 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Adapting Text-based Dialogue State Tracker for Spoken Dialogues
Aug 30, 2023
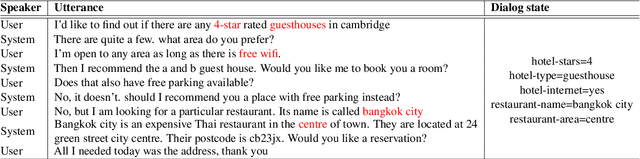
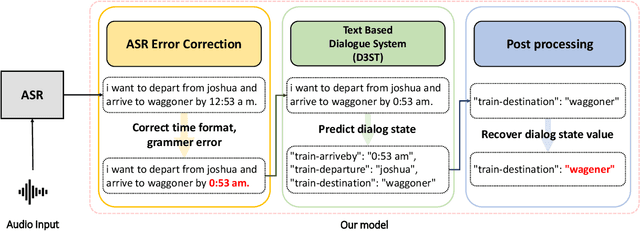
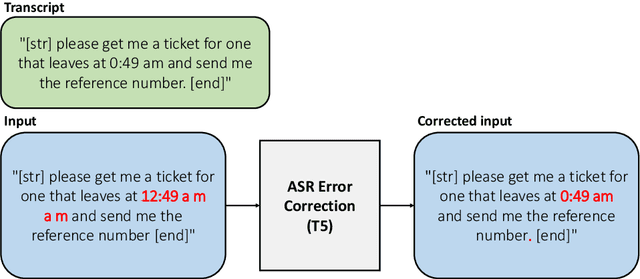

Although there have been remarkable advances in dialogue systems through the dialogue systems technology competition (DSTC), it remains one of the key challenges to building a robust task-oriented dialogue system with a speech interface. Most of the progress has been made for text-based dialogue systems since there are abundant datasets with written corpora while those with spoken dialogues are very scarce. However, as can be seen from voice assistant systems such as Siri and Alexa, it is of practical importance to transfer the success to spoken dialogues. In this paper, we describe our engineering effort in building a highly successful model that participated in the speech-aware dialogue systems technology challenge track in DSTC11. Our model consists of three major modules: (1) automatic speech recognition error correction to bridge the gap between the spoken and the text utterances, (2) text-based dialogue system (D3ST) for estimating the slots and values using slot descriptions, and (3) post-processing for recovering the error of the estimated slot value. Our experiments show that it is important to use an explicit automatic speech recognition error correction module, post-processing, and data augmentation to adapt a text-based dialogue state tracker for spoken dialogue corpora.
On the Relation between Internal Language Model and Sequence Discriminative Training for Neural Transducers
Sep 25, 2023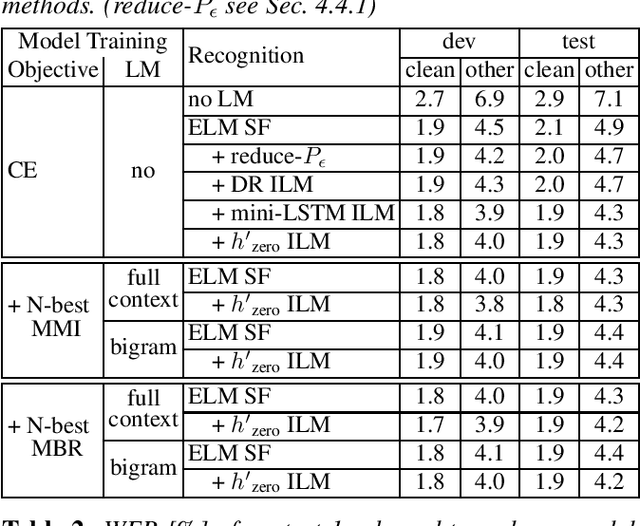
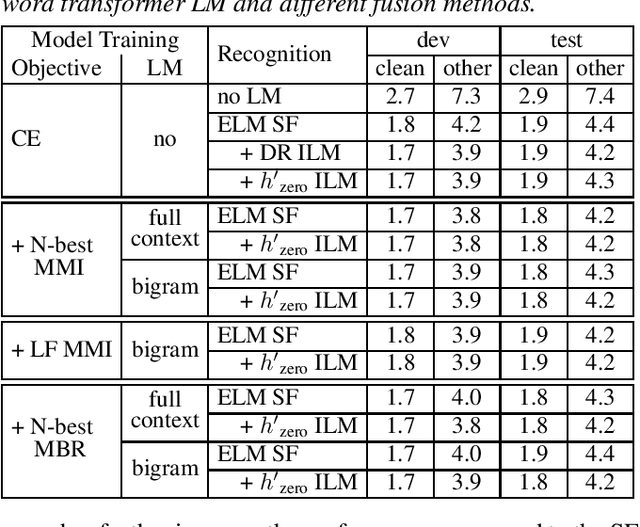
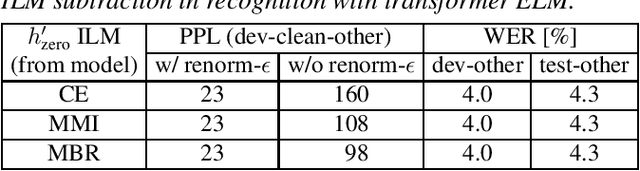
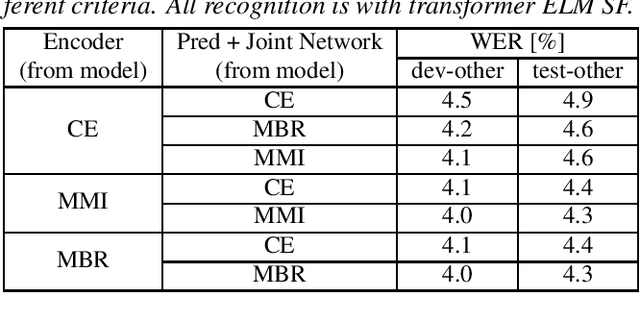
Internal language model (ILM) subtraction has been widely applied to improve the performance of the RNN-Transducer with external language model (LM) fusion for speech recognition. In this work, we show that sequence discriminative training has a strong correlation with ILM subtraction from both theoretical and empirical points of view. Theoretically, we derive that the global optimum of maximum mutual information (MMI) training shares a similar formula as ILM subtraction. Empirically, we show that ILM subtraction and sequence discriminative training achieve similar performance across a wide range of experiments on Librispeech, including both MMI and minimum Bayes risk (MBR) criteria, as well as neural transducers and LMs of both full and limited context. The benefit of ILM subtraction also becomes much smaller after sequence discriminative training. We also provide an in-depth study to show that sequence discriminative training has a minimal effect on the commonly used zero-encoder ILM estimation, but a joint effect on both encoder and prediction + joint network for posterior probability reshaping including both ILM and blank suppression.
INTapt: Information-Theoretic Adversarial Prompt Tuning for Enhanced Non-Native Speech Recognition
May 25, 2023
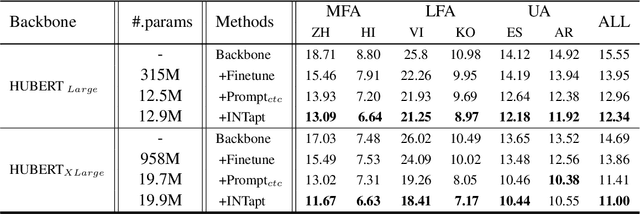
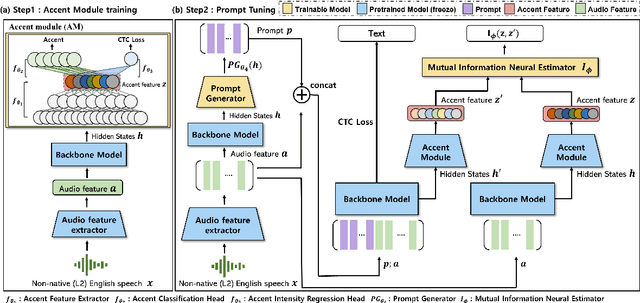
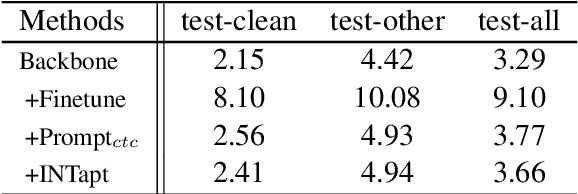
Automatic Speech Recognition (ASR) systems have attained unprecedented performance with large speech models pre-trained based on self-supervised speech representation learning. However, these pre-trained speech models suffer from representational bias as they tend to better represent those prominent accents (i.e., native (L1) English accent) in the pre-training speech corpus than less represented accents, resulting in a deteriorated performance for non-native (L2) English accents. Although there have been some approaches to mitigate this issue, all of these methods require updating the pre-trained model weights. In this paper, we propose Information Theoretic Adversarial Prompt Tuning (INTapt), which introduces prompts concatenated to the original input that can re-modulate the attention of the pre-trained model such that the corresponding input resembles a native (L1) English speech without updating the backbone weights. INTapt is trained simultaneously in the following two manners: (1) adversarial training to reduce accent feature dependence between the original input and the prompt-concatenated input and (2) training to minimize CTC loss for improving ASR performance to a prompt-concatenated input. Experimental results show that INTapt improves the performance of L2 English and increases feature similarity between L2 and L1 accents.
HowToCaption: Prompting LLMs to Transform Video Annotations at Scale
Oct 07, 2023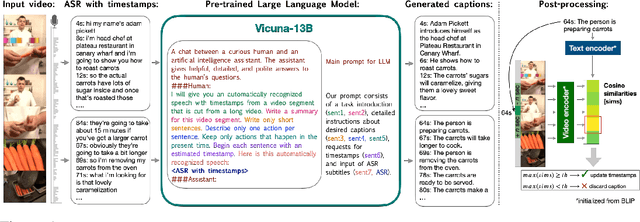
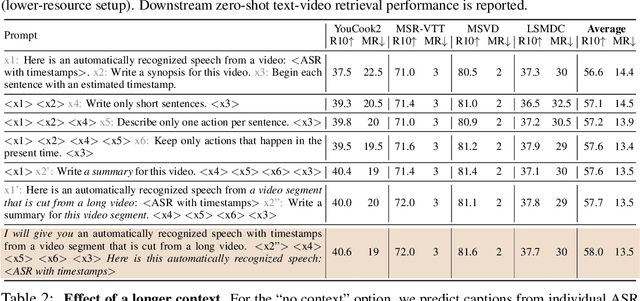


Instructional videos are an excellent source for learning multimodal representations by leveraging video-subtitle pairs extracted with automatic speech recognition systems (ASR) from the audio signal in the videos. However, in contrast to human-annotated captions, both speech and subtitles naturally differ from the visual content of the videos and thus provide only noisy supervision for multimodal learning. As a result, large-scale annotation-free web video training data remains sub-optimal for training text-video models. In this work, we propose to leverage the capability of large language models (LLMs) to obtain fine-grained video descriptions aligned with videos. Specifically, we prompt an LLM to create plausible video descriptions based on ASR narrations of the video for a large-scale instructional video dataset. To this end, we introduce a prompting method that is able to take into account a longer text of subtitles, allowing us to capture context beyond a single sentence. To align the captions to the video temporally, we prompt the LLM to generate timestamps for each produced caption based on the subtitles. In this way, we obtain human-style video captions at scale without human supervision. We apply our method to the subtitles of the HowTo100M dataset, creating a new large-scale dataset, HowToCaption. Our evaluation shows that the resulting captions not only significantly improve the performance over many different benchmark datasets for text-video retrieval but also lead to a disentangling of textual narration from the audio, boosting performance in text-video-audio tasks.
The Broad Impact of Feature Imitation: Neural Enhancements Across Financial, Speech, and Physiological Domains
Sep 21, 2023Initialization of neural network weights plays a pivotal role in determining their performance. Feature Imitating Networks (FINs) offer a novel strategy by initializing weights to approximate specific closed-form statistical features, setting a promising foundation for deep learning architectures. While the applicability of FINs has been chiefly tested in biomedical domains, this study extends its exploration into other time series datasets. Three different experiments are conducted in this study to test the applicability of imitating Tsallis entropy for performance enhancement: Bitcoin price prediction, speech emotion recognition, and chronic neck pain detection. For the Bitcoin price prediction, models embedded with FINs reduced the root mean square error by around 1000 compared to the baseline. In the speech emotion recognition task, the FIN-augmented model increased classification accuracy by over 3 percent. Lastly, in the CNP detection experiment, an improvement of about 7 percent was observed compared to established classifiers. These findings validate the broad utility and potency of FINs in diverse applications.
Variational Connectionist Temporal Classification for Order-Preserving Sequence Modeling
Sep 21, 2023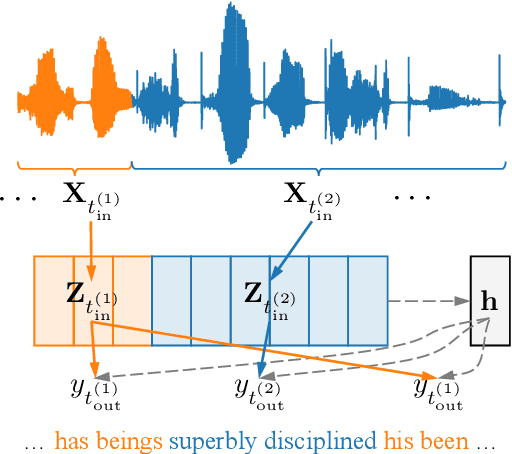
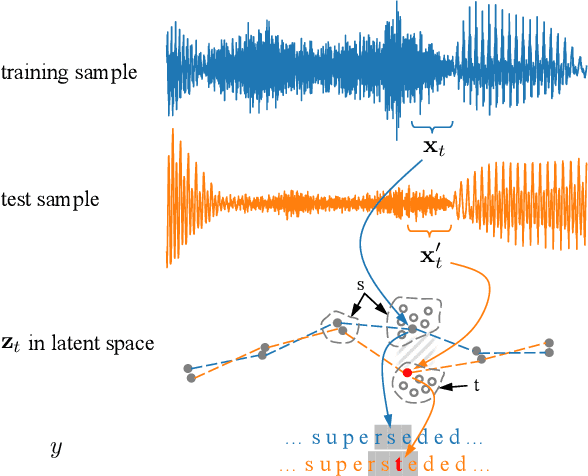
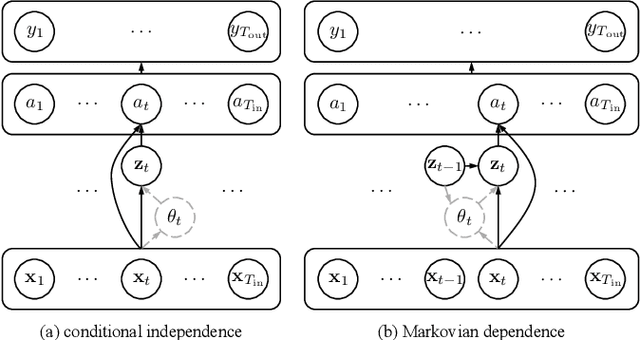
Connectionist temporal classification (CTC) is commonly adopted for sequence modeling tasks like speech recognition, where it is necessary to preserve order between the input and target sequences. However, CTC is only applied to deterministic sequence models, where the latent space is discontinuous and sparse, which in turn makes them less capable of handling data variability when compared to variational models. In this paper, we integrate CTC with a variational model and derive loss functions that can be used to train more generalizable sequence models that preserve order. Specifically, we derive two versions of the novel variational CTC based on two reasonable assumptions, the first being that the variational latent variables at each time step are conditionally independent; and the second being that these latent variables are Markovian. We show that both loss functions allow direct optimization of the variational lower bound for the model log-likelihood, and present computationally tractable forms for implementing them.
Bit Cipher -- A Simple yet Powerful Word Representation System that Integrates Efficiently with Language Models
Nov 18, 2023While Large Language Models (LLMs) become ever more dominant, classic pre-trained word embeddings sustain their relevance through computational efficiency and nuanced linguistic interpretation. Drawing from recent studies demonstrating that the convergence of GloVe and word2vec optimizations all tend towards log-co-occurrence matrix variants, we construct a novel word representation system called Bit-cipher that eliminates the need of backpropagation while leveraging contextual information and hyper-efficient dimensionality reduction techniques based on unigram frequency, providing strong interpretability, alongside efficiency. We use the bit-cipher algorithm to train word vectors via a two-step process that critically relies on a hyperparameter -- bits -- that controls the vector dimension. While the first step trains the bit-cipher, the second utilizes it under two different aggregation modes -- summation or concatenation -- to produce contextually rich representations from word co-occurrences. We extend our investigation into bit-cipher's efficacy, performing probing experiments on part-of-speech (POS) tagging and named entity recognition (NER) to assess its competitiveness with classic embeddings like word2vec and GloVe. Additionally, we explore its applicability in LM training and fine-tuning. By replacing embedding layers with cipher embeddings, our experiments illustrate the notable efficiency of cipher in accelerating the training process and attaining better optima compared to conventional training paradigms. Experiments on the integration of bit-cipher embedding layers with Roberta, T5, and OPT, prior to or as a substitute for fine-tuning, showcase a promising enhancement to transfer learning, allowing rapid model convergence while preserving competitive performance.
Exploring Speech Enhancement for Low-resource Speech Synthesis
Sep 19, 2023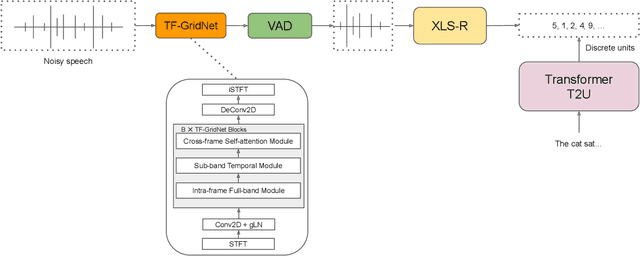

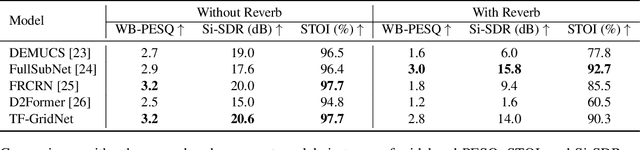
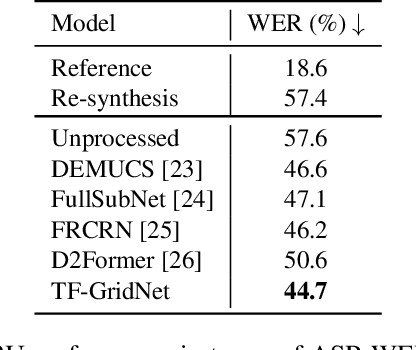
High-quality and intelligible speech is essential to text-to-speech (TTS) model training, however, obtaining high-quality data for low-resource languages is challenging and expensive. Applying speech enhancement on Automatic Speech Recognition (ASR) corpus mitigates the issue by augmenting the training data, while how the nonlinear speech distortion brought by speech enhancement models affects TTS training still needs to be investigated. In this paper, we train a TF-GridNet speech enhancement model and apply it to low-resource datasets that were collected for the ASR task, then train a discrete unit based TTS model on the enhanced speech. We use Arabic datasets as an example and show that the proposed pipeline significantly improves the low-resource TTS system compared with other baseline methods in terms of ASR WER metric. We also run empirical analysis on the correlation between speech enhancement and TTS performances.
Vesper: A Compact and Effective Pretrained Model for Speech Emotion Recognition
Jul 20, 2023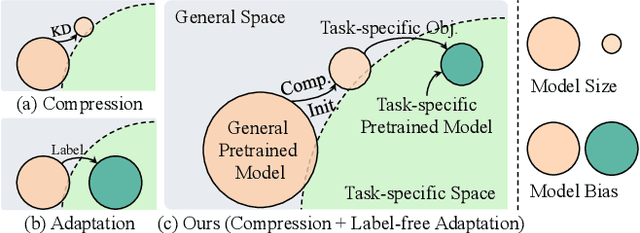
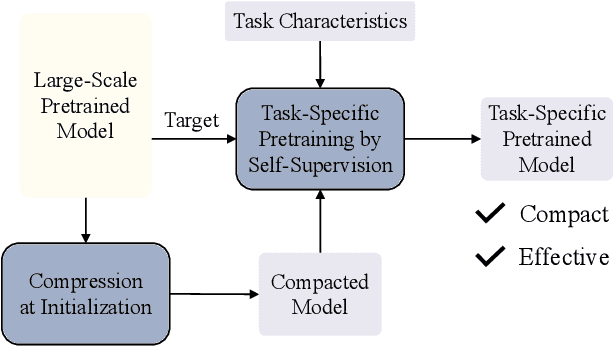
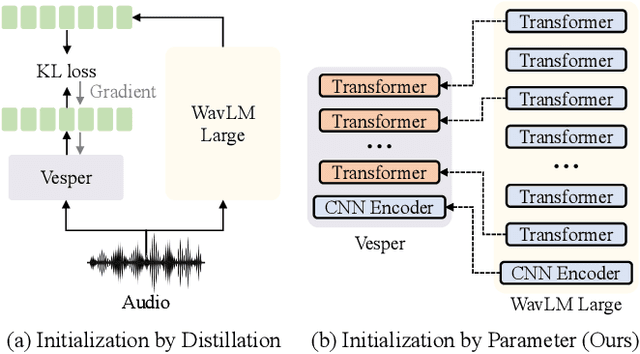
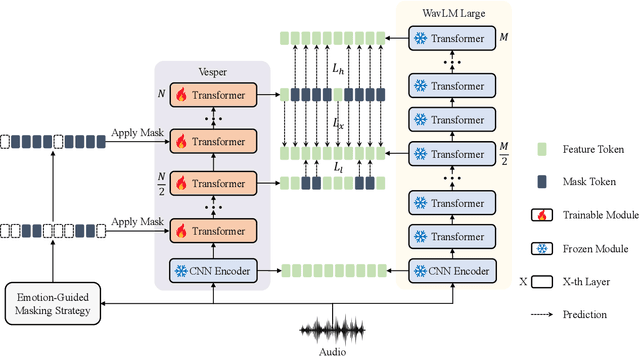
This paper presents a paradigm that adapts general large-scale pretrained models (PTMs) to speech emotion recognition task. Although PTMs shed new light on artificial general intelligence, they are constructed with general tasks in mind, and thus, their efficacy for specific tasks can be further improved. Additionally, employing PTMs in practical applications can be challenging due to their considerable size. Above limitations spawn another research direction, namely, optimizing large-scale PTMs for specific tasks to generate task-specific PTMs that are both compact and effective. In this paper, we focus on the speech emotion recognition task and propose an improved emotion-specific pretrained encoder called Vesper. Vesper is pretrained on a speech dataset based on WavLM and takes into account emotional characteristics. To enhance sensitivity to emotional information, Vesper employs an emotion-guided masking strategy to identify the regions that need masking. Subsequently, Vesper employs hierarchical and cross-layer self-supervision to improve its ability to capture acoustic and semantic representations, both of which are crucial for emotion recognition. Experimental results on the IEMOCAP, MELD, and CREMA-D datasets demonstrate that Vesper with 4 layers outperforms WavLM Base with 12 layers, and the performance of Vesper with 12 layers surpasses that of WavLM Large with 24 layers.
RTFS-Net: Recurrent time-frequency modelling for efficient audio-visual speech separation
Sep 29, 2023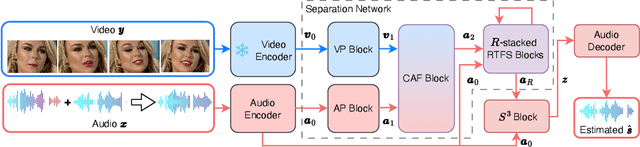
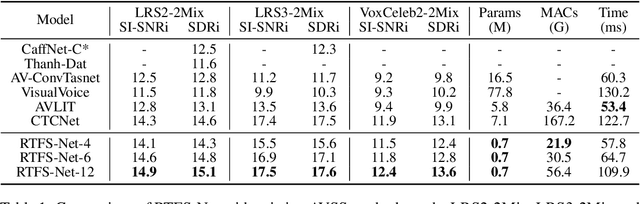
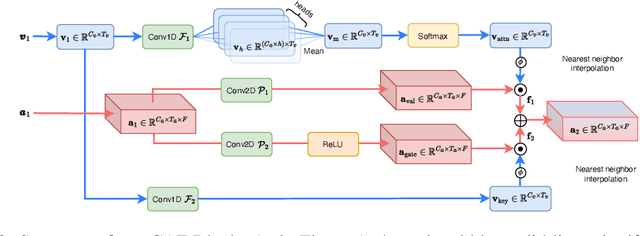

Audio-visual speech separation methods aim to integrate different modalities to generate high-quality separated speech, thereby enhancing the performance of downstream tasks such as speech recognition. Most existing state-of-the-art (SOTA) models operate in the time domain. However, their overly simplistic approach to modeling acoustic features often necessitates larger and more computationally intensive models in order to achieve SOTA performance. In this paper, we present a novel time-frequency domain audio-visual speech separation method: Recurrent Time-Frequency Separation Network (RTFS-Net), which applies its algorithms on the complex time-frequency bins yielded by the Short-Time Fourier Transform. We model and capture the time and frequency dimensions of the audio independently using a multi-layered RNN along each dimension. Furthermore, we introduce a unique attention-based fusion technique for the efficient integration of audio and visual information, and a new mask separation approach that takes advantage of the intrinsic spectral nature of the acoustic features for a clearer separation. RTFS-Net outperforms the previous SOTA method using only 10% of the parameters and 18% of the MACs. This is the first time-frequency domain audio-visual speech separation method to outperform all contemporary time-domain counterparts.