 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
ImportantAug: a data augmentation agent for speech
Dec 14, 2021

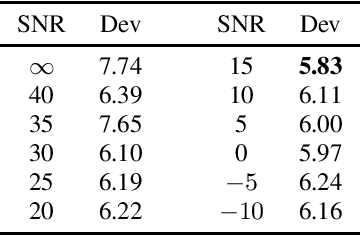


We introduce ImportantAug, a technique to augment training data for speech classification and recognition models by adding noise to unimportant regions of the speech and not to important regions. Importance is predicted for each utterance by a data augmentation agent that is trained to maximize the amount of noise it adds while minimizing its impact on recognition performance. The effectiveness of our method is illustrated on version two of the Google Speech Commands (GSC) dataset. On the standard GSC test set, it achieves a 23.3% relative error rate reduction compared to conventional noise augmentation which applies noise to speech without regard to where it might be most effective. It also provides a 25.4% error rate reduction compared to a baseline without data augmentation. Additionally, the proposed ImportantAug outperforms the conventional noise augmentation and the baseline on two test sets with additional noise added.
Computer-Generated Music for Tabletop Role-Playing Games
Aug 16, 2020In this paper we present Bardo Composer, a system to generate background music for tabletop role-playing games. Bardo Composer uses a speech recognition system to translate player speech into text, which is classified according to a model of emotion. Bardo Composer then uses Stochastic Bi-Objective Beam Search, a variant of Stochastic Beam Search that we introduce in this paper, with a neural model to generate musical pieces conveying the desired emotion. We performed a user study with 116 participants to evaluate whether people are able to correctly identify the emotion conveyed in the pieces generated by the system. In our study we used pieces generated for Call of the Wild, a Dungeons and Dragons campaign available on YouTube. Our results show that human subjects could correctly identify the emotion of the generated music pieces as accurately as they were able to identify the emotion of pieces written by humans.
Towards the evaluation of simultaneous speech translation from a communicative perspective
Mar 15, 2021
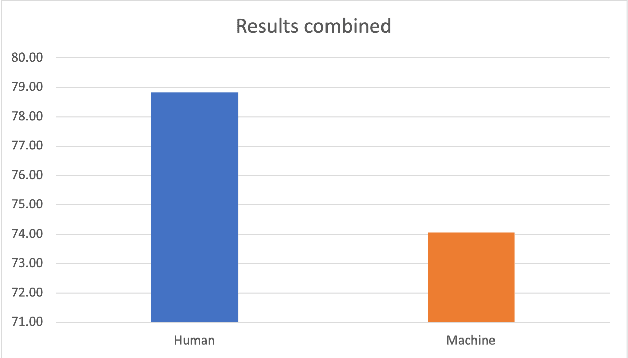
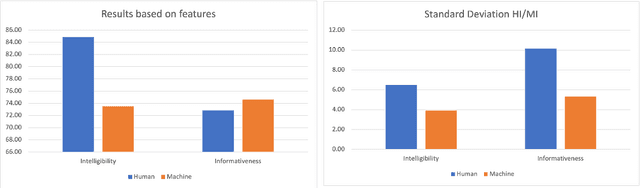
In recent years, machine speech-to-speech and speech-to-text translation has gained momentum thanks to advances in artificial intelligence, especially in the domains of speech recognition and machine translation. The quality of such applications is commonly tested with automatic metrics, such as BLEU, primarily with the goal of assessing improvements of releases or in the context of evaluation campaigns. However, little is known about how such systems compare to human performances in similar communicative tasks or how the performance of such systems is perceived by final users. In this paper, we present the results of an experiment aimed at evaluating the quality of a simultaneous speech translation engine by comparing it to the performance of professional interpreters. To do so, we select a framework developed for the assessment of human interpreters and use it to perform a manual evaluation on both human and machine performances. In our sample, we found better performance for the human interpreters in terms of intelligibility, while the machine performs slightly better in terms of informativeness. The limitations of the study and the possible enhancements of the chosen framework are discussed. Despite its intrinsic limitations, the use of this framework represents a first step towards a user-centric and communication-oriented methodology for evaluating simultaneous speech translation.
Quantization and Deployment of Deep Neural Networks on Microcontrollers
May 27, 2021
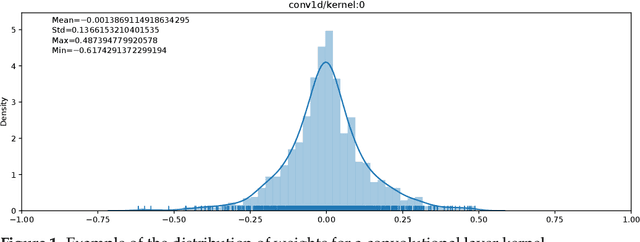

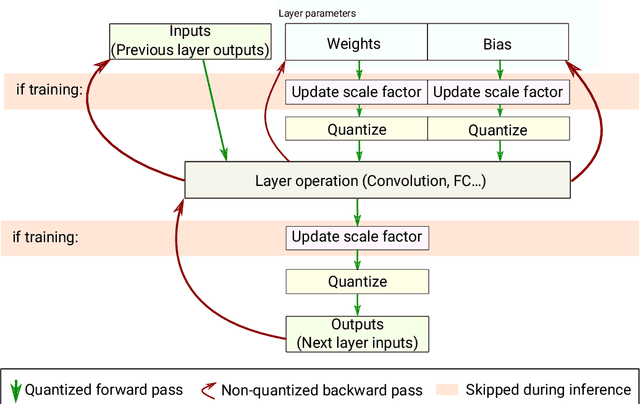
Embedding Artificial Intelligence onto low-power devices is a challenging task that has been partly overcome with recent advances in machine learning and hardware design. Presently, deep neural networks can be deployed on embedded targets to perform different tasks such as speech recognition,object detection or Human Activity Recognition. However, there is still room for optimization of deep neural networks onto embedded devices. These optimizations mainly address power consumption,memory and real-time constraints, but also an easier deployment at the edge. Moreover, there is still a need for a better understanding of what can be achieved for different use cases. This work focuses on quantization and deployment of deep neural networks onto low-power 32-bit microcontrollers. The quantization methods, relevant in the context of an embedded execution onto a microcontroller, are first outlined. Then, a new framework for end-to-end deep neural networks training, quantization and deployment is presented. This framework, called MicroAI, is designed as an alternative to existing inference engines (TensorFlow Lite for Microcontrollers and STM32Cube.AI). Our framework can indeed be easily adjusted and/or extended for specific use cases. Execution using single precision 32-bit floating-point as well as fixed-point on 8- and 16-bit integers are supported. The proposed quantization method is evaluated with three different datasets (UCI-HAR, Spoken MNIST and GTSRB). Finally, a comparison study between MicroAI and both existing embedded inference engines is provided in terms of memory and power efficiency. On-device evaluation is done using ARM Cortex-M4F-based microcontrollers (Ambiq Apollo3 and STM32L452RE).
* 36 pages, 14 figures. Published in MDPI Sensors 2021, special issue "Embedded Artificial Intelligence (AI) for Smart Sensing and IoT Applications": https://www.mdpi.com/1424-8220/21/9/2984
A Distributed Optimisation Framework Combining Natural Gradient with Hessian-Free for Discriminative Sequence Training
Mar 12, 2021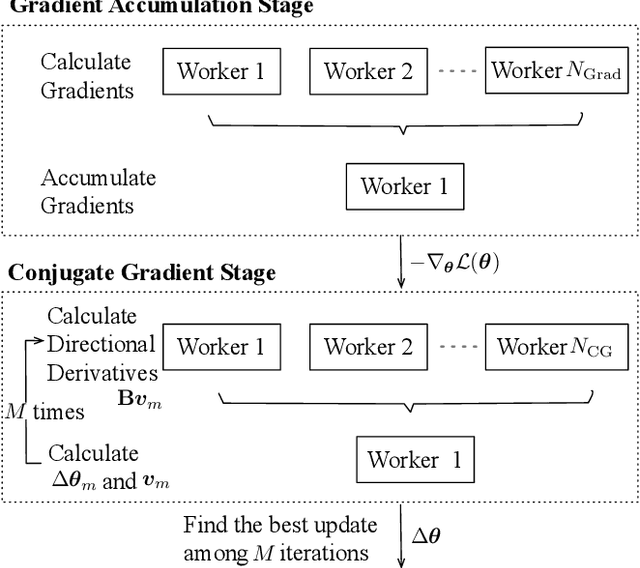

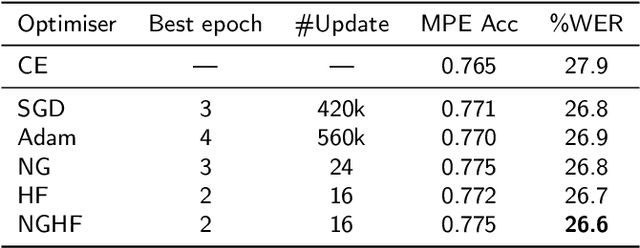
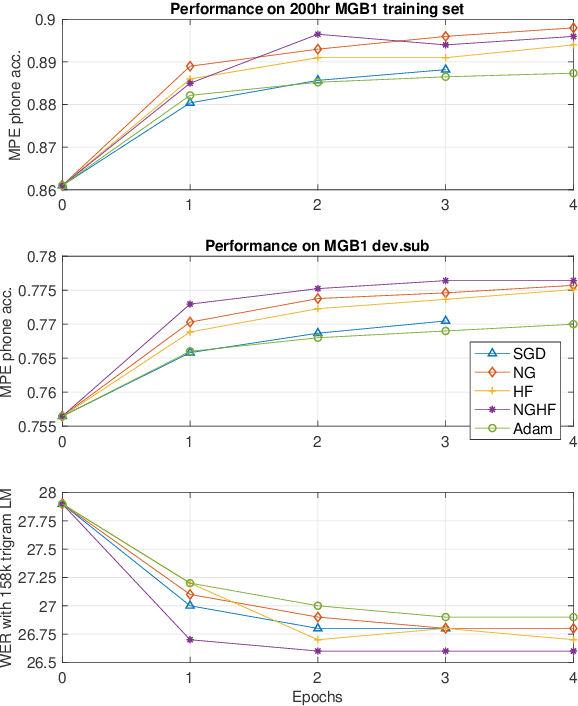
This paper presents a novel natural gradient and Hessian-free (NGHF) optimisation framework for neural network training that can operate efficiently in a distributed manner. It relies on the linear conjugate gradient (CG) algorithm to combine the natural gradient (NG) method with local curvature information from Hessian-free (HF) or other second-order methods. A solution to a numerical issue in CG allows effective parameter updates to be generated with far fewer CG iterations than usually used (e.g. 5-8 instead of 200). This work also presents a novel preconditioning approach to improve the progress made by individual CG iterations for models with shared parameters. Although applicable to other training losses and model structures, NGHF is investigated in this paper for lattice-based discriminative sequence training for hybrid hidden Markov model acoustic models using a standard recurrent neural network, long short-term memory, and time delay neural network models for output probability calculation. Automatic speech recognition experiments are reported on the multi-genre broadcast data set for a range of different acoustic model types. These experiments show that NGHF achieves larger word error rate reductions than standard stochastic gradient descent or Adam, while requiring orders of magnitude fewer parameter updates.
Focus on the present: a regularization method for the ASR source-target attention layer
Nov 02, 2020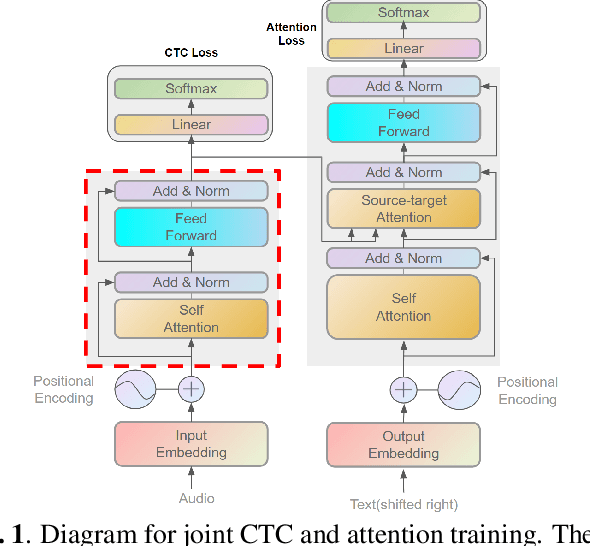
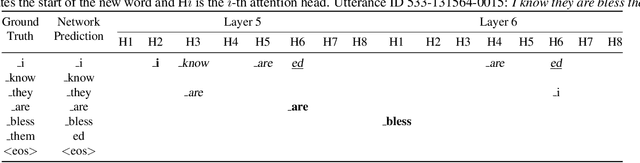


This paper introduces a novel method to diagnose the source-target attention in state-of-the-art end-to-end speech recognition models with joint connectionist temporal classification (CTC) and attention training. Our method is based on the fact that both, CTC and source-target attention, are acting on the same encoder representations. To understand the functionality of the attention, CTC is applied to compute the token posteriors given the attention outputs. We found that the source-target attention heads are able to predict several tokens ahead of the current one. Inspired by the observation, a new regularization method is proposed which leverages CTC to make source-target attention more focused on the frames corresponding to the output token being predicted by the decoder. Experiments reveal stable improvements up to 7\% and 13\% relatively with the proposed regularization on TED-LIUM 2 and LibriSpeech.
Training Speech Enhancement Systems with Noisy Speech Datasets
May 26, 2021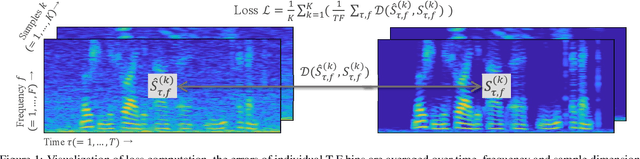
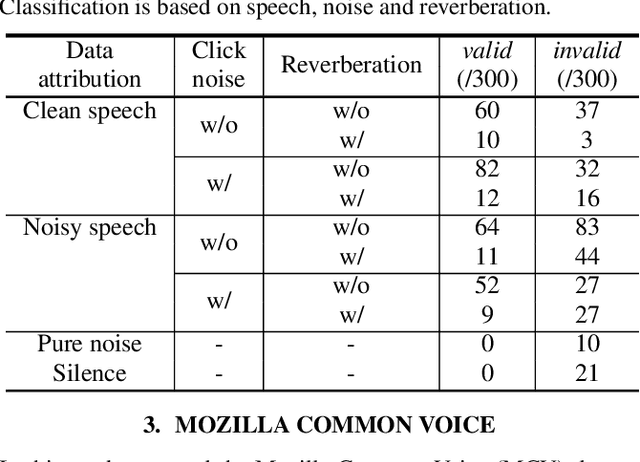
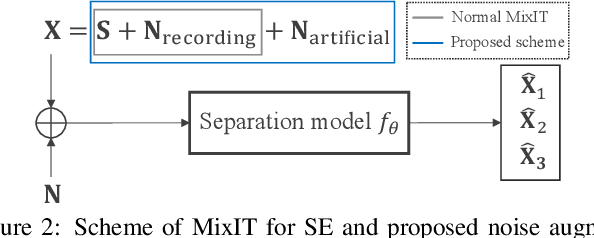

Recently, deep neural network (DNN)-based speech enhancement (SE) systems have been used with great success. During training, such systems require clean speech data - ideally, in large quantity with a variety of acoustic conditions, many different speaker characteristics and for a given sampling rate (e.g., 48kHz for fullband SE). However, obtaining such clean speech data is not straightforward - especially, if only considering publicly available datasets. At the same time, a lot of material for automatic speech recognition (ASR) with the desired acoustic/speaker/sampling rate characteristics is publicly available except being clean, i.e., it also contains background noise as this is even often desired in order to have ASR systems that are noise-robust. Hence, using such data to train SE systems is not straightforward. In this paper, we propose two improvements to train SE systems on noisy speech data. First, we propose several modifications of the loss functions, which make them robust against noisy speech targets. In particular, computing the median over the sample axis before averaging over time-frequency bins allows to use such data. Furthermore, we propose a noise augmentation scheme for mixture-invariant training (MixIT), which allows using it also in such scenarios. For our experiments, we use the Mozilla Common Voice dataset and we show that using our robust loss function improves PESQ by up to 0.19 compared to a system trained in the traditional way. Similarly, for MixIT we can see an improvement of up to 0.27 in PESQ when using our proposed noise augmentation.
Non-Attentive Tacotron: Robust and Controllable Neural TTS Synthesis Including Unsupervised Duration Modeling
Oct 08, 2020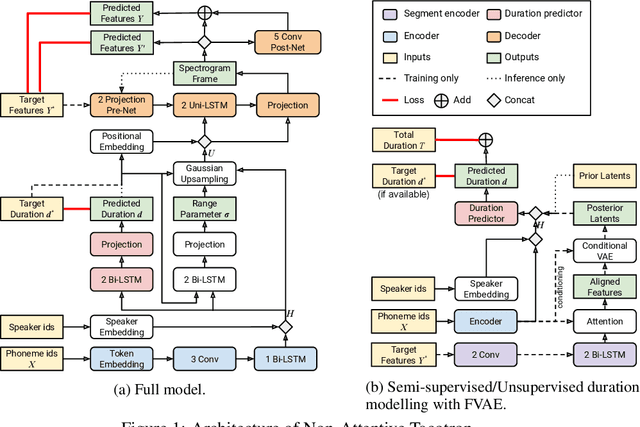

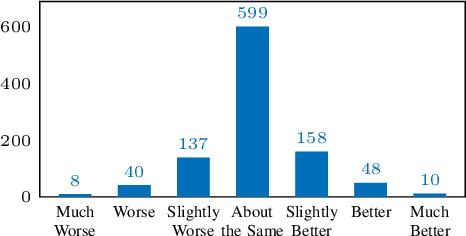

This paper presents Non-Attentive Tacotron based on the Tacotron 2 text-to-speech model, replacing the attention mechanism with an explicit duration predictor. This improves robustness significantly as measured by unaligned duration ratio and word deletion rate, two metrics introduced in this paper for large-scale robustness evaluation using a pre-trained speech recognition model. With the use of Gaussian upsampling, Non-Attentive Tacotron achieves a 5-scale mean opinion score for naturalness of 4.41, slightly outperforming Tacotron 2. The duration predictor enables both utterance-wide and per-phoneme control of duration at inference time. When accurate target durations are scarce or unavailable in the training data, we propose a method using a fine-grained variational auto-encoder to train the duration predictor in a semi-supervised or unsupervised manner, with results almost as good as supervised training.
Voice based self help System: User Experience Vs Accuracy
Apr 07, 2015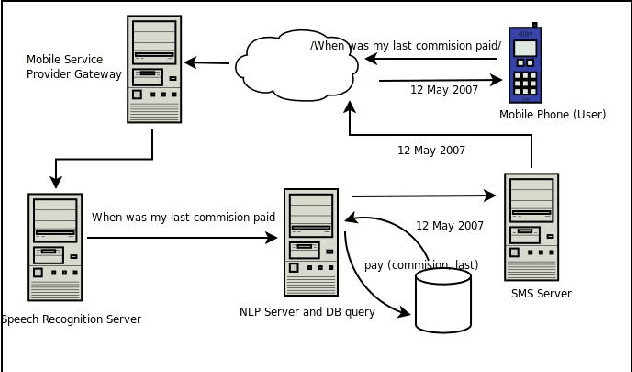
In general, self help systems are being increasingly deployed by service based industries because they are capable of delivering better customer service and increasingly the switch is to voice based self help systems because they provide a natural interface for a human to interact with a machine. A speech based self help system ideally needs a speech recognition engine to convert spoken speech to text and in addition a language processing engine to take care of any misrecognitions by the speech recognition engine. Any off-the-shelf speech recognition engine is generally a combination of acoustic processing and speech grammar. While this is the norm, we believe that ideally a speech recognition application should have in addition to a speech recognition engine a separate language processing engine to give the system better performance. In this paper, we discuss ways in which the speech recognition engine and the language processing engine can be combined to give a better user experience.
DEVI: Open-source Human-Robot Interface for Interactive Receptionist Systems
Jan 02, 2021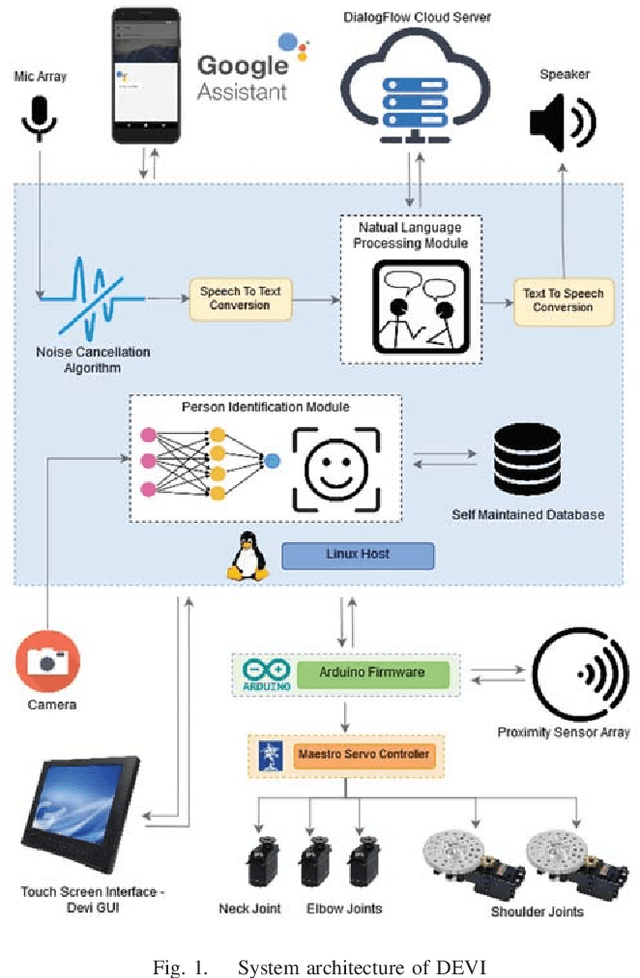
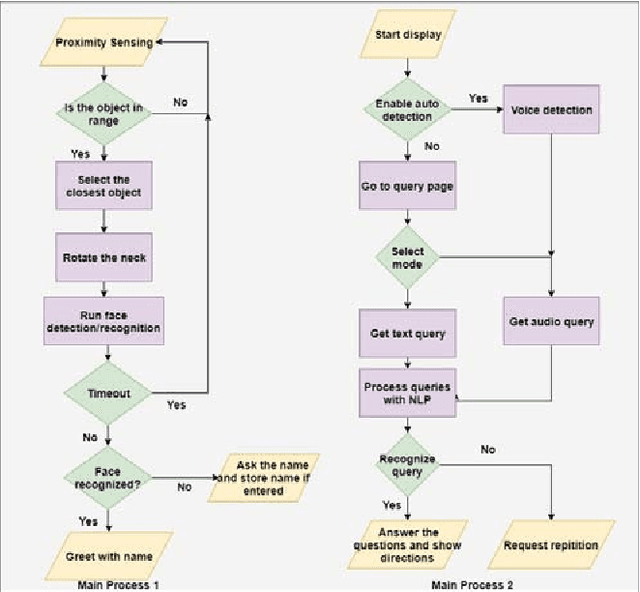

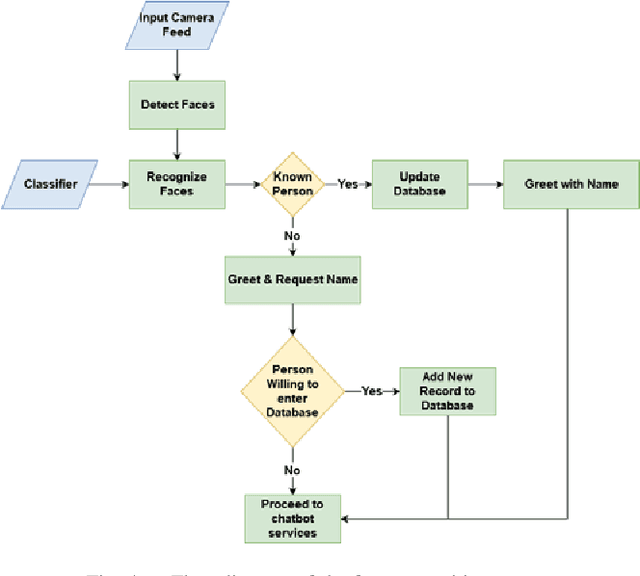
Humanoid robots that act as human-robot interfaces equipped with social skills can assist people in many of their daily activities. Receptionist robots are one such application where social skills and appearance are of utmost importance. Many existing robot receptionist systems suffer from high cost and they do not disclose internal architectures for further development for robot researchers. Moreover, there does not exist customizable open-source robot receptionist frameworks to be deployed for any given application. In this paper we present an open-source robot receptionist intelligence core -- "DEVI"(means 'lady' in Sinhala), that provides researchers with ease of creating customized robot receptionists according to the requirements (cost, external appearance, and required processing power). Moreover, this paper also presents details on a prototype implementation of a physical robot using the DEVI system. The robot can give directional guidance with physical gestures, answer basic queries using a speech recognition and synthesis system, recognize and greet known people using face recognition and register new people in its database, using a self-learning neural network. Experiments conducted with DEVI show the effectiveness of the proposed system.