 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Adapting an Unadaptable ASR System
Jun 01, 2023
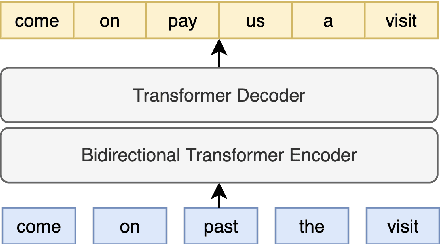
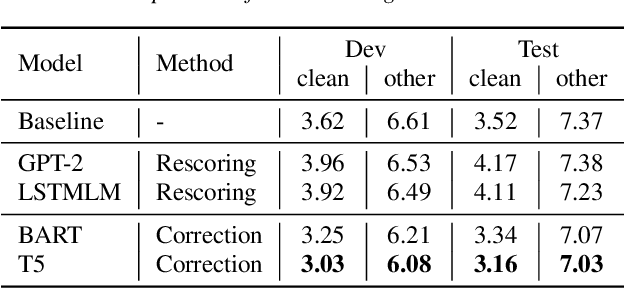
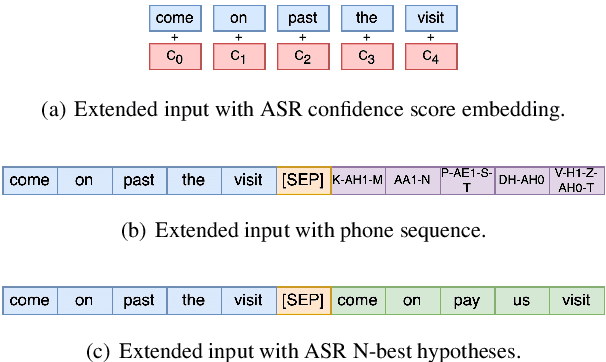
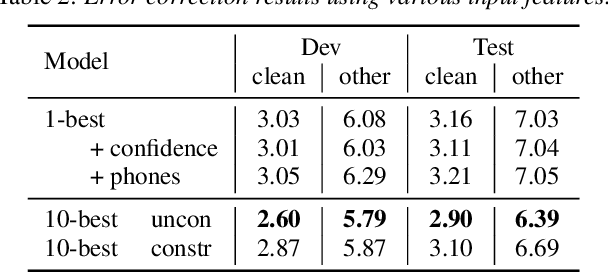
As speech recognition model sizes and training data requirements grow, it is increasingly common for systems to only be available via APIs from online service providers rather than having direct access to models themselves. In this scenario it is challenging to adapt systems to a specific target domain. To address this problem we consider the recently released OpenAI Whisper ASR as an example of a large-scale ASR system to assess adaptation methods. An error correction based approach is adopted, as this does not require access to the model, but can be trained from either 1-best or N-best outputs that are normally available via the ASR API. LibriSpeech is used as the primary target domain for adaptation. The generalization ability of the system in two distinct dimensions are then evaluated. First, whether the form of correction model is portable to other speech recognition domains, and secondly whether it can be used for ASR models having a different architecture.
Personalized Predictive ASR for Latency Reduction in Voice Assistants
May 23, 2023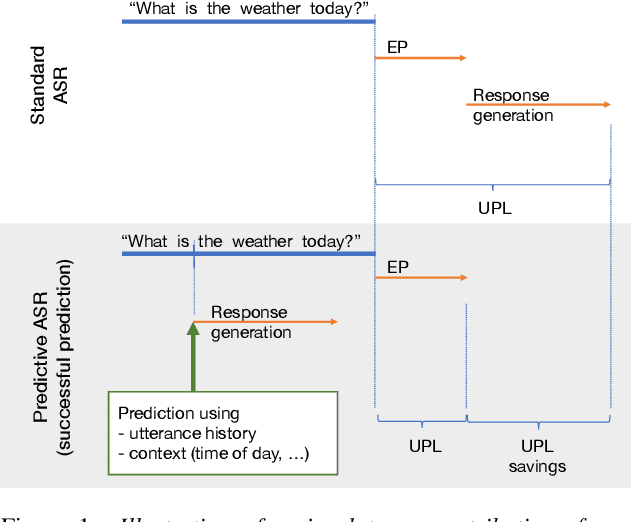
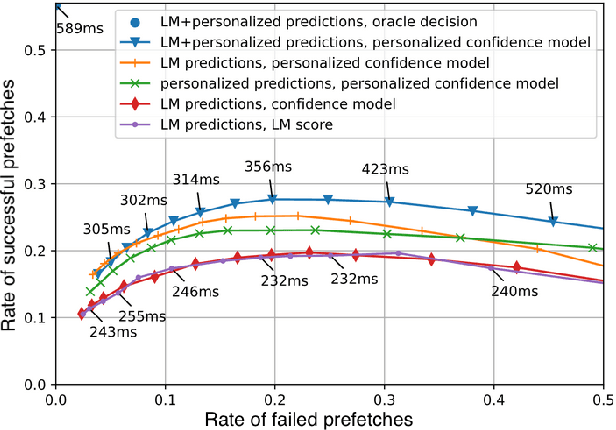
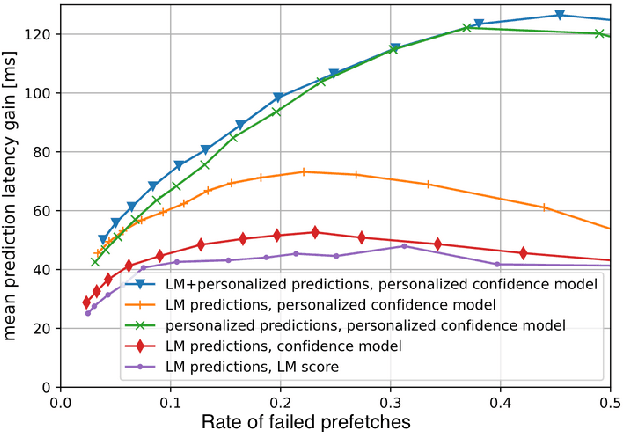
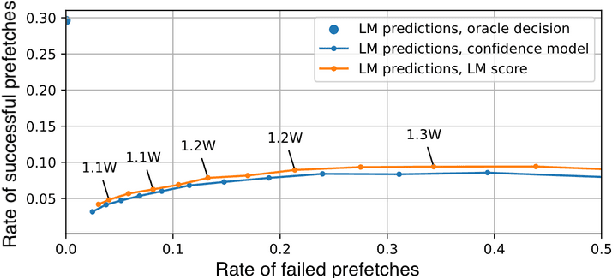
Streaming Automatic Speech Recognition (ASR) in voice assistants can utilize prefetching to partially hide the latency of response generation. Prefetching involves passing a preliminary ASR hypothesis to downstream systems in order to prefetch and cache a response. If the final ASR hypothesis after endpoint detection matches the preliminary one, the cached response can be delivered to the user, thus saving latency. In this paper, we extend this idea by introducing predictive automatic speech recognition, where we predict the full utterance from a partially observed utterance, and prefetch the response based on the predicted utterance. We introduce two personalization approaches and investigate the tradeoff between potential latency gains from successful predictions and the cost increase from failed predictions. We evaluate our methods on an internal voice assistant dataset as well as the public SLURP dataset.
Confidence Score Based Speaker Adaptation of Conformer Speech Recognition Systems
Feb 15, 2023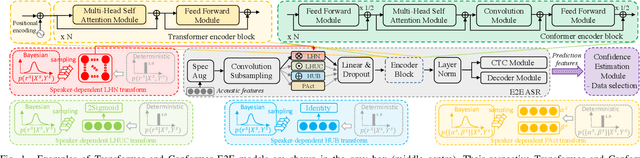
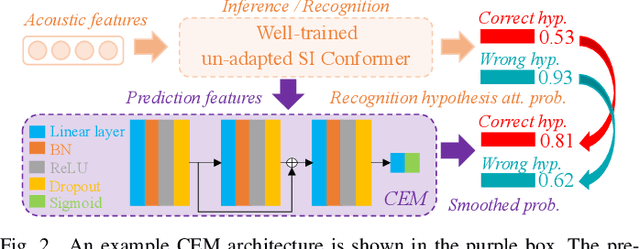
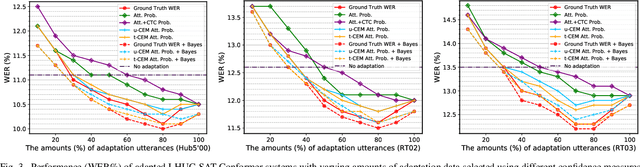
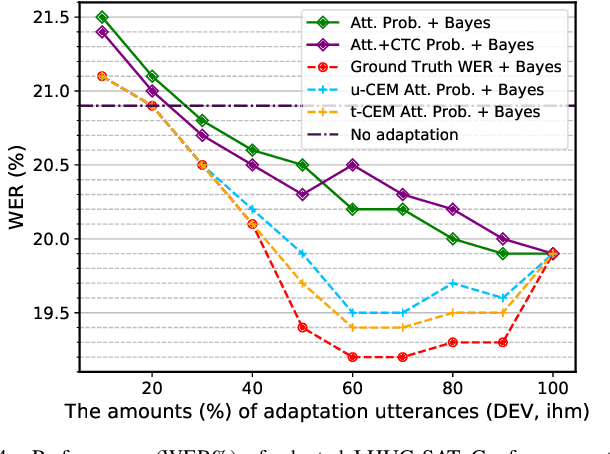
Speaker adaptation techniques provide a powerful solution to customise automatic speech recognition (ASR) systems for individual users. Practical application of unsupervised model-based speaker adaptation techniques to data intensive end-to-end ASR systems is hindered by the scarcity of speaker-level data and performance sensitivity to transcription errors. To address these issues, a set of compact and data efficient speaker-dependent (SD) parameter representations are used to facilitate both speaker adaptive training and test-time unsupervised speaker adaptation of state-of-the-art Conformer ASR systems. The sensitivity to supervision quality is reduced using a confidence score-based selection of the less erroneous subset of speaker-level adaptation data. Two lightweight confidence score estimation modules are proposed to produce more reliable confidence scores. The data sparsity issue, which is exacerbated by data selection, is addressed by modelling the SD parameter uncertainty using Bayesian learning. Experiments on the benchmark 300-hour Switchboard and the 233-hour AMI datasets suggest that the proposed confidence score-based adaptation schemes consistently outperformed the baseline speaker-independent (SI) Conformer model and conventional non-Bayesian, point estimate-based adaptation using no speaker data selection. Similar consistent performance improvements were retained after external Transformer and LSTM language model rescoring. In particular, on the 300-hour Switchboard corpus, statistically significant WER reductions of 1.0%, 1.3%, and 1.4% absolute (9.5%, 10.9%, and 11.3% relative) were obtained over the baseline SI Conformer on the NIST Hub5'00, RT02, and RT03 evaluation sets respectively. Similar WER reductions of 2.7% and 3.3% absolute (8.9% and 10.2% relative) were also obtained on the AMI development and evaluation sets.
Employing Hybrid Deep Neural Networks on Dari Speech
May 04, 2023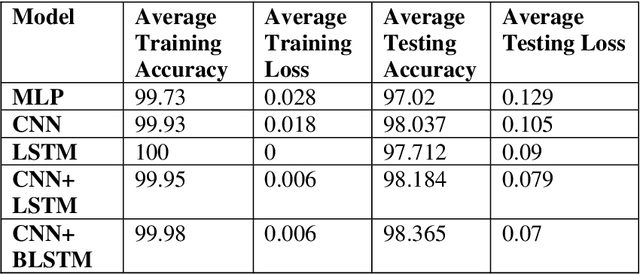
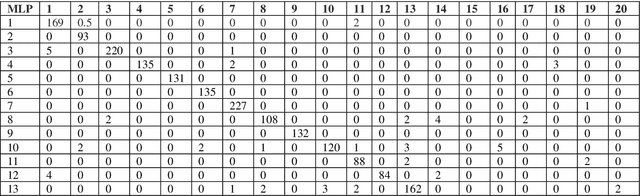

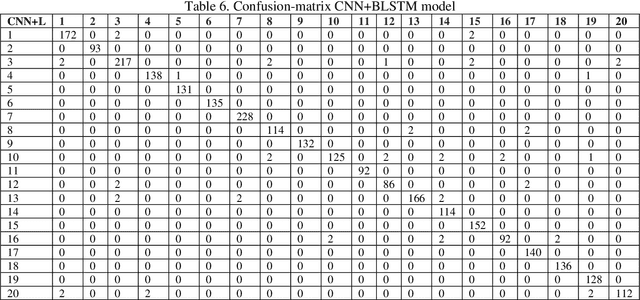
This paper is an extension of our previous conference paper. In recent years, there has been a growing interest among researchers in developing and improving speech recognition systems to facilitate and enhance human-computer interaction. Today, Automatic Speech Recognition (ASR) systems have become ubiquitous, used in everything from games to translation systems, robots, and more. However, much research is still needed on speech recognition systems for low-resource languages. This article focuses on the recognition of individual words in the Dari language using the Mel-frequency cepstral coefficients (MFCCs) feature extraction method and three different deep neural network models: Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Multilayer Perceptron (MLP), as well as two hybrid models combining CNN and RNN. We evaluate these models using an isolated Dari word corpus that we have created, consisting of 1000 utterances for 20 short Dari terms. Our study achieved an impressive average accuracy of 98.365%.
Front-End Adapter: Adapting Front-End Input of Speech based Self-Supervised Learning for Speech Recognition
Feb 18, 2023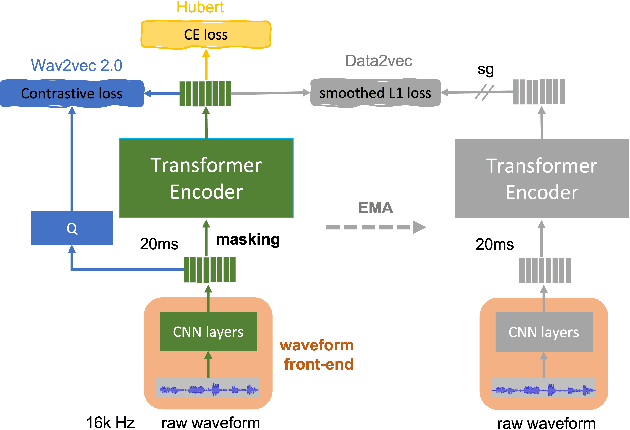
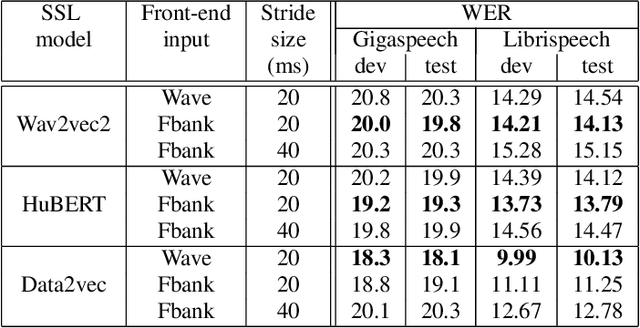
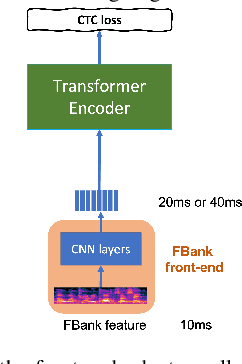
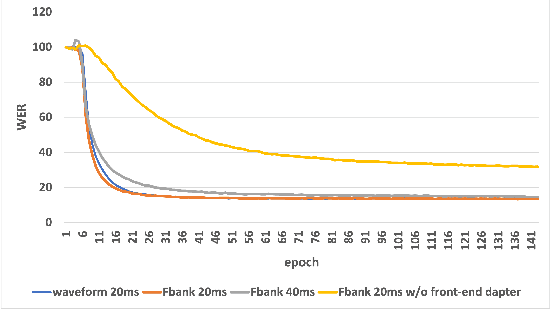
Recent years have witnessed a boom in self-supervised learning (SSL) in various areas including speech processing. Speech based SSL models present promising performance in a range of speech related tasks. However, the training of SSL models is computationally expensive and a common practice is to fine-tune a released SSL model on the specific task. It is essential to use consistent front-end input during pre-training and fine-tuning. This consistency may introduce potential issues when the optimal front-end is not the same as that used in pre-training. In this paper, we propose a simple but effective front-end adapter to address this front-end discrepancy. By minimizing the distance between the outputs of different front-ends, the filterbank feature (Fbank) can be compatible with SSL models which are pre-trained with waveform. The experiment results demonstrate the effectiveness of our proposed front-end adapter on several popular SSL models for the speech recognition task.
Personalization of CTC Speech Recognition Models
Oct 18, 2022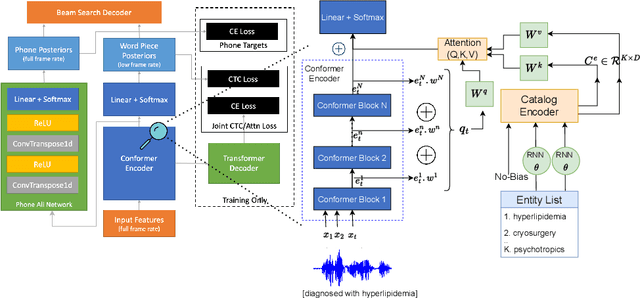
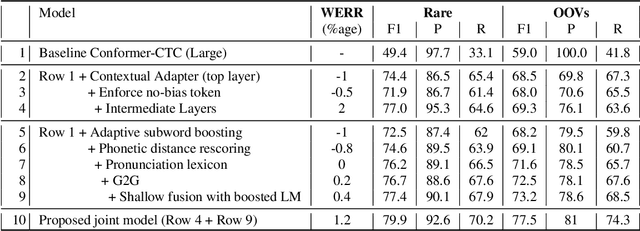
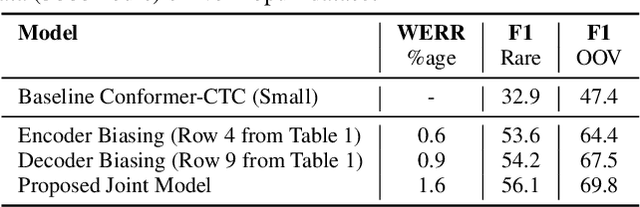
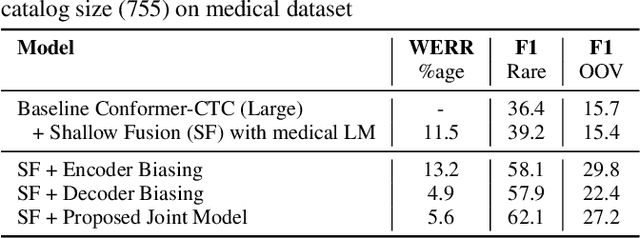
End-to-end speech recognition models trained using joint Connectionist Temporal Classification (CTC)-Attention loss have gained popularity recently. In these models, a non-autoregressive CTC decoder is often used at inference time due to its speed and simplicity. However, such models are hard to personalize because of their conditional independence assumption that prevents output tokens from previous time steps to influence future predictions. To tackle this, we propose a novel two-way approach that first biases the encoder with attention over a predefined list of rare long-tail and out-of-vocabulary (OOV) words and then uses dynamic boosting and phone alignment network during decoding to further bias the subword predictions. We evaluate our approach on open-source VoxPopuli and in-house medical datasets to showcase a 60% improvement in F1 score on domain-specific rare words over a strong CTC baseline.
A Preliminary Study on Augmenting Speech Emotion Recognition using a Diffusion Model
May 19, 2023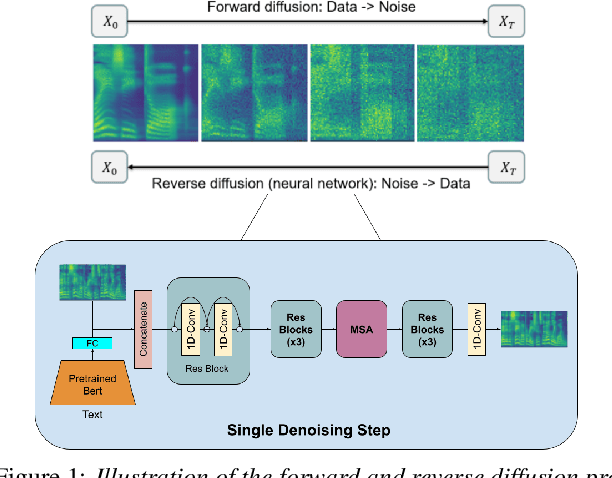


In this paper, we propose to utilise diffusion models for data augmentation in speech emotion recognition (SER). In particular, we present an effective approach to utilise improved denoising diffusion probabilistic models (IDDPM) to generate synthetic emotional data. We condition the IDDPM with the textual embedding from bidirectional encoder representations from transformers (BERT) to generate high-quality synthetic emotional samples in different speakers' voices\footnote{synthetic samples URL: \url{https://emulationai.com/research/diffusion-ser.}}. We implement a series of experiments and show that better quality synthetic data helps improve SER performance. We compare results with generative adversarial networks (GANs) and show that the proposed model generates better-quality synthetic samples that can considerably improve the performance of SER when augmented with synthetic data.
Audio-visual End-to-end Multi-channel Speech Separation, Dereverberation and Recognition
Jul 06, 2023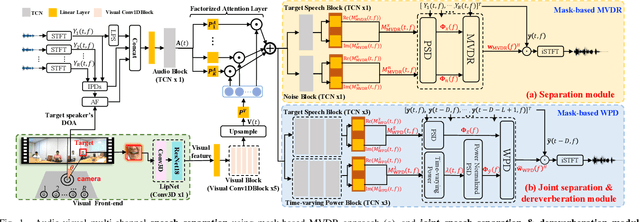
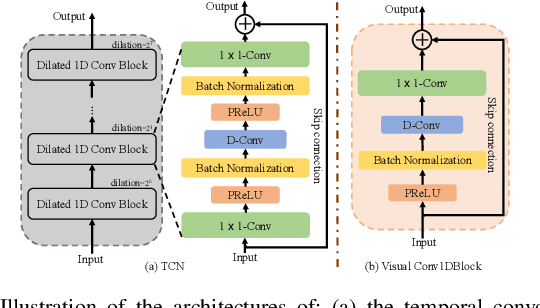
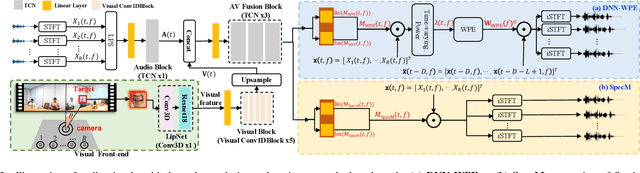

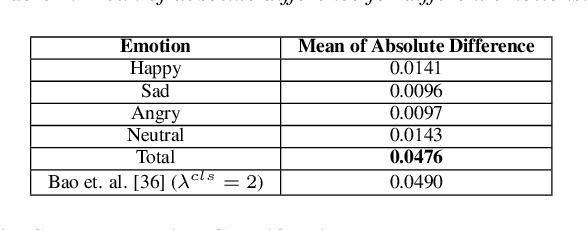
Accurate recognition of cocktail party speech containing overlapping speakers, noise and reverberation remains a highly challenging task to date. Motivated by the invariance of visual modality to acoustic signal corruption, an audio-visual multi-channel speech separation, dereverberation and recognition approach featuring a full incorporation of visual information into all system components is proposed in this paper. The efficacy of the video input is consistently demonstrated in mask-based MVDR speech separation, DNN-WPE or spectral mapping (SpecM) based speech dereverberation front-end and Conformer ASR back-end. Audio-visual integrated front-end architectures performing speech separation and dereverberation in a pipelined or joint fashion via mask-based WPD are investigated. The error cost mismatch between the speech enhancement front-end and ASR back-end components is minimized by end-to-end jointly fine-tuning using either the ASR cost function alone, or its interpolation with the speech enhancement loss. Experiments were conducted on the mixture overlapped and reverberant speech data constructed using simulation or replay of the Oxford LRS2 dataset. The proposed audio-visual multi-channel speech separation, dereverberation and recognition systems consistently outperformed the comparable audio-only baseline by 9.1% and 6.2% absolute (41.7% and 36.0% relative) word error rate (WER) reductions. Consistent speech enhancement improvements were also obtained on PESQ, STOI and SRMR scores.
The CHiME-7 DASR Challenge: Distant Meeting Transcription with Multiple Devices in Diverse Scenarios
Jul 14, 2023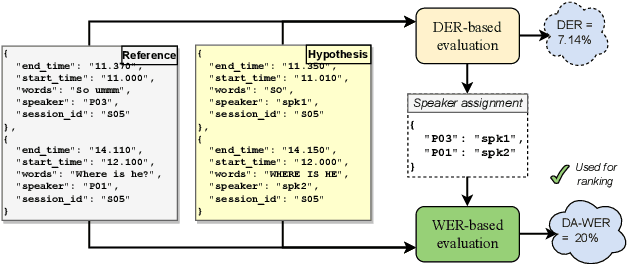
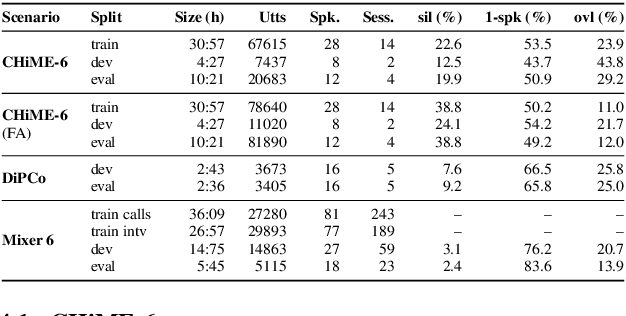
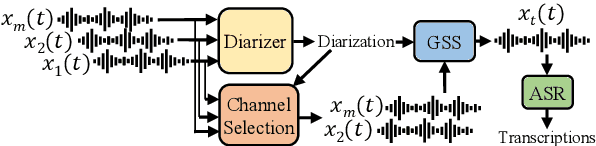
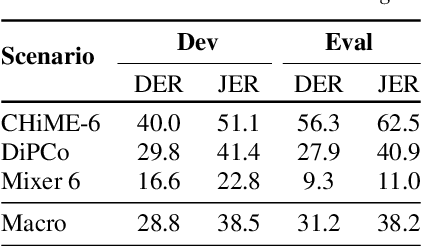
The CHiME challenges have played a significant role in the development and evaluation of robust automatic speech recognition (ASR) systems. We introduce the CHiME-7 distant ASR (DASR) task, within the 7th CHiME challenge. This task comprises joint ASR and diarization in far-field settings with multiple, and possibly heterogeneous, recording devices. Different from previous challenges, we evaluate systems on 3 diverse scenarios: CHiME-6, DiPCo, and Mixer 6. The goal is for participants to devise a single system that can generalize across different array geometries and use cases with no a-priori information. Another departure from earlier CHiME iterations is that participants are allowed to use open-source pre-trained models and datasets. In this paper, we describe the challenge design, motivation, and fundamental research questions in detail. We also present the baseline system, which is fully array-topology agnostic and features multi-channel diarization, channel selection, guided source separation and a robust ASR model that leverages self-supervised speech representations (SSLR).
SGGNet$^2$: Speech-Scene Graph Grounding Network for Speech-guided Navigation
Jul 14, 2023
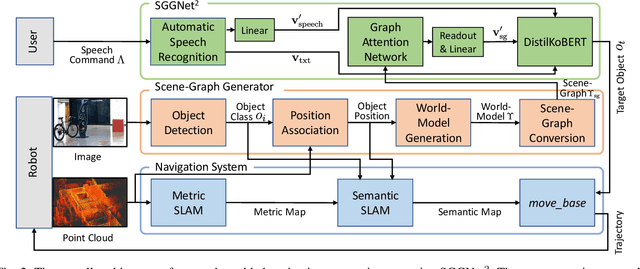
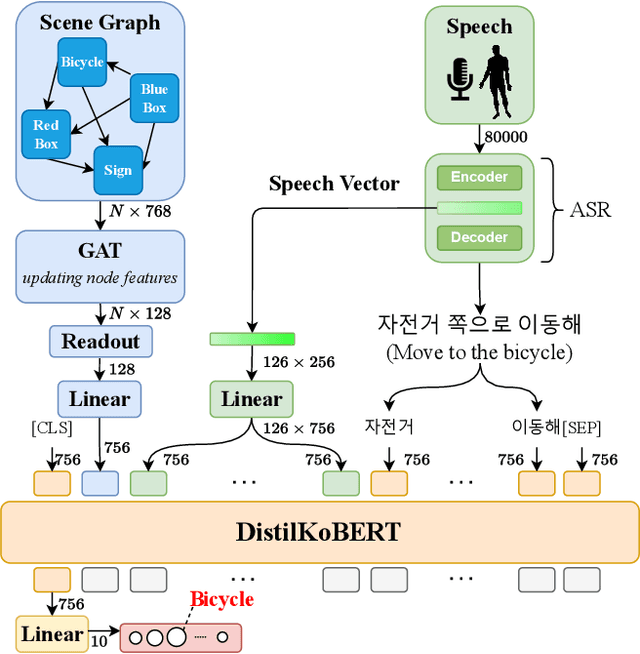

The spoken language serves as an accessible and efficient interface, enabling non-experts and disabled users to interact with complex assistant robots. However, accurately grounding language utterances gives a significant challenge due to the acoustic variability in speakers' voices and environmental noise. In this work, we propose a novel speech-scene graph grounding network (SGGNet$^2$) that robustly grounds spoken utterances by leveraging the acoustic similarity between correctly recognized and misrecognized words obtained from automatic speech recognition (ASR) systems. To incorporate the acoustic similarity, we extend our previous grounding model, the scene-graph-based grounding network (SGGNet), with the ASR model from NVIDIA NeMo. We accomplish this by feeding the latent vector of speech pronunciations into the BERT-based grounding network within SGGNet. We evaluate the effectiveness of using latent vectors of speech commands in grounding through qualitative and quantitative studies. We also demonstrate the capability of SGGNet$^2$ in a speech-based navigation task using a real quadruped robot, RBQ-3, from Rainbow Robotics.