 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
The timing bottleneck: Why timing and overlap are mission-critical for conversational user interfaces, speech recognition and dialogue systems
Jul 28, 2023

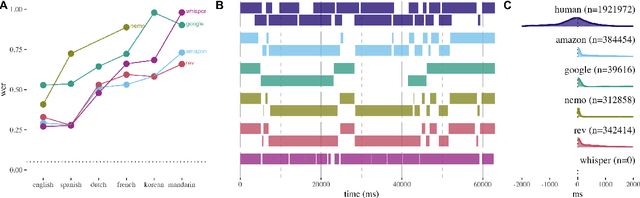
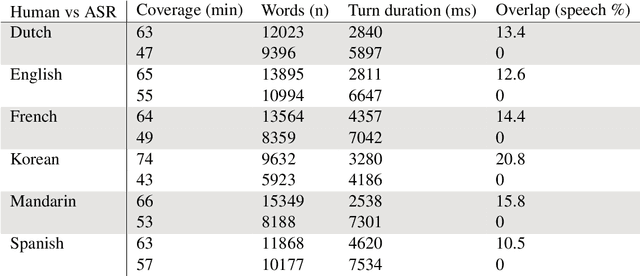
Speech recognition systems are a key intermediary in voice-driven human-computer interaction. Although speech recognition works well for pristine monologic audio, real-life use cases in open-ended interactive settings still present many challenges. We argue that timing is mission-critical for dialogue systems, and evaluate 5 major commercial ASR systems for their conversational and multilingual support. We find that word error rates for natural conversational data in 6 languages remain abysmal, and that overlap remains a key challenge (study 1). This impacts especially the recognition of conversational words (study 2), and in turn has dire consequences for downstream intent recognition (study 3). Our findings help to evaluate the current state of conversational ASR, contribute towards multidimensional error analysis and evaluation, and identify phenomena that need most attention on the way to build robust interactive speech technologies.
Globally Normalising the Transducer for Streaming Speech Recognition
Jul 20, 2023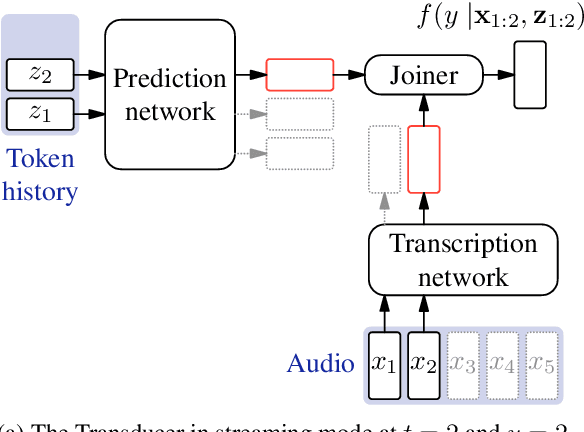
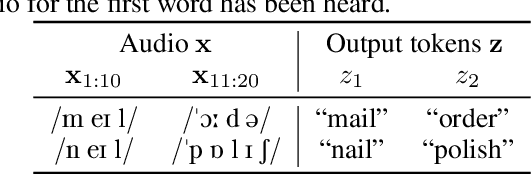
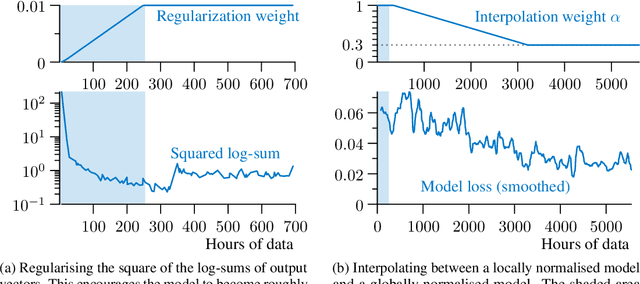
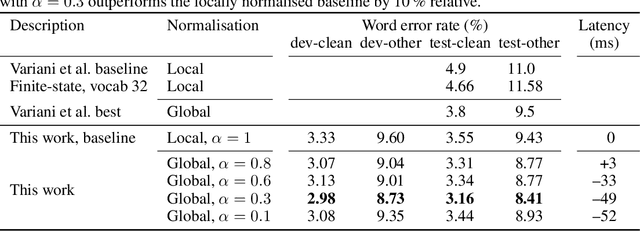
The Transducer (e.g. RNN-Transducer or Conformer-Transducer) generates an output label sequence as it traverses the input sequence. It is straightforward to use in streaming mode, where it generates partial hypotheses before the complete input has been seen. This makes it popular in speech recognition. However, in streaming mode the Transducer has a mathematical flaw which, simply put, restricts the model's ability to change its mind. The fix is to replace local normalisation (e.g. a softmax) with global normalisation, but then the loss function becomes impossible to evaluate exactly. A recent paper proposes to solve this by approximating the model, severely degrading performance. Instead, this paper proposes to approximate the loss function, allowing global normalisation to apply to a state-of-the-art streaming model. Global normalisation reduces its word error rate by 9-11% relative, closing almost half the gap between streaming and lookahead mode.
End-to-End Single-Channel Speaker-Turn Aware Conversational Speech Translation
Nov 01, 2023Conventional speech-to-text translation (ST) systems are trained on single-speaker utterances, and they may not generalize to real-life scenarios where the audio contains conversations by multiple speakers. In this paper, we tackle single-channel multi-speaker conversational ST with an end-to-end and multi-task training model, named Speaker-Turn Aware Conversational Speech Translation, that combines automatic speech recognition, speech translation and speaker turn detection using special tokens in a serialized labeling format. We run experiments on the Fisher-CALLHOME corpus, which we adapted by merging the two single-speaker channels into one multi-speaker channel, thus representing the more realistic and challenging scenario with multi-speaker turns and cross-talk. Experimental results across single- and multi-speaker conditions and against conventional ST systems, show that our model outperforms the reference systems on the multi-speaker condition, while attaining comparable performance on the single-speaker condition. We release scripts for data processing and model training.
Noise robust speech emotion recognition with signal-to-noise ratio adapting speech enhancement
Sep 03, 2023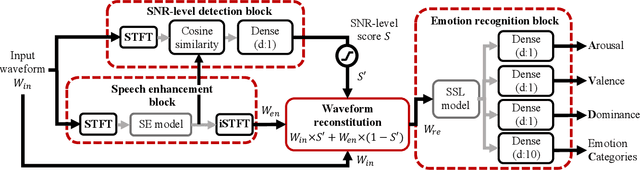

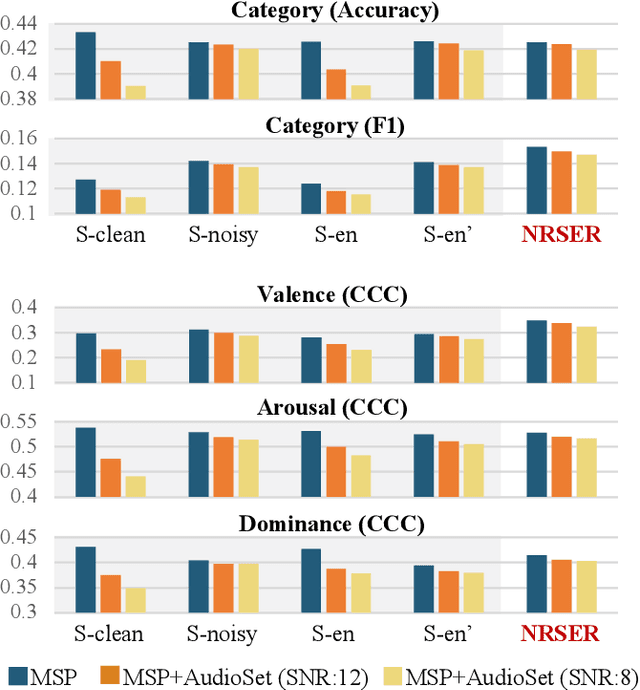
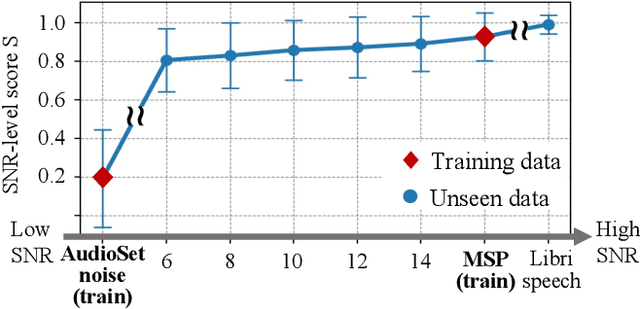
Speech emotion recognition (SER) often experiences reduced performance due to background noise. In addition, making a prediction on signals with only background noise could undermine user trust in the system. In this study, we propose a Noise Robust Speech Emotion Recognition system, NRSER. NRSER employs speech enhancement (SE) to effectively reduce the noise in input signals. Then, the signal-to-noise-ratio (SNR)-level detection structure and waveform reconstitution strategy are introduced to reduce the negative impact of SE on speech signals with no or little background noise. Our experimental results show that NRSER can effectively improve the noise robustness of the SER system, including preventing the system from making emotion recognition on signals consisting solely of background noise. Moreover, the proposed SNR-level detection structure can be used individually for tasks such as data selection.
Towards Stealthy Backdoor Attacks against Speech Recognition via Elements of Sound
Jul 17, 2023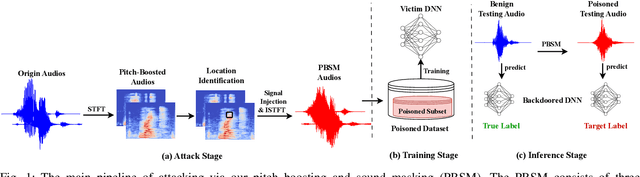
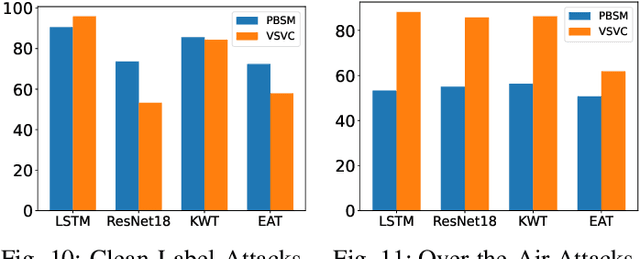
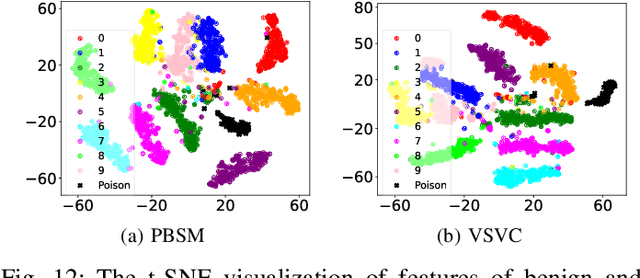
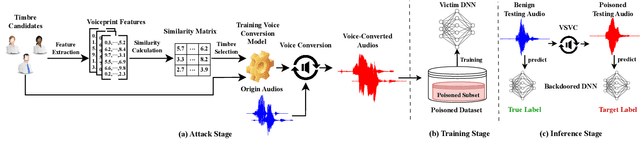
Deep neural networks (DNNs) have been widely and successfully adopted and deployed in various applications of speech recognition. Recently, a few works revealed that these models are vulnerable to backdoor attacks, where the adversaries can implant malicious prediction behaviors into victim models by poisoning their training process. In this paper, we revisit poison-only backdoor attacks against speech recognition. We reveal that existing methods are not stealthy since their trigger patterns are perceptible to humans or machine detection. This limitation is mostly because their trigger patterns are simple noises or separable and distinctive clips. Motivated by these findings, we propose to exploit elements of sound ($e.g.$, pitch and timbre) to design more stealthy yet effective poison-only backdoor attacks. Specifically, we insert a short-duration high-pitched signal as the trigger and increase the pitch of remaining audio clips to `mask' it for designing stealthy pitch-based triggers. We manipulate timbre features of victim audios to design the stealthy timbre-based attack and design a voiceprint selection module to facilitate the multi-backdoor attack. Our attacks can generate more `natural' poisoned samples and therefore are more stealthy. Extensive experiments are conducted on benchmark datasets, which verify the effectiveness of our attacks under different settings ($e.g.$, all-to-one, all-to-all, clean-label, physical, and multi-backdoor settings) and their stealthiness. The code for reproducing main experiments are available at \url{https://github.com/HanboCai/BadSpeech_SoE}.
Differential Evolution Algorithm based Hyper-Parameters Selection of Convolutional Neural Network for Speech Command Recognition
Oct 13, 2023Speech Command Recognition (SCR), which deals with identification of short uttered speech commands, is crucial for various applications, including IoT devices and assistive technology. Despite the promise shown by Convolutional Neural Networks (CNNs) in SCR tasks, their efficacy relies heavily on hyper-parameter selection, which is typically laborious and time-consuming when done manually. This paper introduces a hyper-parameter selection method for CNNs based on the Differential Evolution (DE) algorithm, aiming to enhance performance in SCR tasks. Training and testing with the Google Speech Command (GSC) dataset, the proposed approach showed effectiveness in classifying speech commands. Moreover, a comparative analysis with Genetic Algorithm based selections and other deep CNN (DCNN) models highlighted the efficiency of the proposed DE algorithm in hyper-parameter selection for CNNs in SCR tasks.
SparseVSR: Lightweight and Noise Robust Visual Speech Recognition
Jul 10, 2023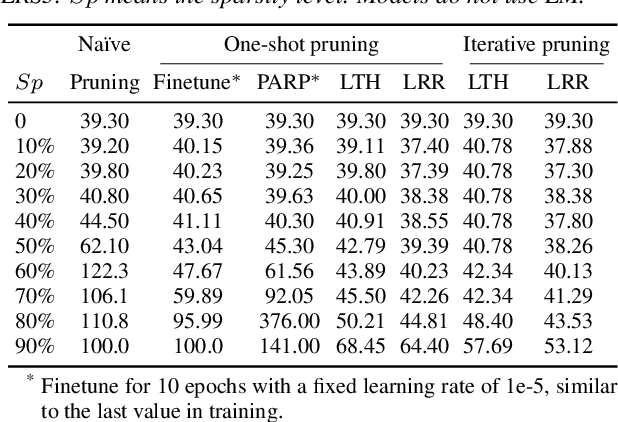
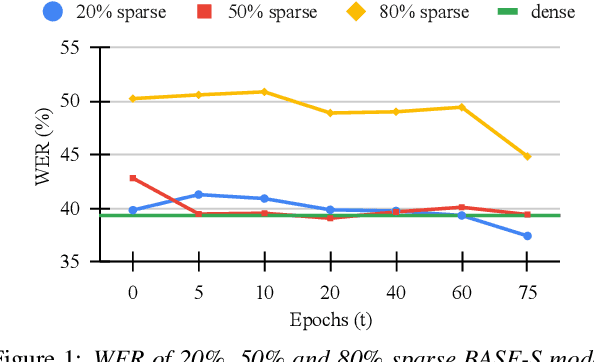
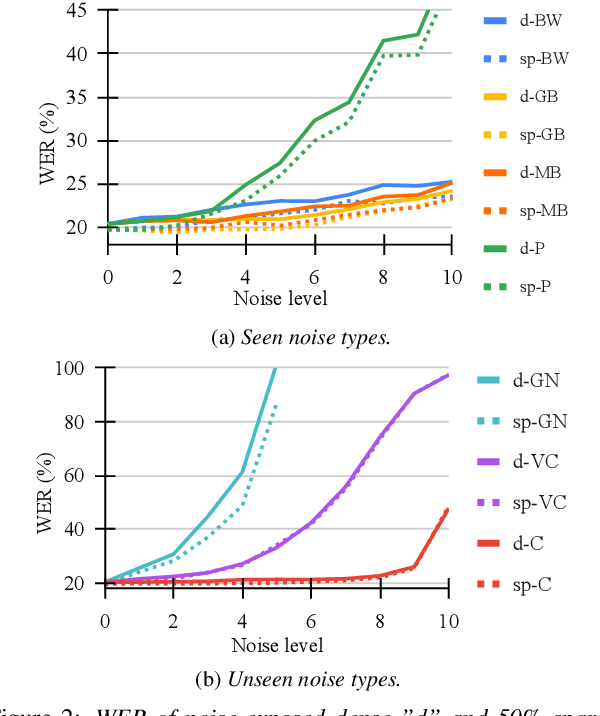
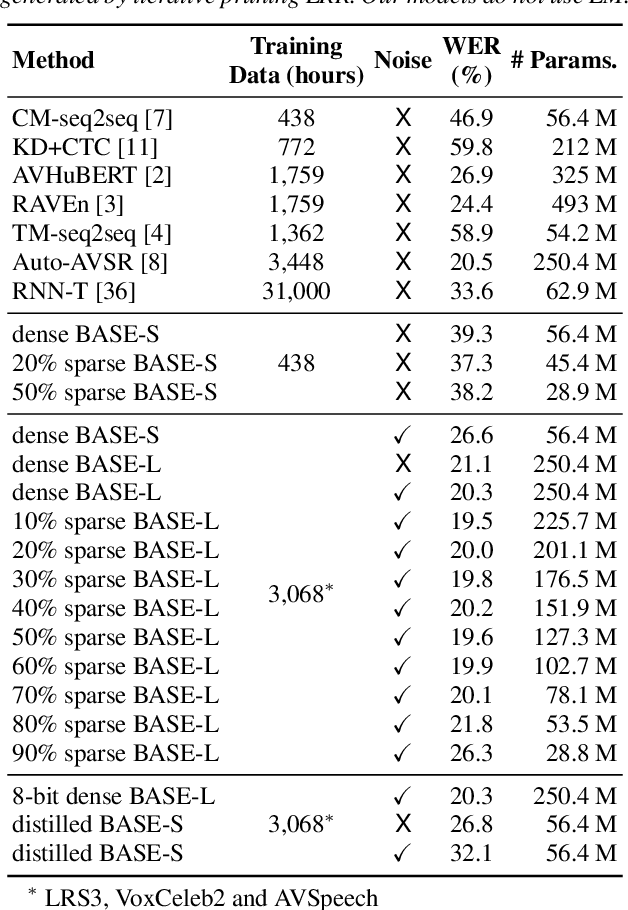
Recent advances in deep neural networks have achieved unprecedented success in visual speech recognition. However, there remains substantial disparity between current methods and their deployment in resource-constrained devices. In this work, we explore different magnitude-based pruning techniques to generate a lightweight model that achieves higher performance than its dense model equivalent, especially under the presence of visual noise. Our sparse models achieve state-of-the-art results at 10% sparsity on the LRS3 dataset and outperform the dense equivalent up to 70% sparsity. We evaluate our 50% sparse model on 7 different visual noise types and achieve an overall absolute improvement of more than 2% WER compared to the dense equivalent. Our results confirm that sparse networks are more resistant to noise than dense networks.
OpenSR: Open-Modality Speech Recognition via Maintaining Multi-Modality Alignment
Jun 10, 2023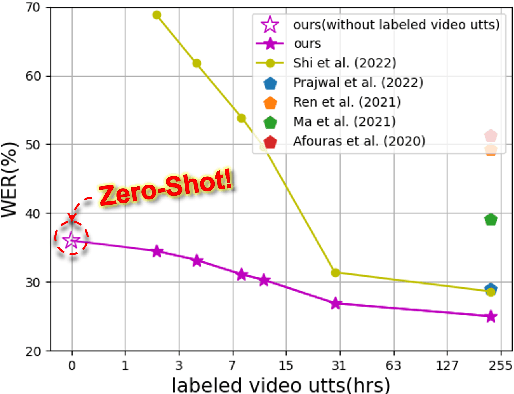
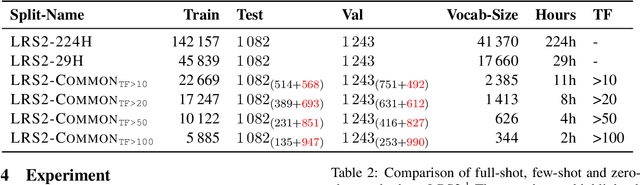
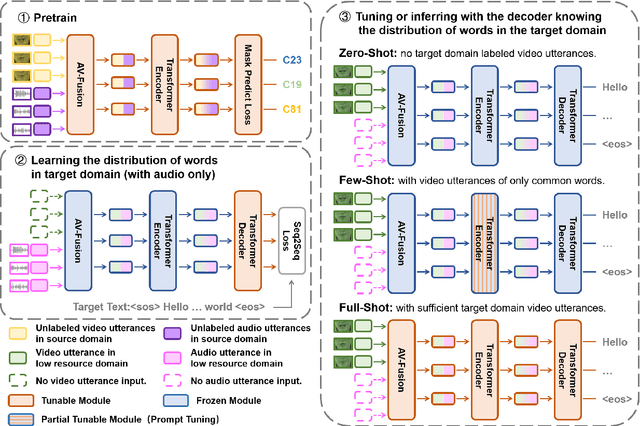
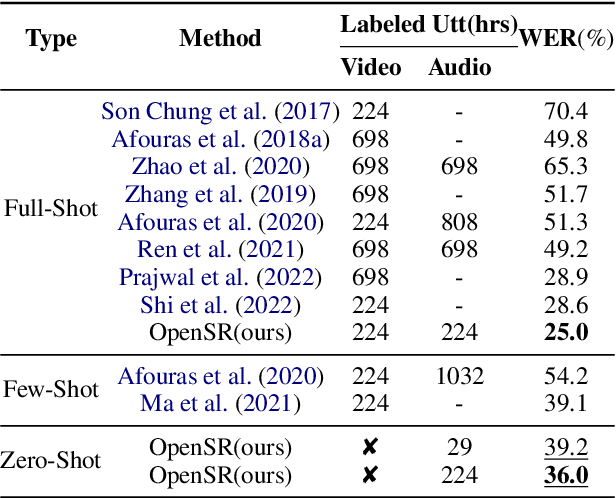
Speech Recognition builds a bridge between the multimedia streaming (audio-only, visual-only or audio-visual) and the corresponding text transcription. However, when training the specific model of new domain, it often gets stuck in the lack of new-domain utterances, especially the labeled visual utterances. To break through this restriction, we attempt to achieve zero-shot modality transfer by maintaining the multi-modality alignment in phoneme space learned with unlabeled multimedia utterances in the high resource domain during the pre-training \cite{shi2022learning}, and propose a training system Open-modality Speech Recognition (\textbf{OpenSR}) that enables the models trained on a single modality (e.g., audio-only) applicable to more modalities (e.g., visual-only and audio-visual). Furthermore, we employ a cluster-based prompt tuning strategy to handle the domain shift for the scenarios with only common words in the new domain utterances. We demonstrate that OpenSR enables modality transfer from one to any in three different settings (zero-, few- and full-shot), and achieves highly competitive zero-shot performance compared to the existing few-shot and full-shot lip-reading methods. To the best of our knowledge, OpenSR achieves the state-of-the-art performance of word error rate in LRS2 on audio-visual speech recognition and lip-reading with 2.7\% and 25.0\%, respectively. The code and demo are available at https://github.com/Exgc/OpenSR.
Hearing Lips in Noise: Universal Viseme-Phoneme Mapping and Transfer for Robust Audio-Visual Speech Recognition
Jun 18, 2023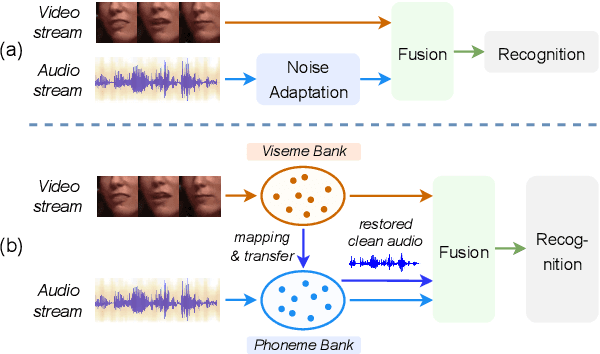
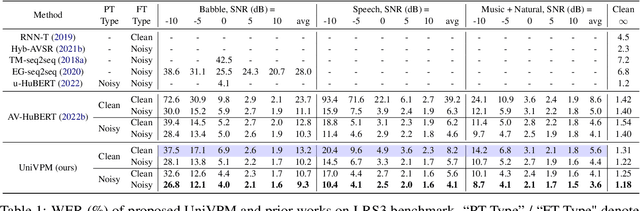
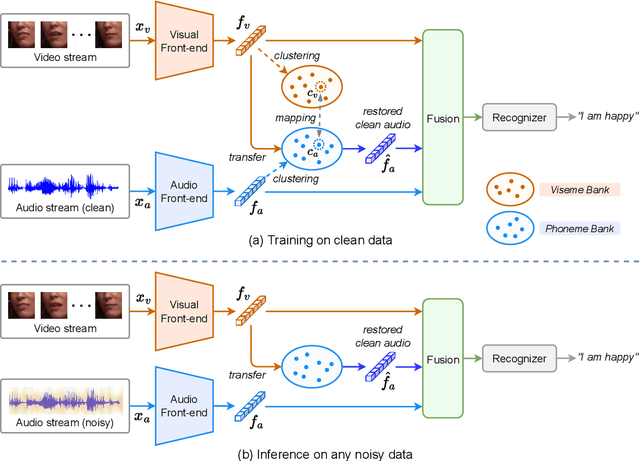
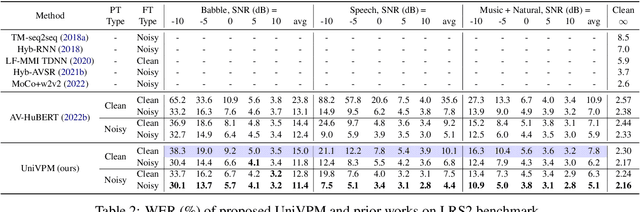
Audio-visual speech recognition (AVSR) provides a promising solution to ameliorate the noise-robustness of audio-only speech recognition with visual information. However, most existing efforts still focus on audio modality to improve robustness considering its dominance in AVSR task, with noise adaptation techniques such as front-end denoise processing. Though effective, these methods are usually faced with two practical challenges: 1) lack of sufficient labeled noisy audio-visual training data in some real-world scenarios and 2) less optimal model generality to unseen testing noises. In this work, we investigate the noise-invariant visual modality to strengthen robustness of AVSR, which can adapt to any testing noises while without dependence on noisy training data, a.k.a., unsupervised noise adaptation. Inspired by human perception mechanism, we propose a universal viseme-phoneme mapping (UniVPM) approach to implement modality transfer, which can restore clean audio from visual signals to enable speech recognition under any noisy conditions. Extensive experiments on public benchmarks LRS3 and LRS2 show that our approach achieves the state-of-the-art under various noisy as well as clean conditions. In addition, we also outperform previous state-of-the-arts on visual speech recognition task.
Findings of the 2023 ML-SUPERB Challenge: Pre-Training and Evaluation over More Languages and Beyond
Oct 09, 2023

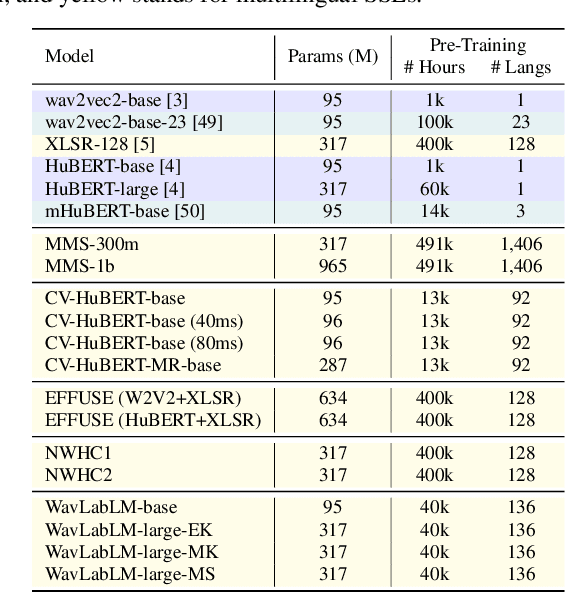
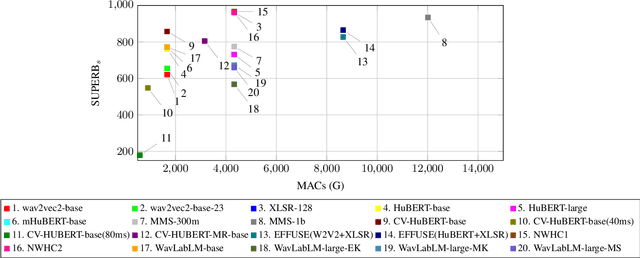
The 2023 Multilingual Speech Universal Performance Benchmark (ML-SUPERB) Challenge expands upon the acclaimed SUPERB framework, emphasizing self-supervised models in multilingual speech recognition and language identification. The challenge comprises a research track focused on applying ML-SUPERB to specific multilingual subjects, a Challenge Track for model submissions, and a New Language Track where language resource researchers can contribute and evaluate their low-resource language data in the context of the latest progress in multilingual speech recognition. The challenge garnered 12 model submissions and 54 language corpora, resulting in a comprehensive benchmark encompassing 154 languages. The findings indicate that merely scaling models is not the definitive solution for multilingual speech tasks, and a variety of speech/voice types present significant challenges in multilingual speech processing.