 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Evaluating Speech Synthesis by Training Recognizers on Synthetic Speech
Oct 01, 2023
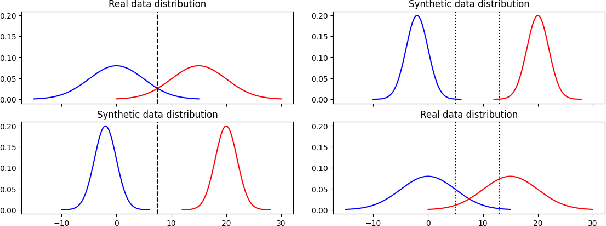
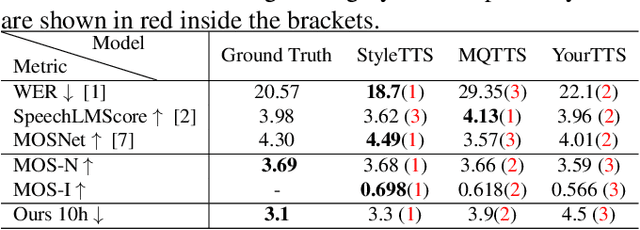
Modern speech synthesis systems have improved significantly, with synthetic speech being indistinguishable from real speech. However, efficient and holistic evaluation of synthetic speech still remains a significant challenge. Human evaluation using Mean Opinion Score (MOS) is ideal, but inefficient due to high costs. Therefore, researchers have developed auxiliary automatic metrics like Word Error Rate (WER) to measure intelligibility. Prior works focus on evaluating synthetic speech based on pre-trained speech recognition models, however, this can be limiting since this approach primarily measures speech intelligibility. In this paper, we propose an evaluation technique involving the training of an ASR model on synthetic speech and assessing its performance on real speech. Our main assumption is that by training the ASR model on the synthetic speech, the WER on real speech reflects the similarity between distributions, a broader assessment of synthetic speech quality beyond intelligibility. Our proposed metric demonstrates a strong correlation with both MOS naturalness and MOS intelligibility when compared to SpeechLMScore and MOSNet on three recent Text-to-Speech (TTS) systems: MQTTS, StyleTTS, and YourTTS.
Some voices are too common: Building fair speech recognition systems using the Common Voice dataset
Jun 01, 2023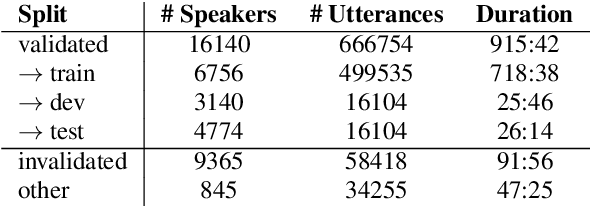
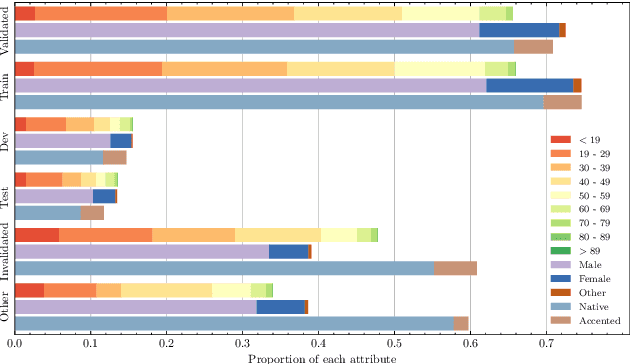
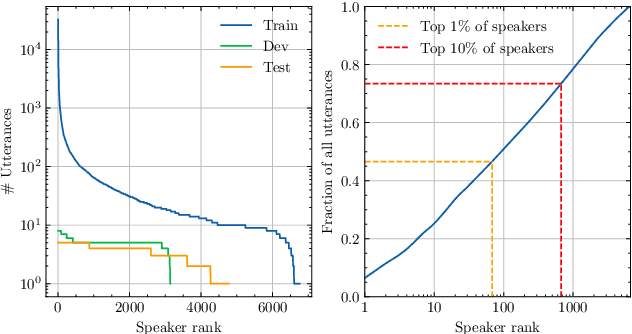
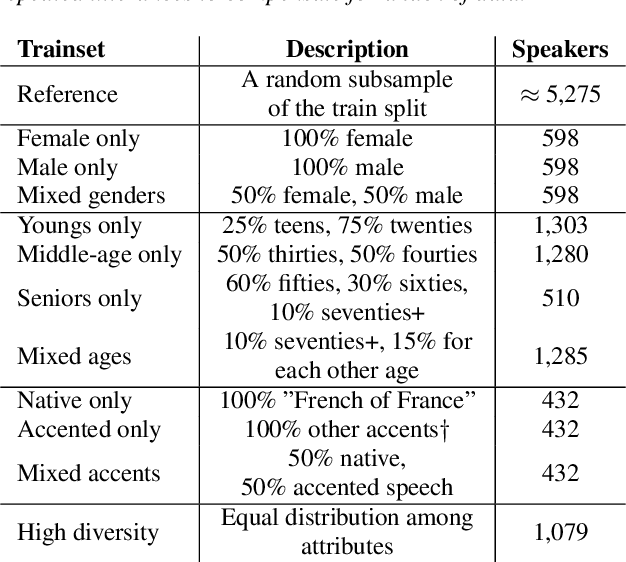
Automatic speech recognition (ASR) systems become increasingly efficient thanks to new advances in neural network training like self-supervised learning. However, they are known to be unfair toward certain groups, for instance, people speaking with an accent. In this work, we use the French Common Voice dataset to quantify the biases of a pre-trained wav2vec~2.0 model toward several demographic groups. By fine-tuning the pre-trained model on a variety of fixed-size, carefully crafted training sets, we demonstrate the importance of speaker diversity. We also run an in-depth analysis of the Common Voice corpus and identify important shortcomings that should be taken into account by users of this dataset.
Human Transcription Quality Improvement
Sep 24, 2023
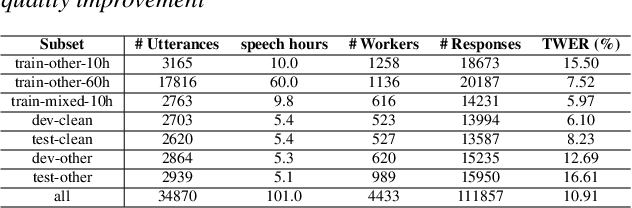
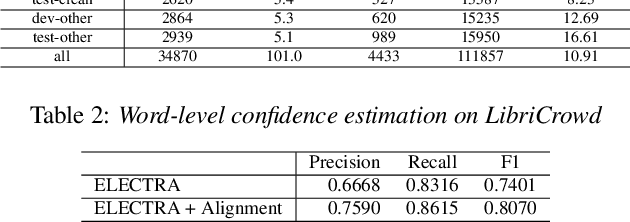
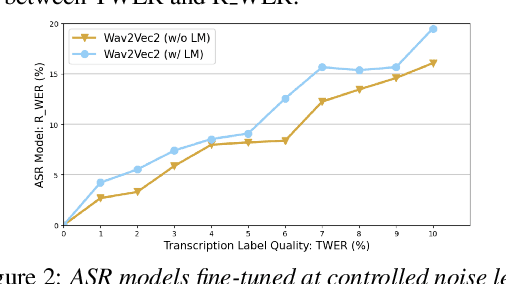
High quality transcription data is crucial for training automatic speech recognition (ASR) systems. However, the existing industry-level data collection pipelines are expensive to researchers, while the quality of crowdsourced transcription is low. In this paper, we propose a reliable method to collect speech transcriptions. We introduce two mechanisms to improve transcription quality: confidence estimation based reprocessing at labeling stage, and automatic word error correction at post-labeling stage. We collect and release LibriCrowd - a large-scale crowdsourced dataset of audio transcriptions on 100 hours of English speech. Experiment shows the Transcription WER is reduced by over 50%. We further investigate the impact of transcription error on ASR model performance and found a strong correlation. The transcription quality improvement provides over 10% relative WER reduction for ASR models. We release the dataset and code to benefit the research community.
* 5 pages, 3 figures, 5 tables, INTERSPEECH 2023
Distilling HuBERT with LSTMs via Decoupled Knowledge Distillation
Sep 18, 2023Much research effort is being applied to the task of compressing the knowledge of self-supervised models, which are powerful, yet large and memory consuming. In this work, we show that the original method of knowledge distillation (and its more recently proposed extension, decoupled knowledge distillation) can be applied to the task of distilling HuBERT. In contrast to methods that focus on distilling internal features, this allows for more freedom in the network architecture of the compressed model. We thus propose to distill HuBERT's Transformer layers into an LSTM-based distilled model that reduces the number of parameters even below DistilHuBERT and at the same time shows improved performance in automatic speech recognition.
Memory-augmented conformer for improved end-to-end long-form ASR
Sep 22, 2023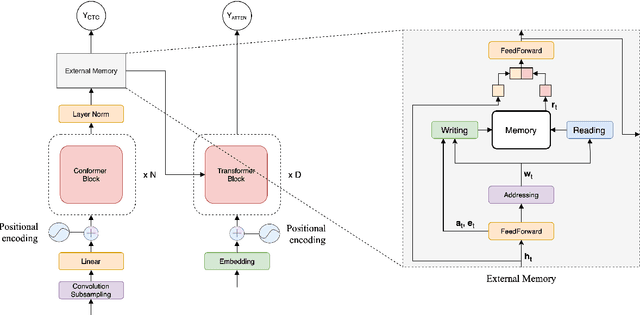
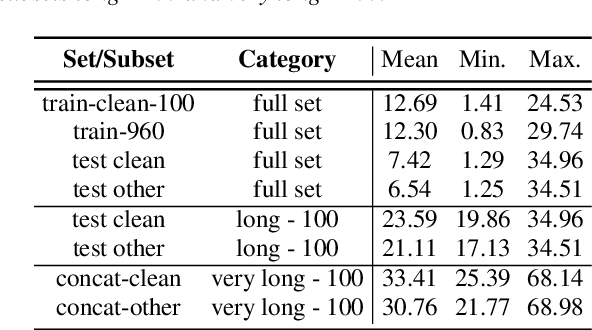
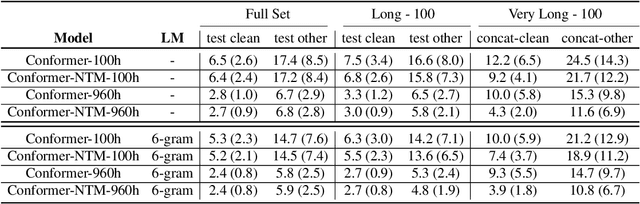
Conformers have recently been proposed as a promising modelling approach for automatic speech recognition (ASR), outperforming recurrent neural network-based approaches and transformers. Nevertheless, in general, the performance of these end-to-end models, especially attention-based models, is particularly degraded in the case of long utterances. To address this limitation, we propose adding a fully-differentiable memory-augmented neural network between the encoder and decoder of a conformer. This external memory can enrich the generalization for longer utterances since it allows the system to store and retrieve more information recurrently. Notably, we explore the neural Turing machine (NTM) that results in our proposed Conformer-NTM model architecture for ASR. Experimental results using Librispeech train-clean-100 and train-960 sets show that the proposed system outperforms the baseline conformer without memory for long utterances.
HuBERTopic: Enhancing Semantic Representation of HuBERT through Self-supervision Utilizing Topic Model
Oct 06, 2023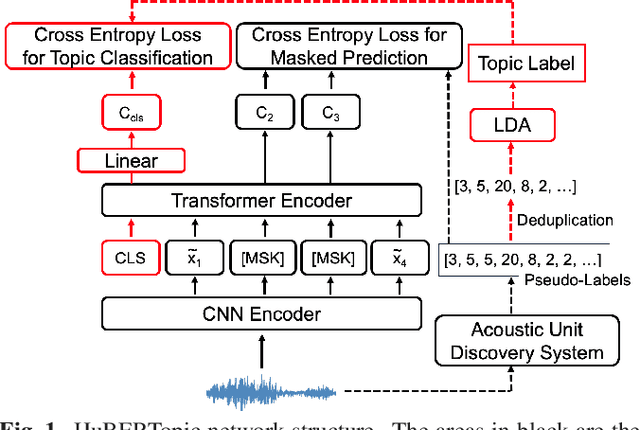
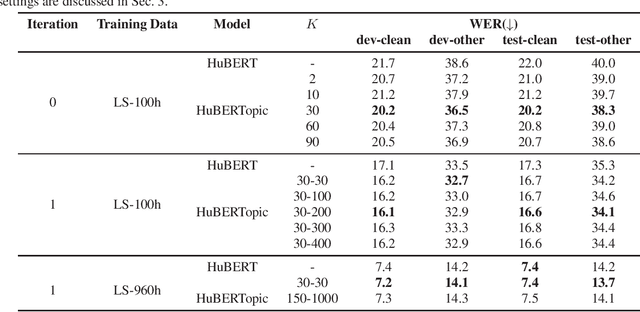

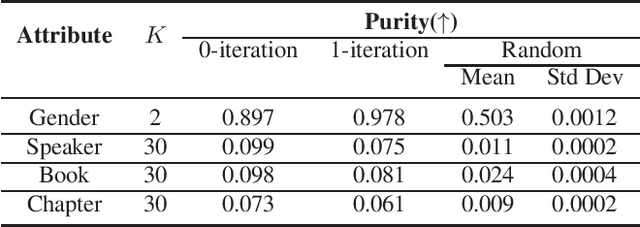
Recently, the usefulness of self-supervised representation learning (SSRL) methods has been confirmed in various downstream tasks. Many of these models, as exemplified by HuBERT and WavLM, use pseudo-labels generated from spectral features or the model's own representation features. From previous studies, it is known that the pseudo-labels contain semantic information. However, the masked prediction task, the learning criterion of HuBERT, focuses on local contextual information and may not make effective use of global semantic information such as speaker, theme of speech, and so on. In this paper, we propose a new approach to enrich the semantic representation of HuBERT. We apply topic model to pseudo-labels to generate a topic label for each utterance. An auxiliary topic classification task is added to HuBERT by using topic labels as teachers. This allows additional global semantic information to be incorporated in an unsupervised manner. Experimental results demonstrate that our method achieves comparable or better performance than the baseline in most tasks, including automatic speech recognition and five out of the eight SUPERB tasks. Moreover, we find that topic labels include various information about utterance, such as gender, speaker, and its theme. This highlights the effectiveness of our approach in capturing multifaceted semantic nuances.
calamanCy: A Tagalog Natural Language Processing Toolkit
Nov 13, 2023

We introduce calamanCy, an open-source toolkit for constructing natural language processing (NLP) pipelines for Tagalog. It is built on top of spaCy, enabling easy experimentation and integration with other frameworks. calamanCy addresses the development gap by providing a consistent API for building NLP applications and offering general-purpose multitask models with out-of-the-box support for dependency parsing, parts-of-speech (POS) tagging, and named entity recognition (NER). calamanCy aims to accelerate the progress of Tagalog NLP by consolidating disjointed resources in a unified framework. The calamanCy toolkit is available on GitHub: https://github.com/ljvmiranda921/calamanCy.
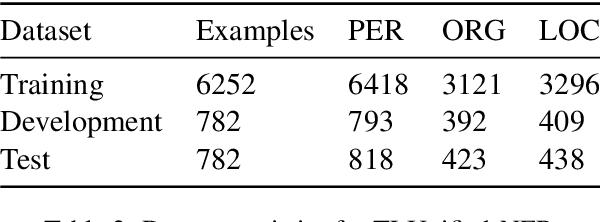
AfriSpeech-200: Pan-African Accented Speech Dataset for Clinical and General Domain ASR
Sep 30, 2023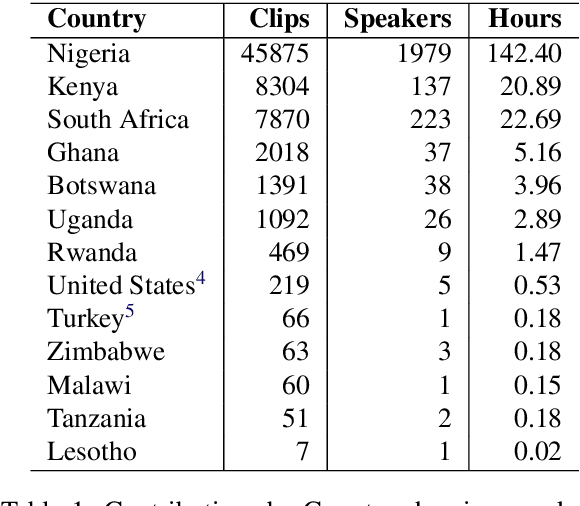

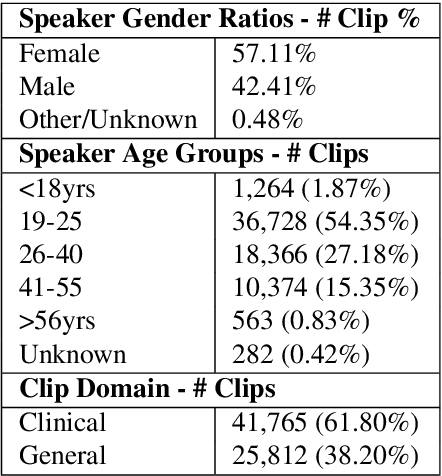
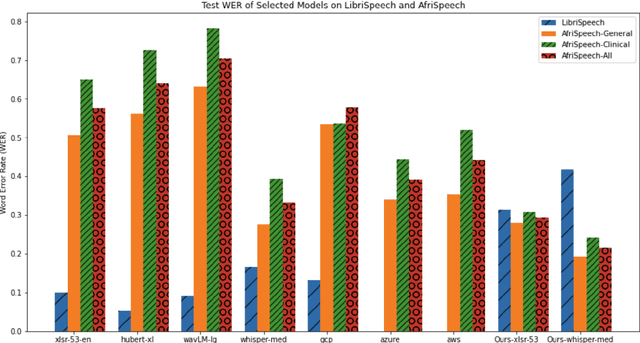
Africa has a very low doctor-to-patient ratio. At very busy clinics, doctors could see 30+ patients per day -- a heavy patient burden compared with developed countries -- but productivity tools such as clinical automatic speech recognition (ASR) are lacking for these overworked clinicians. However, clinical ASR is mature, even ubiquitous, in developed nations, and clinician-reported performance of commercial clinical ASR systems is generally satisfactory. Furthermore, the recent performance of general domain ASR is approaching human accuracy. However, several gaps exist. Several publications have highlighted racial bias with speech-to-text algorithms and performance on minority accents lags significantly. To our knowledge, there is no publicly available research or benchmark on accented African clinical ASR, and speech data is non-existent for the majority of African accents. We release AfriSpeech, 200hrs of Pan-African English speech, 67,577 clips from 2,463 unique speakers across 120 indigenous accents from 13 countries for clinical and general domain ASR, a benchmark test set, with publicly available pre-trained models with SOTA performance on the AfriSpeech benchmark.
An Analysis of Personalized Speech Recognition System Development for the Deaf and Hard-of-Hearing
Jun 24, 2023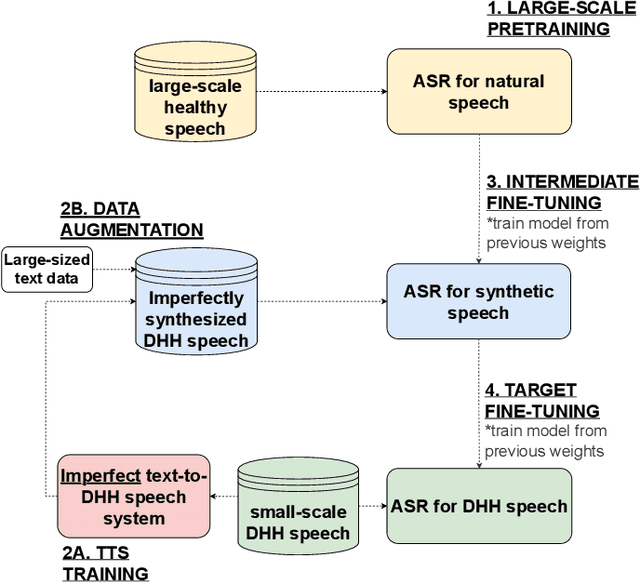
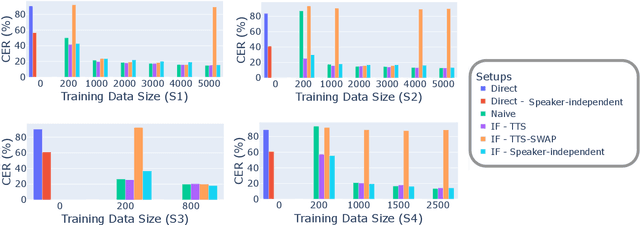
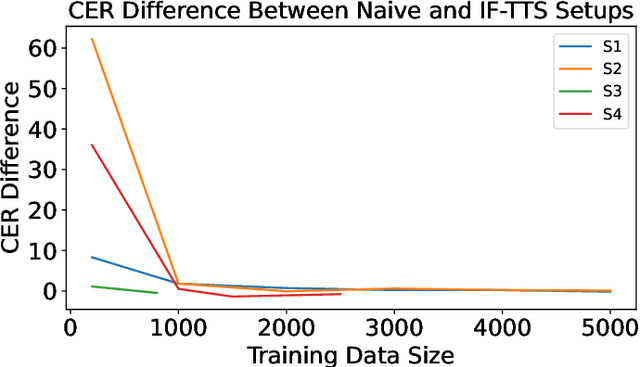
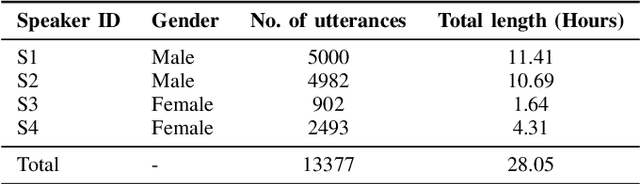
Deaf or hard-of-hearing (DHH) speakers typically have atypical speech caused by deafness. With the growing support of speech-based devices and software applications, more work needs to be done to make these devices inclusive to everyone. To do so, we analyze the use of openly-available automatic speech recognition (ASR) tools with a DHH Japanese speaker dataset. As these out-of-the-box ASR models typically do not perform well on DHH speech, we provide a thorough analysis of creating personalized ASR systems. We collected a large DHH speaker dataset of four speakers totaling around 28.05 hours and thoroughly analyzed the performance of different training frameworks by varying the training data sizes. Our findings show that 1000 utterances (or 1-2 hours) from a target speaker can already significantly improve the model performance with minimal amount of work needed, thus we recommend researchers to collect at least 1000 utterances to make an efficient personalized ASR system. In cases where 1000 utterances is difficult to collect, we also discover significant improvements in using previously proposed data augmentation techniques such as intermediate fine-tuning when only 200 utterances are available.
DiaCorrect: Error Correction Back-end For Speaker Diarization
Sep 15, 2023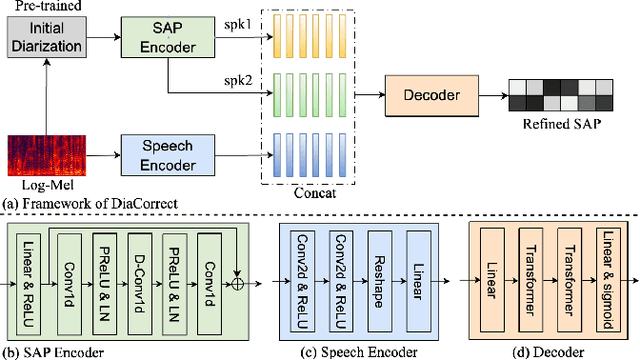
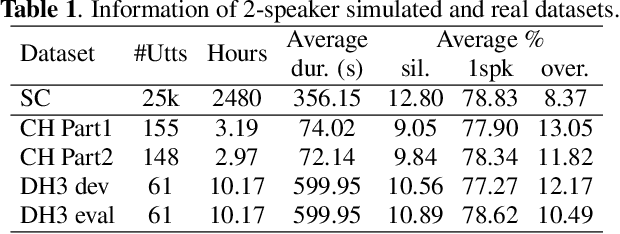
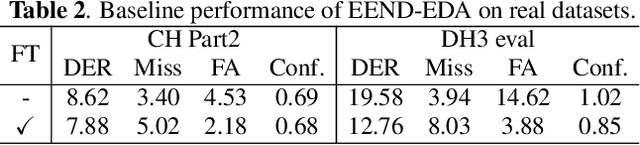
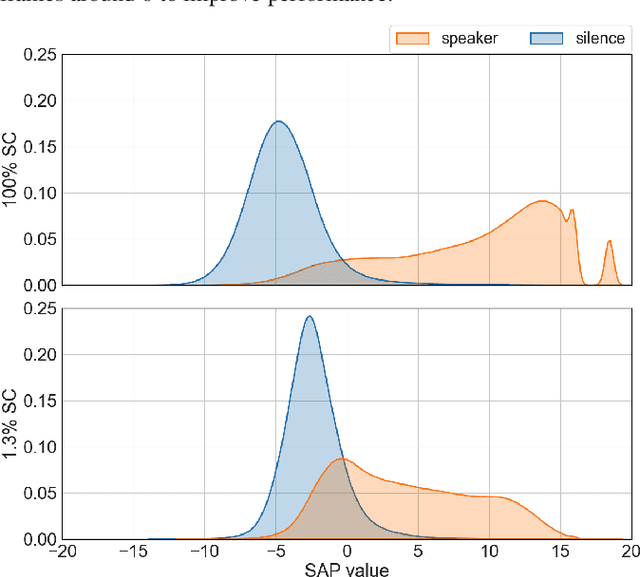
In this work, we propose an error correction framework, named DiaCorrect, to refine the output of a diarization system in a simple yet effective way. This method is inspired by error correction techniques in automatic speech recognition. Our model consists of two parallel convolutional encoders and a transform-based decoder. By exploiting the interactions between the input recording and the initial system's outputs, DiaCorrect can automatically correct the initial speaker activities to minimize the diarization errors. Experiments on 2-speaker telephony data show that the proposed DiaCorrect can effectively improve the initial model's results. Our source code is publicly available at https://github.com/BUTSpeechFIT/diacorrect.