 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Incorporating L2 Phonemes Using Articulatory Features for Robust Speech Recognition
Jun 05, 2023
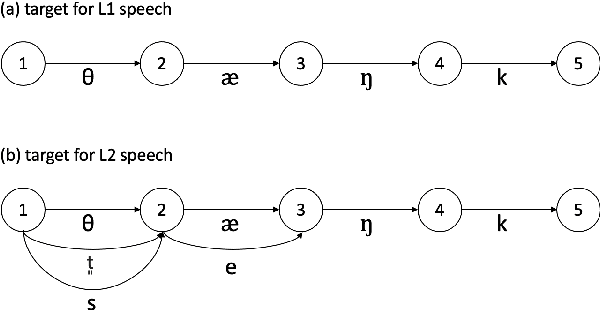



The limited availability of non-native speech datasets presents a major challenge in automatic speech recognition (ASR) to narrow the performance gap between native and non-native speakers. To address this, the focus of this study is on the efficient incorporation of the L2 phonemes, which in this work refer to Korean phonemes, through articulatory feature analysis. This not only enables accurate modeling of pronunciation variants but also allows for the utilization of both native Korean and English speech datasets. We employ the lattice-free maximum mutual information (LF-MMI) objective in an end-to-end manner, to train the acoustic model to align and predict one of multiple pronunciation candidates. Experimental results show that the proposed method improves ASR accuracy for Korean L2 speech by training solely on L1 speech data. Furthermore, fine-tuning on L2 speech improves recognition accuracy for both L1 and L2 speech without performance trade-offs.
Modality Dropout for Multimodal Device Directed Speech Detection using Verbal and Non-Verbal Features
Oct 23, 2023Device-directed speech detection (DDSD) is the binary classification task of distinguishing between queries directed at a voice assistant versus side conversation or background speech. State-of-the-art DDSD systems use verbal cues, e.g acoustic, text and/or automatic speech recognition system (ASR) features, to classify speech as device-directed or otherwise, and often have to contend with one or more of these modalities being unavailable when deployed in real-world settings. In this paper, we investigate fusion schemes for DDSD systems that can be made more robust to missing modalities. Concurrently, we study the use of non-verbal cues, specifically prosody features, in addition to verbal cues for DDSD. We present different approaches to combine scores and embeddings from prosody with the corresponding verbal cues, finding that prosody improves DDSD performance by upto 8.5% in terms of false acceptance rate (FA) at a given fixed operating point via non-linear intermediate fusion, while our use of modality dropout techniques improves the performance of these models by 7.4% in terms of FA when evaluated with missing modalities during inference time.
Distillation Strategies for Discriminative Speech Recognition Rescoring
Jun 15, 2023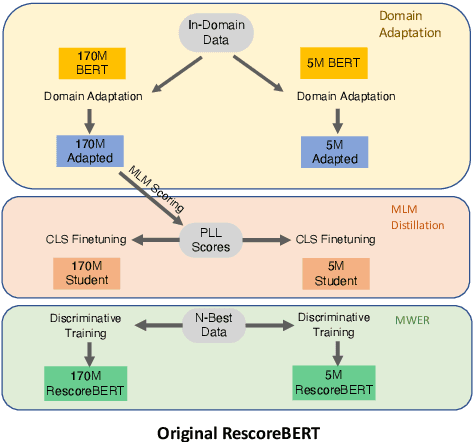
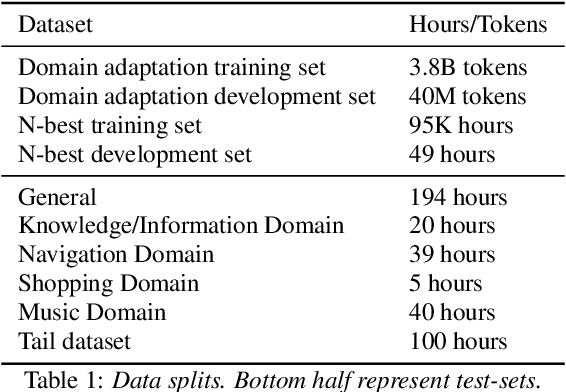
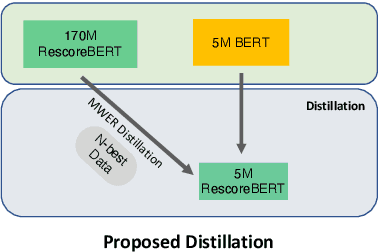
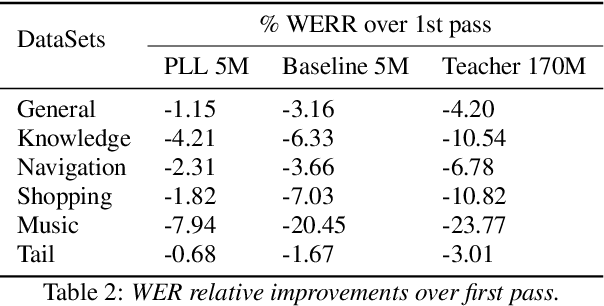
Second-pass rescoring is employed in most state-of-the-art speech recognition systems. Recently, BERT based models have gained popularity for re-ranking the n-best hypothesis by exploiting the knowledge from masked language model pre-training. Further, fine-tuning with discriminative loss such as minimum word error rate (MWER) has shown to perform better than likelihood-based loss. Streaming applications with low latency requirements impose significant constraints on the size of the models, thereby limiting the word error rate (WER) performance gains. In this paper, we propose effective strategies for distilling from large models discriminatively trained with the MWER objective. We experiment on Librispeech and production scale internal dataset for voice-assistant. Our results demonstrate relative improvements of upto 7% WER over student models trained with MWER. We also show that the proposed distillation can reduce the WER gap between the student and the teacher by 62% upto 100%.
Integration of Frame- and Label-synchronous Beam Search for Streaming Encoder-decoder Speech Recognition
Jul 24, 2023Although frame-based models, such as CTC and transducers, have an affinity for streaming automatic speech recognition, their decoding uses no future knowledge, which could lead to incorrect pruning. Conversely, label-based attention encoder-decoder mitigates this issue using soft attention to the input, while it tends to overestimate labels biased towards its training domain, unlike CTC. We exploit these complementary attributes and propose to integrate the frame- and label-synchronous (F-/L-Sync) decoding alternately performed within a single beam-search scheme. F-Sync decoding leads the decoding for block-wise processing, while L-Sync decoding provides the prioritized hypotheses using look-ahead future frames within a block. We maintain the hypotheses from both decoding methods to perform effective pruning. Experiments demonstrate that the proposed search algorithm achieves lower error rates compared to the other search methods, while being robust against out-of-domain situations.
Unified Segment-to-Segment Framework for Simultaneous Sequence Generation
Oct 27, 2023Simultaneous sequence generation is a pivotal task for real-time scenarios, such as streaming speech recognition, simultaneous machine translation and simultaneous speech translation, where the target sequence is generated while receiving the source sequence. The crux of achieving high-quality generation with low latency lies in identifying the optimal moments for generating, accomplished by learning a mapping between the source and target sequences. However, existing methods often rely on task-specific heuristics for different sequence types, limiting the model's capacity to adaptively learn the source-target mapping and hindering the exploration of multi-task learning for various simultaneous tasks. In this paper, we propose a unified segment-to-segment framework (Seg2Seg) for simultaneous sequence generation, which learns the mapping in an adaptive and unified manner. During the process of simultaneous generation, the model alternates between waiting for a source segment and generating a target segment, making the segment serve as the natural bridge between the source and target. To accomplish this, Seg2Seg introduces a latent segment as the pivot between source to target and explores all potential source-target mappings via the proposed expectation training, thereby learning the optimal moments for generating. Experiments on multiple simultaneous generation tasks demonstrate that Seg2Seg achieves state-of-the-art performance and exhibits better generality across various tasks.
SlideSpeech: A Large-Scale Slide-Enriched Audio-Visual Corpus
Sep 12, 2023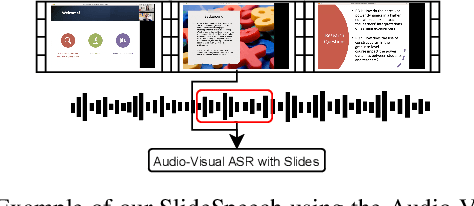
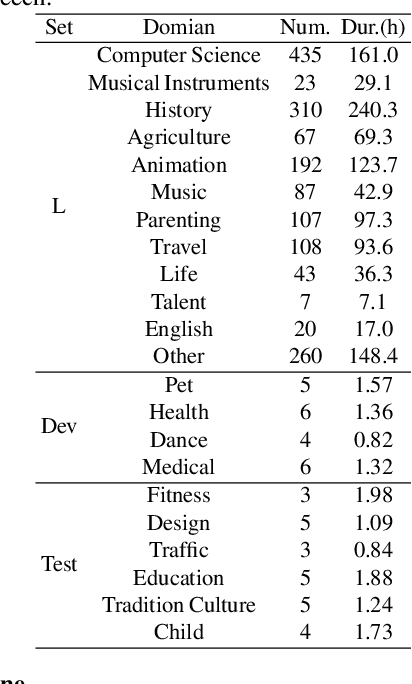
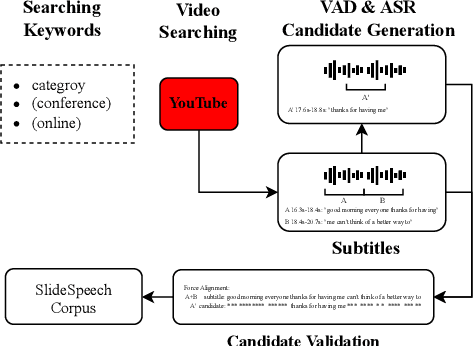

Multi-Modal automatic speech recognition (ASR) techniques aim to leverage additional modalities to improve the performance of speech recognition systems. While existing approaches primarily focus on video or contextual information, the utilization of extra supplementary textual information has been overlooked. Recognizing the abundance of online conference videos with slides, which provide rich domain-specific information in the form of text and images, we release SlideSpeech, a large-scale audio-visual corpus enriched with slides. The corpus contains 1,705 videos, 1,000+ hours, with 473 hours of high-quality transcribed speech. Moreover, the corpus contains a significant amount of real-time synchronized slides. In this work, we present the pipeline for constructing the corpus and propose baseline methods for utilizing text information in the visual slide context. Through the application of keyword extraction and contextual ASR methods in the benchmark system, we demonstrate the potential of improving speech recognition performance by incorporating textual information from supplementary video slides.
The North System for Formosa Speech Recognition Challenge 2023
Oct 06, 2023This report provides a concise overview of the proposed North system, which aims to achieve automatic word/syllable recognition for Taiwanese Hakka (Sixian). The report outlines three key components of the system: the acquisition, composition, and utilization of the training data; the architecture of the model; and the hardware specifications and operational statistics. The demonstration of the system has been made public at https://asrvm.iis.sinica.edu.tw/hakka_sixian.
Unsupervised Representations Improve Supervised Learning in Speech Emotion Recognition
Sep 22, 2023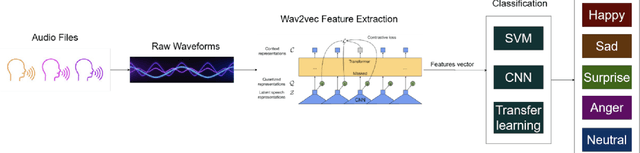

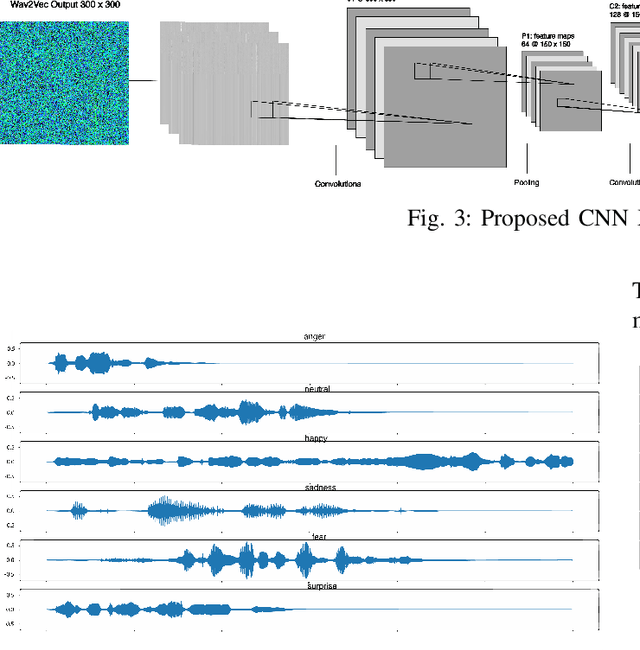
Speech Emotion Recognition (SER) plays a pivotal role in enhancing human-computer interaction by enabling a deeper understanding of emotional states across a wide range of applications, contributing to more empathetic and effective communication. This study proposes an innovative approach that integrates self-supervised feature extraction with supervised classification for emotion recognition from small audio segments. In the preprocessing step, to eliminate the need of crafting audio features, we employed a self-supervised feature extractor, based on the Wav2Vec model, to capture acoustic features from audio data. Then, the output featuremaps of the preprocessing step are fed to a custom designed Convolutional Neural Network (CNN)-based model to perform emotion classification. Utilizing the ShEMO dataset as our testing ground, the proposed method surpasses two baseline methods, i.e. support vector machine classifier and transfer learning of a pretrained CNN. comparing the propose method to the state-of-the-art methods in SER task indicates the superiority of the proposed method. Our findings underscore the pivotal role of deep unsupervised feature learning in elevating the landscape of SER, offering enhanced emotional comprehension in the realm of human-computer interactions.
Leveraging Speech PTM, Text LLM, and Emotional TTS for Speech Emotion Recognition
Sep 19, 2023
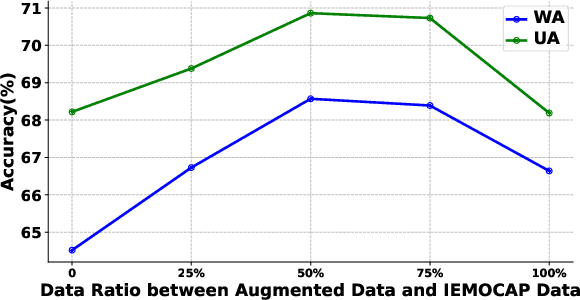
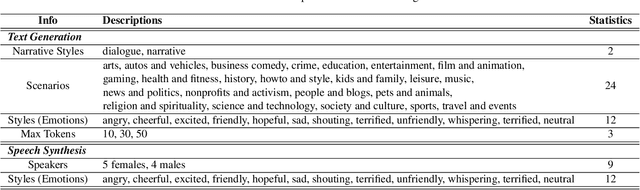
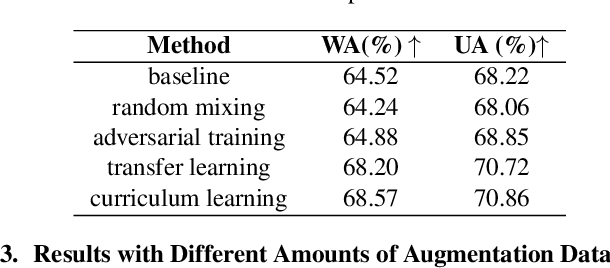
In this paper, we explored how to boost speech emotion recognition (SER) with the state-of-the-art speech pre-trained model (PTM), data2vec, text generation technique, GPT-4, and speech synthesis technique, Azure TTS. First, we investigated the representation ability of different speech self-supervised pre-trained models, and we found that data2vec has a good representation ability on the SER task. Second, we employed a powerful large language model (LLM), GPT-4, and emotional text-to-speech (TTS) model, Azure TTS, to generate emotionally congruent text and speech. We carefully designed the text prompt and dataset construction, to obtain the synthetic emotional speech data with high quality. Third, we studied different ways of data augmentation to promote the SER task with synthetic speech, including random mixing, adversarial training, transfer learning, and curriculum learning. Experiments and ablation studies on the IEMOCAP dataset demonstrate the effectiveness of our method, compared with other data augmentation methods, and data augmentation with other synthetic data.
CL-MASR: A Continual Learning Benchmark for Multilingual ASR
Oct 25, 2023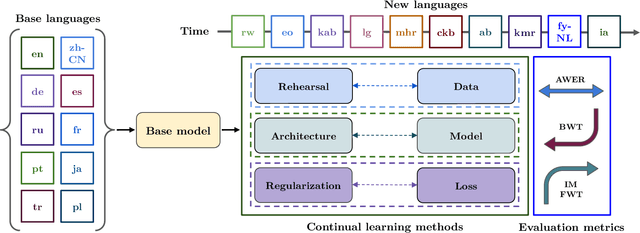
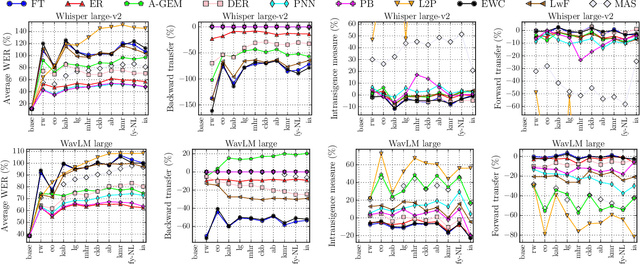
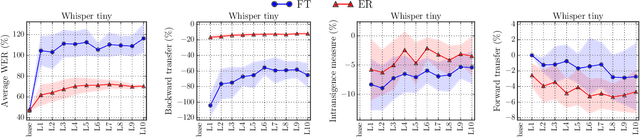
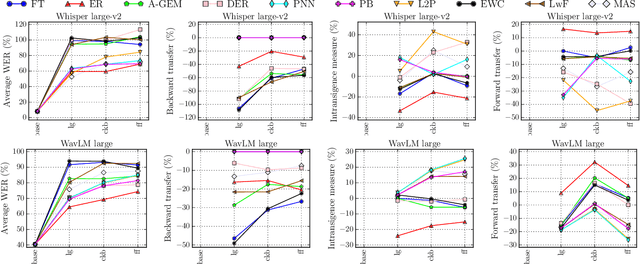
Modern multilingual automatic speech recognition (ASR) systems like Whisper have made it possible to transcribe audio in multiple languages with a single model. However, current state-of-the-art ASR models are typically evaluated on individual languages or in a multi-task setting, overlooking the challenge of continually learning new languages. There is insufficient research on how to add new languages without losing valuable information from previous data. Furthermore, existing continual learning benchmarks focus mostly on vision and language tasks, leaving continual learning for multilingual ASR largely unexplored. To bridge this gap, we propose CL-MASR, a benchmark designed for studying multilingual ASR in a continual learning setting. CL-MASR provides a diverse set of continual learning methods implemented on top of large-scale pretrained ASR models, along with common metrics to assess the effectiveness of learning new languages while addressing the issue of catastrophic forgetting. To the best of our knowledge, CL-MASR is the first continual learning benchmark for the multilingual ASR task. The code is available at https://github.com/speechbrain/benchmarks.