 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
LanSER: Language-Model Supported Speech Emotion Recognition
Sep 07, 2023
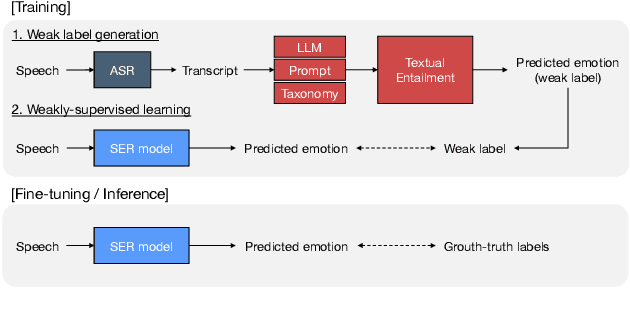


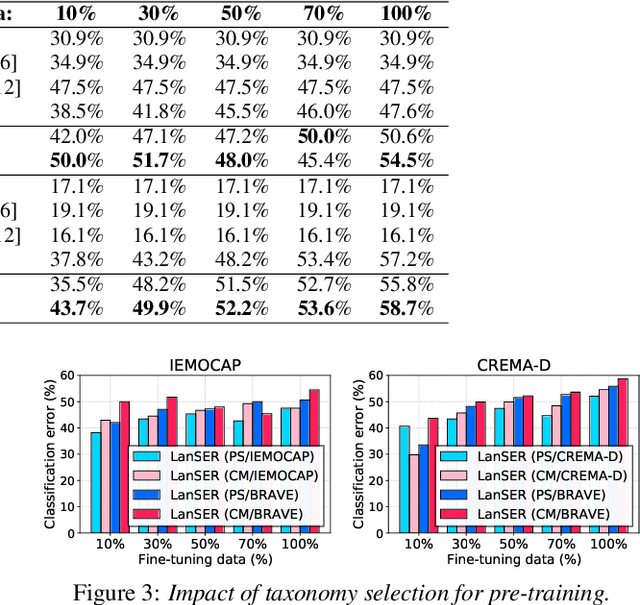
Speech emotion recognition (SER) models typically rely on costly human-labeled data for training, making scaling methods to large speech datasets and nuanced emotion taxonomies difficult. We present LanSER, a method that enables the use of unlabeled data by inferring weak emotion labels via pre-trained large language models through weakly-supervised learning. For inferring weak labels constrained to a taxonomy, we use a textual entailment approach that selects an emotion label with the highest entailment score for a speech transcript extracted via automatic speech recognition. Our experimental results show that models pre-trained on large datasets with this weak supervision outperform other baseline models on standard SER datasets when fine-tuned, and show improved label efficiency. Despite being pre-trained on labels derived only from text, we show that the resulting representations appear to model the prosodic content of speech.
* Presented at INTERSPEECH 2023
Multimodal Data and Resource Efficient Device-Directed Speech Detection with Large Foundation Models
Dec 06, 2023Interactions with virtual assistants typically start with a trigger phrase followed by a command. In this work, we explore the possibility of making these interactions more natural by eliminating the need for a trigger phrase. Our goal is to determine whether a user addressed the virtual assistant based on signals obtained from the streaming audio recorded by the device microphone. We address this task by combining 1-best hypotheses and decoder signals from an automatic speech recognition system with acoustic representations from an audio encoder as input features to a large language model (LLM). In particular, we are interested in data and resource efficient systems that require only a small amount of training data and can operate in scenarios with only a single frozen LLM available on a device. For this reason, our model is trained on 80k or less examples of multimodal data using a combination of low-rank adaptation and prefix tuning. We compare the proposed system to unimodal baselines and show that the multimodal approach achieves lower equal-error-rates (EERs), while using only a fraction of the training data. We also show that low-dimensional specialized audio representations lead to lower EERs than high-dimensional general audio representations.
1-step Speech Processing and Understanding Using CTC Loss
Nov 08, 2023Recent studies have made some progress in refining end-to-end (E2E) speech recognition encoders by applying Connectionist Temporal Classification (CTC) loss to enhance named entity recognition within transcriptions. However, these methods have been constrained by their exclusive use of the ASCII character set, allowing only a limited array of semantic labels. Our proposed solution extends the E2E automatic speech recognition (ASR) system's vocabulary by adding a set of unused placeholder symbols, conceptually akin to the <pad> tokens used in sequence modeling. These placeholders are then assigned to represent semantic tags and are integrated into the transcription process as distinct tokens. We demonstrate notable improvements in entity tagging, intent discernment, and transcription accuracy on the SLUE benchmark and yields results that are on par with those for the SLURP dataset. Additionally, we provide a visual analysis of the system's proficiency in accurately pinpointing meaningful tokens over time, illustrating the enhancement in transcription quality through the utilization of supplementary semantic tags.
PMMTalk: Speech-Driven 3D Facial Animation from Complementary Pseudo Multi-modal Features
Dec 05, 2023Speech-driven 3D facial animation has improved a lot recently while most related works only utilize acoustic modality and neglect the influence of visual and textual cues, leading to unsatisfactory results in terms of precision and coherence. We argue that visual and textual cues are not trivial information. Therefore, we present a novel framework, namely PMMTalk, using complementary Pseudo Multi-Modal features for improving the accuracy of facial animation. The framework entails three modules: PMMTalk encoder, cross-modal alignment module, and PMMTalk decoder. Specifically, the PMMTalk encoder employs the off-the-shelf talking head generation architecture and speech recognition technology to extract visual and textual information from speech, respectively. Subsequently, the cross-modal alignment module aligns the audio-image-text features at temporal and semantic levels. Then PMMTalk decoder is employed to predict lip-syncing facial blendshape coefficients. Contrary to prior methods, PMMTalk only requires an additional random reference face image but yields more accurate results. Additionally, it is artist-friendly as it seamlessly integrates into standard animation production workflows by introducing facial blendshape coefficients. Finally, given the scarcity of 3D talking face datasets, we introduce a large-scale 3D Chinese Audio-Visual Facial Animation (3D-CAVFA) dataset. Extensive experiments and user studies show that our approach outperforms the state of the art. We recommend watching the supplementary video.
1SPU: 1-step Speech Processing Unit
Nov 10, 2023Recent studies have made some progress in refining end-to-end (E2E) speech recognition encoders by applying Connectionist Temporal Classification (CTC) loss to enhance named entity recognition within transcriptions. However, these methods have been constrained by their exclusive use of the ASCII character set, allowing only a limited array of semantic labels. We propose 1SPU, a 1-step Speech Processing Unit which can recognize speech events (e.g: speaker change) or an NL event (Intent, Emotion) while also transcribing vocal content. It extends the E2E automatic speech recognition (ASR) system's vocabulary by adding a set of unused placeholder symbols, conceptually akin to the <pad> tokens used in sequence modeling. These placeholders are then assigned to represent semantic events (in form of tags) and are integrated into the transcription process as distinct tokens. We demonstrate notable improvements on the SLUE benchmark and yields results that are on par with those for the SLURP dataset. Additionally, we provide a visual analysis of the system's proficiency in accurately pinpointing meaningful tokens over time, illustrating the enhancement in transcription quality through the utilization of supplementary semantic tags.
Training dynamic models using early exits for automatic speech recognition on resource-constrained devices
Sep 18, 2023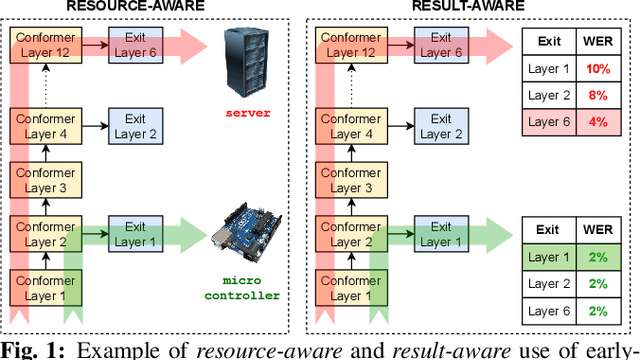
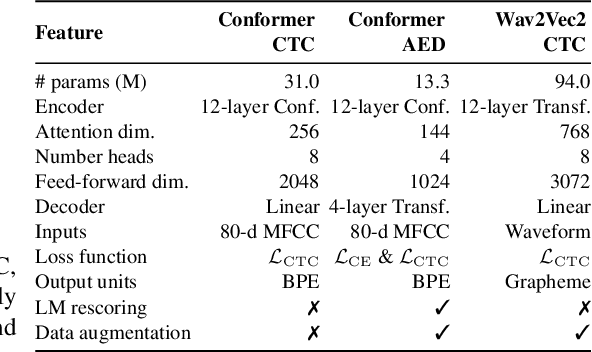
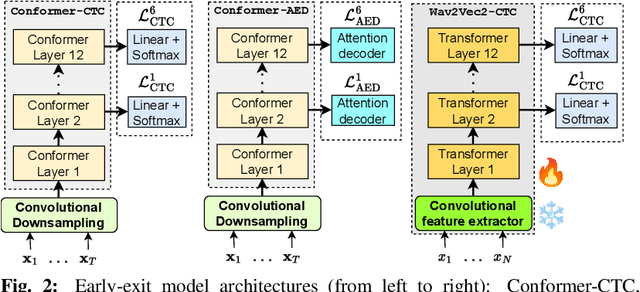
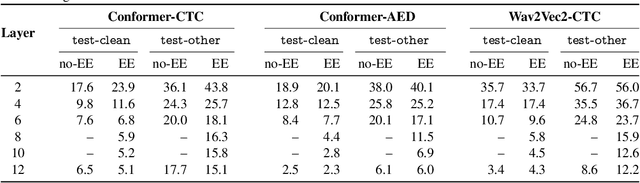
The possibility of dynamically modifying the computational load of neural models at inference time is crucial for on-device processing, where computational power is limited and time-varying. Established approaches for neural model compression exist, but they provide architecturally static models. In this paper, we investigate the use of early-exit architectures, that rely on intermediate exit branches, applied to large-vocabulary speech recognition. This allows for the development of dynamic models that adjust their computational cost to the available resources and recognition performance. Unlike previous works, besides using pre-trained backbones we also train the model from scratch with an early-exit architecture. Experiments on public datasets show that early-exit architectures from scratch not only preserve performance levels when using fewer encoder layers, but also improve task accuracy as compared to using single-exit models or using pre-trained models. Additionally, we investigate an exit selection strategy based on posterior probabilities as an alternative to frame-based entropy.
FreqFed: A Frequency Analysis-Based Approach for Mitigating Poisoning Attacks in Federated Learning
Dec 07, 2023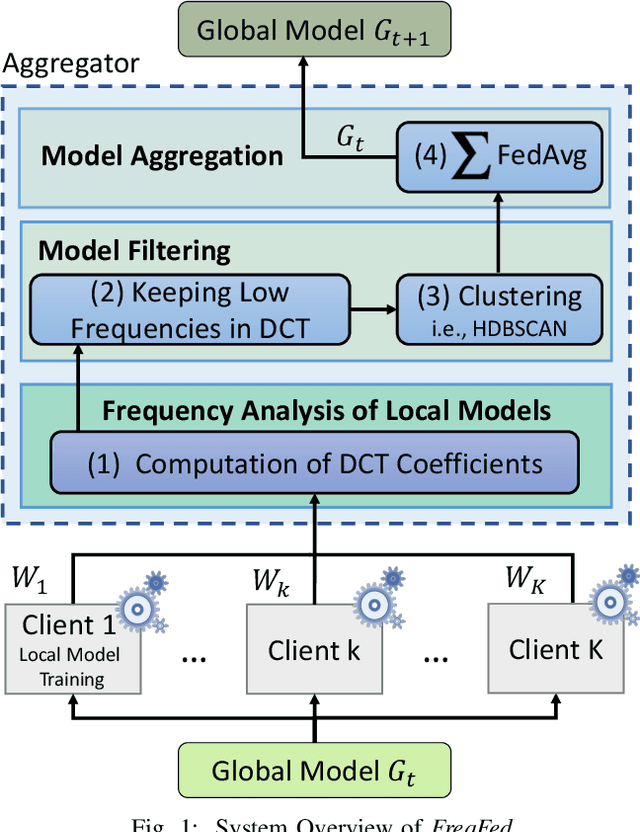
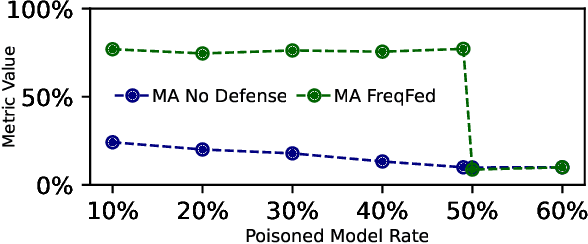

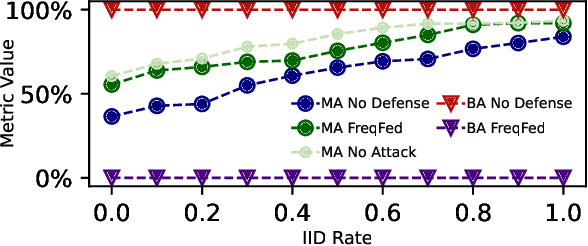
Federated learning (FL) is a collaborative learning paradigm allowing multiple clients to jointly train a model without sharing their training data. However, FL is susceptible to poisoning attacks, in which the adversary injects manipulated model updates into the federated model aggregation process to corrupt or destroy predictions (untargeted poisoning) or implant hidden functionalities (targeted poisoning or backdoors). Existing defenses against poisoning attacks in FL have several limitations, such as relying on specific assumptions about attack types and strategies or data distributions or not sufficiently robust against advanced injection techniques and strategies and simultaneously maintaining the utility of the aggregated model. To address the deficiencies of existing defenses, we take a generic and completely different approach to detect poisoning (targeted and untargeted) attacks. We present FreqFed, a novel aggregation mechanism that transforms the model updates (i.e., weights) into the frequency domain, where we can identify the core frequency components that inherit sufficient information about weights. This allows us to effectively filter out malicious updates during local training on the clients, regardless of attack types, strategies, and clients' data distributions. We extensively evaluate the efficiency and effectiveness of FreqFed in different application domains, including image classification, word prediction, IoT intrusion detection, and speech recognition. We demonstrate that FreqFed can mitigate poisoning attacks effectively with a negligible impact on the utility of the aggregated model.
Convoifilter: A case study of doing cocktail party speech recognition
Aug 22, 2023
This paper presents an end-to-end model designed to improve automatic speech recognition (ASR) for a particular speaker in a crowded, noisy environment. The model utilizes a single-channel speech enhancement module that isolates the speaker's voice from background noise, along with an ASR module. Through this approach, the model is able to decrease the word error rate (WER) of ASR from 80% to 26.4%. Typically, these two components are adjusted independently due to variations in data requirements. However, speech enhancement can create anomalies that decrease ASR efficiency. By implementing a joint fine-tuning strategy, the model can reduce the WER from 26.4% in separate tuning to 14.5% in joint tuning.
The CHiME-7 Challenge: System Description and Performance of NeMo Team's DASR System
Oct 18, 2023We present the NVIDIA NeMo team's multi-channel speech recognition system for the 7th CHiME Challenge Distant Automatic Speech Recognition (DASR) Task, focusing on the development of a multi-channel, multi-speaker speech recognition system tailored to transcribe speech from distributed microphones and microphone arrays. The system predominantly comprises of the following integral modules: the Speaker Diarization Module, Multi-channel Audio Front-End Processing Module, and the ASR Module. These components collectively establish a cascading system, meticulously processing multi-channel and multi-speaker audio input. Moreover, this paper highlights the comprehensive optimization process that significantly enhanced our system's performance. Our team's submission is largely based on NeMo toolkits and will be publicly available.
Indonesian Automatic Speech Recognition with XLSR-53
Aug 20, 2023
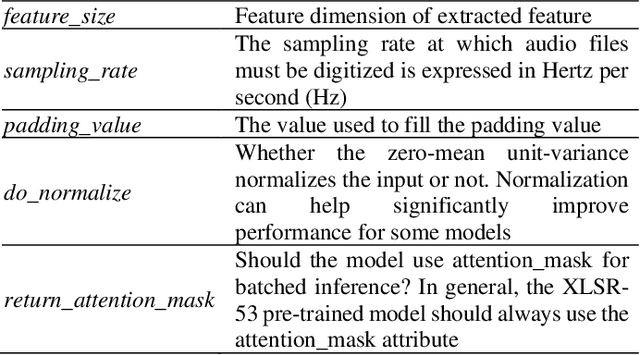
This study focuses on the development of Indonesian Automatic Speech Recognition (ASR) using the XLSR-53 pre-trained model, the XLSR stands for cross-lingual speech representations. The use of this XLSR-53 pre-trained model is to significantly reduce the amount of training data in non-English languages required to achieve a competitive Word Error Rate (WER). The total amount of data used in this study is 24 hours, 18 minutes, and 1 second: (1) TITML-IDN 14 hours and 31 minutes; (2) Magic Data 3 hours and 33 minutes; and (3) Common Voice 6 hours, 14 minutes, and 1 second. With a WER of 20%, the model built in this study can compete with similar models using the Common Voice dataset split test. WER can be decreased by around 8% using a language model, resulted in WER from 20% to 12%. Thus, the results of this study have succeeded in perfecting previous research in contributing to the creation of a better Indonesian ASR with a smaller amount of data.