 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
RedPenNet for Grammatical Error Correction: Outputs to Tokens, Attentions to Spans
Sep 19, 2023
The text editing tasks, including sentence fusion, sentence splitting and rephrasing, text simplification, and Grammatical Error Correction (GEC), share a common trait of dealing with highly similar input and output sequences. This area of research lies at the intersection of two well-established fields: (i) fully autoregressive sequence-to-sequence approaches commonly used in tasks like Neural Machine Translation (NMT) and (ii) sequence tagging techniques commonly used to address tasks such as Part-of-speech tagging, Named-entity recognition (NER), and similar. In the pursuit of a balanced architecture, researchers have come up with numerous imaginative and unconventional solutions, which we're discussing in the Related Works section. Our approach to addressing text editing tasks is called RedPenNet and is aimed at reducing architectural and parametric redundancies presented in specific Sequence-To-Edits models, preserving their semi-autoregressive advantages. Our models achieve $F_{0.5}$ scores of 77.60 on the BEA-2019 (test), which can be considered as state-of-the-art the only exception for system combination and 67.71 on the UAGEC+Fluency (test) benchmarks. This research is being conducted in the context of the UNLP 2023 workshop, where it was presented as a paper as a paper for the Shared Task in Grammatical Error Correction (GEC) for Ukrainian. This study aims to apply the RedPenNet approach to address the GEC problem in the Ukrainian language.
Personalization of CTC Speech Recognition Models
Oct 18, 2022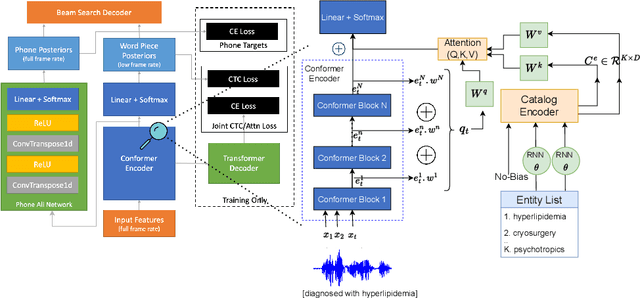
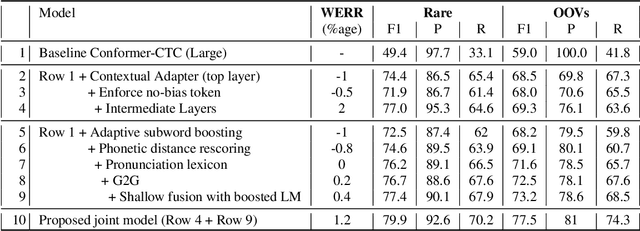
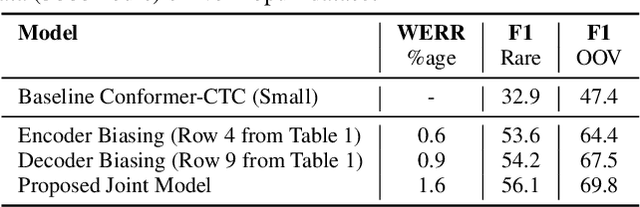
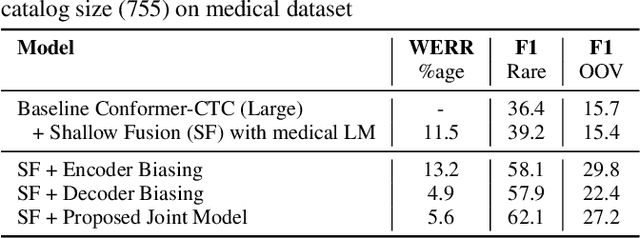
End-to-end speech recognition models trained using joint Connectionist Temporal Classification (CTC)-Attention loss have gained popularity recently. In these models, a non-autoregressive CTC decoder is often used at inference time due to its speed and simplicity. However, such models are hard to personalize because of their conditional independence assumption that prevents output tokens from previous time steps to influence future predictions. To tackle this, we propose a novel two-way approach that first biases the encoder with attention over a predefined list of rare long-tail and out-of-vocabulary (OOV) words and then uses dynamic boosting and phone alignment network during decoding to further bias the subword predictions. We evaluate our approach on open-source VoxPopuli and in-house medical datasets to showcase a 60% improvement in F1 score on domain-specific rare words over a strong CTC baseline.
Learning Robust Self-attention Features for Speech Emotion Recognition with Label-adaptive Mixup
May 07, 2023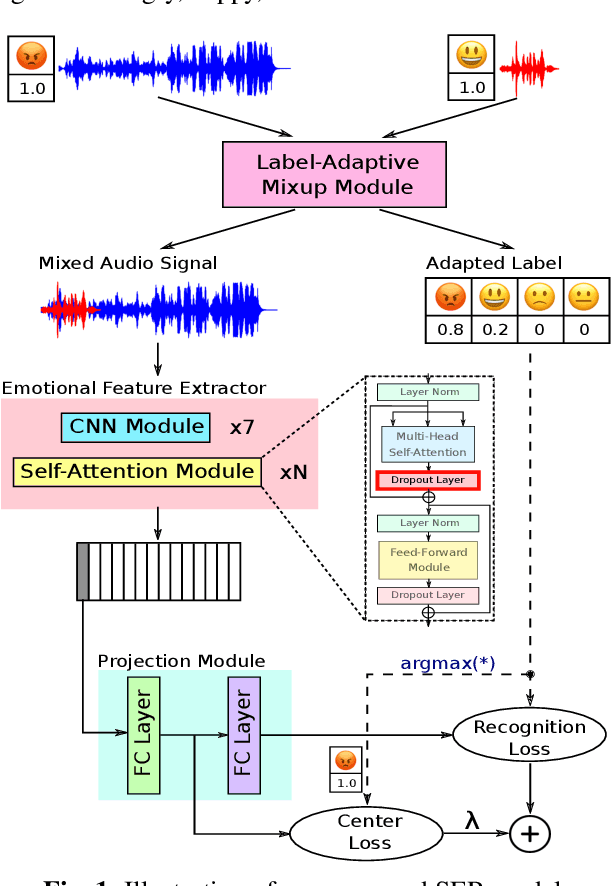
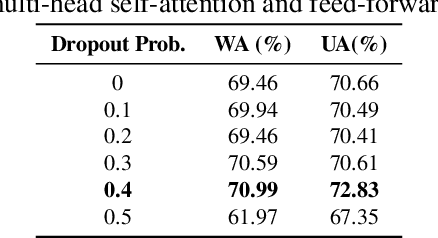
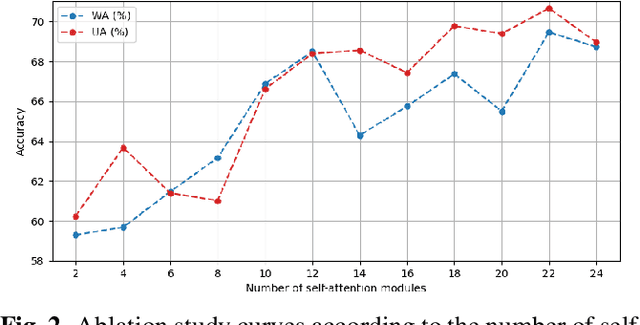

Speech Emotion Recognition (SER) is to recognize human emotions in a natural verbal interaction scenario with machines, which is considered as a challenging problem due to the ambiguous human emotions. Despite the recent progress in SER, state-of-the-art models struggle to achieve a satisfactory performance. We propose a self-attention based method with combined use of label-adaptive mixup and center loss. By adapting label probabilities in mixup and fitting center loss to the mixup training scheme, our proposed method achieves a superior performance to the state-of-the-art methods.
A Deep Dive into the Disparity of Word Error Rates Across Thousands of NPTEL MOOC Videos
Jul 20, 2023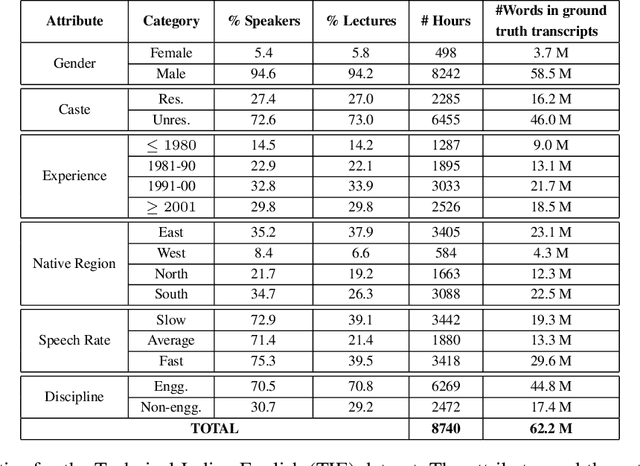
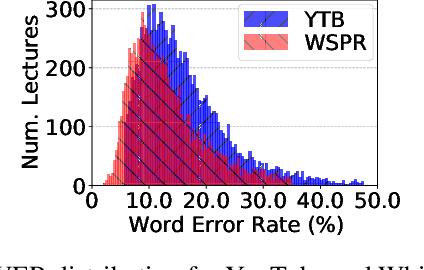
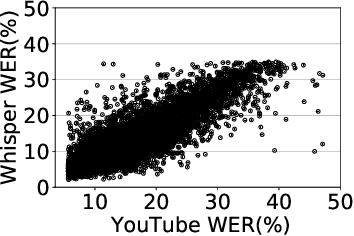
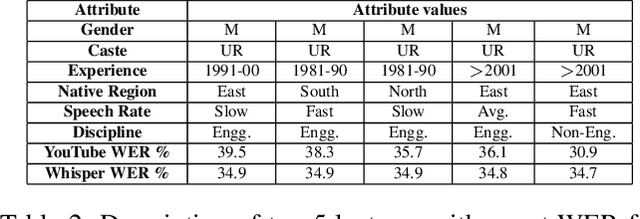
Automatic speech recognition (ASR) systems are designed to transcribe spoken language into written text and find utility in a variety of applications including voice assistants and transcription services. However, it has been observed that state-of-the-art ASR systems which deliver impressive benchmark results, struggle with speakers of certain regions or demographics due to variation in their speech properties. In this work, we describe the curation of a massive speech dataset of 8740 hours consisting of $\sim9.8$K technical lectures in the English language along with their transcripts delivered by instructors representing various parts of Indian demography. The dataset is sourced from the very popular NPTEL MOOC platform. We use the curated dataset to measure the existing disparity in YouTube Automatic Captions and OpenAI Whisper model performance across the diverse demographic traits of speakers in India. While there exists disparity due to gender, native region, age and speech rate of speakers, disparity based on caste is non-existent. We also observe statistically significant disparity across the disciplines of the lectures. These results indicate the need of more inclusive and robust ASR systems and more representational datasets for disparity evaluation in them.
MASR: Metadata Aware Speech Representation
Jul 20, 2023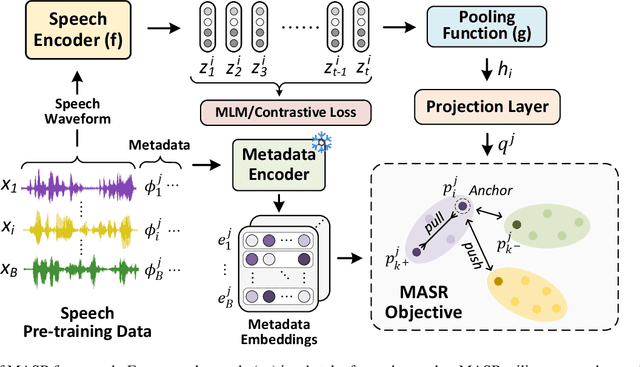
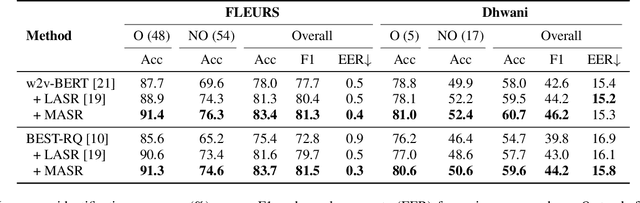
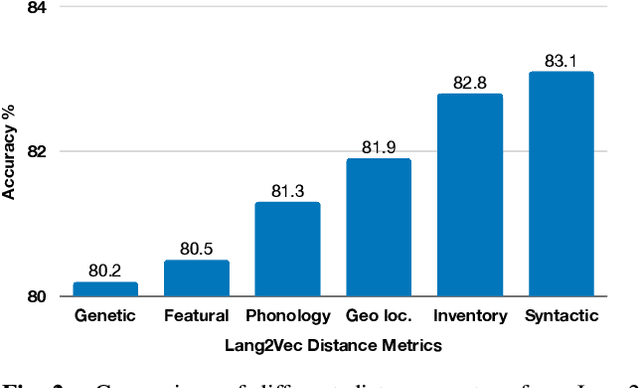

In the recent years, speech representation learning is constructed primarily as a self-supervised learning (SSL) task, using the raw audio signal alone, while ignoring the side-information that is often available for a given speech recording. In this paper, we propose MASR, a Metadata Aware Speech Representation learning framework, which addresses the aforementioned limitations. MASR enables the inclusion of multiple external knowledge sources to enhance the utilization of meta-data information. The external knowledge sources are incorporated in the form of sample-level pair-wise similarity matrices that are useful in a hard-mining loss. A key advantage of the MASR framework is that it can be combined with any choice of SSL method. Using MASR representations, we perform evaluations on several downstream tasks such as language identification, speech recognition and other non-semantic tasks such as speaker and emotion recognition. In these experiments, we illustrate significant performance improvements for the MASR over other established benchmarks. We perform a detailed analysis on the language identification task to provide insights on how the proposed loss function enables the representations to separate closely related languages.
Adaptive Sparse and Monotonic Attention for Transformer-based Automatic Speech Recognition
Sep 30, 2022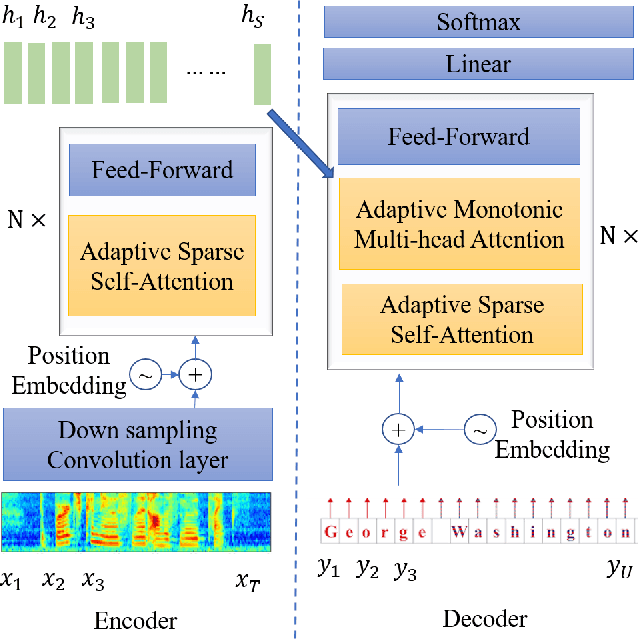
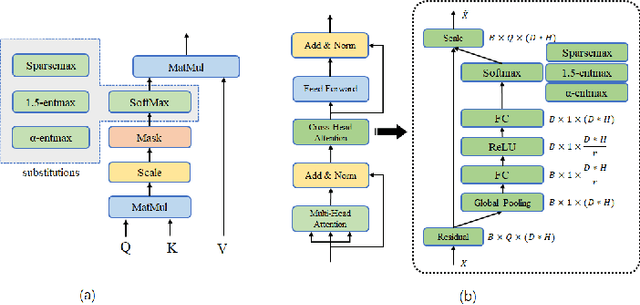
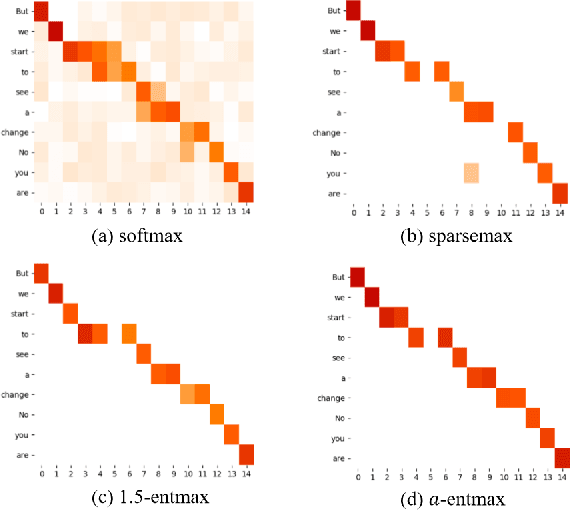
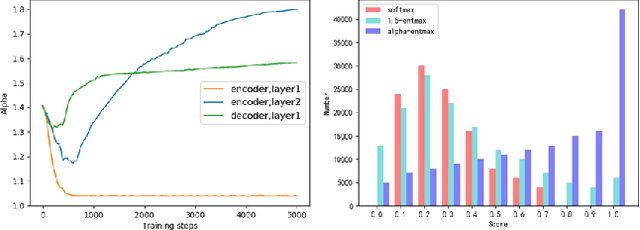
The Transformer architecture model, based on self-attention and multi-head attention, has achieved remarkable success in offline end-to-end Automatic Speech Recognition (ASR). However, self-attention and multi-head attention cannot be easily applied for streaming or online ASR. For self-attention in Transformer ASR, the softmax normalization function-based attention mechanism makes it impossible to highlight important speech information. For multi-head attention in Transformer ASR, it is not easy to model monotonic alignments in different heads. To overcome these two limits, we integrate sparse attention and monotonic attention into Transformer-based ASR. The sparse mechanism introduces a learned sparsity scheme to enable each self-attention structure to fit the corresponding head better. The monotonic attention deploys regularization to prune redundant heads for the multi-head attention structure. The experiments show that our method can effectively improve the attention mechanism on widely used benchmarks of speech recognition.
Learning Multi-modal Representations by Watching Hundreds of Surgical Video Lectures
Jul 27, 2023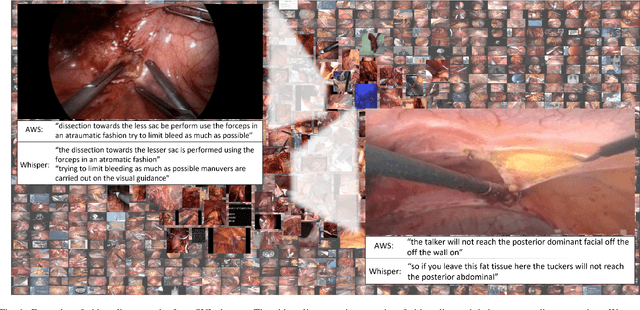
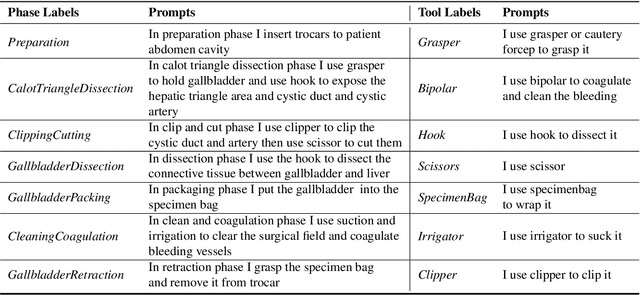
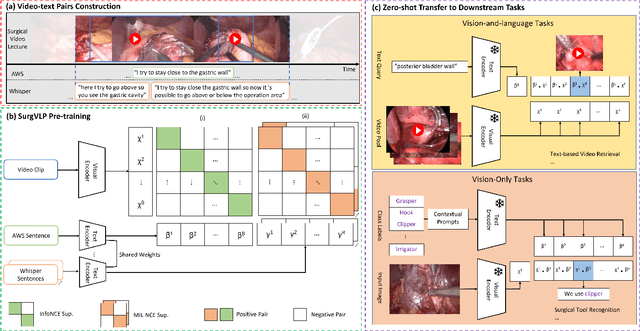
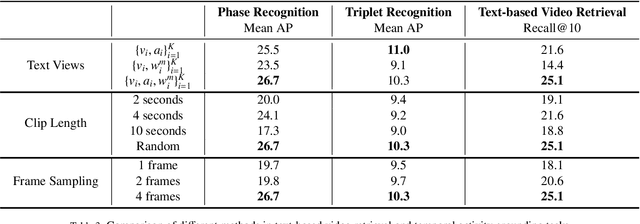
Recent advancements in surgical computer vision applications have been driven by fully-supervised methods, primarily using only visual data. These methods rely on manually annotated surgical videos to predict a fixed set of object categories, limiting their generalizability to unseen surgical procedures and downstream tasks. In this work, we put forward the idea that the surgical video lectures available through open surgical e-learning platforms can provide effective supervisory signals for multi-modal representation learning without relying on manual annotations. We address the surgery-specific linguistic challenges present in surgical video lectures by employing multiple complementary automatic speech recognition systems to generate text transcriptions. We then present a novel method, SurgVLP - Surgical Vision Language Pre-training, for multi-modal representation learning. SurgVLP constructs a new contrastive learning objective to align video clip embeddings with the corresponding multiple text embeddings by bringing them together within a joint latent space. To effectively show the representation capability of the learned joint latent space, we introduce several vision-and-language tasks for surgery, such as text-based video retrieval, temporal activity grounding, and video captioning, as benchmarks for evaluation. We further demonstrate that without using any labeled ground truth, our approach can be employed for traditional vision-only surgical downstream tasks, such as surgical tool, phase, and triplet recognition. The code will be made available at https://github.com/CAMMA-public/SurgVLP
Scaling Speech Technology to 1,000+ Languages
May 22, 2023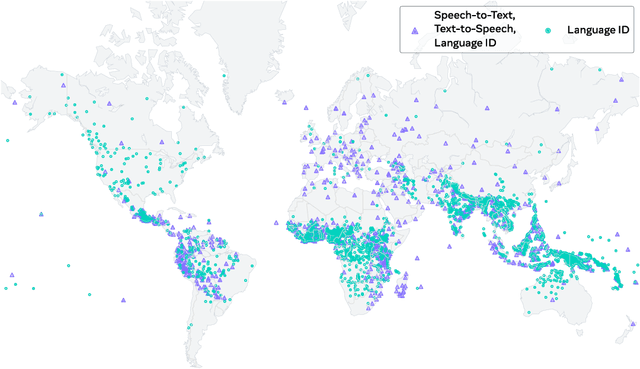

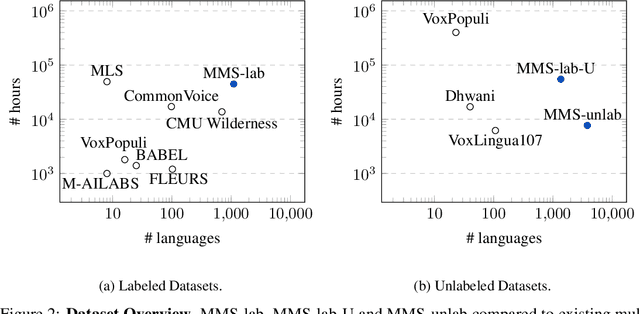

Expanding the language coverage of speech technology has the potential to improve access to information for many more people. However, current speech technology is restricted to about one hundred languages which is a small fraction of the over 7,000 languages spoken around the world. The Massively Multilingual Speech (MMS) project increases the number of supported languages by 10-40x, depending on the task. The main ingredients are a new dataset based on readings of publicly available religious texts and effectively leveraging self-supervised learning. We built pre-trained wav2vec 2.0 models covering 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for the same number of languages, as well as a language identification model for 4,017 languages. Experiments show that our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark while being trained on a small fraction of the labeled data.
Progressive Multi-Scale Self-Supervised Learning for Speech Recognition
Dec 07, 2022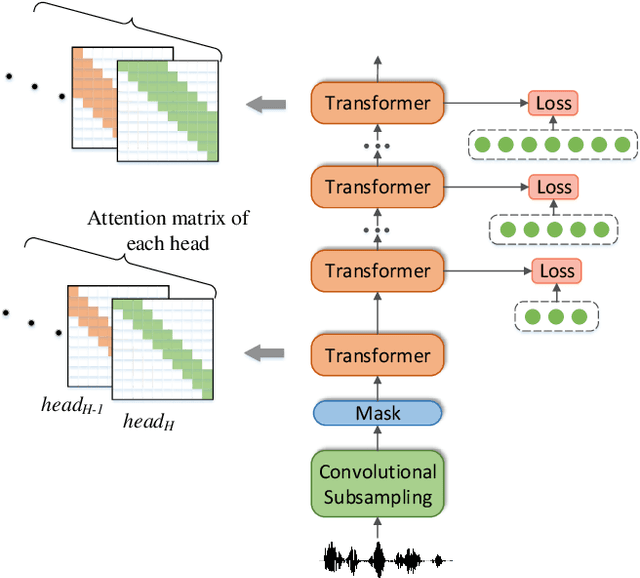
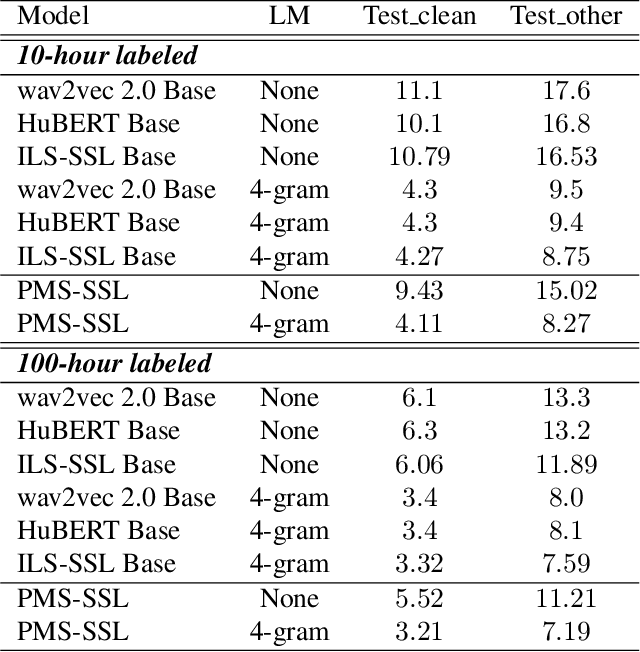

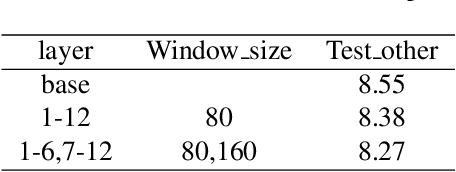
Self-supervised learning (SSL) models have achieved considerable improvements in automatic speech recognition (ASR). In addition, ASR performance could be further improved if the model is dedicated to audio content information learning theoretically. To this end, we propose a progressive multi-scale self-supervised learning (PMS-SSL) method, which uses fine-grained target sets to compute SSL loss at top layer while uses coarse-grained target sets at intermediate layers. Furthermore, PMS-SSL introduces multi-scale structure into multi-head self-attention for better speech representation, which restricts the attention area into a large scope at higher layers while restricts the attention area into a small scope at lower layers. Experiments on Librispeech dataset indicate the effectiveness of our proposed method. Compared with HuBERT, PMS-SSL achieves 13.7% / 12.7% relative WER reduction on test other evaluation subsets respectively when fine-tuned on 10hours / 100hours subsets.
Prompting the Hidden Talent of Web-Scale Speech Models for Zero-Shot Task Generalization
May 18, 2023
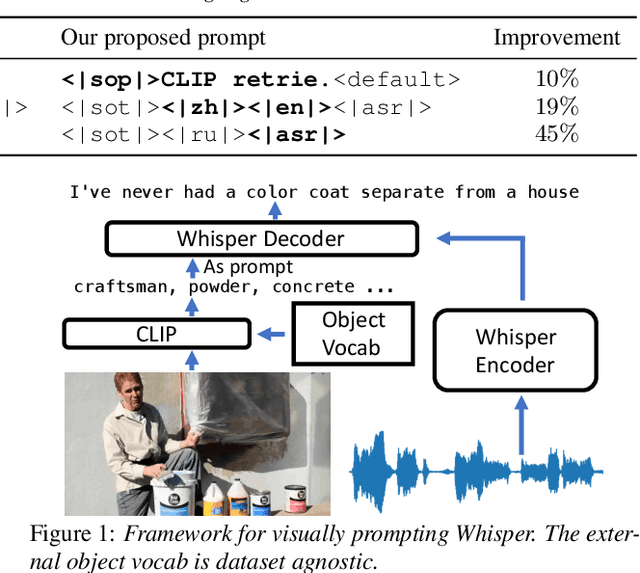
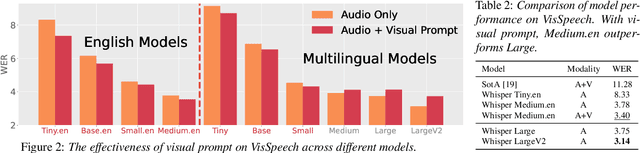

We investigate the emergent abilities of the recently proposed web-scale speech model Whisper, by adapting it to unseen tasks with prompt engineering. We selected three tasks: audio-visual speech recognition (AVSR), code-switched speech recognition (CS-ASR), and speech translation (ST) on unseen language pairs. We design task-specific prompts, by either leveraging another large-scale model, or simply manipulating the special tokens in the default prompts. Experiments show that compared to the default prompts, our proposed prompts improve performance by 10% to 45% on the three zero-shot tasks, and even outperform SotA supervised models on some datasets. In addition, our experiments reveal many interesting properties of Whisper, including its robustness to prompts, bias on accents, and the multilingual understanding in its latent space. Code is available at https://github.com/jasonppy/PromptingWhisper