 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Beyond Isolated Utterances: Conversational Emotion Recognition
Sep 13, 2021
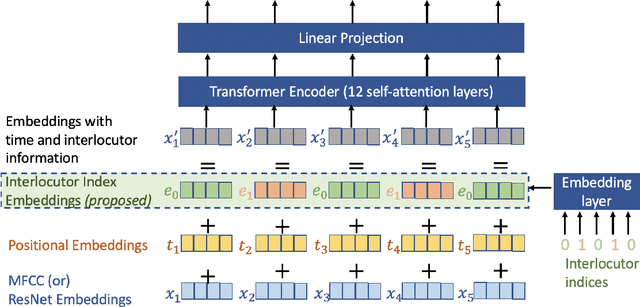

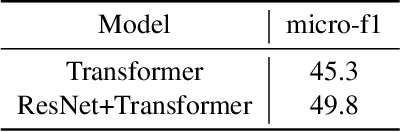
Speech emotion recognition is the task of recognizing the speaker's emotional state given a recording of their utterance. While most of the current approaches focus on inferring emotion from isolated utterances, we argue that this is not sufficient to achieve conversational emotion recognition (CER) which deals with recognizing emotions in conversations. In this work, we propose several approaches for CER by treating it as a sequence labeling task. We investigated transformer architecture for CER and, compared it with ResNet-34 and BiLSTM architectures in both contextual and context-less scenarios using IEMOCAP corpus. Based on the inner workings of the self-attention mechanism, we proposed DiverseCatAugment (DCA), an augmentation scheme, which improved the transformer model performance by an absolute 3.3% micro-f1 on conversations and 3.6% on isolated utterances. We further enhanced the performance by introducing an interlocutor-aware transformer model where we learn a dictionary of interlocutor index embeddings to exploit diarized conversations.
Multi-modal embeddings using multi-task learning for emotion recognition
Sep 10, 2020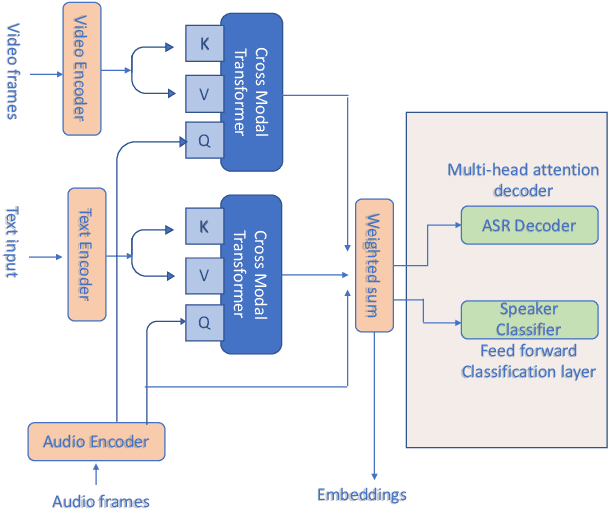
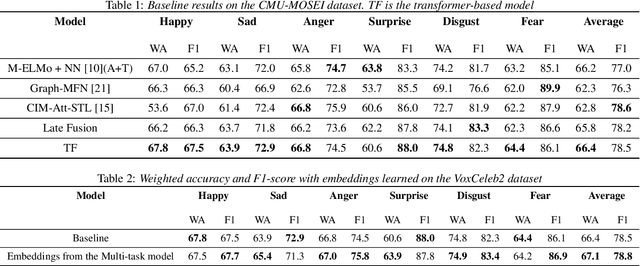
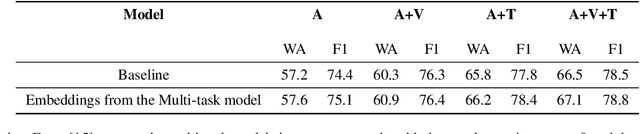
General embeddings like word2vec, GloVe and ELMo have shown a lot of success in natural language tasks. The embeddings are typically extracted from models that are built on general tasks such as skip-gram models and natural language generation. In this paper, we extend the work from natural language understanding to multi-modal architectures that use audio, visual and textual information for machine learning tasks. The embeddings in our network are extracted using the encoder of a transformer model trained using multi-task training. We use person identification and automatic speech recognition as the tasks in our embedding generation framework. We tune and evaluate the embeddings on the downstream task of emotion recognition and demonstrate that on the CMU-MOSEI dataset, the embeddings can be used to improve over previous state of the art results.
The Sequence-to-Sequence Baseline for the Voice Conversion Challenge 2020: Cascading ASR and TTS
Oct 06, 2020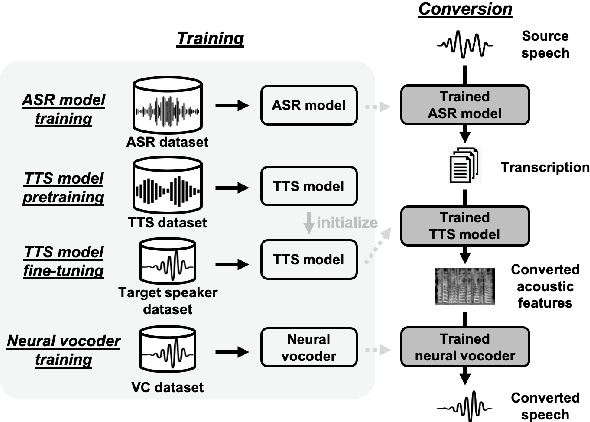
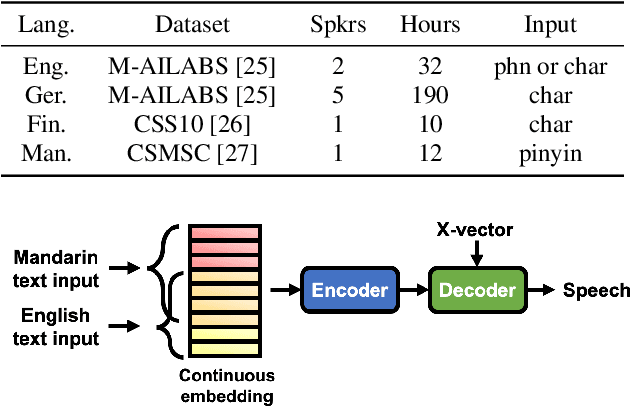
This paper presents the sequence-to-sequence (seq2seq) baseline system for the voice conversion challenge (VCC) 2020. We consider a naive approach for voice conversion (VC), which is to first transcribe the input speech with an automatic speech recognition (ASR) model, followed using the transcriptions to generate the voice of the target with a text-to-speech (TTS) model. We revisit this method under a sequence-to-sequence (seq2seq) framework by utilizing ESPnet, an open-source end-to-end speech processing toolkit, and the many well-configured pretrained models provided by the community. Official evaluation results show that our system comes out top among the participating systems in terms of conversion similarity, demonstrating the promising ability of seq2seq models to convert speaker identity. The implementation is made open-source at: https://github.com/espnet/espnet/tree/master/egs/vcc20.
Split Computing and Early Exiting for Deep Learning Applications: Survey and Research Challenges
Mar 08, 2021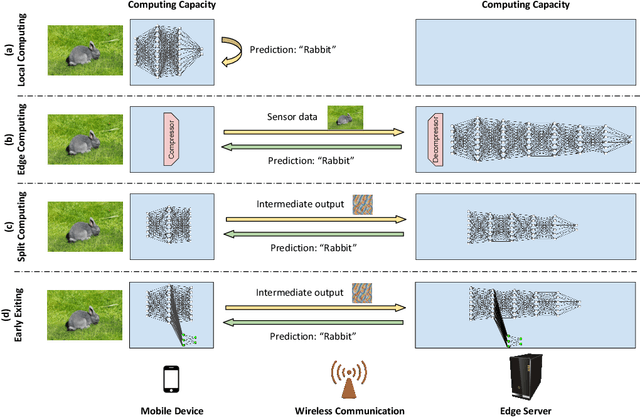
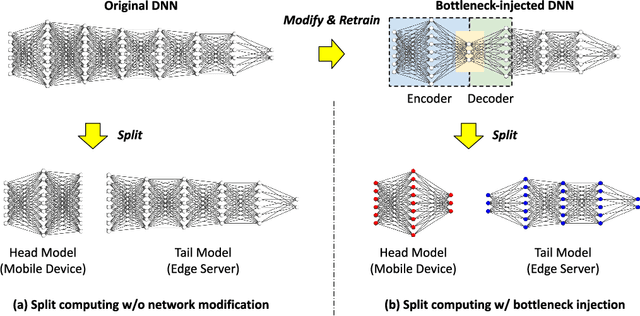
Mobile devices such as smartphones and autonomous vehicles increasingly rely on deep neural networks (DNNs) to execute complex inference tasks such as image classification and speech recognition, among others. However, continuously executing the entire DNN on the mobile device can quickly deplete its battery. Although task offloading to edge devices may decrease the mobile device's computational burden, erratic patterns in channel quality, network and edge server load can lead to a significant delay in task execution. Recently, approaches based on split computing (SC) have been proposed, where the DNN is split into a head and a tail model, executed respectively on the mobile device and on the edge device. Ultimately, this may reduce bandwidth usage as well as energy consumption. Another approach, called early exiting (EE), trains models to present multiple "exits" earlier in the architecture, each providing increasingly higher target accuracy. Therefore, the trade-off between accuracy and delay can be tuned according to the current conditions or application demands. In this paper, we provide a comprehensive survey of the state of the art in SC and EE strategies, by presenting a comparison of the most relevant approaches. We conclude the paper by providing a set of compelling research challenges.
Transferable Positive/Negative Speech Emotion Recognition via Class-wise Adversarial Domain Adaptation
Oct 30, 2018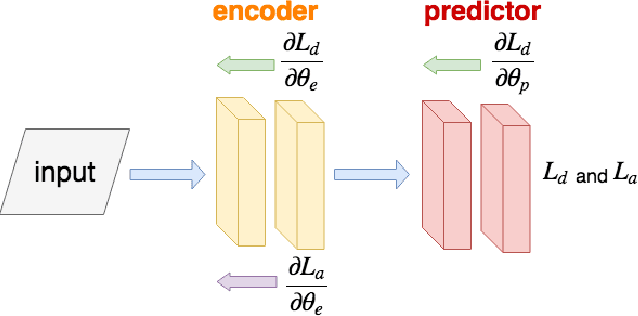
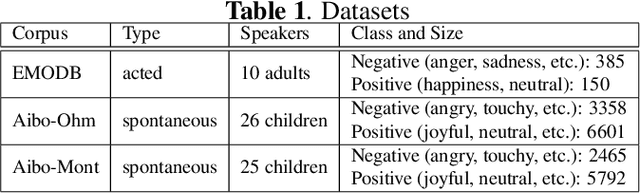
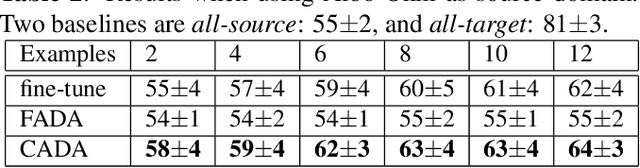
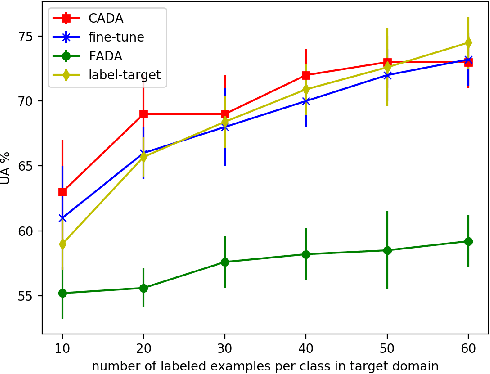
Speech emotion recognition plays an important role in building more intelligent and human-like agents. Due to the difficulty of collecting speech emotional data, an increasingly popular solution is leveraging a related and rich source corpus to help address the target corpus. However, domain shift between the corpora poses a serious challenge, making domain shift adaptation difficult to function even on the recognition of positive/negative emotions. In this work, we propose class-wise adversarial domain adaptation to address this challenge by reducing the shift for all classes between different corpora. Experiments on the well-known corpora EMODB and Aibo demonstrate that our method is effective even when only a very limited number of target labeled examples are provided.
ConcealNet: An End-to-end Neural Network for Packet Loss Concealment in Deep Speech Emotion Recognition
May 15, 2020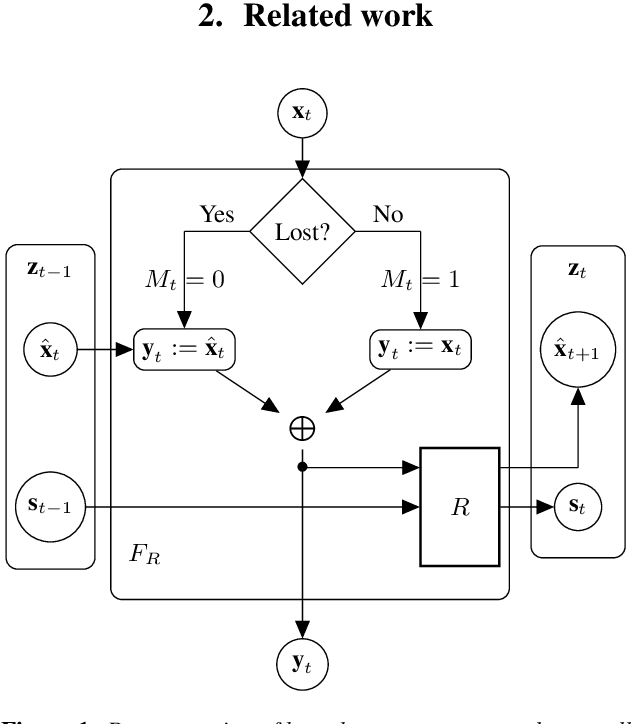
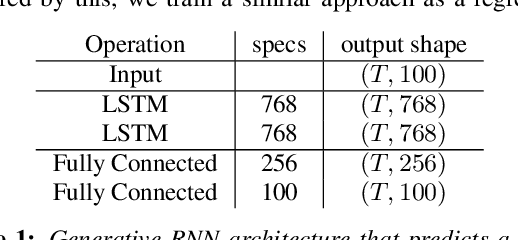
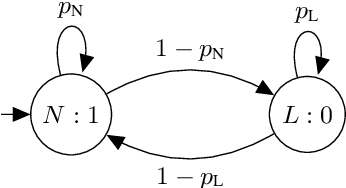
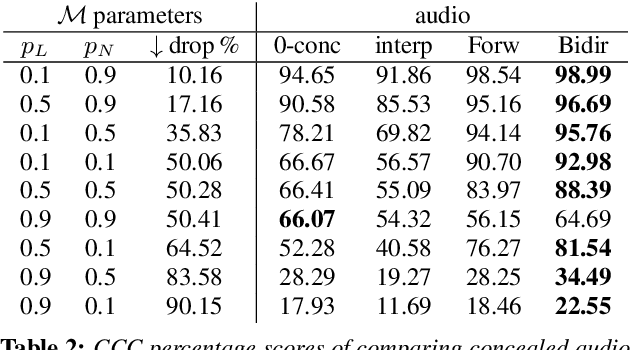
Packet loss is a common problem in data transmission, including speech data transmission. This may affect a wide range of applications that stream audio data, like streaming applications or speech emotion recognition (SER). Packet Loss Concealment (PLC) is any technique of facing packet loss. Simple PLC baselines are 0-substitution or linear interpolation. In this paper, we present a concealment wrapper, which can be used with stacked recurrent neural cells. The concealment cell can provide a recurrent neural network (ConcealNet), that performs real-time step-wise end-to-end PLC at inference time. Additionally, extending this with an end-to-end emotion prediction neural network provides a network that performs SER from audio with lost frames, end-to-end. The proposed model is compared against the fore-mentioned baselines. Additionally, a bidirectional variant with better performance is utilised. For evaluation, we chose the public RECOLA dataset given its long audio tracks with continuous emotion labels. ConcealNet is evaluated on the reconstruction of the audio and the quality of corresponding emotions predicted after that. The proposed ConcealNet model has shown considerable improvement, for both audio reconstruction and the corresponding emotion prediction, in environments that do not have losses with long duration, even when the losses occur frequently.
Robustness of on-device Models: Adversarial Attack to Deep Learning Models on Android Apps
Feb 04, 2021
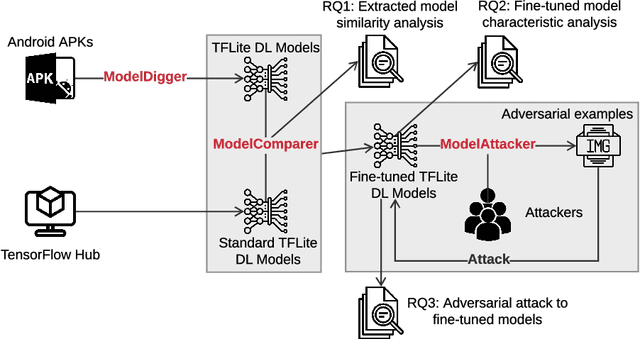
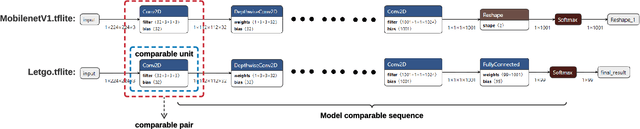
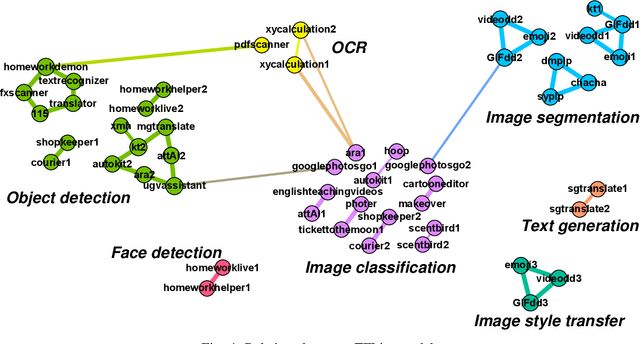
Deep learning has shown its power in many applications, including object detection in images, natural-language understanding, and speech recognition. To make it more accessible to end users, many deep learning models are now embedded in mobile apps. Compared to offloading deep learning from smartphones to the cloud, performing machine learning on-device can help improve latency, connectivity, and power consumption. However, most deep learning models within Android apps can easily be obtained via mature reverse engineering, while the models' exposure may invite adversarial attacks. In this study, we propose a simple but effective approach to hacking deep learning models using adversarial attacks by identifying highly similar pre-trained models from TensorFlow Hub. All 10 real-world Android apps in the experiment are successfully attacked by our approach. Apart from the feasibility of the model attack, we also carry out an empirical study that investigates the characteristics of deep learning models used by hundreds of Android apps on Google Play. The results show that many of them are similar to each other and widely use fine-tuning techniques to pre-trained models on the Internet.
Vocoder-free End-to-End Voice Conversion with Transformer Network
Feb 05, 2020
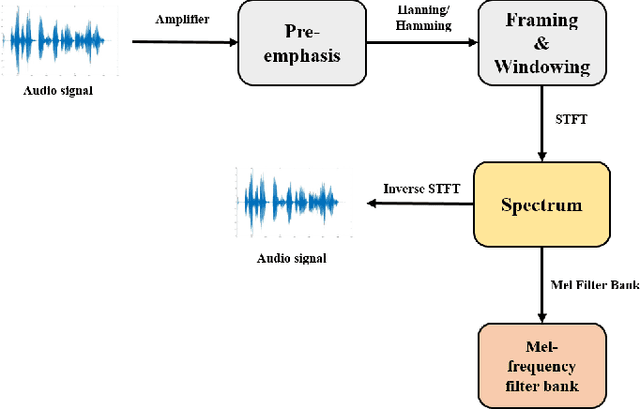
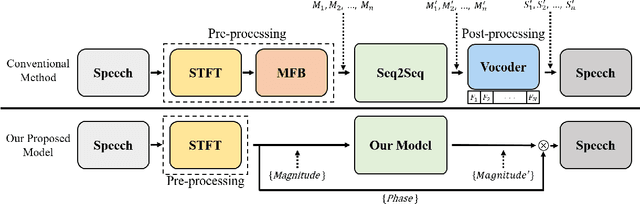
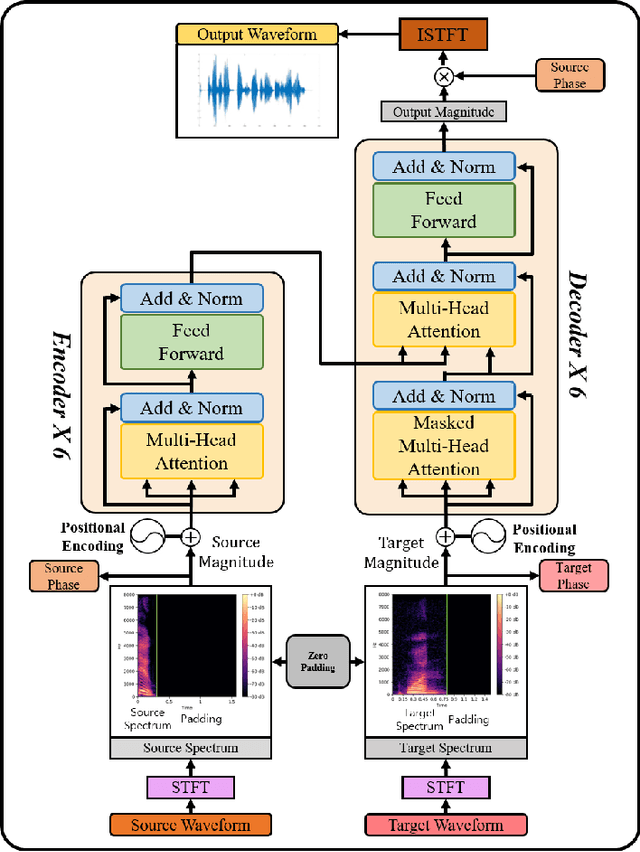
Mel-frequency filter bank (MFB) based approaches have the advantage of learning speech compared to raw spectrum since MFB has less feature size. However, speech generator with MFB approaches require additional vocoder that needs a huge amount of computation expense for training process. The additional pre/post processing such as MFB and vocoder is not essential to convert real human speech to others. It is possible to only use the raw spectrum along with the phase to generate different style of voices with clear pronunciation. In this regard, we propose a fast and effective approach to convert realistic voices using raw spectrum in a parallel manner. Our transformer-based model architecture which does not have any CNN or RNN layers has shown the advantage of learning fast and solved the limitation of sequential computation of conventional RNN. In this paper, we introduce a vocoder-free end-to-end voice conversion method using transformer network. The presented conversion model can also be used in speaker adaptation for speech recognition. Our approach can convert the source voice to a target voice without using MFB and vocoder. We can get an adapted MFB for speech recognition by multiplying the converted magnitude with phase. We perform our voice conversion experiments on TIDIGITS dataset using the metrics such as naturalness, similarity, and clarity with mean opinion score, respectively.
Confusion2vec 2.0: Enriching Ambiguous Spoken Language Representations with Subwords
Feb 03, 2021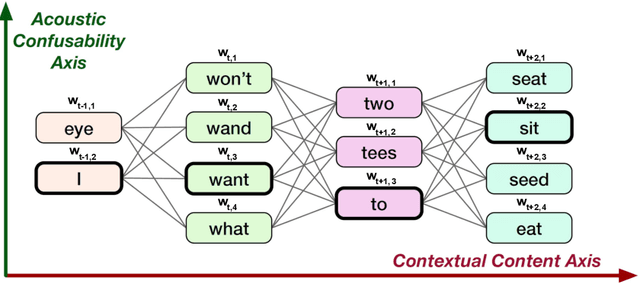
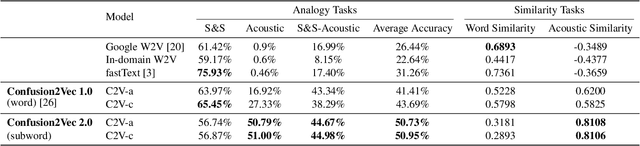
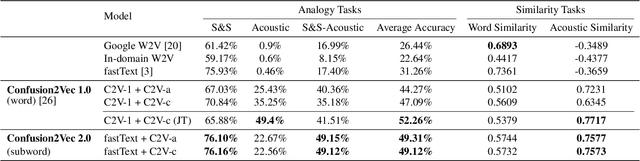
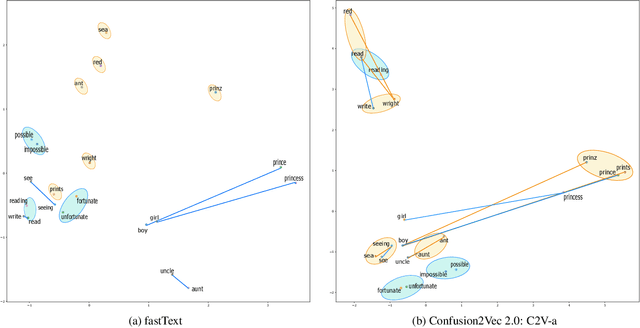
Word vector representations enable machines to encode human language for spoken language understanding and processing. Confusion2vec, motivated from human speech production and perception, is a word vector representation which encodes ambiguities present in human spoken language in addition to semantics and syntactic information. Confusion2vec provides a robust spoken language representation by considering inherent human language ambiguities. In this paper, we propose a novel word vector space estimation by unsupervised learning on lattices output by an automatic speech recognition (ASR) system. We encode each word in confusion2vec vector space by its constituent subword character n-grams. We show the subword encoding helps better represent the acoustic perceptual ambiguities in human spoken language via information modeled on lattice structured ASR output. The usefulness of the proposed Confusion2vec representation is evaluated using semantic, syntactic and acoustic analogy and word similarity tasks. We also show the benefits of subword modeling for acoustic ambiguity representation on the task of spoken language intent detection. The results significantly outperform existing word vector representations when evaluated on erroneous ASR outputs. We demonstrate that Confusion2vec subword modeling eliminates the need for retraining/adapting the natural language understanding models on ASR transcripts.
Voice based self help System: User Experience Vs Accuracy
Apr 07, 2015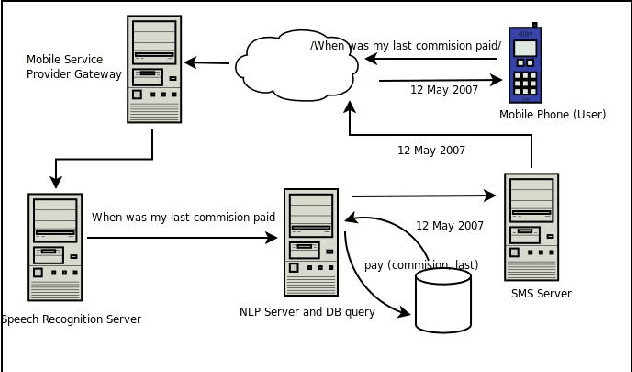
In general, self help systems are being increasingly deployed by service based industries because they are capable of delivering better customer service and increasingly the switch is to voice based self help systems because they provide a natural interface for a human to interact with a machine. A speech based self help system ideally needs a speech recognition engine to convert spoken speech to text and in addition a language processing engine to take care of any misrecognitions by the speech recognition engine. Any off-the-shelf speech recognition engine is generally a combination of acoustic processing and speech grammar. While this is the norm, we believe that ideally a speech recognition application should have in addition to a speech recognition engine a separate language processing engine to give the system better performance. In this paper, we discuss ways in which the speech recognition engine and the language processing engine can be combined to give a better user experience.