 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Code-Switched Urdu ASR for Noisy Telephonic Environment using Data Centric Approach with Hybrid HMM and CNN-TDNN
Jul 24, 2023
Call Centers have huge amount of audio data which can be used for achieving valuable business insights and transcription of phone calls is manually tedious task. An effective Automated Speech Recognition system can accurately transcribe these calls for easy search through call history for specific context and content allowing automatic call monitoring, improving QoS through keyword search and sentiment analysis. ASR for Call Center requires more robustness as telephonic environment are generally noisy. Moreover, there are many low-resourced languages that are on verge of extinction which can be preserved with help of Automatic Speech Recognition Technology. Urdu is the $10^{th}$ most widely spoken language in the world, with 231,295,440 worldwide still remains a resource constrained language in ASR. Regional call-center conversations operate in local language, with a mix of English numbers and technical terms generally causing a "code-switching" problem. Hence, this paper describes an implementation framework of a resource efficient Automatic Speech Recognition/ Speech to Text System in a noisy call-center environment using Chain Hybrid HMM and CNN-TDNN for Code-Switched Urdu Language. Using Hybrid HMM-DNN approach allowed us to utilize the advantages of Neural Network with less labelled data. Adding CNN with TDNN has shown to work better in noisy environment due to CNN's additional frequency dimension which captures extra information from noisy speech, thus improving accuracy. We collected data from various open sources and labelled some of the unlabelled data after analysing its general context and content from Urdu language as well as from commonly used words from other languages, primarily English and were able to achieve WER of 5.2% with noisy as well as clean environment in isolated words or numbers as well as in continuous spontaneous speech.
Mixture Encoder for Joint Speech Separation and Recognition
Jun 21, 2023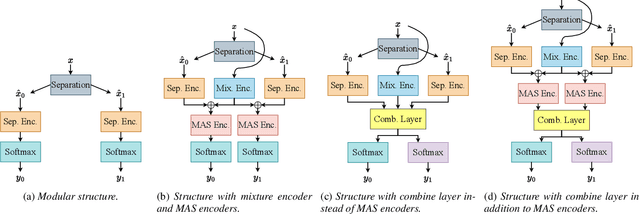
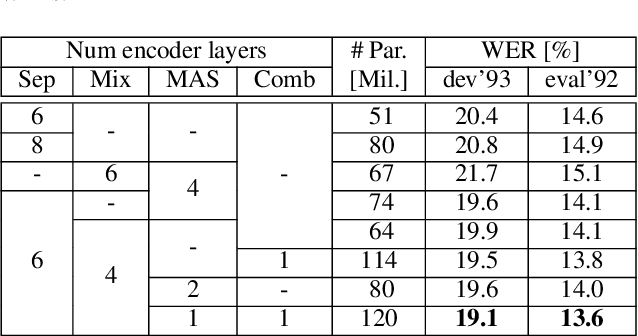
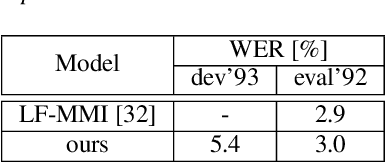
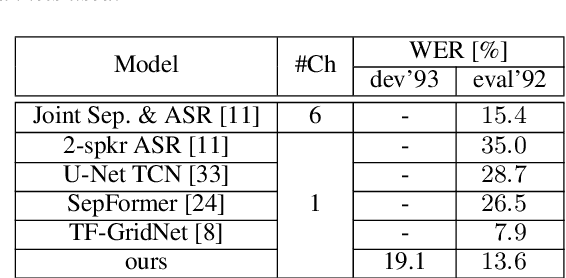
Multi-speaker automatic speech recognition (ASR) is crucial for many real-world applications, but it requires dedicated modeling techniques. Existing approaches can be divided into modular and end-to-end methods. Modular approaches separate speakers and recognize each of them with a single-speaker ASR system. End-to-end models process overlapped speech directly in a single, powerful neural network. This work proposes a middle-ground approach that leverages explicit speech separation similarly to the modular approach but also incorporates mixture speech information directly into the ASR module in order to mitigate the propagation of errors made by the speech separator. We also explore a way to exchange cross-speaker context information through a layer that combines information of the individual speakers. Our system is optimized through separate and joint training stages and achieves a relative improvement of 7% in word error rate over a purely modular setup on the SMS-WSJ task.
Leveraging Visemes for Better Visual Speech Representation and Lip Reading
Jul 19, 2023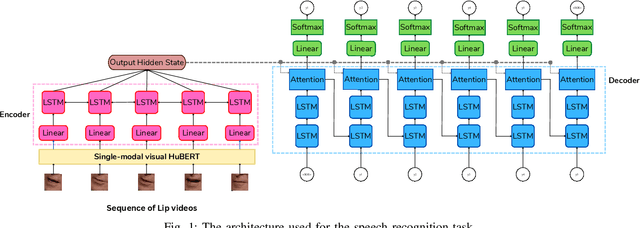
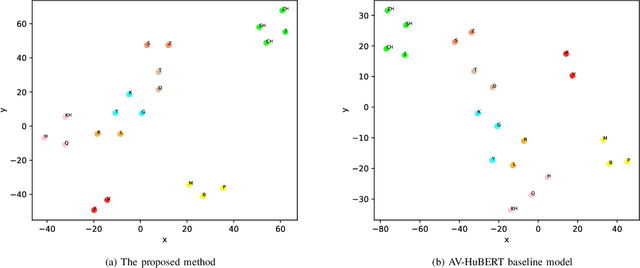
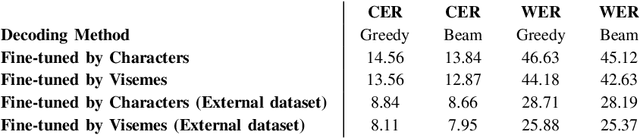
Lip reading is a challenging task that has many potential applications in speech recognition, human-computer interaction, and security systems. However, existing lip reading systems often suffer from low accuracy due to the limitations of video features. In this paper, we propose a novel approach that leverages visemes, which are groups of phonetically similar lip shapes, to extract more discriminative and robust video features for lip reading. We evaluate our approach on various tasks, including word-level and sentence-level lip reading, and audiovisual speech recognition using the Arman-AV dataset, a largescale Persian corpus. Our experimental results show that our viseme based approach consistently outperforms the state-of-theart methods in all these tasks. The proposed method reduces the lip-reading word error rate (WER) by 9.1% relative to the best previous method.
Dual-Attention Neural Transducers for Efficient Wake Word Spotting in Speech Recognition
Apr 05, 2023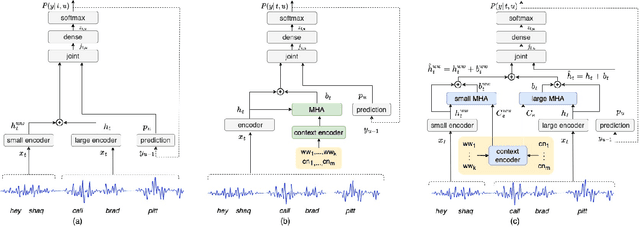
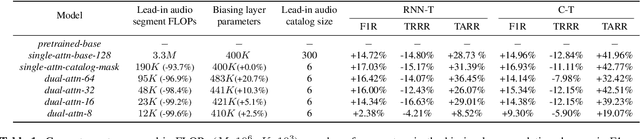
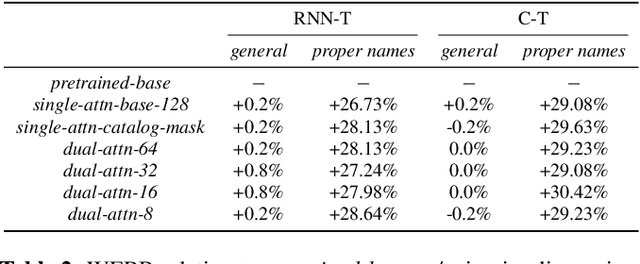
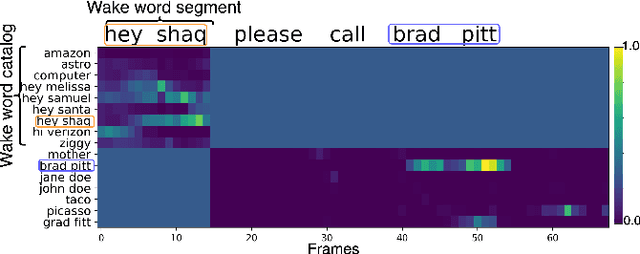
We present dual-attention neural biasing, an architecture designed to boost Wake Words (WW) recognition and improve inference time latency on speech recognition tasks. This architecture enables a dynamic switch for its runtime compute paths by exploiting WW spotting to select which branch of its attention networks to execute for an input audio frame. With this approach, we effectively improve WW spotting accuracy while saving runtime compute cost as defined by floating point operations (FLOPs). Using an in-house de-identified dataset, we demonstrate that the proposed dual-attention network can reduce the compute cost by $90\%$ for WW audio frames, with only $1\%$ increase in the number of parameters. This architecture improves WW F1 score by $16\%$ relative and improves generic rare word error rate by $3\%$ relative compared to the baselines.
Sharing Low Rank Conformer Weights for Tiny Always-On Ambient Speech Recognition Models
Mar 15, 2023
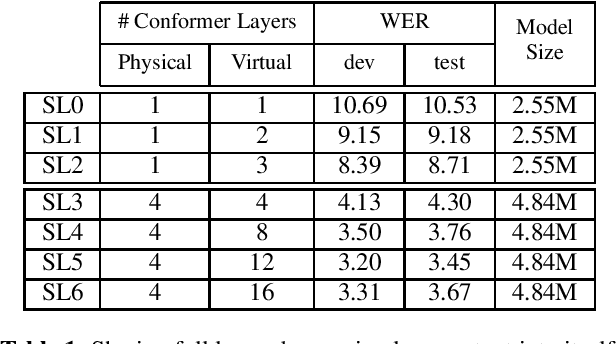

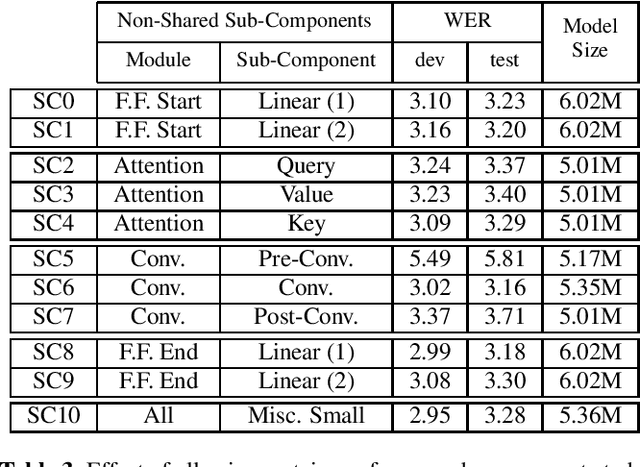
Continued improvements in machine learning techniques offer exciting new opportunities through the use of larger models and larger training datasets. However, there is a growing need to offer these new capabilities on-board low-powered devices such as smartphones, wearables and other embedded environments where only low memory is available. Towards this, we consider methods to reduce the model size of Conformer-based speech recognition models which typically require models with greater than 100M parameters down to just $5$M parameters while minimizing impact on model quality. Such a model allows us to achieve always-on ambient speech recognition on edge devices with low-memory neural processors. We propose model weight reuse at different levels within our model architecture: (i) repeating full conformer block layers, (ii) sharing specific conformer modules across layers, (iii) sharing sub-components per conformer module, and (iv) sharing decomposed sub-component weights after low-rank decomposition. By sharing weights at different levels of our model, we can retain the full model in-memory while increasing the number of virtual transformations applied to the input. Through a series of ablation studies and evaluations, we find that with weight sharing and a low-rank architecture, we can achieve a WER of 2.84 and 2.94 for Librispeech dev-clean and test-clean respectively with a $5$M parameter model.
Complex Dynamic Neurons Improved Spiking Transformer Network for Efficient Automatic Speech Recognition
Feb 02, 2023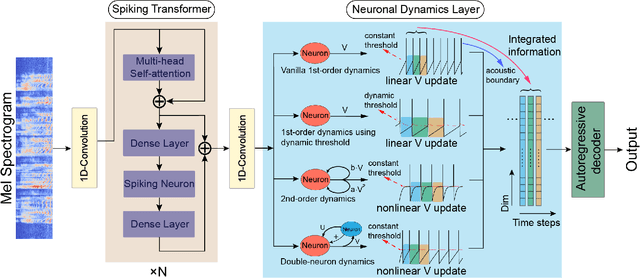

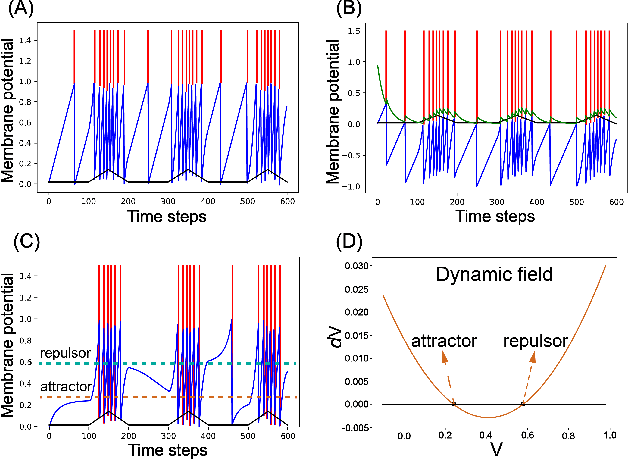
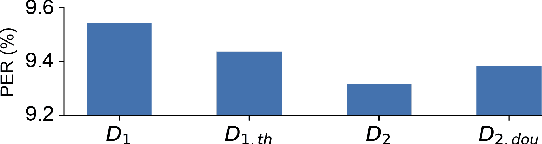
The spiking neural network (SNN) using leaky-integrated-and-fire (LIF) neurons has been commonly used in automatic speech recognition (ASR) tasks. However, the LIF neuron is still relatively simple compared to that in the biological brain. Further research on more types of neurons with different scales of neuronal dynamics is necessary. Here we introduce four types of neuronal dynamics to post-process the sequential patterns generated from the spiking transformer to get the complex dynamic neuron improved spiking transformer neural network (DyTr-SNN). We found that the DyTr-SNN could handle the non-toy automatic speech recognition task well, representing a lower phoneme error rate, lower computational cost, and higher robustness. These results indicate that the further cooperation of SNNs and neural dynamics at the neuron and network scales might have much in store for the future, especially on the ASR tasks.
Streaming Punctuation: A Novel Punctuation Technique Leveraging Bidirectional Context for Continuous Speech Recognition
Jan 10, 2023

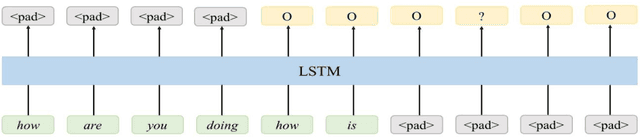

While speech recognition Word Error Rate (WER) has reached human parity for English, continuous speech recognition scenarios such as voice typing and meeting transcriptions still suffer from segmentation and punctuation problems, resulting from irregular pausing patterns or slow speakers. Transformer sequence tagging models are effective at capturing long bi-directional context, which is crucial for automatic punctuation. Automatic Speech Recognition (ASR) production systems, however, are constrained by real-time requirements, making it hard to incorporate the right context when making punctuation decisions. Context within the segments produced by ASR decoders can be helpful but limiting in overall punctuation performance for a continuous speech session. In this paper, we propose a streaming approach for punctuation or re-punctuation of ASR output using dynamic decoding windows and measure its impact on punctuation and segmentation accuracy across scenarios. The new system tackles over-segmentation issues, improving segmentation F0.5-score by 13.9%. Streaming punctuation achieves an average BLEUscore improvement of 0.66 for the downstream task of Machine Translation (MT).
* arXiv admin note: substantial text overlap with arXiv:2210.05756
Capturing Spectral and Long-term Contextual Information for Speech Emotion Recognition Using Deep Learning Techniques
Aug 04, 2023
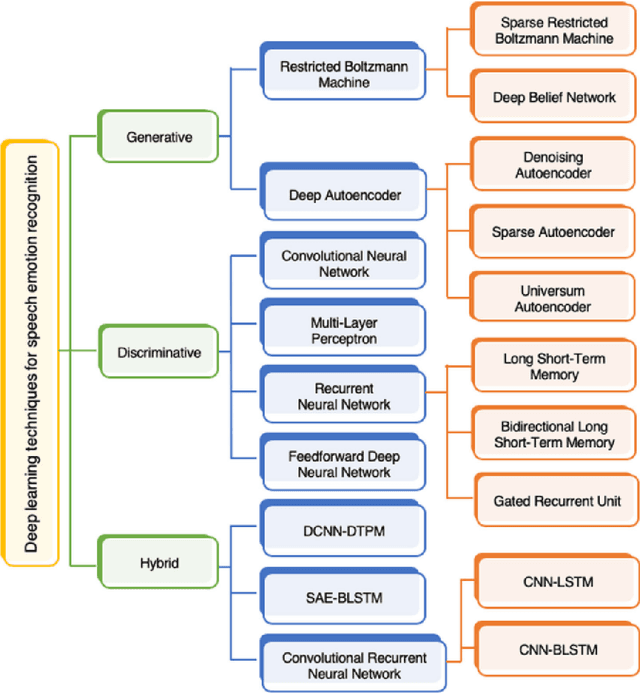
Traditional approaches in speech emotion recognition, such as LSTM, CNN, RNN, SVM, and MLP, have limitations such as difficulty capturing long-term dependencies in sequential data, capturing the temporal dynamics, and struggling to capture complex patterns and relationships in multimodal data. This research addresses these shortcomings by proposing an ensemble model that combines Graph Convolutional Networks (GCN) for processing textual data and the HuBERT transformer for analyzing audio signals. We found that GCNs excel at capturing Long-term contextual dependencies and relationships within textual data by leveraging graph-based representations of text and thus detecting the contextual meaning and semantic relationships between words. On the other hand, HuBERT utilizes self-attention mechanisms to capture long-range dependencies, enabling the modeling of temporal dynamics present in speech and capturing subtle nuances and variations that contribute to emotion recognition. By combining GCN and HuBERT, our ensemble model can leverage the strengths of both approaches. This allows for the simultaneous analysis of multimodal data, and the fusion of these modalities enables the extraction of complementary information, enhancing the discriminative power of the emotion recognition system. The results indicate that the combined model can overcome the limitations of traditional methods, leading to enhanced accuracy in recognizing emotions from speech.
Self-regularised Minimum Latency Training for Streaming Transformer-based Speech Recognition
Apr 24, 2023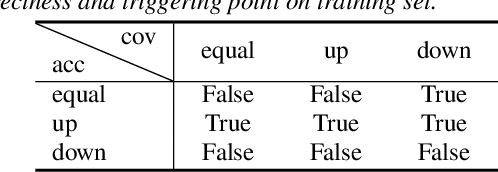
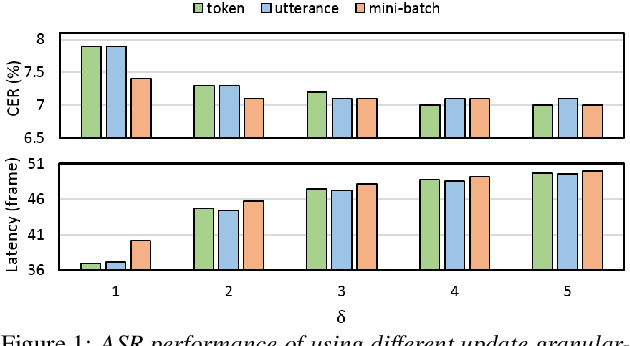
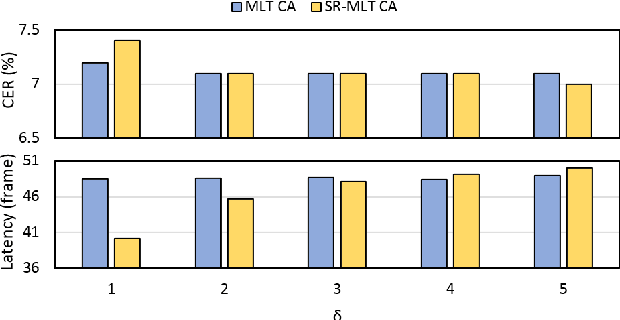
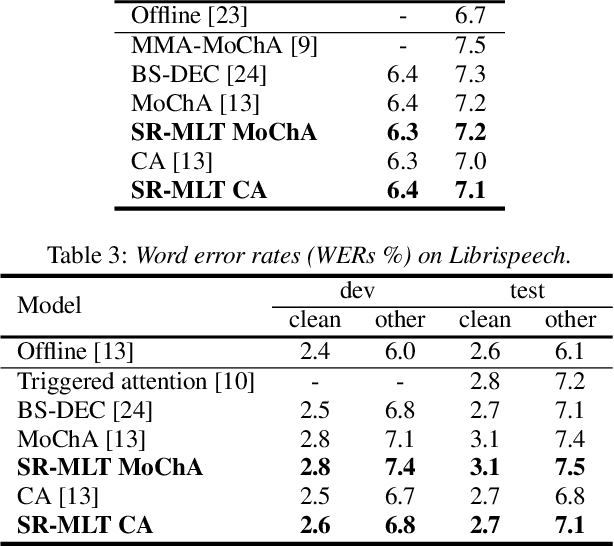
This paper proposes a self-regularised minimum latency training (SR-MLT) method for streaming Transformer-based automatic speech recognition (ASR) systems. In previous works, latency was optimised by truncating the online attention weights based on the hard alignments obtained from conventional ASR models, without taking into account the potential loss of ASR accuracy. On the contrary, here we present a strategy to obtain the alignments as a part of the model training without external supervision. The alignments produced by the proposed method are dynamically regularised on the training data, such that the latency reduction does not result in the loss of ASR accuracy. SR-MLT is applied as a fine-tuning step on the pre-trained Transformer models that are based on either monotonic chunkwise attention (MoChA) or cumulative attention (CA) algorithms for online decoding. ASR experiments on the AIShell-1 and Librispeech datasets show that when applied on a decent pre-trained MoChA or CA baseline model, SR-MLT can effectively reduce the latency with the relative gains ranging from 11.8% to 39.5%. Furthermore, we also demonstrate that under certain accuracy levels, the models trained with SR-MLT can achieve lower latency when compared to those supervised using external hard alignments.