 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Learning Emotional Representations from Imbalanced Speech Data for Speech Emotion Recognition and Emotional Text-to-Speech
Jun 09, 2023
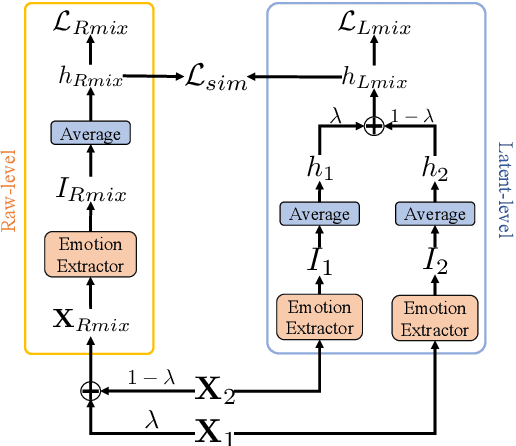
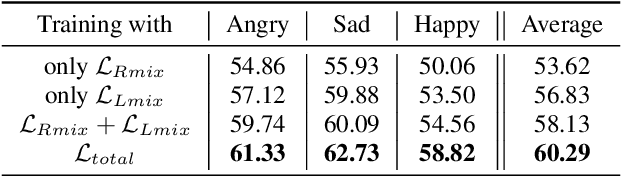
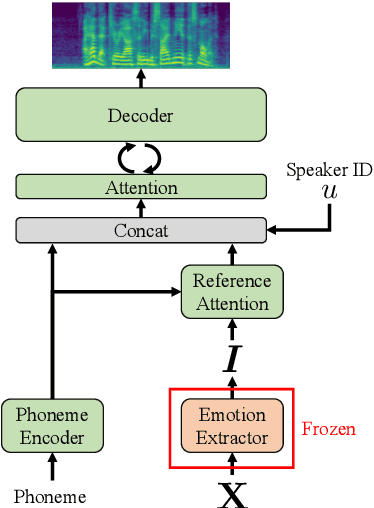
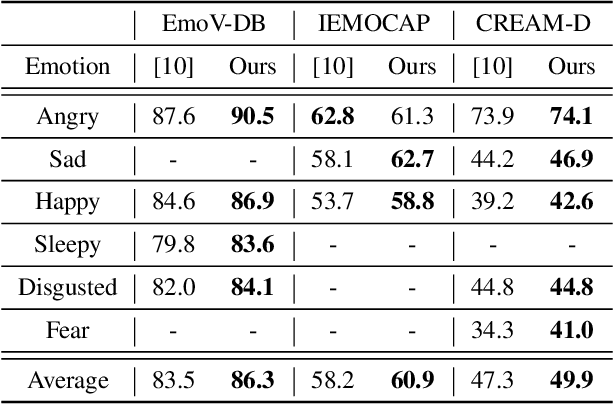
Effective speech emotional representations play a key role in Speech Emotion Recognition (SER) and Emotional Text-To-Speech (TTS) tasks. However, emotional speech samples are more difficult and expensive to acquire compared with Neutral style speech, which causes one issue that most related works unfortunately neglect: imbalanced datasets. Models might overfit to the majority Neutral class and fail to produce robust and effective emotional representations. In this paper, we propose an Emotion Extractor to address this issue. We use augmentation approaches to train the model and enable it to extract effective and generalizable emotional representations from imbalanced datasets. Our empirical results show that (1) for the SER task, the proposed Emotion Extractor surpasses the state-of-the-art baseline on three imbalanced datasets; (2) the produced representations from our Emotion Extractor benefit the TTS model, and enable it to synthesize more expressive speech.
Accented Speech Recognition under the Indian context
Sep 11, 2022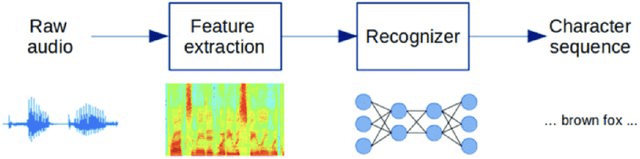
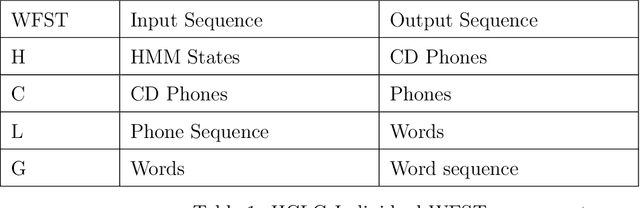
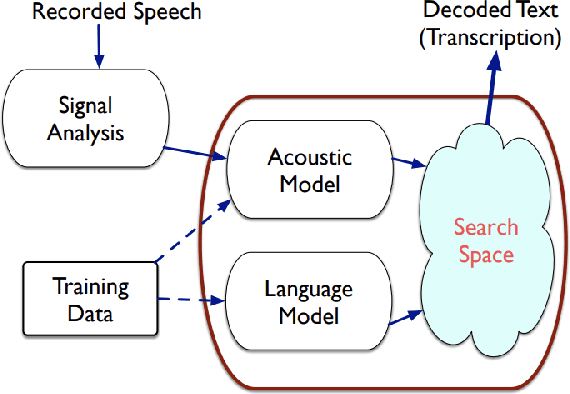
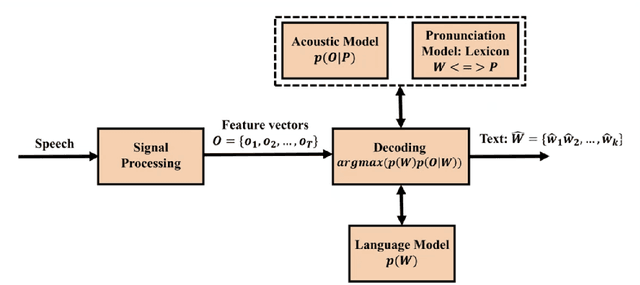
Accent forms an integral part of identifying cultures, emotions, behavior'ss, etc. People often perceive each other in a different manner due to their accent. The accent itself can be a conveyor of status, pride, and other emotional information which can be captured through Speech itself. Accent itself can be defined as: "the way in which people in a particular area, country, or social group pronounce words" or "a special emphasis given to a syllable in a word, word in a sentence, or note in a set of musical notes". Accented Speech Recognition is one the most important problems in the domain of Speech Recognition. Speech recognition is an interdisciplinary sub-field of Computer Science and Linguistics research where the main aim is to develop technologies which enable conversion of speech into text. The speech can be of any form such as read speech or spontaneous speech, conversational speech. As all instances of language utterances are present speech is very diverse and exhibits many traits of variability. This diversity stems from the environmental conditions, variabilities from speaker to speaker, channel noise, differences in Speech production due to disabilities, presence of disfluencies. Speech therefore is indeed a rich source of information waiting to be exploited.
ASR and Emotional Speech: A Word-Level Investigation of the Mutual Impact of Speech and Emotion Recognition
May 25, 2023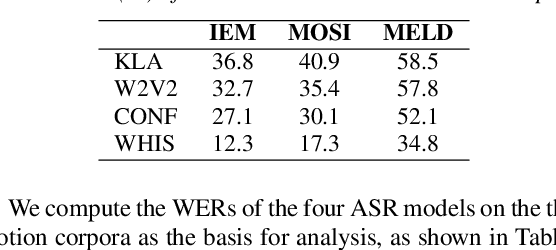
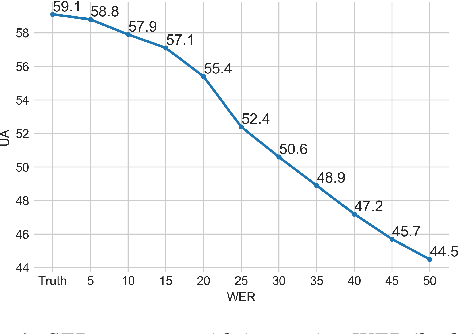
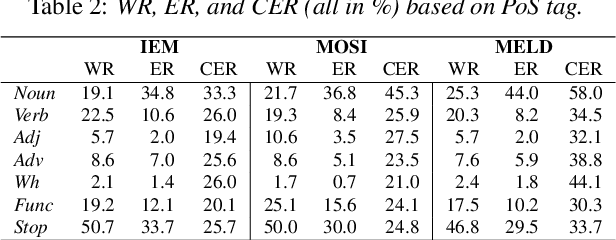
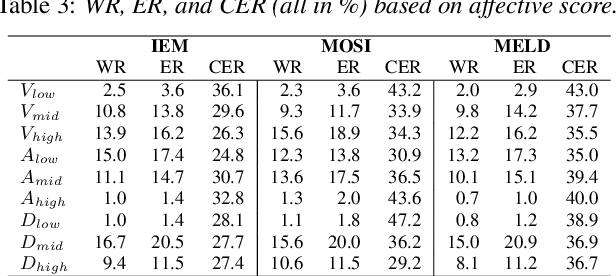
In Speech Emotion Recognition (SER), textual data is often used alongside audio signals to address their inherent variability. However, the reliance on human annotated text in most research hinders the development of practical SER systems. To overcome this challenge, we investigate how Automatic Speech Recognition (ASR) performs on emotional speech by analyzing the ASR performance on emotion corpora and examining the distribution of word errors and confidence scores in ASR transcripts to gain insight into how emotion affects ASR. We utilize four ASR systems, namely Kaldi ASR, wav2vec, Conformer, and Whisper, and three corpora: IEMOCAP, MOSI, and MELD to ensure generalizability. Additionally, we conduct text-based SER on ASR transcripts with increasing word error rates to investigate how ASR affects SER. The objective of this study is to uncover the relationship and mutual impact of ASR and SER, in order to facilitate ASR adaptation to emotional speech and the use of SER in real world.
Continual Learning for On-Device Speech Recognition using Disentangled Conformers
Dec 13, 2022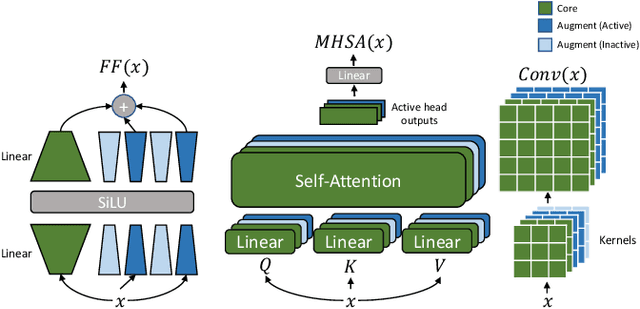
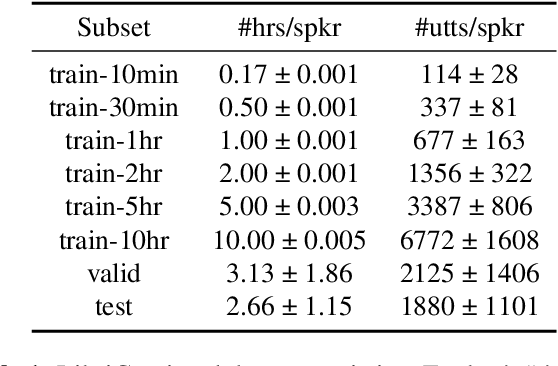
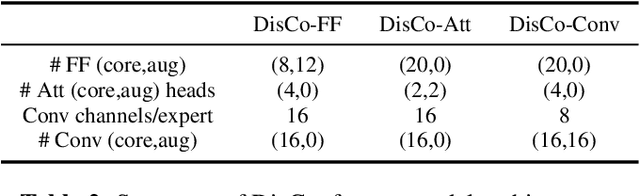
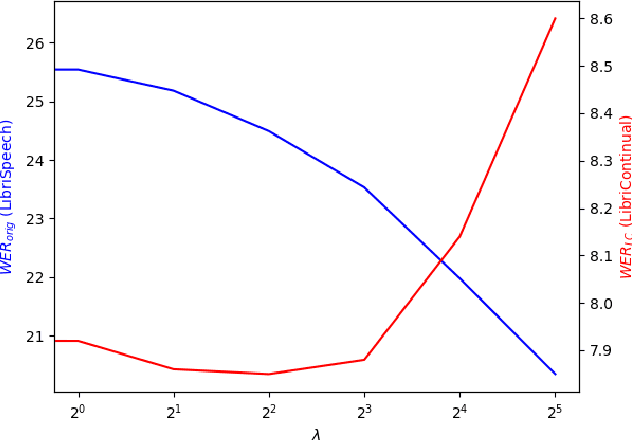
Automatic speech recognition research focuses on training and evaluating on static datasets. Yet, as speech models are increasingly deployed on personal devices, such models encounter user-specific distributional shifts. To simulate this real-world scenario, we introduce LibriContinual, a continual learning benchmark for speaker-specific domain adaptation derived from LibriVox audiobooks, with data corresponding to 118 individual speakers and 6 train splits per speaker of different sizes. Additionally, current speech recognition models and continual learning algorithms are not optimized to be compute-efficient. We adapt a general-purpose training algorithm NetAug for ASR and create a novel Conformer variant called the DisConformer (Disentangled Conformer). This algorithm produces ASR models consisting of a frozen 'core' network for general-purpose use and several tunable 'augment' networks for speaker-specific tuning. Using such models, we propose a novel compute-efficient continual learning algorithm called DisentangledCL. Our experiments show that the DisConformer models significantly outperform baselines on general ASR i.e. LibriSpeech (15.58% rel. WER on test-other). On speaker-specific LibriContinual they significantly outperform trainable-parameter-matched baselines (by 20.65% rel. WER on test) and even match fully finetuned baselines in some settings.
Stabilising and accelerating light gated recurrent units for automatic speech recognition
Feb 16, 2023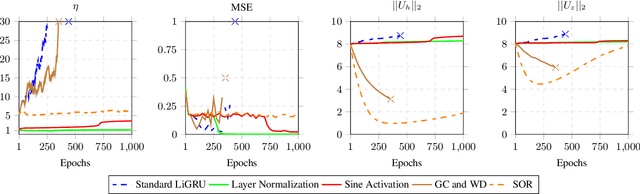

The light gated recurrent units (Li-GRU) is well-known for achieving impressive results in automatic speech recognition (ASR) tasks while being lighter and faster to train than a standard gated recurrent units (GRU). However, the unbounded nature of its rectified linear unit on the candidate recurrent gate induces an important gradient exploding phenomenon disrupting the training process and preventing it from being applied to famous datasets. In this paper, we theoretically and empirically derive the necessary conditions for its stability as well as engineering mechanisms to speed up by a factor of five its training time, hence introducing a novel version of this architecture named SLi-GRU. Then, we evaluate its performance both on a toy task illustrating its newly acquired capabilities and a set of three different ASR datasets demonstrating lower word error rates compared to more complex recurrent neural networks.
Neural approaches to spoken content embedding
Aug 28, 2023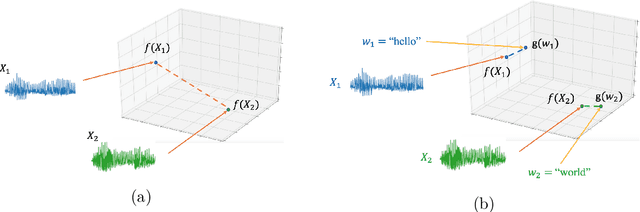
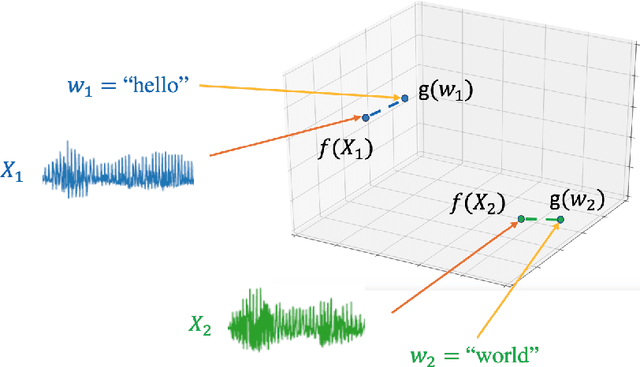
Comparing spoken segments is a central operation to speech processing. Traditional approaches in this area have favored frame-level dynamic programming algorithms, such as dynamic time warping, because they require no supervision, but they are limited in performance and efficiency. As an alternative, acoustic word embeddings -- fixed-dimensional vector representations of variable-length spoken word segments -- have begun to be considered for such tasks as well. However, the current space of such discriminative embedding models, training approaches, and their application to real-world downstream tasks is limited. We start by considering ``single-view" training losses where the goal is to learn an acoustic word embedding model that separates same-word and different-word spoken segment pairs. Then, we consider ``multi-view" contrastive losses. In this setting, acoustic word embeddings are learned jointly with embeddings of character sequences to generate acoustically grounded embeddings of written words, or acoustically grounded word embeddings. In this thesis, we contribute new discriminative acoustic word embedding (AWE) and acoustically grounded word embedding (AGWE) approaches based on recurrent neural networks (RNNs). We improve model training in terms of both efficiency and performance. We take these developments beyond English to several low-resource languages and show that multilingual training improves performance when labeled data is limited. We apply our embedding models, both monolingual and multilingual, to the downstream tasks of query-by-example speech search and automatic speech recognition. Finally, we show how our embedding approaches compare with and complement more recent self-supervised speech models.
Privacy-oriented manipulation of speaker representations
Oct 10, 2023Speaker embeddings are ubiquitous, with applications ranging from speaker recognition and diarization to speech synthesis and voice anonymisation. The amount of information held by these embeddings lends them versatility, but also raises privacy concerns. Speaker embeddings have been shown to contain information on age, sex, health and more, which speakers may want to keep private, especially when this information is not required for the target task. In this work, we propose a method for removing and manipulating private attributes from speaker embeddings that leverages a Vector-Quantized Variational Autoencoder architecture, combined with an adversarial classifier and a novel mutual information loss. We validate our model on two attributes, sex and age, and perform experiments with ignorant and fully-informed attackers, and with in-domain and out-of-domain data.
deHuBERT: Disentangling Noise in a Self-supervised Model for Robust Speech Recognition
Feb 28, 2023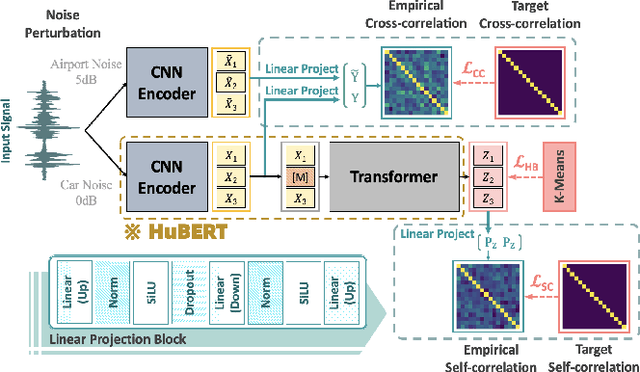
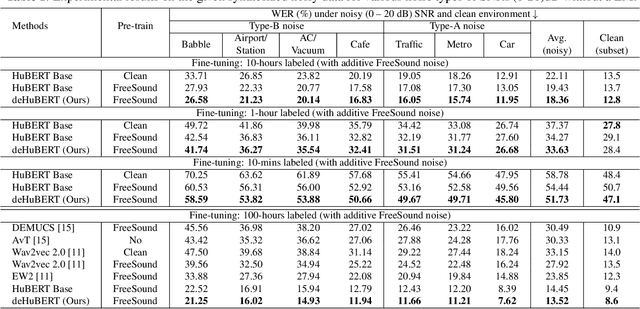

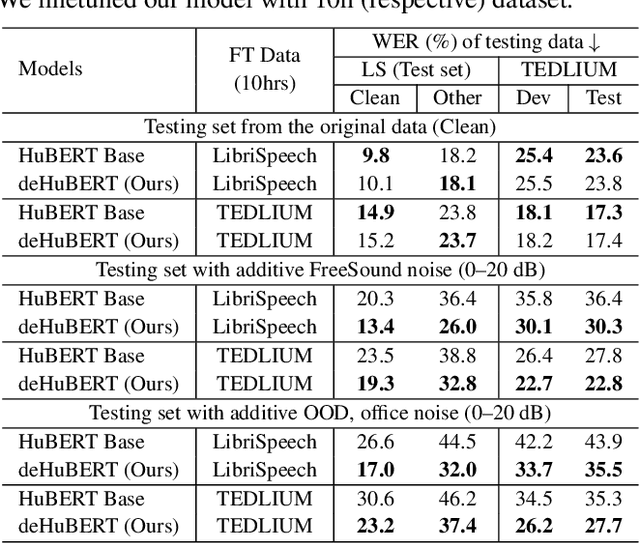
Existing self-supervised pre-trained speech models have offered an effective way to leverage massive unannotated corpora to build good automatic speech recognition (ASR). However, many current models are trained on a clean corpus from a single source, which tends to do poorly when noise is present during testing. Nonetheless, it is crucial to overcome the adverse influence of noise for real-world applications. In this work, we propose a novel training framework, called deHuBERT, for noise reduction encoding inspired by H. Barlow's redundancy-reduction principle. The new framework improves the HuBERT training algorithm by introducing auxiliary losses that drive the self- and cross-correlation matrix between pairwise noise-distorted embeddings towards identity matrix. This encourages the model to produce noise-agnostic speech representations. With this method, we report improved robustness in noisy environments, including unseen noises, without impairing the performance on the clean set.
Boosting Punctuation Restoration with Data Generation and Reinforcement Learning
Jul 24, 2023Punctuation restoration is an important task in automatic speech recognition (ASR) which aim to restore the syntactic structure of generated ASR texts to improve readability. While punctuated texts are abundant from written documents, the discrepancy between written punctuated texts and ASR texts limits the usability of written texts in training punctuation restoration systems for ASR texts. This paper proposes a reinforcement learning method to exploit in-topic written texts and recent advances in large pre-trained generative language models to bridge this gap. The experiments show that our method achieves state-of-the-art performance on the ASR test set on two benchmark datasets for punctuation restoration.
Contextual-Utterance Training for Automatic Speech Recognition
Oct 27, 2022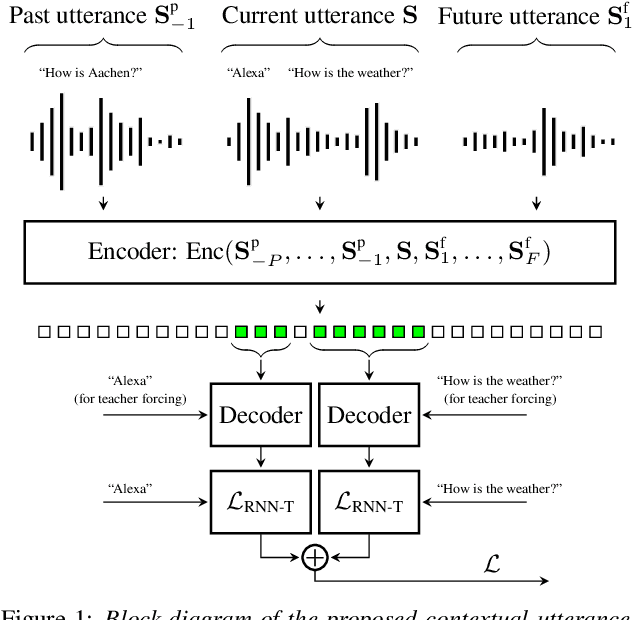
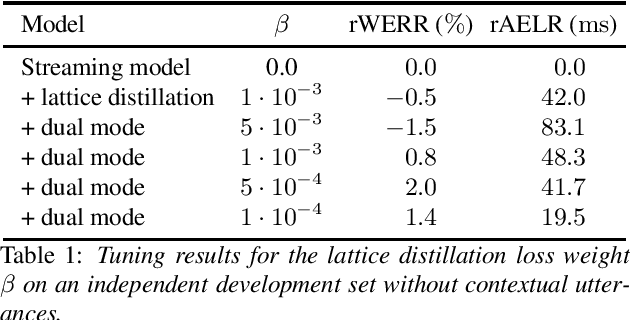
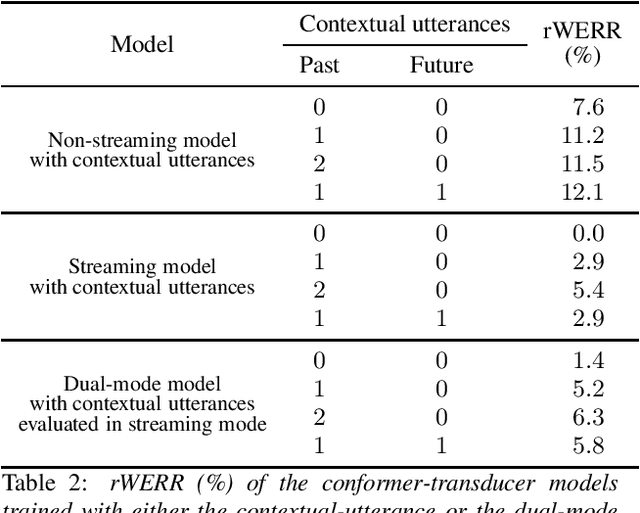

Recent studies of streaming automatic speech recognition (ASR) recurrent neural network transducer (RNN-T)-based systems have fed the encoder with past contextual information in order to improve its word error rate (WER) performance. In this paper, we first propose a contextual-utterance training technique which makes use of the previous and future contextual utterances in order to do an implicit adaptation to the speaker, topic and acoustic environment. Also, we propose a dual-mode contextual-utterance training technique for streaming automatic speech recognition (ASR) systems. This proposed approach allows to make a better use of the available acoustic context in streaming models by distilling "in-place" the knowledge of a teacher, which is able to see both past and future contextual utterances, to the student which can only see the current and past contextual utterances. The experimental results show that a conformer-transducer system trained with the proposed techniques outperforms the same system trained with the classical RNN-T loss. Specifically, the proposed technique is able to reduce both the WER and the average last token emission latency by more than 6% and 40ms relative, respectively.