 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Leveraging Modality-specific Representations for Audio-visual Speech Recognition via Reinforcement Learning
Dec 10, 2022
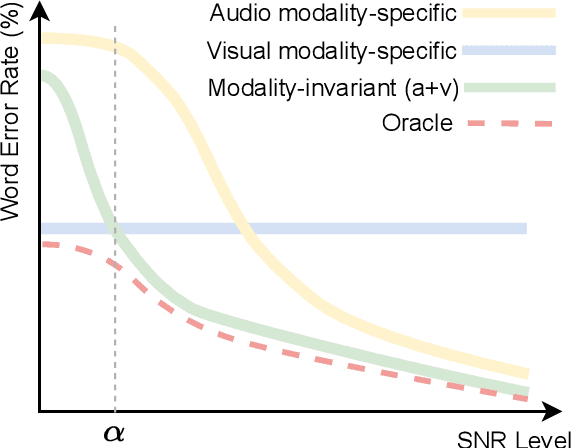

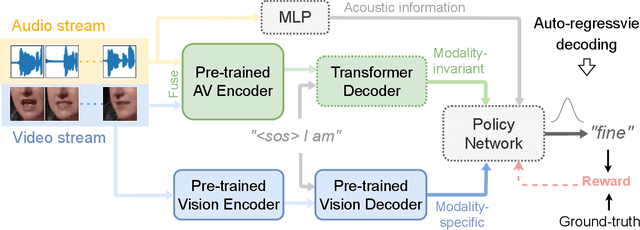
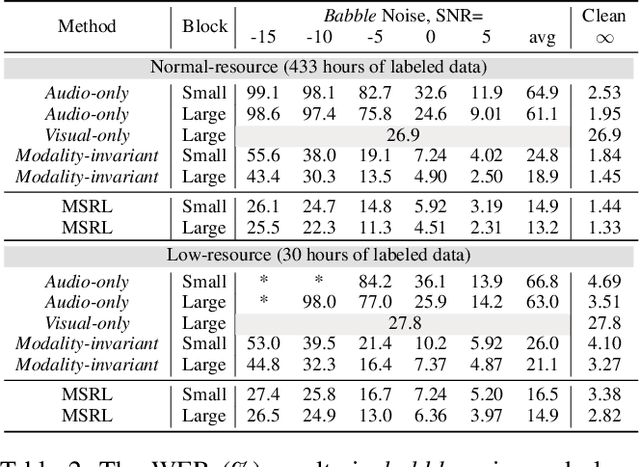
Audio-visual speech recognition (AVSR) has gained remarkable success for ameliorating the noise-robustness of speech recognition. Mainstream methods focus on fusing audio and visual inputs to obtain modality-invariant representations. However, such representations are prone to over-reliance on audio modality as it is much easier to recognize than video modality in clean conditions. As a result, the AVSR model underestimates the importance of visual stream in face of noise corruption. To this end, we leverage visual modality-specific representations to provide stable complementary information for the AVSR task. Specifically, we propose a reinforcement learning (RL) based framework called MSRL, where the agent dynamically harmonizes modality-invariant and modality-specific representations in the auto-regressive decoding process. We customize a reward function directly related to task-specific metrics (i.e., word error rate), which encourages the MSRL to effectively explore the optimal integration strategy. Experimental results on the LRS3 dataset show that the proposed method achieves state-of-the-art in both clean and various noisy conditions. Furthermore, we demonstrate the better generality of MSRL system than other baselines when test set contains unseen noises.
Zambezi Voice: A Multilingual Speech Corpus for Zambian Languages
Jun 07, 2023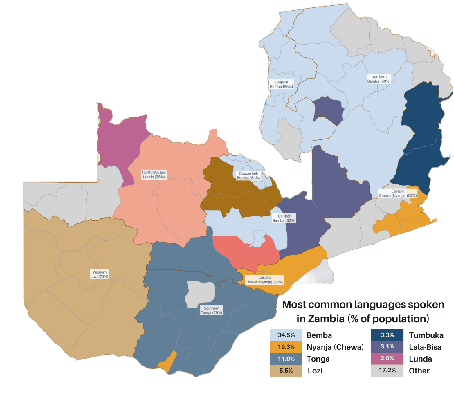
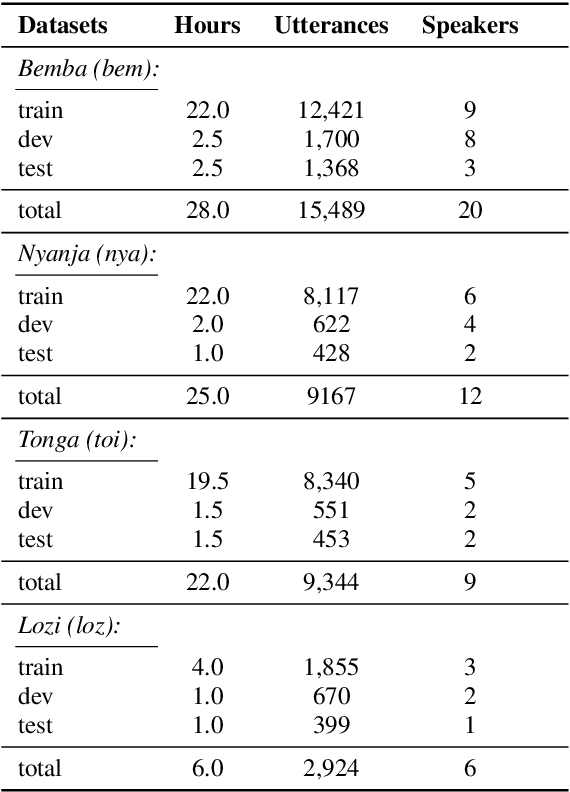
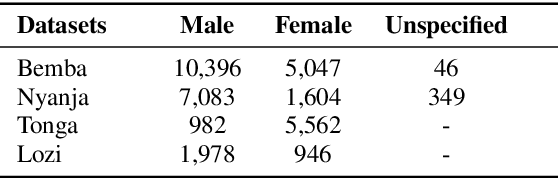
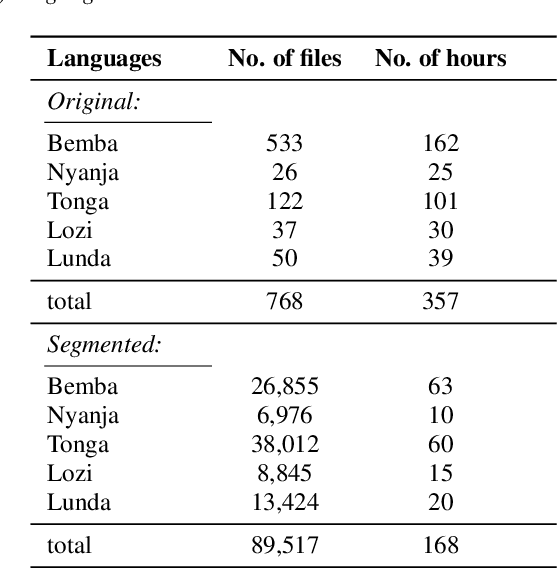
This work introduces Zambezi Voice, an open-source multilingual speech resource for Zambian languages. It contains two collections of datasets: unlabelled audio recordings of radio news and talk shows programs (160 hours) and labelled data (over 80 hours) consisting of read speech recorded from text sourced from publicly available literature books. The dataset is created for speech recognition but can be extended to multilingual speech processing research for both supervised and unsupervised learning approaches. To our knowledge, this is the first multilingual speech dataset created for Zambian languages. We exploit pretraining and cross-lingual transfer learning by finetuning the Wav2Vec2.0 large-scale multilingual pre-trained model to build end-to-end (E2E) speech recognition models for our baseline models. The dataset is released publicly under a Creative Commons BY-NC-ND 4.0 license and can be accessed through the project repository. See https://github.com/unza-speech-lab/zambezi-voice
Multilingual Zero Resource Speech Recognition Base on Self-Supervise Pre-Trained Acoustic Models
Oct 13, 2022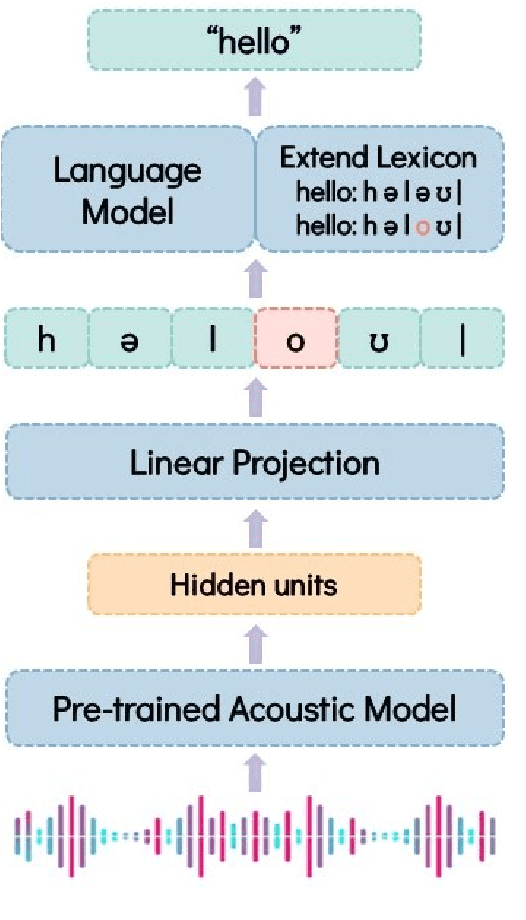
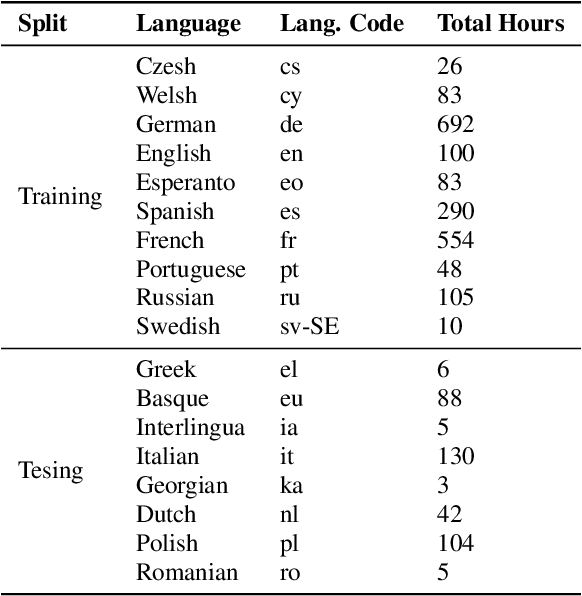
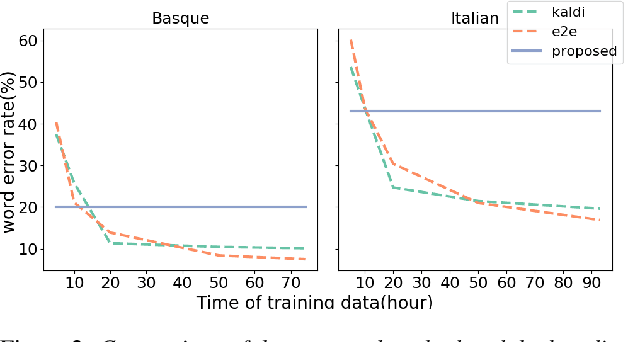
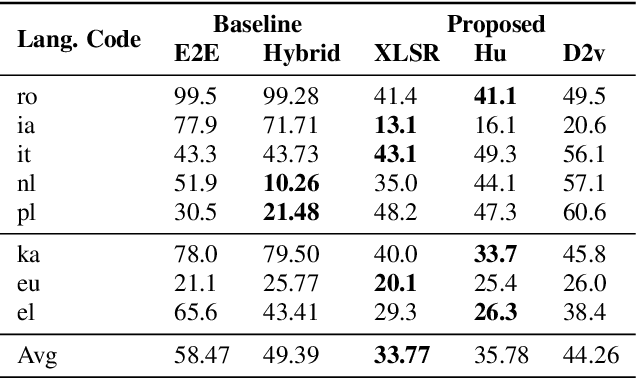
Labeled audio data is insufficient to build satisfying speech recognition systems for most of the languages in the world. There have been some zero-resource methods trying to perform phoneme or word-level speech recognition without labeled audio data of the target language, but the error rate of these methods is usually too high to be applied in real-world scenarios. Recently, the representation ability of self-supervise pre-trained models has been found to be extremely beneficial in zero-resource phoneme recognition. As far as we are concerned, this paper is the first attempt to extend the use of pre-trained models into word-level zero-resource speech recognition. This is done by fine-tuning the pre-trained models on IPA phoneme transcriptions and decoding with a language model trained on extra texts. Experiments on Wav2vec 2.0 and HuBERT models show that this method can achieve less than 20% word error rate on some languages, and the average error rate on 8 languages is 33.77%.
Emotions Beyond Words: Non-Speech Audio Emotion Recognition With Edge Computing
May 01, 2023

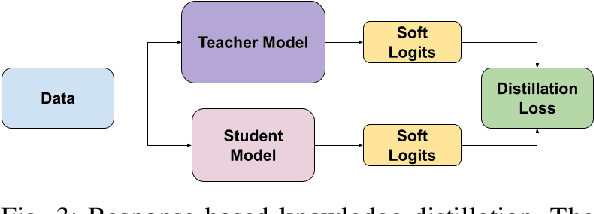
Non-speech emotion recognition has a wide range of applications including healthcare, crime control and rescue, and entertainment, to name a few. Providing these applications using edge computing has great potential, however, recent studies are focused on speech-emotion recognition using complex architectures. In this paper, a non-speech-based emotion recognition system is proposed, which can rely on edge computing to analyse emotions conveyed through non-speech expressions like screaming and crying. In particular, we explore knowledge distillation to design a computationally efficient system that can be deployed on edge devices with limited resources without degrading the performance significantly. We comprehensively evaluate our proposed framework using two publicly available datasets and highlight its effectiveness by comparing the results with the well-known MobileNet model. Our results demonstrate the feasibility and effectiveness of using edge computing for non-speech emotion detection, which can potentially improve applications that rely on emotion detection in communication networks. To the best of our knowledge, this is the first work on an edge-computing-based framework for detecting emotions in non-speech audio, offering promising directions for future research.
PEFT-SER: On the Use of Parameter Efficient Transfer Learning Approaches For Speech Emotion Recognition Using Pre-trained Speech Models
Jun 08, 2023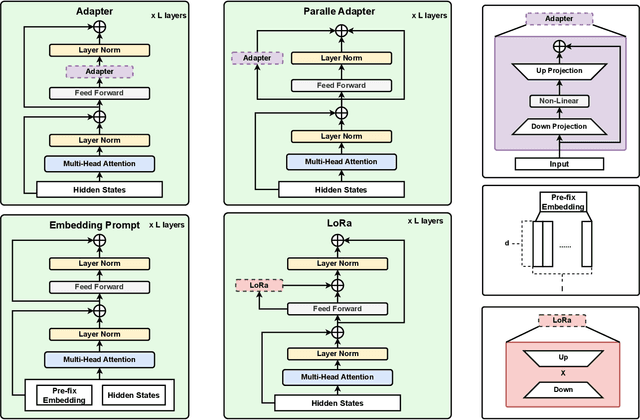
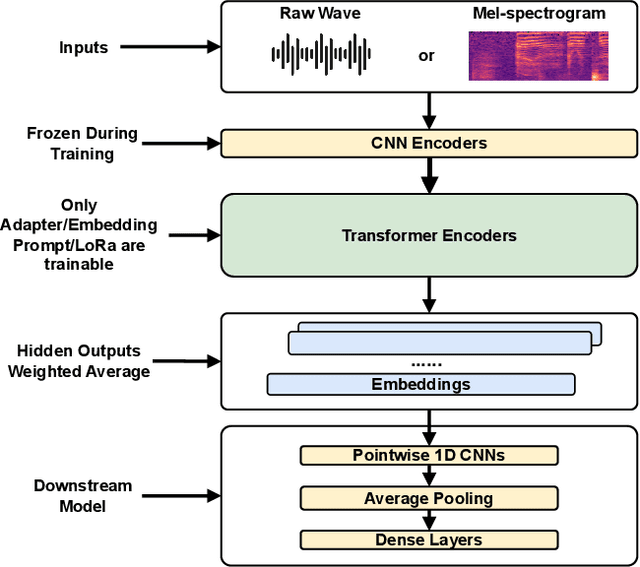

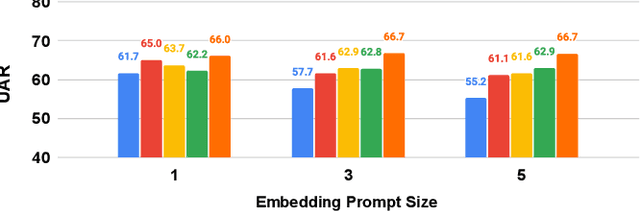
Many recent studies have focused on fine-tuning pre-trained models for speech emotion recognition (SER), resulting in promising performance compared to traditional methods that rely largely on low-level, knowledge-inspired acoustic features. These pre-trained speech models learn general-purpose speech representations using self-supervised or weakly-supervised learning objectives from large-scale datasets. Despite the significant advances made in SER through the use of pre-trained architecture, fine-tuning these large pre-trained models for different datasets requires saving copies of entire weight parameters, rendering them impractical to deploy in real-world settings. As an alternative, this work explores parameter-efficient fine-tuning (PEFT) approaches for adapting pre-trained speech models for emotion recognition. Specifically, we evaluate the efficacy of adapter tuning, embedding prompt tuning, and LoRa (Low-rank approximation) on four popular SER testbeds. Our results reveal that LoRa achieves the best fine-tuning performance in emotion recognition while enhancing fairness and requiring only a minimal extra amount of weight parameters. Furthermore, our findings offer novel insights into future research directions in SER, distinct from existing approaches focusing on directly fine-tuning the model architecture. Our code is publicly available under: https://github.com/usc-sail/peft-ser.
Modality Confidence Aware Training for Robust End-to-End Spoken Language Understanding
Jul 22, 2023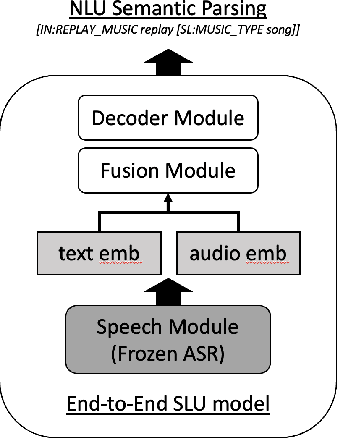
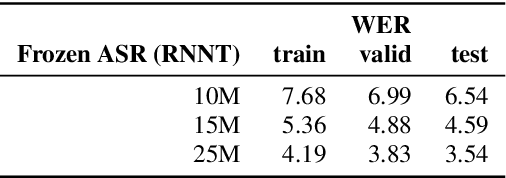
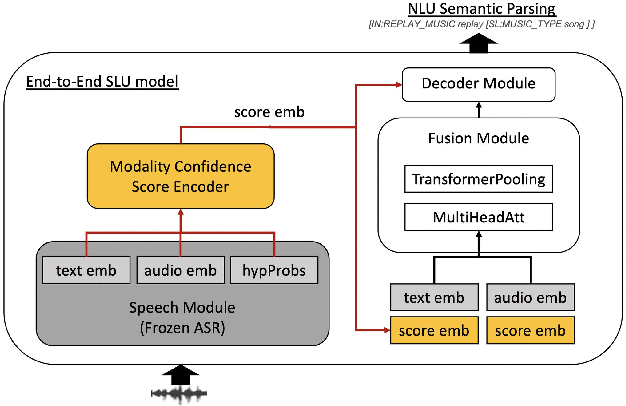

End-to-end (E2E) spoken language understanding (SLU) systems that generate a semantic parse from speech have become more promising recently. This approach uses a single model that utilizes audio and text representations from pre-trained speech recognition models (ASR), and outperforms traditional pipeline SLU systems in on-device streaming scenarios. However, E2E SLU systems still show weakness when text representation quality is low due to ASR transcription errors. To overcome this issue, we propose a novel E2E SLU system that enhances robustness to ASR errors by fusing audio and text representations based on the estimated modality confidence of ASR hypotheses. We introduce two novel techniques: 1) an effective method to encode the quality of ASR hypotheses and 2) an effective approach to integrate them into E2E SLU models. We show accuracy improvements on STOP dataset and share the analysis to demonstrate the effectiveness of our approach.
Compensating Removed Frequency Components: Thwarting Voice Spectrum Reduction Attacks
Aug 18, 2023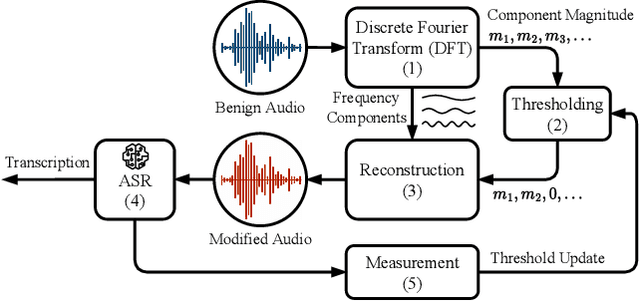
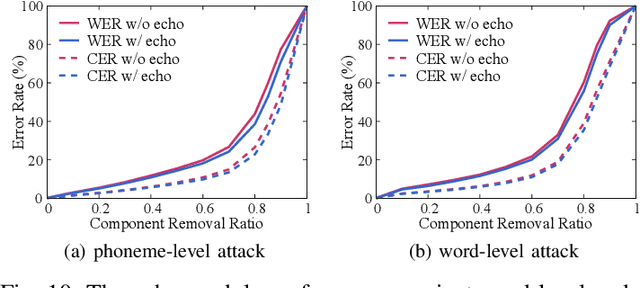
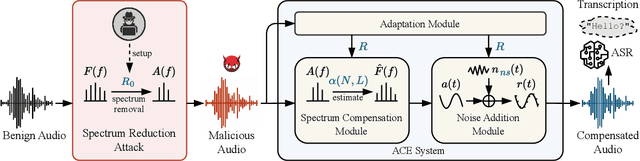
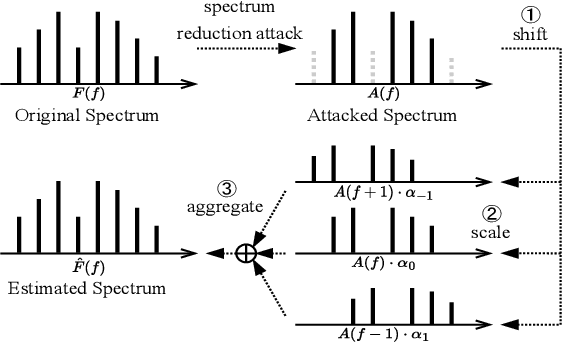
Automatic speech recognition (ASR) provides diverse audio-to-text services for humans to communicate with machines. However, recent research reveals ASR systems are vulnerable to various malicious audio attacks. In particular, by removing the non-essential frequency components, a new spectrum reduction attack can generate adversarial audios that can be perceived by humans but cannot be correctly interpreted by ASR systems. It raises a new challenge for content moderation solutions to detect harmful content in audio and video available on social media platforms. In this paper, we propose an acoustic compensation system named ACE to counter the spectrum reduction attacks over ASR systems. Our system design is based on two observations, namely, frequency component dependencies and perturbation sensitivity. First, since the Discrete Fourier Transform computation inevitably introduces spectral leakage and aliasing effects to the audio frequency spectrum, the frequency components with similar frequencies will have a high correlation. Thus, considering the intrinsic dependencies between neighboring frequency components, it is possible to recover more of the original audio by compensating for the removed components based on the remaining ones. Second, since the removed components in the spectrum reduction attacks can be regarded as an inverse of adversarial noise, the attack success rate will decrease when the adversarial audio is replayed in an over-the-air scenario. Hence, we can model the acoustic propagation process to add over-the-air perturbations into the attacked audio. We implement a prototype of ACE and the experiments show ACE can effectively reduce up to 87.9% of ASR inference errors caused by spectrum reduction attacks. Also, by analyzing residual errors, we summarize six general types of ASR inference errors and investigate the error causes and potential mitigation solutions.
Improving Speech Emotion Recognition Performance using Differentiable Architecture Search
May 23, 2023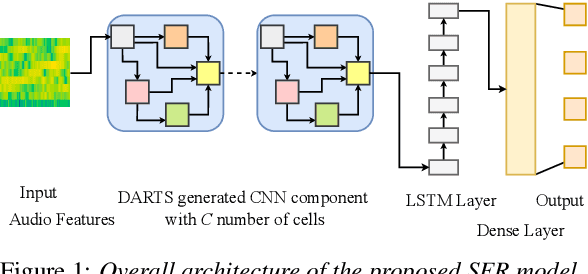
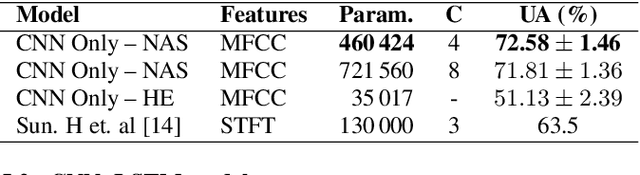
Speech Emotion Recognition (SER) is a critical enabler of emotion-aware communication in human-computer interactions. Deep Learning (DL) has improved the performance of SER models by improving model complexity. However, designing DL architectures requires prior experience and experimental evaluations. Encouragingly, Neural Architecture Search (NAS) allows automatic search for an optimum DL model. In particular, Differentiable Architecture Search (DARTS) is an efficient method of using NAS to search for optimised models. In this paper, we propose DARTS for a joint CNN and LSTM architecture for improving SER performance. Our choice of the CNN LSTM coupling is inspired by results showing that similar models offer improved performance. While SER researchers have considered CNNs and RNNs separately, the viability of using DARTs jointly for CNN and LSTM still needs exploration. Experimenting with the IEMOCAP dataset, we demonstrate that our approach outperforms best-reported results using DARTS for SER.
An Automatic Speech Recognition System for Bengali Language based on Wav2Vec2 and Transfer Learning
Sep 20, 2022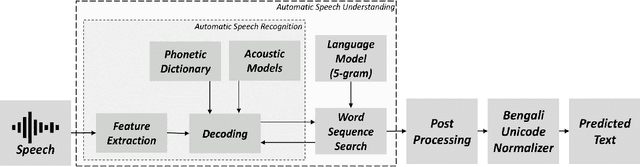
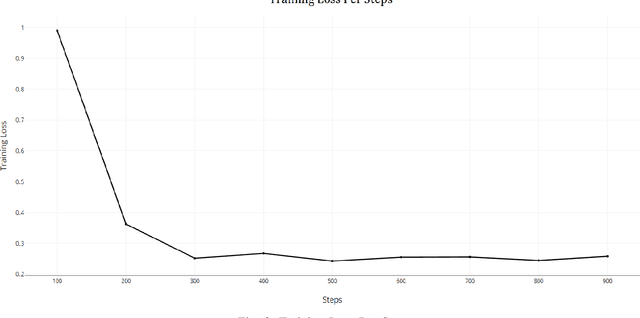
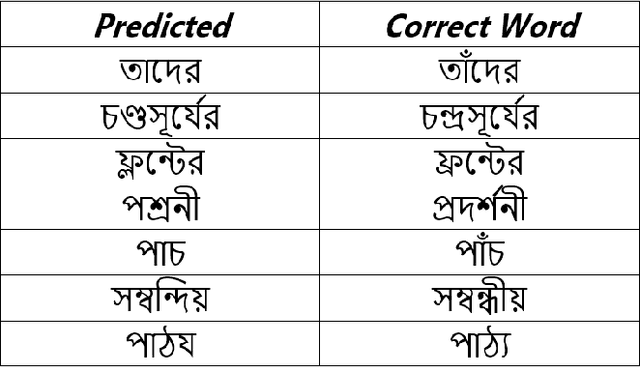
An independent, automated method of decoding and transcribing oral speech is known as automatic speech recognition (ASR). A typical ASR system extracts feature from audio recordings or streams and run one or more algorithms to map the features to corresponding texts. Numerous of research has been done in the field of speech signal processing in recent years. When given adequate resources, both conventional ASR and emerging end-to-end (E2E) speech recognition have produced promising results. However, for low-resource languages like Bengali, the current state of ASR lags behind, although the low resource state does not reflect upon the fact that this language is spoken by over 500 million people all over the world. Despite its popularity, there aren't many diverse open-source datasets available, which makes it difficult to conduct research on Bengali speech recognition systems. This paper is a part of the competition named `BUET CSE Fest DL Sprint'. The purpose of this paper is to improve the speech recognition performance of the Bengali language by adopting speech recognition technology on the E2E structure based on the transfer learning framework. The proposed method effectively models the Bengali language and achieves 3.819 score in `Levenshtein Mean Distance' on the test dataset of 7747 samples, when only 1000 samples of train dataset were used to train.
MAC: A unified framework boosting low resource automatic speech recognition
Feb 15, 2023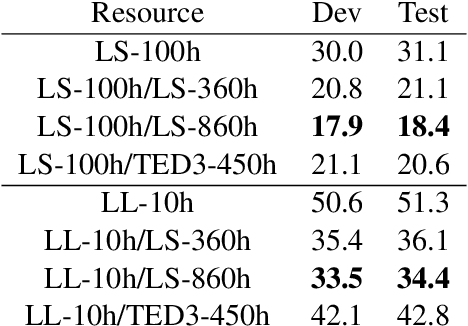
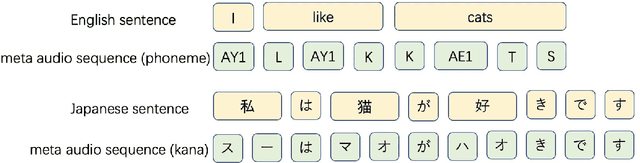
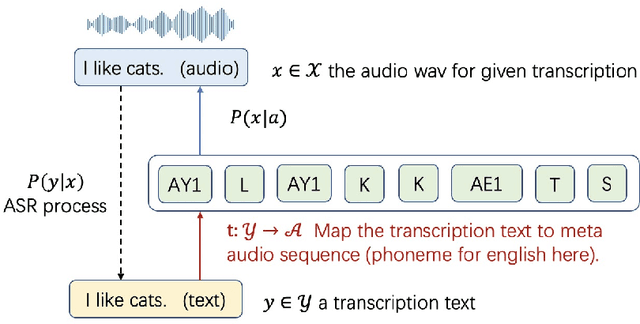
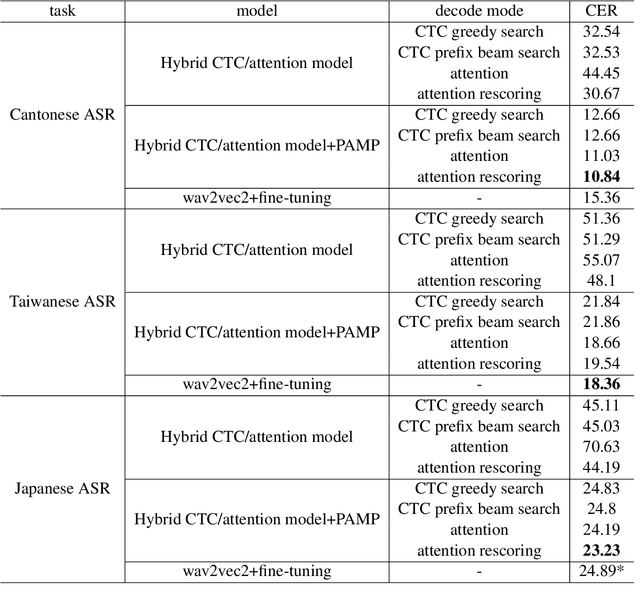
We propose a unified framework for low resource automatic speech recognition tasks named meta audio concatenation (MAC). It is easy to implement and can be carried out in extremely low resource environments. Mathematically, we give a clear description of MAC framework from the perspective of bayesian sampling. In this framework, we leverage a novel concatenative synthesis text-to-speech system to boost the low resource ASR task. By the concatenative synthesis text-to-speech system, we can integrate language pronunciation rules and adjust the TTS process. Furthermore, we propose a broad notion of meta audio set to meet the modeling needs of different languages and different scenes when using the system. Extensive experiments have demonstrated the great effectiveness of MAC on low resource ASR tasks. For CTC greedy search, CTC prefix, attention, and attention rescoring decode mode in Cantonese ASR task, Taiwanese ASR task, and Japanese ASR task the MAC method can reduce the CER by more than 15\%. Furthermore, in the ASR task, MAC beats wav2vec2 (with fine-tuning) on common voice datasets of Cantonese and gets really competitive results on common voice datasets of Taiwanese and Japanese. Among them, it is worth mentioning that we achieve a \textbf{10.9\%} character error rate (CER) on the common voice Cantonese ASR task, bringing about \textbf{30\%} relative improvement compared to the wav2vec2 (with fine-tuning).