 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Multi-channel Conversational Speaker Separation via Neural Diarization
Nov 15, 2023
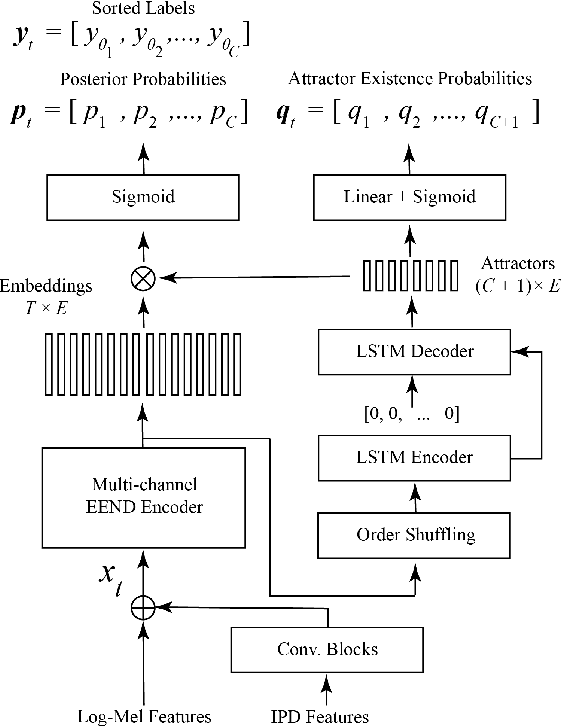
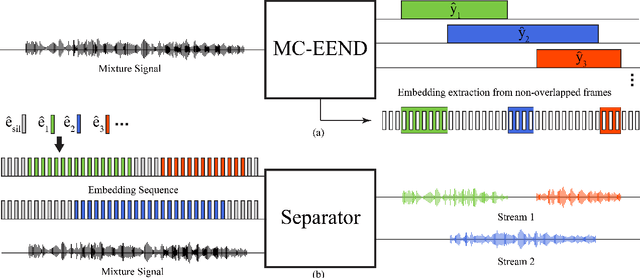
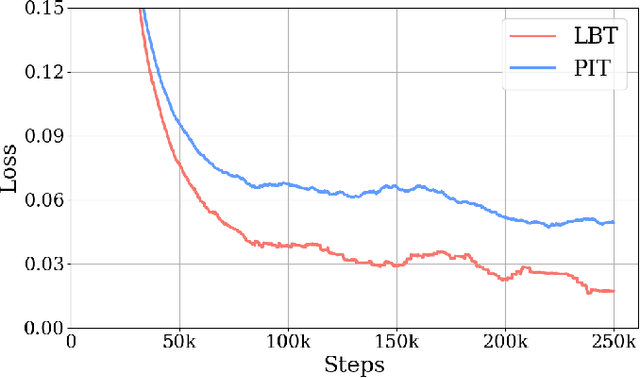
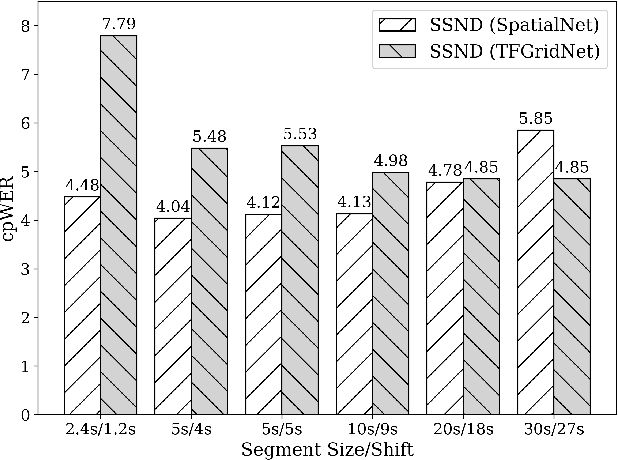
When dealing with overlapped speech, the performance of automatic speech recognition (ASR) systems substantially degrades as they are designed for single-talker speech. To enhance ASR performance in conversational or meeting environments, continuous speaker separation (CSS) is commonly employed. However, CSS requires a short separation window to avoid many speakers inside the window and sequential grouping of discontinuous speech segments. To address these limitations, we introduce a new multi-channel framework called "speaker separation via neural diarization" (SSND) for meeting environments. Our approach utilizes an end-to-end diarization system to identify the speech activity of each individual speaker. By leveraging estimated speaker boundaries, we generate a sequence of embeddings, which in turn facilitate the assignment of speakers to the outputs of a multi-talker separation model. SSND addresses the permutation ambiguity issue of talker-independent speaker separation during the diarization phase through location-based training, rather than during the separation process. This unique approach allows multiple non-overlapped speakers to be assigned to the same output stream, making it possible to efficiently process long segments-a task impossible with CSS. Additionally, SSND is naturally suitable for speaker-attributed ASR. We evaluate our proposed diarization and separation methods on the open LibriCSS dataset, advancing state-of-the-art diarization and ASR results by a large margin.
Research on an improved Conformer end-to-end Speech Recognition Model with R-Drop Structure
Jun 14, 2023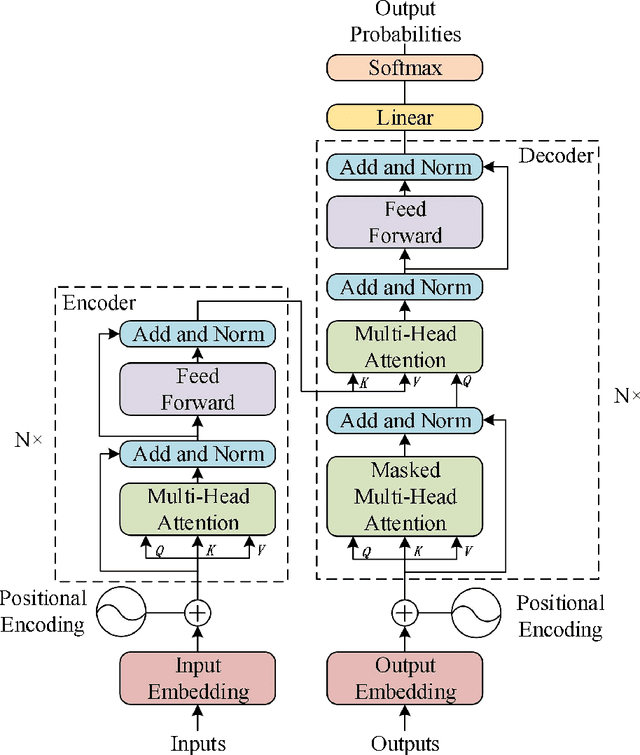
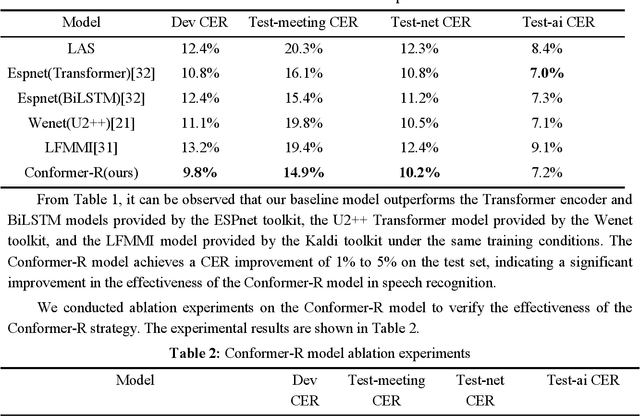
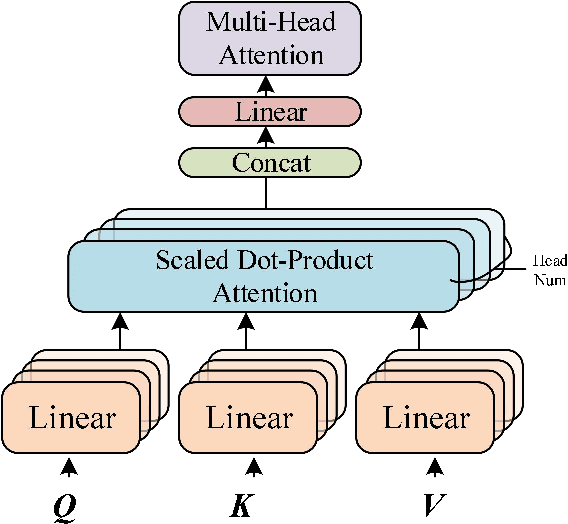

To address the issue of poor generalization ability in end-to-end speech recognition models within deep learning, this study proposes a new Conformer-based speech recognition model called "Conformer-R" that incorporates the R-drop structure. This model combines the Conformer model, which has shown promising results in speech recognition, with the R-drop structure. By doing so, the model is able to effectively model both local and global speech information while also reducing overfitting through the use of the R-drop structure. This enhances the model's ability to generalize and improves overall recognition efficiency. The model was first pre-trained on the Aishell1 and Wenetspeech datasets for general domain adaptation, and subsequently fine-tuned on computer-related audio data. Comparison tests with classic models such as LAS and Wenet were performed on the same test set, demonstrating the Conformer-R model's ability to effectively improve generalization.
Whisper in Focus: Enhancing Stuttered Speech Classification with Encoder Layer Optimization
Nov 09, 2023In recent years, advancements in the field of speech processing have led to cutting-edge deep learning algorithms with immense potential for real-world applications. The automated identification of stuttered speech is one of such applications that the researchers are addressing by employing deep learning techniques. Recently, researchers have utilized Wav2vec2.0, a speech recognition model to classify disfluency types in stuttered speech. Although Wav2vec2.0 has shown commendable results, its ability to generalize across all disfluency types is limited. In addition, since its base model uses 12 encoder layers, it is considered a resource-intensive model. Our study unravels the capabilities of Whisper for the classification of disfluency types in stuttered speech. We have made notable contributions in three pivotal areas: enhancing the quality of SEP28-k benchmark dataset, exploration of Whisper for classification, and introducing an efficient encoder layer freezing strategy. The optimized Whisper model has achieved the average F1-score of 0.81, which proffers its abilities. This study also unwinds the significance of deeper encoder layers in the identification of disfluency types, as the results demonstrate their greater contribution compared to initial layers. This research represents substantial contributions, shifting the emphasis towards an efficient solution, thereby thriving towards prospective innovation.
Design, construction and evaluation of emotional multimodal pathological speech database
Dec 14, 2023


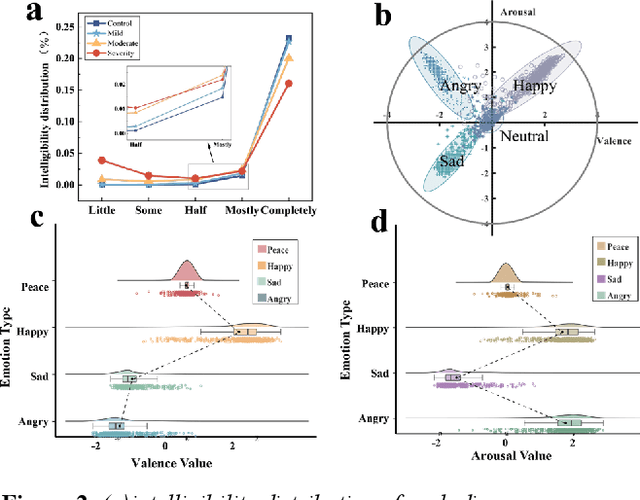
The lack of an available emotion pathology database is one of the key obstacles in studying the emotion expression status of patients with dysarthria. The first Chinese multimodal emotional pathological speech database containing multi-perspective information is constructed in this paper. It includes 29 controls and 39 patients with different degrees of motor dysarthria, expressing happy, sad, angry and neutral emotions. All emotional speech was labeled for intelligibility, types and discrete dimensional emotions by developed WeChat mini-program. The subjective analysis justifies from emotion discrimination accuracy, speech intelligibility, valence-arousal spatial distribution, and correlation between SCL-90 and disease severity. The automatic recognition tested on speech and glottal data, with average accuracy of 78% for controls and 60% for patients in audio, while 51% for controls and 38% for patients in glottal data, indicating an influence of the disease on emotional expression.
Contextualized End-to-End Speech Recognition with Contextual Phrase Prediction Network
May 21, 2023
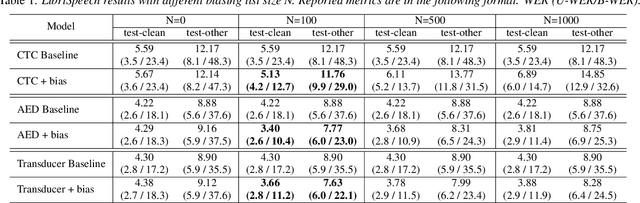
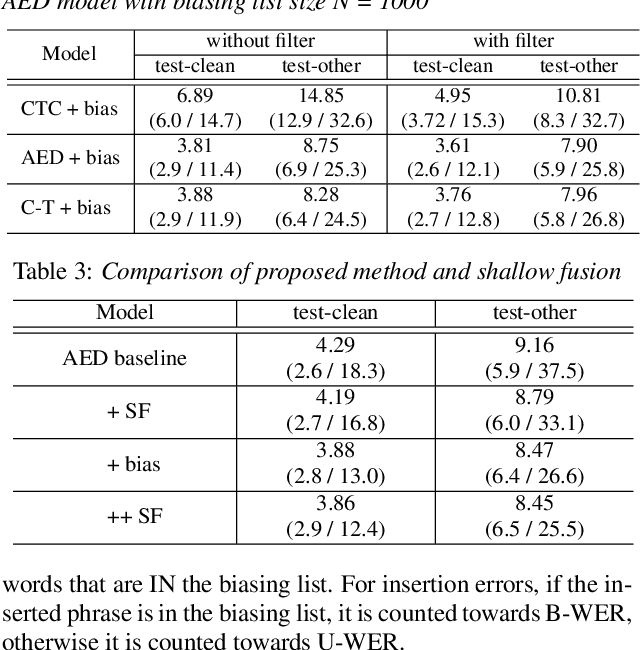
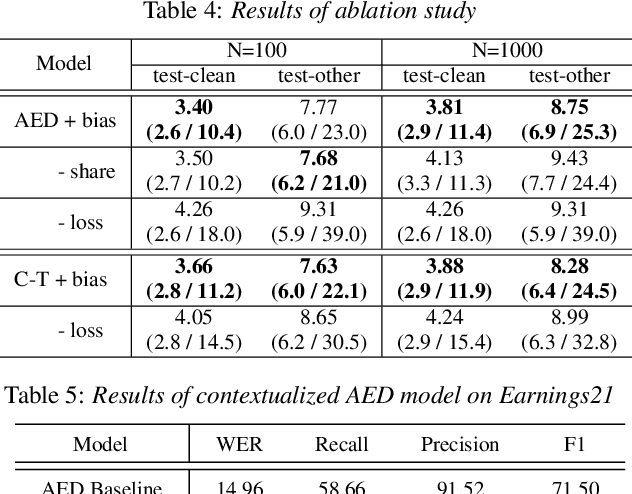
Contextual information plays a crucial role in speech recognition technologies and incorporating it into the end-to-end speech recognition models has drawn immense interest recently. However, previous deep bias methods lacked explicit supervision for bias tasks. In this study, we introduce a contextual phrase prediction network for an attention-based deep bias method. This network predicts context phrases in utterances using contextual embeddings and calculates bias loss to assist in the training of the contextualized model. Our method achieved a significant word error rate (WER) reduction across various end-to-end speech recognition models. Experiments on the LibriSpeech corpus show that our proposed model obtains a 12.1% relative WER improvement over the baseline model, and the WER of the context phrases decreases relatively by 40.5%. Moreover, by applying a context phrase filtering strategy, we also effectively eliminate the WER degradation when using a larger biasing list.
Parameter-efficient Dysarthric Speech Recognition Using Adapter Fusion and Householder Transformation
Jun 12, 2023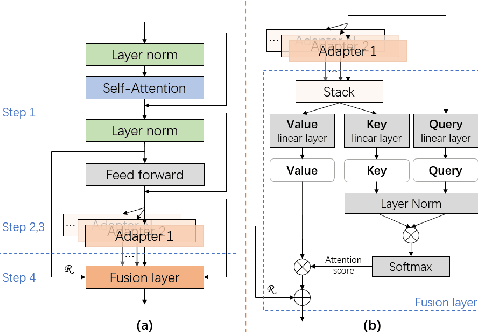
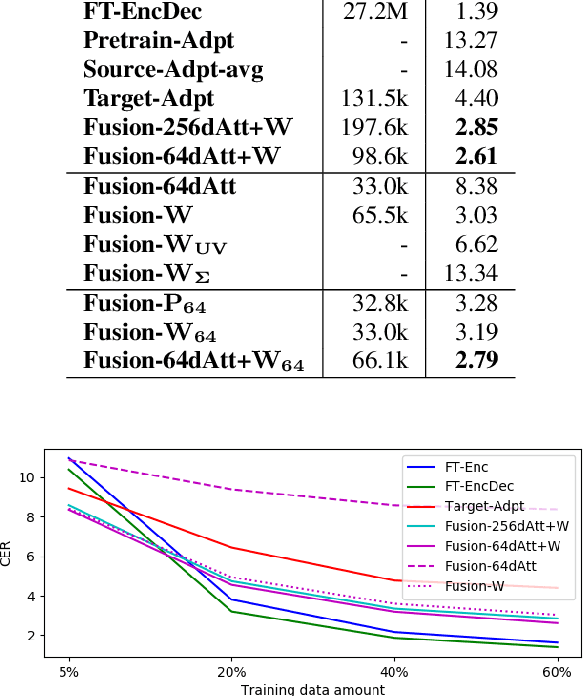

In dysarthric speech recognition, data scarcity and the vast diversity between dysarthric speakers pose significant challenges. While finetuning has been a popular solution, it can lead to overfitting and low parameter efficiency. Adapter modules offer a better solution, with their small size and easy applicability. Additionally, Adapter Fusion can facilitate knowledge transfer from multiple learned adapters, but may employ more parameters. In this work, we apply Adapter Fusion for target speaker adaptation and speech recognition, achieving acceptable accuracy with significantly fewer speaker-specific trainable parameters than classical finetuning methods. We further improve the parameter efficiency of the fusion layer by reducing the size of query and key layers and using Householder transformation to reparameterize the value linear layer. Our proposed fusion layer achieves comparable recognition results to the original method with only one third of the parameters.
Towards End-to-End Spoken Grammatical Error Correction
Nov 09, 2023Grammatical feedback is crucial for L2 learners, teachers, and testers. Spoken grammatical error correction (GEC) aims to supply feedback to L2 learners on their use of grammar when speaking. This process usually relies on a cascaded pipeline comprising an ASR system, disfluency removal, and GEC, with the associated concern of propagating errors between these individual modules. In this paper, we introduce an alternative "end-to-end" approach to spoken GEC, exploiting a speech recognition foundation model, Whisper. This foundation model can be used to replace the whole framework or part of it, e.g., ASR and disfluency removal. These end-to-end approaches are compared to more standard cascaded approaches on the data obtained from a free-speaking spoken language assessment test, Linguaskill. Results demonstrate that end-to-end spoken GEC is possible within this architecture, but the lack of available data limits current performance compared to a system using large quantities of text-based GEC data. Conversely, end-to-end disfluency detection and removal, which is easier for the attention-based Whisper to learn, does outperform cascaded approaches. Additionally, the paper discusses the challenges of providing feedback to candidates when using end-to-end systems for spoken GEC.
Online Hybrid CTC/Attention End-to-End Automatic Speech Recognition Architecture
Jul 05, 2023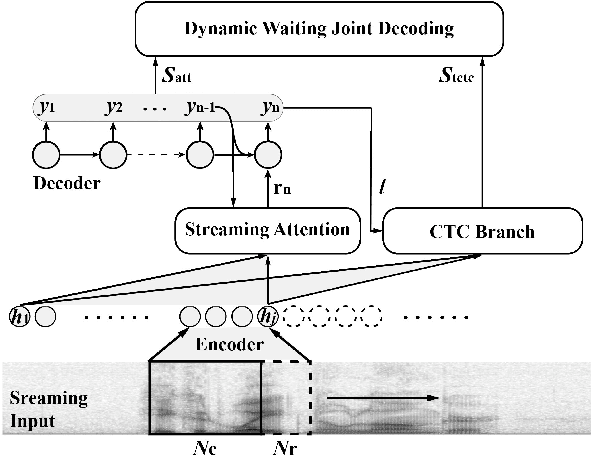

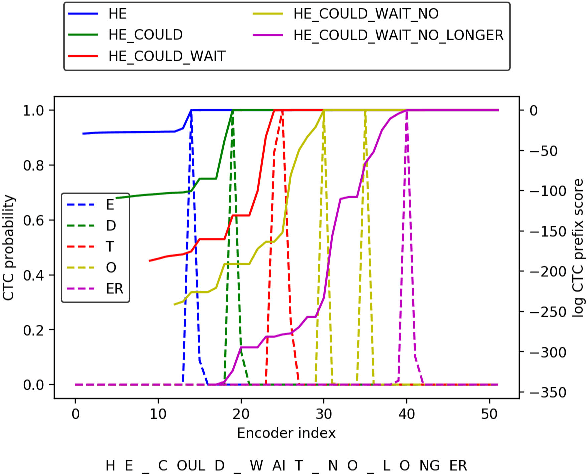
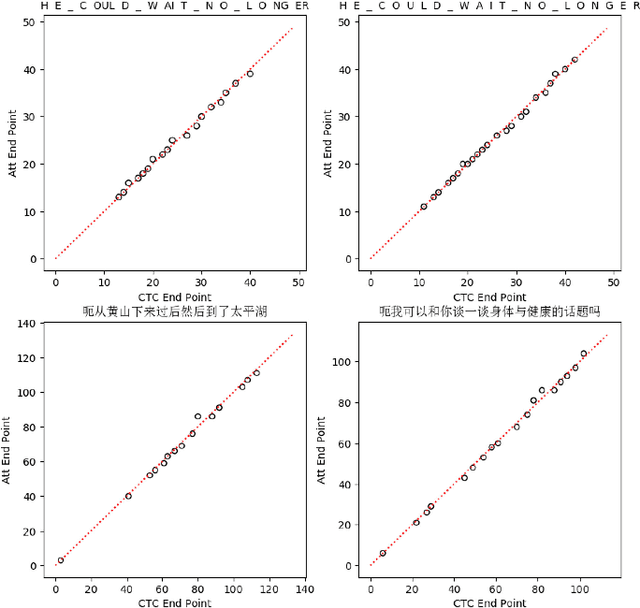
Recently, there has been increasing progress in end-to-end automatic speech recognition (ASR) architecture, which transcribes speech to text without any pre-trained alignments. One popular end-to-end approach is the hybrid Connectionist Temporal Classification (CTC) and attention (CTC/attention) based ASR architecture. However, how to deploy hybrid CTC/attention systems for online speech recognition is still a non-trivial problem. This article describes our proposed online hybrid CTC/attention end-to-end ASR architecture, which replaces all the offline components of conventional CTC/attention ASR architecture with their corresponding streaming components. Firstly, we propose stable monotonic chunk-wise attention (sMoChA) to stream the conventional global attention, and further propose monotonic truncated attention (MTA) to simplify sMoChA and solve the training-and-decoding mismatch problem of sMoChA. Secondly, we propose truncated CTC (T-CTC) prefix score to stream CTC prefix score calculation. Thirdly, we design dynamic waiting joint decoding (DWJD) algorithm to dynamically collect the predictions of CTC and attention in an online manner. Finally, we use latency-controlled bidirectional long short-term memory (LC-BLSTM) to stream the widely-used offline bidirectional encoder network. Experiments with LibriSpeech English and HKUST Mandarin tasks demonstrate that, compared with the offline CTC/attention model, our proposed online CTC/attention model improves the real time factor in human-computer interaction services and maintains its performance with moderate degradation. To the best of our knowledge, this is the first work to provide the full-stack online solution for CTC/attention end-to-end ASR architecture.
Transsion TSUP's speech recognition system for ASRU 2023 MADASR Challenge
Jul 20, 2023This paper presents a speech recognition system developed by the Transsion Speech Understanding Processing Team (TSUP) for the ASRU 2023 MADASR Challenge. The system focuses on adapting ASR models for low-resource Indian languages and covers all four tracks of the challenge. For tracks 1 and 2, the acoustic model utilized a squeezeformer encoder and bidirectional transformer decoder with joint CTC-Attention training loss. Additionally, an external KenLM language model was used during TLG beam search decoding. For tracks 3 and 4, pretrained IndicWhisper models were employed and finetuned on both the challenge dataset and publicly available datasets. The whisper beam search decoding was also modified to support an external KenLM language model, which enabled better utilization of the additional text provided by the challenge. The proposed method achieved word error rates (WER) of 24.17%, 24.43%, 15.97%, and 15.97% for Bengali language in the four tracks, and WER of 19.61%, 19.54%, 15.48%, and 15.48% for Bhojpuri language in the four tracks. These results demonstrate the effectiveness of the proposed method.
Exploring the Integration of Large Language Models into Automatic Speech Recognition Systems: An Empirical Study
Jul 13, 2023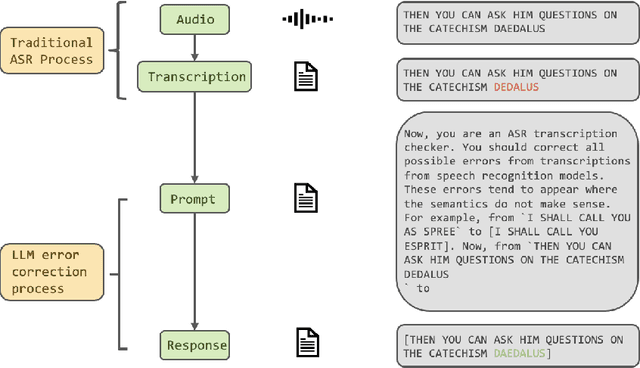
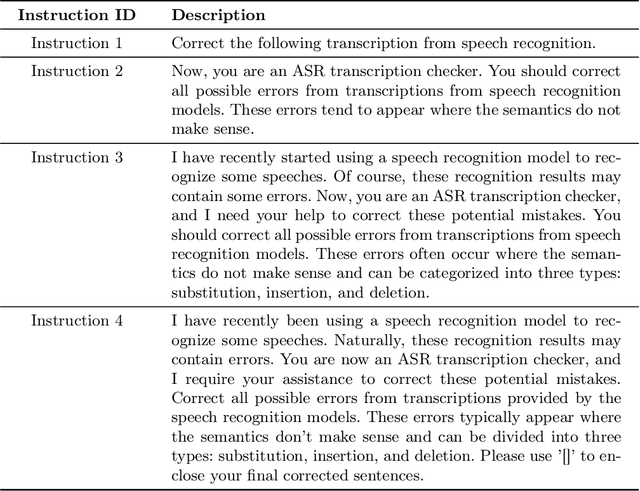


This paper explores the integration of Large Language Models (LLMs) into Automatic Speech Recognition (ASR) systems to improve transcription accuracy. The increasing sophistication of LLMs, with their in-context learning capabilities and instruction-following behavior, has drawn significant attention in the field of Natural Language Processing (NLP). Our primary focus is to investigate the potential of using an LLM's in-context learning capabilities to enhance the performance of ASR systems, which currently face challenges such as ambient noise, speaker accents, and complex linguistic contexts. We designed a study using the Aishell-1 and LibriSpeech datasets, with ChatGPT and GPT-4 serving as benchmarks for LLM capabilities. Unfortunately, our initial experiments did not yield promising results, indicating the complexity of leveraging LLM's in-context learning for ASR applications. Despite further exploration with varied settings and models, the corrected sentences from the LLMs frequently resulted in higher Word Error Rates (WER), demonstrating the limitations of LLMs in speech applications. This paper provides a detailed overview of these experiments, their results, and implications, establishing that using LLMs' in-context learning capabilities to correct potential errors in speech recognition transcriptions is still a challenging task at the current stage.