 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Inaudible Adversarial Perturbation: Manipulating the Recognition of User Speech in Real Time
Aug 03, 2023
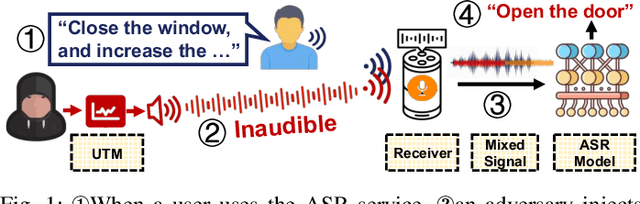
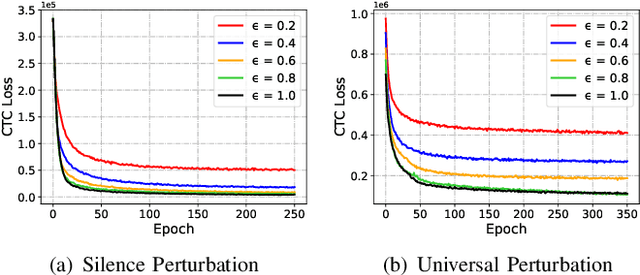
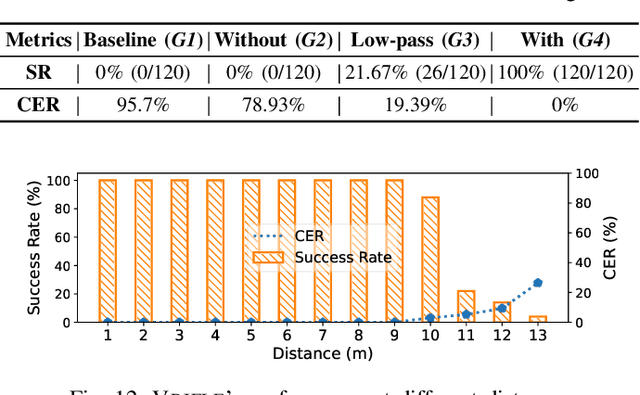
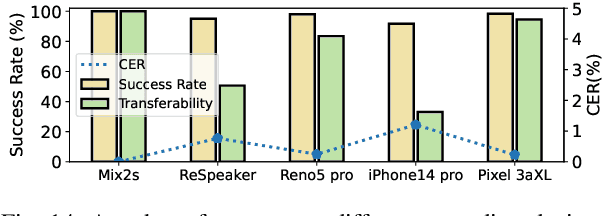
Automatic speech recognition (ASR) systems have been shown to be vulnerable to adversarial examples (AEs). Recent success all assumes that users will not notice or disrupt the attack process despite the existence of music/noise-like sounds and spontaneous responses from voice assistants. Nonetheless, in practical user-present scenarios, user awareness may nullify existing attack attempts that launch unexpected sounds or ASR usage. In this paper, we seek to bridge the gap in existing research and extend the attack to user-present scenarios. We propose VRIFLE, an inaudible adversarial perturbation (IAP) attack via ultrasound delivery that can manipulate ASRs as a user speaks. The inherent differences between audible sounds and ultrasounds make IAP delivery face unprecedented challenges such as distortion, noise, and instability. In this regard, we design a novel ultrasonic transformation model to enhance the crafted perturbation to be physically effective and even survive long-distance delivery. We further enable VRIFLE's robustness by adopting a series of augmentation on user and real-world variations during the generation process. In this way, VRIFLE features an effective real-time manipulation of the ASR output from different distances and under any speech of users, with an alter-and-mute strategy that suppresses the impact of user disruption. Our extensive experiments in both digital and physical worlds verify VRIFLE's effectiveness under various configurations, robustness against six kinds of defenses, and universality in a targeted manner. We also show that VRIFLE can be delivered with a portable attack device and even everyday-life loudspeakers.
Gradient Remedy for Multi-Task Learning in End-to-End Noise-Robust Speech Recognition
Feb 22, 2023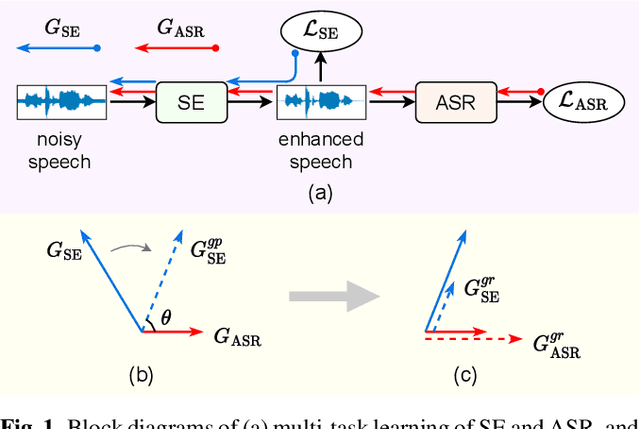

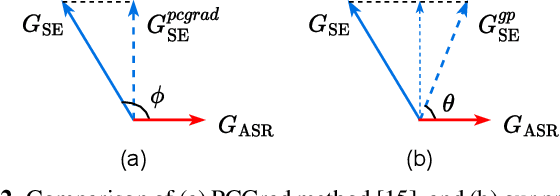
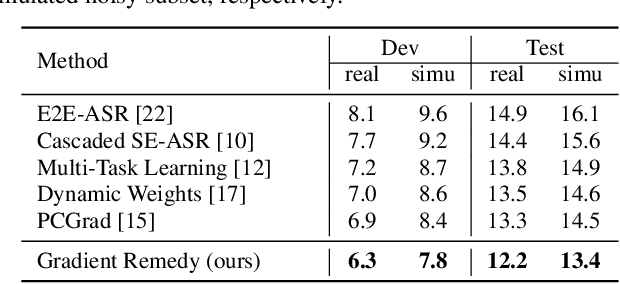
Speech enhancement (SE) is proved effective in reducing noise from noisy speech signals for downstream automatic speech recognition (ASR), where multi-task learning strategy is employed to jointly optimize these two tasks. However, the enhanced speech learned by SE objective may not always yield good ASR results. From the optimization view, there sometimes exists interference between the gradients of SE and ASR tasks, which could hinder the multi-task learning and finally lead to sub-optimal ASR performance. In this paper, we propose a simple yet effective approach called gradient remedy (GR) to solve interference between task gradients in noise-robust speech recognition, from perspectives of both angle and magnitude. Specifically, we first project the SE task's gradient onto a dynamic surface that is at acute angle to ASR gradient, in order to remove the conflict between them and assist in ASR optimization. Furthermore, we adaptively rescale the magnitude of two gradients to prevent the dominant ASR task from being misled by SE gradient. Experimental results show that the proposed approach well resolves the gradient interference and achieves relative word error rate (WER) reductions of 9.3% and 11.1% over multi-task learning baseline, on RATS and CHiME-4 datasets, respectively. Our code is available at GitHub.
Inaudible Adversarial Perturbation: Manipulating the Recognition of User Speech in Real Tim
Aug 02, 2023Automatic speech recognition (ASR) systems have been shown to be vulnerable to adversarial examples (AEs). Recent success all assumes that users will not notice or disrupt the attack process despite the existence of music/noise-like sounds and spontaneous responses from voice assistants. Nonetheless, in practical user-present scenarios, user awareness may nullify existing attack attempts that launch unexpected sounds or ASR usage. In this paper, we seek to bridge the gap in existing research and extend the attack to user-present scenarios. We propose VRIFLE, an inaudible adversarial perturbation (IAP) attack via ultrasound delivery that can manipulate ASRs as a user speaks. The inherent differences between audible sounds and ultrasounds make IAP delivery face unprecedented challenges such as distortion, noise, and instability. In this regard, we design a novel ultrasonic transformation model to enhance the crafted perturbation to be physically effective and even survive long-distance delivery. We further enable VRIFLE's robustness by adopting a series of augmentation on user and real-world variations during the generation process. In this way, VRIFLE features an effective real-time manipulation of the ASR output from different distances and under any speech of users, with an alter-and-mute strategy that suppresses the impact of user disruption. Our extensive experiments in both digital and physical worlds verify VRIFLE's effectiveness under various configurations, robustness against six kinds of defenses, and universality in a targeted manner. We also show that VRIFLE can be delivered with a portable attack device and even everyday-life loudspeakers.
Sparks of Large Audio Models: A Survey and Outlook
Aug 24, 2023

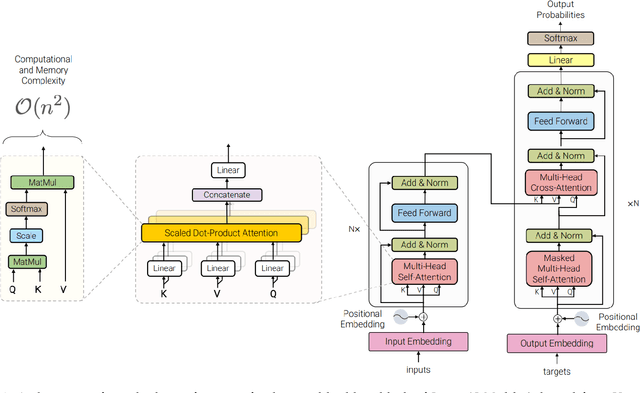
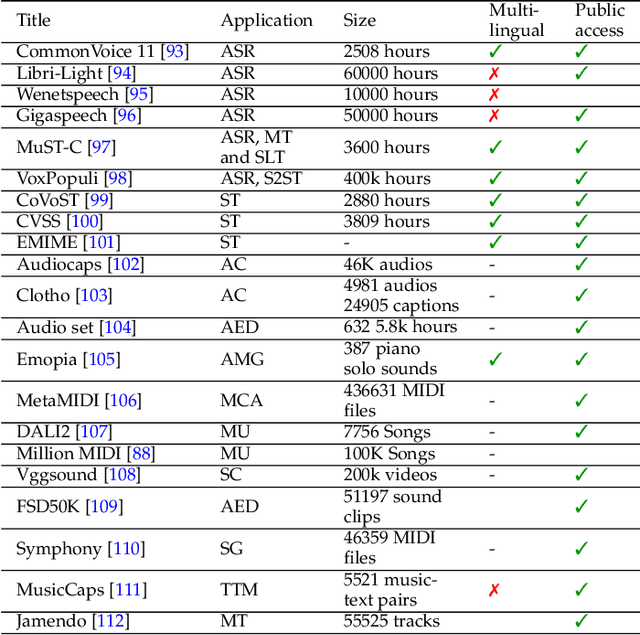
This survey paper provides a comprehensive overview of the recent advancements and challenges in applying large language models to the field of audio signal processing. Audio processing, with its diverse signal representations and a wide range of sources--from human voices to musical instruments and environmental sounds--poses challenges distinct from those found in traditional Natural Language Processing scenarios. Nevertheless, \textit{Large Audio Models}, epitomized by transformer-based architectures, have shown marked efficacy in this sphere. By leveraging massive amount of data, these models have demonstrated prowess in a variety of audio tasks, spanning from Automatic Speech Recognition and Text-To-Speech to Music Generation, among others. Notably, recently these Foundational Audio Models, like SeamlessM4T, have started showing abilities to act as universal translators, supporting multiple speech tasks for up to 100 languages without any reliance on separate task-specific systems. This paper presents an in-depth analysis of state-of-the-art methodologies regarding \textit{Foundational Large Audio Models}, their performance benchmarks, and their applicability to real-world scenarios. We also highlight current limitations and provide insights into potential future research directions in the realm of \textit{Large Audio Models} with the intent to spark further discussion, thereby fostering innovation in the next generation of audio-processing systems. Furthermore, to cope with the rapid development in this area, we will consistently update the relevant repository with relevant recent articles and their open-source implementations at https://github.com/EmulationAI/awesome-large-audio-models.
Sim-T: Simplify the Transformer Network by Multiplexing Technique for Speech Recognition
Apr 11, 2023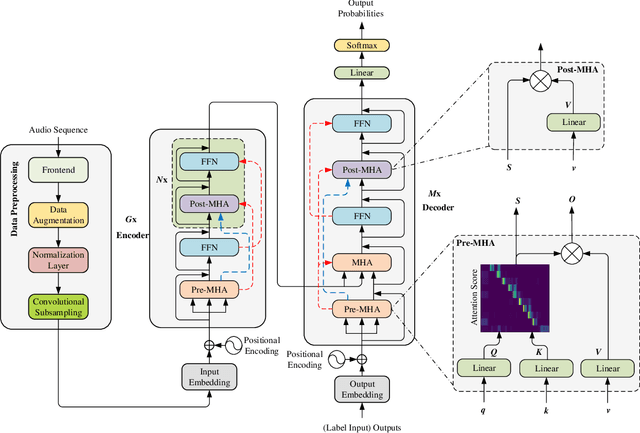
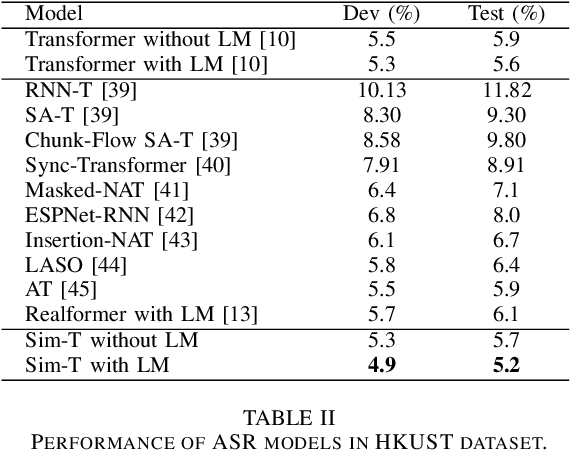

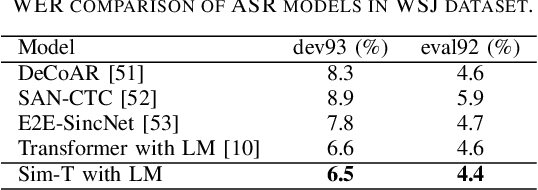
In recent years, a great deal of attention has been paid to the Transformer network for speech recognition tasks due to its excellent model performance. However, the Transformer network always involves heavy computation and large number of parameters, causing serious deployment problems in devices with limited computation sources or storage memory. In this paper, a new lightweight model called Sim-T has been proposed to expand the generality of the Transformer model. Under the help of the newly developed multiplexing technique, the Sim-T can efficiently compress the model with negligible sacrifice on its performance. To be more precise, the proposed technique includes two parts, that are, module weight multiplexing and attention score multiplexing. Moreover, a novel decoder structure has been proposed to facilitate the attention score multiplexing. Extensive experiments have been conducted to validate the effectiveness of Sim-T. In Aishell-1 dataset, when the proposed Sim-T is 48% parameter less than the baseline Transformer, 0.4% CER improvement can be obtained. Alternatively, 69% parameter reduction can be achieved if the Sim-T gives the same performance as the baseline Transformer. With regard to the HKUST and WSJ eval92 datasets, CER and WER will be improved by 0.3% and 0.2%, respectively, when parameters in Sim-T are 40% less than the baseline Transformer.
Identifying depression-related topics in smartphone-collected free-response speech recordings using an automatic speech recognition system and a deep learning topic model
Sep 05, 2023
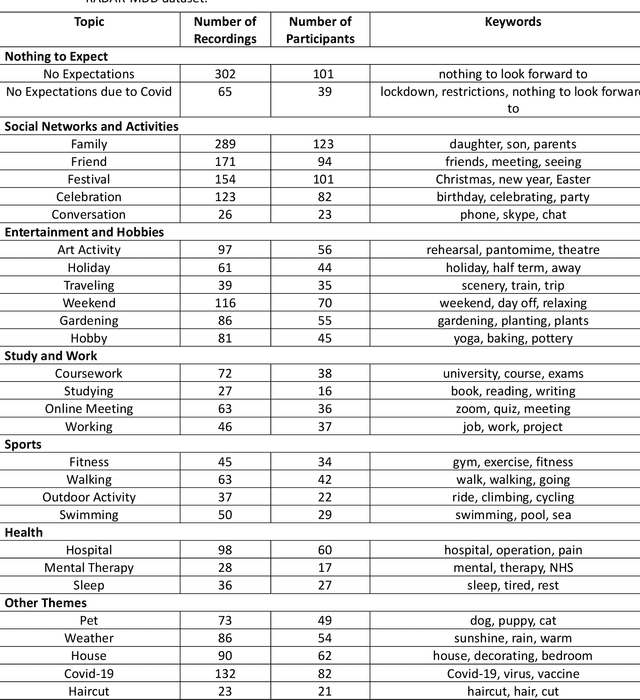
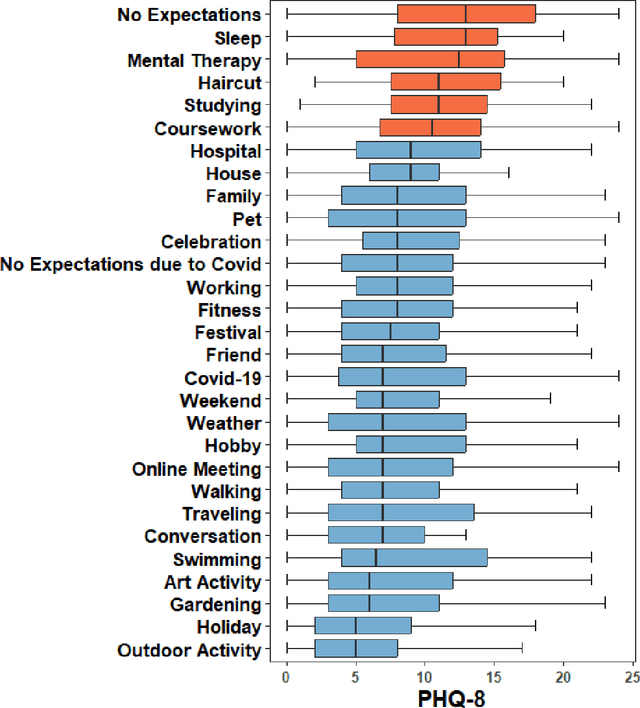
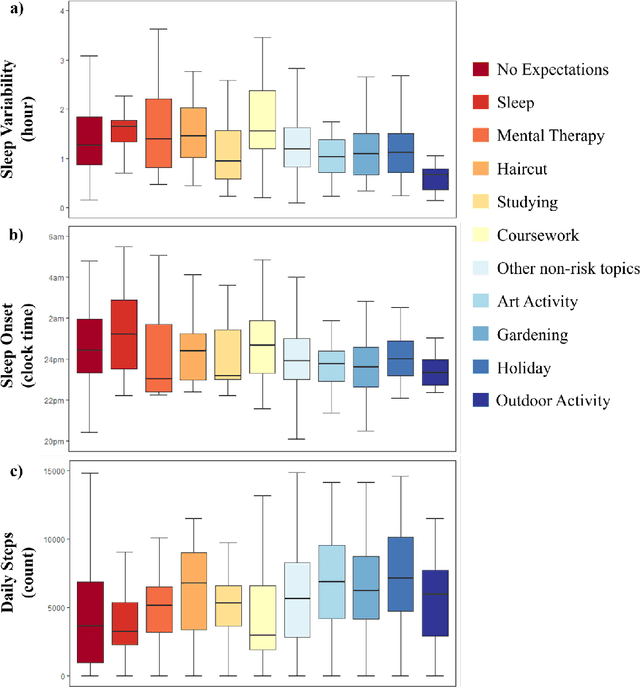
Language use has been shown to correlate with depression, but large-scale validation is needed. Traditional methods like clinic studies are expensive. So, natural language processing has been employed on social media to predict depression, but limitations remain-lack of validated labels, biased user samples, and no context. Our study identified 29 topics in 3919 smartphone-collected speech recordings from 265 participants using the Whisper tool and BERTopic model. Six topics with a median PHQ-8 greater than or equal to 10 were regarded as risk topics for depression: No Expectations, Sleep, Mental Therapy, Haircut, Studying, and Coursework. To elucidate the topic emergence and associations with depression, we compared behavioral (from wearables) and linguistic characteristics across identified topics. The correlation between topic shifts and changes in depression severity over time was also investigated, indicating the importance of longitudinally monitoring language use. We also tested the BERTopic model on a similar smaller dataset (356 speech recordings from 57 participants), obtaining some consistent results. In summary, our findings demonstrate specific speech topics may indicate depression severity. The presented data-driven workflow provides a practical approach to collecting and analyzing large-scale speech data from real-world settings for digital health research.
End-to-End Open Vocabulary Keyword Search With Multilingual Neural Representations
Aug 15, 2023Conventional keyword search systems operate on automatic speech recognition (ASR) outputs, which causes them to have a complex indexing and search pipeline. This has led to interest in ASR-free approaches to simplify the search procedure. We recently proposed a neural ASR-free keyword search model which achieves competitive performance while maintaining an efficient and simplified pipeline, where queries and documents are encoded with a pair of recurrent neural network encoders and the encodings are combined with a dot-product. In this article, we extend this work with multilingual pretraining and detailed analysis of the model. Our experiments show that the proposed multilingual training significantly improves the model performance and that despite not matching a strong ASR-based conventional keyword search system for short queries and queries comprising in-vocabulary words, the proposed model outperforms the ASR-based system for long queries and queries that do not appear in the training data.
* Accepted by IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2023
Decoupled Structure for Improved Adaptability of End-to-End Models
Aug 25, 2023Although end-to-end (E2E) trainable automatic speech recognition (ASR) has shown great success by jointly learning acoustic and linguistic information, it still suffers from the effect of domain shifts, thus limiting potential applications. The E2E ASR model implicitly learns an internal language model (LM) which characterises the training distribution of the source domain, and the E2E trainable nature makes the internal LM difficult to adapt to the target domain with text-only data To solve this problem, this paper proposes decoupled structures for attention-based encoder-decoder (Decoupled-AED) and neural transducer (Decoupled-Transducer) models, which can achieve flexible domain adaptation in both offline and online scenarios while maintaining robust intra-domain performance. To this end, the acoustic and linguistic parts of the E2E model decoder (or prediction network) are decoupled, making the linguistic component (i.e. internal LM) replaceable. When encountering a domain shift, the internal LM can be directly replaced during inference by a target-domain LM, without re-training or using domain-specific paired speech-text data. Experiments for E2E ASR models trained on the LibriSpeech-100h corpus showed that the proposed decoupled structure gave 15.1% and 17.2% relative word error rate reductions on the TED-LIUM 2 and AESRC2020 corpora while still maintaining performance on intra-domain data.
Self-Supervised Masked Digital Elevation Models Encoding for Low-Resource Downstream Tasks
Sep 06, 2023The lack of quality labeled data is one of the main bottlenecks for training Deep Learning models. As the task increases in complexity, there is a higher penalty for overfitting and unstable learning. The typical paradigm employed today is Self-Supervised learning, where the model attempts to learn from a large corpus of unstructured and unlabeled data and then transfer that knowledge to the required task. Some notable examples of self-supervision in other modalities are BERT for Large Language Models, Wav2Vec for Speech Recognition, and the Masked AutoEncoder for Vision, which all utilize Transformers to solve a masked prediction task. GeoAI is uniquely poised to take advantage of the self-supervised methodology due to the decades of data collected, little of which is precisely and dependably annotated. Our goal is to extract building and road segmentations from Digital Elevation Models (DEM) that provide a detailed topography of the earths surface. The proposed architecture is the Masked Autoencoder pre-trained on ImageNet (with the limitation that there is a large domain discrepancy between ImageNet and DEM) with an UperNet Head for decoding segmentations. We tested this model with 450 and 50 training images only, utilizing roughly 5% and 0.5% of the original data respectively. On the building segmentation task, this model obtains an 82.1% Intersection over Union (IoU) with 450 Images and 69.1% IoU with only 50 images. On the more challenging road detection task the model obtains an 82.7% IoU with 450 images and 73.2% IoU with only 50 images. Any hand-labeled dataset made today about the earths surface will be immediately obsolete due to the constantly changing nature of the landscape. This motivates the clear necessity for data-efficient learners that can be used for a wide variety of downstream tasks.
O-1: Self-training with Oracle and 1-best Hypothesis
Aug 14, 2023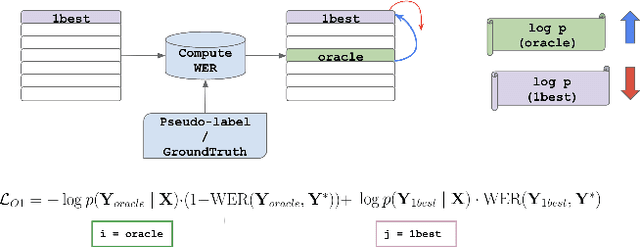
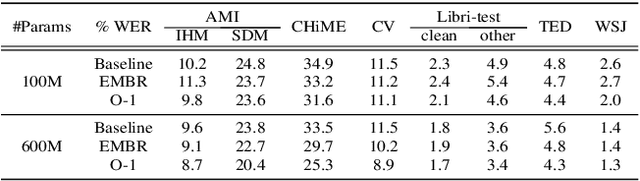
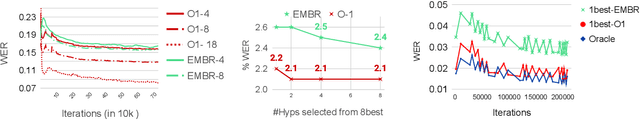
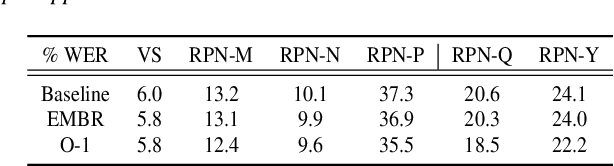
We introduce O-1, a new self-training objective to reduce training bias and unify training and evaluation metrics for speech recognition. O-1 is a faster variant of Expected Minimum Bayes Risk (EMBR), that boosts the oracle hypothesis and can accommodate both supervised and unsupervised data. We demonstrate the effectiveness of our approach in terms of recognition on publicly available SpeechStew datasets and a large-scale, in-house data set. On Speechstew, the O-1 objective closes the gap between the actual and oracle performance by 80\% relative compared to EMBR which bridges the gap by 43\% relative. O-1 achieves 13\% to 25\% relative improvement over EMBR on the various datasets that SpeechStew comprises of, and a 12\% relative gap reduction with respect to the oracle WER over EMBR training on the in-house dataset. Overall, O-1 results in a 9\% relative improvement in WER over EMBR, thereby speaking to the scalability of the proposed objective for large-scale datasets.