 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Improving Rare Words Recognition through Homophone Extension and Unified Writing for Low-resource Cantonese Speech Recognition
Feb 02, 2023

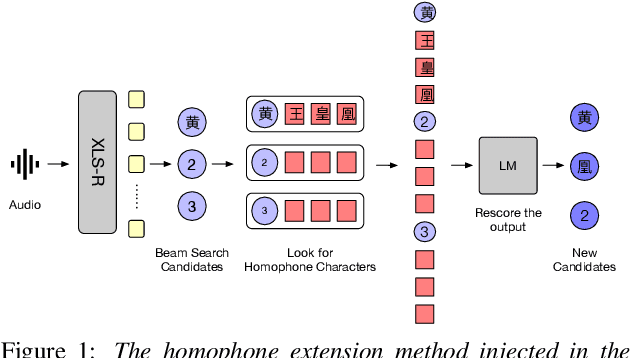
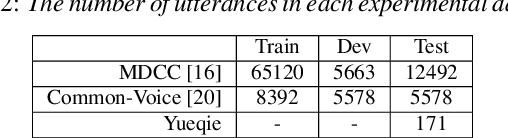
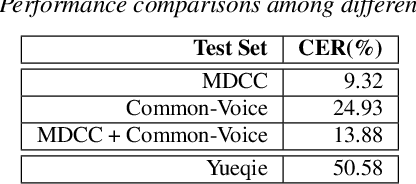
Homophone characters are common in tonal syllable-based languages, such as Mandarin and Cantonese. The data-intensive end-to-end Automatic Speech Recognition (ASR) systems are more likely to mis-recognize homophone characters and rare words under low-resource settings. For the problem of lowresource Cantonese speech recognition, this paper presents a novel homophone extension method to integrate human knowledge of the homophone lexicon into the beam search decoding process with language model re-scoring. Besides, we propose an automatic unified writing method to merge the variants of Cantonese characters and standardize speech annotation guidelines, which enables more efficient utilization of labeled utterances by providing more samples for the merged characters. We empirically show that both homophone extension and unified writing improve the recognition performance significantly on both in-domain and out-of-domain test sets, with an absolute Character Error Rate (CER) decrease of around 5% and 18%.
* The 13th International Symposium on Chinese Spoken Language Processing (ISCSLP 2022)
A Multi-Purpose Audio-Visual Corpus for Multi-Modal Persian Speech Recognition: the Arman-AV Dataset
Jan 21, 2023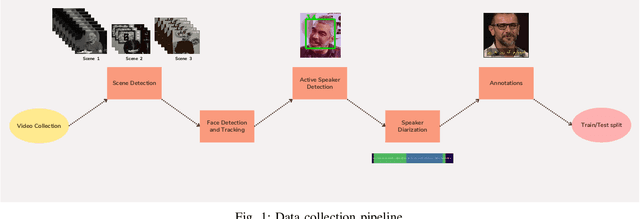

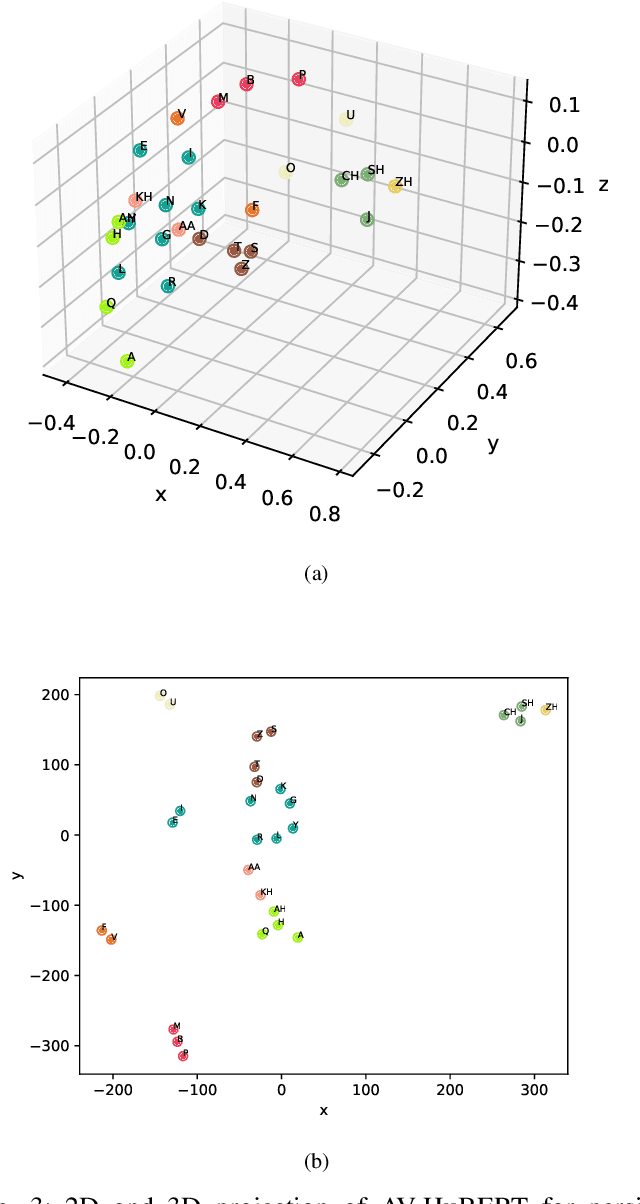
In recent years, significant progress has been made in automatic lip reading. But these methods require large-scale datasets that do not exist for many low-resource languages. In this paper, we have presented a new multipurpose audio-visual dataset for Persian. This dataset consists of almost 220 hours of videos with 1760 corresponding speakers. In addition to lip reading, the dataset is suitable for automatic speech recognition, audio-visual speech recognition, and speaker recognition. Also, it is the first large-scale lip reading dataset in Persian. A baseline method was provided for each mentioned task. In addition, we have proposed a technique to detect visemes (a visual equivalent of a phoneme) in Persian. The visemes obtained by this method increase the accuracy of the lip reading task by 7% relatively compared to the previously proposed visemes, which can be applied to other languages as well.
LeVoice ASR Systems for the ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge
Oct 17, 2022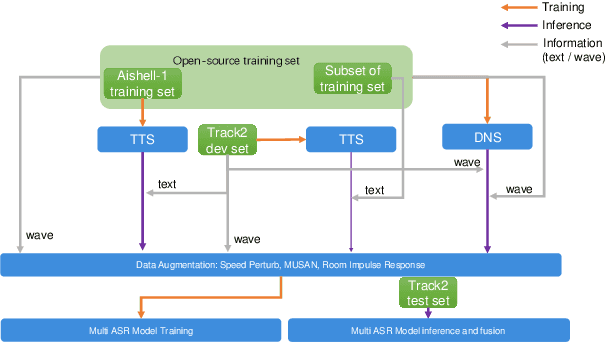
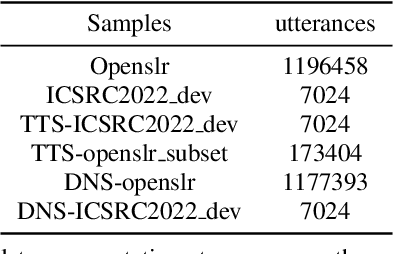
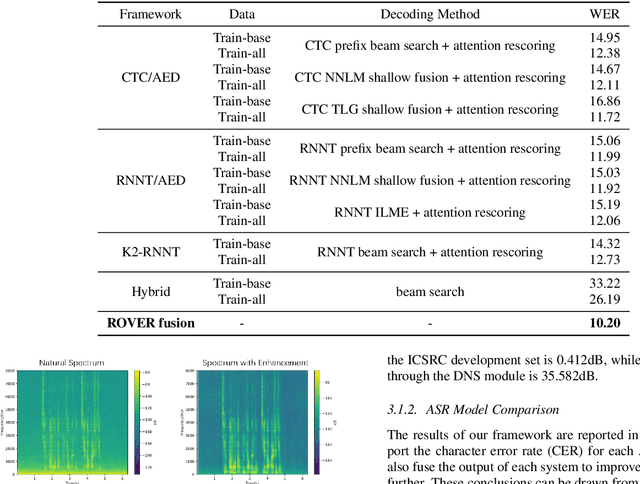
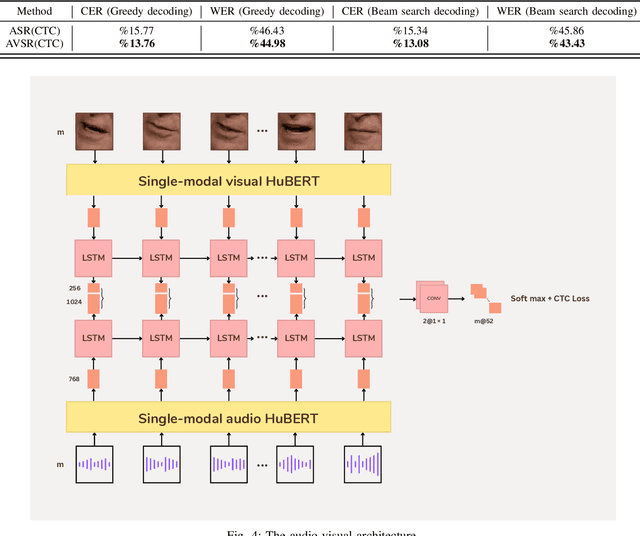
This paper describes LeVoice automatic speech recognition systems to track2 of intelligent cockpit speech recognition challenge 2022. Track2 is a speech recognition task without limits on the scope of model size. Our main points include deep learning based speech enhancement, text-to-speech based speech generation, training data augmentation via various techniques and speech recognition model fusion. We compared and fused the hybrid architecture and two kinds of end-to-end architecture. For end-to-end modeling, we used models based on connectionist temporal classification/attention-based encoder-decoder architecture and recurrent neural network transducer/attention-based encoder-decoder architecture. The performance of these models is evaluated with an additional language model to improve word error rates. As a result, our system achieved 10.2\% character error rate on the challenge test set data and ranked third place among the submitted systems in the challenge.
Clinical BERTScore: An Improved Measure of Automatic Speech Recognition Performance in Clinical Settings
Mar 13, 2023
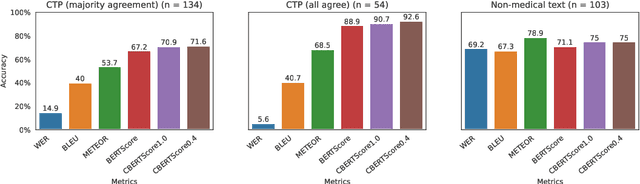
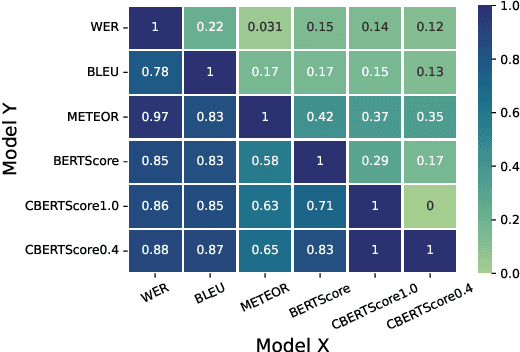
Automatic Speech Recognition (ASR) in medical contexts has the potential to save time, cut costs, increase report accuracy, and reduce physician burnout. However, the healthcare industry has been slower to adopt this technology, in part due to the importance of avoiding medically-relevant transcription mistakes. In this work, we present the Clinical BERTScore (CBERTScore), an ASR metric that penalizes clinically-relevant mistakes more than others. We demonstrate that this metric more closely aligns with clinician preferences on medical sentences as compared to other metrics (WER, BLUE, METEOR, etc), sometimes by wide margins. We collect a benchmark of 13 clinician preferences on 149 realistic medical sentences called the Clinician Transcript Preference benchmark (CTP), demonstrate that CBERTScore more closely matches what clinicians prefer, and release the benchmark for the community to further develop clinically-aware ASR metrics.
PAMP: A unified framework boosting low resource automatic speech recognition
Feb 05, 2023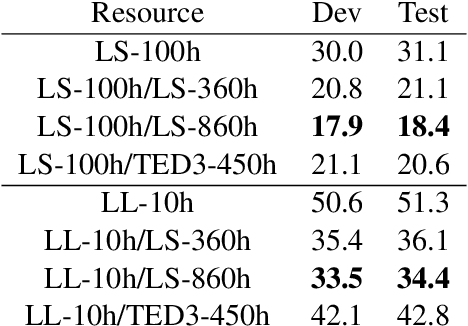
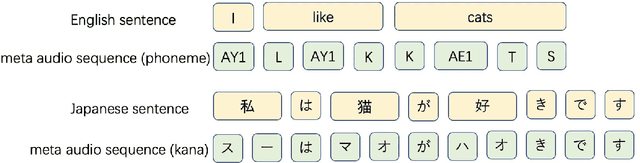
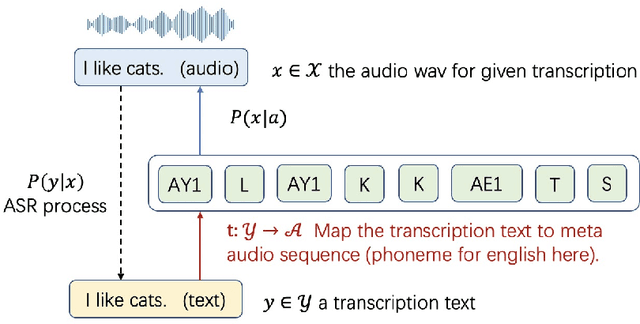
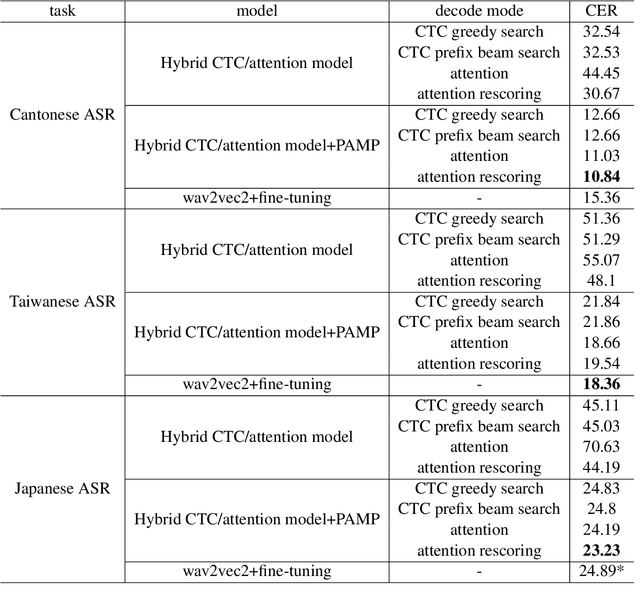
We propose a novel text-to-speech (TTS) data augmentation framework for low resource automatic speech recognition (ASR) tasks, named phoneme audio mix up (PAMP). The PAMP method is highly interpretable and can incorporate prior knowledge of pronunciation rules. Furthermore, PAMP can be easily deployed in almost any language, extremely for low resource ASR tasks. Extensive experiments have demonstrated the great effectiveness of PAMP on low resource ASR tasks: we achieve a \textbf{10.84\%} character error rate (CER) on the common voice Cantonese ASR task, bringing a great relative improvement of about \textbf{30\%} compared to the previous state-of-the-art which was achieved by fine-tuning the wav2vec2 pretrained model.
Sparks of Large Audio Models: A Survey and Outlook
Aug 24, 2023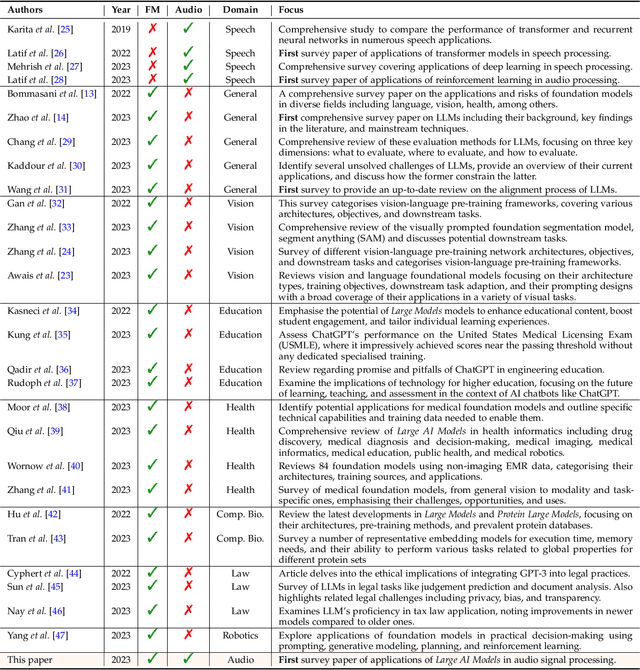

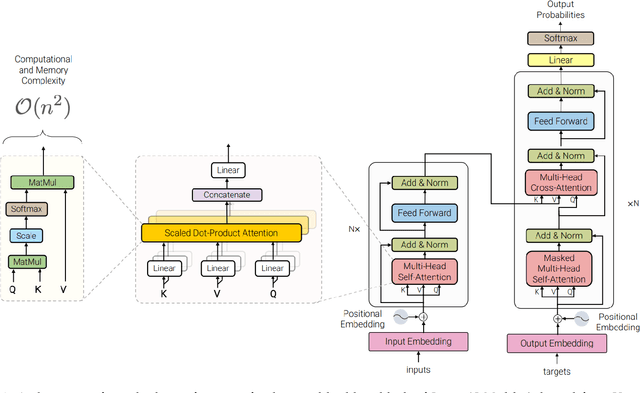
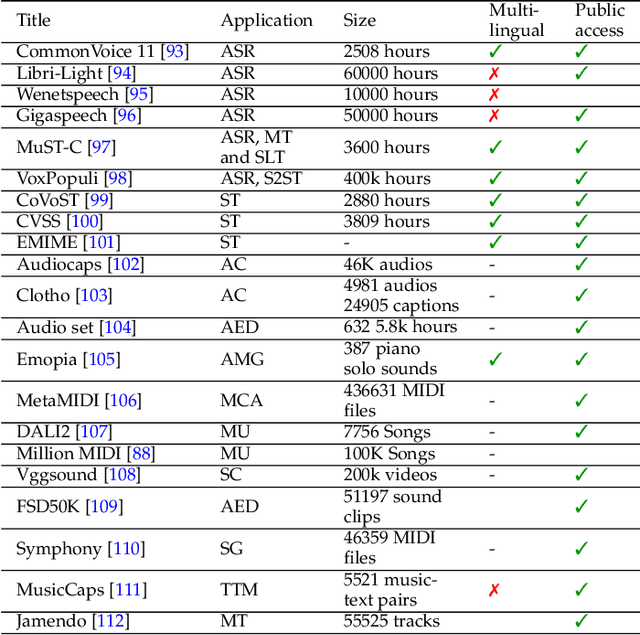
This survey paper provides a comprehensive overview of the recent advancements and challenges in applying large language models to the field of audio signal processing. Audio processing, with its diverse signal representations and a wide range of sources--from human voices to musical instruments and environmental sounds--poses challenges distinct from those found in traditional Natural Language Processing scenarios. Nevertheless, \textit{Large Audio Models}, epitomized by transformer-based architectures, have shown marked efficacy in this sphere. By leveraging massive amount of data, these models have demonstrated prowess in a variety of audio tasks, spanning from Automatic Speech Recognition and Text-To-Speech to Music Generation, among others. Notably, recently these Foundational Audio Models, like SeamlessM4T, have started showing abilities to act as universal translators, supporting multiple speech tasks for up to 100 languages without any reliance on separate task-specific systems. This paper presents an in-depth analysis of state-of-the-art methodologies regarding \textit{Foundational Large Audio Models}, their performance benchmarks, and their applicability to real-world scenarios. We also highlight current limitations and provide insights into potential future research directions in the realm of \textit{Large Audio Models} with the intent to spark further discussion, thereby fostering innovation in the next generation of audio-processing systems. Furthermore, to cope with the rapid development in this area, we will consistently update the relevant repository with relevant recent articles and their open-source implementations at https://github.com/EmulationAI/awesome-large-audio-models.
End-to-End Open Vocabulary Keyword Search With Multilingual Neural Representations
Aug 15, 2023Conventional keyword search systems operate on automatic speech recognition (ASR) outputs, which causes them to have a complex indexing and search pipeline. This has led to interest in ASR-free approaches to simplify the search procedure. We recently proposed a neural ASR-free keyword search model which achieves competitive performance while maintaining an efficient and simplified pipeline, where queries and documents are encoded with a pair of recurrent neural network encoders and the encodings are combined with a dot-product. In this article, we extend this work with multilingual pretraining and detailed analysis of the model. Our experiments show that the proposed multilingual training significantly improves the model performance and that despite not matching a strong ASR-based conventional keyword search system for short queries and queries comprising in-vocabulary words, the proposed model outperforms the ASR-based system for long queries and queries that do not appear in the training data.
* Accepted by IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2023
SynthVSR: Scaling Up Visual Speech Recognition With Synthetic Supervision
Apr 03, 2023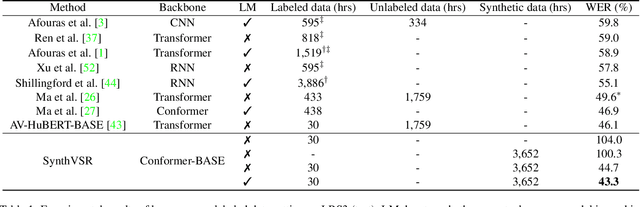
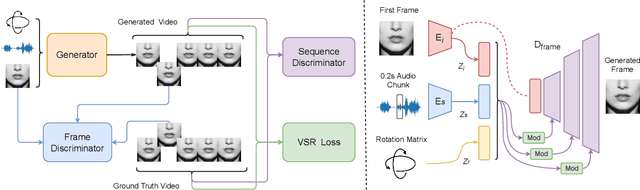
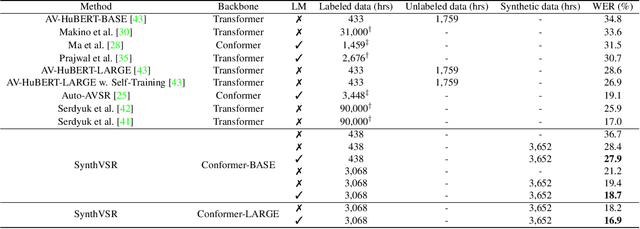

Recently reported state-of-the-art results in visual speech recognition (VSR) often rely on increasingly large amounts of video data, while the publicly available transcribed video datasets are limited in size. In this paper, for the first time, we study the potential of leveraging synthetic visual data for VSR. Our method, termed SynthVSR, substantially improves the performance of VSR systems with synthetic lip movements. The key idea behind SynthVSR is to leverage a speech-driven lip animation model that generates lip movements conditioned on the input speech. The speech-driven lip animation model is trained on an unlabeled audio-visual dataset and could be further optimized towards a pre-trained VSR model when labeled videos are available. As plenty of transcribed acoustic data and face images are available, we are able to generate large-scale synthetic data using the proposed lip animation model for semi-supervised VSR training. We evaluate the performance of our approach on the largest public VSR benchmark - Lip Reading Sentences 3 (LRS3). SynthVSR achieves a WER of 43.3% with only 30 hours of real labeled data, outperforming off-the-shelf approaches using thousands of hours of video. The WER is further reduced to 27.9% when using all 438 hours of labeled data from LRS3, which is on par with the state-of-the-art self-supervised AV-HuBERT method. Furthermore, when combined with large-scale pseudo-labeled audio-visual data SynthVSR yields a new state-of-the-art VSR WER of 16.9% using publicly available data only, surpassing the recent state-of-the-art approaches trained with 29 times more non-public machine-transcribed video data (90,000 hours). Finally, we perform extensive ablation studies to understand the effect of each component in our proposed method.
Cross-Corpus Multilingual Speech Emotion Recognition: Amharic vs. Other Languages
Jul 20, 2023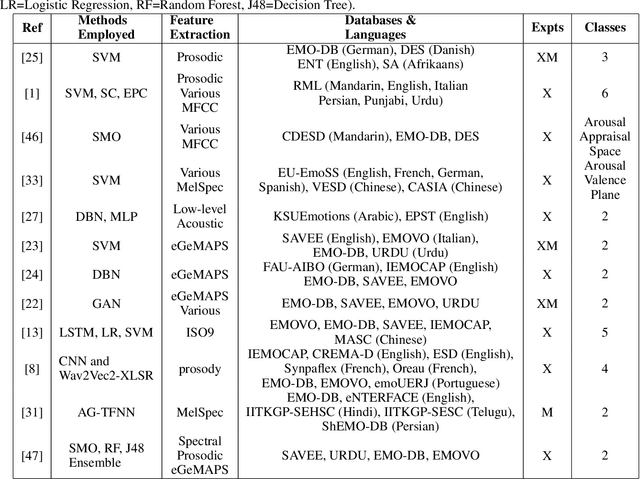
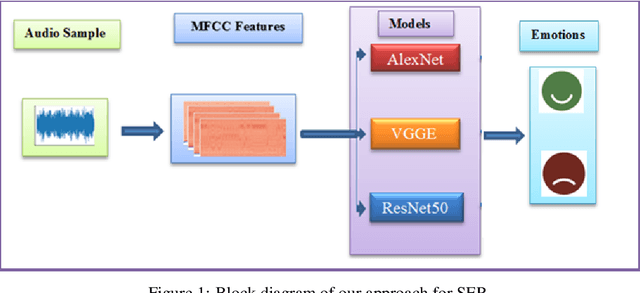
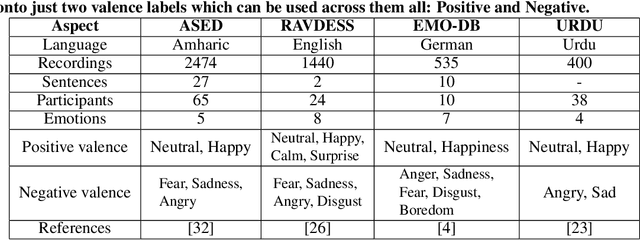
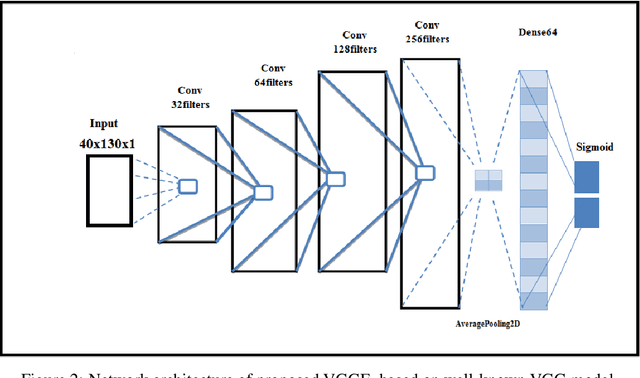
In a conventional Speech emotion recognition (SER) task, a classifier for a given language is trained on a pre-existing dataset for that same language. However, where training data for a language does not exist, data from other languages can be used instead. We experiment with cross-lingual and multilingual SER, working with Amharic, English, German and URDU. For Amharic, we use our own publicly-available Amharic Speech Emotion Dataset (ASED). For English, German and Urdu we use the existing RAVDESS, EMO-DB and URDU datasets. We followed previous research in mapping labels for all datasets to just two classes, positive and negative. Thus we can compare performance on different languages directly, and combine languages for training and testing. In Experiment 1, monolingual SER trials were carried out using three classifiers, AlexNet, VGGE (a proposed variant of VGG), and ResNet50. Results averaged for the three models were very similar for ASED and RAVDESS, suggesting that Amharic and English SER are equally difficult. Similarly, German SER is more difficult, and Urdu SER is easier. In Experiment 2, we trained on one language and tested on another, in both directions for each pair: Amharic<->German, Amharic<->English, and Amharic<->Urdu. Results with Amharic as target suggested that using English or German as source will give the best result. In Experiment 3, we trained on several non-Amharic languages and then tested on Amharic. The best accuracy obtained was several percent greater than the best accuracy in Experiment 2, suggesting that a better result can be obtained when using two or three non-Amharic languages for training than when using just one non-Amharic language. Overall, the results suggest that cross-lingual and multilingual training can be an effective strategy for training a SER classifier when resources for a language are scarce.
Decoupled Structure for Improved Adaptability of End-to-End Models
Aug 25, 2023Although end-to-end (E2E) trainable automatic speech recognition (ASR) has shown great success by jointly learning acoustic and linguistic information, it still suffers from the effect of domain shifts, thus limiting potential applications. The E2E ASR model implicitly learns an internal language model (LM) which characterises the training distribution of the source domain, and the E2E trainable nature makes the internal LM difficult to adapt to the target domain with text-only data To solve this problem, this paper proposes decoupled structures for attention-based encoder-decoder (Decoupled-AED) and neural transducer (Decoupled-Transducer) models, which can achieve flexible domain adaptation in both offline and online scenarios while maintaining robust intra-domain performance. To this end, the acoustic and linguistic parts of the E2E model decoder (or prediction network) are decoupled, making the linguistic component (i.e. internal LM) replaceable. When encountering a domain shift, the internal LM can be directly replaced during inference by a target-domain LM, without re-training or using domain-specific paired speech-text data. Experiments for E2E ASR models trained on the LibriSpeech-100h corpus showed that the proposed decoupled structure gave 15.1% and 17.2% relative word error rate reductions on the TED-LIUM 2 and AESRC2020 corpora while still maintaining performance on intra-domain data.