 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
An Effective Transformer-based Contextual Model and Temporal Gate Pooling for Speaker Identification
Aug 22, 2023
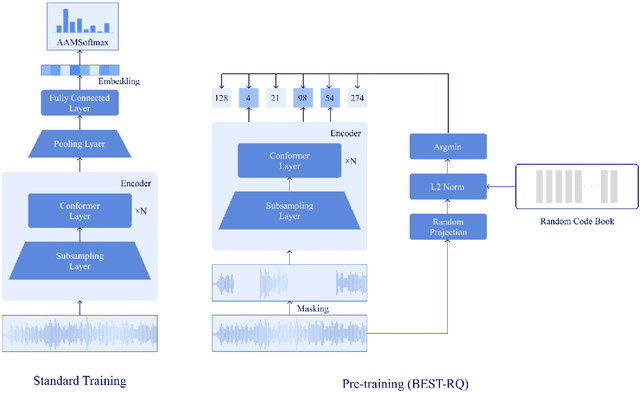
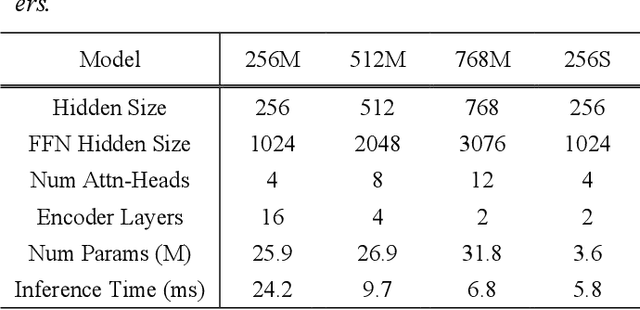
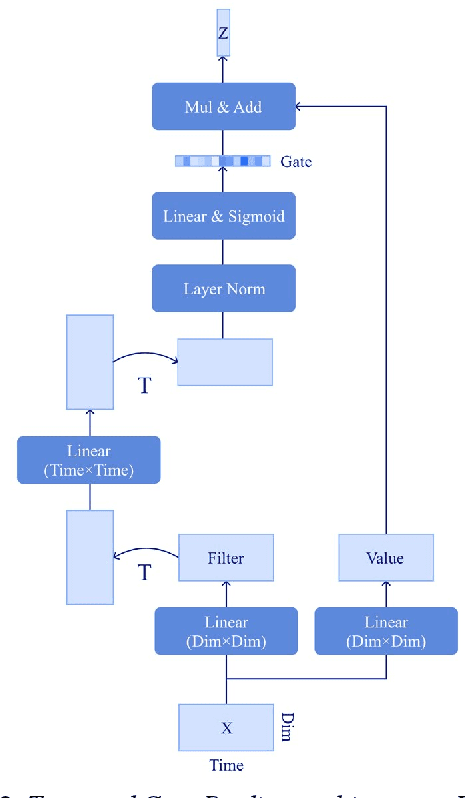
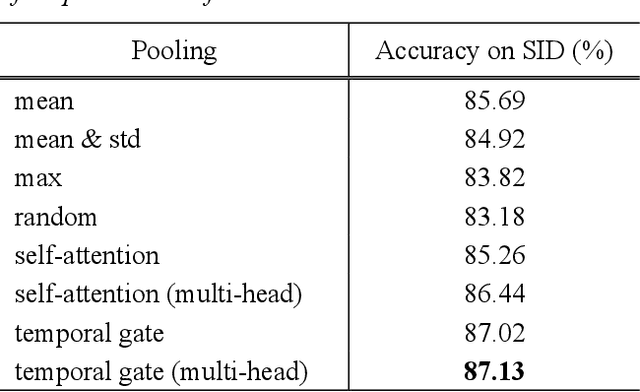
Wav2vec2 has achieved success in applying Transformer architecture and self-supervised learning to speech recognition. Recently, these have come to be used not only for speech recognition but also for the entire speech processing. This paper introduces an effective end-to-end speaker identification model applied Transformer-based contextual model. We explored the relationship between the parameters and the performance in order to discern the structure of an effective model. Furthermore, we propose a pooling method, Temporal Gate Pooling, with powerful learning ability for speaker identification. We applied Conformer as encoder and BEST-RQ for pre-training and conducted an evaluation utilizing the speaker identification of VoxCeleb1. The proposed method has achieved an accuracy of 85.9% with 28.5M parameters, demonstrating comparable precision to wav2vec2 with 317.7M parameters. Code is available at https://github.com/HarunoriKawano/speaker-identification-with-tgp.
BLSP: Bootstrapping Language-Speech Pre-training via Behavior Alignment of Continuation Writing
Sep 02, 2023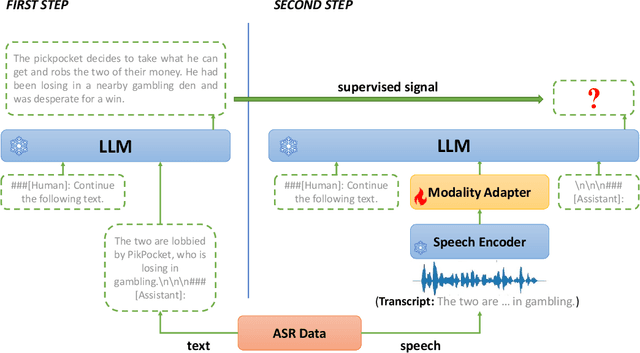


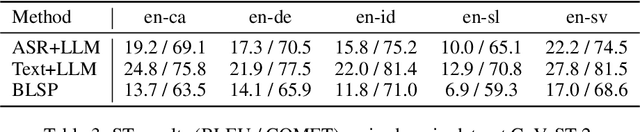
The emergence of large language models (LLMs) has sparked significant interest in extending their remarkable language capabilities to speech. However, modality alignment between speech and text still remains an open problem. Current solutions can be categorized into two strategies. One is a cascaded approach where outputs (tokens or states) of a separately trained speech recognition system are used as inputs for LLMs, which limits their potential in modeling alignment between speech and text. The other is an end-to-end approach that relies on speech instruction data, which is very difficult to collect in large quantities. In this paper, we address these issues and propose the BLSP approach that Bootstraps Language-Speech Pre-training via behavior alignment of continuation writing. We achieve this by learning a lightweight modality adapter between a frozen speech encoder and an LLM, ensuring that the LLM exhibits the same generation behavior regardless of the modality of input: a speech segment or its transcript. The training process can be divided into two steps. The first step prompts an LLM to generate texts with speech transcripts as prefixes, obtaining text continuations. In the second step, these continuations are used as supervised signals to train the modality adapter in an end-to-end manner. We demonstrate that this straightforward process can extend the capabilities of LLMs to speech, enabling speech recognition, speech translation, spoken language understanding, and speech conversation, even in zero-shot cross-lingual scenarios.
Dynamic ASR Pathways: An Adaptive Masking Approach Towards Efficient Pruning of A Multilingual ASR Model
Sep 22, 2023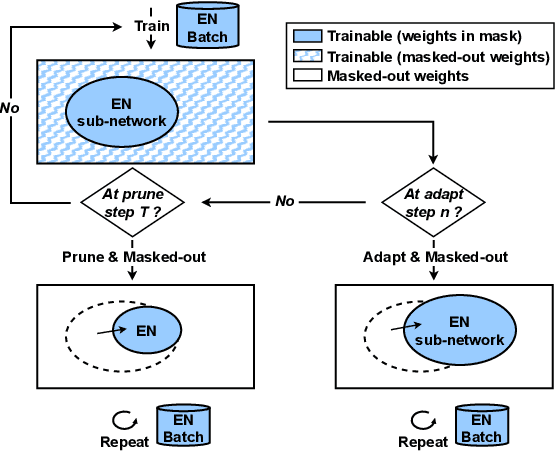
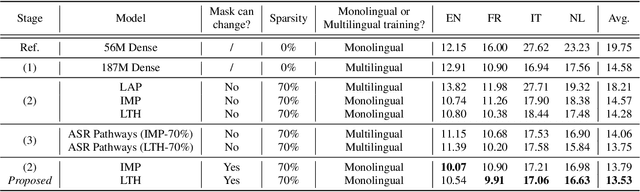
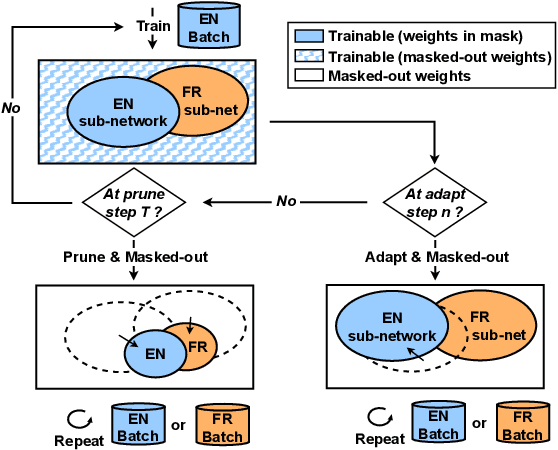
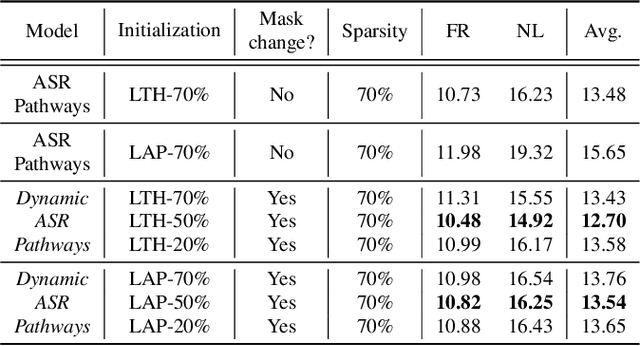
Neural network pruning offers an effective method for compressing a multilingual automatic speech recognition (ASR) model with minimal performance loss. However, it entails several rounds of pruning and re-training needed to be run for each language. In this work, we propose the use of an adaptive masking approach in two scenarios for pruning a multilingual ASR model efficiently, each resulting in sparse monolingual models or a sparse multilingual model (named as Dynamic ASR Pathways). Our approach dynamically adapts the sub-network, avoiding premature decisions about a fixed sub-network structure. We show that our approach outperforms existing pruning methods when targeting sparse monolingual models. Further, we illustrate that Dynamic ASR Pathways jointly discovers and trains better sub-networks (pathways) of a single multilingual model by adapting from different sub-network initializations, thereby reducing the need for language-specific pruning.
Investigating End-to-End ASR Architectures for Long Form Audio Transcription
Sep 20, 2023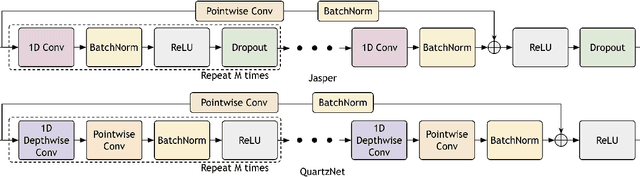
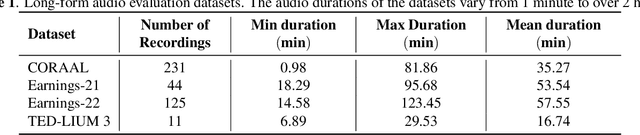


This paper presents an overview and evaluation of some of the end-to-end ASR models on long-form audios. We study three categories of Automatic Speech Recognition(ASR) models based on their core architecture: (1) convolutional, (2) convolutional with squeeze-and-excitation and (3) convolutional models with attention. We selected one ASR model from each category and evaluated Word Error Rate, maximum audio length and real-time factor for each model on a variety of long audio benchmarks: Earnings-21 and 22, CORAAL, and TED-LIUM3. The model from the category of self-attention with local attention and global token has the best accuracy comparing to other architectures. We also compared models with CTC and RNNT decoders and showed that CTC-based models are more robust and efficient than RNNT on long form audio.
SGEM: Test-Time Adaptation for Automatic Speech Recognition via Sequential-Level Generalized Entropy Minimization
Jun 08, 2023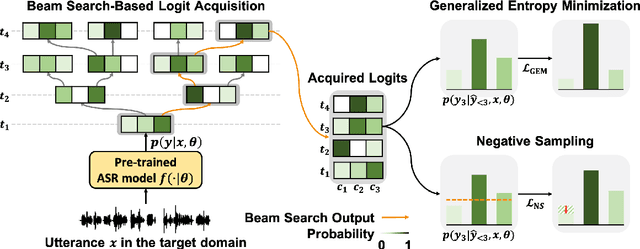
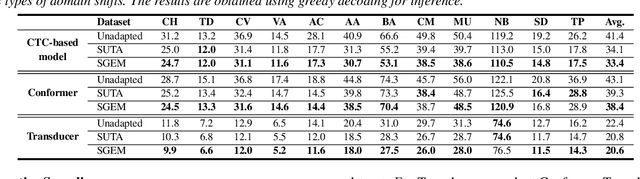

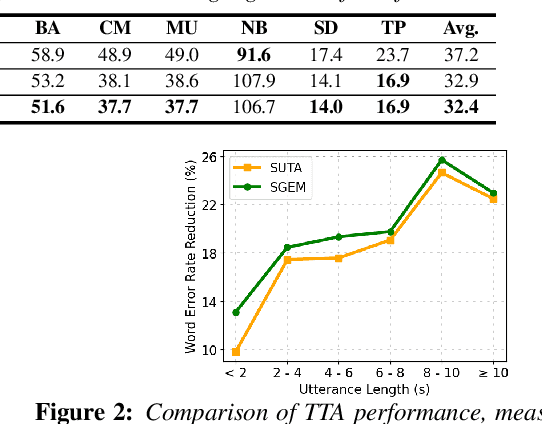
Automatic speech recognition (ASR) models are frequently exposed to data distribution shifts in many real-world scenarios, leading to erroneous predictions. To tackle this issue, an existing test-time adaptation (TTA) method has recently been proposed to adapt the pre-trained ASR model on unlabeled test instances without source data. Despite decent performance gain, this work relies solely on naive greedy decoding and performs adaptation across timesteps at a frame level, which may not be optimal given the sequential nature of the model output. Motivated by this, we propose a novel TTA framework, dubbed SGEM, for general ASR models. To treat the sequential output, SGEM first exploits beam search to explore candidate output logits and selects the most plausible one. Then, it utilizes generalized entropy minimization and negative sampling as unsupervised objectives to adapt the model. SGEM achieves state-of-the-art performance for three mainstream ASR models under various domain shifts.
Weakly-Supervised Speech Pre-training: A Case Study on Target Speech Recognition
May 25, 2023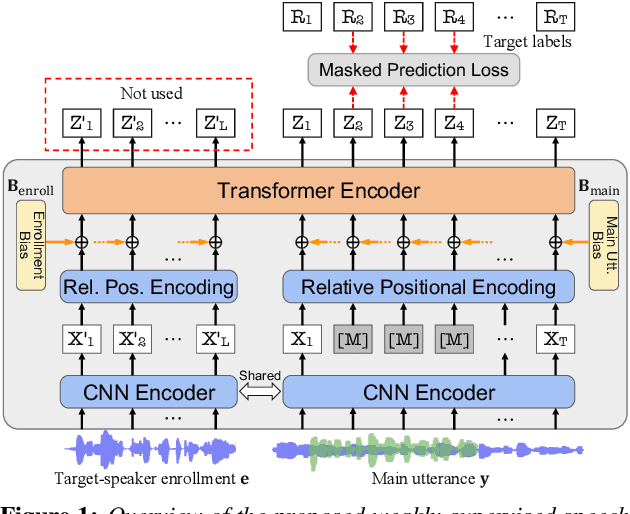
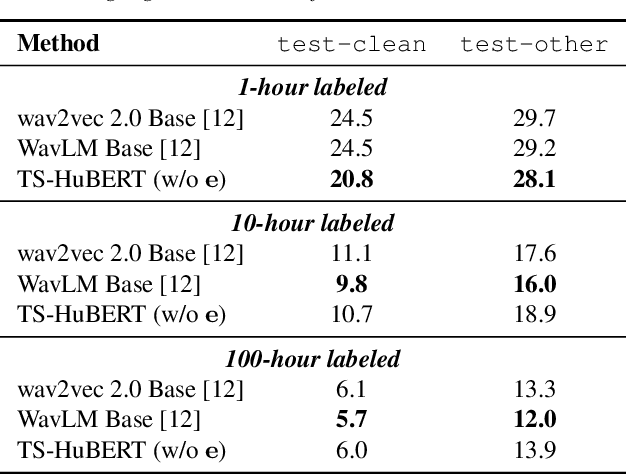
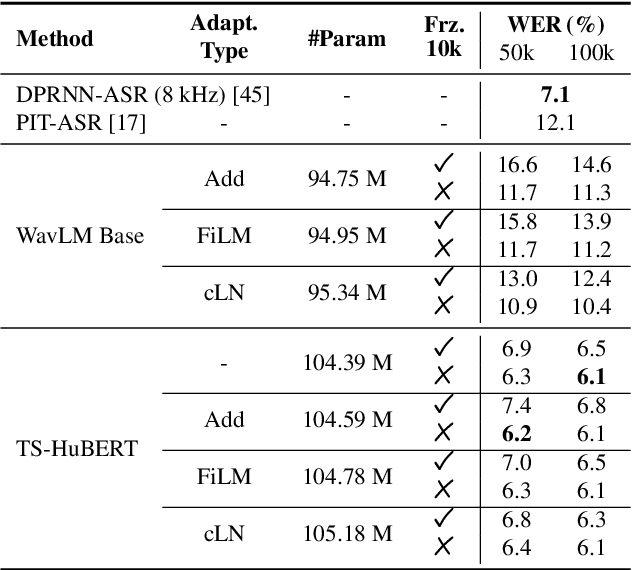
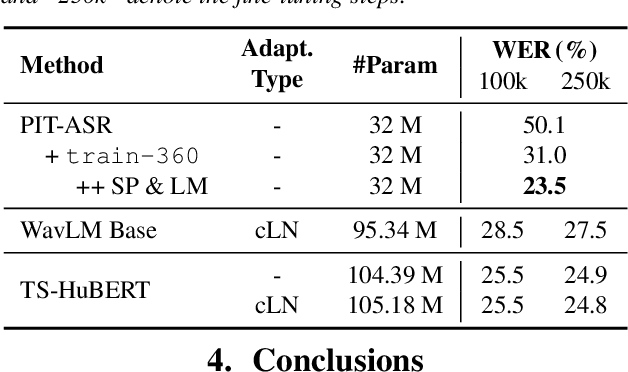
Self-supervised learning (SSL) based speech pre-training has attracted much attention for its capability of extracting rich representations learned from massive unlabeled data. On the other hand, the use of weakly-supervised data is less explored for speech pre-training. To fill this gap, we propose a weakly-supervised speech pre-training method based on speaker-aware speech data. It adopts a similar training procedure to the widely-used masked speech prediction based SSL framework, while incorporating additional target-speaker enrollment information as an auxiliary input. In this way, the learned representation is steered towards the target speaker even in the presence of highly overlapping interference, allowing potential applications to tasks such as target speech recognition. Our experiments on Libri2Mix and WSJ0-2mix datasets show that the proposed model achieves significantly better ASR performance compared to WavLM, the state-of-the-art SSL model with denoising capability.
A Comparative Study on E-Branchformer vs Conformer in Speech Recognition, Translation, and Understanding Tasks
May 18, 2023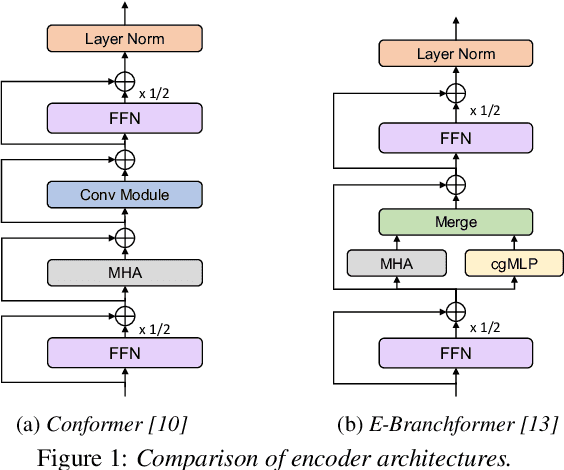
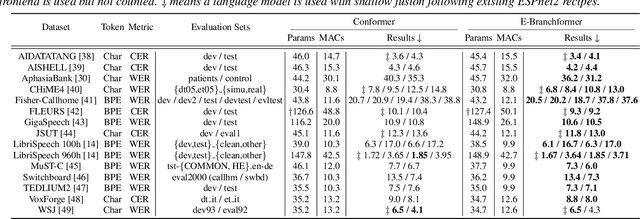
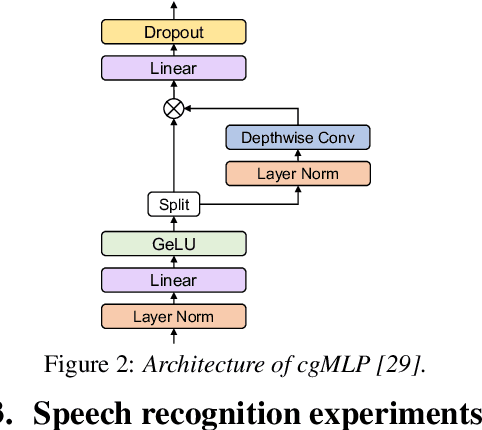
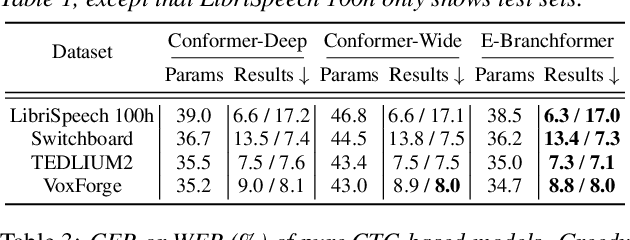
Conformer, a convolution-augmented Transformer variant, has become the de facto encoder architecture for speech processing due to its superior performance in various tasks, including automatic speech recognition (ASR), speech translation (ST) and spoken language understanding (SLU). Recently, a new encoder called E-Branchformer has outperformed Conformer in the LibriSpeech ASR benchmark, making it promising for more general speech applications. This work compares E-Branchformer and Conformer through extensive experiments using different types of end-to-end sequence-to-sequence models. Results demonstrate that E-Branchformer achieves comparable or better performance than Conformer in almost all evaluation sets across 15 ASR, 2 ST, and 3 SLU benchmarks, while being more stable during training. We will release our training configurations and pre-trained models for reproducibility, which can benefit the speech community.
A privacy-preserving method using secret key for convolutional neural network-based speech classification
Oct 06, 2023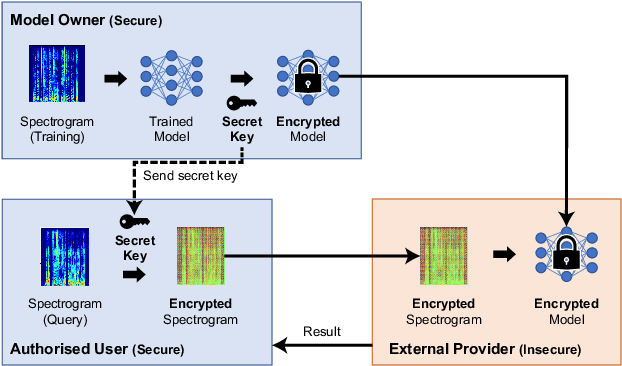
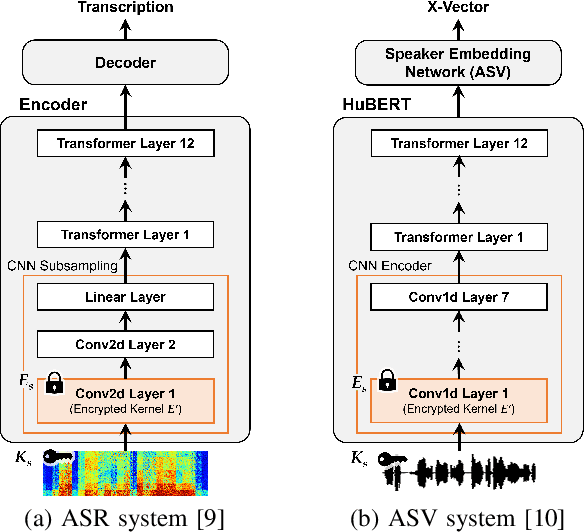
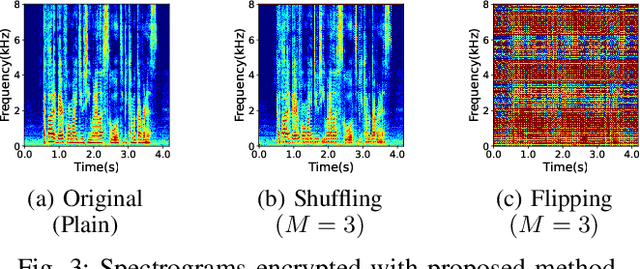
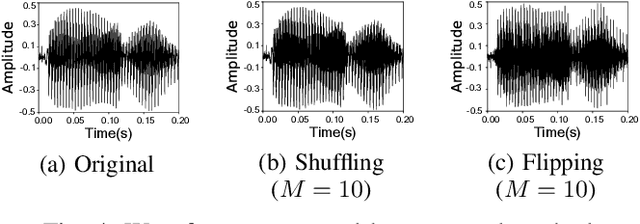
In this paper, we propose a privacy-preserving method with a secret key for convolutional neural network (CNN)-based speech classification tasks. Recently, many methods related to privacy preservation have been developed in image classification research fields. In contrast, in speech classification research fields, little research has considered these risks. To promote research on privacy preservation for speech classification, we provide an encryption method with a secret key in CNN-based speech classification systems. The encryption method is based on a random matrix with an invertible inverse. The encrypted speech data with a correct key can be accepted by a model with an encrypted kernel generated using an inverse matrix of a random matrix. Whereas the encrypted speech data is strongly distorted, the classification tasks can be correctly performed when a correct key is provided. Additionally, in this paper, we evaluate the difficulty of reconstructing the original information from the encrypted spectrograms and waveforms. In our experiments, the proposed encryption methods are performed in automatic speech recognition~(ASR) and automatic speaker verification~(ASV) tasks. The results show that the encrypted data can be used completely the same as the original data when a correct secret key is provided in the transformer-based ASR and x-vector-based ASV with self-supervised front-end systems. The robustness of the encrypted data against reconstruction attacks is also illustrated.
Auto-AVSR: Audio-Visual Speech Recognition with Automatic Labels
Mar 25, 2023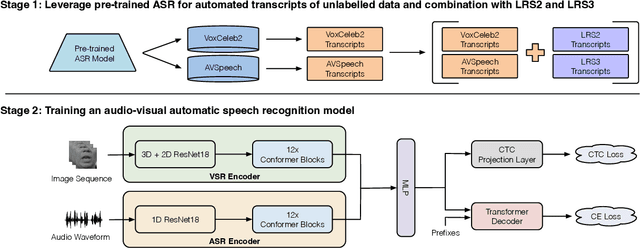
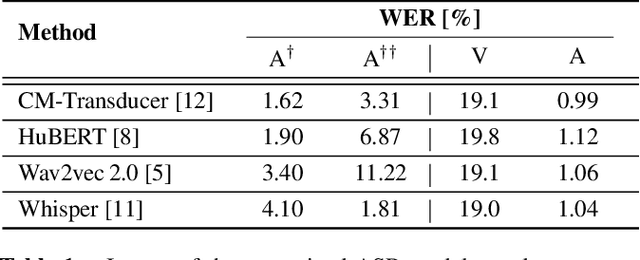
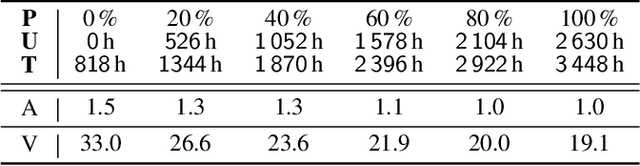
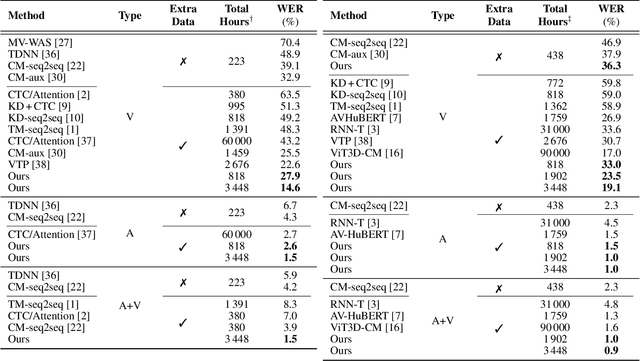
Audio-visual speech recognition has received a lot of attention due to its robustness against acoustic noise. Recently, the performance of automatic, visual, and audio-visual speech recognition (ASR, VSR, and AV-ASR, respectively) has been substantially improved, mainly due to the use of larger models and training sets. However, accurate labelling of datasets is time-consuming and expensive. Hence, in this work, we investigate the use of automatically-generated transcriptions of unlabelled datasets to increase the training set size. For this purpose, we use publicly-available pre-trained ASR models to automatically transcribe unlabelled datasets such as AVSpeech and VoxCeleb2. Then, we train ASR, VSR and AV-ASR models on the augmented training set, which consists of the LRS2 and LRS3 datasets as well as the additional automatically-transcribed data. We demonstrate that increasing the size of the training set, a recent trend in the literature, leads to reduced WER despite using noisy transcriptions. The proposed model achieves new state-of-the-art performance on AV-ASR on LRS2 and LRS3. In particular, it achieves a WER of 0.9% on LRS3, a relative improvement of 30% over the current state-of-the-art approach, and outperforms methods that have been trained on non-publicly available datasets with 26 times more training data.
NoRefER: a Referenceless Quality Metric for Automatic Speech Recognition via Semi-Supervised Language Model Fine-Tuning with Contrastive Learning
Jun 21, 2023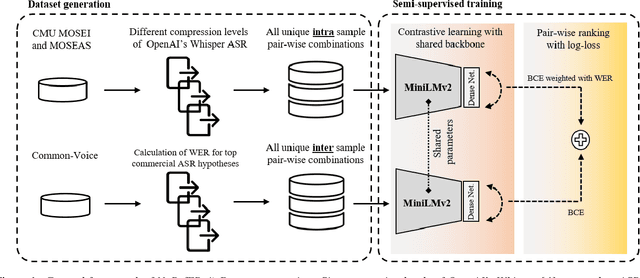
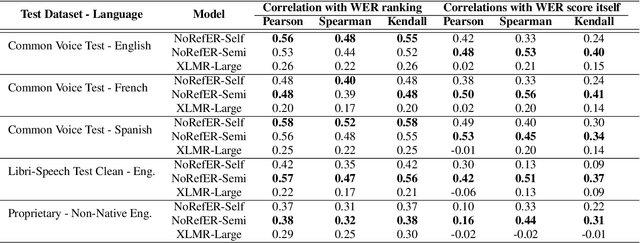
This paper introduces NoRefER, a novel referenceless quality metric for automatic speech recognition (ASR) systems. Traditional reference-based metrics for evaluating ASR systems require costly ground-truth transcripts. NoRefER overcomes this limitation by fine-tuning a multilingual language model for pair-wise ranking ASR hypotheses using contrastive learning with Siamese network architecture. The self-supervised NoRefER exploits the known quality relationships between hypotheses from multiple compression levels of an ASR for learning to rank intra-sample hypotheses by quality, which is essential for model comparisons. The semi-supervised version also uses a referenced dataset to improve its inter-sample quality ranking, which is crucial for selecting potentially erroneous samples. The results indicate that NoRefER correlates highly with reference-based metrics and their intra-sample ranks, indicating a high potential for referenceless ASR evaluation or a/b testing.