 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Cross-lingual Knowledge Transfer and Iterative Pseudo-labeling for Low-Resource Speech Recognition with Transducers
May 23, 2023
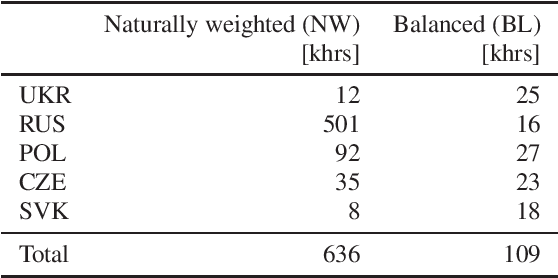


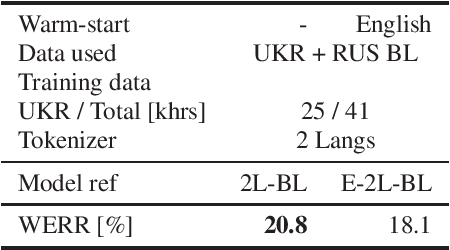
Voice technology has become ubiquitous recently. However, the accuracy, and hence experience, in different languages varies significantly, which makes the technology not equally inclusive. The availability of data for different languages is one of the key factors affecting accuracy, especially in training of all-neural end-to-end automatic speech recognition systems. Cross-lingual knowledge transfer and iterative pseudo-labeling are two techniques that have been shown to be successful for improving the accuracy of ASR systems, in particular for low-resource languages, like Ukrainian. Our goal is to train an all-neural Transducer-based ASR system to replace a DNN-HMM hybrid system with no manually annotated training data. We show that the Transducer system trained using transcripts produced by the hybrid system achieves 18% reduction in terms of word error rate. However, using a combination of cross-lingual knowledge transfer from related languages and iterative pseudo-labeling, we are able to achieve 35% reduction of the error rate.
Personalized Adaptation with Pre-trained Speech Encoders for Continuous Emotion Recognition
Sep 05, 2023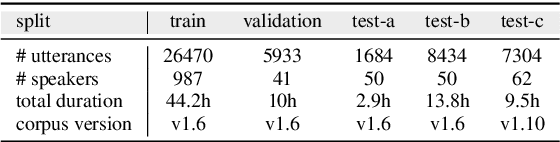
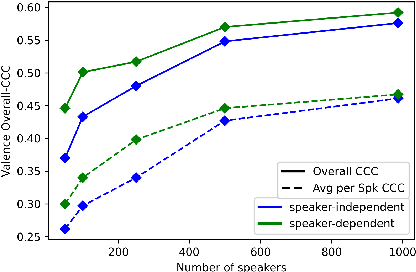
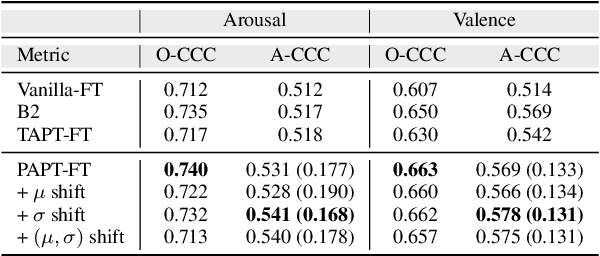
There are individual differences in expressive behaviors driven by cultural norms and personality. This between-person variation can result in reduced emotion recognition performance. Therefore, personalization is an important step in improving the generalization and robustness of speech emotion recognition. In this paper, to achieve unsupervised personalized emotion recognition, we first pre-train an encoder with learnable speaker embeddings in a self-supervised manner to learn robust speech representations conditioned on speakers. Second, we propose an unsupervised method to compensate for the label distribution shifts by finding similar speakers and leveraging their label distributions from the training set. Extensive experimental results on the MSP-Podcast corpus indicate that our method consistently outperforms strong personalization baselines and achieves state-of-the-art performance for valence estimation.
Agricultural Robotic System: The Automation of Detection and Speech Control
Jul 19, 2023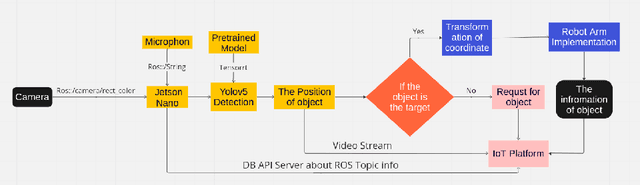
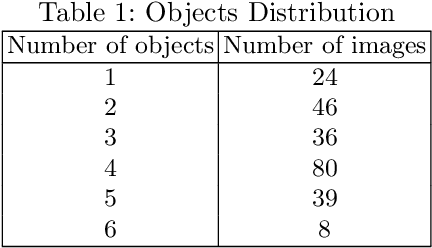
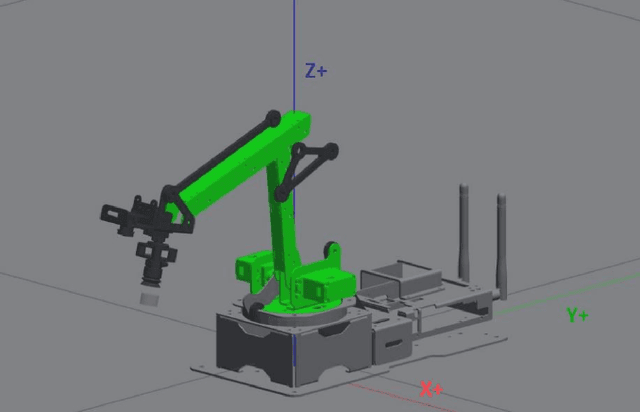
Agriculture industries often face challenges in manual tasks such as planting, harvesting, fertilizing, and detection, which can be time consuming and prone to errors. The "Agricultural Robotic System" project addresses these issues through a modular design that integrates advanced visual, speech recognition, and robotic technologies. This system is comprised of separate but interconnected modules for vision detection and speech recognition, creating a flexible and adaptable solution. The vision detection module uses computer vision techniques, trained on YOLOv5 and deployed on the Jetson Nano in TensorRT format, to accurately detect and identify different items. A robotic arm module then precisely controls the picking up of seedlings or seeds, and arranges them in specific locations. The speech recognition module enhances intelligent human robot interaction, allowing for efficient and intuitive control of the system. This modular approach improves the efficiency and accuracy of agricultural tasks, demonstrating the potential of robotics in the agricultural industry.
Improving Accented Speech Recognition with Multi-Domain Training
Mar 14, 2023
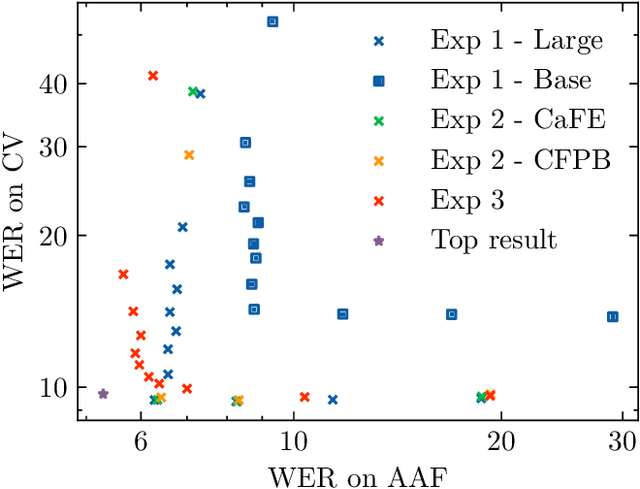

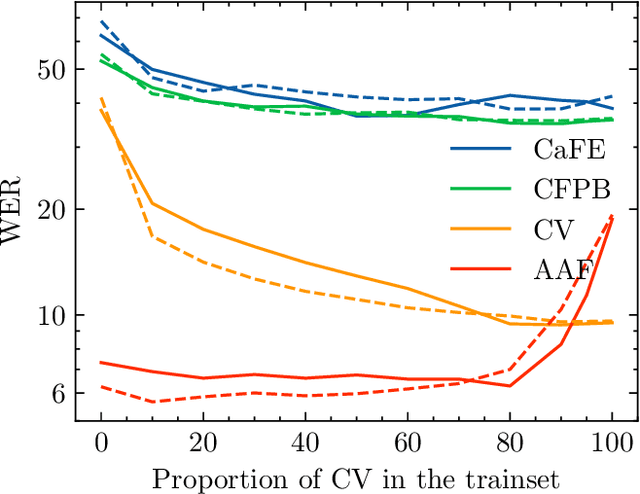
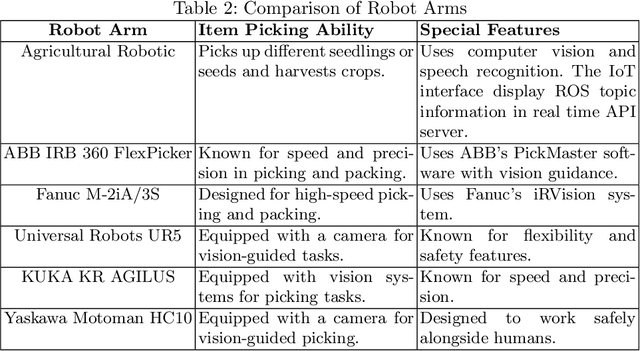
Thanks to the rise of self-supervised learning, automatic speech recognition (ASR) systems now achieve near-human performance on a wide variety of datasets. However, they still lack generalization capability and are not robust to domain shifts like accent variations. In this work, we use speech audio representing four different French accents to create fine-tuning datasets that improve the robustness of pre-trained ASR models. By incorporating various accents in the training set, we obtain both in-domain and out-of-domain improvements. Our numerical experiments show that we can reduce error rates by up to 25% (relative) on African and Belgian accents compared to single-domain training while keeping a good performance on standard French.
Using Text Injection to Improve Recognition of Personal Identifiers in Speech
Aug 14, 2023Accurate recognition of specific categories, such as persons' names, dates or other identifiers is critical in many Automatic Speech Recognition (ASR) applications. As these categories represent personal information, ethical use of this data including collection, transcription, training and evaluation demands special care. One way of ensuring the security and privacy of individuals is to redact or eliminate Personally Identifiable Information (PII) from collection altogether. However, this results in ASR models that tend to have lower recognition accuracy of these categories. We use text-injection to improve the recognition of PII categories by including fake textual substitutes of PII categories in the training data using a text injection method. We demonstrate substantial improvement to Recall of Names and Dates in medical notes while improving overall WER. For alphanumeric digit sequences we show improvements to Character Error Rate and Sentence Accuracy.
Cross-modal Alignment with Optimal Transport for CTC-based ASR
Sep 24, 2023Temporal connectionist temporal classification (CTC)-based automatic speech recognition (ASR) is one of the most successful end to end (E2E) ASR frameworks. However, due to the token independence assumption in decoding, an external language model (LM) is required which destroys its fast parallel decoding property. Several studies have been proposed to transfer linguistic knowledge from a pretrained LM (PLM) to the CTC based ASR. Since the PLM is built from text while the acoustic model is trained with speech, a cross-modal alignment is required in order to transfer the context dependent linguistic knowledge from the PLM to acoustic encoding. In this study, we propose a novel cross-modal alignment algorithm based on optimal transport (OT). In the alignment process, a transport coupling matrix is obtained using OT, which is then utilized to transform a latent acoustic representation for matching the context-dependent linguistic features encoded by the PLM. Based on the alignment, the latent acoustic feature is forced to encode context dependent linguistic information. We integrate this latent acoustic feature to build conformer encoder-based CTC ASR system. On the AISHELL-1 data corpus, our system achieved 3.96% and 4.27% character error rate (CER) for dev and test sets, respectively, which corresponds to relative improvements of 28.39% and 29.42% compared to the baseline conformer CTC ASR system without cross-modal knowledge transfer.
Improving Robustness of Neural Inverse Text Normalization via Data-Augmentation, Semi-Supervised Learning, and Post-Aligning Method
Sep 12, 2023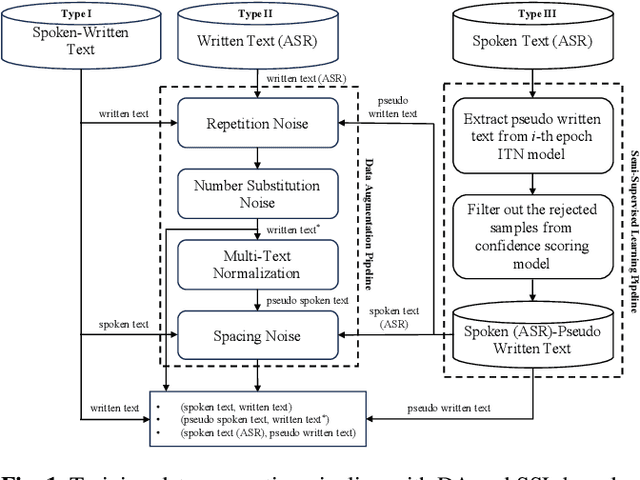
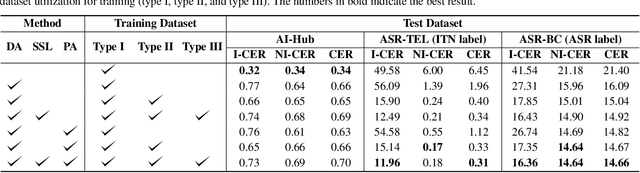
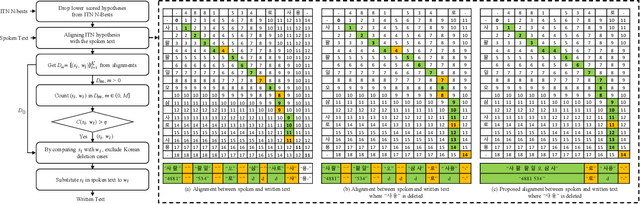
Inverse text normalization (ITN) is crucial for converting spoken-form into written-form, especially in the context of automatic speech recognition (ASR). While most downstream tasks of ASR rely on written-form, ASR systems often output spoken-form, highlighting the necessity for robust ITN in product-level ASR-based applications. Although neural ITN methods have shown promise, they still encounter performance challenges, particularly when dealing with ASR-generated spoken text. These challenges arise from the out-of-domain problem between training data and ASR-generated text. To address this, we propose a direct training approach that utilizes ASR-generated written or spoken text, with pairs augmented through ASR linguistic context emulation and a semi-supervised learning method enhanced by a large language model, respectively. Additionally, we introduce a post-aligning method to manage unpredictable errors, thereby enhancing the reliability of ITN. Our experiments show that our proposed methods remarkably improved ITN performance in various ASR scenarios.
Towards Word-Level End-to-End Neural Speaker Diarization with Auxiliary Network
Sep 15, 2023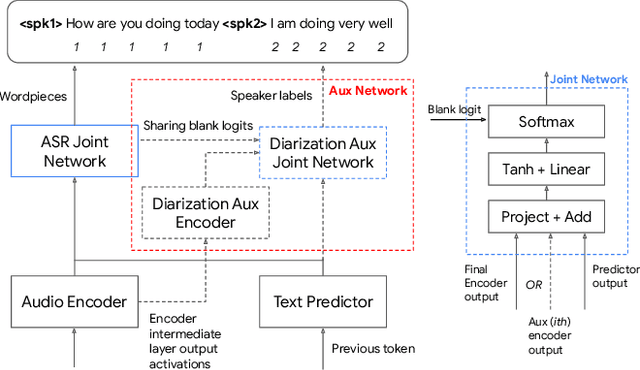
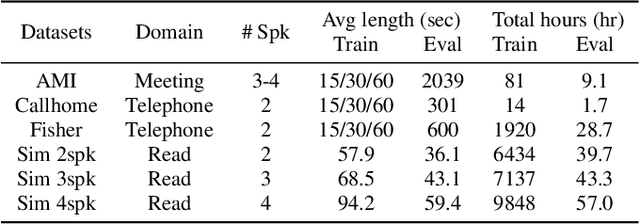
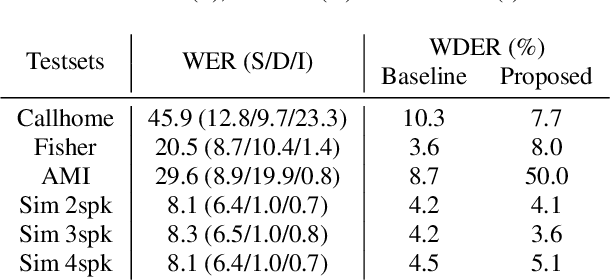
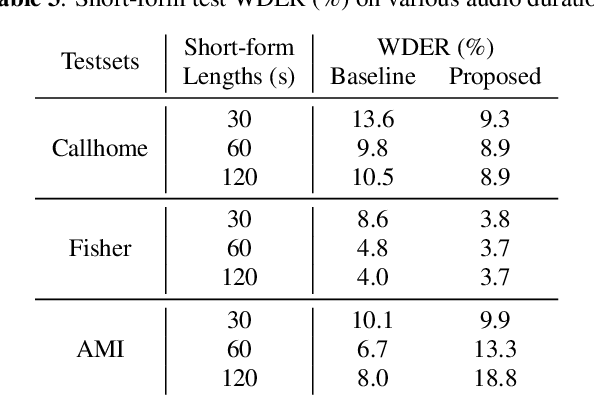
While standard speaker diarization attempts to answer the question "who spoken when", most of relevant applications in reality are more interested in determining "who spoken what". Whether it is the conventional modularized approach or the more recent end-to-end neural diarization (EEND), an additional automatic speech recognition (ASR) model and an orchestration algorithm are required to associate the speaker labels with recognized words. In this paper, we propose Word-level End-to-End Neural Diarization (WEEND) with auxiliary network, a multi-task learning algorithm that performs end-to-end ASR and speaker diarization in the same neural architecture. That is, while speech is being recognized, speaker labels are predicted simultaneously for each recognized word. Experimental results demonstrate that WEEND outperforms the turn-based diarization baseline system on all 2-speaker short-form scenarios and has the capability to generalize to audio lengths of 5 minutes. Although 3+speaker conversations are harder, we find that with enough in-domain training data, WEEND has the potential to deliver high quality diarized text.
HTEC: Human Transcription Error Correction
Sep 18, 2023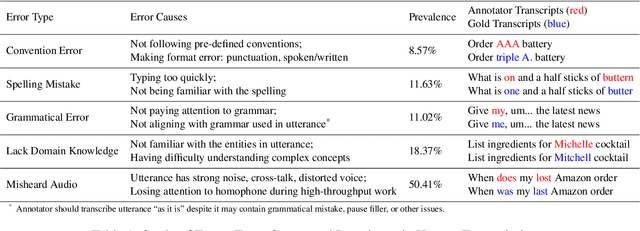
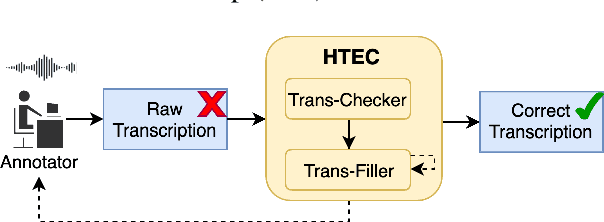

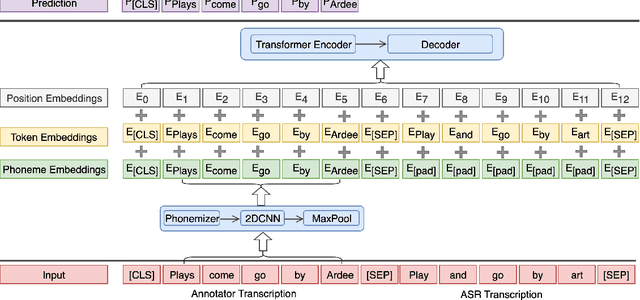
High-quality human transcription is essential for training and improving Automatic Speech Recognition (ASR) models. Recent study~\cite{libricrowd} has found that every 1% worse transcription Word Error Rate (WER) increases approximately 2% ASR WER by using the transcriptions to train ASR models. Transcription errors are inevitable for even highly-trained annotators. However, few studies have explored human transcription correction. Error correction methods for other problems, such as ASR error correction and grammatical error correction, do not perform sufficiently for this problem. Therefore, we propose HTEC for Human Transcription Error Correction. HTEC consists of two stages: Trans-Checker, an error detection model that predicts and masks erroneous words, and Trans-Filler, a sequence-to-sequence generative model that fills masked positions. We propose a holistic list of correction operations, including four novel operations handling deletion errors. We further propose a variant of embeddings that incorporates phoneme information into the input of the transformer. HTEC outperforms other methods by a large margin and surpasses human annotators by 2.2% to 4.5% in WER. Finally, we deployed HTEC to assist human annotators and showed HTEC is particularly effective as a co-pilot, which improves transcription quality by 15.1% without sacrificing transcription velocity.
Learning Speech Representation From Contrastive Token-Acoustic Pretraining
Sep 06, 2023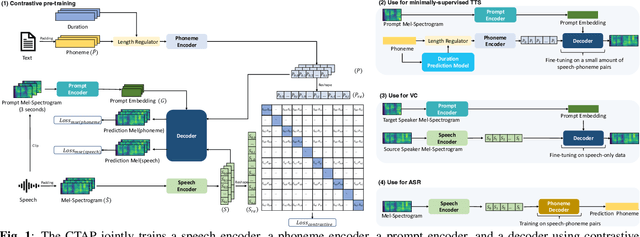
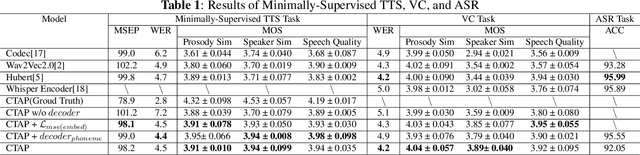
For fine-grained generation and recognition tasks such as minimally-supervised text-to-speech (TTS), voice conversion (VC), and automatic speech recognition (ASR), the intermediate representations extracted from speech should serve as a "bridge" between text and acoustic information, containing information from both modalities. The semantic content is emphasized, while the paralinguistic information such as speaker identity and acoustic details should be de-emphasized. However, existing methods for extracting fine-grained intermediate representations from speech suffer from issues of excessive redundancy and dimension explosion. Contrastive learning is a good method for modeling intermediate representations from two modalities. However, existing contrastive learning methods in the audio field focus on extracting global descriptive information for downstream audio classification tasks, making them unsuitable for TTS, VC, and ASR tasks. To address these issues, we propose a method named "Contrastive Token-Acoustic Pretraining (CTAP)", which uses two encoders to bring phoneme and speech into a joint multimodal space, learning how to connect phoneme and speech at the frame level. The CTAP model is trained on 210k speech and phoneme text pairs, achieving minimally-supervised TTS, VC, and ASR. The proposed CTAP method offers a promising solution for fine-grained generation and recognition downstream tasks in speech processing.