 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Language-Routing Mixture of Experts for Multilingual and Code-Switching Speech Recognition
Jul 14, 2023
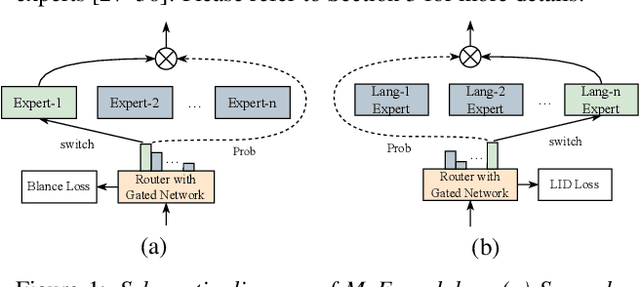
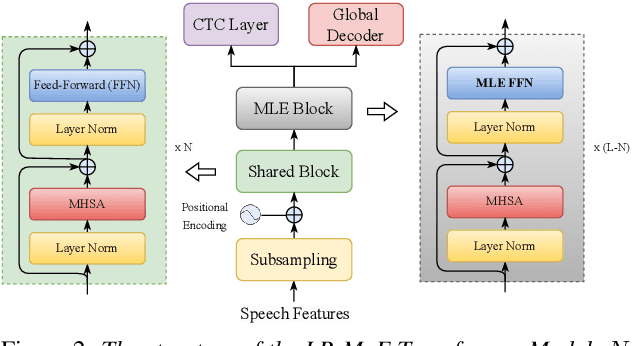
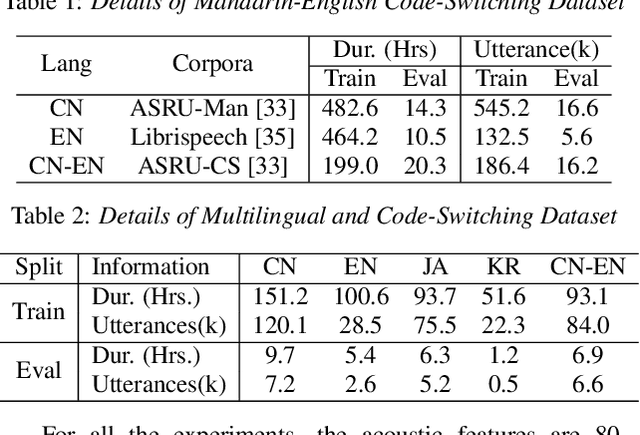
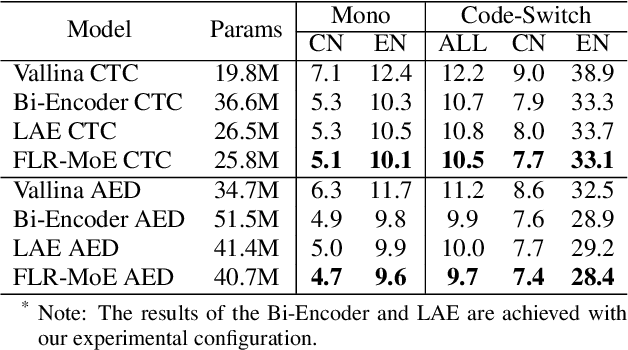
Multilingual speech recognition for both monolingual and code-switching speech is a challenging task. Recently, based on the Mixture of Experts (MoE), many works have made good progress in multilingual and code-switching ASR, but present huge computational complexity with the increase of supported languages. In this work, we propose a computation-efficient network named Language-Routing Mixture of Experts (LR-MoE) for multilingual and code-switching ASR. LR-MoE extracts language-specific representations through the Mixture of Language Experts (MLE), which is guided to learn by a frame-wise language routing mechanism. The weight-shared frame-level language identification (LID) network is jointly trained as the shared pre-router of each MoE layer. Experiments show that the proposed method significantly improves multilingual and code-switching speech recognition performances over baseline with comparable computational efficiency.
Federated Representation Learning for Automatic Speech Recognition
Aug 03, 2023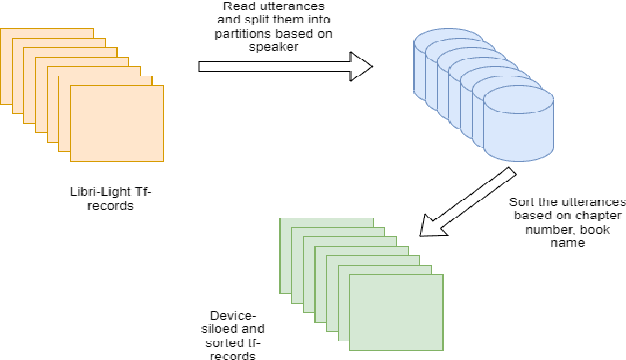
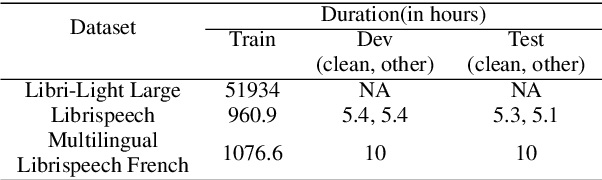
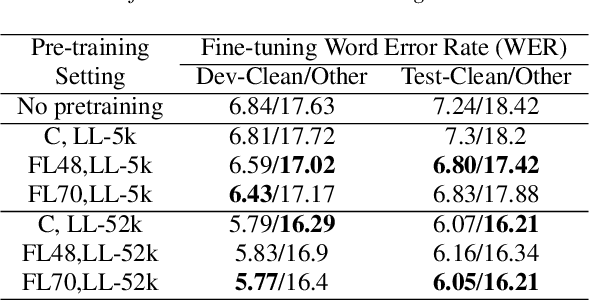
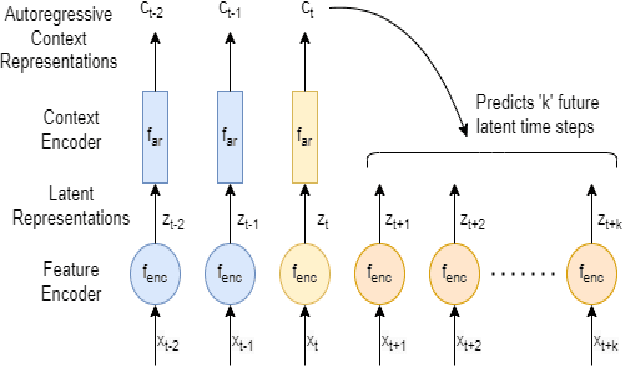
Federated Learning (FL) is a privacy-preserving paradigm, allowing edge devices to learn collaboratively without sharing data. Edge devices like Alexa and Siri are prospective sources of unlabeled audio data that can be tapped to learn robust audio representations. In this work, we bring Self-supervised Learning (SSL) and FL together to learn representations for Automatic Speech Recognition respecting data privacy constraints. We use the speaker and chapter information in the unlabeled speech dataset, Libri-Light, to simulate non-IID speaker-siloed data distributions and pre-train an LSTM encoder with the Contrastive Predictive Coding framework with FedSGD. We show that the pre-trained ASR encoder in FL performs as well as a centrally pre-trained model and produces an improvement of 12-15% (WER) compared to no pre-training. We further adapt the federated pre-trained models to a new language, French, and show a 20% (WER) improvement over no pre-training.
Soft Random Sampling: A Theoretical and Empirical Analysis
Nov 21, 2023Soft random sampling (SRS) is a simple yet effective approach for efficient training of large-scale deep neural networks when dealing with massive data. SRS selects a subset uniformly at random with replacement from the full data set in each epoch. In this paper, we conduct a theoretical and empirical analysis of SRS. First, we analyze its sampling dynamics including data coverage and occupancy. Next, we investigate its convergence with non-convex objective functions and give the convergence rate. Finally, we provide its generalization performance. We empirically evaluate SRS for image recognition on CIFAR10 and automatic speech recognition on Librispeech and an in-house payload dataset to demonstrate its effectiveness. Compared to existing coreset-based data selection methods, SRS offers a better accuracy-efficiency trade-off. Especially on real-world industrial scale data sets, it is shown to be a powerful training strategy with significant speedup and competitive performance with almost no additional computing cost.
Text-Only Domain Adaptation for End-to-End Speech Recognition through Down-Sampling Acoustic Representation
Sep 04, 2023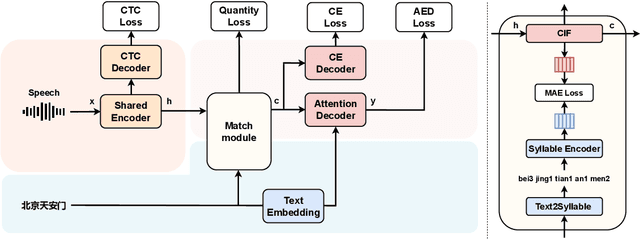
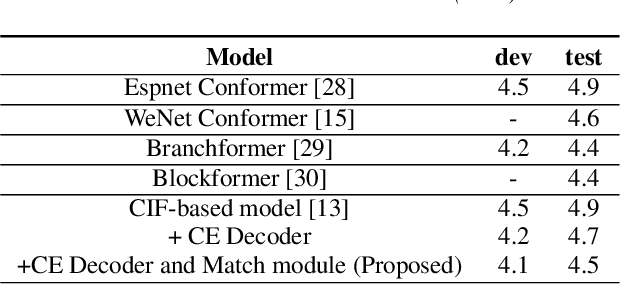
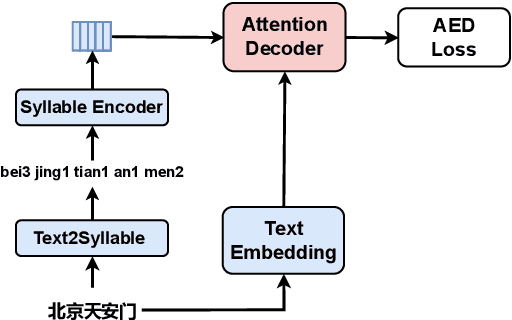

Mapping two modalities, speech and text, into a shared representation space, is a research topic of using text-only data to improve end-to-end automatic speech recognition (ASR) performance in new domains. However, the length of speech representation and text representation is inconsistent. Although the previous method up-samples the text representation to align with acoustic modality, it may not match the expected actual duration. In this paper, we proposed novel representations match strategy through down-sampling acoustic representation to align with text modality. By introducing a continuous integrate-and-fire (CIF) module generating acoustic representations consistent with token length, our ASR model can learn unified representations from both modalities better, allowing for domain adaptation using text-only data of the target domain. Experiment results of new domain data demonstrate the effectiveness of the proposed method.
Boosting Norwegian Automatic Speech Recognition
Jul 04, 2023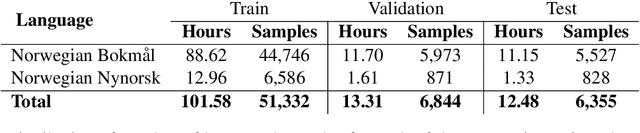

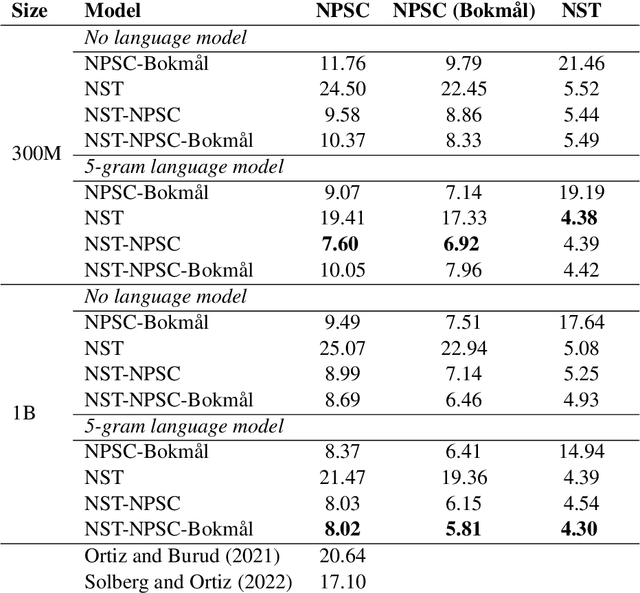
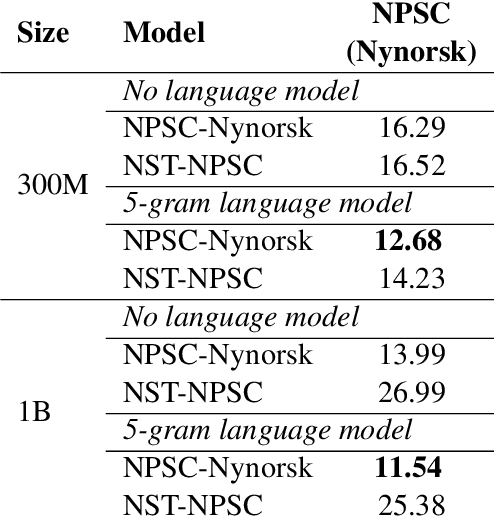
In this paper, we present several baselines for automatic speech recognition (ASR) models for the two official written languages in Norway: Bokm{\aa}l and Nynorsk. We compare the performance of models of varying sizes and pre-training approaches on multiple Norwegian speech datasets. Additionally, we measure the performance of these models against previous state-of-the-art ASR models, as well as on out-of-domain datasets. We improve the state of the art on the Norwegian Parliamentary Speech Corpus (NPSC) from a word error rate (WER) of 17.10\% to 7.60\%, with models achieving 5.81\% for Bokm{\aa}l and 11.54\% for Nynorsk. We also discuss the challenges and potential solutions for further improving ASR models for Norwegian.
* 10 pages, 10 figures. Published as Proceedings NoDaLiDa 2023, pages 555--564
Adaptation of Whisper models to child speech recognition
Jul 24, 2023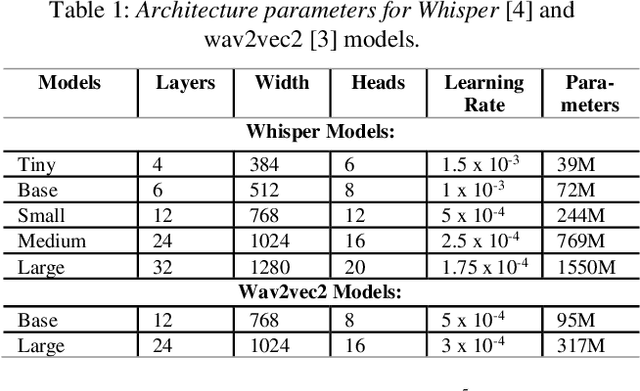
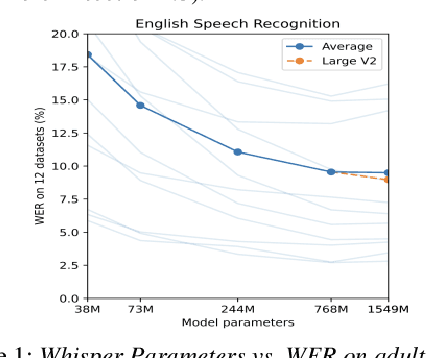
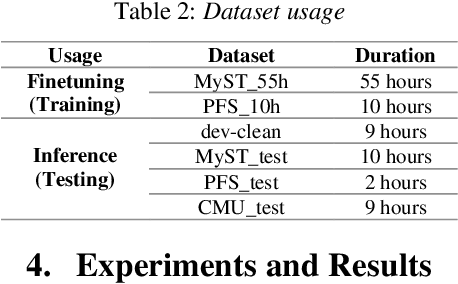
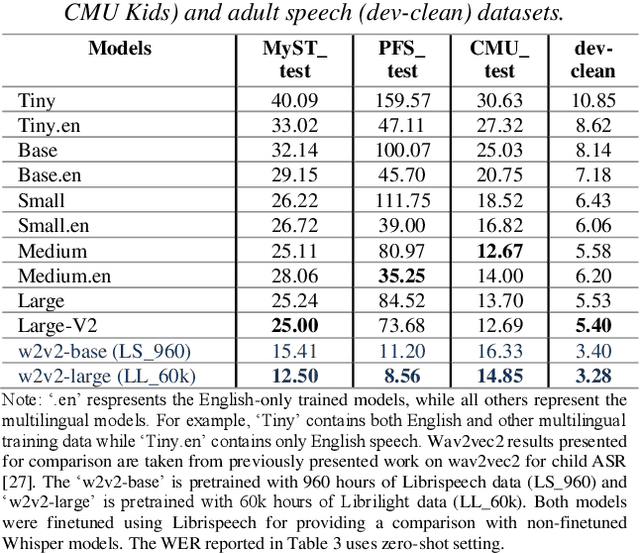
Automatic Speech Recognition (ASR) systems often struggle with transcribing child speech due to the lack of large child speech datasets required to accurately train child-friendly ASR models. However, there are huge amounts of annotated adult speech datasets which were used to create multilingual ASR models, such as Whisper. Our work aims to explore whether such models can be adapted to child speech to improve ASR for children. In addition, we compare Whisper child-adaptations with finetuned self-supervised models, such as wav2vec2. We demonstrate that finetuning Whisper on child speech yields significant improvements in ASR performance on child speech, compared to non finetuned Whisper models. Additionally, utilizing self-supervised Wav2vec2 models that have been finetuned on child speech outperforms Whisper finetuning.
Harnessing the Zero-Shot Power of Instruction-Tuned Large Language Model in End-to-End Speech Recognition
Sep 19, 2023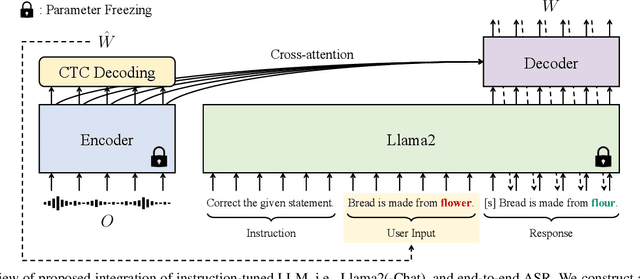
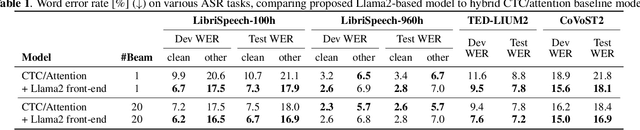
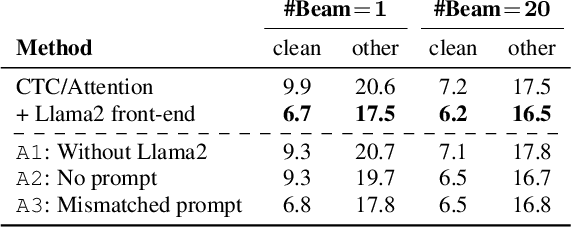
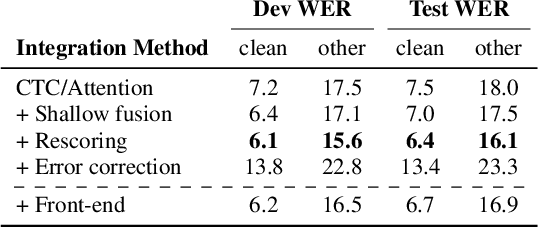
We present a novel integration of an instruction-tuned large language model (LLM) and end-to-end automatic speech recognition (ASR). Modern LLMs can perform a wide range of linguistic tasks within zero-shot learning when provided with a precise instruction or a prompt to guide the text generation process towards the desired task. We explore using this zero-shot capability of LLMs to extract linguistic information that can contribute to improving ASR performance. Specifically, we direct an LLM to correct grammatical errors in an ASR hypothesis and harness the embedded linguistic knowledge to conduct end-to-end ASR. The proposed model is built on the hybrid connectionist temporal classification (CTC) and attention architecture, where an instruction-tuned LLM (i.e., Llama2) is employed as a front-end of the decoder. An ASR hypothesis, subject to correction, is obtained from the encoder via CTC decoding, which is then fed into the LLM along with an instruction. The decoder subsequently takes as input the LLM embeddings to perform sequence generation, incorporating acoustic information from the encoder output. Experimental results and analyses demonstrate that the proposed integration yields promising performance improvements, and our approach largely benefits from LLM-based rescoring.
Optimized Tokenization for Transcribed Error Correction
Oct 16, 2023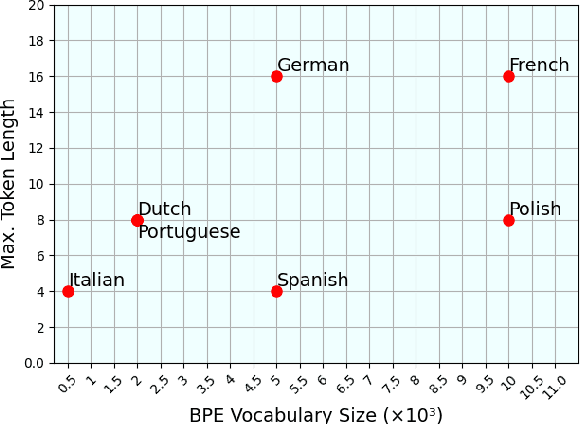
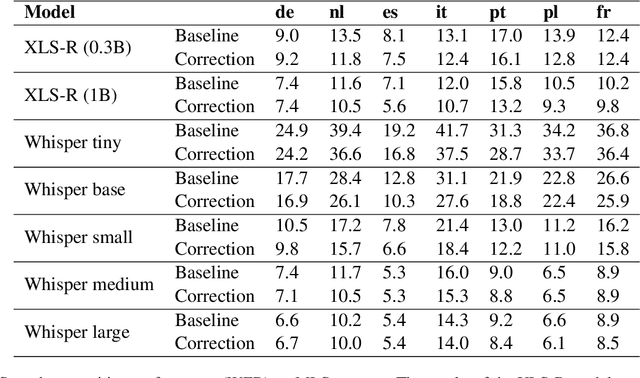
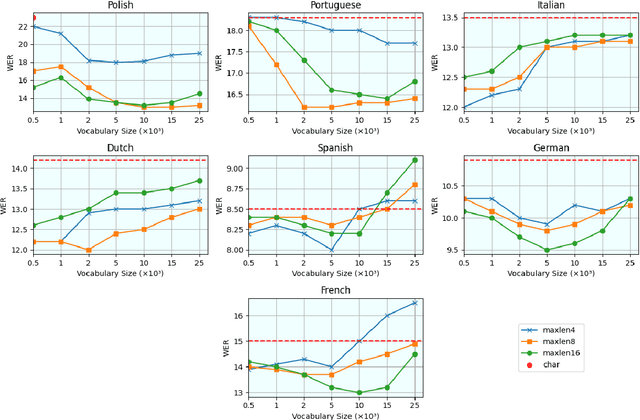
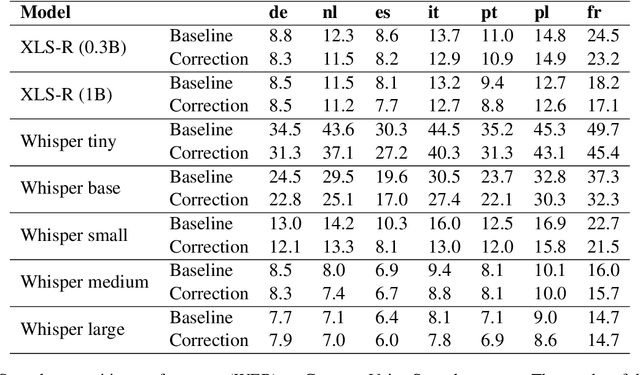
The challenges facing speech recognition systems, such as variations in pronunciations, adverse audio conditions, and the scarcity of labeled data, emphasize the necessity for a post-processing step that corrects recurring errors. Previous research has shown the advantages of employing dedicated error correction models, yet training such models requires large amounts of labeled data which is not easily obtained. To overcome this limitation, synthetic transcribed-like data is often utilized, however, bridging the distribution gap between transcribed errors and synthetic noise is not trivial. In this paper, we demonstrate that the performance of correction models can be significantly increased by training solely using synthetic data. Specifically, we empirically show that: (1) synthetic data generated using the error distribution derived from a set of transcribed data outperforms the common approach of applying random perturbations; (2) applying language-specific adjustments to the vocabulary of a BPE tokenizer strike a balance between adapting to unseen distributions and retaining knowledge of transcribed errors. We showcase the benefits of these key observations, and evaluate our approach using multiple languages, speech recognition systems and prominent speech recognition datasets.
Improving Large-scale Deep Biasing with Phoneme Features and Text-only Data in Streaming Transducer
Nov 15, 2023Deep biasing for the Transducer can improve the recognition performance of rare words or contextual entities, which is essential in practical applications, especially for streaming Automatic Speech Recognition (ASR). However, deep biasing with large-scale rare words remains challenging, as the performance drops significantly when more distractors exist and there are words with similar grapheme sequences in the bias list. In this paper, we combine the phoneme and textual information of rare words in Transducers to distinguish words with similar pronunciation or spelling. Moreover, the introduction of training with text-only data containing more rare words benefits large-scale deep biasing. The experiments on the LibriSpeech corpus demonstrate that the proposed method achieves state-of-the-art performance on rare word error rate for different scales and levels of bias lists.