 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Importance of Smoothness Induced by Optimizers in FL4ASR: Towards Understanding Federated Learning for End-to-End ASR
Sep 22, 2023
In this paper, we start by training End-to-End Automatic Speech Recognition (ASR) models using Federated Learning (FL) and examining the fundamental considerations that can be pivotal in minimizing the performance gap in terms of word error rate between models trained using FL versus their centralized counterpart. Specifically, we study the effect of (i) adaptive optimizers, (ii) loss characteristics via altering Connectionist Temporal Classification (CTC) weight, (iii) model initialization through seed start, (iv) carrying over modeling setup from experiences in centralized training to FL, e.g., pre-layer or post-layer normalization, and (v) FL-specific hyperparameters, such as number of local epochs, client sampling size, and learning rate scheduler, specifically for ASR under heterogeneous data distribution. We shed light on how some optimizers work better than others via inducing smoothness. We also summarize the applicability of algorithms, trends, and propose best practices from prior works in FL (in general) toward End-to-End ASR models.
A Comparative Study on E-Branchformer vs Conformer in Speech Recognition, Translation, and Understanding Tasks
May 18, 2023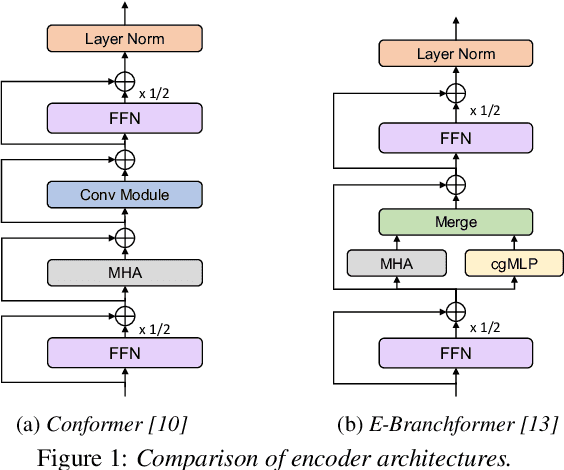
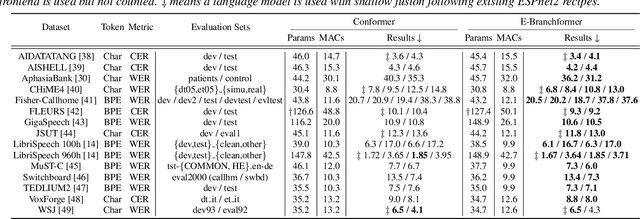
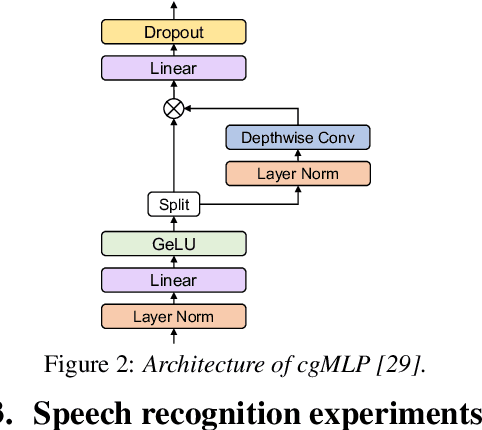
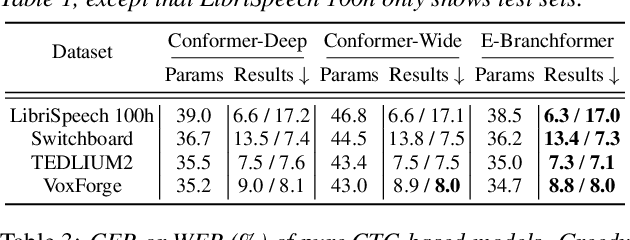
Conformer, a convolution-augmented Transformer variant, has become the de facto encoder architecture for speech processing due to its superior performance in various tasks, including automatic speech recognition (ASR), speech translation (ST) and spoken language understanding (SLU). Recently, a new encoder called E-Branchformer has outperformed Conformer in the LibriSpeech ASR benchmark, making it promising for more general speech applications. This work compares E-Branchformer and Conformer through extensive experiments using different types of end-to-end sequence-to-sequence models. Results demonstrate that E-Branchformer achieves comparable or better performance than Conformer in almost all evaluation sets across 15 ASR, 2 ST, and 3 SLU benchmarks, while being more stable during training. We will release our training configurations and pre-trained models for reproducibility, which can benefit the speech community.
On the Relation between Internal Language Model and Sequence Discriminative Training for Neural Transducers
Sep 25, 2023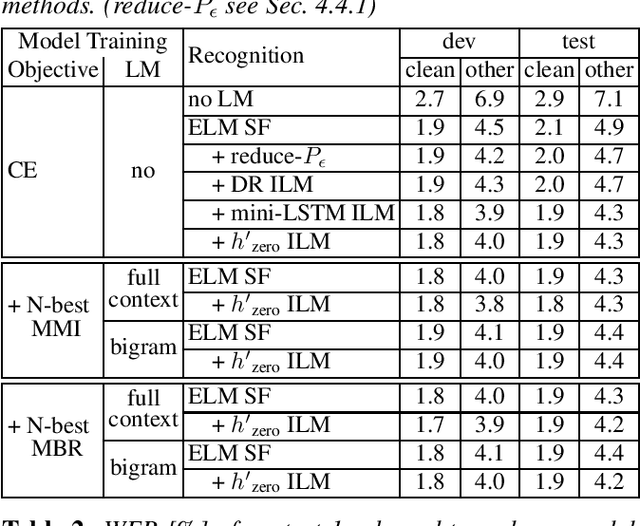
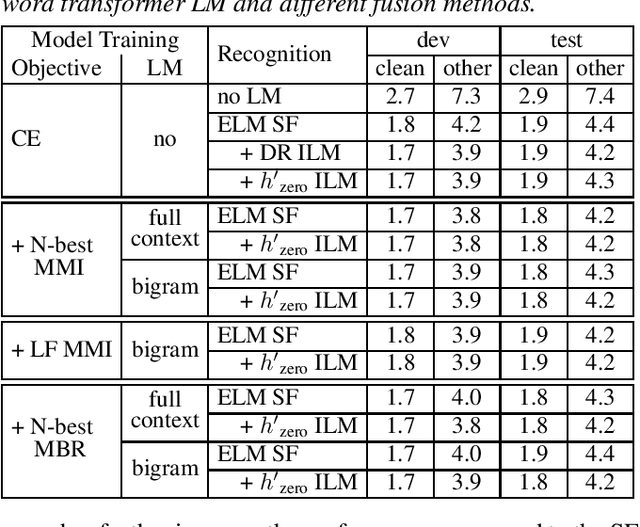
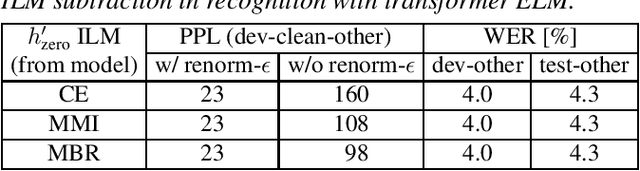
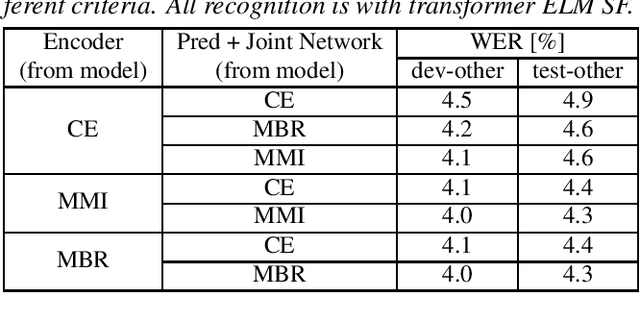
Internal language model (ILM) subtraction has been widely applied to improve the performance of the RNN-Transducer with external language model (LM) fusion for speech recognition. In this work, we show that sequence discriminative training has a strong correlation with ILM subtraction from both theoretical and empirical points of view. Theoretically, we derive that the global optimum of maximum mutual information (MMI) training shares a similar formula as ILM subtraction. Empirically, we show that ILM subtraction and sequence discriminative training achieve similar performance across a wide range of experiments on Librispeech, including both MMI and minimum Bayes risk (MBR) criteria, as well as neural transducers and LMs of both full and limited context. The benefit of ILM subtraction also becomes much smaller after sequence discriminative training. We also provide an in-depth study to show that sequence discriminative training has a minimal effect on the commonly used zero-encoder ILM estimation, but a joint effect on both encoder and prediction + joint network for posterior probability reshaping including both ILM and blank suppression.
HowToCaption: Prompting LLMs to Transform Video Annotations at Scale
Oct 07, 2023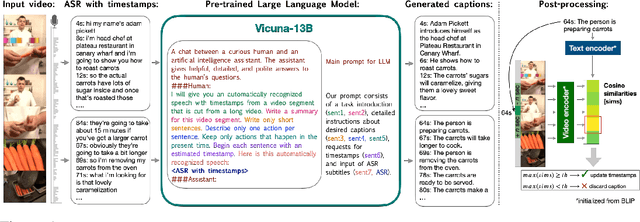
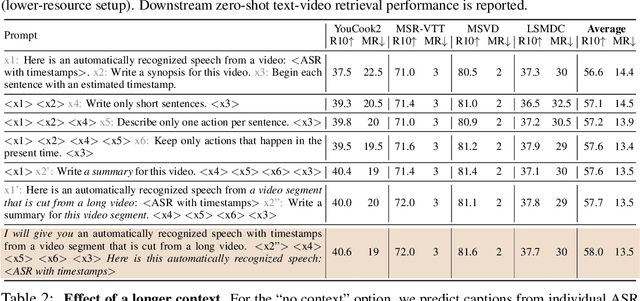


Instructional videos are an excellent source for learning multimodal representations by leveraging video-subtitle pairs extracted with automatic speech recognition systems (ASR) from the audio signal in the videos. However, in contrast to human-annotated captions, both speech and subtitles naturally differ from the visual content of the videos and thus provide only noisy supervision for multimodal learning. As a result, large-scale annotation-free web video training data remains sub-optimal for training text-video models. In this work, we propose to leverage the capability of large language models (LLMs) to obtain fine-grained video descriptions aligned with videos. Specifically, we prompt an LLM to create plausible video descriptions based on ASR narrations of the video for a large-scale instructional video dataset. To this end, we introduce a prompting method that is able to take into account a longer text of subtitles, allowing us to capture context beyond a single sentence. To align the captions to the video temporally, we prompt the LLM to generate timestamps for each produced caption based on the subtitles. In this way, we obtain human-style video captions at scale without human supervision. We apply our method to the subtitles of the HowTo100M dataset, creating a new large-scale dataset, HowToCaption. Our evaluation shows that the resulting captions not only significantly improve the performance over many different benchmark datasets for text-video retrieval but also lead to a disentangling of textual narration from the audio, boosting performance in text-video-audio tasks.
NoRefER: a Referenceless Quality Metric for Automatic Speech Recognition via Semi-Supervised Language Model Fine-Tuning with Contrastive Learning
Jun 21, 2023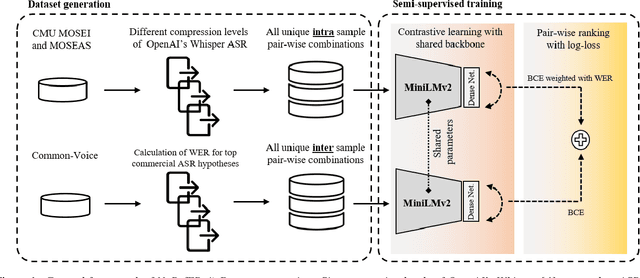
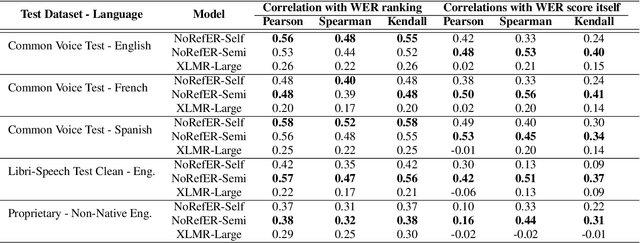
This paper introduces NoRefER, a novel referenceless quality metric for automatic speech recognition (ASR) systems. Traditional reference-based metrics for evaluating ASR systems require costly ground-truth transcripts. NoRefER overcomes this limitation by fine-tuning a multilingual language model for pair-wise ranking ASR hypotheses using contrastive learning with Siamese network architecture. The self-supervised NoRefER exploits the known quality relationships between hypotheses from multiple compression levels of an ASR for learning to rank intra-sample hypotheses by quality, which is essential for model comparisons. The semi-supervised version also uses a referenced dataset to improve its inter-sample quality ranking, which is crucial for selecting potentially erroneous samples. The results indicate that NoRefER correlates highly with reference-based metrics and their intra-sample ranks, indicating a high potential for referenceless ASR evaluation or a/b testing.
Exploring the Integration of Speech Separation and Recognition with Self-Supervised Learning Representation
Jul 23, 2023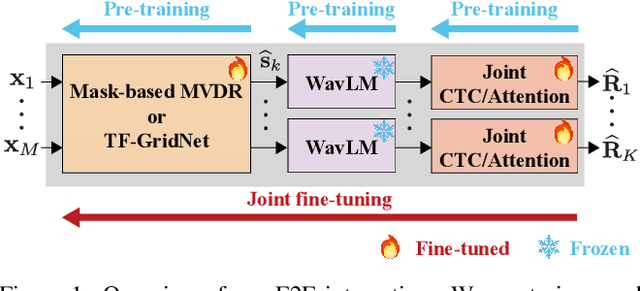
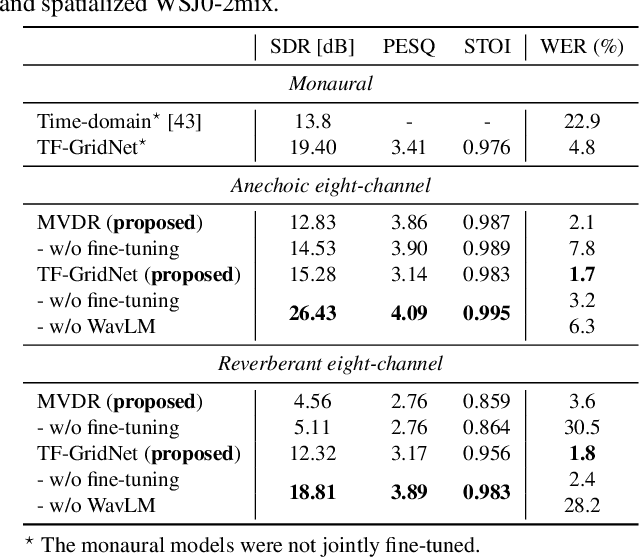
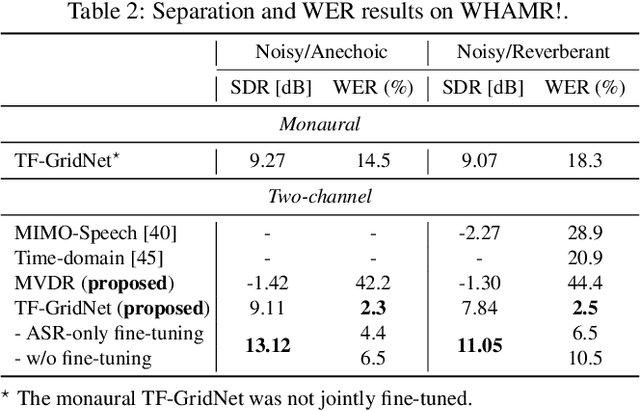
Neural speech separation has made remarkable progress and its integration with automatic speech recognition (ASR) is an important direction towards realizing multi-speaker ASR. This work provides an insightful investigation of speech separation in reverberant and noisy-reverberant scenarios as an ASR front-end. In detail, we explore multi-channel separation methods, mask-based beamforming and complex spectral mapping, as well as the best features to use in the ASR back-end model. We employ the recent self-supervised learning representation (SSLR) as a feature and improve the recognition performance from the case with filterbank features. To further improve multi-speaker recognition performance, we present a carefully designed training strategy for integrating speech separation and recognition with SSLR. The proposed integration using TF-GridNet-based complex spectral mapping and WavLM-based SSLR achieves a 2.5% word error rate in reverberant WHAMR! test set, significantly outperforming an existing mask-based MVDR beamforming and filterbank integration (28.9%).
The Broad Impact of Feature Imitation: Neural Enhancements Across Financial, Speech, and Physiological Domains
Sep 21, 2023Initialization of neural network weights plays a pivotal role in determining their performance. Feature Imitating Networks (FINs) offer a novel strategy by initializing weights to approximate specific closed-form statistical features, setting a promising foundation for deep learning architectures. While the applicability of FINs has been chiefly tested in biomedical domains, this study extends its exploration into other time series datasets. Three different experiments are conducted in this study to test the applicability of imitating Tsallis entropy for performance enhancement: Bitcoin price prediction, speech emotion recognition, and chronic neck pain detection. For the Bitcoin price prediction, models embedded with FINs reduced the root mean square error by around 1000 compared to the baseline. In the speech emotion recognition task, the FIN-augmented model increased classification accuracy by over 3 percent. Lastly, in the CNP detection experiment, an improvement of about 7 percent was observed compared to established classifiers. These findings validate the broad utility and potency of FINs in diverse applications.
Variational Connectionist Temporal Classification for Order-Preserving Sequence Modeling
Sep 21, 2023
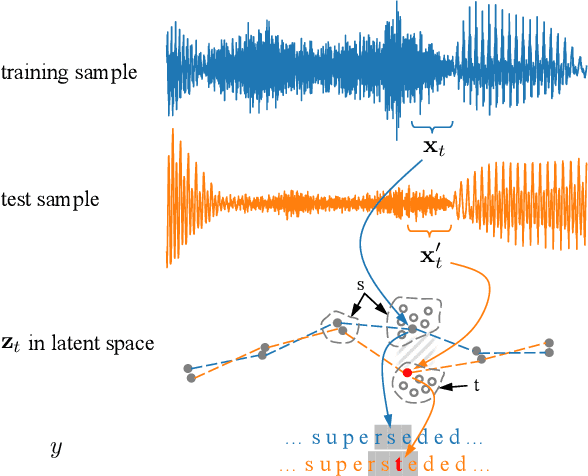
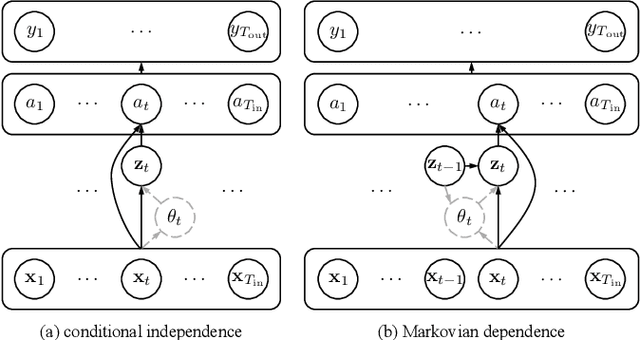
Connectionist temporal classification (CTC) is commonly adopted for sequence modeling tasks like speech recognition, where it is necessary to preserve order between the input and target sequences. However, CTC is only applied to deterministic sequence models, where the latent space is discontinuous and sparse, which in turn makes them less capable of handling data variability when compared to variational models. In this paper, we integrate CTC with a variational model and derive loss functions that can be used to train more generalizable sequence models that preserve order. Specifically, we derive two versions of the novel variational CTC based on two reasonable assumptions, the first being that the variational latent variables at each time step are conditionally independent; and the second being that these latent variables are Markovian. We show that both loss functions allow direct optimization of the variational lower bound for the model log-likelihood, and present computationally tractable forms for implementing them.
Adapting Text-based Dialogue State Tracker for Spoken Dialogues
Aug 30, 2023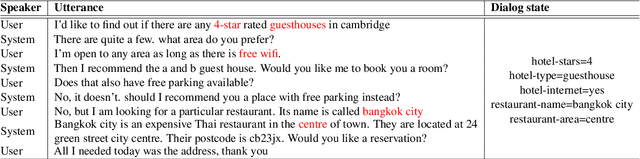
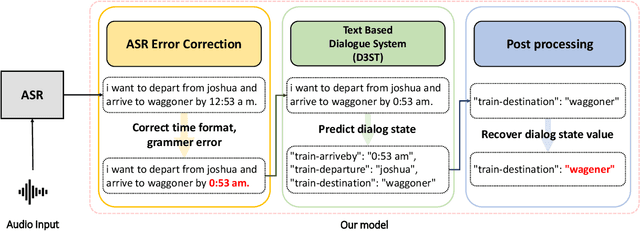
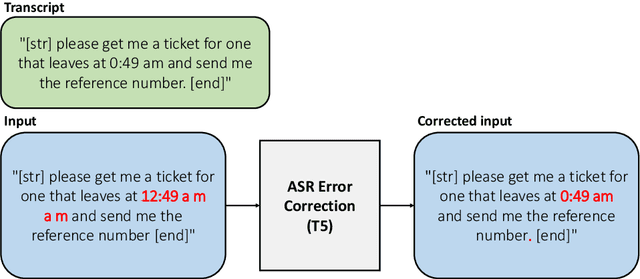

Although there have been remarkable advances in dialogue systems through the dialogue systems technology competition (DSTC), it remains one of the key challenges to building a robust task-oriented dialogue system with a speech interface. Most of the progress has been made for text-based dialogue systems since there are abundant datasets with written corpora while those with spoken dialogues are very scarce. However, as can be seen from voice assistant systems such as Siri and Alexa, it is of practical importance to transfer the success to spoken dialogues. In this paper, we describe our engineering effort in building a highly successful model that participated in the speech-aware dialogue systems technology challenge track in DSTC11. Our model consists of three major modules: (1) automatic speech recognition error correction to bridge the gap between the spoken and the text utterances, (2) text-based dialogue system (D3ST) for estimating the slots and values using slot descriptions, and (3) post-processing for recovering the error of the estimated slot value. Our experiments show that it is important to use an explicit automatic speech recognition error correction module, post-processing, and data augmentation to adapt a text-based dialogue state tracker for spoken dialogue corpora.
Exploring Speech Enhancement for Low-resource Speech Synthesis
Sep 19, 2023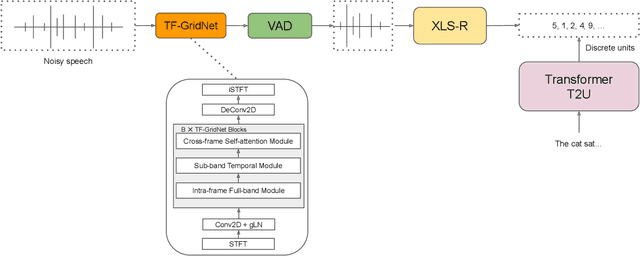

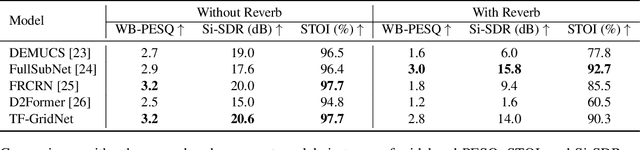
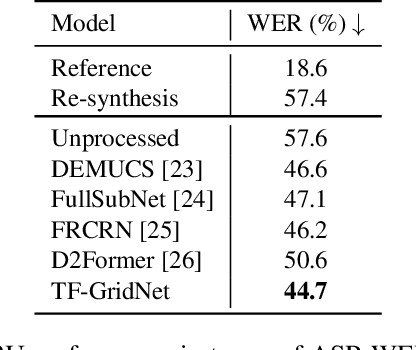
High-quality and intelligible speech is essential to text-to-speech (TTS) model training, however, obtaining high-quality data for low-resource languages is challenging and expensive. Applying speech enhancement on Automatic Speech Recognition (ASR) corpus mitigates the issue by augmenting the training data, while how the nonlinear speech distortion brought by speech enhancement models affects TTS training still needs to be investigated. In this paper, we train a TF-GridNet speech enhancement model and apply it to low-resource datasets that were collected for the ASR task, then train a discrete unit based TTS model on the enhanced speech. We use Arabic datasets as an example and show that the proposed pipeline significantly improves the low-resource TTS system compared with other baseline methods in terms of ASR WER metric. We also run empirical analysis on the correlation between speech enhancement and TTS performances.