 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
calamanCy: A Tagalog Natural Language Processing Toolkit
Nov 13, 2023

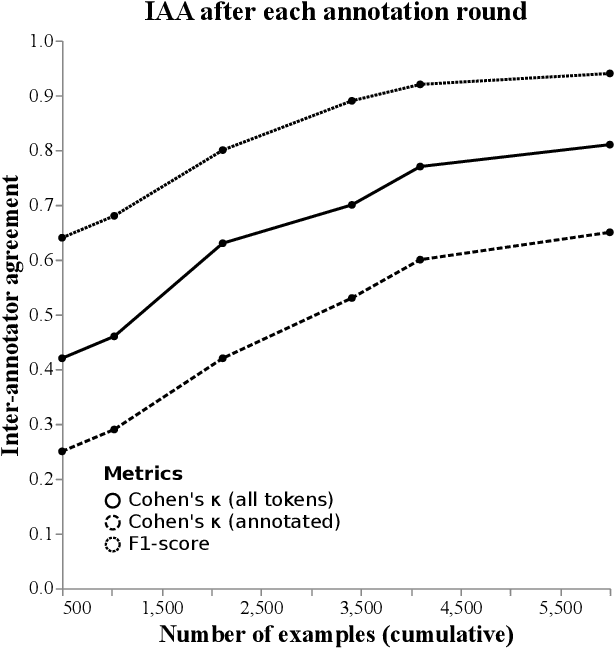

We introduce calamanCy, an open-source toolkit for constructing natural language processing (NLP) pipelines for Tagalog. It is built on top of spaCy, enabling easy experimentation and integration with other frameworks. calamanCy addresses the development gap by providing a consistent API for building NLP applications and offering general-purpose multitask models with out-of-the-box support for dependency parsing, parts-of-speech (POS) tagging, and named entity recognition (NER). calamanCy aims to accelerate the progress of Tagalog NLP by consolidating disjointed resources in a unified framework. The calamanCy toolkit is available on GitHub: https://github.com/ljvmiranda921/calamanCy.
Debiased Automatic Speech Recognition for Dysarthric Speech via Sample Reweighting with Sample Affinity Test
May 22, 2023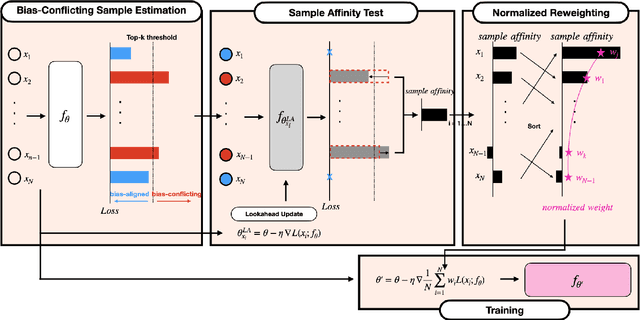
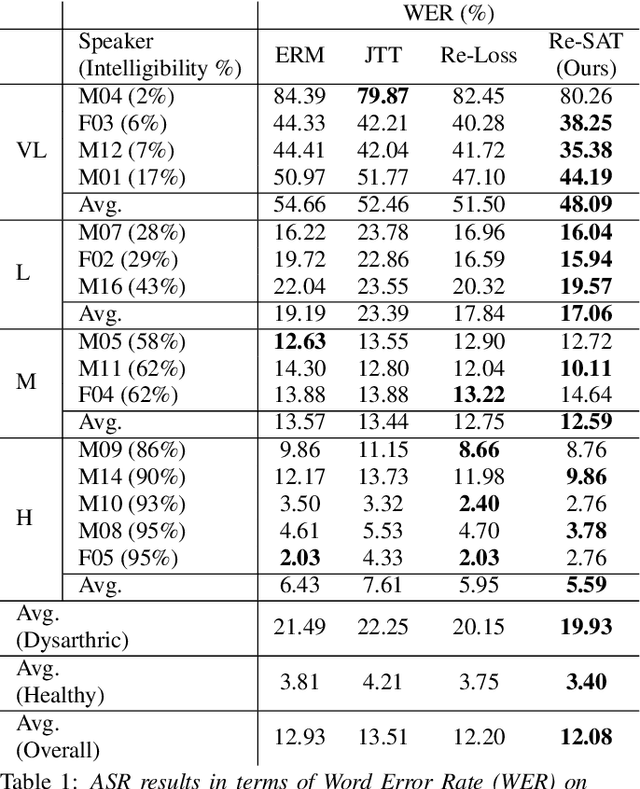
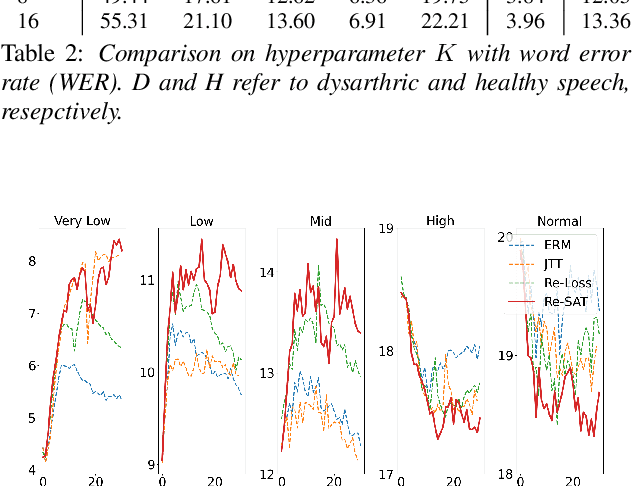
Automatic speech recognition systems based on deep learning are mainly trained under empirical risk minimization (ERM). Since ERM utilizes the averaged performance on the data samples regardless of a group such as healthy or dysarthric speakers, ASR systems are unaware of the performance disparities across the groups. This results in biased ASR systems whose performance differences among groups are severe. In this study, we aim to improve the ASR system in terms of group robustness for dysarthric speakers. To achieve our goal, we present a novel approach, sample reweighting with sample affinity test (Re-SAT). Re-SAT systematically measures the debiasing helpfulness of the given data sample and then mitigates the bias by debiasing helpfulness-based sample reweighting. Experimental results demonstrate that Re-SAT contributes to improved ASR performance on dysarthric speech without performance degradation on healthy speech.
HuBERTopic: Enhancing Semantic Representation of HuBERT through Self-supervision Utilizing Topic Model
Oct 06, 2023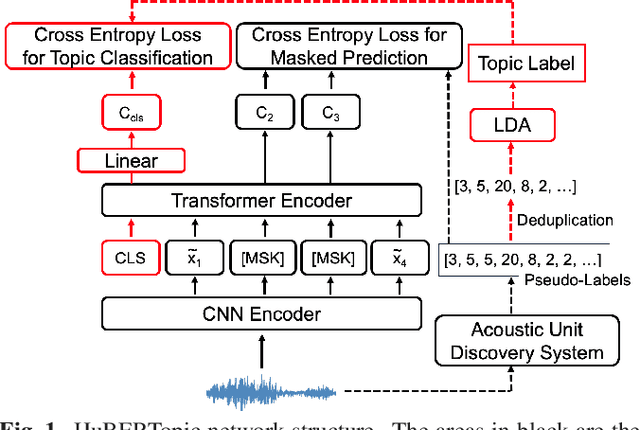
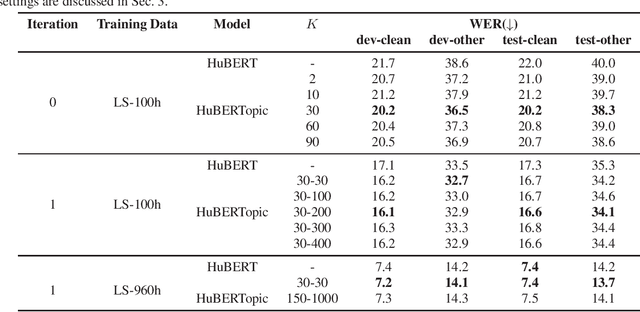

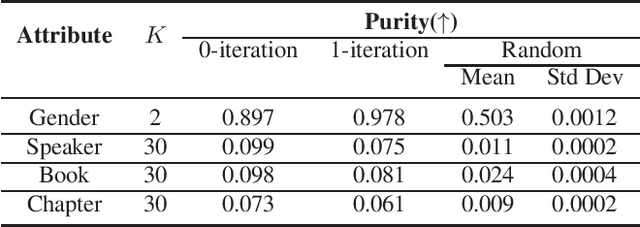
Recently, the usefulness of self-supervised representation learning (SSRL) methods has been confirmed in various downstream tasks. Many of these models, as exemplified by HuBERT and WavLM, use pseudo-labels generated from spectral features or the model's own representation features. From previous studies, it is known that the pseudo-labels contain semantic information. However, the masked prediction task, the learning criterion of HuBERT, focuses on local contextual information and may not make effective use of global semantic information such as speaker, theme of speech, and so on. In this paper, we propose a new approach to enrich the semantic representation of HuBERT. We apply topic model to pseudo-labels to generate a topic label for each utterance. An auxiliary topic classification task is added to HuBERT by using topic labels as teachers. This allows additional global semantic information to be incorporated in an unsupervised manner. Experimental results demonstrate that our method achieves comparable or better performance than the baseline in most tasks, including automatic speech recognition and five out of the eight SUPERB tasks. Moreover, we find that topic labels include various information about utterance, such as gender, speaker, and its theme. This highlights the effectiveness of our approach in capturing multifaceted semantic nuances.
Human Transcription Quality Improvement
Sep 24, 2023
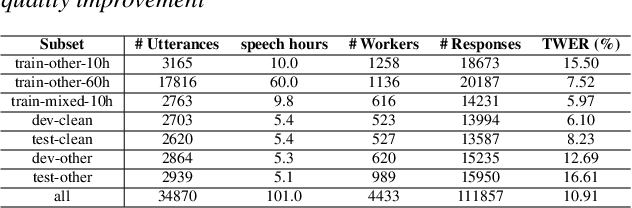
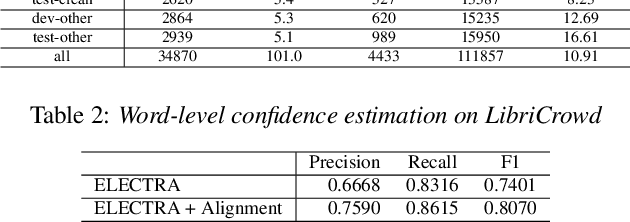
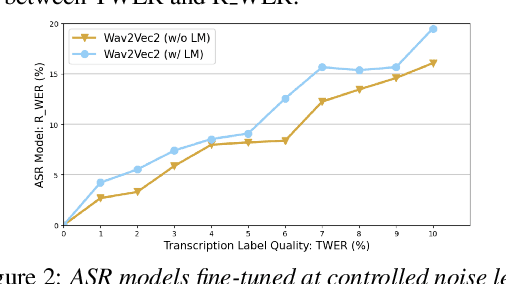
High quality transcription data is crucial for training automatic speech recognition (ASR) systems. However, the existing industry-level data collection pipelines are expensive to researchers, while the quality of crowdsourced transcription is low. In this paper, we propose a reliable method to collect speech transcriptions. We introduce two mechanisms to improve transcription quality: confidence estimation based reprocessing at labeling stage, and automatic word error correction at post-labeling stage. We collect and release LibriCrowd - a large-scale crowdsourced dataset of audio transcriptions on 100 hours of English speech. Experiment shows the Transcription WER is reduced by over 50%. We further investigate the impact of transcription error on ASR model performance and found a strong correlation. The transcription quality improvement provides over 10% relative WER reduction for ASR models. We release the dataset and code to benefit the research community.
* 5 pages, 3 figures, 5 tables, INTERSPEECH 2023
Distilling HuBERT with LSTMs via Decoupled Knowledge Distillation
Sep 18, 2023Much research effort is being applied to the task of compressing the knowledge of self-supervised models, which are powerful, yet large and memory consuming. In this work, we show that the original method of knowledge distillation (and its more recently proposed extension, decoupled knowledge distillation) can be applied to the task of distilling HuBERT. In contrast to methods that focus on distilling internal features, this allows for more freedom in the network architecture of the compressed model. We thus propose to distill HuBERT's Transformer layers into an LSTM-based distilled model that reduces the number of parameters even below DistilHuBERT and at the same time shows improved performance in automatic speech recognition.
Memory-augmented conformer for improved end-to-end long-form ASR
Sep 22, 2023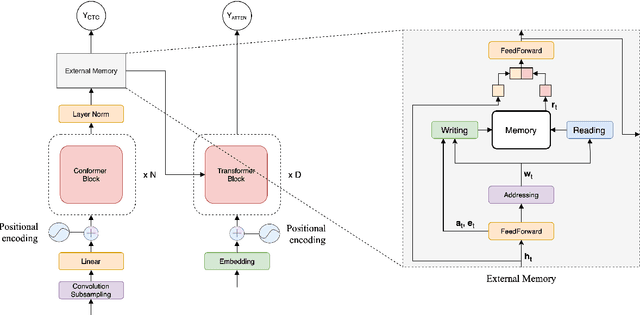
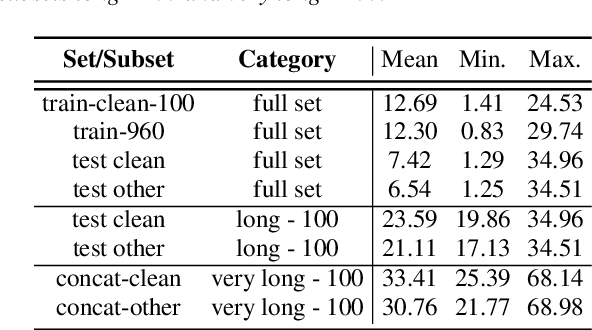
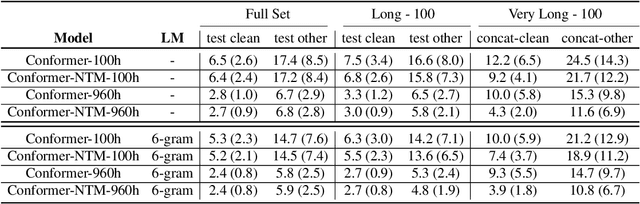
Conformers have recently been proposed as a promising modelling approach for automatic speech recognition (ASR), outperforming recurrent neural network-based approaches and transformers. Nevertheless, in general, the performance of these end-to-end models, especially attention-based models, is particularly degraded in the case of long utterances. To address this limitation, we propose adding a fully-differentiable memory-augmented neural network between the encoder and decoder of a conformer. This external memory can enrich the generalization for longer utterances since it allows the system to store and retrieve more information recurrently. Notably, we explore the neural Turing machine (NTM) that results in our proposed Conformer-NTM model architecture for ASR. Experimental results using Librispeech train-clean-100 and train-960 sets show that the proposed system outperforms the baseline conformer without memory for long utterances.
Enhancing Unsupervised Speech Recognition with Diffusion GANs
Mar 23, 2023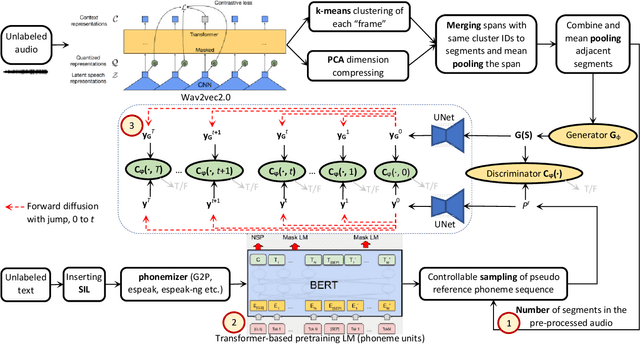
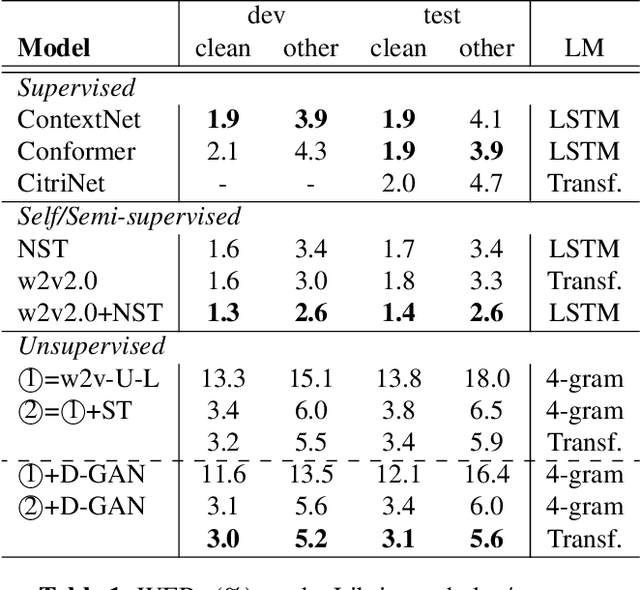
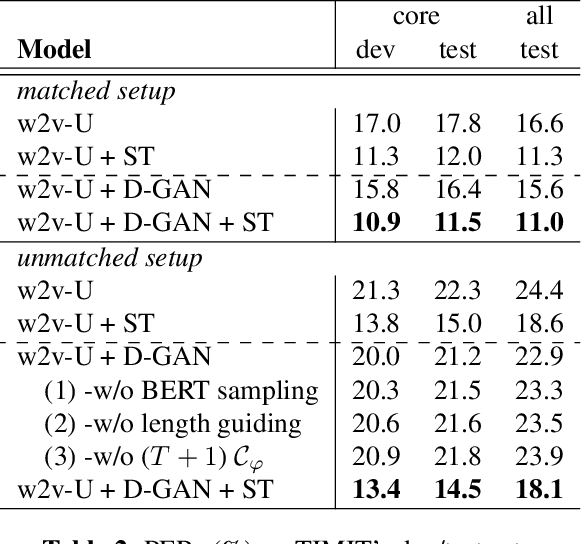
We enhance the vanilla adversarial training method for unsupervised Automatic Speech Recognition (ASR) by a diffusion-GAN. Our model (1) injects instance noises of various intensities to the generator's output and unlabeled reference text which are sampled from pretrained phoneme language models with a length constraint, (2) asks diffusion timestep-dependent discriminators to separate them, and (3) back-propagates the gradients to update the generator. Word/phoneme error rate comparisons with wav2vec-U under Librispeech (3.1% for test-clean and 5.6% for test-other), TIMIT and MLS datasets, show that our enhancement strategies work effectively.
MIR-GAN: Refining Frame-Level Modality-Invariant Representations with Adversarial Network for Audio-Visual Speech Recognition
Jun 18, 2023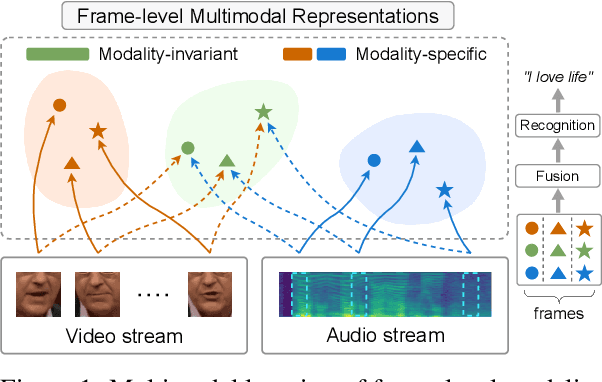
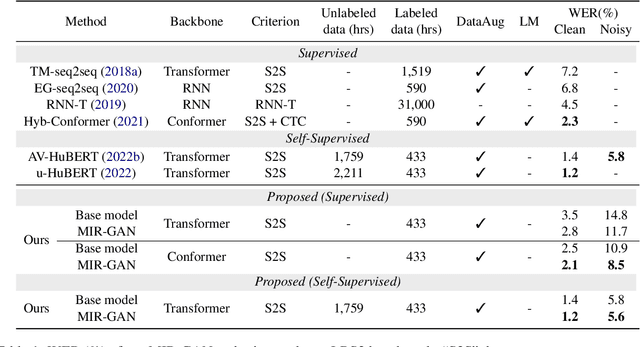
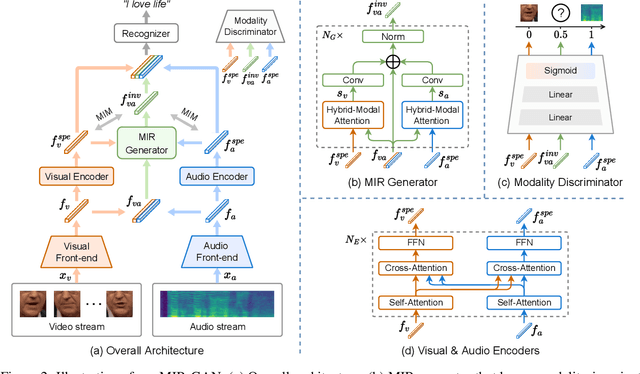
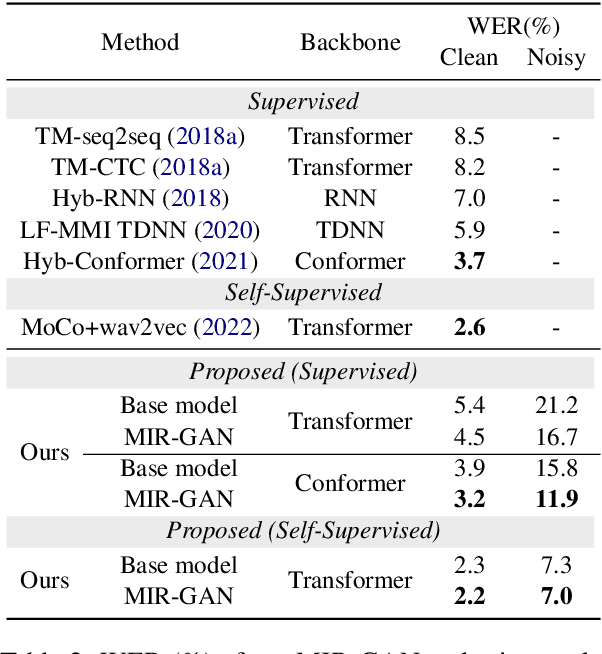
Audio-visual speech recognition (AVSR) attracts a surge of research interest recently by leveraging multimodal signals to understand human speech. Mainstream approaches addressing this task have developed sophisticated architectures and techniques for multi-modality fusion and representation learning. However, the natural heterogeneity of different modalities causes distribution gap between their representations, making it challenging to fuse them. In this paper, we aim to learn the shared representations across modalities to bridge their gap. Different from existing similar methods on other multimodal tasks like sentiment analysis, we focus on the temporal contextual dependencies considering the sequence-to-sequence task setting of AVSR. In particular, we propose an adversarial network to refine frame-level modality-invariant representations (MIR-GAN), which captures the commonality across modalities to ease the subsequent multimodal fusion process. Extensive experiments on public benchmarks LRS3 and LRS2 show that our approach outperforms the state-of-the-arts.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
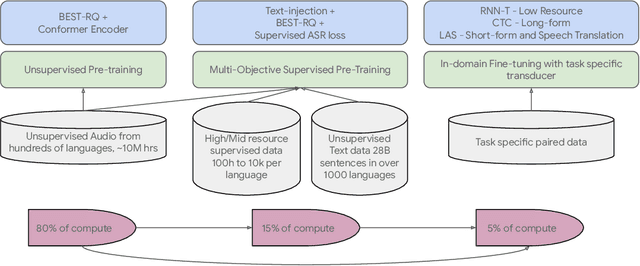
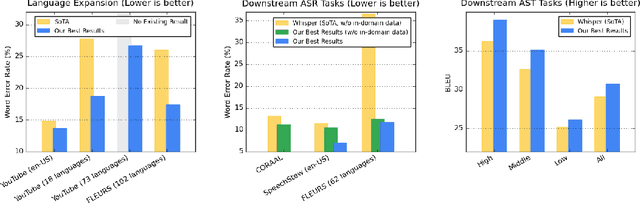

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
AfriSpeech-200: Pan-African Accented Speech Dataset for Clinical and General Domain ASR
Sep 30, 2023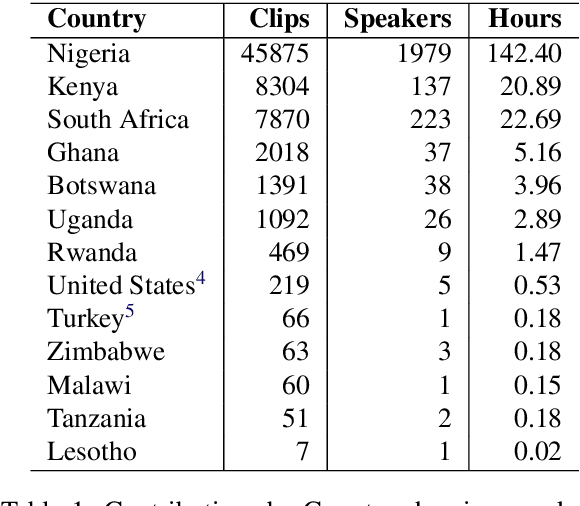

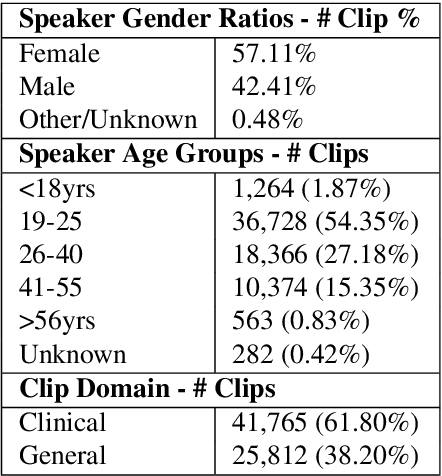
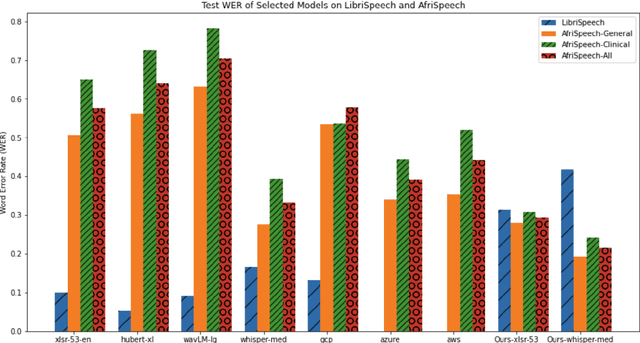
Africa has a very low doctor-to-patient ratio. At very busy clinics, doctors could see 30+ patients per day -- a heavy patient burden compared with developed countries -- but productivity tools such as clinical automatic speech recognition (ASR) are lacking for these overworked clinicians. However, clinical ASR is mature, even ubiquitous, in developed nations, and clinician-reported performance of commercial clinical ASR systems is generally satisfactory. Furthermore, the recent performance of general domain ASR is approaching human accuracy. However, several gaps exist. Several publications have highlighted racial bias with speech-to-text algorithms and performance on minority accents lags significantly. To our knowledge, there is no publicly available research or benchmark on accented African clinical ASR, and speech data is non-existent for the majority of African accents. We release AfriSpeech, 200hrs of Pan-African English speech, 67,577 clips from 2,463 unique speakers across 120 indigenous accents from 13 countries for clinical and general domain ASR, a benchmark test set, with publicly available pre-trained models with SOTA performance on the AfriSpeech benchmark.