 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
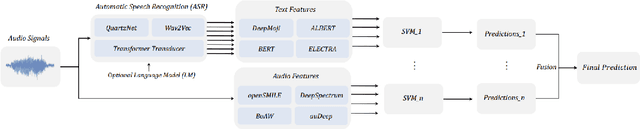
Multimodal Speech Recognition for Language-Guided Embodied Agents
Feb 27, 2023
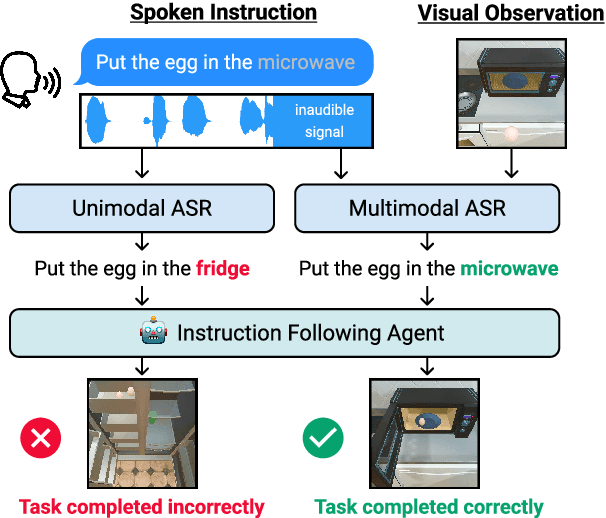
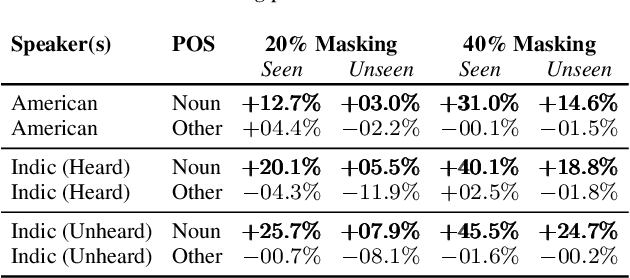
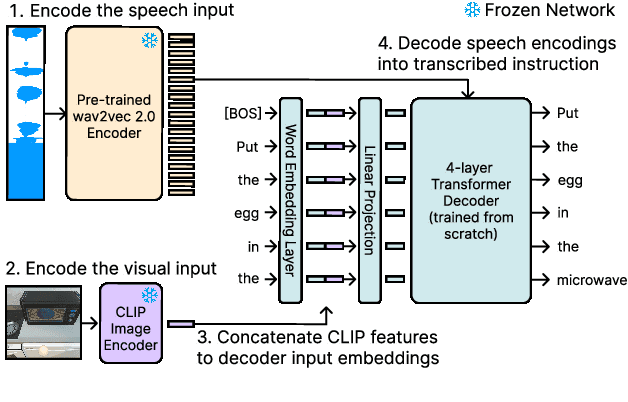
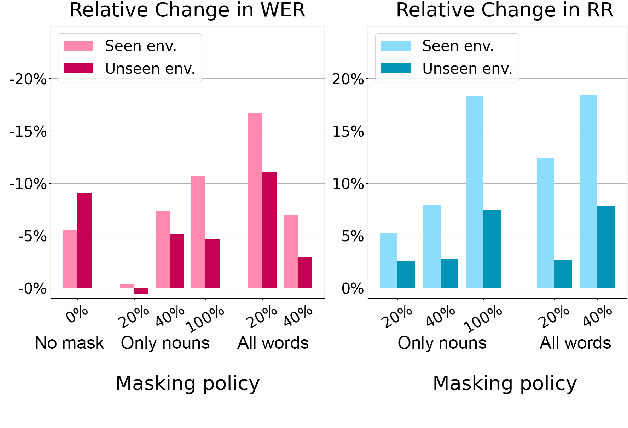
Benchmarks for language-guided embodied agents typically assume text-based instructions, but deployed agents will encounter spoken instructions. While Automatic Speech Recognition (ASR) models can bridge the input gap, erroneous ASR transcripts can hurt the agents' ability to complete tasks. In this work, we propose training a multimodal ASR model to reduce errors in transcribing spoken instructions by considering the accompanying visual context. We train our model on a dataset of spoken instructions, synthesized from the ALFRED task completion dataset, where we simulate acoustic noise by systematically masking spoken words. We find that utilizing visual observations facilitates masked word recovery, with multimodal ASR models recovering up to 30% more masked words than unimodal baselines. We also find that a text-trained embodied agent successfully completes tasks more often by following transcribed instructions from multimodal ASR models.
Capturing Spectral and Long-term Contextual Information for Speech Emotion Recognition Using Deep Learning Techniques
Aug 04, 2023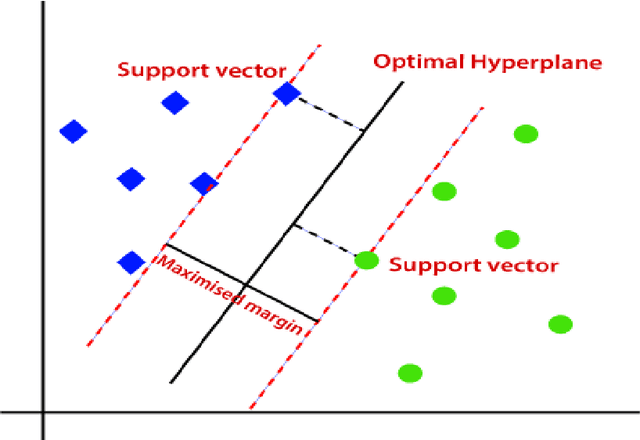
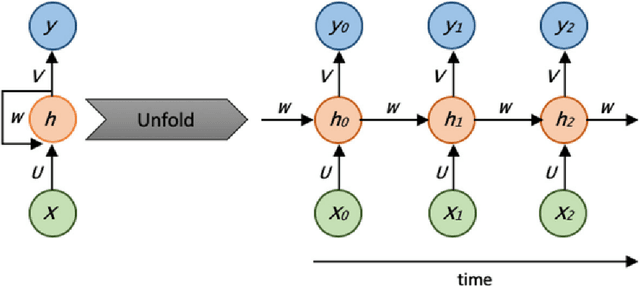
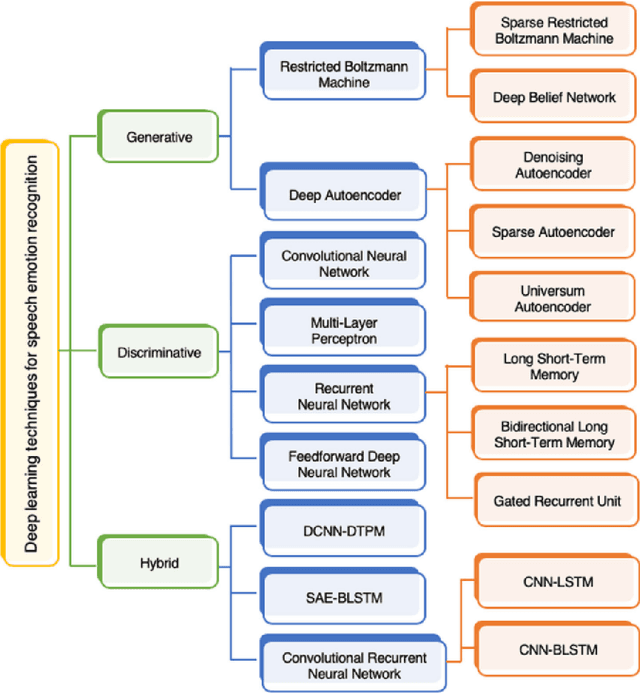
Traditional approaches in speech emotion recognition, such as LSTM, CNN, RNN, SVM, and MLP, have limitations such as difficulty capturing long-term dependencies in sequential data, capturing the temporal dynamics, and struggling to capture complex patterns and relationships in multimodal data. This research addresses these shortcomings by proposing an ensemble model that combines Graph Convolutional Networks (GCN) for processing textual data and the HuBERT transformer for analyzing audio signals. We found that GCNs excel at capturing Long-term contextual dependencies and relationships within textual data by leveraging graph-based representations of text and thus detecting the contextual meaning and semantic relationships between words. On the other hand, HuBERT utilizes self-attention mechanisms to capture long-range dependencies, enabling the modeling of temporal dynamics present in speech and capturing subtle nuances and variations that contribute to emotion recognition. By combining GCN and HuBERT, our ensemble model can leverage the strengths of both approaches. This allows for the simultaneous analysis of multimodal data, and the fusion of these modalities enables the extraction of complementary information, enhancing the discriminative power of the emotion recognition system. The results indicate that the combined model can overcome the limitations of traditional methods, leading to enhanced accuracy in recognizing emotions from speech.
Investigating the Sensitivity of Automatic Speech Recognition Systems to Phonetic Variation in L2 Englishes
May 12, 2023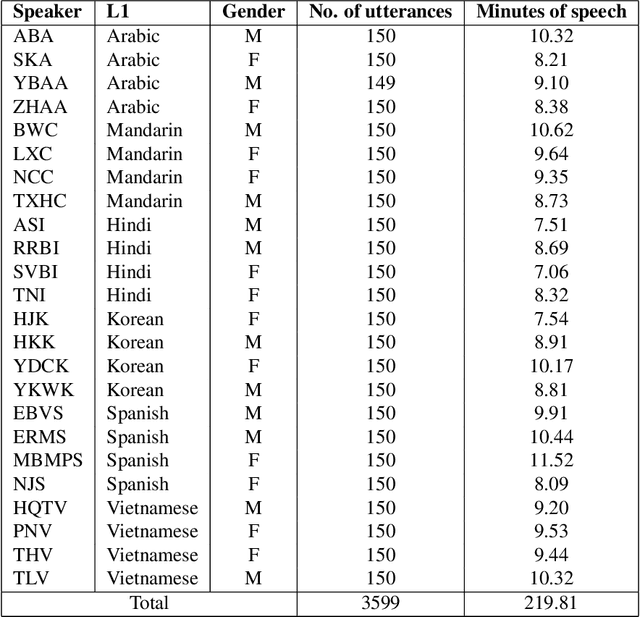
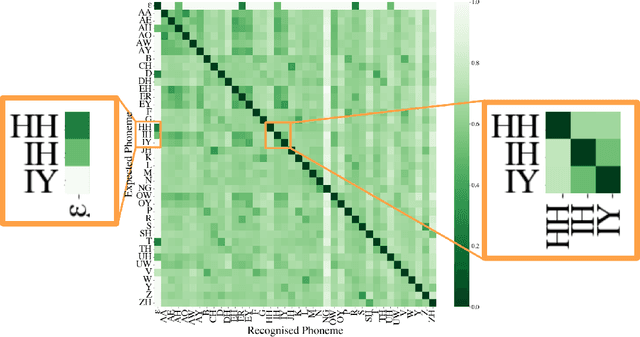
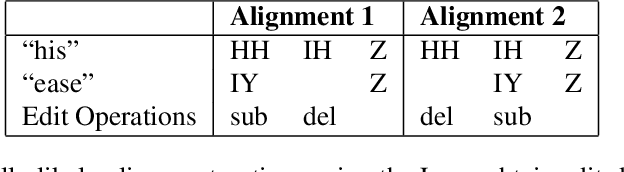
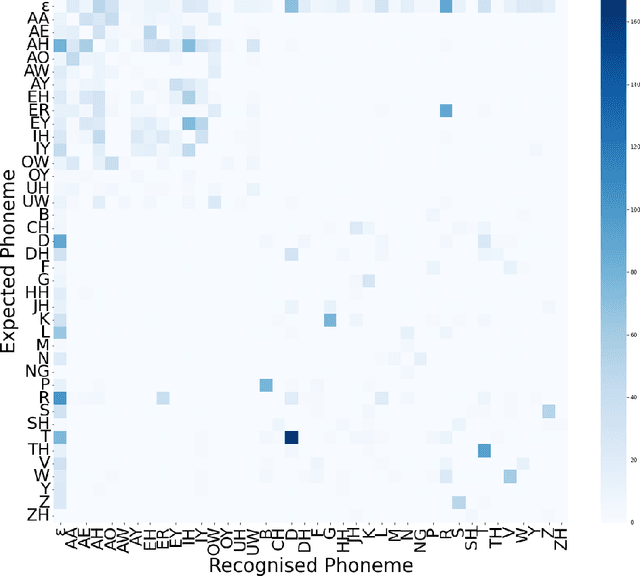
Automatic Speech Recognition (ASR) systems exhibit the best performance on speech that is similar to that on which it was trained. As such, underrepresented varieties including regional dialects, minority-speakers, and low-resource languages, see much higher word error rates (WERs) than those varieties seen as 'prestigious', 'mainstream', or 'standard'. This can act as a barrier to incorporating ASR technology into the annotation process for large-scale linguistic research since the manual correction of the erroneous automated transcripts can be just as time and resource consuming as manual transcriptions. A deeper understanding of the behaviour of an ASR system is thus beneficial from a speech technology standpoint, in terms of improving ASR accuracy, and from an annotation standpoint, where knowing the likely errors made by an ASR system can aid in this manual correction. This work demonstrates a method of probing an ASR system to discover how it handles phonetic variation across a number of L2 Englishes. Specifically, how particular phonetic realisations which were rare or absent in the system's training data can lead to phoneme level misrecognitions and contribute to higher WERs. It is demonstrated that the behaviour of the ASR is systematic and consistent across speakers with similar spoken varieties (in this case the same L1) and phoneme substitution errors are typically in agreement with human annotators. By identifying problematic productions specific weaknesses can be addressed by sourcing such realisations for training and fine-tuning thus making the system more robust to pronunciation variation.
I3D: Transformer architectures with input-dependent dynamic depth for speech recognition
Mar 14, 2023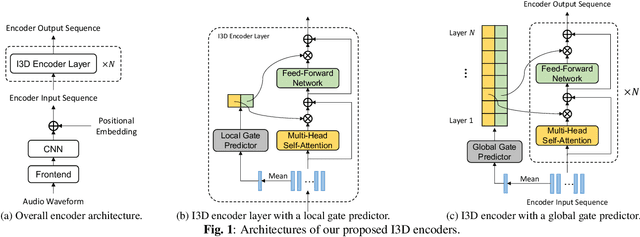
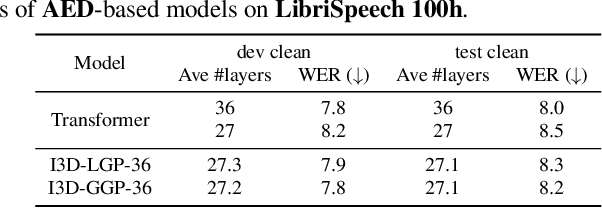
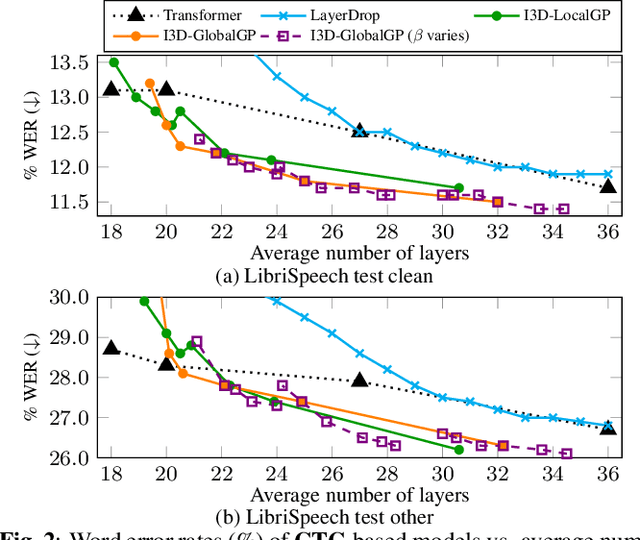
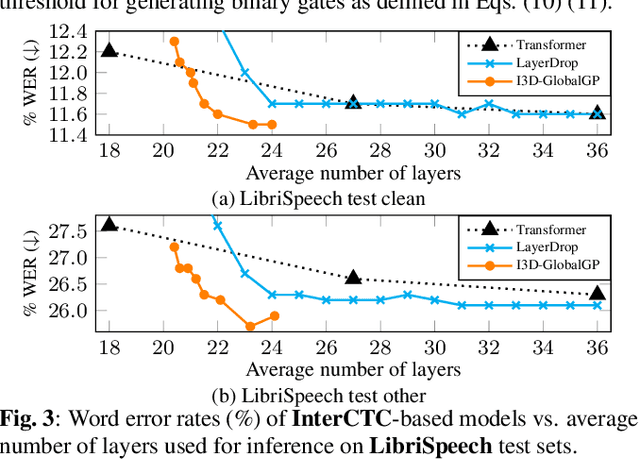
Transformer-based end-to-end speech recognition has achieved great success. However, the large footprint and computational overhead make it difficult to deploy these models in some real-world applications. Model compression techniques can reduce the model size and speed up inference, but the compressed model has a fixed architecture which might be suboptimal. We propose a novel Transformer encoder with Input-Dependent Dynamic Depth (I3D) to achieve strong performance-efficiency trade-offs. With a similar number of layers at inference time, I3D-based models outperform the vanilla Transformer and the static pruned model via iterative layer pruning. We also present interesting analysis on the gate probabilities and the input-dependency, which helps us better understand deep encoders.
Enhancing multilingual speech recognition in air traffic control by sentence-level language identification
Apr 29, 2023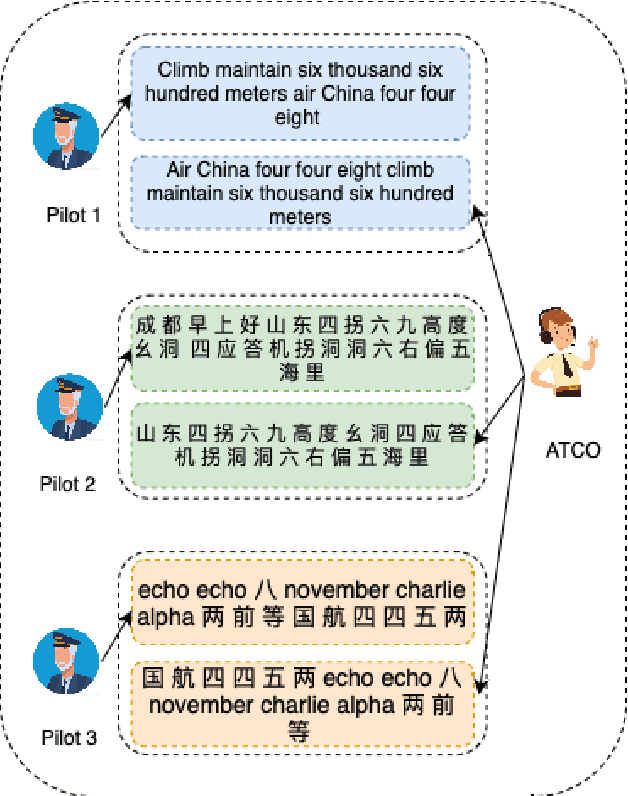
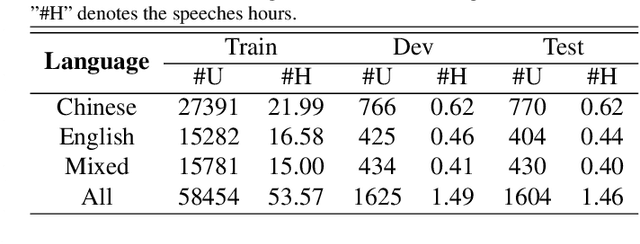
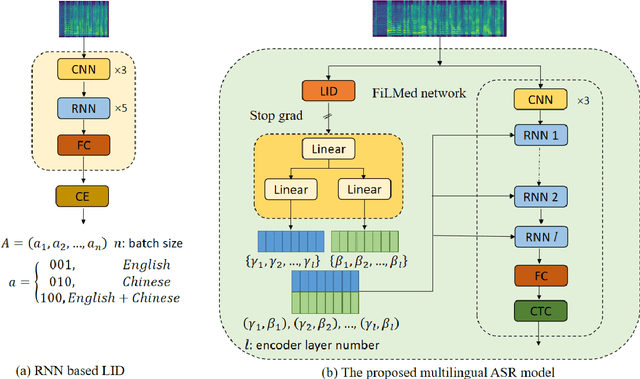
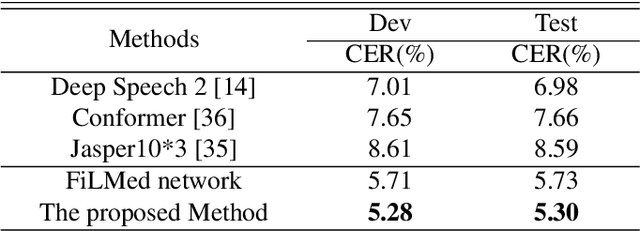
Automatic speech recognition (ASR) technique is becoming increasingly popular to improve the efficiency and safety of air traffic control (ATC) operations. However, the conversation between ATC controllers and pilots using multilingual speech brings a great challenge to building high-accuracy ASR systems. In this work, we present a two-stage multilingual ASR framework. The first stage is to train a language identifier (LID), that based on a recurrent neural network (RNN) to obtain sentence language identification in the form of one-hot encoding. The second stage aims to train an RNN-based end-to-end multilingual recognition model that utilizes sentence language features generated by LID to enhance input features. In this work, We introduce Featurewise Linear Modulation (FiLM) to improve the performance of multilingual ASR by utilizing sentence language identification. Furthermore, we introduce a new sentence language identification learning module called SLIL, which consists of a FiLM layer and a Squeeze-and-Excitation Networks layer. Extensive experiments on the ATCSpeech dataset show that our proposed method outperforms the baseline model. Compared to the vanilla FiLMed backbone model, the proposed multilingual ASR model obtains about 7.50% character error rate relative performance improvement.
Political corpus creation through automatic speech recognition on EU debates
Apr 17, 2023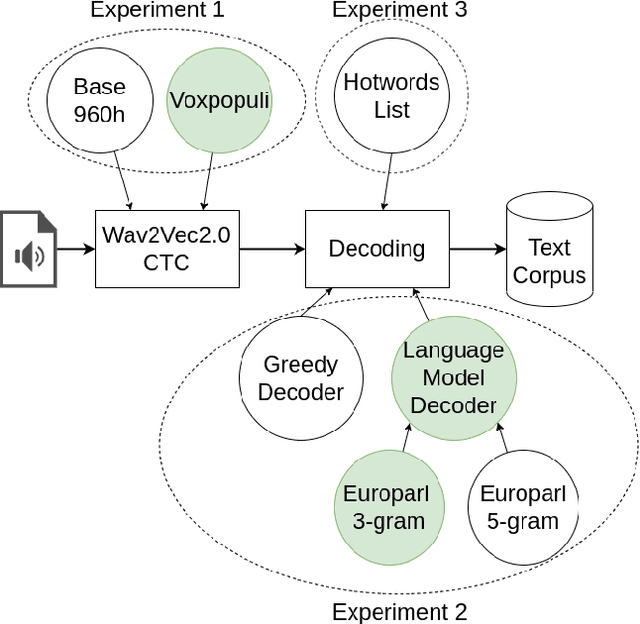

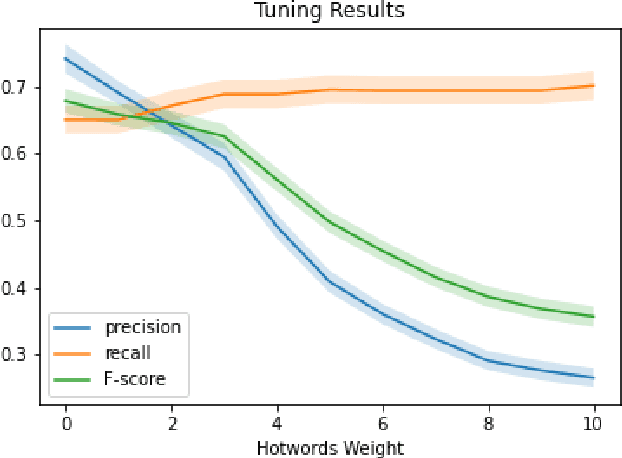
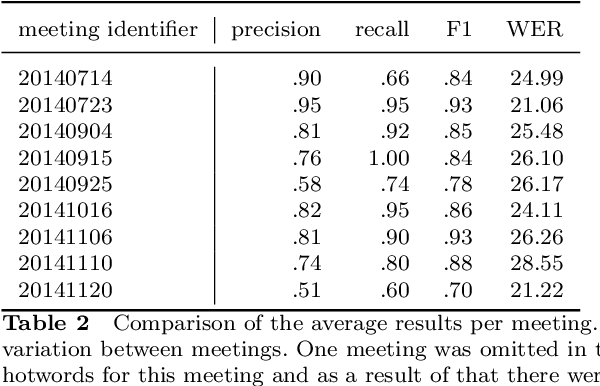
In this paper, we present a transcribed corpus of the LIBE committee of the EU parliament, totalling 3.6 Million running words. The meetings of parliamentary committees of the EU are a potentially valuable source of information for political scientists but the data is not readily available because only disclosed as speech recordings together with limited metadata. The meetings are in English, partly spoken by non-native speakers, and partly spoken by interpreters. We investigated the most appropriate Automatic Speech Recognition (ASR) model to create an accurate text transcription of the audio recordings of the meetings in order to make their content available for research and analysis. We focused on the unsupervised domain adaptation of the ASR pipeline. Building on the transformer-based Wav2vec2.0 model, we experimented with multiple acoustic models, language models and the addition of domain-specific terms. We found that a domain-specific acoustic model and a domain-specific language model give substantial improvements to the ASR output, reducing the word error rate (WER) from 28.22 to 17.95. The use of domain-specific terms in the decoding stage did not have a positive effect on the quality of the ASR in terms of WER. Initial topic modelling results indicated that the corpus is useful for downstream analysis tasks. We release the resulting corpus and our analysis pipeline for future research.
A Novel Method for improving accuracy in neural network by reinstating traditional back propagation technique
Aug 09, 2023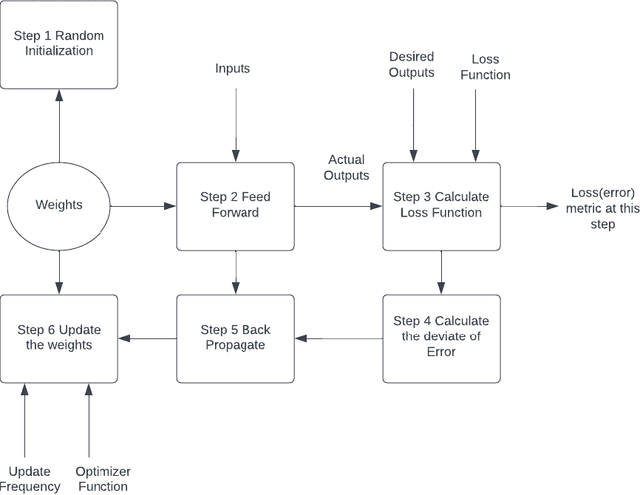
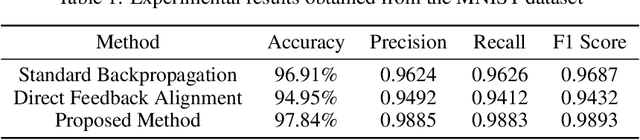

Deep learning has revolutionized industries like computer vision, natural language processing, and speech recognition. However, back propagation, the main method for training deep neural networks, faces challenges like computational overhead and vanishing gradients. In this paper, we propose a novel instant parameter update methodology that eliminates the need for computing gradients at each layer. Our approach accelerates learning, avoids the vanishing gradient problem, and outperforms state-of-the-art methods on benchmark data sets. This research presents a promising direction for efficient and effective deep neural network training.
Naaloss: Rethinking the objective of speech enhancement
Aug 24, 2023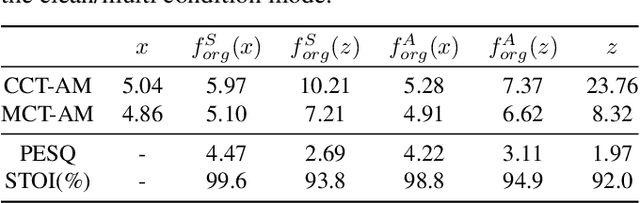
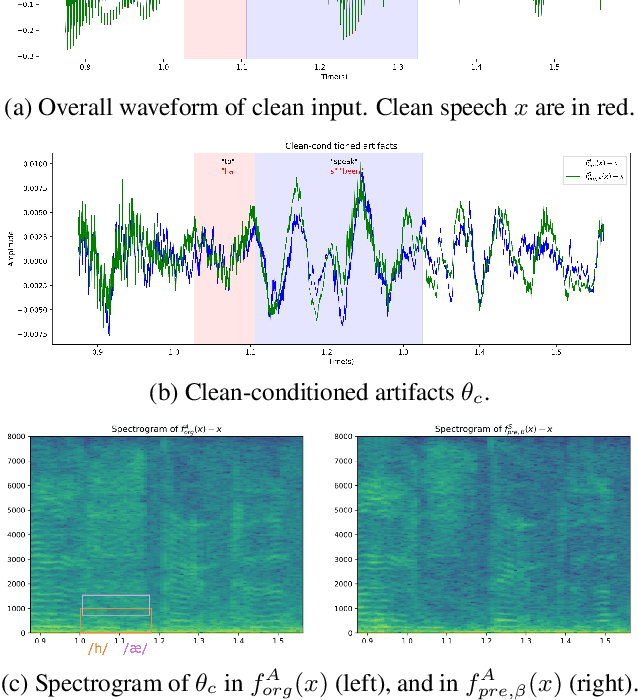
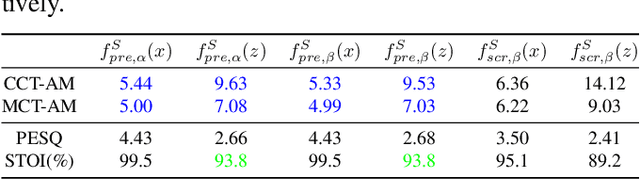
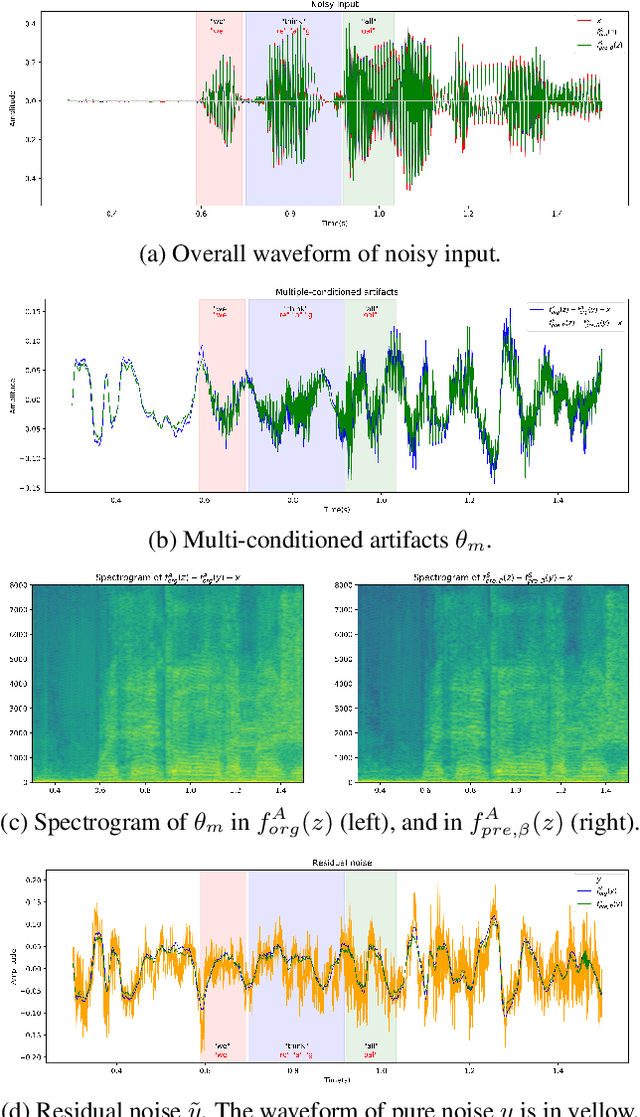
Reducing noise interference is crucial for automatic speech recognition (ASR) in a real-world scenario. However, most single-channel speech enhancement (SE) generates "processing artifacts" that negatively affect ASR performance. Hence, in this study, we suggest a Noise- and Artifacts-aware loss function, NAaLoss, to ameliorate the influence of artifacts from a novel perspective. NAaLoss considers the loss of estimation, de-artifact, and noise ignorance, enabling the learned SE to individually model speech, artifacts, and noise. We examine two SE models (simple/advanced) learned with NAaLoss under various input scenarios (clean/noisy) using two configurations of the ASR system (with/without noise robustness). Experiments reveal that NAaLoss significantly improves the ASR performance of most setups while preserving the quality of SE toward perception and intelligibility. Furthermore, we visualize artifacts through waveforms and spectrograms, and explain their impact on ASR.
From English to More Languages: Parameter-Efficient Model Reprogramming for Cross-Lingual Speech Recognition
Jan 19, 2023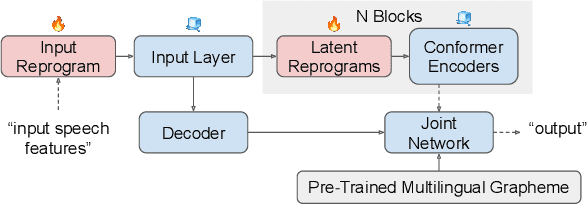

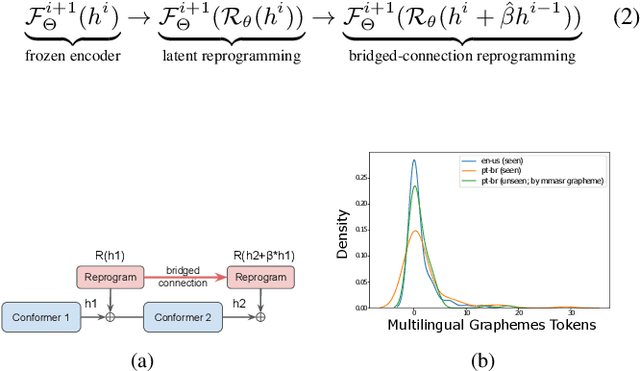
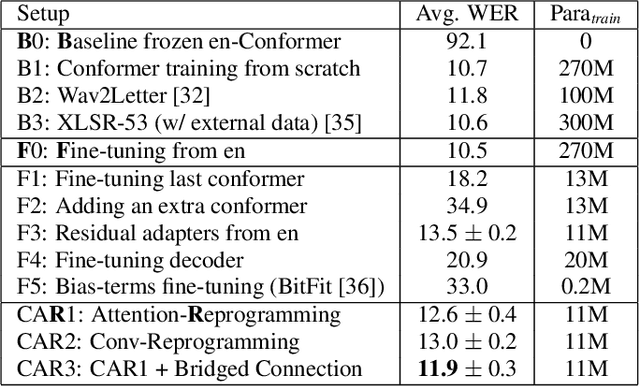
In this work, we propose a new parameter-efficient learning framework based on neural model reprogramming for cross-lingual speech recognition, which can \textbf{re-purpose} well-trained English automatic speech recognition (ASR) models to recognize the other languages. We design different auxiliary neural architectures focusing on learnable pre-trained feature enhancement that, for the first time, empowers model reprogramming on ASR. Specifically, we investigate how to select trainable components (i.e., encoder) of a conformer-based RNN-Transducer, as a frozen pre-trained backbone. Experiments on a seven-language multilingual LibriSpeech speech (MLS) task show that model reprogramming only requires 4.2% (11M out of 270M) to 6.8% (45M out of 660M) of its original trainable parameters from a full ASR model to perform competitive results in a range of 11.9% to 8.1% WER averaged across different languages. In addition, we discover different setups to make large-scale pre-trained ASR succeed in both monolingual and multilingual speech recognition. Our methods outperform existing ASR tuning architectures and their extension with self-supervised losses (e.g., w2v-bert) in terms of lower WER and better training efficiency.
Making More of Little Data: Improving Low-Resource Automatic Speech Recognition Using Data Augmentation
May 19, 2023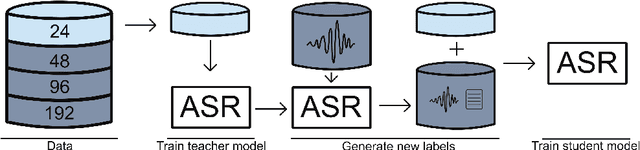
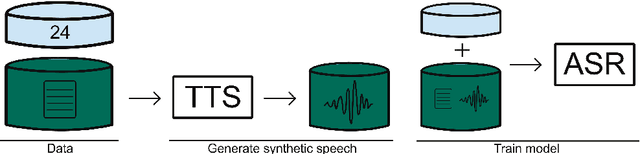
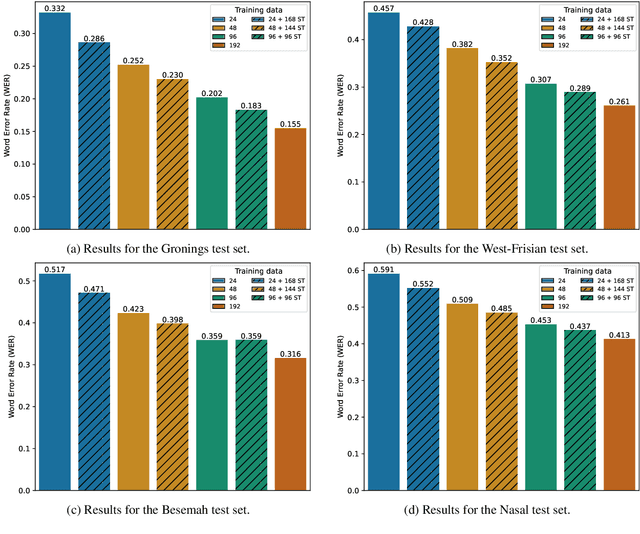
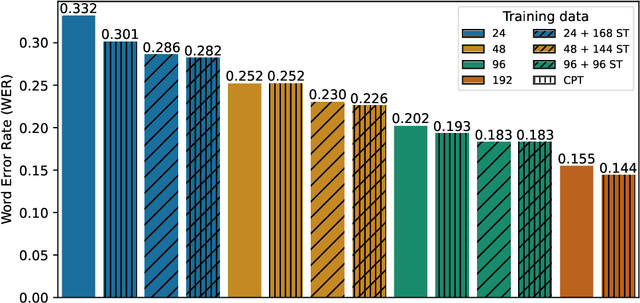
The performance of automatic speech recognition (ASR) systems has advanced substantially in recent years, particularly for languages for which a large amount of transcribed speech is available. Unfortunately, for low-resource languages, such as minority languages, regional languages or dialects, ASR performance generally remains much lower. In this study, we investigate whether data augmentation techniques could help improve low-resource ASR performance, focusing on four typologically diverse minority languages or language variants (West Germanic: Gronings, West-Frisian; Malayo-Polynesian: Besemah, Nasal). For all four languages, we examine the use of self-training, where an ASR system trained with the available human-transcribed data is used to generate transcriptions, which are then combined with the original data to train a new ASR system. For Gronings, for which there was a pre-existing text-to-speech (TTS) system available, we also examined the use of TTS to generate ASR training data from text-only sources. We find that using a self-training approach consistently yields improved performance (a relative WER reduction up to 20.5% compared to using an ASR system trained on 24 minutes of manually transcribed speech). The performance gain from TTS augmentation for Gronings was even stronger (up to 25.5% relative reduction in WER compared to a system based on 24 minutes of manually transcribed speech). In sum, our results show the benefit of using self-training or (if possible) TTS-generated data as an efficient solution to overcome the limitations of data availability for resource-scarce languages in order to improve ASR performance.