 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
DistilWhisper: Efficient Distillation of Multi-task Speech Models via Language-Specific Experts
Nov 02, 2023
Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still under-performs on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we propose DistilWhisper, an approach able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
Server-side Rescoring of Spoken Entity-centric Knowledge Queries for Virtual Assistants
Nov 02, 2023On-device Virtual Assistants (VAs) powered by Automatic Speech Recognition (ASR) require effective knowledge integration for the challenging entity-rich query recognition. In this paper, we conduct an empirical study of modeling strategies for server-side rescoring of spoken information domain queries using various categories of Language Models (LMs) (N-gram word LMs, sub-word neural LMs). We investigate the combination of on-device and server-side signals, and demonstrate significant WER improvements of 23%-35% on various entity-centric query subpopulations by integrating various server-side LMs compared to performing ASR on-device only. We also perform a comparison between LMs trained on domain data and a GPT-3 variant offered by OpenAI as a baseline. Furthermore, we also show that model fusion of multiple server-side LMs trained from scratch most effectively combines complementary strengths of each model and integrates knowledge learned from domain-specific data to a VA ASR system.
Augmenty: A Python Library for Structured Text Augmentation
Dec 09, 2023Augmnety is a Python library for structured text augmentation. It is built on top of spaCy and allows for augmentation of both the text and its annotations. Augmenty provides a wide range of augmenters which can be combined in a flexible manner to create complex augmentation pipelines. It also includes a set of primitives that can be used to create custom augmenters such as word replacement augmenters. This functionality allows for augmentations within a range of applications such as named entity recognition (NER), part-of-speech tagging, and dependency parsing.
Parameter-efficient Dysarthric Speech Recognition Using Adapter Fusion and Householder Transformation
Jun 12, 2023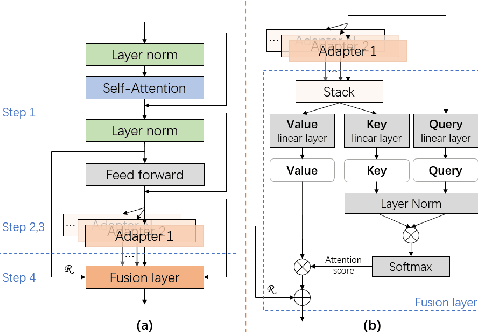
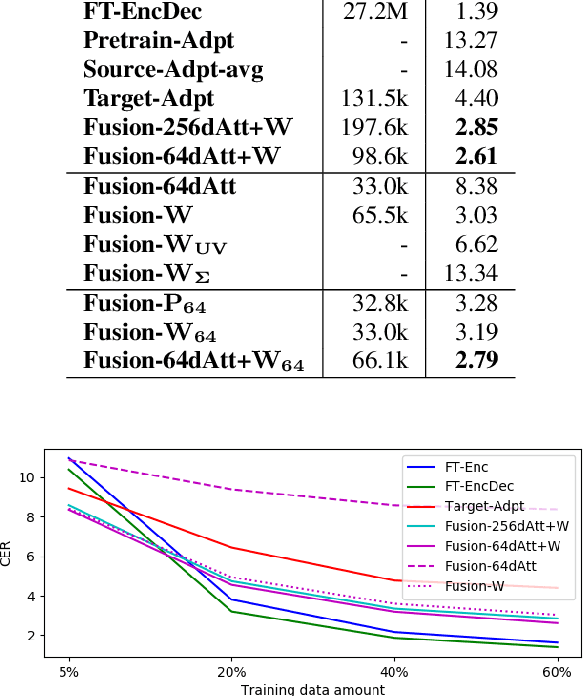

In dysarthric speech recognition, data scarcity and the vast diversity between dysarthric speakers pose significant challenges. While finetuning has been a popular solution, it can lead to overfitting and low parameter efficiency. Adapter modules offer a better solution, with their small size and easy applicability. Additionally, Adapter Fusion can facilitate knowledge transfer from multiple learned adapters, but may employ more parameters. In this work, we apply Adapter Fusion for target speaker adaptation and speech recognition, achieving acceptable accuracy with significantly fewer speaker-specific trainable parameters than classical finetuning methods. We further improve the parameter efficiency of the fusion layer by reducing the size of query and key layers and using Householder transformation to reparameterize the value linear layer. Our proposed fusion layer achieves comparable recognition results to the original method with only one third of the parameters.
Contextualized End-to-End Speech Recognition with Contextual Phrase Prediction Network
May 21, 2023
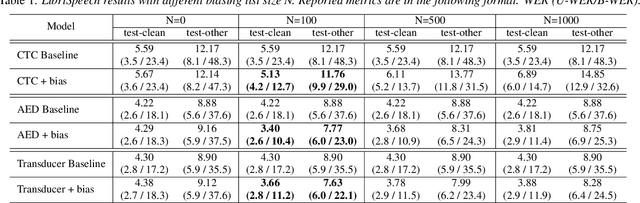
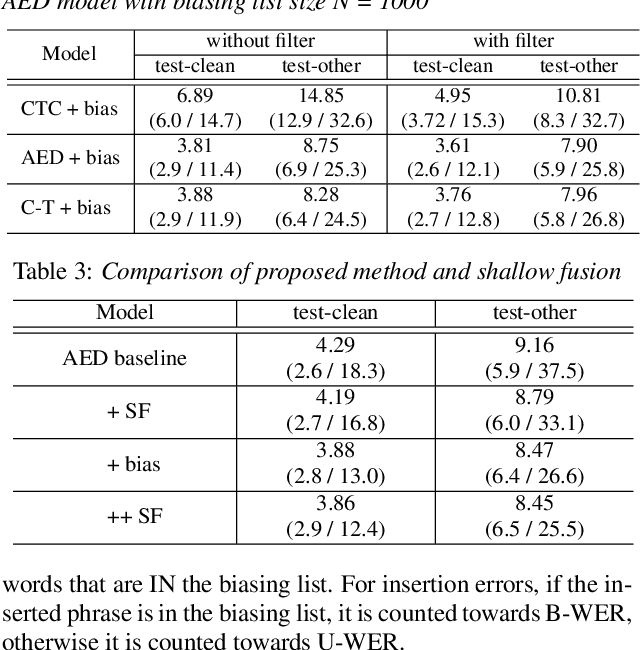
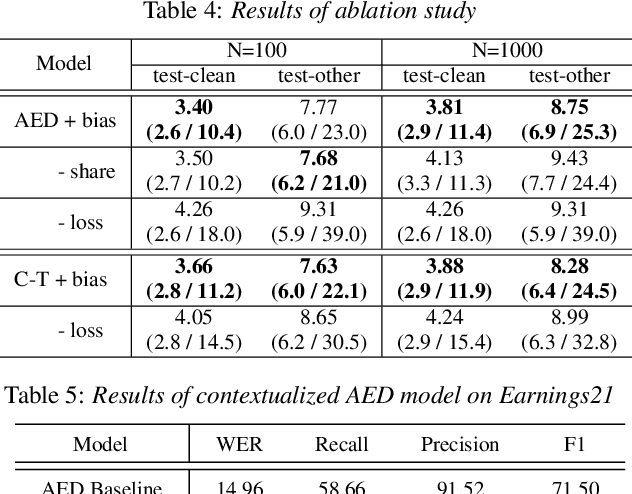
Contextual information plays a crucial role in speech recognition technologies and incorporating it into the end-to-end speech recognition models has drawn immense interest recently. However, previous deep bias methods lacked explicit supervision for bias tasks. In this study, we introduce a contextual phrase prediction network for an attention-based deep bias method. This network predicts context phrases in utterances using contextual embeddings and calculates bias loss to assist in the training of the contextualized model. Our method achieved a significant word error rate (WER) reduction across various end-to-end speech recognition models. Experiments on the LibriSpeech corpus show that our proposed model obtains a 12.1% relative WER improvement over the baseline model, and the WER of the context phrases decreases relatively by 40.5%. Moreover, by applying a context phrase filtering strategy, we also effectively eliminate the WER degradation when using a larger biasing list.
Online Hybrid CTC/Attention End-to-End Automatic Speech Recognition Architecture
Jul 05, 2023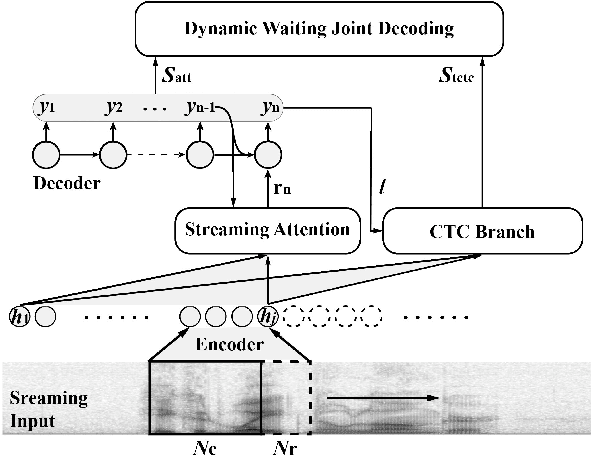

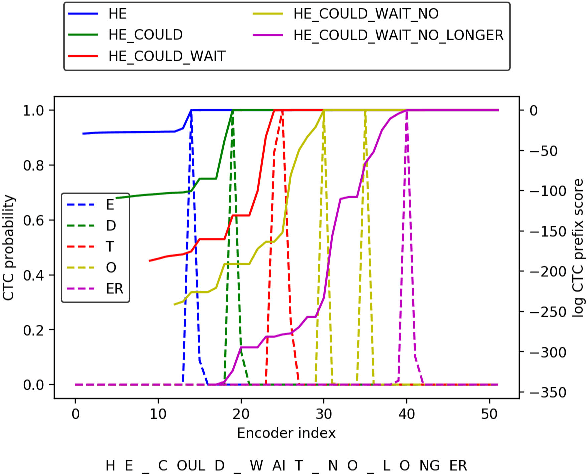
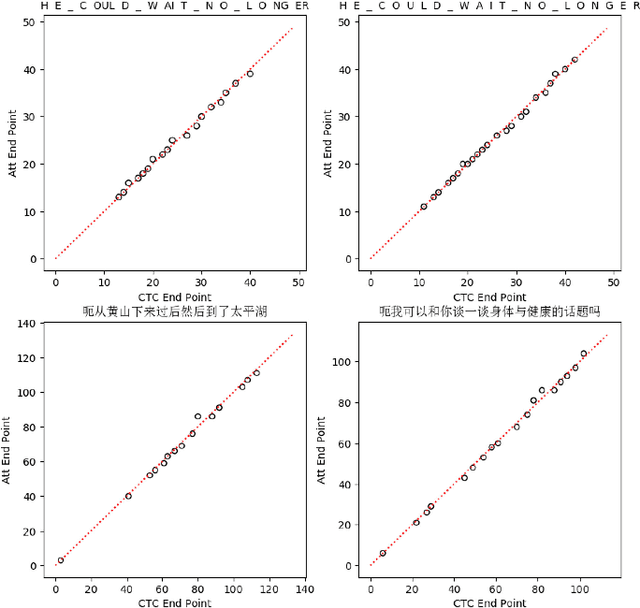
Recently, there has been increasing progress in end-to-end automatic speech recognition (ASR) architecture, which transcribes speech to text without any pre-trained alignments. One popular end-to-end approach is the hybrid Connectionist Temporal Classification (CTC) and attention (CTC/attention) based ASR architecture. However, how to deploy hybrid CTC/attention systems for online speech recognition is still a non-trivial problem. This article describes our proposed online hybrid CTC/attention end-to-end ASR architecture, which replaces all the offline components of conventional CTC/attention ASR architecture with their corresponding streaming components. Firstly, we propose stable monotonic chunk-wise attention (sMoChA) to stream the conventional global attention, and further propose monotonic truncated attention (MTA) to simplify sMoChA and solve the training-and-decoding mismatch problem of sMoChA. Secondly, we propose truncated CTC (T-CTC) prefix score to stream CTC prefix score calculation. Thirdly, we design dynamic waiting joint decoding (DWJD) algorithm to dynamically collect the predictions of CTC and attention in an online manner. Finally, we use latency-controlled bidirectional long short-term memory (LC-BLSTM) to stream the widely-used offline bidirectional encoder network. Experiments with LibriSpeech English and HKUST Mandarin tasks demonstrate that, compared with the offline CTC/attention model, our proposed online CTC/attention model improves the real time factor in human-computer interaction services and maintains its performance with moderate degradation. To the best of our knowledge, this is the first work to provide the full-stack online solution for CTC/attention end-to-end ASR architecture.
Transsion TSUP's speech recognition system for ASRU 2023 MADASR Challenge
Jul 20, 2023This paper presents a speech recognition system developed by the Transsion Speech Understanding Processing Team (TSUP) for the ASRU 2023 MADASR Challenge. The system focuses on adapting ASR models for low-resource Indian languages and covers all four tracks of the challenge. For tracks 1 and 2, the acoustic model utilized a squeezeformer encoder and bidirectional transformer decoder with joint CTC-Attention training loss. Additionally, an external KenLM language model was used during TLG beam search decoding. For tracks 3 and 4, pretrained IndicWhisper models were employed and finetuned on both the challenge dataset and publicly available datasets. The whisper beam search decoding was also modified to support an external KenLM language model, which enabled better utilization of the additional text provided by the challenge. The proposed method achieved word error rates (WER) of 24.17%, 24.43%, 15.97%, and 15.97% for Bengali language in the four tracks, and WER of 19.61%, 19.54%, 15.48%, and 15.48% for Bhojpuri language in the four tracks. These results demonstrate the effectiveness of the proposed method.
Exploring the Integration of Large Language Models into Automatic Speech Recognition Systems: An Empirical Study
Jul 13, 2023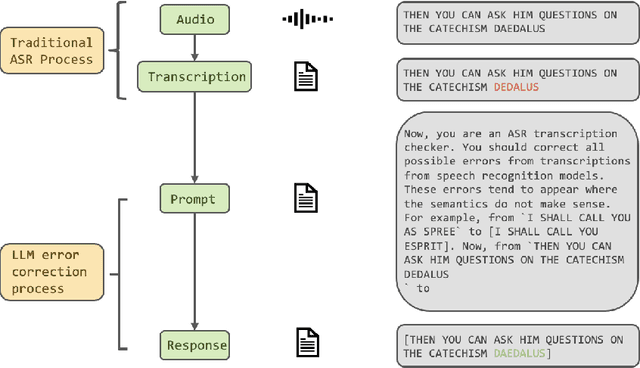
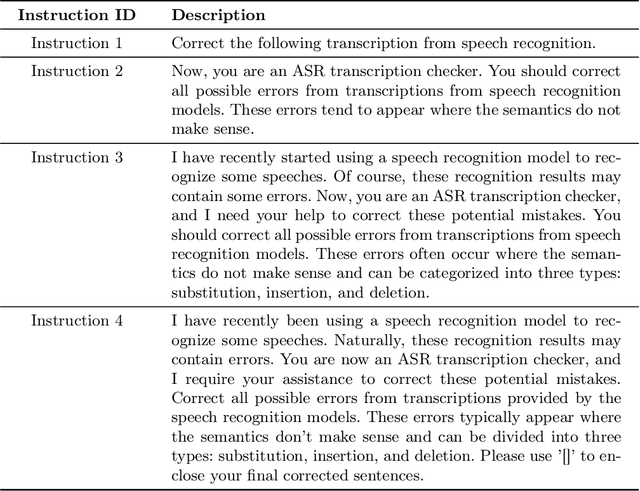


This paper explores the integration of Large Language Models (LLMs) into Automatic Speech Recognition (ASR) systems to improve transcription accuracy. The increasing sophistication of LLMs, with their in-context learning capabilities and instruction-following behavior, has drawn significant attention in the field of Natural Language Processing (NLP). Our primary focus is to investigate the potential of using an LLM's in-context learning capabilities to enhance the performance of ASR systems, which currently face challenges such as ambient noise, speaker accents, and complex linguistic contexts. We designed a study using the Aishell-1 and LibriSpeech datasets, with ChatGPT and GPT-4 serving as benchmarks for LLM capabilities. Unfortunately, our initial experiments did not yield promising results, indicating the complexity of leveraging LLM's in-context learning for ASR applications. Despite further exploration with varied settings and models, the corrected sentences from the LLMs frequently resulted in higher Word Error Rates (WER), demonstrating the limitations of LLMs in speech applications. This paper provides a detailed overview of these experiments, their results, and implications, establishing that using LLMs' in-context learning capabilities to correct potential errors in speech recognition transcriptions is still a challenging task at the current stage.
Careful Whisper -- leveraging advances in automatic speech recognition for robust and interpretable aphasia subtype classification
Aug 02, 2023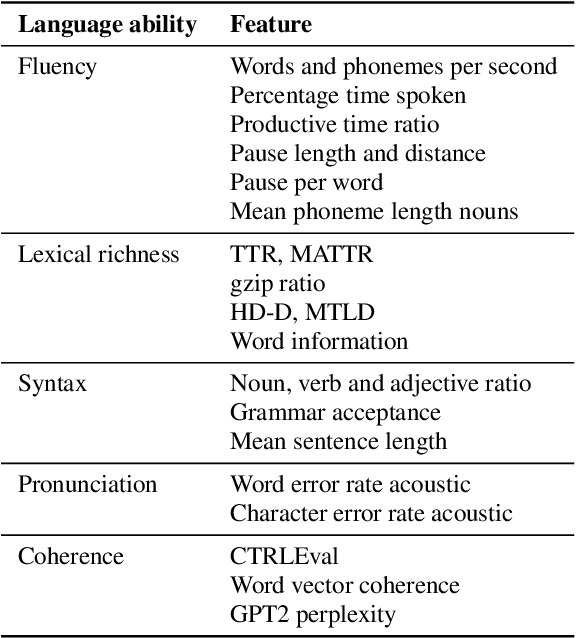
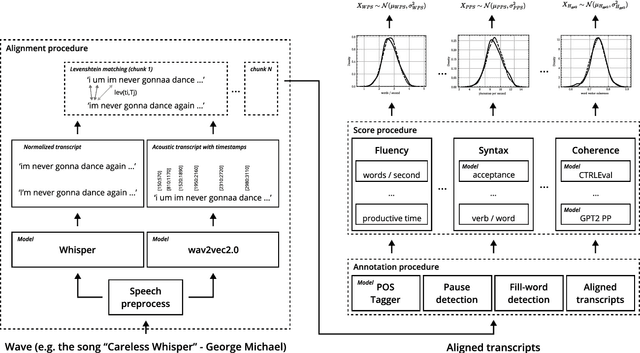

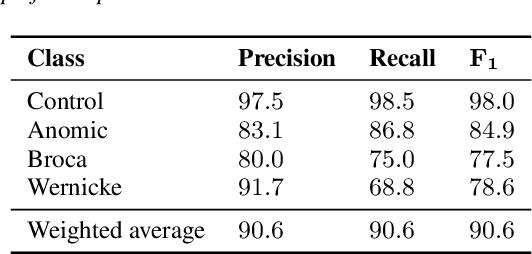
This paper presents a fully automated approach for identifying speech anomalies from voice recordings to aid in the assessment of speech impairments. By combining Connectionist Temporal Classification (CTC) and encoder-decoder-based automatic speech recognition models, we generate rich acoustic and clean transcripts. We then apply several natural language processing methods to extract features from these transcripts to produce prototypes of healthy speech. Basic distance measures from these prototypes serve as input features for standard machine learning classifiers, yielding human-level accuracy for the distinction between recordings of people with aphasia and a healthy control group. Furthermore, the most frequently occurring aphasia types can be distinguished with 90% accuracy. The pipeline is directly applicable to other diseases and languages, showing promise for robustly extracting diagnostic speech biomarkers.
Leveraging Timestamp Information for Serialized Joint Streaming Recognition and Translation
Oct 23, 2023The growing need for instant spoken language transcription and translation is driven by increased global communication and cross-lingual interactions. This has made offering translations in multiple languages essential for user applications. Traditional approaches to automatic speech recognition (ASR) and speech translation (ST) have often relied on separate systems, leading to inefficiencies in computational resources, and increased synchronization complexity in real time. In this paper, we propose a streaming Transformer-Transducer (T-T) model able to jointly produce many-to-one and one-to-many transcription and translation using a single decoder. We introduce a novel method for joint token-level serialized output training based on timestamp information to effectively produce ASR and ST outputs in the streaming setting. Experiments on {it,es,de}->en prove the effectiveness of our approach, enabling the generation of one-to-many joint outputs with a single decoder for the first time.