 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Investigations on End-to-End Audiovisual Fusion
Apr 30, 2018

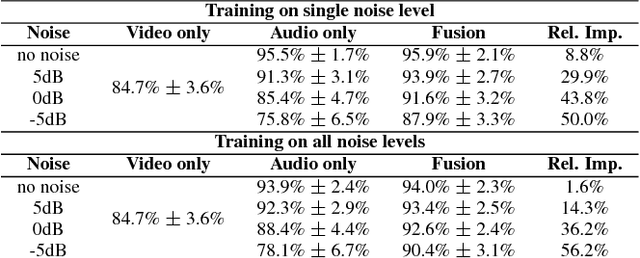
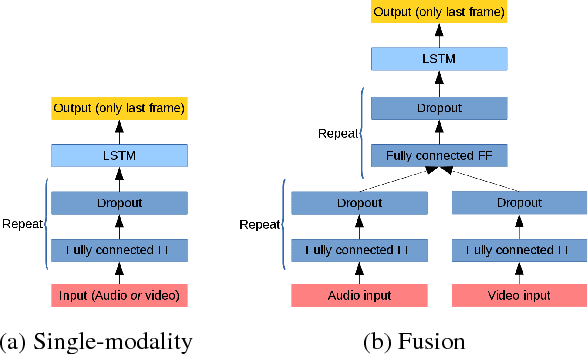

Audiovisual speech recognition (AVSR) is a method to alleviate the adverse effect of noise in the acoustic signal. Leveraging recent developments in deep neural network-based speech recognition, we present an AVSR neural network architecture which is trained end-to-end, without the need to separately model the process of decision fusion as in conventional (e.g. HMM-based) systems. The fusion system outperforms single-modality recognition under all noise conditions. Investigation of the saliency of the input features shows that the neural network automatically adapts to different noise levels in the acoustic signal.
* Published at ICASSP 2018
Neural model robustness for skill routing in large-scale conversational AI systems: A design choice exploration
Mar 04, 2021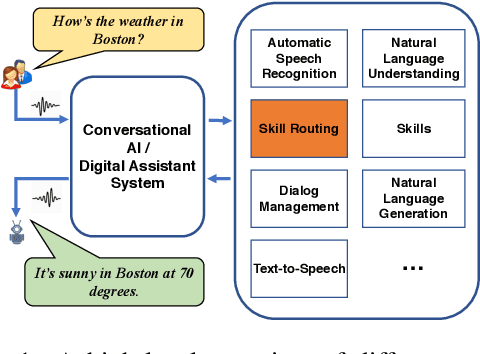
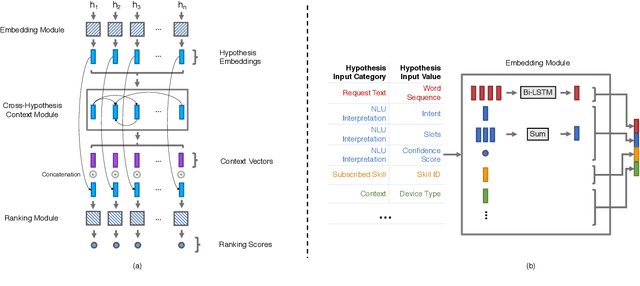
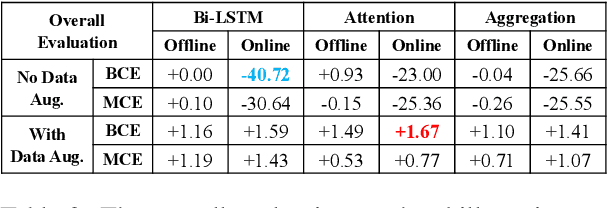
Current state-of-the-art large-scale conversational AI or intelligent digital assistant systems in industry comprises a set of components such as Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU). For some of these systems that leverage a shared NLU ontology (e.g., a centralized intent/slot schema), there exists a separate skill routing component to correctly route a request to an appropriate skill, which is either a first-party or third-party application that actually executes on a user request. The skill routing component is needed as there are thousands of skills that can either subscribe to the same intent and/or subscribe to an intent under specific contextual conditions (e.g., device has a screen). Ensuring model robustness or resilience in the skill routing component is an important problem since skills may dynamically change their subscription in the ontology after the skill routing model has been deployed to production. We show how different modeling design choices impact the model robustness in the context of skill routing on a state-of-the-art commercial conversational AI system, specifically on the choices around data augmentation, model architecture, and optimization method. We show that applying data augmentation can be a very effective and practical way to drastically improve model robustness.
Iterative Compression of End-to-End ASR Model using AutoML
Aug 06, 2020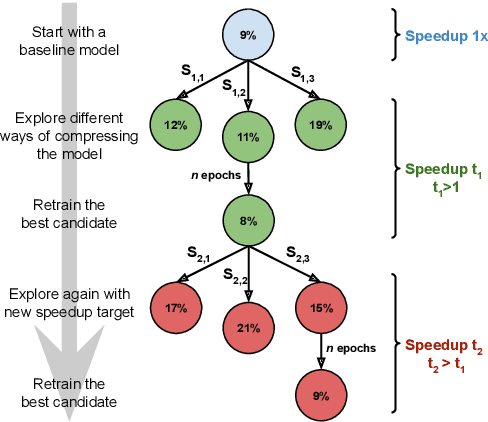
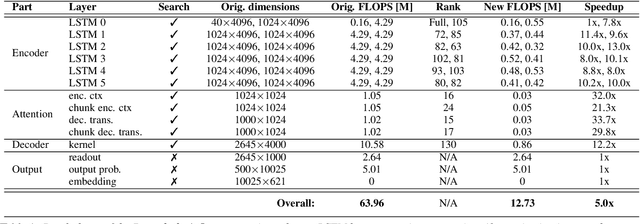
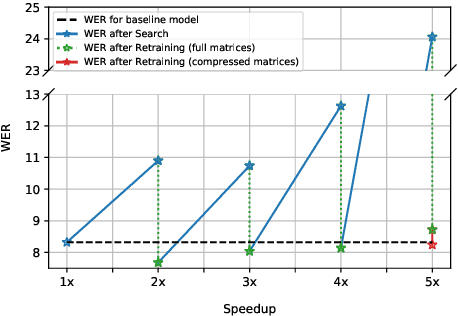
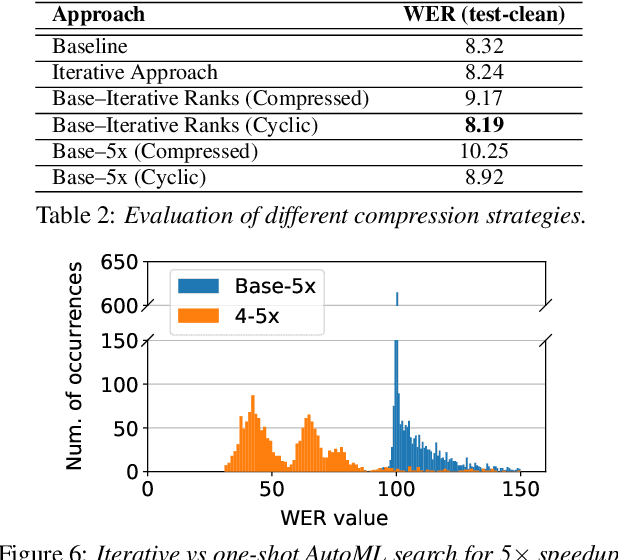
Increasing demand for on-device Automatic Speech Recognition (ASR) systems has resulted in renewed interests in developing automatic model compression techniques. Past research have shown that AutoML-based Low Rank Factorization (LRF) technique, when applied to an end-to-end Encoder-Attention-Decoder style ASR model, can achieve a speedup of up to 3.7x, outperforming laborious manual rank-selection approaches. However, we show that current AutoML-based search techniques only work up to a certain compression level, beyond which they fail to produce compressed models with acceptable word error rates (WER). In this work, we propose an iterative AutoML-based LRF approach that achieves over 5x compression without degrading the WER, thereby advancing the state-of-the-art in ASR compression.
Unsupervised Cross-Domain Singing Voice Conversion
Aug 06, 2020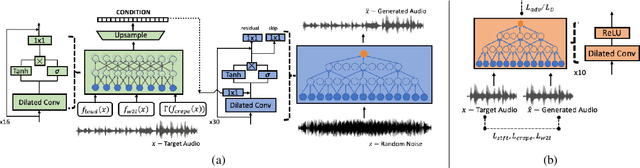
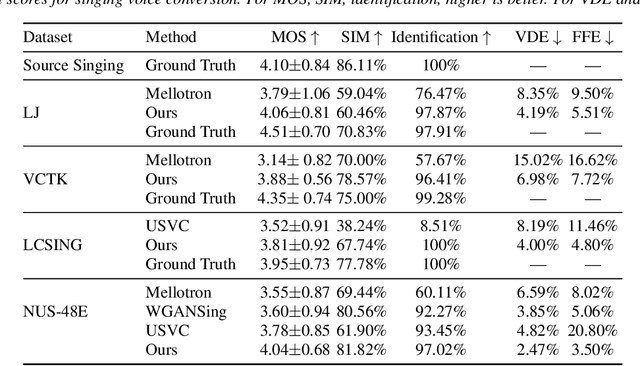
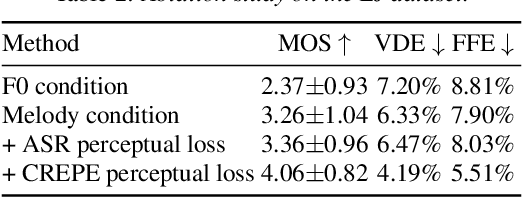
We present a wav-to-wav generative model for the task of singing voice conversion from any identity. Our method utilizes both an acoustic model, trained for the task of automatic speech recognition, together with melody extracted features to drive a waveform-based generator. The proposed generative architecture is invariant to the speaker's identity and can be trained to generate target singers from unlabeled training data, using either speech or singing sources. The model is optimized in an end-to-end fashion without any manual supervision, such as lyrics, musical notes or parallel samples. The proposed approach is fully-convolutional and can generate audio in real-time. Experiments show that our method significantly outperforms the baseline methods while generating convincingly better audio samples than alternative attempts.
A New Amharic Speech Emotion Dataset and Classification Benchmark
Jan 07, 2022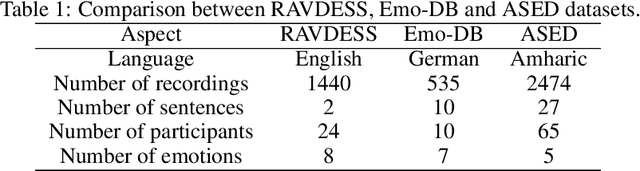
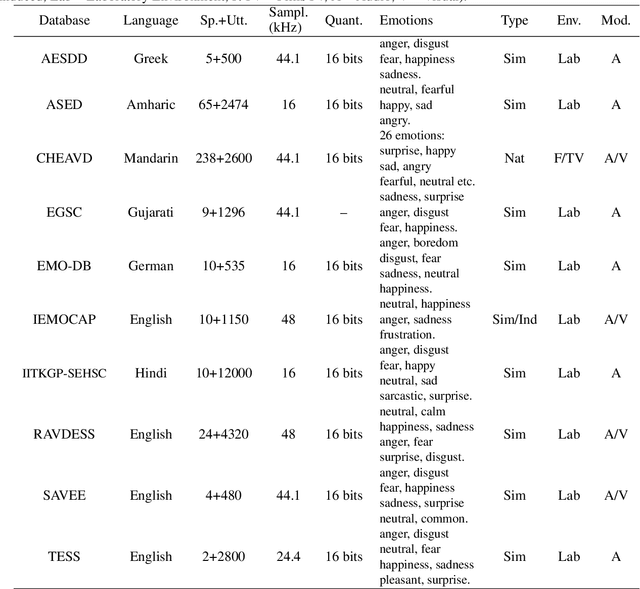


In this paper we present the Amharic Speech Emotion Dataset (ASED), which covers four dialects (Gojjam, Wollo, Shewa and Gonder) and five different emotions (neutral, fearful, happy, sad and angry). We believe it is the first Speech Emotion Recognition (SER) dataset for the Amharic language. 65 volunteer participants, all native speakers, recorded 2,474 sound samples, two to four seconds in length. Eight judges assigned emotions to the samples with high agreement level (Fleiss kappa = 0.8). The resulting dataset is freely available for download. Next, we developed a four-layer variant of the well-known VGG model which we call VGGb. Three experiments were then carried out using VGGb for SER, using ASED. First, we investigated whether Mel-spectrogram features or Mel-frequency Cepstral coefficient (MFCC) features work best for Amharic. This was done by training two VGGb SER models on ASED, one using Mel-spectrograms and the other using MFCC. Four forms of training were tried, standard cross-validation, and three variants based on sentences, dialects and speaker groups. Thus, a sentence used for training would not be used for testing, and the same for a dialect and speaker group. The conclusion was that MFCC features are superior under all four training schemes. MFCC was therefore adopted for Experiment 2, where VGGb and three other existing models were compared on ASED: RESNet50, Alex-Net and LSTM. VGGb was found to have very good accuracy (90.73%) as well as the fastest training time. In Experiment 3, the performance of VGGb was compared when trained on two existing SER datasets, RAVDESS (English) and EMO-DB (German) as well as on ASED (Amharic). Results are comparable across these languages, with ASED being the highest. This suggests that VGGb can be successfully applied to other languages. We hope that ASED will encourage researchers to experiment with other models for Amharic SER.
Detecting Audio Attacks on ASR Systems with Dropout Uncertainty
Jun 02, 2020
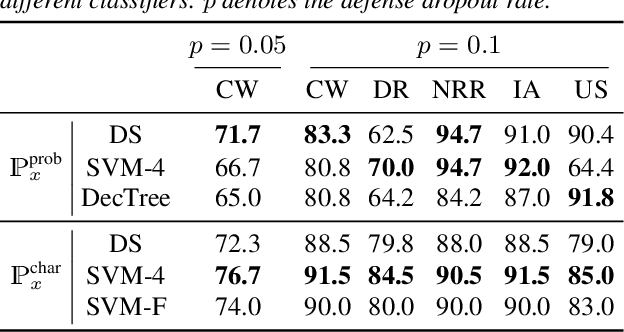
Various adversarial audio attacks have recently been developed to fool automatic speech recognition (ASR) systems. We here propose a defense against such attacks based on the uncertainty introduced by dropout in neural networks. We show that our defense is able to detect attacks created through optimized perturbations and frequency masking on a state-of-the-art end-to-end ASR system. Furthermore, the defense can be made robust against attacks that are immune to noise reduction. We test our defense on Mozilla's CommonVoice dataset, the UrbanSound dataset, and an excerpt of the LibriSpeech dataset, showing that it achieves high detection accuracy in a wide range of scenarios.
Continuous Speech Separation with Ad Hoc Microphone Arrays
Mar 03, 2021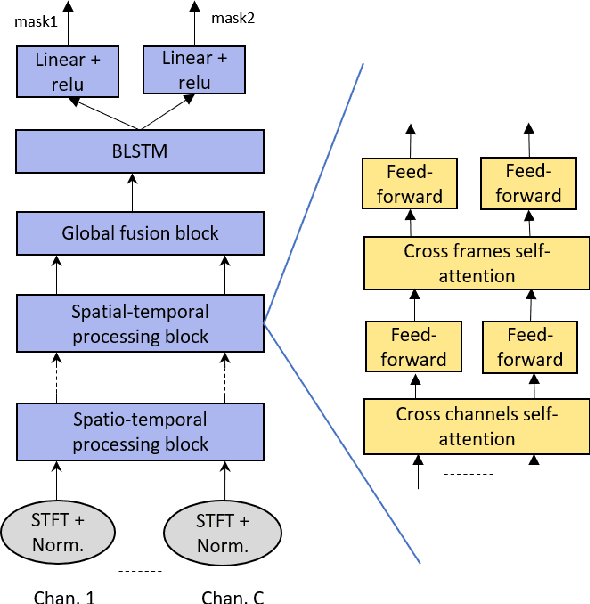

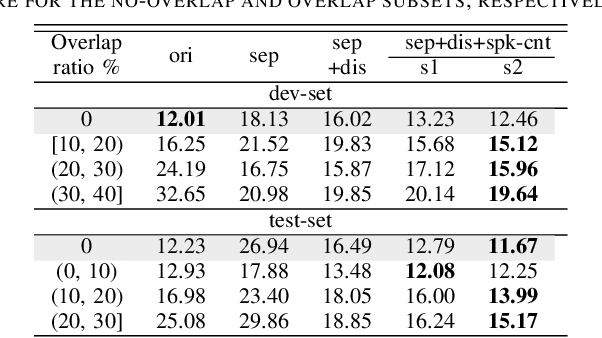
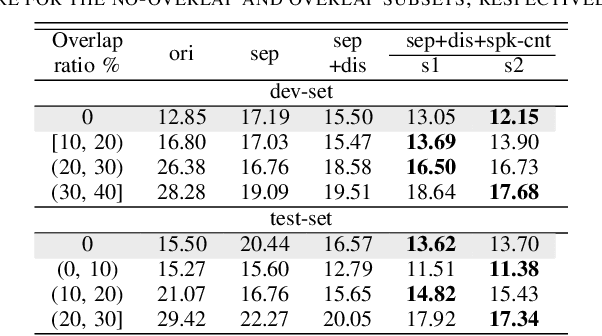
Speech separation has been shown effective for multi-talker speech recognition. Under the ad hoc microphone array setup where the array consists of spatially distributed asynchronous microphones, additional challenges must be overcome as the geometry and number of microphones are unknown beforehand. Prior studies show, with a spatial-temporalinterleaving structure, neural networks can efficiently utilize the multi-channel signals of the ad hoc array. In this paper, we further extend this approach to continuous speech separation. Several techniques are introduced to enable speech separation for real continuous recordings. First, we apply a transformer-based network for spatio-temporal modeling of the ad hoc array signals. In addition, two methods are proposed to mitigate a speech duplication problem during single talker segments, which seems more severe in the ad hoc array scenarios. One method is device distortion simulation for reducing the acoustic mismatch between simulated training data and real recordings. The other is speaker counting to detect the single speaker segments and merge the output signal channels. Experimental results for AdHoc-LibiCSS, a new dataset consisting of continuous recordings of concatenated LibriSpeech utterances obtained by multiple different devices, show the proposed separation method can significantly improve the ASR accuracy for overlapped speech with little performance degradation for single talker segments.
Multi-channel Multi-frame ADL-MVDR for Target Speech Separation
Dec 24, 2020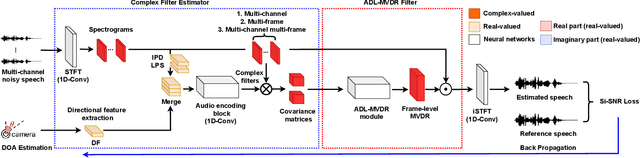
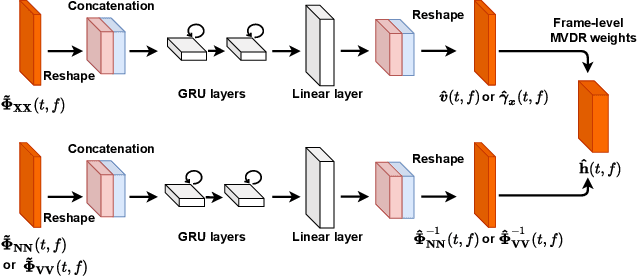
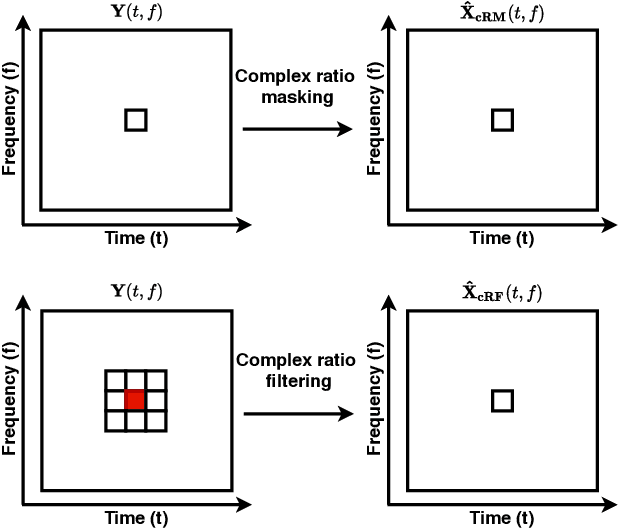
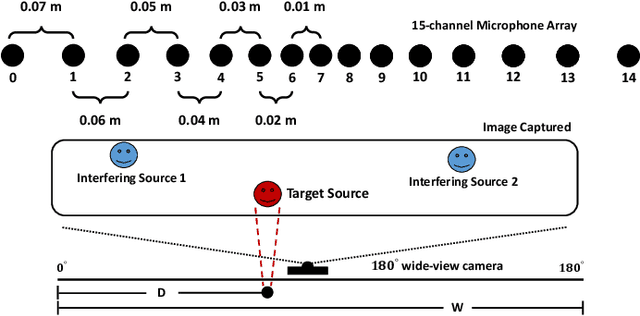
Many purely neural network based speech separation approaches have been proposed that greatly improve objective assessment scores, but they often introduce nonlinear distortions that are harmful to automatic speech recognition (ASR). Minimum variance distortionless response (MVDR) filters strive to remove nonlinear distortions, however, these approaches either are not optimal for removing residual (linear) noise, or they are unstable when used jointly with neural networks. In this study, we propose a multi-channel multi-frame (MCMF) all deep learning (ADL)-MVDR approach for target speech separation, which extends our preliminary multi-channel ADL-MVDR approach. The MCMF ADL-MVDR handles different numbers of microphone channels in one framework, where it addresses linear and nonlinear distortions. Spatio-temporal cross correlations are also fully utilized in the proposed approach. The proposed system is evaluated using a Mandarin audio-visual corpora and is compared with several state-of-the-art approaches. Experimental results demonstrate the superiority of our proposed framework under different scenarios and across several objective evaluation metrics, including ASR performance.
Estimation error analysis of deep learning on the regression problem on the variable exponent Besov space
Sep 27, 2020
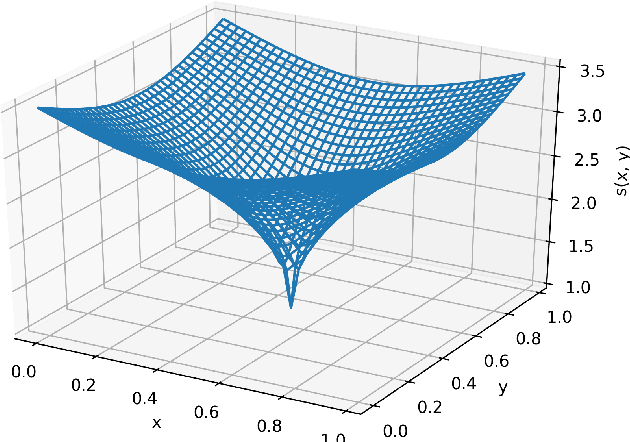
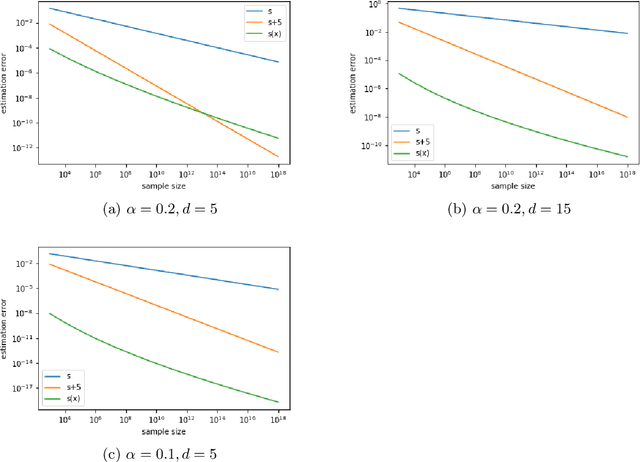
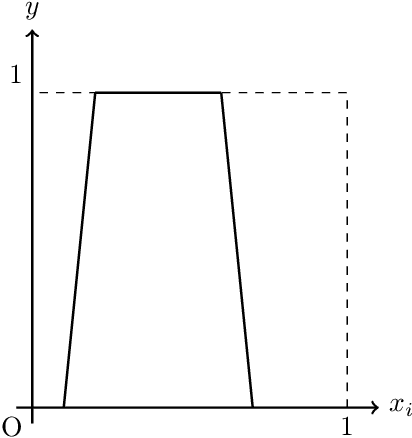
Deep learning has achieved notable success in various fields, including image and speech recognition. One of the factors in the successful performance of deep learning is its high feature extraction ability. In this study, we focus on the adaptivity of deep learning; consequently, we treat the variable exponent Besov space, which has a different smoothness depending on the input location $x$. In other words, the difficulty of the estimation is not uniform within the domain. We analyze the general approximation error of the variable exponent Besov space and the approximation and estimation errors of deep learning. We note that the improvement based on adaptivity is remarkable when the region upon which the target function has less smoothness is small and the dimension is large. Moreover, the superiority to linear estimators is shown with respect to the convergence rate of the estimation error.
Cascaded Models With Cyclic Feedback For Direct Speech Translation
Oct 21, 2020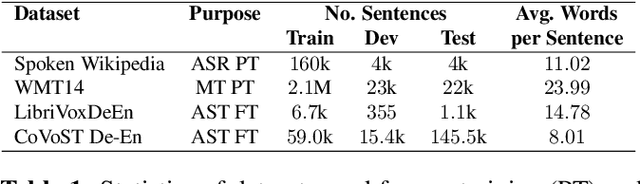
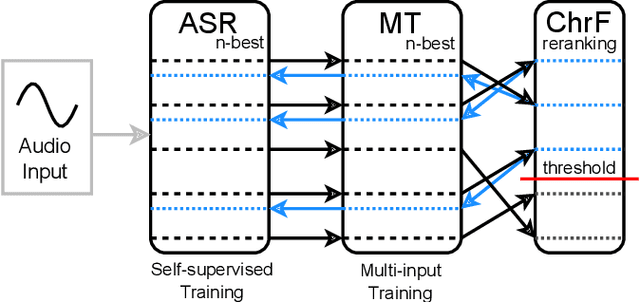

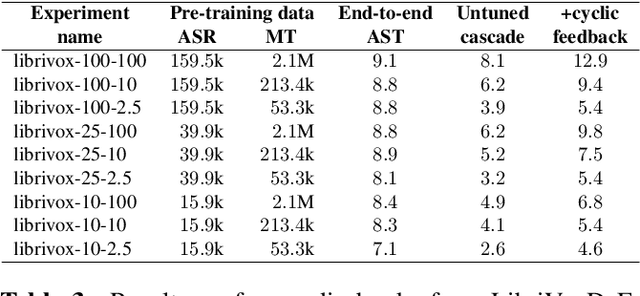
Direct speech translation describes a scenario where only speech inputs and corresponding translations are available. Such data are notoriously limited. We present a technique that allows cascades of automatic speech recognition (ASR) and machine translation (MT) to exploit in-domain direct speech translation data in addition to out-of-domain MT and ASR data. After pre-training MT and ASR, we use a feedback cycle where the downstream performance of the MT system is used as a signal to improve the ASR system by self-training, and the MT component is fine-tuned on multiple ASR outputs, making it more tolerant towards spelling variations. A comparison to end-to-end speech translation using components of identical architecture and the same data shows gains of up to 3.8 BLEU points on LibriVoxDeEn and up to 5.1 BLEU points on CoVoST for German-to-English speech translation.