 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Foundation Model Assisted Automatic Speech Emotion Recognition: Transcribing, Annotating, and Augmenting
Sep 15, 2023
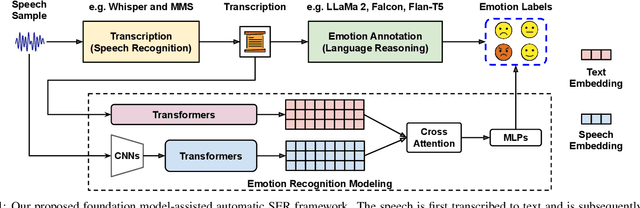
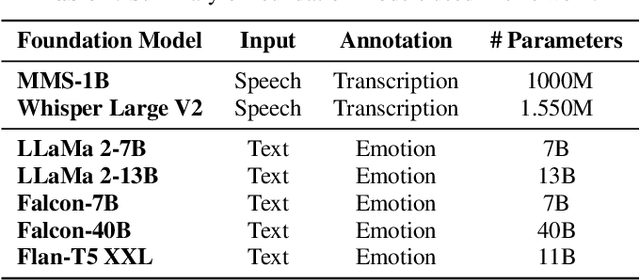
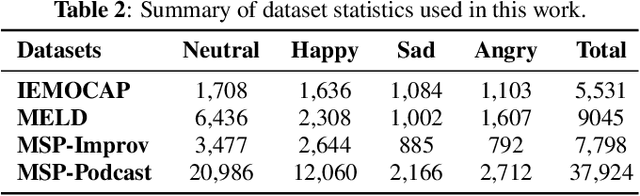
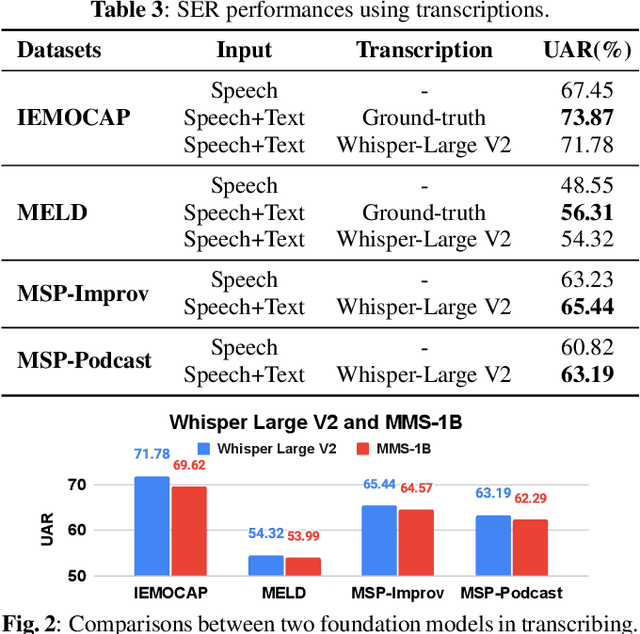
Significant advances are being made in speech emotion recognition (SER) using deep learning models. Nonetheless, training SER systems remains challenging, requiring both time and costly resources. Like many other machine learning tasks, acquiring datasets for SER requires substantial data annotation efforts, including transcription and labeling. These annotation processes present challenges when attempting to scale up conventional SER systems. Recent developments in foundational models have had a tremendous impact, giving rise to applications such as ChatGPT. These models have enhanced human-computer interactions including bringing unique possibilities for streamlining data collection in fields like SER. In this research, we explore the use of foundational models to assist in automating SER from transcription and annotation to augmentation. Our study demonstrates that these models can generate transcriptions to enhance the performance of SER systems that rely solely on speech data. Furthermore, we note that annotating emotions from transcribed speech remains a challenging task. However, combining outputs from multiple LLMs enhances the quality of annotations. Lastly, our findings suggest the feasibility of augmenting existing speech emotion datasets by annotating unlabeled speech samples.
Can Whisper perform speech-based in-context learning
Sep 13, 2023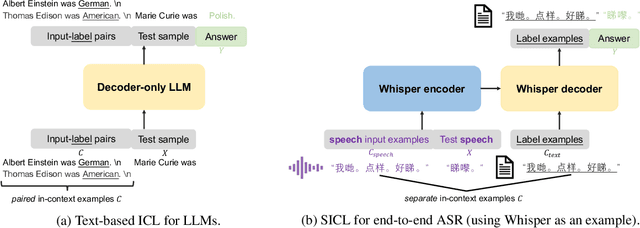
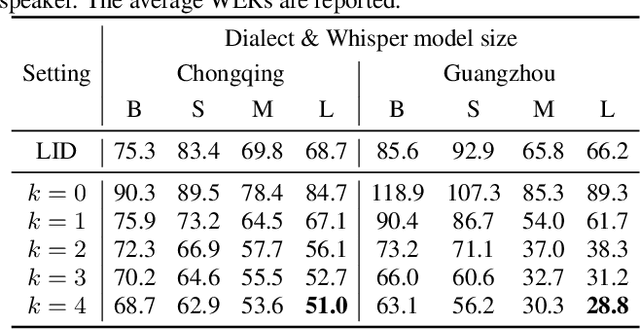
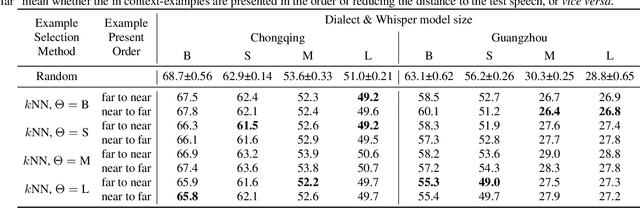
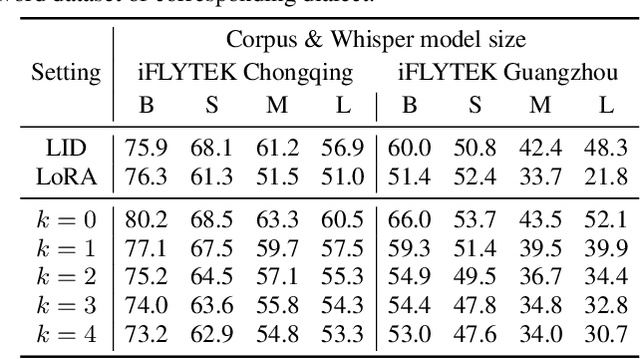
This paper investigates the in-context learning abilities of the Whisper automatic speech recognition (ASR) models released by OpenAI. A novel speech-based in-context learning (SICL) approach is proposed for test-time adaptation, which can reduce the word error rates (WERs) with only a small number of labelled speech samples without gradient descent. Language-level adaptation experiments using Chinese dialects showed that when applying SICL to isolated word ASR, consistent and considerable relative WER reductions can be achieved using Whisper models of any size on two dialects, which is on average 32.3%. A k-nearest-neighbours-based in-context example selection technique can be applied to further improve the efficiency of SICL, which can increase the average relative WER reduction to 36.4%. The findings are verified using speaker adaptation or continuous speech recognition tasks, and both achieved considerable relative WER reductions. Detailed quantitative analyses are also provided to shed light on SICL's adaptability to phonological variances and dialect-specific lexical nuances.
ed-cec: improving rare word recognition using asr postprocessing based on error detection and context-aware error correction
Oct 08, 2023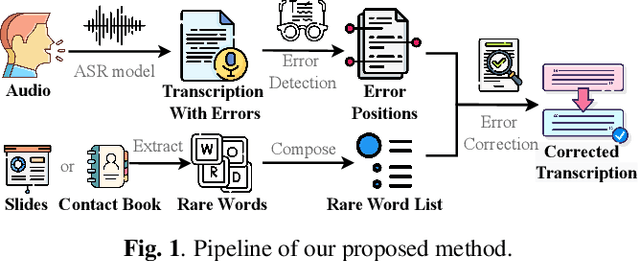
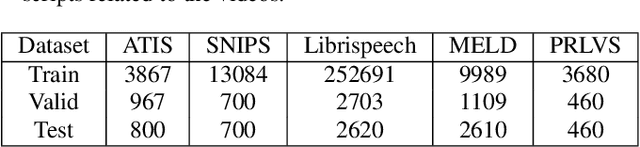
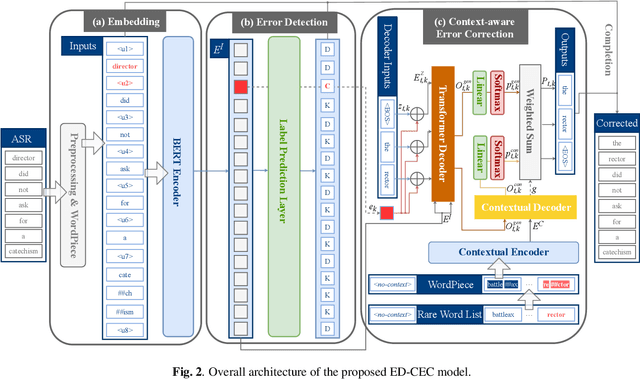
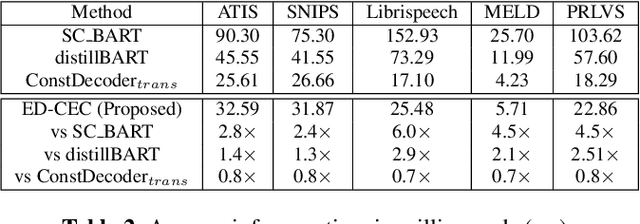
Automatic speech recognition (ASR) systems often encounter difficulties in accurately recognizing rare words, leading to errors that can have a negative impact on downstream tasks such as keyword spotting, intent detection, and text summarization. To address this challenge, we present a novel ASR postprocessing method that focuses on improving the recognition of rare words through error detection and context-aware error correction. Our method optimizes the decoding process by targeting only the predicted error positions, minimizing unnecessary computations. Moreover, we leverage a rare word list to provide additional contextual knowledge, enabling the model to better correct rare words. Experimental results across five datasets demonstrate that our proposed method achieves significantly lower word error rates (WERs) than previous approaches while maintaining a reasonable inference speed. Furthermore, our approach exhibits promising robustness across different ASR systems.
HypR: A comprehensive study for ASR hypothesis revising with a reference corpus
Sep 19, 2023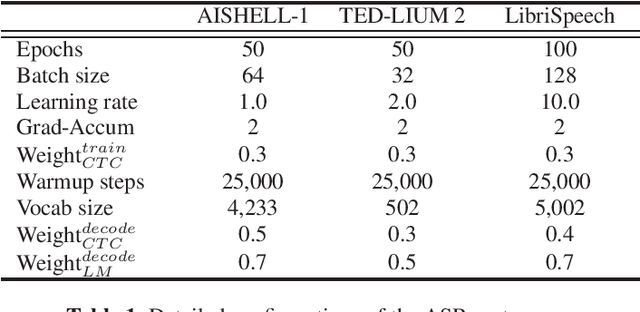
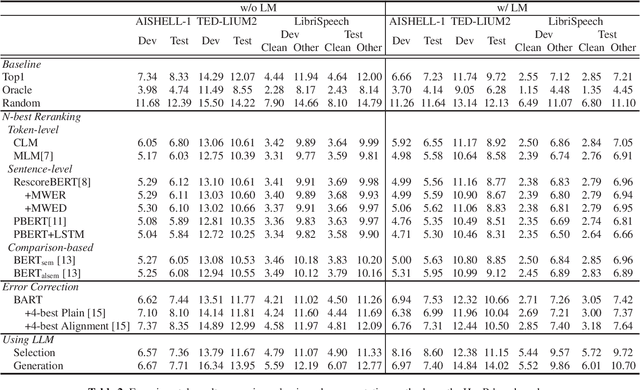
With the development of deep learning, automatic speech recognition (ASR) has made significant progress. To further enhance the performance, revising recognition results is one of the lightweight but efficient manners. Various methods can be roughly classified into N-best reranking methods and error correction models. The former aims to select the hypothesis with the lowest error rate from a set of candidates generated by ASR for a given input speech. The latter focuses on detecting recognition errors in a given hypothesis and correcting these errors to obtain an enhanced result. However, we observe that these studies are hardly comparable to each other as they are usually evaluated on different corpora, paired with different ASR models, and even use different datasets to train the models. Accordingly, we first concentrate on releasing an ASR hypothesis revising (HypR) dataset in this study. HypR contains several commonly used corpora (AISHELL-1, TED-LIUM 2, and LibriSpeech) and provides 50 recognition hypotheses for each speech utterance. The checkpoint models of the ASR are also published. In addition, we implement and compare several classic and representative methods, showing the recent research progress in revising speech recognition results. We hope the publicly available HypR dataset can become a reference benchmark for subsequent research and promote the school of research to an advanced level.
Federated Self-Learning with Weak Supervision for Speech Recognition
Jun 21, 2023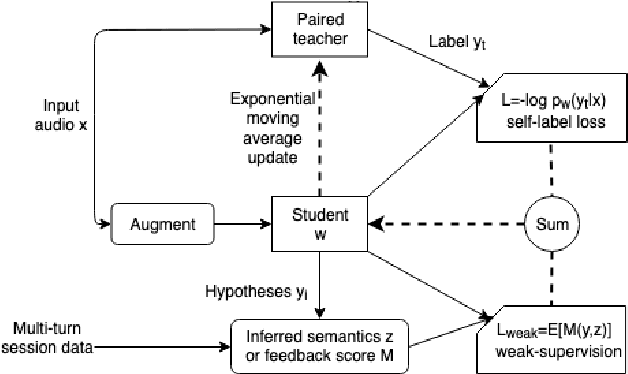
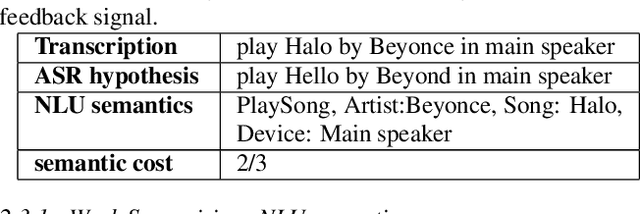
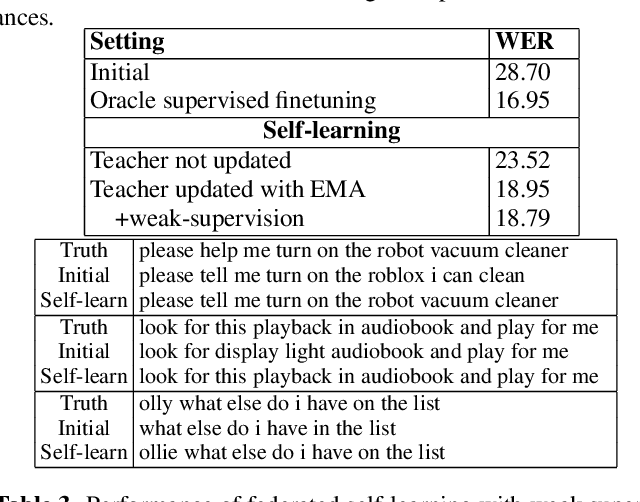
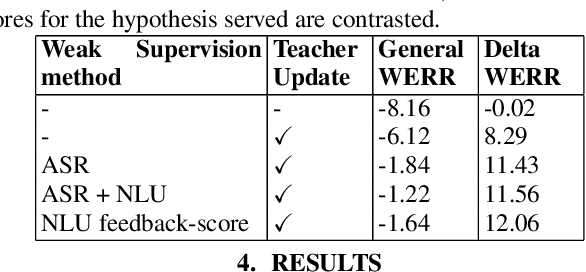
Automatic speech recognition (ASR) models with low-footprint are increasingly being deployed on edge devices for conversational agents, which enhances privacy. We study the problem of federated continual incremental learning for recurrent neural network-transducer (RNN-T) ASR models in the privacy-enhancing scheme of learning on-device, without access to ground truth human transcripts or machine transcriptions from a stronger ASR model. In particular, we study the performance of a self-learning based scheme, with a paired teacher model updated through an exponential moving average of ASR models. Further, we propose using possibly noisy weak-supervision signals such as feedback scores and natural language understanding semantics determined from user behavior across multiple turns in a session of interactions with the conversational agent. These signals are leveraged in a multi-task policy-gradient training approach to improve the performance of self-learning for ASR. Finally, we show how catastrophic forgetting can be mitigated by combining on-device learning with a memory-replay approach using selected historical datasets. These innovations allow for 10% relative improvement in WER on new use cases with minimal degradation on other test sets in the absence of strong-supervision signals such as ground-truth transcriptions.
Multi-Head State Space Model for Speech Recognition
May 25, 2023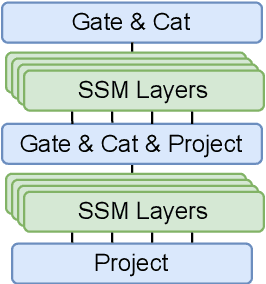
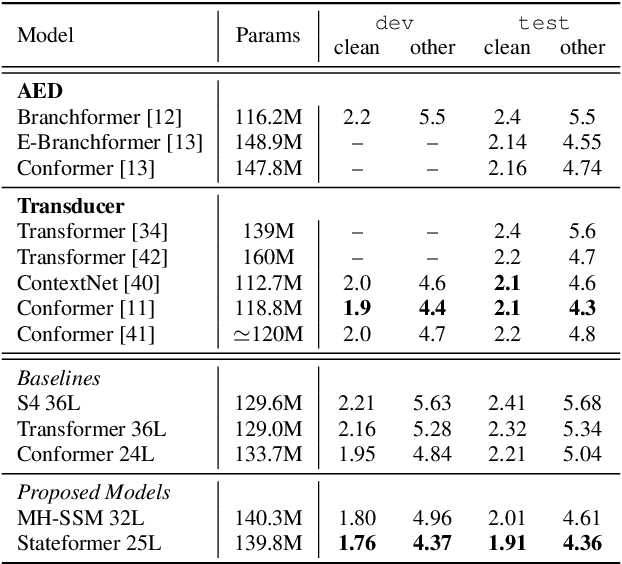
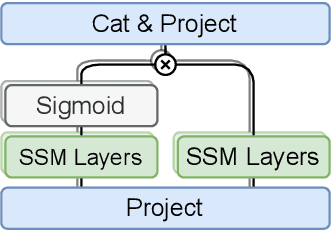
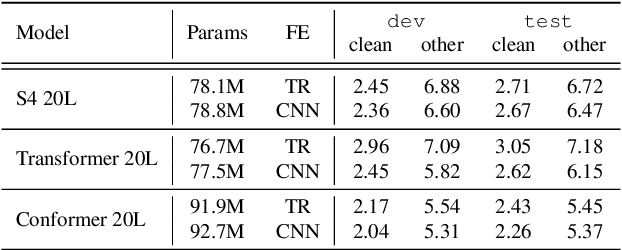
State space models (SSMs) have recently shown promising results on small-scale sequence and language modelling tasks, rivalling and outperforming many attention-based approaches. In this paper, we propose a multi-head state space (MH-SSM) architecture equipped with special gating mechanisms, where parallel heads are taught to learn local and global temporal dynamics on sequence data. As a drop-in replacement for multi-head attention in transformer encoders, this new model significantly outperforms the transformer transducer on the LibriSpeech speech recognition corpus. Furthermore, we augment the transformer block with MH-SSMs layers, referred to as the Stateformer, achieving state-of-the-art performance on the LibriSpeech task, with word error rates of 1.76\%/4.37\% on the development and 1.91\%/4.36\% on the test sets without using an external language model.
Prompting Large Language Models for Zero-Shot Domain Adaptation in Speech Recognition
Jun 28, 2023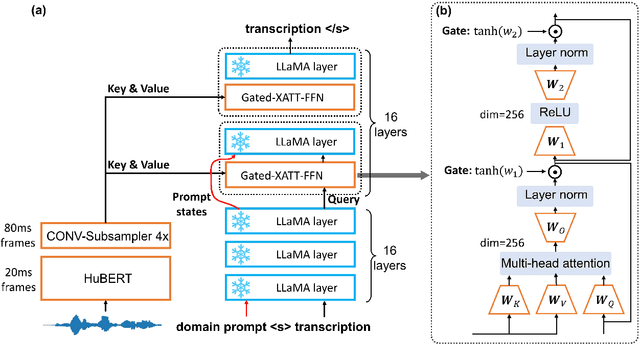
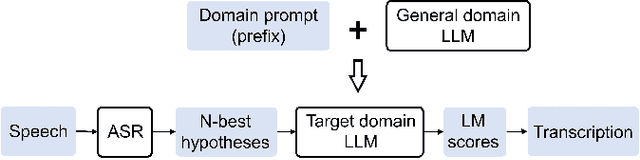
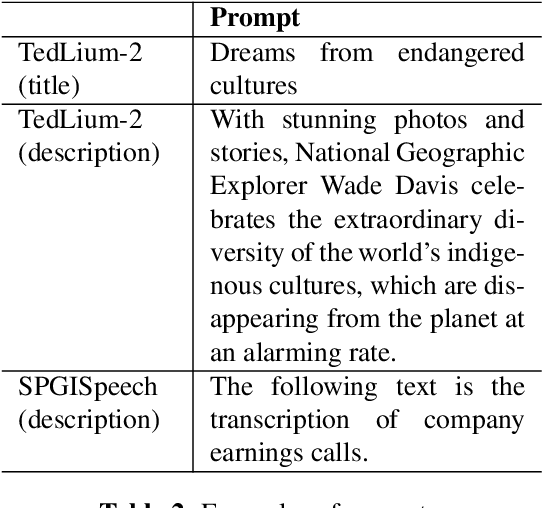
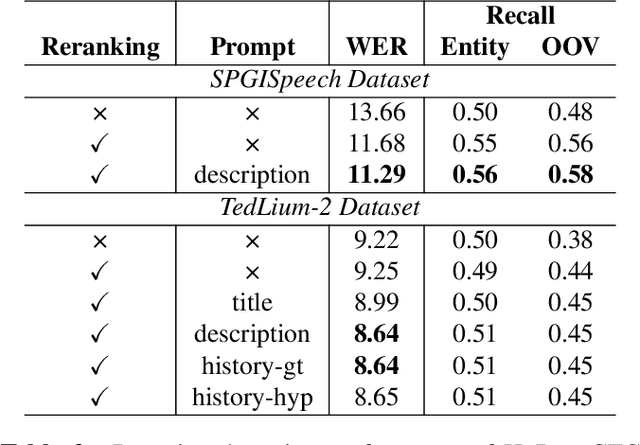
The integration of Language Models (LMs) has proven to be an effective way to address domain shifts in speech recognition. However, these approaches usually require a significant amount of target domain text data for the training of LMs. Different from these methods, in this work, with only a domain-specific text prompt, we propose two zero-shot ASR domain adaptation methods using LLaMA, a 7-billion-parameter large language model (LLM). LLM is used in two ways: 1) second-pass rescoring: reranking N-best hypotheses of a given ASR system with LLaMA; 2) deep LLM-fusion: incorporating LLM into the decoder of an encoder-decoder based ASR system. Experiments show that, with only one domain prompt, both methods can effectively reduce word error rates (WER) on out-of-domain TedLium-2 and SPGISpeech datasets. Especially, the deep LLM-fusion has the advantage of better recall of entity and out-of-vocabulary words.
An Effective Transformer-based Contextual Model and Temporal Gate Pooling for Speaker Identification
Sep 10, 2023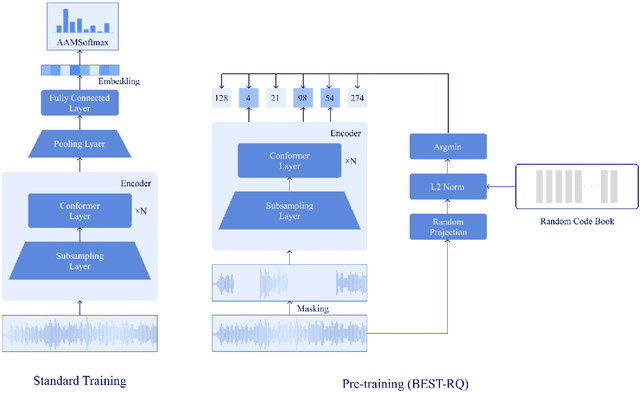
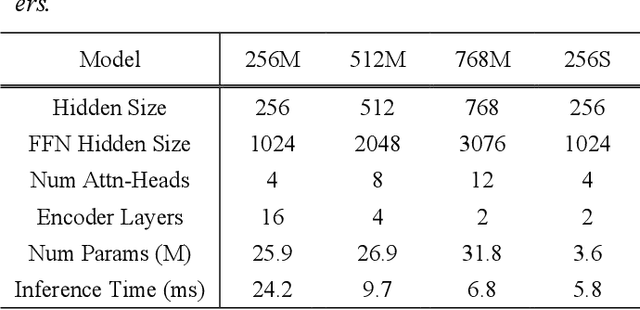
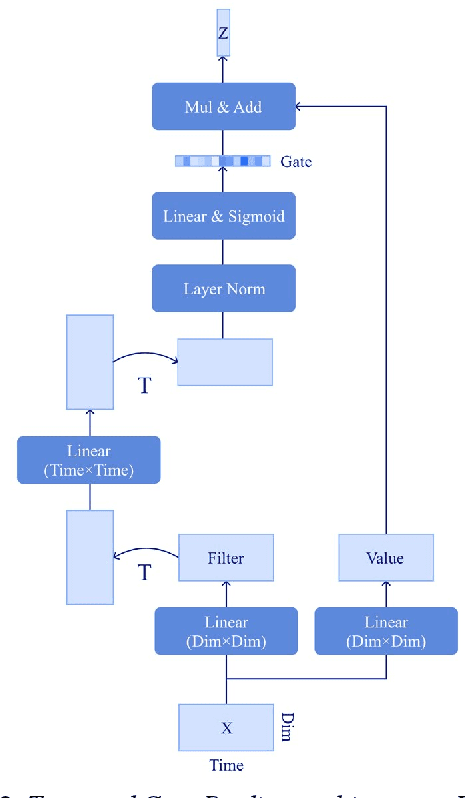
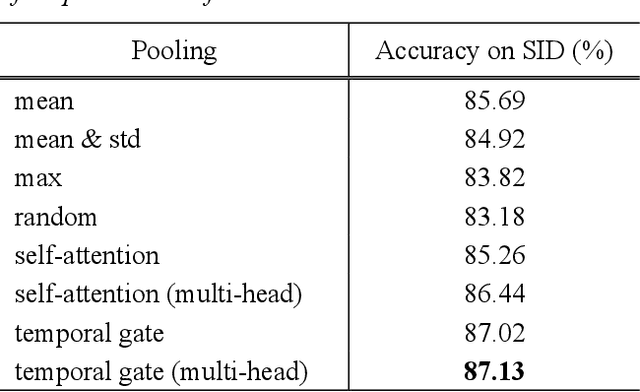
Wav2vec2 has achieved success in applying Transformer architecture and self-supervised learning to speech recognition. Recently, these have come to be used not only for speech recognition but also for the entire speech processing. This paper introduces an effective end-to-end speaker identification model applied Transformer-based contextual model. We explored the relationship between the hyper-parameters and the performance in order to discern the structure of an effective model. Furthermore, we propose a pooling method, Temporal Gate Pooling, with powerful learning ability for speaker identification. We applied Conformer as encoder and BEST-RQ for pre-training and conducted an evaluation utilizing the speaker identification of VoxCeleb1. The proposed method has achieved an accuracy of 87.1% with 28.5M parameters, demonstrating comparable precision to wav2vec2 with 317.7M parameters. Code is available at https://github.com/HarunoriKawano/speaker-identification-with-tgp.
Bypass Temporal Classification: Weakly Supervised Automatic Speech Recognition with Imperfect Transcripts
Jun 01, 2023
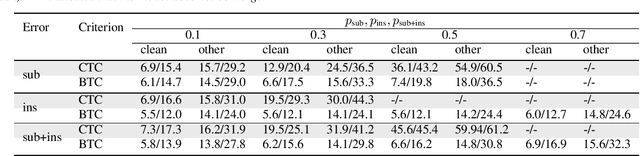
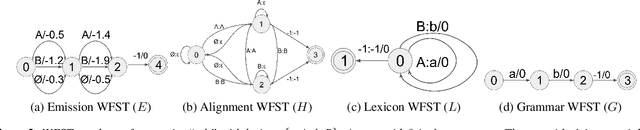
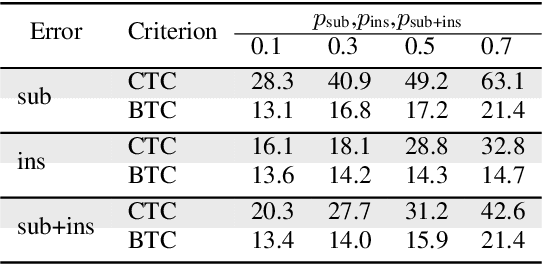
This paper presents a novel algorithm for building an automatic speech recognition (ASR) model with imperfect training data. Imperfectly transcribed speech is a prevalent issue in human-annotated speech corpora, which degrades the performance of ASR models. To address this problem, we propose Bypass Temporal Classification (BTC) as an expansion of the Connectionist Temporal Classification (CTC) criterion. BTC explicitly encodes the uncertainties associated with transcripts during training. This is accomplished by enhancing the flexibility of the training graph, which is implemented as a weighted finite-state transducer (WFST) composition. The proposed algorithm improves the robustness and accuracy of ASR systems, particularly when working with imprecisely transcribed speech corpora. Our implementation will be open-sourced.
Iteratively Improving Speech Recognition and Voice Conversion
May 24, 2023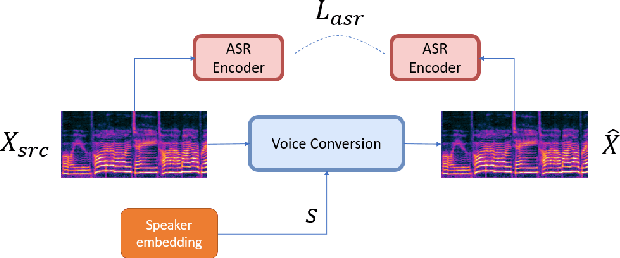
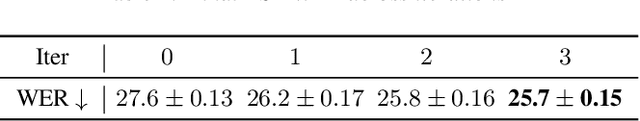
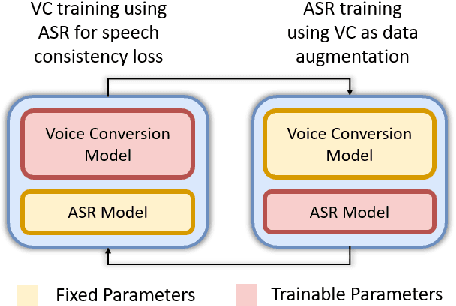
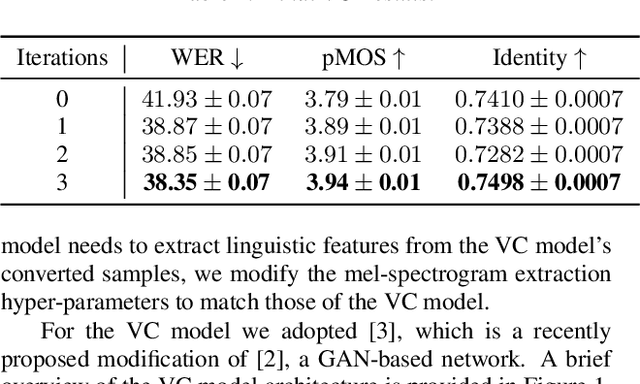
Many existing works on voice conversion (VC) tasks use automatic speech recognition (ASR) models for ensuring linguistic consistency between source and converted samples. However, for the low-data resource domains, training a high-quality ASR remains to be a challenging task. In this work, we propose a novel iterative way of improving both the ASR and VC models. We first train an ASR model which is used to ensure content preservation while training a VC model. In the next iteration, the VC model is used as a data augmentation method to further fine-tune the ASR model and generalize it to diverse speakers. By iteratively leveraging the improved ASR model to train VC model and vice-versa, we experimentally show improvement in both the models. Our proposed framework outperforms the ASR and one-shot VC baseline models on English singing and Hindi speech domains in subjective and objective evaluations in low-data resource settings.