 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Cross-Language Speech Emotion Recognition Using Multimodal Dual Attention Transformers
Jul 14, 2023
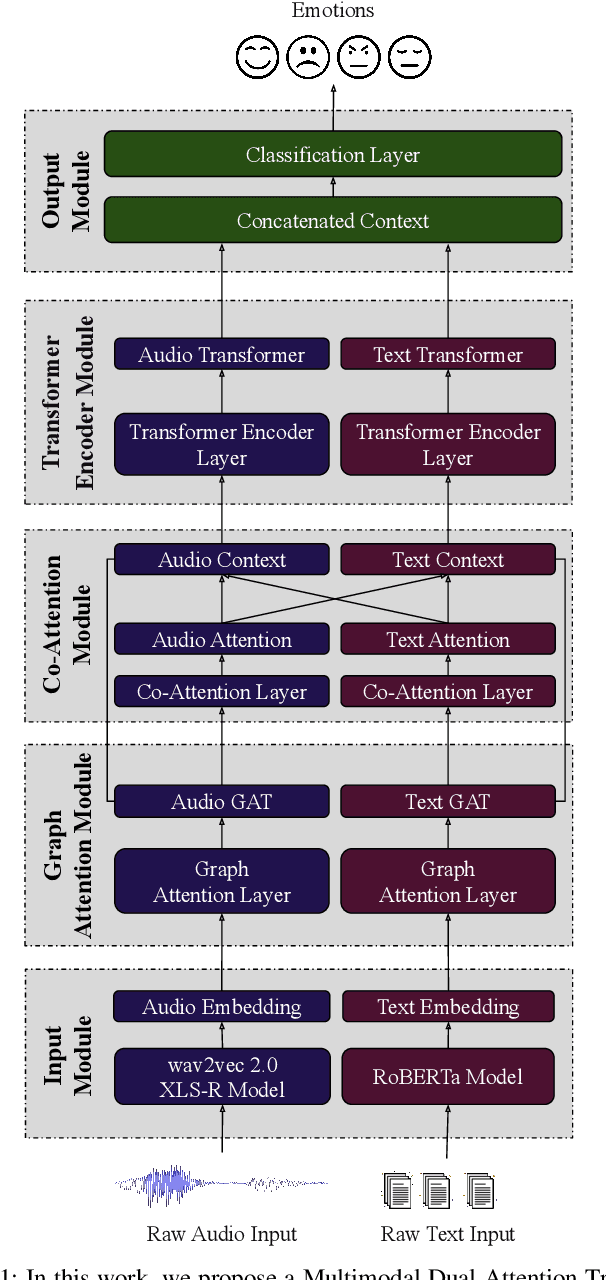
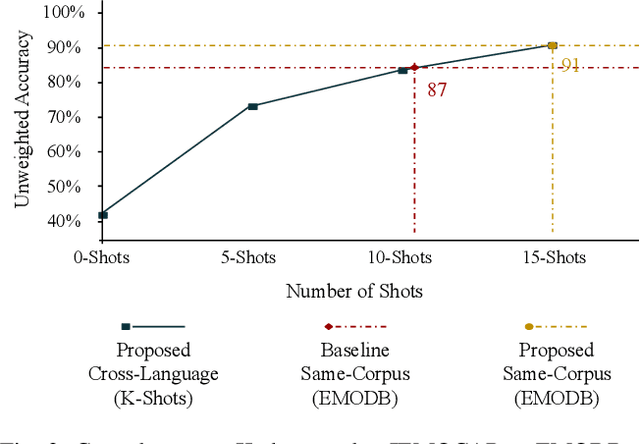
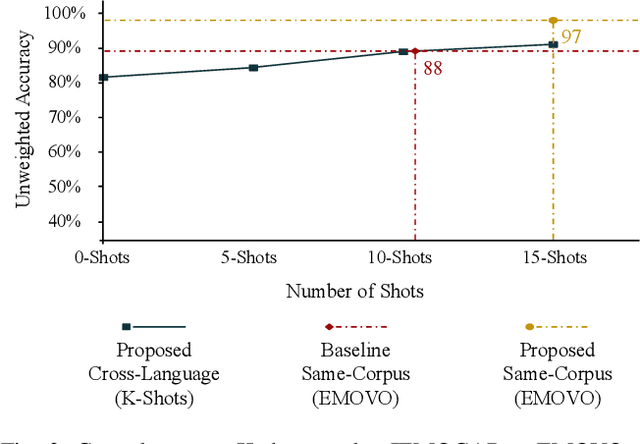
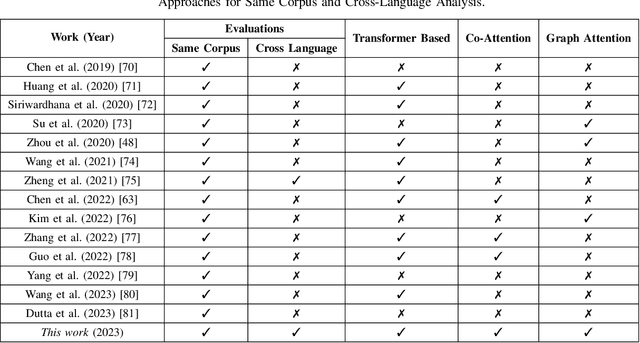
Despite the recent progress in speech emotion recognition (SER), state-of-the-art systems are unable to achieve improved performance in cross-language settings. In this paper, we propose a Multimodal Dual Attention Transformer (MDAT) model to improve cross-language SER. Our model utilises pre-trained models for multimodal feature extraction and is equipped with a dual attention mechanism including graph attention and co-attention to capture complex dependencies across different modalities and achieve improved cross-language SER results using minimal target language data. In addition, our model also exploits a transformer encoder layer for high-level feature representation to improve emotion classification accuracy. In this way, MDAT performs refinement of feature representation at various stages and provides emotional salient features to the classification layer. This novel approach also ensures the preservation of modality-specific emotional information while enhancing cross-modality and cross-language interactions. We assess our model's performance on four publicly available SER datasets and establish its superior effectiveness compared to recent approaches and baseline models.
Non-autoregressive End-to-end Approaches for Joint Automatic Speech Recognition and Spoken Language Understanding
Apr 21, 2023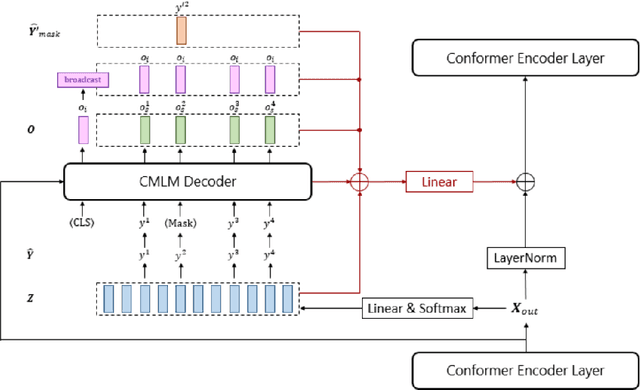

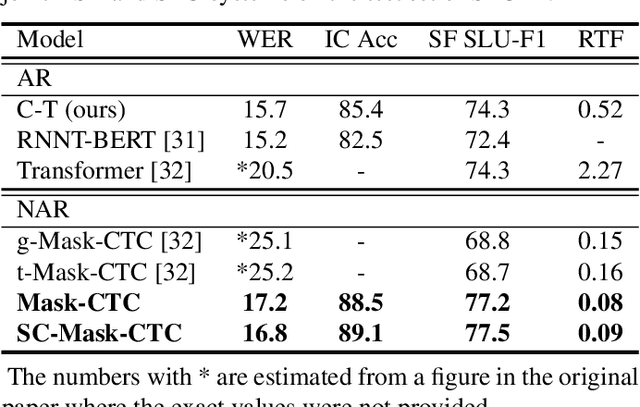
This paper presents the use of non-autoregressive (NAR) approaches for joint automatic speech recognition (ASR) and spoken language understanding (SLU) tasks. The proposed NAR systems employ a Conformer encoder that applies connectionist temporal classification (CTC) to transcribe the speech utterance into raw ASR hypotheses, which are further refined with a bidirectional encoder representations from Transformers (BERT)-like decoder. In the meantime, the intent and slot labels of the utterance are predicted simultaneously using the same decoder. Both Mask-CTC and self-conditioned CTC (SC-CTC) approaches are explored for this study. Experiments conducted on the SLURP dataset show that the proposed SC-Mask-CTC NAR system achieves 3.7% and 3.2% absolute gains in SLU metrics and a competitive level of ASR accuracy, when compared to a Conformer-Transformer based autoregressive (AR) model. Additionally, the NAR systems achieve 6x faster decoding speed than the AR baseline.
From English to More Languages: Parameter-Efficient Model Reprogramming for Cross-Lingual Speech Recognition
Jan 19, 2023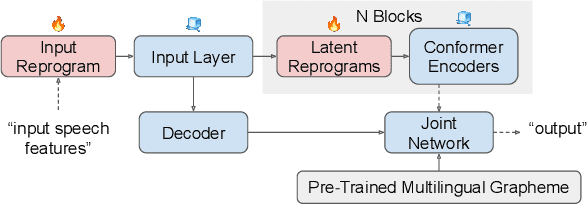

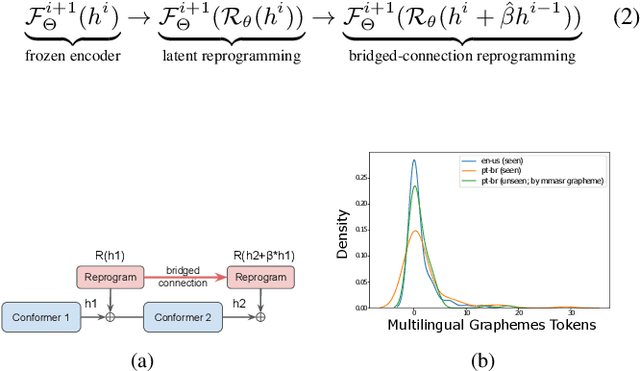
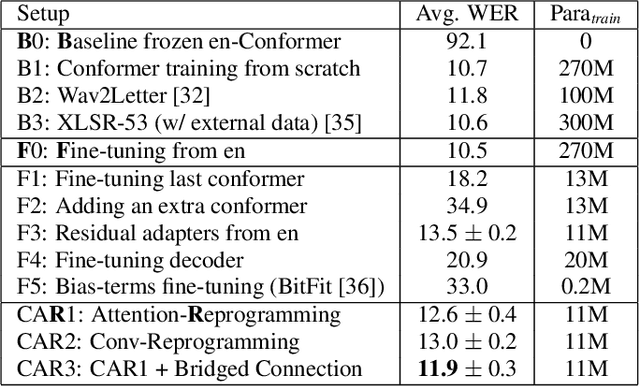
In this work, we propose a new parameter-efficient learning framework based on neural model reprogramming for cross-lingual speech recognition, which can \textbf{re-purpose} well-trained English automatic speech recognition (ASR) models to recognize the other languages. We design different auxiliary neural architectures focusing on learnable pre-trained feature enhancement that, for the first time, empowers model reprogramming on ASR. Specifically, we investigate how to select trainable components (i.e., encoder) of a conformer-based RNN-Transducer, as a frozen pre-trained backbone. Experiments on a seven-language multilingual LibriSpeech speech (MLS) task show that model reprogramming only requires 4.2% (11M out of 270M) to 6.8% (45M out of 660M) of its original trainable parameters from a full ASR model to perform competitive results in a range of 11.9% to 8.1% WER averaged across different languages. In addition, we discover different setups to make large-scale pre-trained ASR succeed in both monolingual and multilingual speech recognition. Our methods outperform existing ASR tuning architectures and their extension with self-supervised losses (e.g., w2v-bert) in terms of lower WER and better training efficiency.
A Deep Learning System for Domain-specific speech Recognition
Mar 18, 2023

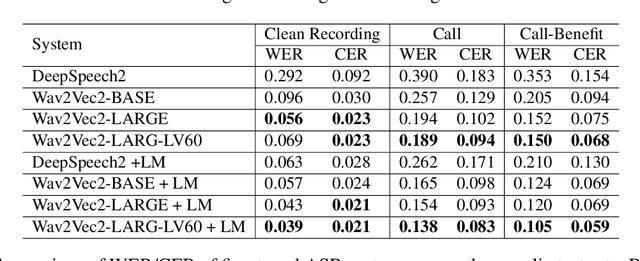

As human-machine voice interfaces provide easy access to increasingly intelligent machines, many state-of-the-art automatic speech recognition (ASR) systems are proposed. However, commercial ASR systems usually have poor performance on domain-specific speech especially under low-resource settings. The author works with pre-trained DeepSpeech2 and Wav2Vec2 acoustic models to develop benefit-specific ASR systems. The domain-specific data are collected using proposed semi-supervised learning annotation with little human intervention. The best performance comes from a fine-tuned Wav2Vec2-Large-LV60 acoustic model with an external KenLM, which surpasses the Google and AWS ASR systems on benefit-specific speech. The viability of using error prone ASR transcriptions as part of spoken language understanding (SLU) is also investigated. Results of a benefit-specific natural language understanding (NLU) task show that the domain-specific fine-tuned ASR system can outperform the commercial ASR systems even when its transcriptions have higher word error rate (WER), and the results between fine-tuned ASR and human transcriptions are similar.
Improving CTC-AED model with integrated-CTC and auxiliary loss regularization
Aug 15, 2023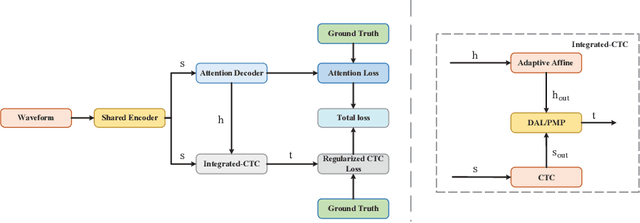

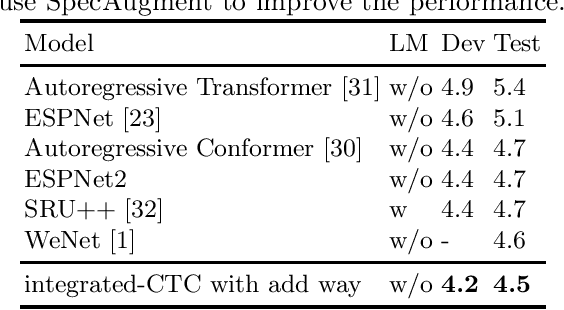

Connectionist temporal classification (CTC) and attention-based encoder decoder (AED) joint training has been widely applied in automatic speech recognition (ASR). Unlike most hybrid models that separately calculate the CTC and AED losses, our proposed integrated-CTC utilizes the attention mechanism of AED to guide the output of CTC. In this paper, we employ two fusion methods, namely direct addition of logits (DAL) and preserving the maximum probability (PMP). We achieve dimensional consistency by adaptively affine transforming the attention results to match the dimensions of CTC. To accelerate model convergence and improve accuracy, we introduce auxiliary loss regularization for accelerated convergence. Experimental results demonstrate that the DAL method performs better in attention rescoring, while the PMP method excels in CTC prefix beam search and greedy search.
Speech Diarization and ASR with GMM
Jul 11, 2023

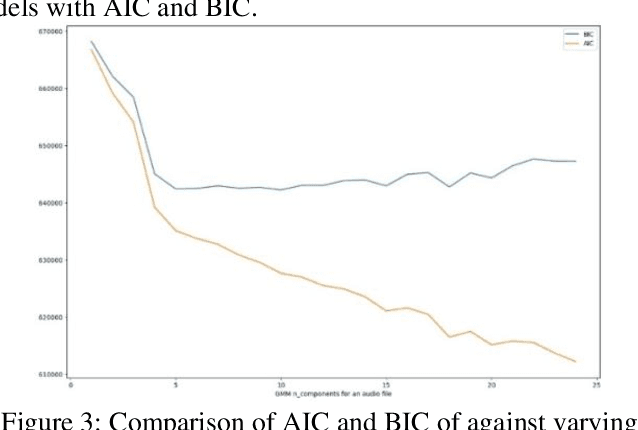
In this research paper, we delve into the topics of Speech Diarization and Automatic Speech Recognition (ASR). Speech diarization involves the separation of individual speakers within an audio stream. By employing the ASR transcript, the diarization process aims to segregate each speaker's utterances, grouping them based on their unique audio characteristics. On the other hand, Automatic Speech Recognition refers to the capability of a machine or program to identify and convert spoken words and phrases into a machine-readable format. In our speech diarization approach, we utilize the Gaussian Mixer Model (GMM) to represent speech segments. The inter-cluster distance is computed based on the GMM parameters, and the distance threshold serves as the stopping criterion. ASR entails the conversion of an unknown speech waveform into a corresponding written transcription. The speech signal is analyzed using synchronized algorithms, taking into account the pitch frequency. Our primary objective typically revolves around developing a model that minimizes the Word Error Rate (WER) metric during speech transcription.
TODM: Train Once Deploy Many Efficient Supernet-Based RNN-T Compression For On-device ASR Models
Sep 05, 2023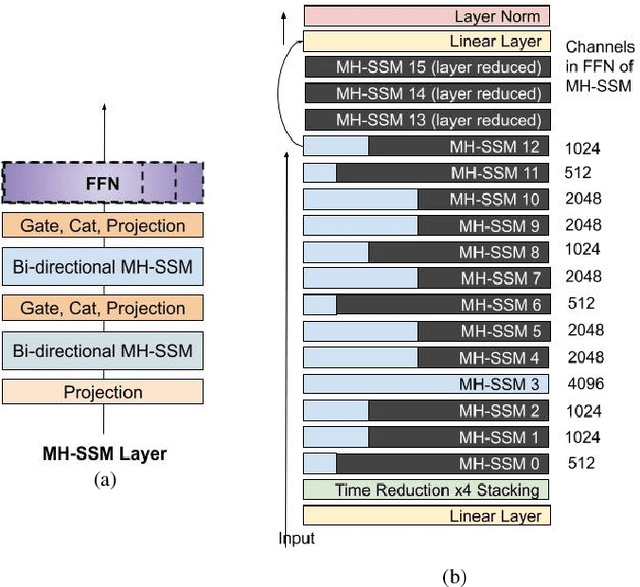
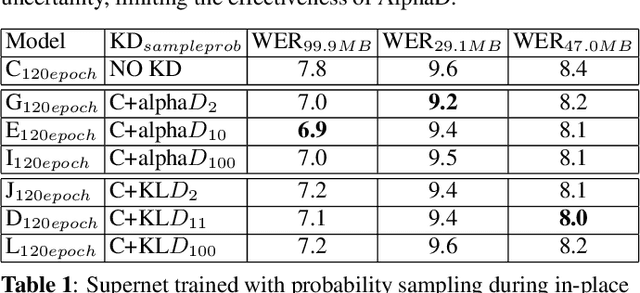
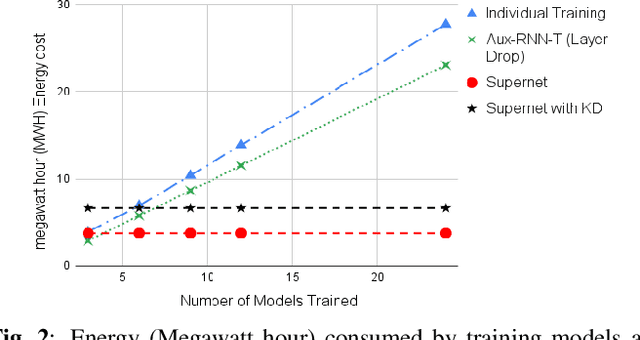
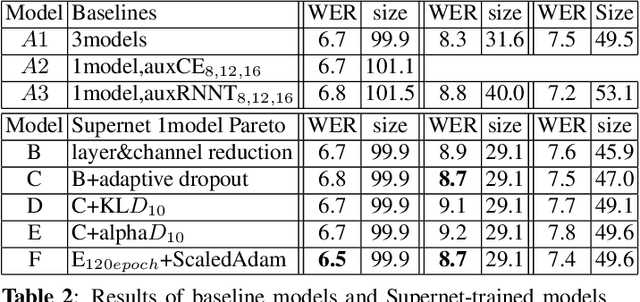
Automatic Speech Recognition (ASR) models need to be optimized for specific hardware before they can be deployed on devices. This can be done by tuning the model's hyperparameters or exploring variations in its architecture. Re-training and re-validating models after making these changes can be a resource-intensive task. This paper presents TODM (Train Once Deploy Many), a new approach to efficiently train many sizes of hardware-friendly on-device ASR models with comparable GPU-hours to that of a single training job. TODM leverages insights from prior work on Supernet, where Recurrent Neural Network Transducer (RNN-T) models share weights within a Supernet. It reduces layer sizes and widths of the Supernet to obtain subnetworks, making them smaller models suitable for all hardware types. We introduce a novel combination of three techniques to improve the outcomes of the TODM Supernet: adaptive dropouts, an in-place Alpha-divergence knowledge distillation, and the use of ScaledAdam optimizer. We validate our approach by comparing Supernet-trained versus individually tuned Multi-Head State Space Model (MH-SSM) RNN-T using LibriSpeech. Results demonstrate that our TODM Supernet either matches or surpasses the performance of manually tuned models by up to a relative of 3% better in word error rate (WER), while efficiently keeping the cost of training many models at a small constant.
Whisper-AT: Noise-Robust Automatic Speech Recognizers are Also Strong General Audio Event Taggers
Jul 06, 2023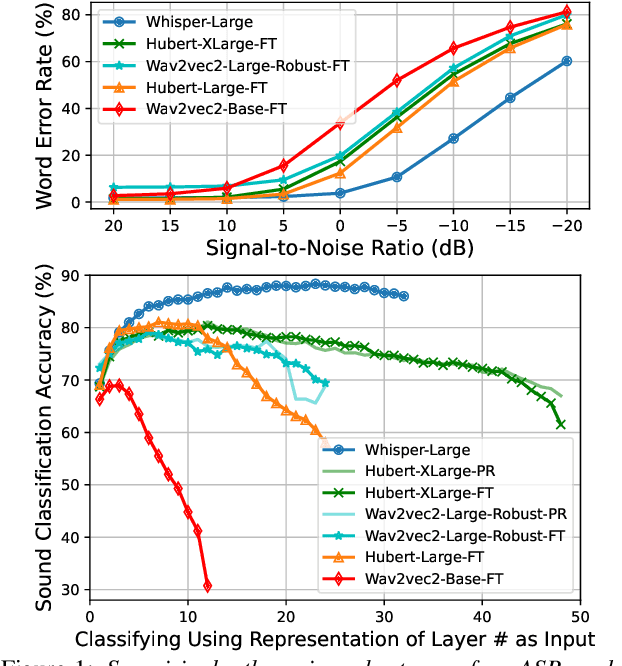
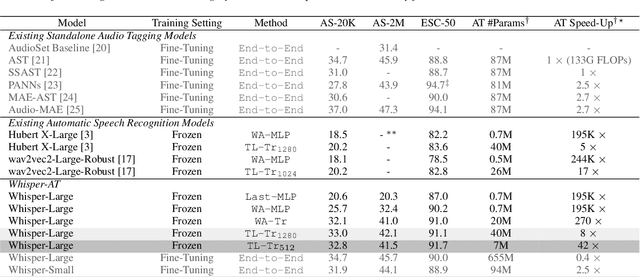
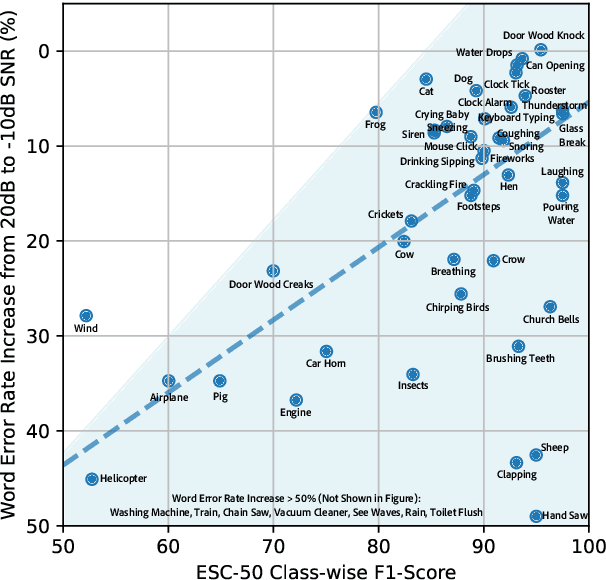
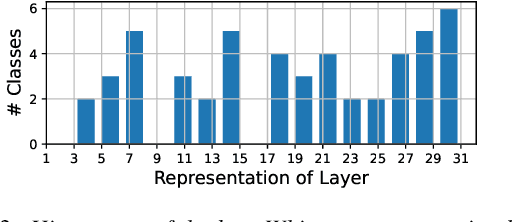
In this paper, we focus on Whisper, a recent automatic speech recognition model trained with a massive 680k hour labeled speech corpus recorded in diverse conditions. We first show an interesting finding that while Whisper is very robust against real-world background sounds (e.g., music), its audio representation is actually not noise-invariant, but is instead highly correlated to non-speech sounds, indicating that Whisper recognizes speech conditioned on the noise type. With this finding, we build a unified audio tagging and speech recognition model Whisper-AT by freezing the backbone of Whisper, and training a lightweight audio tagging model on top of it. With <1% extra computational cost, Whisper-AT can recognize audio events, in addition to spoken text, in a single forward pass.
AdVerb: Visually Guided Audio Dereverberation
Aug 23, 2023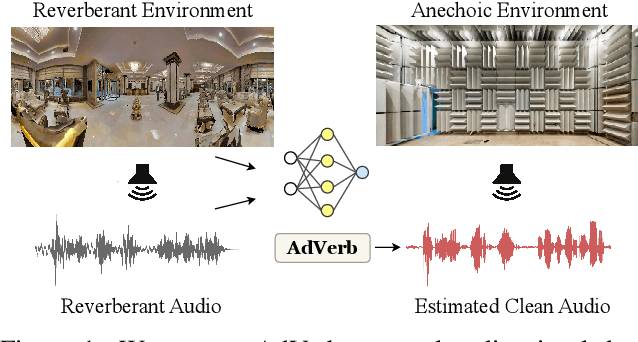
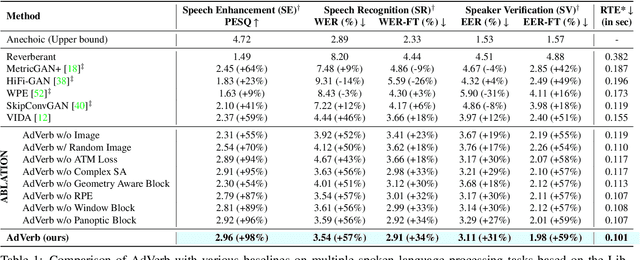
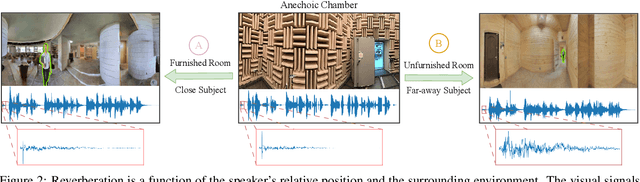
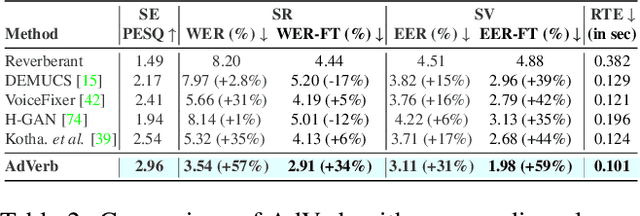
We present AdVerb, a novel audio-visual dereverberation framework that uses visual cues in addition to the reverberant sound to estimate clean audio. Although audio-only dereverberation is a well-studied problem, our approach incorporates the complementary visual modality to perform audio dereverberation. Given an image of the environment where the reverberated sound signal has been recorded, AdVerb employs a novel geometry-aware cross-modal transformer architecture that captures scene geometry and audio-visual cross-modal relationship to generate a complex ideal ratio mask, which, when applied to the reverberant audio predicts the clean sound. The effectiveness of our method is demonstrated through extensive quantitative and qualitative evaluations. Our approach significantly outperforms traditional audio-only and audio-visual baselines on three downstream tasks: speech enhancement, speech recognition, and speaker verification, with relative improvements in the range of 18% - 82% on the LibriSpeech test-clean set. We also achieve highly satisfactory RT60 error scores on the AVSpeech dataset.
Evaluating Automatic Speech Recognition in an Incremental Setting
Feb 23, 2023
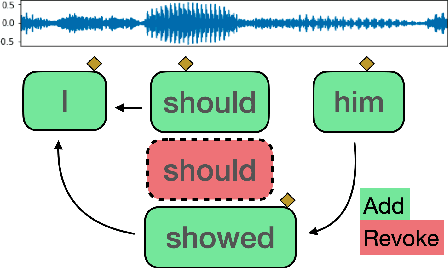
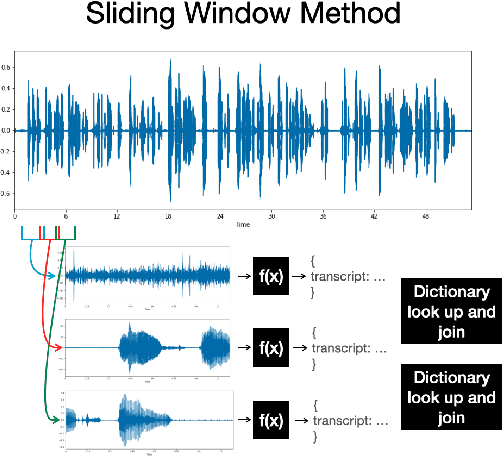
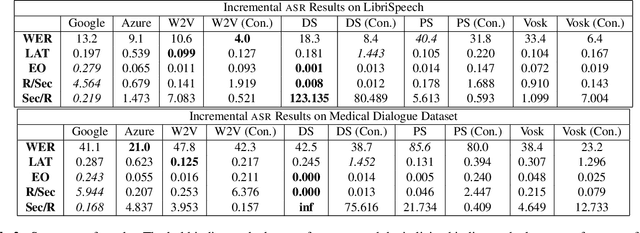
The increasing reliability of automatic speech recognition has proliferated its everyday use. However, for research purposes, it is often unclear which model one should choose for a task, particularly if there is a requirement for speed as well as accuracy. In this paper, we systematically evaluate six speech recognizers using metrics including word error rate, latency, and the number of updates to already recognized words on English test data, as well as propose and compare two methods for streaming audio into recognizers for incremental recognition. We further propose Revokes per Second as a new metric for evaluating incremental recognition and demonstrate that it provides insights into overall model performance. We find that, generally, local recognizers are faster and require fewer updates than cloud-based recognizers. Finally, we find Meta's Wav2Vec model to be the fastest, and find Mozilla's DeepSpeech model to be the most stable in its predictions.