 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
PEFT-SER: On the Use of Parameter Efficient Transfer Learning Approaches For Speech Emotion Recognition Using Pre-trained Speech Models
Jun 08, 2023
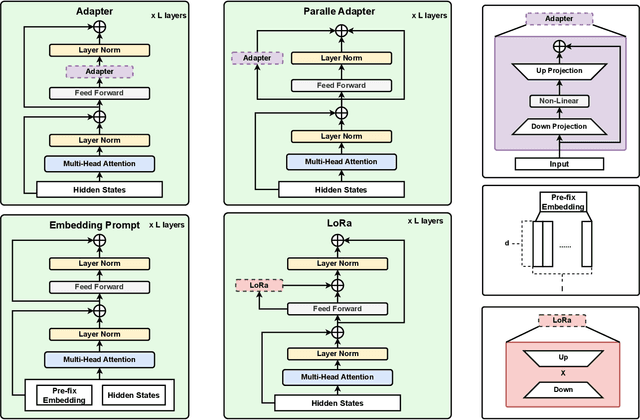
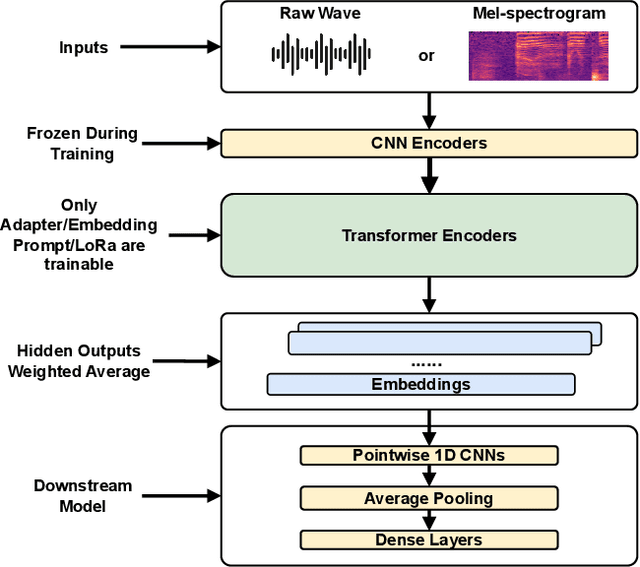

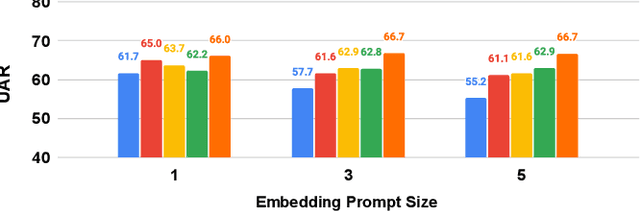
Many recent studies have focused on fine-tuning pre-trained models for speech emotion recognition (SER), resulting in promising performance compared to traditional methods that rely largely on low-level, knowledge-inspired acoustic features. These pre-trained speech models learn general-purpose speech representations using self-supervised or weakly-supervised learning objectives from large-scale datasets. Despite the significant advances made in SER through the use of pre-trained architecture, fine-tuning these large pre-trained models for different datasets requires saving copies of entire weight parameters, rendering them impractical to deploy in real-world settings. As an alternative, this work explores parameter-efficient fine-tuning (PEFT) approaches for adapting pre-trained speech models for emotion recognition. Specifically, we evaluate the efficacy of adapter tuning, embedding prompt tuning, and LoRa (Low-rank approximation) on four popular SER testbeds. Our results reveal that LoRa achieves the best fine-tuning performance in emotion recognition while enhancing fairness and requiring only a minimal extra amount of weight parameters. Furthermore, our findings offer novel insights into future research directions in SER, distinct from existing approaches focusing on directly fine-tuning the model architecture. Our code is publicly available under: https://github.com/usc-sail/peft-ser.
Modeling of Speech-dependent Own Voice Transfer Characteristics for Hearables with In-ear Microphones
Oct 10, 2023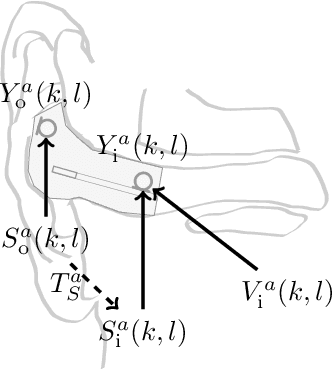
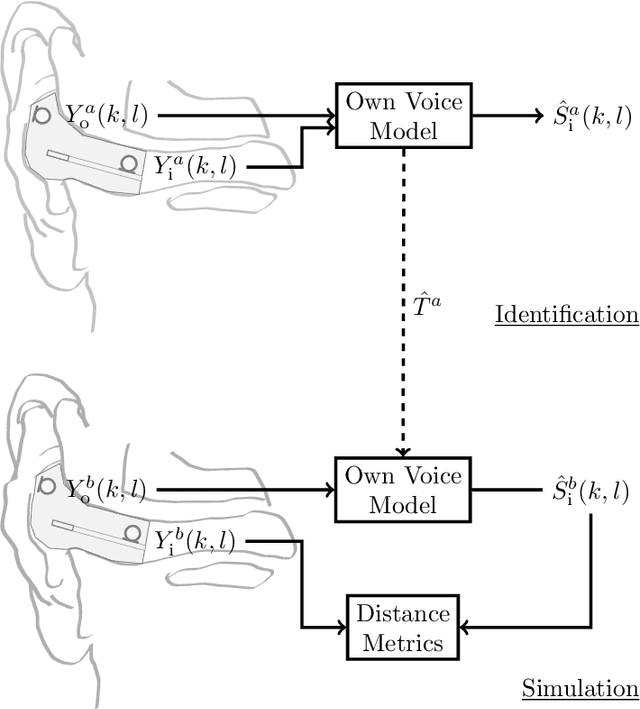
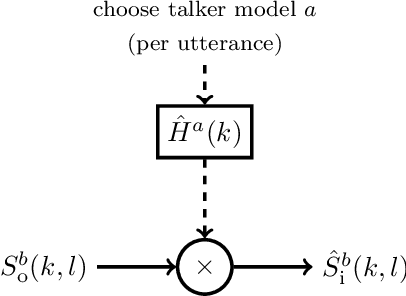
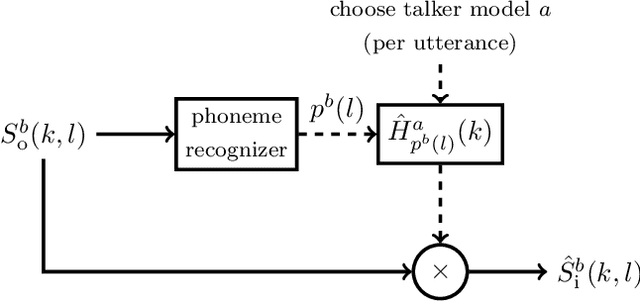
Hearables often contain an in-ear microphone, which may be used to capture the own voice of its user. However, due to ear canal occlusion the in-ear microphone mostly records body-conducted speech, which suffers from band-limitation effects and is subject to amplification of low frequency content. These transfer characteristics are assumed to vary both based on speech content and between individual talkers. It is desirable to have an accurate model of the own voice transfer characteristics between hearable microphones. Such a model can be used, e.g., to simulate a large amount of in-ear recordings to train supervised learning-based algorithms aiming at compensating own voice transfer characteristics. In this paper we propose a speech-dependent system identification model based on phoneme recognition. Using recordings from a prototype hearable, the modeling accuracy is evaluated in terms of technical measures. We investigate robustness of transfer characteristic models to utterance or talker mismatch. Simulation results show that using the proposed speech-dependent model is preferable for simulating in-ear recordings compared to a speech-independent model. The proposed model is able to generalize better to new utterances than an adaptive filtering-based model. Additionally, we find that talker-averaged models generalize better to different talkers than individual models.
Online Continual Learning of End-to-End Speech Recognition Models
Jul 11, 2022
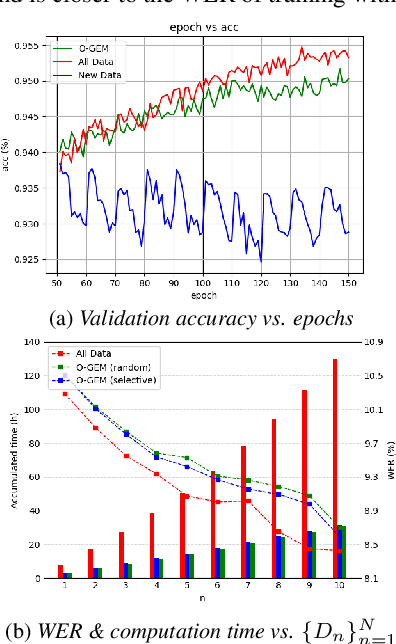
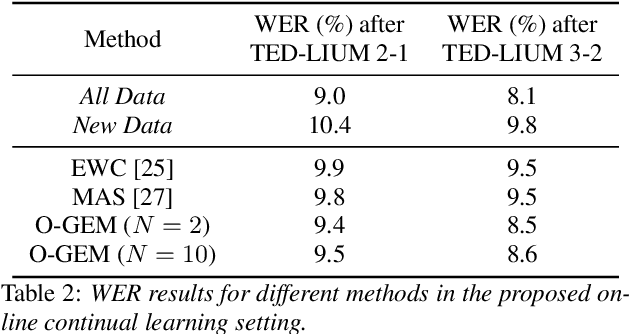
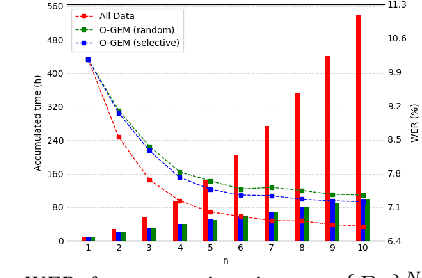
Continual Learning, also known as Lifelong Learning, aims to continually learn from new data as it becomes available. While prior research on continual learning in automatic speech recognition has focused on the adaptation of models across multiple different speech recognition tasks, in this paper we propose an experimental setting for \textit{online continual learning} for automatic speech recognition of a single task. Specifically focusing on the case where additional training data for the same task becomes available incrementally over time, we demonstrate the effectiveness of performing incremental model updates to end-to-end speech recognition models with an online Gradient Episodic Memory (GEM) method. Moreover, we show that with online continual learning and a selective sampling strategy, we can maintain an accuracy that is similar to retraining a model from scratch while requiring significantly lower computation costs. We have also verified our method with self-supervised learning (SSL) features.
Streaming Audio-Visual Speech Recognition with Alignment Regularization
Nov 03, 2022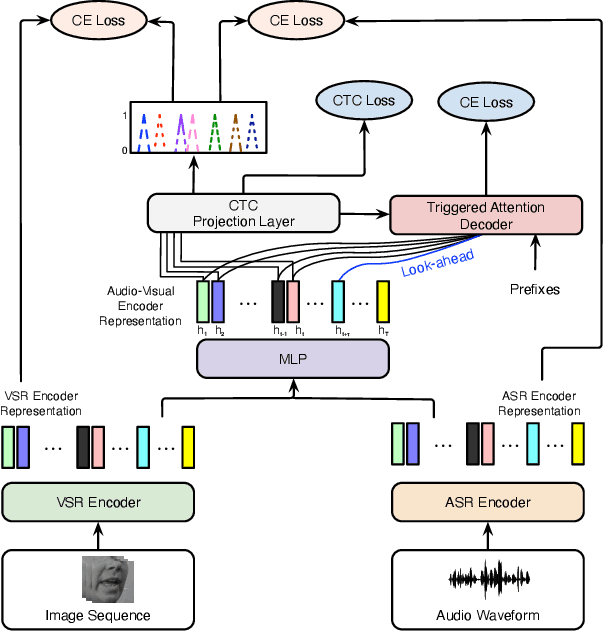
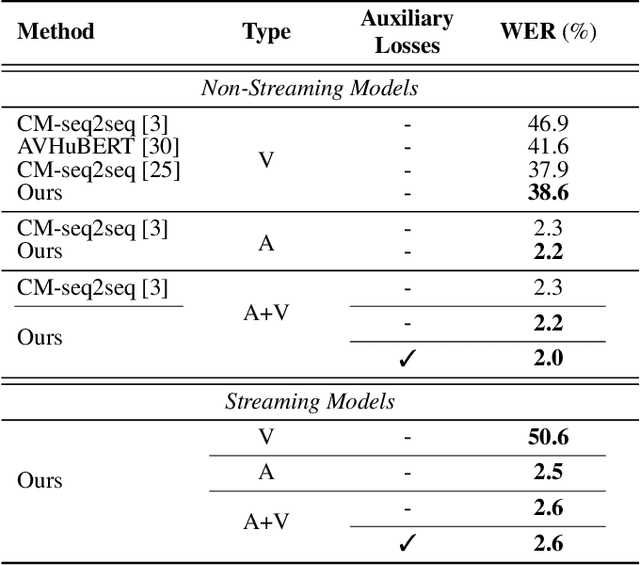
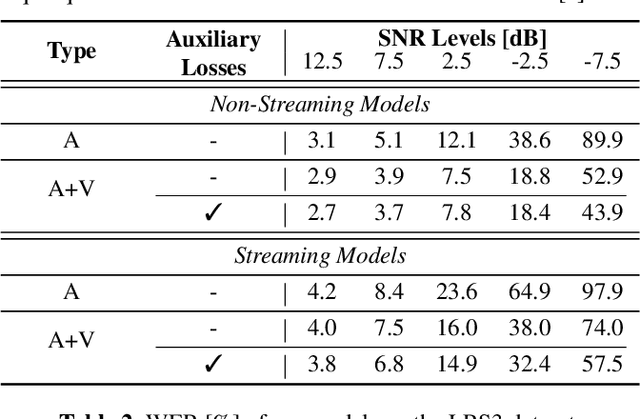
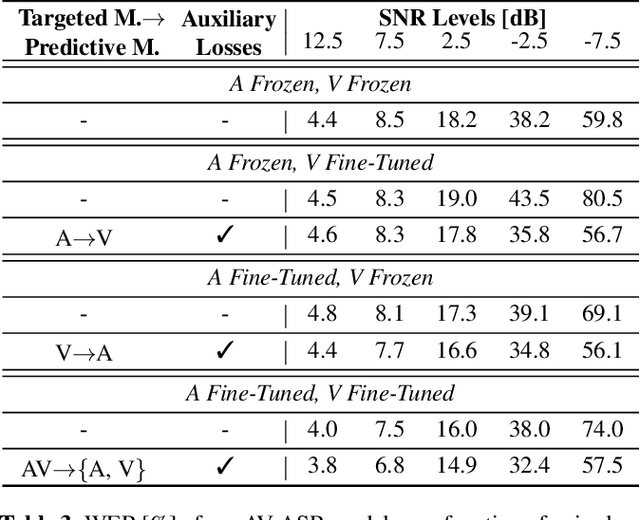
Recognizing a word shortly after it is spoken is an important requirement for automatic speech recognition (ASR) systems in real-world scenarios. As a result, a large body of work on streaming audio-only ASR models has been presented in the literature. However, streaming audio-visual automatic speech recognition (AV-ASR) has received little attention in earlier works. In this work, we propose a streaming AV-ASR system based on a hybrid connectionist temporal classification (CTC)/attention neural network architecture. The audio and the visual encoder neural networks are both based on the conformer architecture, which is made streamable using chunk-wise self-attention (CSA) and causal convolution. Streaming recognition with a decoder neural network is realized by using the triggered attention technique, which performs time-synchronous decoding with joint CTC/attention scoring. For frame-level ASR criteria, such as CTC, a synchronized response from the audio and visual encoders is critical for a joint AV decision making process. In this work, we propose a novel alignment regularization technique that promotes synchronization of the audio and visual encoder, which in turn results in better word error rates (WERs) at all SNR levels for streaming and offline AV-ASR models. The proposed AV-ASR model achieves WERs of 2.0% and 2.6% on the Lip Reading Sentences 3 (LRS3) dataset in an offline and online setup, respectively, which both present state-of-the-art results when no external training data are used.
MAC: A unified framework boosting low resource automatic speech recognition
Feb 15, 2023
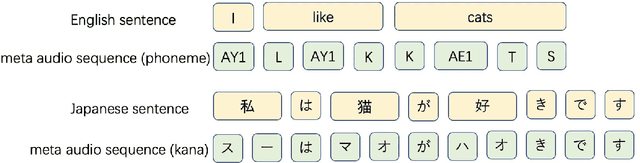
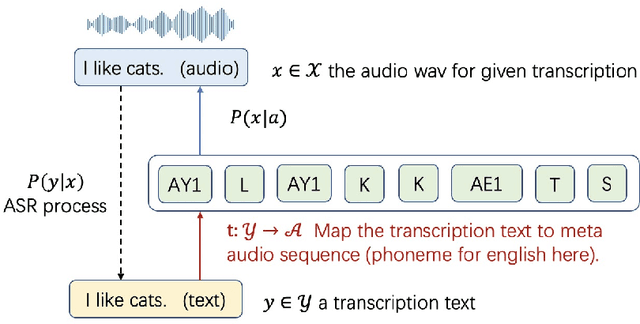
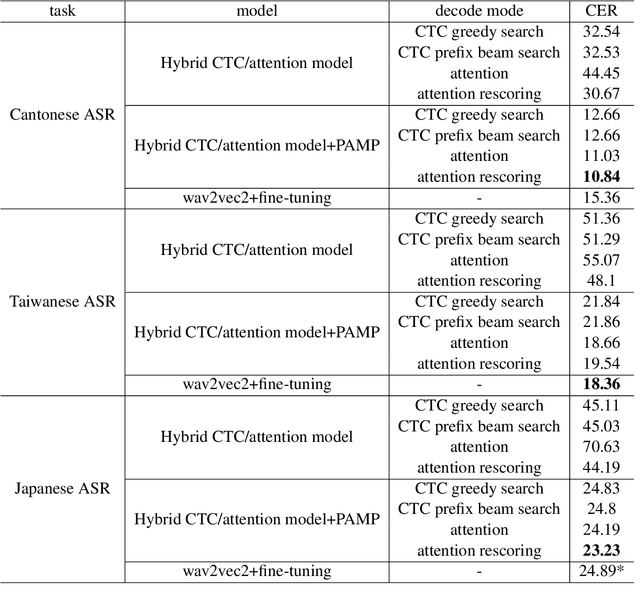
We propose a unified framework for low resource automatic speech recognition tasks named meta audio concatenation (MAC). It is easy to implement and can be carried out in extremely low resource environments. Mathematically, we give a clear description of MAC framework from the perspective of bayesian sampling. In this framework, we leverage a novel concatenative synthesis text-to-speech system to boost the low resource ASR task. By the concatenative synthesis text-to-speech system, we can integrate language pronunciation rules and adjust the TTS process. Furthermore, we propose a broad notion of meta audio set to meet the modeling needs of different languages and different scenes when using the system. Extensive experiments have demonstrated the great effectiveness of MAC on low resource ASR tasks. For CTC greedy search, CTC prefix, attention, and attention rescoring decode mode in Cantonese ASR task, Taiwanese ASR task, and Japanese ASR task the MAC method can reduce the CER by more than 15\%. Furthermore, in the ASR task, MAC beats wav2vec2 (with fine-tuning) on common voice datasets of Cantonese and gets really competitive results on common voice datasets of Taiwanese and Japanese. Among them, it is worth mentioning that we achieve a \textbf{10.9\%} character error rate (CER) on the common voice Cantonese ASR task, bringing about \textbf{30\%} relative improvement compared to the wav2vec2 (with fine-tuning).
Improving Speech Emotion Recognition Performance using Differentiable Architecture Search
May 23, 2023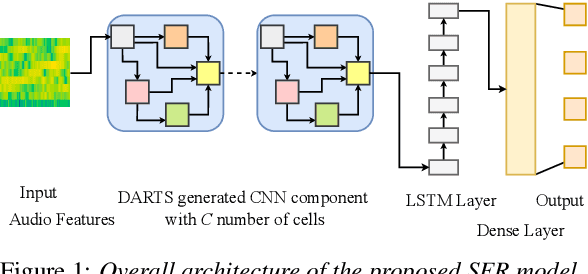
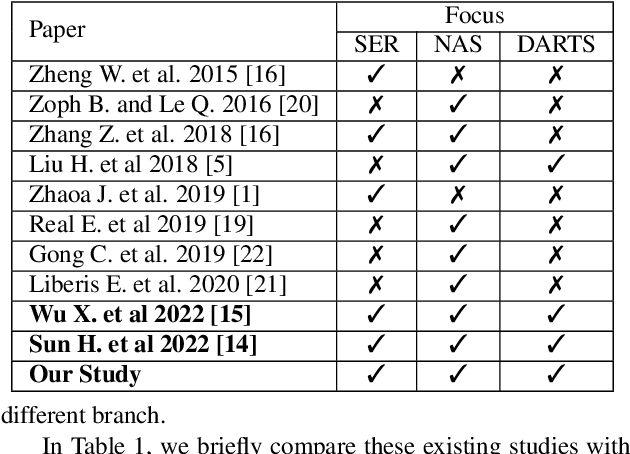
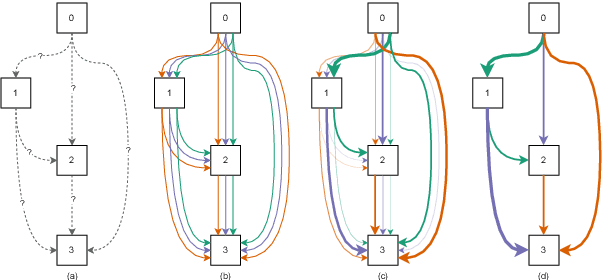
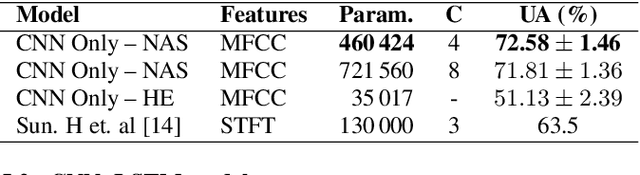
Speech Emotion Recognition (SER) is a critical enabler of emotion-aware communication in human-computer interactions. Deep Learning (DL) has improved the performance of SER models by improving model complexity. However, designing DL architectures requires prior experience and experimental evaluations. Encouragingly, Neural Architecture Search (NAS) allows automatic search for an optimum DL model. In particular, Differentiable Architecture Search (DARTS) is an efficient method of using NAS to search for optimised models. In this paper, we propose DARTS for a joint CNN and LSTM architecture for improving SER performance. Our choice of the CNN LSTM coupling is inspired by results showing that similar models offer improved performance. While SER researchers have considered CNNs and RNNs separately, the viability of using DARTs jointly for CNN and LSTM still needs exploration. Experimenting with the IEMOCAP dataset, we demonstrate that our approach outperforms best-reported results using DARTS for SER.
Language-Universal Adapter Learning with Knowledge Distillation for End-to-End Multilingual Speech Recognition
Feb 28, 2023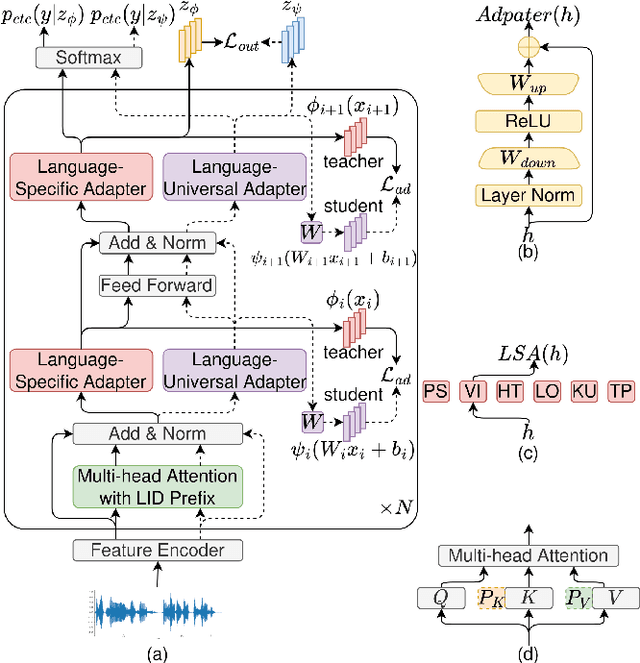
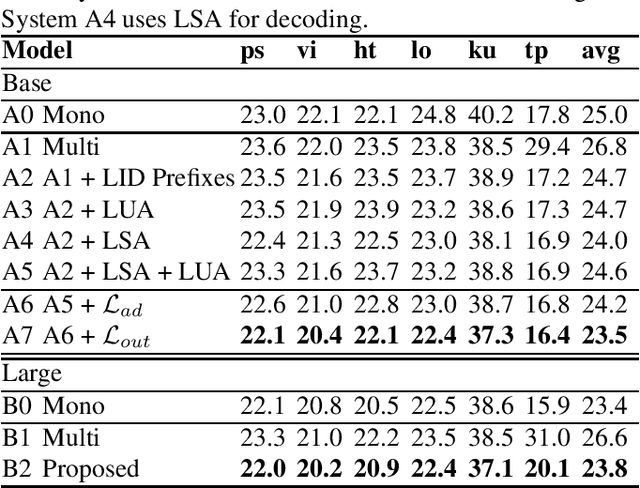

In this paper, we propose a language-universal adapter learning framework based on a pre-trained model for end-to-end multilingual automatic speech recognition (ASR). For acoustic modeling, the wav2vec 2.0 pre-trained model is fine-tuned by inserting language-specific and language-universal adapters. An online knowledge distillation is then used to enable the language-universal adapters to learn both language-specific and universal features. The linguistic information confusion is also reduced by leveraging language identifiers (LIDs). With LIDs we perform a position-wise modification on the multi-head attention outputs. In the inference procedure, the language-specific adapters are removed while the language-universal adapters are kept activated. The proposed method improves the recognition accuracy and addresses the linear increase of the number of adapters' parameters with the number of languages in common multilingual ASR systems. Experiments on the BABEL dataset confirm the effectiveness of the proposed framework. Compared to the conventional multilingual model, a 3.3% absolute error rate reduction is achieved. The code is available at: https://github.com/shen9712/UniversalAdapterLearning.
Modality Confidence Aware Training for Robust End-to-End Spoken Language Understanding
Jul 22, 2023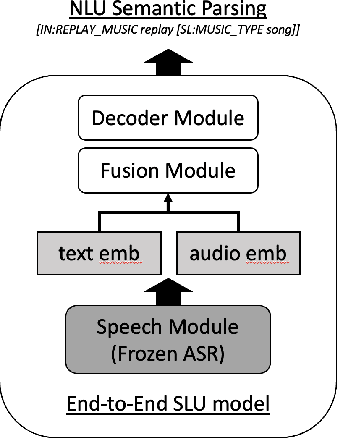
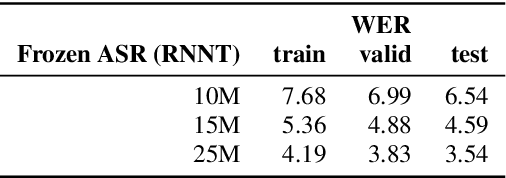
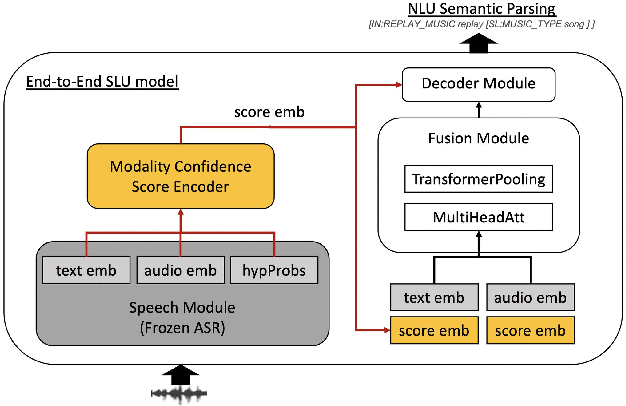

End-to-end (E2E) spoken language understanding (SLU) systems that generate a semantic parse from speech have become more promising recently. This approach uses a single model that utilizes audio and text representations from pre-trained speech recognition models (ASR), and outperforms traditional pipeline SLU systems in on-device streaming scenarios. However, E2E SLU systems still show weakness when text representation quality is low due to ASR transcription errors. To overcome this issue, we propose a novel E2E SLU system that enhances robustness to ASR errors by fusing audio and text representations based on the estimated modality confidence of ASR hypotheses. We introduce two novel techniques: 1) an effective method to encode the quality of ASR hypotheses and 2) an effective approach to integrate them into E2E SLU models. We show accuracy improvements on STOP dataset and share the analysis to demonstrate the effectiveness of our approach.
Compensating Removed Frequency Components: Thwarting Voice Spectrum Reduction Attacks
Aug 18, 2023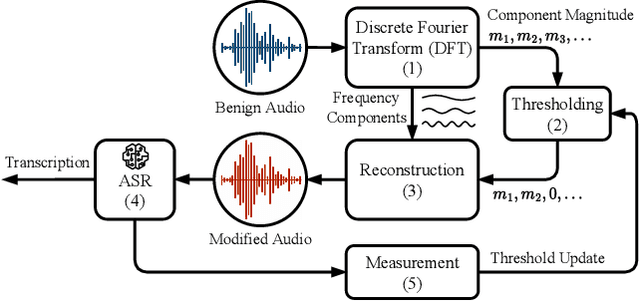
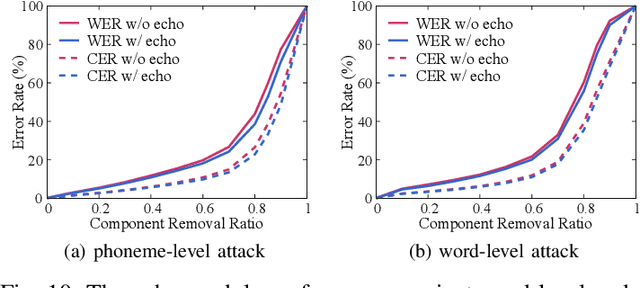
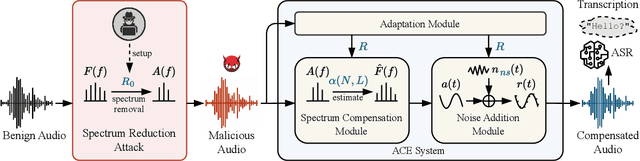
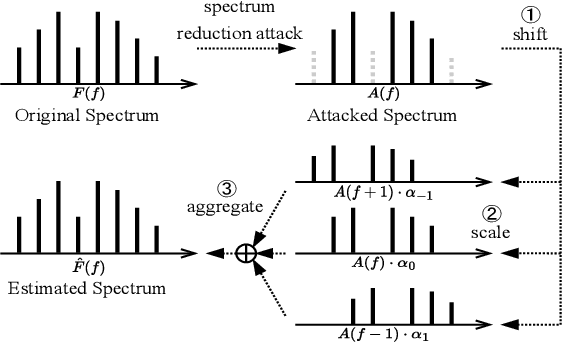
Automatic speech recognition (ASR) provides diverse audio-to-text services for humans to communicate with machines. However, recent research reveals ASR systems are vulnerable to various malicious audio attacks. In particular, by removing the non-essential frequency components, a new spectrum reduction attack can generate adversarial audios that can be perceived by humans but cannot be correctly interpreted by ASR systems. It raises a new challenge for content moderation solutions to detect harmful content in audio and video available on social media platforms. In this paper, we propose an acoustic compensation system named ACE to counter the spectrum reduction attacks over ASR systems. Our system design is based on two observations, namely, frequency component dependencies and perturbation sensitivity. First, since the Discrete Fourier Transform computation inevitably introduces spectral leakage and aliasing effects to the audio frequency spectrum, the frequency components with similar frequencies will have a high correlation. Thus, considering the intrinsic dependencies between neighboring frequency components, it is possible to recover more of the original audio by compensating for the removed components based on the remaining ones. Second, since the removed components in the spectrum reduction attacks can be regarded as an inverse of adversarial noise, the attack success rate will decrease when the adversarial audio is replayed in an over-the-air scenario. Hence, we can model the acoustic propagation process to add over-the-air perturbations into the attacked audio. We implement a prototype of ACE and the experiments show ACE can effectively reduce up to 87.9% of ASR inference errors caused by spectrum reduction attacks. Also, by analyzing residual errors, we summarize six general types of ASR inference errors and investigate the error causes and potential mitigation solutions.
EM-Network: Oracle Guided Self-distillation for Sequence Learning
Jun 14, 2023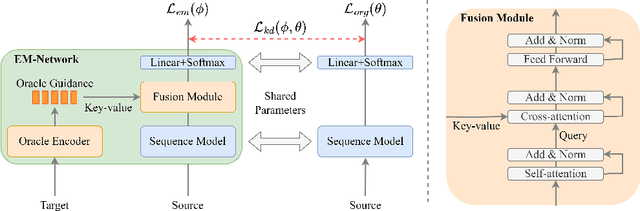
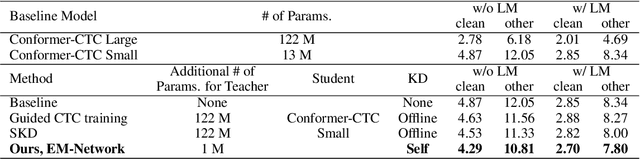
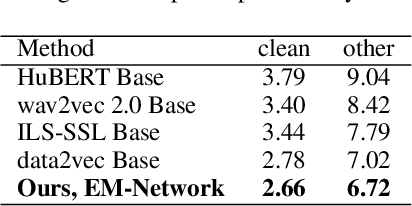
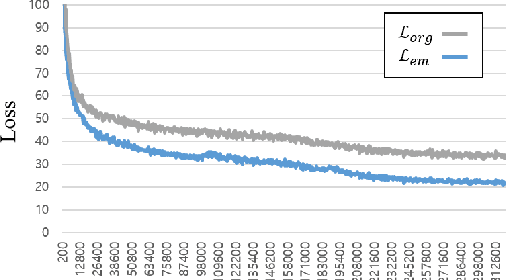
We introduce EM-Network, a novel self-distillation approach that effectively leverages target information for supervised sequence-to-sequence (seq2seq) learning. In contrast to conventional methods, it is trained with oracle guidance, which is derived from the target sequence. Since the oracle guidance compactly represents the target-side context that can assist the sequence model in solving the task, the EM-Network achieves a better prediction compared to using only the source input. To allow the sequence model to inherit the promising capability of the EM-Network, we propose a new self-distillation strategy, where the original sequence model can benefit from the knowledge of the EM-Network in a one-stage manner. We conduct comprehensive experiments on two types of seq2seq models: connectionist temporal classification (CTC) for speech recognition and attention-based encoder-decoder (AED) for machine translation. Experimental results demonstrate that the EM-Network significantly advances the current state-of-the-art approaches, improving over the best prior work on speech recognition and establishing state-of-the-art performance on WMT'14 and IWSLT'14.