 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A large-scale multimodal dataset of human speech recognition
Mar 15, 2023
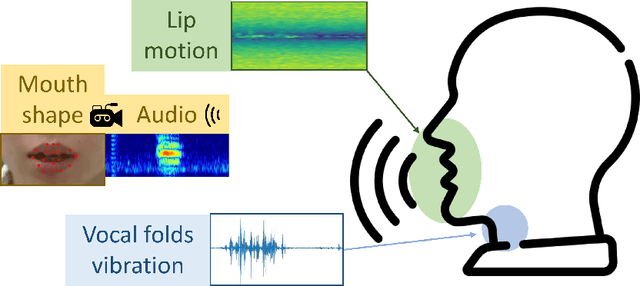

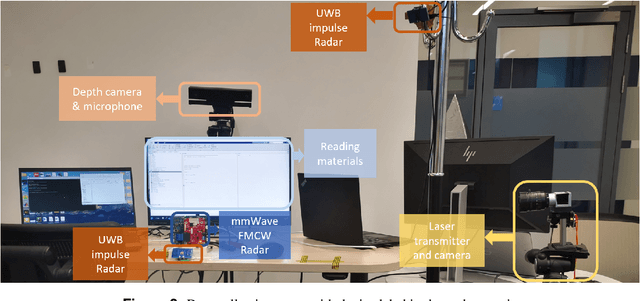
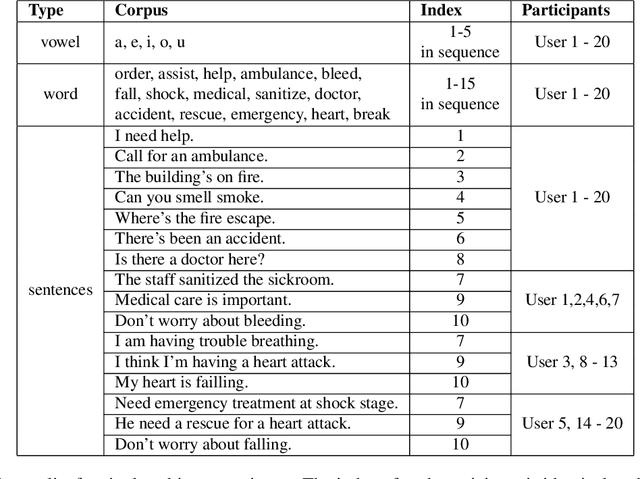
Nowadays, non-privacy small-scale motion detection has attracted an increasing amount of research in remote sensing in speech recognition. These new modalities are employed to enhance and restore speech information from speakers of multiple types of data. In this paper, we propose a dataset contains 7.5 GHz Channel Impulse Response (CIR) data from ultra-wideband (UWB) radars, 77-GHz frequency modulated continuous wave (FMCW) data from millimetre wave (mmWave) radar, and laser data. Meanwhile, a depth camera is adopted to record the landmarks of the subject's lip and voice. Approximately 400 minutes of annotated speech profiles are provided, which are collected from 20 participants speaking 5 vowels, 15 words and 16 sentences. The dataset has been validated and has potential for the research of lip reading and multimodal speech recognition.
Lenient Evaluation of Japanese Speech Recognition: Modeling Naturally Occurring Spelling Inconsistency
Jun 07, 2023
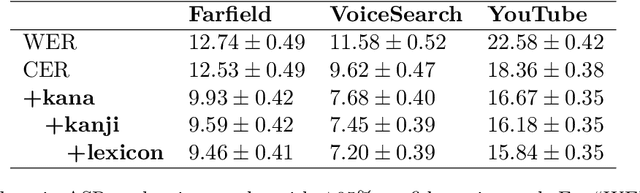
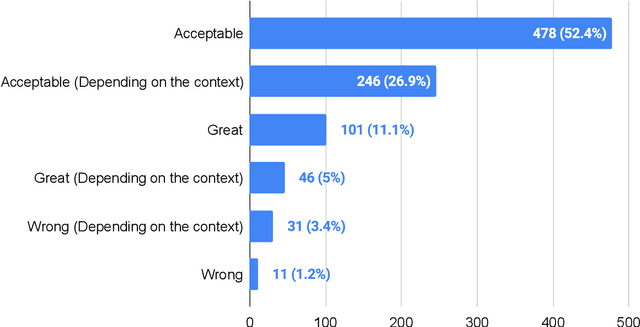
Word error rate (WER) and character error rate (CER) are standard metrics in Speech Recognition (ASR), but one problem has always been alternative spellings: If one's system transcribes adviser whereas the ground truth has advisor, this will count as an error even though the two spellings really represent the same word. Japanese is notorious for ``lacking orthography'': most words can be spelled in multiple ways, presenting a problem for accurate ASR evaluation. In this paper we propose a new lenient evaluation metric as a more defensible CER measure for Japanese ASR. We create a lattice of plausible respellings of the reference transcription, using a combination of lexical resources, a Japanese text-processing system, and a neural machine translation model for reconstructing kanji from hiragana or katakana. In a manual evaluation, raters rated 95.4% of the proposed spelling variants as plausible. ASR results show that our method, which does not penalize the system for choosing a valid alternate spelling of a word, affords a 2.4%-3.1% absolute reduction in CER depending on the task.
Evaluating Speech Synthesis by Training Recognizers on Synthetic Speech
Oct 01, 2023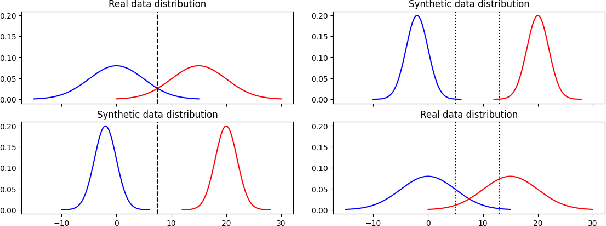
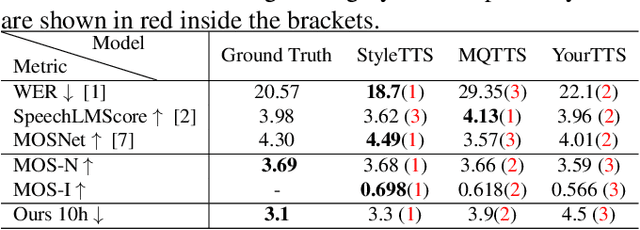
Modern speech synthesis systems have improved significantly, with synthetic speech being indistinguishable from real speech. However, efficient and holistic evaluation of synthetic speech still remains a significant challenge. Human evaluation using Mean Opinion Score (MOS) is ideal, but inefficient due to high costs. Therefore, researchers have developed auxiliary automatic metrics like Word Error Rate (WER) to measure intelligibility. Prior works focus on evaluating synthetic speech based on pre-trained speech recognition models, however, this can be limiting since this approach primarily measures speech intelligibility. In this paper, we propose an evaluation technique involving the training of an ASR model on synthetic speech and assessing its performance on real speech. Our main assumption is that by training the ASR model on the synthetic speech, the WER on real speech reflects the similarity between distributions, a broader assessment of synthetic speech quality beyond intelligibility. Our proposed metric demonstrates a strong correlation with both MOS naturalness and MOS intelligibility when compared to SpeechLMScore and MOSNet on three recent Text-to-Speech (TTS) systems: MQTTS, StyleTTS, and YourTTS.
LAE-ST-MoE: Boosted Language-Aware Encoder Using Speech Translation Auxiliary Task for E2E Code-switching ASR
Sep 28, 2023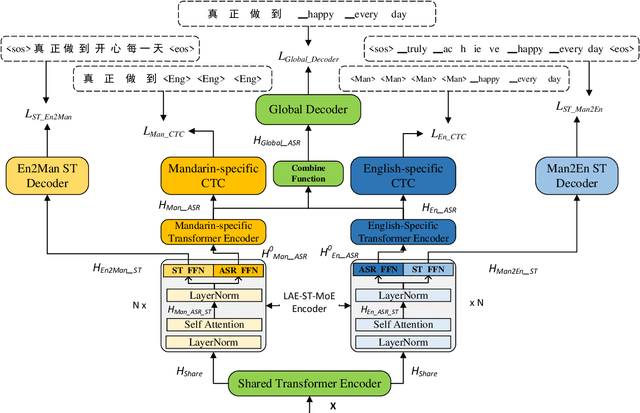
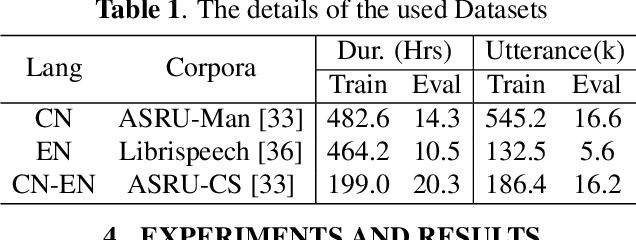
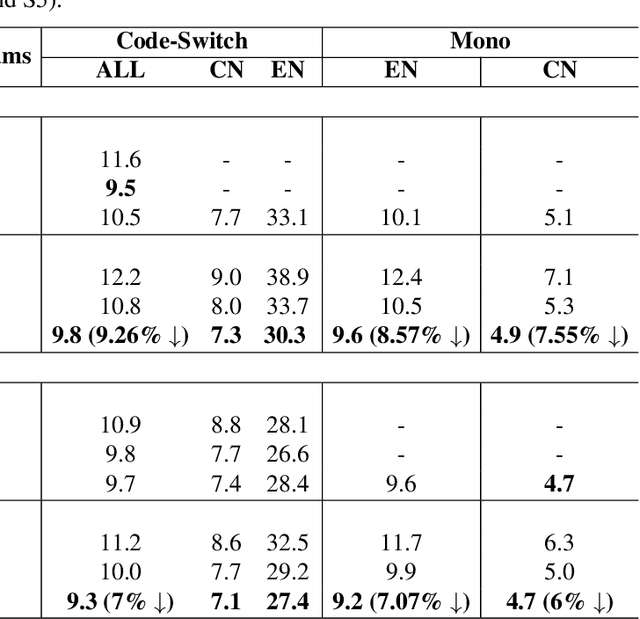
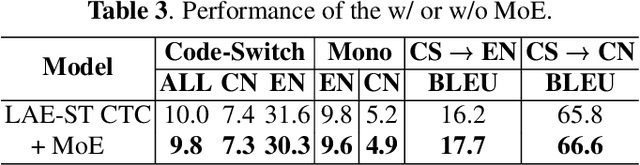
Recently, to mitigate the confusion between different languages in code-switching (CS) automatic speech recognition (ASR), the conditionally factorized models, such as the language-aware encoder (LAE), explicitly disregard the contextual information between different languages. However, this information may be helpful for ASR modeling. To alleviate this issue, we propose the LAE-ST-MoE framework. It incorporates speech translation (ST) tasks into LAE and utilizes ST to learn the contextual information between different languages. It introduces a task-based mixture of expert modules, employing separate feed-forward networks for the ASR and ST tasks. Experimental results on the ASRU 2019 Mandarin-English CS challenge dataset demonstrate that, compared to the LAE-based CTC, the LAE-ST-MoE model achieves a 9.26% mix error reduction on the CS test with the same decoding parameter. Moreover, the well-trained LAE-ST-MoE model can perform ST tasks from CS speech to Mandarin or English text.
Hierarchical Cross-Modality Knowledge Transfer with Sinkhorn Attention for CTC-based ASR
Sep 28, 2023Due to the modality discrepancy between textual and acoustic modeling, efficiently transferring linguistic knowledge from a pretrained language model (PLM) to acoustic encoding for automatic speech recognition (ASR) still remains a challenging task. In this study, we propose a cross-modality knowledge transfer (CMKT) learning framework in a temporal connectionist temporal classification (CTC) based ASR system where hierarchical acoustic alignments with the linguistic representation are applied. Additionally, we propose the use of Sinkhorn attention in cross-modality alignment process, where the transformer attention is a special case of this Sinkhorn attention process. The CMKT learning is supposed to compel the acoustic encoder to encode rich linguistic knowledge for ASR. On the AISHELL-1 dataset, with CTC greedy decoding for inference (without using any language model), we achieved state-of-the-art performance with 3.64% and 3.94% character error rates (CERs) for the development and test sets, which corresponding to relative improvements of 34.18% and 34.88% compared to the baseline CTC-ASR system, respectively.
MuAViC: A Multilingual Audio-Visual Corpus for Robust Speech Recognition and Robust Speech-to-Text Translation
Mar 01, 2023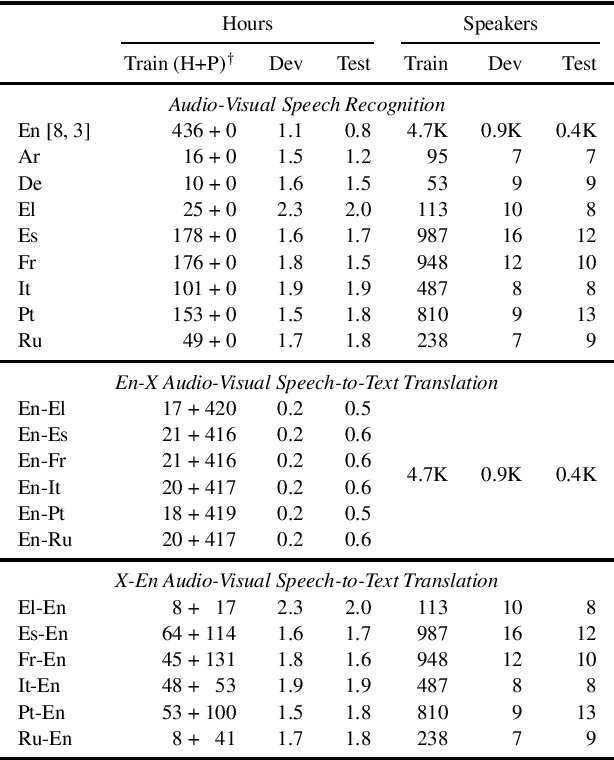
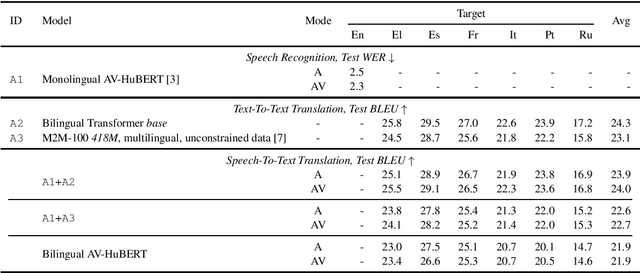

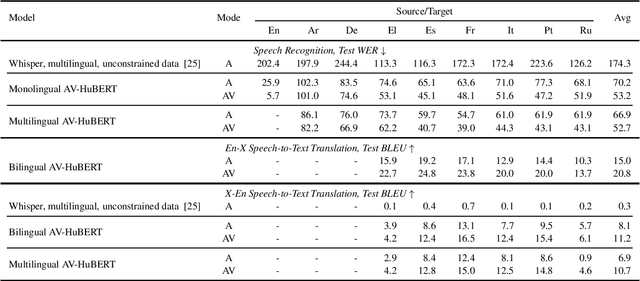
We introduce MuAViC, a multilingual audio-visual corpus for robust speech recognition and robust speech-to-text translation providing 1200 hours of audio-visual speech in 9 languages. It is fully transcribed and covers 6 English-to-X translation as well as 6 X-to-English translation directions. To the best of our knowledge, this is the first open benchmark for audio-visual speech-to-text translation and the largest open benchmark for multilingual audio-visual speech recognition. Our baseline results show that MuAViC is effective for building noise-robust speech recognition and translation models. We make the corpus available at https://github.com/facebookresearch/muavic.
On the Efficacy and Noise-Robustness of Jointly Learned Speech Emotion and Automatic Speech Recognition
May 25, 2023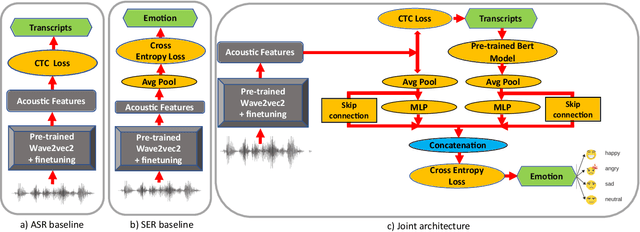
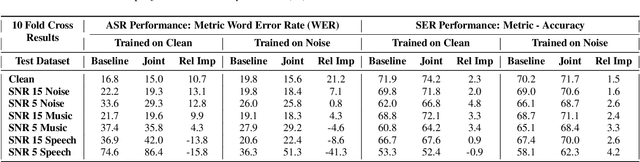
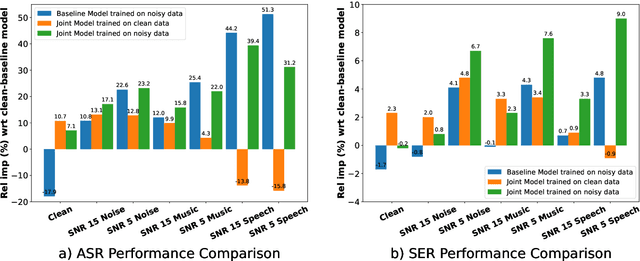
New-age conversational agent systems perform both speech emotion recognition (SER) and automatic speech recognition (ASR) using two separate and often independent approaches for real-world application in noisy environments. In this paper, we investigate a joint ASR-SER multitask learning approach in a low-resource setting and show that improvements are observed not only in SER, but also in ASR. We also investigate the robustness of such jointly trained models to the presence of background noise, babble, and music. Experimental results on the IEMOCAP dataset show that joint learning can improve ASR word error rate (WER) and SER classification accuracy by 10.7% and 2.3% respectively in clean scenarios. In noisy scenarios, results on data augmented with MUSAN show that the joint approach outperforms the independent ASR and SER approaches across many noisy conditions. Overall, the joint ASR-SER approach yielded more noise-resistant models than the independent ASR and SER approaches.
HuBERTopic: Enhancing Semantic Representation of HuBERT through Self-supervision Utilizing Topic Model
Oct 06, 2023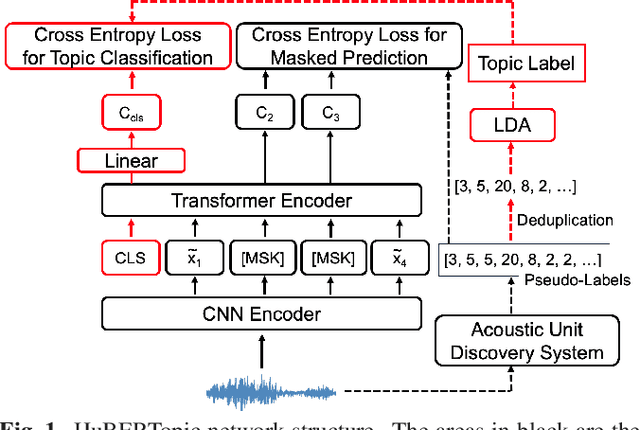
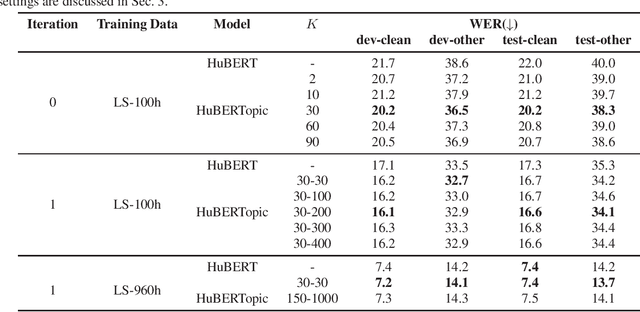

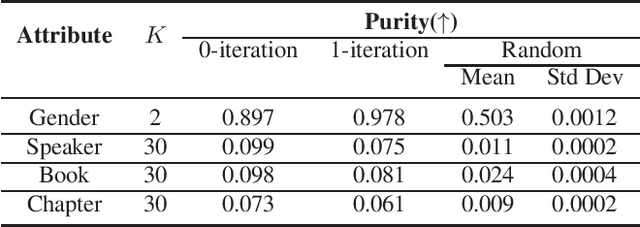
Recently, the usefulness of self-supervised representation learning (SSRL) methods has been confirmed in various downstream tasks. Many of these models, as exemplified by HuBERT and WavLM, use pseudo-labels generated from spectral features or the model's own representation features. From previous studies, it is known that the pseudo-labels contain semantic information. However, the masked prediction task, the learning criterion of HuBERT, focuses on local contextual information and may not make effective use of global semantic information such as speaker, theme of speech, and so on. In this paper, we propose a new approach to enrich the semantic representation of HuBERT. We apply topic model to pseudo-labels to generate a topic label for each utterance. An auxiliary topic classification task is added to HuBERT by using topic labels as teachers. This allows additional global semantic information to be incorporated in an unsupervised manner. Experimental results demonstrate that our method achieves comparable or better performance than the baseline in most tasks, including automatic speech recognition and five out of the eight SUPERB tasks. Moreover, we find that topic labels include various information about utterance, such as gender, speaker, and its theme. This highlights the effectiveness of our approach in capturing multifaceted semantic nuances.
Considerations for Ethical Speech Recognition Datasets
May 03, 2023Speech AI Technologies are largely trained on publicly available datasets or by the massive web-crawling of speech. In both cases, data acquisition focuses on minimizing collection effort, without necessarily taking the data subjects' protection or user needs into consideration. This results to models that are not robust when used on users who deviate from the dominant demographics in the training set, discriminating individuals having different dialects, accents, speaking styles, and disfluencies. In this talk, we use automatic speech recognition as a case study and examine the properties that ethical speech datasets should possess towards responsible AI applications. We showcase diversity issues, inclusion practices, and necessary considerations that can improve trained models, while facilitating model explainability and protecting users and data subjects. We argue for the legal & privacy protection of data subjects, targeted data sampling corresponding to user demographics & needs, appropriate meta data that ensure explainability & accountability in cases of model failure, and the sociotechnical \& situated model design. We hope this talk can inspire researchers \& practitioners to design and use more human-centric datasets in speech technologies and other domains, in ways that empower and respect users, while improving machine learning models' robustness and utility.
Multi-pass Training and Cross-information Fusion for Low-resource End-to-end Accented Speech Recognition
Jun 20, 2023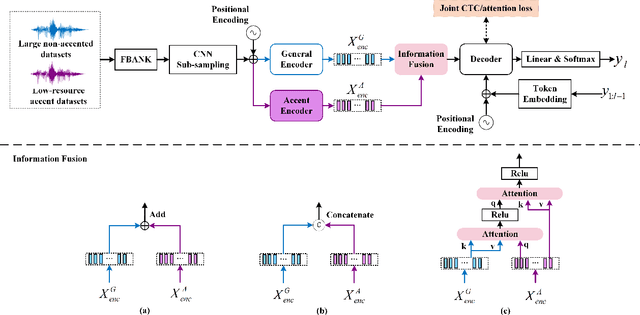
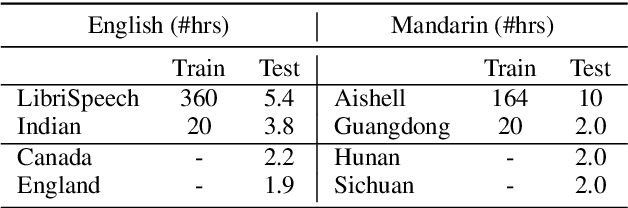

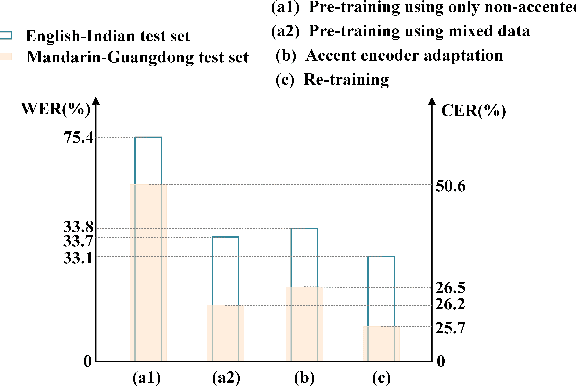
Low-resource accented speech recognition is one of the important challenges faced by current ASR technology in practical applications. In this study, we propose a Conformer-based architecture, called Aformer, to leverage both the acoustic information from large non-accented and limited accented training data. Specifically, a general encoder and an accent encoder are designed in the Aformer to extract complementary acoustic information. Moreover, we propose to train the Aformer in a multi-pass manner, and investigate three cross-information fusion methods to effectively combine the information from both general and accent encoders. All experiments are conducted on both the accented English and Mandarin ASR tasks. Results show that our proposed methods outperform the strong Conformer baseline by relative 10.2% to 24.5% word/character error rate reduction on six in-domain and out-of-domain accented test sets.