 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Reproducing Whisper-Style Training Using an Open-Source Toolkit and Publicly Available Data
Oct 02, 2023
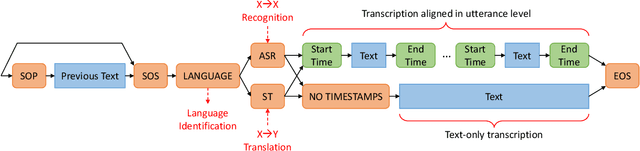
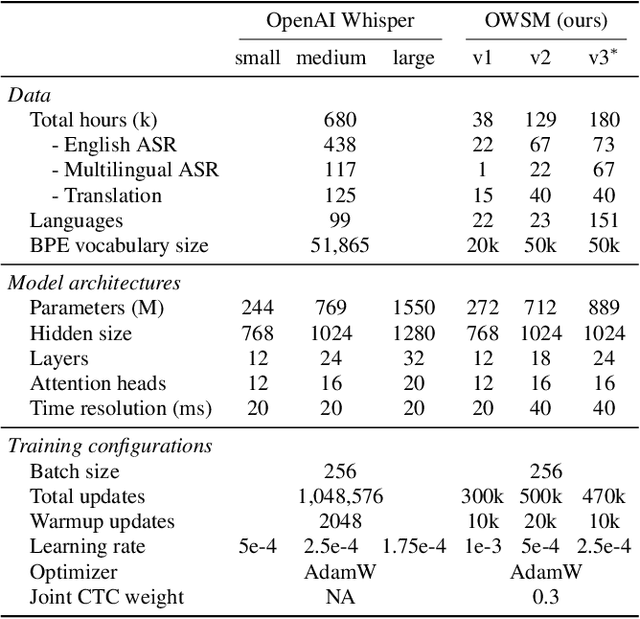
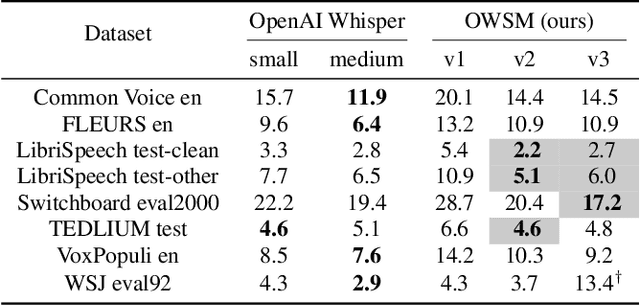
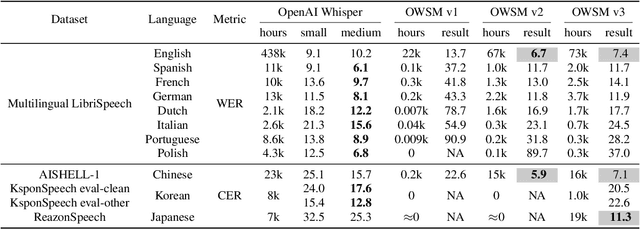
Pre-training speech models on large volumes of data has achieved remarkable success. OpenAI Whisper is a multilingual multitask model trained on 680k hours of supervised speech data. It generalizes well to various speech recognition and translation benchmarks even in a zero-shot setup. However, the full pipeline for developing such models (from data collection to training) is not publicly accessible, which makes it difficult for researchers to further improve its performance and address training-related issues such as efficiency, robustness, fairness, and bias. This work presents an Open Whisper-style Speech Model (OWSM), which reproduces Whisper-style training using an open-source toolkit and publicly available data. OWSM even supports more translation directions and can be more efficient to train. We will publicly release all scripts used for data preparation, training, inference, and scoring as well as pre-trained models and training logs to promote open science.
Fast Word Error Rate Estimation Using Self-Supervised Representations For Speech And Text
Oct 12, 2023The quality of automatic speech recognition (ASR) is typically measured by word error rate (WER). WER estimation is a task aiming to predict the WER of an ASR system, given a speech utterance and a transcription. This task has gained increasing attention while advanced ASR systems are trained on large amounts of data. In this case, WER estimation becomes necessary in many scenarios, for example, selecting training data with unknown transcription quality or estimating the testing performance of an ASR system without ground truth transcriptions. Facing large amounts of data, the computation efficiency of a WER estimator becomes essential in practical applications. However, previous works usually did not consider it as a priority. In this paper, a Fast WER estimator (Fe-WER) using self-supervised learning representation (SSLR) is introduced. The estimator is built upon SSLR aggregated by average pooling. The results show that Fe-WER outperformed the e-WER3 baseline relatively by 19.69% and 7.16% on Ted-Lium3 in both evaluation metrics of root mean square error and Pearson correlation coefficient, respectively. Moreover, the estimation weighted by duration was 10.43% when the target was 10.88%. Lastly, the inference speed was about 4x in terms of a real-time factor.
SGEM: Test-Time Adaptation for Automatic Speech Recognition via Sequential-Level Generalized Entropy Minimization
Jun 21, 2023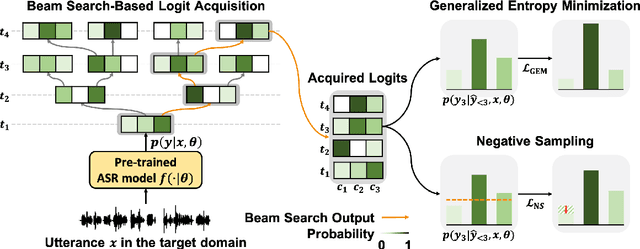
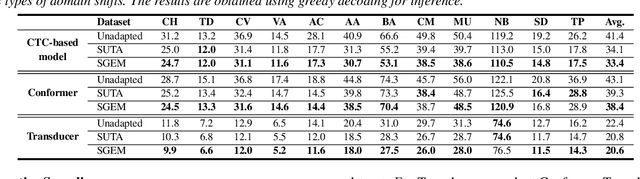

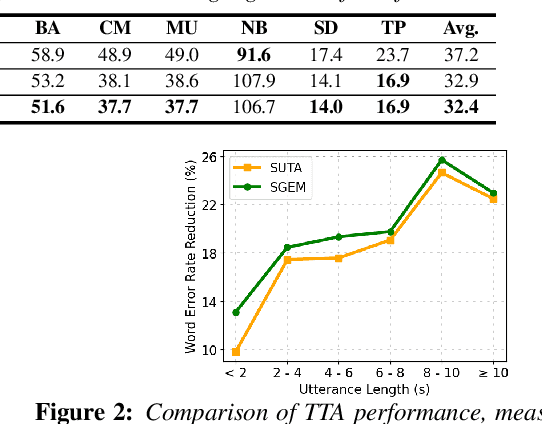
Automatic speech recognition (ASR) models are frequently exposed to data distribution shifts in many real-world scenarios, leading to erroneous predictions. To tackle this issue, an existing test-time adaptation (TTA) method has recently been proposed to adapt the pre-trained ASR model on unlabeled test instances without source data. Despite decent performance gain, this work relies solely on naive greedy decoding and performs adaptation across timesteps at a frame level, which may not be optimal given the sequential nature of the model output. Motivated by this, we propose a novel TTA framework, dubbed SGEM, for general ASR models. To treat the sequential output, SGEM first exploits beam search to explore candidate output logits and selects the most plausible one. Then, it utilizes generalized entropy minimization and negative sampling as unsupervised objectives to adapt the model. SGEM achieves state-of-the-art performance for three mainstream ASR models under various domain shifts.
MuAViC: A Multilingual Audio-Visual Corpus for Robust Speech Recognition and Robust Speech-to-Text Translation
Mar 01, 2023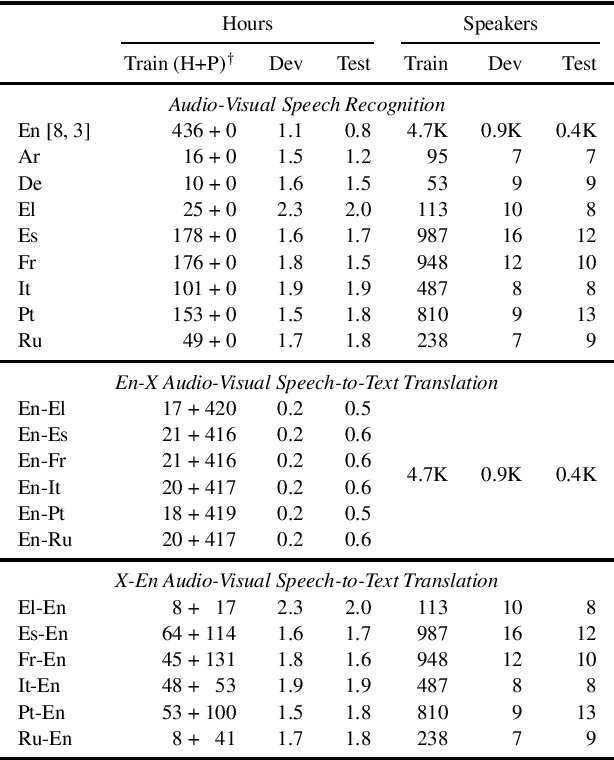
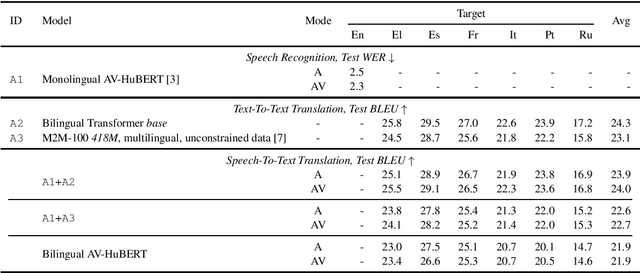

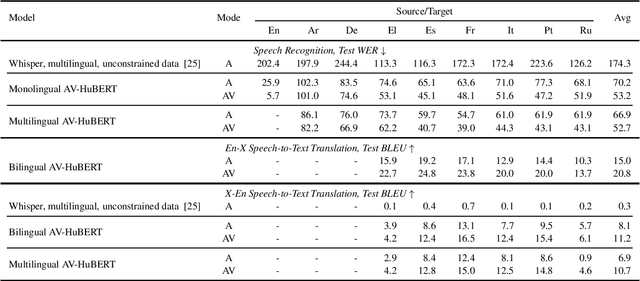
We introduce MuAViC, a multilingual audio-visual corpus for robust speech recognition and robust speech-to-text translation providing 1200 hours of audio-visual speech in 9 languages. It is fully transcribed and covers 6 English-to-X translation as well as 6 X-to-English translation directions. To the best of our knowledge, this is the first open benchmark for audio-visual speech-to-text translation and the largest open benchmark for multilingual audio-visual speech recognition. Our baseline results show that MuAViC is effective for building noise-robust speech recognition and translation models. We make the corpus available at https://github.com/facebookresearch/muavic.
A large-scale multimodal dataset of human speech recognition
Mar 15, 2023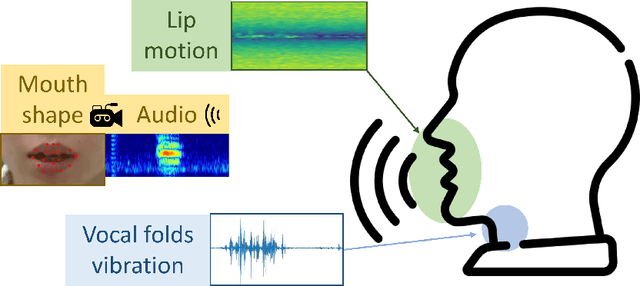

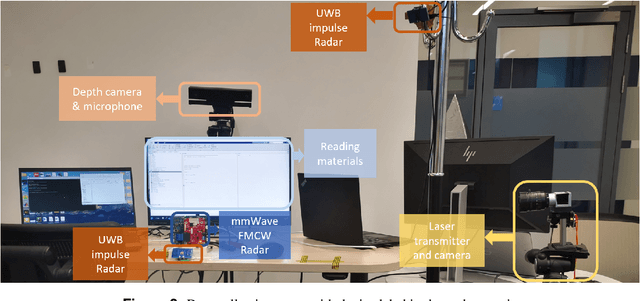
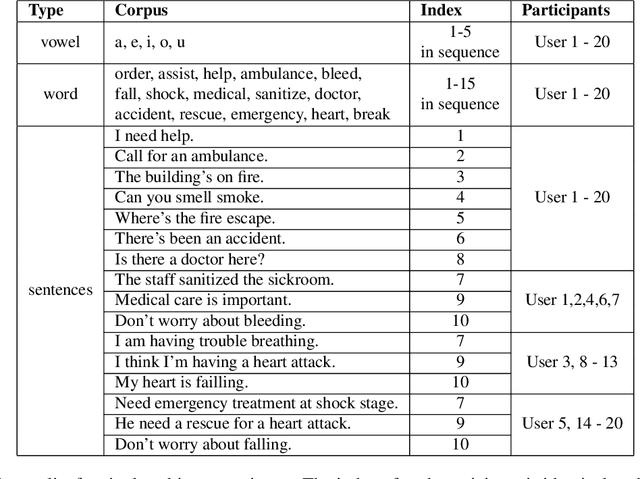
Nowadays, non-privacy small-scale motion detection has attracted an increasing amount of research in remote sensing in speech recognition. These new modalities are employed to enhance and restore speech information from speakers of multiple types of data. In this paper, we propose a dataset contains 7.5 GHz Channel Impulse Response (CIR) data from ultra-wideband (UWB) radars, 77-GHz frequency modulated continuous wave (FMCW) data from millimetre wave (mmWave) radar, and laser data. Meanwhile, a depth camera is adopted to record the landmarks of the subject's lip and voice. Approximately 400 minutes of annotated speech profiles are provided, which are collected from 20 participants speaking 5 vowels, 15 words and 16 sentences. The dataset has been validated and has potential for the research of lip reading and multimodal speech recognition.
Segmentation-Free Streaming Machine Translation
Sep 26, 2023Streaming Machine Translation (MT) is the task of translating an unbounded input text stream in real-time. The traditional cascade approach, which combines an Automatic Speech Recognition (ASR) and an MT system, relies on an intermediate segmentation step which splits the transcription stream into sentence-like units. However, the incorporation of a hard segmentation constrains the MT system and is a source of errors. This paper proposes a Segmentation-Free framework that enables the model to translate an unsegmented source stream by delaying the segmentation decision until the translation has been generated. Extensive experiments show how the proposed Segmentation-Free framework has better quality-latency trade-off than competing approaches that use an independent segmentation model. Software, data and models will be released upon paper acceptance.
Segment-Level Vectorized Beam Search Based on Partially Autoregressive Inference
Oct 01, 2023Attention-based encoder-decoder models with autoregressive (AR) decoding have proven to be the dominant approach for automatic speech recognition (ASR) due to their superior accuracy. However, they often suffer from slow inference. This is primarily attributed to the incremental calculation of the decoder. This work proposes a partially AR framework, which employs segment-level vectorized beam search for improving the inference speed of an ASR model based on the hybrid connectionist temporal classification (CTC) attention-based architecture. It first generates an initial hypothesis using greedy CTC decoding, identifying low-confidence tokens based on their output probabilities. We then utilize the decoder to perform segment-level vectorized beam search on these tokens, re-predicting in parallel with minimal decoder calculations. Experimental results show that our method is 12 to 13 times faster in inference on the LibriSpeech corpus over AR decoding whilst preserving high accuracy.
Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition
May 11, 2023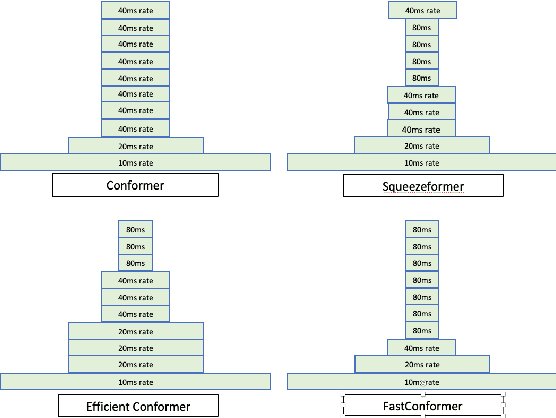

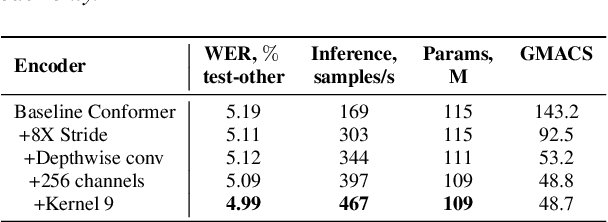

Conformer-based models have become the most dominant end-to-end architecture for speech processing tasks. In this work, we propose a carefully redesigned Conformer with a new down-sampling schema. The proposed model, named Fast Conformer, is 2.8x faster than original Conformer, while preserving state-of-the-art accuracy on Automatic Speech Recognition benchmarks. Also we replace the original Conformer global attention with limited context attention post-training to enable transcription of an hour-long audio. We further improve long-form speech transcription by adding a global token. Fast Conformer combined with a Transformer decoder also outperforms the original Conformer in accuracy and in speed for Speech Translation and Spoken Language Understanding.
Considerations for Ethical Speech Recognition Datasets
May 03, 2023Speech AI Technologies are largely trained on publicly available datasets or by the massive web-crawling of speech. In both cases, data acquisition focuses on minimizing collection effort, without necessarily taking the data subjects' protection or user needs into consideration. This results to models that are not robust when used on users who deviate from the dominant demographics in the training set, discriminating individuals having different dialects, accents, speaking styles, and disfluencies. In this talk, we use automatic speech recognition as a case study and examine the properties that ethical speech datasets should possess towards responsible AI applications. We showcase diversity issues, inclusion practices, and necessary considerations that can improve trained models, while facilitating model explainability and protecting users and data subjects. We argue for the legal & privacy protection of data subjects, targeted data sampling corresponding to user demographics & needs, appropriate meta data that ensure explainability & accountability in cases of model failure, and the sociotechnical \& situated model design. We hope this talk can inspire researchers \& practitioners to design and use more human-centric datasets in speech technologies and other domains, in ways that empower and respect users, while improving machine learning models' robustness and utility.
An Integrated Algorithm for Robust and Imperceptible Audio Adversarial Examples
Oct 05, 2023Audio adversarial examples are audio files that have been manipulated to fool an automatic speech recognition (ASR) system, while still sounding benign to a human listener. Most methods to generate such samples are based on a two-step algorithm: first, a viable adversarial audio file is produced, then, this is fine-tuned with respect to perceptibility and robustness. In this work, we present an integrated algorithm that uses psychoacoustic models and room impulse responses (RIR) in the generation step. The RIRs are dynamically created by a neural network during the generation process to simulate a physical environment to harden our examples against transformations experienced in over-the-air attacks. We compare the different approaches in three experiments: in a simulated environment and in a realistic over-the-air scenario to evaluate the robustness, and in a human study to evaluate the perceptibility. Our algorithms considering psychoacoustics only or in addition to the robustness show an improvement in the signal-to-noise ratio (SNR) as well as in the human perception study, at the cost of an increased word error rate (WER).