 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
ResidualTransformer: Residual Low-rank Learning with Weight-sharing for Transformer Layers
Oct 03, 2023
Memory constraint of always-on devices is one of the major concerns when deploying speech processing models on these devices. While larger models trained with sufficiently large amount of data generally perform better, making them fit in the device memory is a demanding challenge. In this paper, we aim to reduce model size by reparameterizing model weights across Transformer encoder layers and assuming a special weight composition and structure. More specifically, inspired by ResNet and the more recent LoRA work, we propose an approach named ResidualTransformer, where each weight matrix in a Transformer layer comprises 1) a shared full-rank component with its adjacent layers, and 2) a unique low-rank component to itself. The low-rank matrices only account for a small amount of model size increase. In addition, we add diagonal weight matrices to improve modeling capacity of the low-rank matrices. Experiments of our 10k-hour speech recognition and speech translation tasks show that the Transformer encoder size can be reduced by ~3X with very slight performance degradation.
Leveraging Multilingual Self-Supervised Pretrained Models for Sequence-to-Sequence End-to-End Spoken Language Understanding
Oct 09, 2023A number of methods have been proposed for End-to-End Spoken Language Understanding (E2E-SLU) using pretrained models, however their evaluation often lacks multilingual setup and tasks that require prediction of lexical fillers, such as slot filling. In this work, we propose a unified method that integrates multilingual pretrained speech and text models and performs E2E-SLU on six datasets in four languages in a generative manner, including the prediction of lexical fillers. We investigate how the proposed method can be improved by pretraining on widely available speech recognition data using several training objectives. Pretraining on 7000 hours of multilingual data allows us to outperform the state-of-the-art ultimately on two SLU datasets and partly on two more SLU datasets. Finally, we examine the cross-lingual capabilities of the proposed model and improve on the best known result on the PortMEDIA-Language dataset by almost half, achieving a Concept/Value Error Rate of 23.65%.
LibriSpeech-PC: Benchmark for Evaluation of Punctuation and Capitalization Capabilities of end-to-end ASR Models
Oct 04, 2023Traditional automatic speech recognition (ASR) models output lower-cased words without punctuation marks, which reduces readability and necessitates a subsequent text processing model to convert ASR transcripts into a proper format. Simultaneously, the development of end-to-end ASR models capable of predicting punctuation and capitalization presents several challenges, primarily due to limited data availability and shortcomings in the existing evaluation methods, such as inadequate assessment of punctuation prediction. In this paper, we introduce a LibriSpeech-PC benchmark designed to assess the punctuation and capitalization prediction capabilities of end-to-end ASR models. The benchmark includes a LibriSpeech-PC dataset with restored punctuation and capitalization, a novel evaluation metric called Punctuation Error Rate (PER) that focuses on punctuation marks, and initial baseline models. All code, data, and models are publicly available.
GNCformer Enhanced Self-attention for Automatic Speech Recognition
May 22, 2023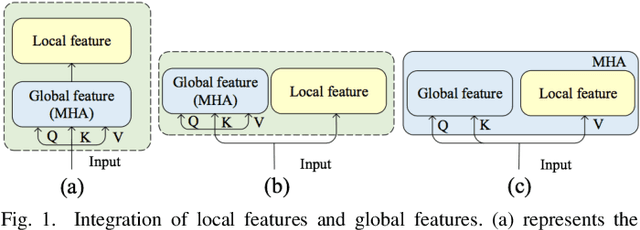
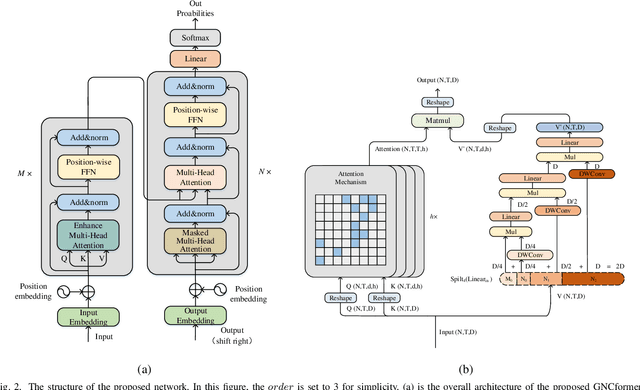
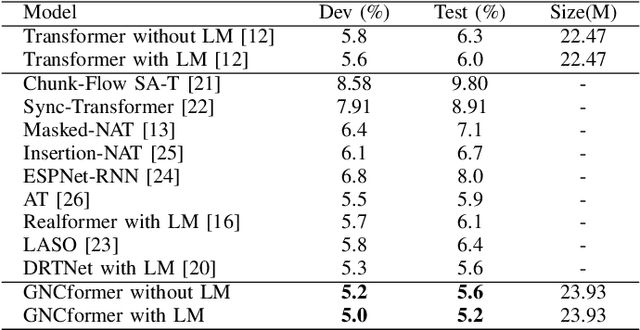

In this paper,an Enhanced Self-Attention (ESA) mechanism has been put forward for robust feature extraction.The proposed ESA is integrated with the recursive gated convolution and self-attention mechanism.In particular, the former is used to capture multi-order feature interaction and the latter is for global feature extraction.In addition, the location of interest that is suitable for inserting the ESA is also worth being explored.In this paper, the ESA is embedded into the encoder layer of the Transformer network for automatic speech recognition (ASR) tasks, and this newly proposed model is named GNCformer. The effectiveness of the GNCformer has been validated using two datasets, that are Aishell-1 and HKUST.Experimental results show that, compared with the Transformer network,0.8%CER,and 1.2%CER improvement for these two mentioned datasets, respectively, can be achieved.It is worth mentioning that only 1.4M additional parameters have been involved in our proposed GNCformer.
The Multimodal Information Based Speech Processing (MISP) 2023 Challenge: Audio-Visual Target Speaker Extraction
Sep 15, 2023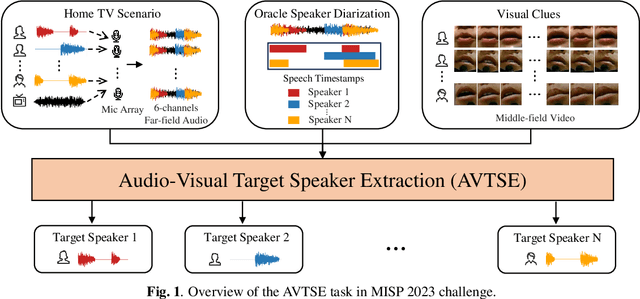
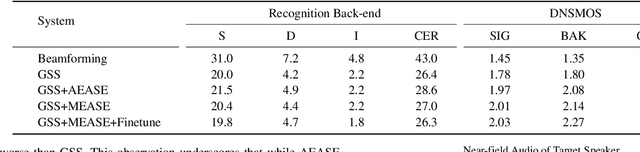
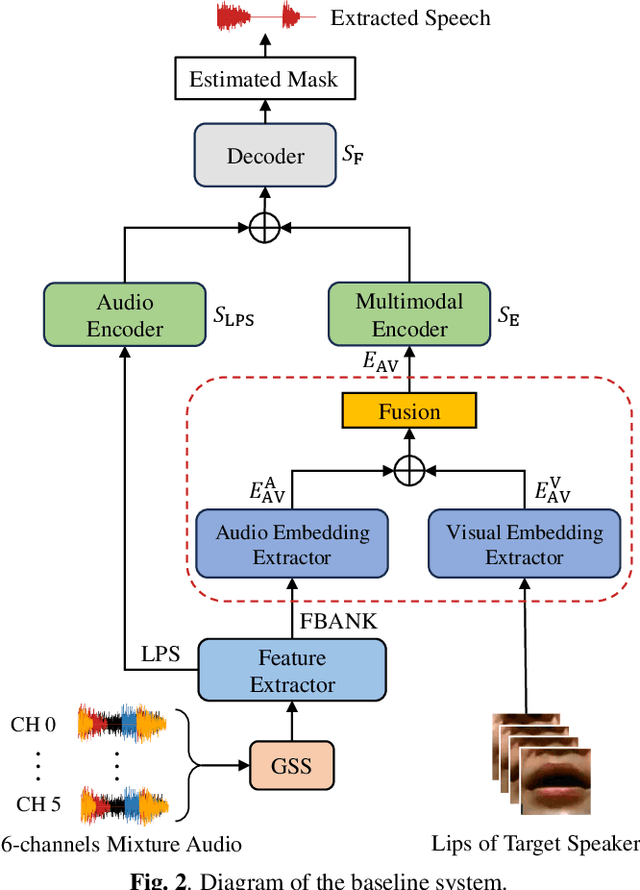
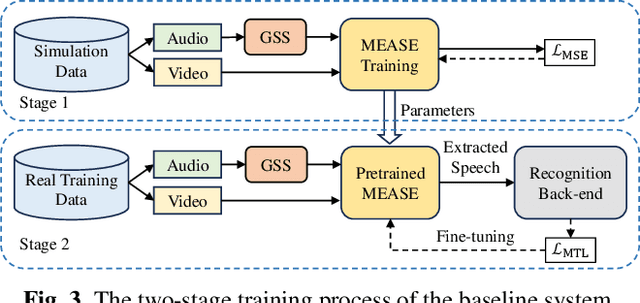
Previous Multimodal Information based Speech Processing (MISP) challenges mainly focused on audio-visual speech recognition (AVSR) with commendable success. However, the most advanced back-end recognition systems often hit performance limits due to the complex acoustic environments. This has prompted a shift in focus towards the Audio-Visual Target Speaker Extraction (AVTSE) task for the MISP 2023 challenge in ICASSP 2024 Signal Processing Grand Challenges. Unlike existing audio-visual speech enhance-ment challenges primarily focused on simulation data, the MISP 2023 challenge uniquely explores how front-end speech processing, combined with visual clues, impacts back-end tasks in real-world scenarios. This pioneering effort aims to set the first benchmark for the AVTSE task, offering fresh insights into enhancing the ac-curacy of back-end speech recognition systems through AVTSE in challenging and real acoustic environments. This paper delivers a thorough overview of the task setting, dataset, and baseline system of the MISP 2023 challenge. It also includes an in-depth analysis of the challenges participants may encounter. The experimental results highlight the demanding nature of this task, and we look forward to the innovative solutions participants will bring forward.
DecoderLens: Layerwise Interpretation of Encoder-Decoder Transformers
Oct 05, 2023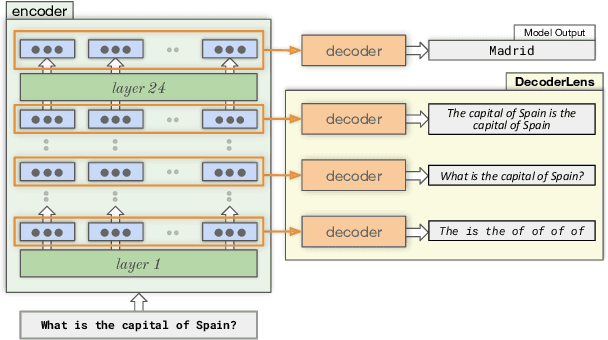
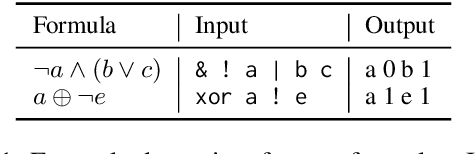
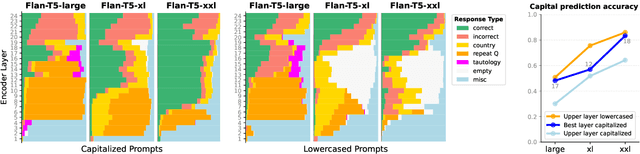

In recent years, many interpretability methods have been proposed to help interpret the internal states of Transformer-models, at different levels of precision and complexity. Here, to analyze encoder-decoder Transformers, we propose a simple, new method: DecoderLens. Inspired by the LogitLens (for decoder-only Transformers), this method involves allowing the decoder to cross-attend representations of intermediate encoder layers instead of using the final encoder output, as is normally done in encoder-decoder models. The method thus maps previously uninterpretable vector representations to human-interpretable sequences of words or symbols. We report results from the DecoderLens applied to models trained on question answering, logical reasoning, speech recognition and machine translation. The DecoderLens reveals several specific subtasks that are solved at low or intermediate layers, shedding new light on the information flow inside the encoder component of this important class of models.
Fast-HuBERT: An Efficient Training Framework for Self-Supervised Speech Representation Learning
Sep 29, 2023Recent years have witnessed significant advancements in self-supervised learning (SSL) methods for speech-processing tasks. Various speech-based SSL models have been developed and present promising performance on a range of downstream tasks including speech recognition. However, existing speech-based SSL models face a common dilemma in terms of computational cost, which might hinder their potential application and in-depth academic research. To address this issue, we first analyze the computational cost of different modules during HuBERT pre-training and then introduce a stack of efficiency optimizations, which is named Fast-HuBERT in this paper. The proposed Fast-HuBERT can be trained in 1.1 days with 8 V100 GPUs on the Librispeech 960h benchmark, without performance degradation, resulting in a 5.2x speedup, compared to the original implementation. Moreover, we explore two well-studied techniques in the Fast-HuBERT and demonstrate consistent improvements as reported in previous work.
Adapting the adapters for code-switching in multilingual ASR
Oct 11, 2023Recently, large pre-trained multilingual speech models have shown potential in scaling Automatic Speech Recognition (ASR) to many low-resource languages. Some of these models employ language adapters in their formulation, which helps to improve monolingual performance and avoids some of the drawbacks of multi-lingual modeling on resource-rich languages. However, this formulation restricts the usability of these models on code-switched speech, where two languages are mixed together in the same utterance. In this work, we propose ways to effectively fine-tune such models on code-switched speech, by assimilating information from both language adapters at each language adaptation point in the network. We also model code-switching as a sequence of latent binary sequences that can be used to guide the flow of information from each language adapter at the frame level. The proposed approaches are evaluated on three code-switched datasets encompassing Arabic, Mandarin, and Hindi languages paired with English, showing consistent improvements in code-switching performance with at least 10\% absolute reduction in CER across all test sets.
Improving End-to-End Speech Processing by Efficient Text Data Utilization with Latent Synthesis
Oct 16, 2023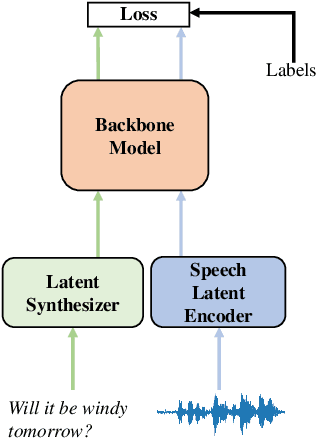
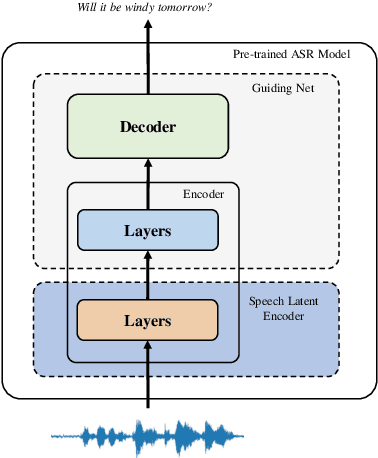

Training a high performance end-to-end speech (E2E) processing model requires an enormous amount of labeled speech data, especially in the era of data-centric artificial intelligence. However, labeled speech data are usually scarcer and more expensive for collection, compared to textual data. We propose Latent Synthesis (LaSyn), an efficient textual data utilization framework for E2E speech processing models. We train a latent synthesizer to convert textual data into an intermediate latent representation of a pre-trained speech model. These pseudo acoustic representations of textual data augment acoustic data for model training. We evaluate LaSyn on low-resource automatic speech recognition (ASR) and spoken language understanding (SLU) tasks. For ASR, LaSyn improves an E2E baseline trained on LibriSpeech train-clean-100, with relative word error rate reductions over 22.3% on different test sets. For SLU, LaSyn improves our E2E baseline by absolute 4.1% for intent classification accuracy and 3.8% for slot filling SLU-F1 on SLURP, and absolute 4.49% and 2.25% for exact match (EM) and EM-Tree accuracies on STOP respectively. With fewer parameters, the results of LaSyn are competitive to published state-of-the-art works. The results demonstrate the quality of the augmented training data. The source code will be available to the community.
Detecting Speech Abnormalities with a Perceiver-based Sequence Classifier that Leverages a Universal Speech Model
Oct 16, 2023We propose a Perceiver-based sequence classifier to detect abnormalities in speech reflective of several neurological disorders. We combine this classifier with a Universal Speech Model (USM) that is trained (unsupervised) on 12 million hours of diverse audio recordings. Our model compresses long sequences into a small set of class-specific latent representations and a factorized projection is used to predict different attributes of the disordered input speech. The benefit of our approach is that it allows us to model different regions of the input for different classes and is at the same time data efficient. We evaluated the proposed model extensively on a curated corpus from the Mayo Clinic. Our model outperforms standard transformer (80.9%) and perceiver (81.8%) models and achieves an average accuracy of 83.1%. With limited task-specific data, we find that pretraining is important and surprisingly pretraining with the unrelated automatic speech recognition (ASR) task is also beneficial. Encodings from the middle layers provide a mix of both acoustic and phonetic information and achieve best prediction results compared to just using the final layer encodings (83.1% vs. 79.6%). The results are promising and with further refinements may help clinicians detect speech abnormalities without needing access to highly specialized speech-language pathologists.