI, speech recognition has recently been examined with respect to performance disparities across different user cohorts. One approach to achieve fairness in speech recognition is to (1) identify speaker cohorts that suffer from subpar performance and (2) apply fairness mitigation measures targeting the cohorts discovered. In this paper, we report on initial findings with both discovery and mitigation of performance disparities using data from a product-scale AI assistant speech recognition system. We compare cohort discovery based on geographic and demographic information to a more scalable method that groups speakers without human labels, using speaker embedding technology. For fairness mitigation, we find that oversampling of underrepresented cohorts, as well as modeling speaker cohort membership by additional input variables, reduces the gap between top- and bottom-performing cohorts, without deteriorating overall recognition accuracy.
Emphasizing Unseen Words: New Vocabulary Acquisition for End-to-End Speech Recognition
Feb 21, 2023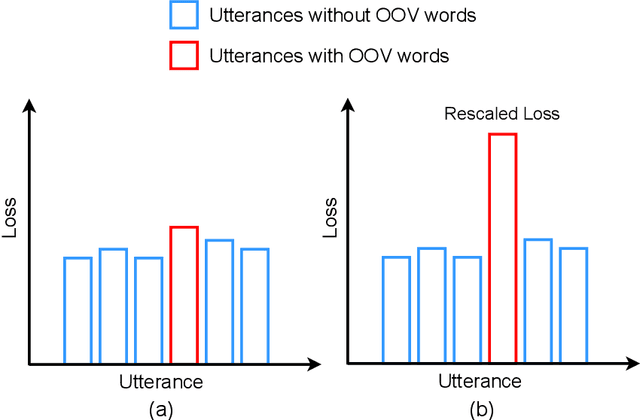
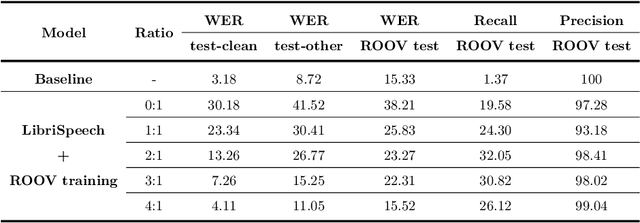
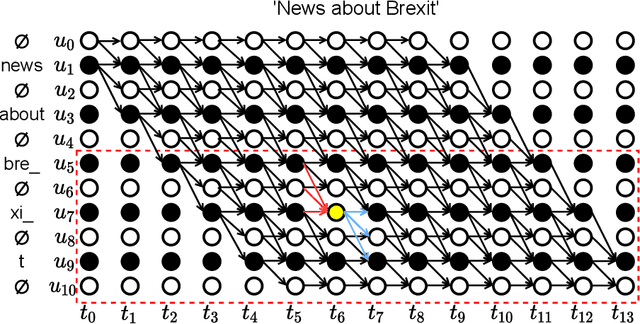
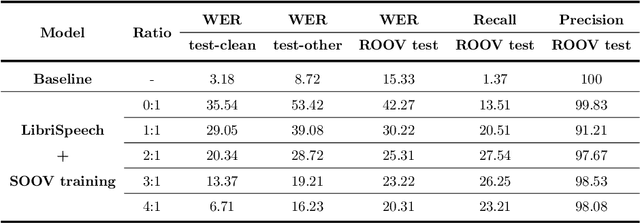
Due to the dynamic nature of human language, automatic speech recognition (ASR) systems need to continuously acquire new vocabulary. Out-Of-Vocabulary (OOV) words, such as trending words and new named entities, pose problems to modern ASR systems that require long training times to adapt their large numbers of parameters. Different from most previous research focusing on language model post-processing, we tackle this problem on an earlier processing level and eliminate the bias in acoustic modeling to recognize OOV words acoustically. We propose to generate OOV words using text-to-speech systems and to rescale losses to encourage neural networks to pay more attention to OOV words. Specifically, we enlarge the classification loss used for training neural networks' parameters of utterances containing OOV words (sentence-level), or rescale the gradient used for back-propagation for OOV words (word-level), when fine-tuning a previously trained model on synthetic audio. To overcome catastrophic forgetting, we also explore the combination of loss rescaling and model regularization, i.e. L2 regularization and elastic weight consolidation (EWC). Compared with previous methods that just fine-tune synthetic audio with EWC, the experimental results on the LibriSpeech benchmark reveal that our proposed loss rescaling approach can achieve significant improvement on the recall rate with only a slight decrease on word error rate. Moreover, word-level rescaling is more stable than utterance-level rescaling and leads to higher recall rates and precision on OOV word recognition. Furthermore, our proposed combined loss rescaling and weight consolidation methods can support continual learning of an ASR system.
MSM-VC: High-fidelity Source Style Transfer for Non-Parallel Voice Conversion by Multi-scale Style Modeling
Sep 03, 2023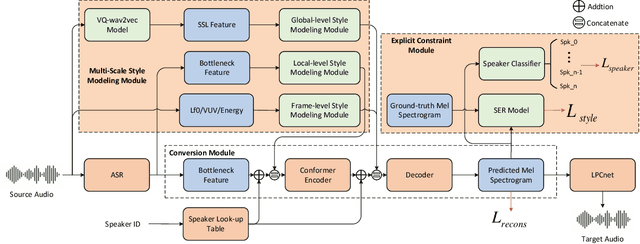
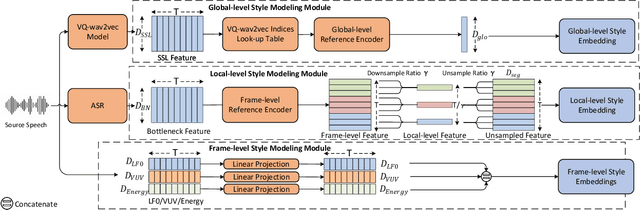
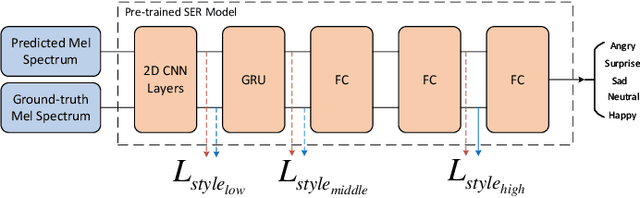
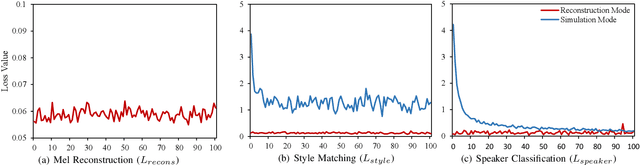
In addition to conveying the linguistic content from source speech to converted speech, maintaining the speaking style of source speech also plays an important role in the voice conversion (VC) task, which is essential in many scenarios with highly expressive source speech, such as dubbing and data augmentation. Previous work generally took explicit prosodic features or fixed-length style embedding extracted from source speech to model the speaking style of source speech, which is insufficient to achieve comprehensive style modeling and target speaker timbre preservation. Inspired by the style's multi-scale nature of human speech, a multi-scale style modeling method for the VC task, referred to as MSM-VC, is proposed in this paper. MSM-VC models the speaking style of source speech from different levels. To effectively convey the speaking style and meanwhile prevent timbre leakage from source speech to converted speech, each level's style is modeled by specific representation. Specifically, prosodic features, pre-trained ASR model's bottleneck features, and features extracted by a model trained with a self-supervised strategy are adopted to model the frame, local, and global-level styles, respectively. Besides, to balance the performance of source style modeling and target speaker timbre preservation, an explicit constraint module consisting of a pre-trained speech emotion recognition model and a speaker classifier is introduced to MSM-VC. This explicit constraint module also makes it possible to simulate the style transfer inference process during the training to improve the disentanglement ability and alleviate the mismatch between training and inference. Experiments performed on the highly expressive speech corpus demonstrate that MSM-VC is superior to the state-of-the-art VC methods for modeling source speech style while maintaining good speech quality and speaker similarity.
Predict-and-Update Network: Audio-Visual Speech Recognition Inspired by Human Speech Perception
Sep 05, 2022
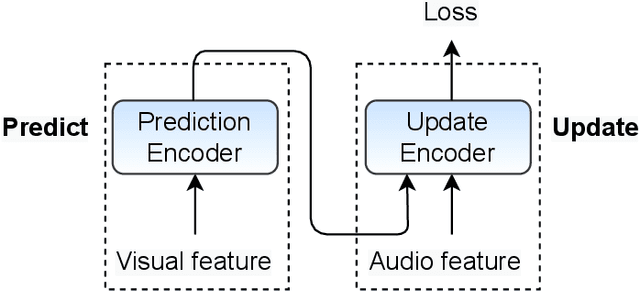
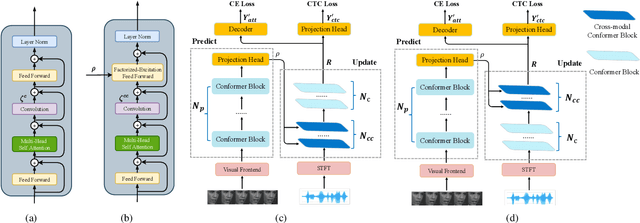
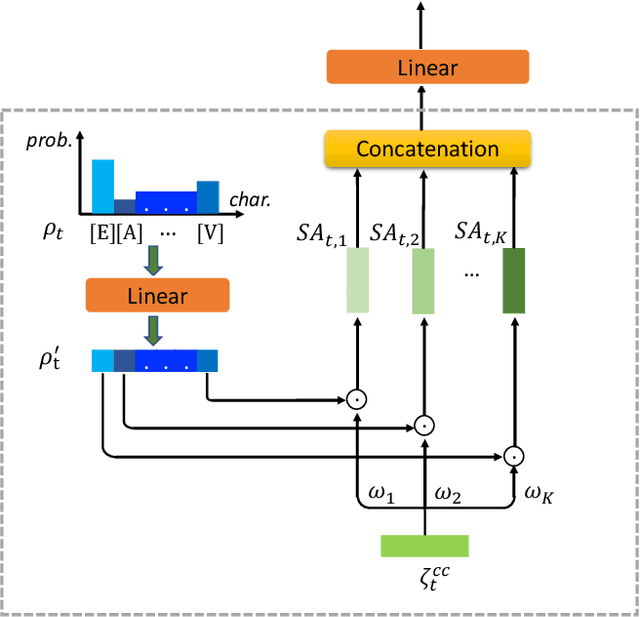
Audio and visual signals complement each other in human speech perception, so do they in speech recognition. The visual hint is less evident than the acoustic hint, but more robust in a complex acoustic environment, as far as speech perception is concerned. It remains a challenge how we effectively exploit the interaction between audio and visual signals for automatic speech recognition. There have been studies to exploit visual signals as redundant or complementary information to audio input in a synchronous manner. Human studies suggest that visual signal primes the listener in advance as to when and on which frequency to attend to. We propose a Predict-and-Update Network (P&U net), to simulate such a visual cueing mechanism for Audio-Visual Speech Recognition (AVSR). In particular, we first predict the character posteriors of the spoken words, i.e. the visual embedding, based on the visual signals. The audio signal is then conditioned on the visual embedding via a novel cross-modal Conformer, that updates the character posteriors. We validate the effectiveness of the visual cueing mechanism through extensive experiments. The proposed P&U net outperforms the state-of-the-art AVSR methods on both LRS2-BBC and LRS3-BBC datasets, with the relative reduced Word Error Rate (WER)s exceeding 10% and 40% under clean and noisy conditions, respectively.
Can Generative Large Language Models Perform ASR Error Correction?
Jul 09, 2023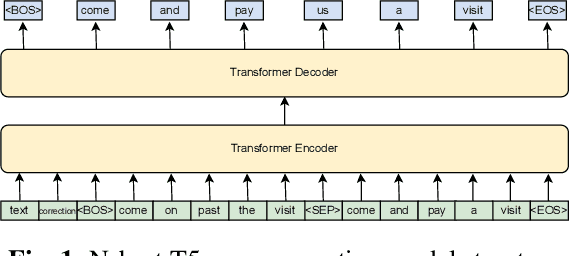
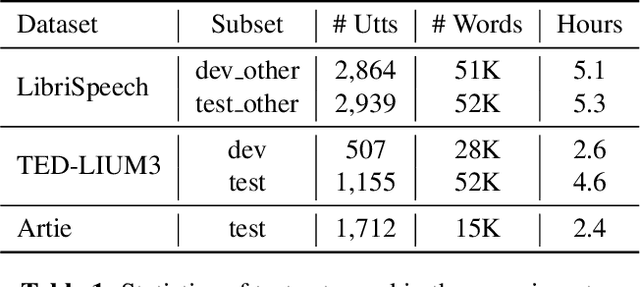
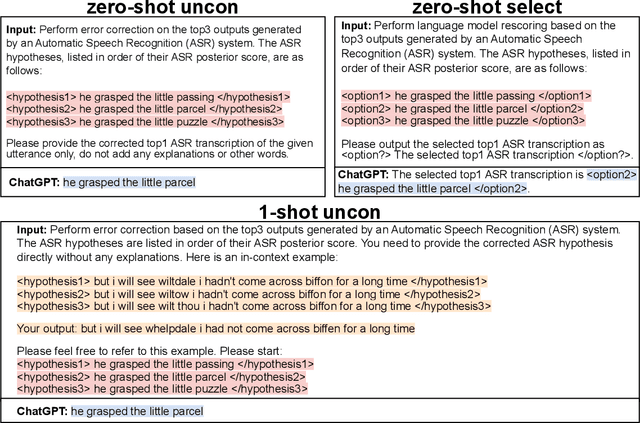
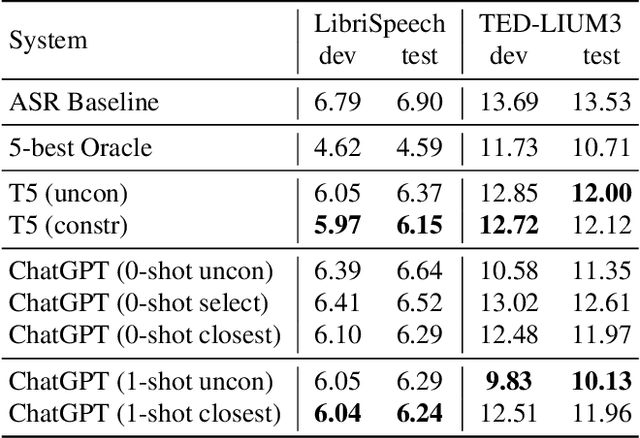
ASR error correction continues to serve as an important part of post-processing for speech recognition systems. Traditionally, these models are trained with supervised training using the decoding results of the underlying ASR system and the reference text. This approach is computationally intensive and the model needs to be re-trained when switching the underlying ASR model. Recent years have seen the development of large language models and their ability to perform natural language processing tasks in a zero-shot manner. In this paper, we take ChatGPT as an example to examine its ability to perform ASR error correction in the zero-shot or 1-shot settings. We use the ASR N-best list as model input and propose unconstrained error correction and N-best constrained error correction methods. Results on a Conformer-Transducer model and the pre-trained Whisper model show that we can largely improve the ASR system performance with error correction using the powerful ChatGPT model.
Using joint training speaker encoder with consistency loss to achieve cross-lingual voice conversion and expressive voice conversion
Jul 01, 2023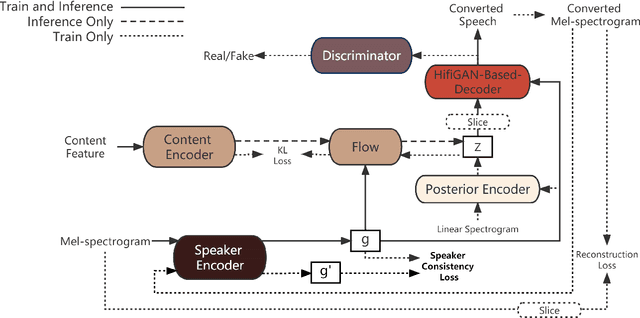


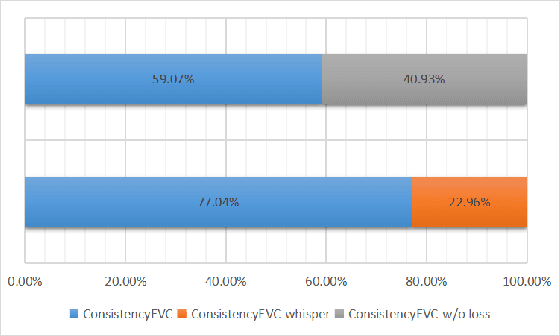
Voice conversion systems have made significant advancements in terms of naturalness and similarity in common voice conversion tasks. However, their performance in more complex tasks such as cross-lingual voice conversion and expressive voice conversion remains imperfect. In this study, we propose a novel approach that combines a jointly trained speaker encoder and content features extracted from the cross-lingual speech recognition model Whisper to achieve high-quality cross-lingual voice conversion. Additionally, we introduce a speaker consistency loss to the joint encoder, which improves the similarity between the converted speech and the reference speech. To further explore the capabilities of the joint speaker encoder, we use the phonetic posteriorgram as the content feature, which enables the model to effectively reproduce both the speaker characteristics and the emotional aspects of the reference speech.