 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Multi-objective Recurrent Neural Networks Optimization for the Edge -- a Quantization-based Approach
Aug 02, 2021
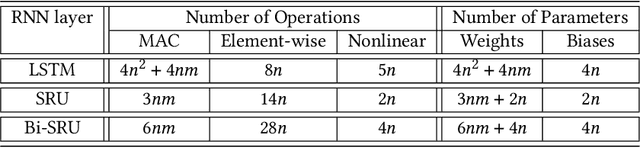
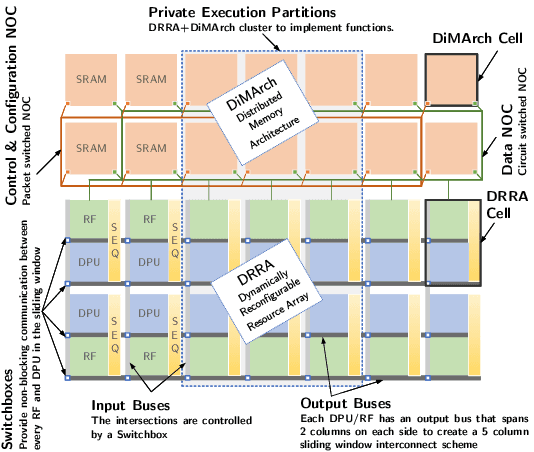

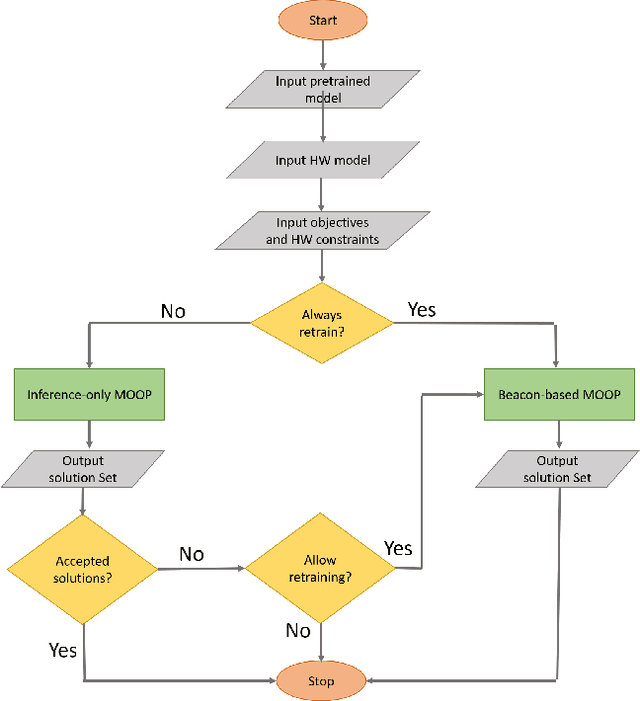
The compression of deep learning models is of fundamental importance in deploying such models to edge devices. Incorporating hardware model and application constraints during compression maximizes the benefits but makes it specifically designed for one case. Therefore, the compression needs to be automated. Searching for the optimal compression method parameters is considered an optimization problem. This article introduces a Multi-Objective Hardware-Aware Quantization (MOHAQ) method, which considers both hardware efficiency and inference error as objectives for mixed-precision quantization. The proposed method makes the evaluation of candidate solutions in a large search space feasible by relying on two steps. First, post-training quantization is applied for fast solution evaluation. Second, we propose a search technique named "beacon-based search" to retrain selected solutions only in the search space and use them as beacons to know the effect of retraining on other solutions. To evaluate the optimization potential, we chose a speech recognition model using the TIMIT dataset. The model is based on Simple Recurrent Unit (SRU) due to its considerable speedup over other recurrent units. We applied our method to run on two platforms: SiLago and Bitfusion. Experimental evaluations showed that SRU can be compressed up to 8x by post-training quantization without any significant increase in the error and up to 12x with only a 1.5 percentage point increase in error. On SiLago, the inference-only search found solutions that achieve 80\% and 64\% of the maximum possible speedup and energy saving, respectively, with a 0.5 percentage point increase in the error. On Bitfusion, with a constraint of a small SRAM size, beacon-based search reduced the error gain of inference-only search by 4 percentage points and increased the possible reached speedup to be 47x compared to the Bitfusion baseline.
Decoupling Pronunciation and Language for End-to-end Code-switching Automatic Speech Recognition
Oct 28, 2020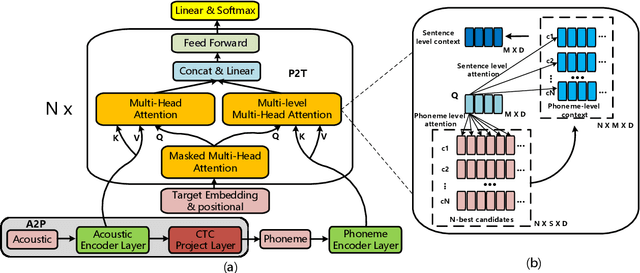
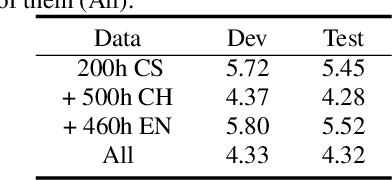
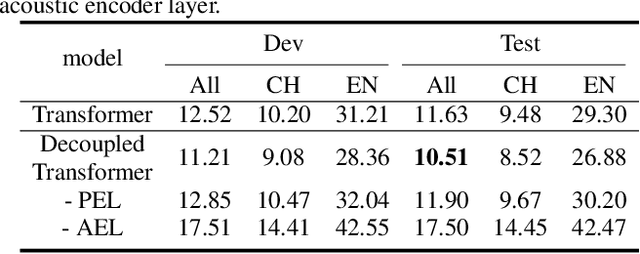
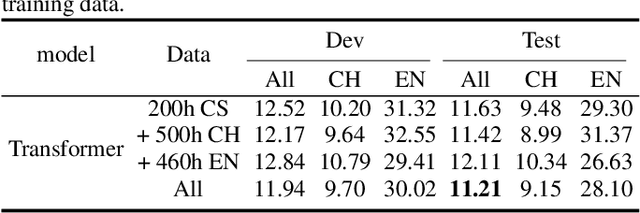
Despite the recent significant advances witnessed in end-to-end (E2E) ASR system for code-switching, hunger for audio-text paired data limits the further improvement of the models' performance. In this paper, we propose a decoupled transformer model to use monolingual paired data and unpaired text data to alleviate the problem of code-switching data shortage. The model is decoupled into two parts: audio-to-phoneme (A2P) network and phoneme-to-text (P2T) network. The A2P network can learn acoustic pattern scenarios using large-scale monolingual paired data. Meanwhile, it generates multiple phoneme sequence candidates for single audio data in real-time during the training process. Then the generated phoneme-text paired data is used to train the P2T network. This network can be pre-trained with large amounts of external unpaired text data. By using monolingual data and unpaired text data, the decoupled transformer model reduces the high dependency on code-switching paired training data of E2E model to a certain extent. Finally, the two networks are optimized jointly through attention fusion. We evaluate the proposed method on the public Mandarin-English code-switching dataset. Compared with our transformer baseline, the proposed method achieves 18.14% relative mix error rate reduction.
Speech2Slot: An End-to-End Knowledge-based Slot Filling from Speech
May 10, 2021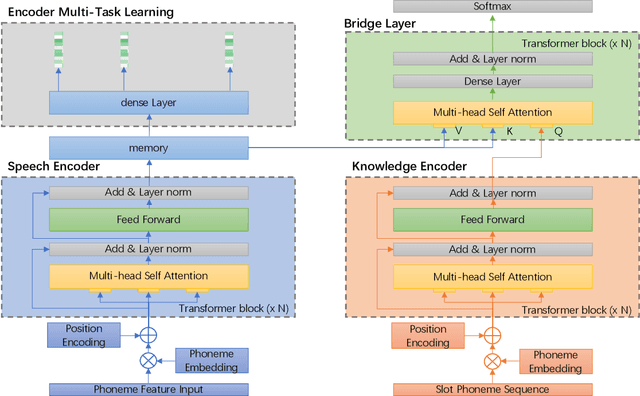
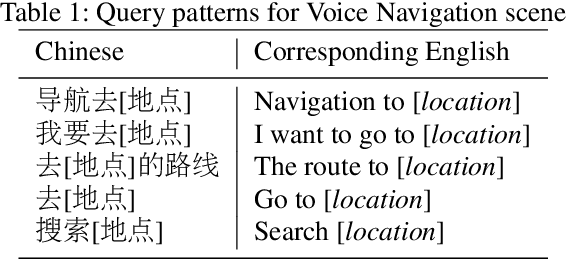
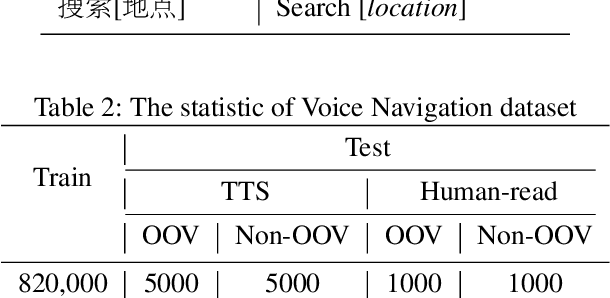
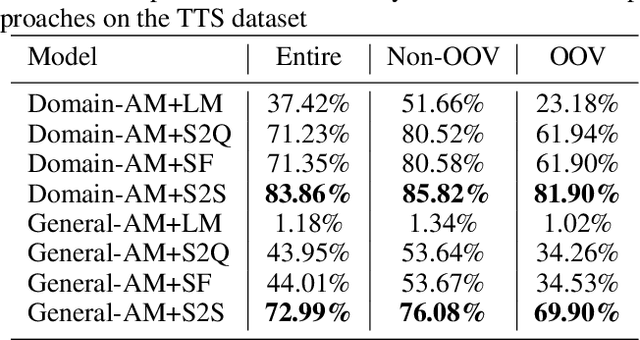
In contrast to conventional pipeline Spoken Language Understanding (SLU) which consists of automatic speech recognition (ASR) and natural language understanding (NLU), end-to-end SLU infers the semantic meaning directly from speech and overcomes the error propagation caused by ASR. End-to-end slot filling (SF) from speech is an essential component of end-to-end SLU, and is usually regarded as a sequence-to-sequence generation problem, heavily relied on the performance of language model of ASR. However, it is hard to generate a correct slot when the slot is out-of-vovabulary (OOV) in training data, especially when a slot is an anti-linguistic entity without grammatical rule. Inspired by object detection in computer vision that is to detect the object from an image, we consider SF as the task of slot detection from speech. In this paper, we formulate the SF task as a matching task and propose an end-to-end knowledge-based SF model, named Speech-to-Slot (Speech2Slot), to leverage knowledge to detect the boundary of a slot from the speech. We also release a large-scale dataset of Chinese speech for slot filling, containing more than 830,000 samples. The experiments show that our approach is markedly superior to the conventional pipeline SLU approach, and outperforms the state-of-the-art end-to-end SF approach with 12.51% accuracy improvement.
Bridging the Gap Between Clean Data Training and Real-World Inference for Spoken Language Understanding
Apr 13, 2021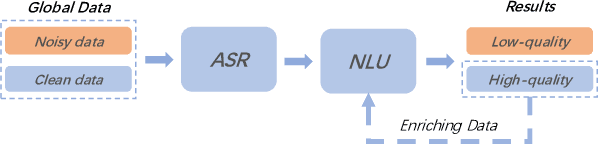
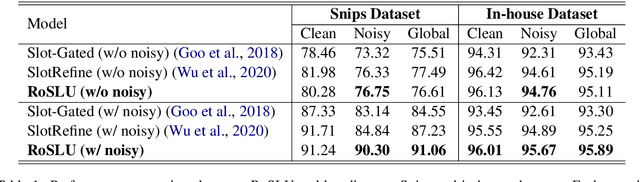
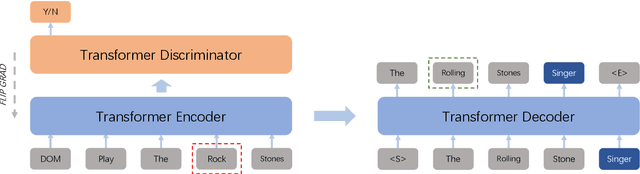
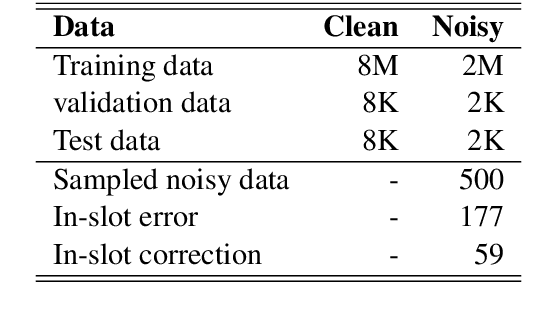
Spoken language understanding (SLU) system usually consists of various pipeline components, where each component heavily relies on the results of its upstream ones. For example, Intent detection (ID), and slot filling (SF) require its upstream automatic speech recognition (ASR) to transform the voice into text. In this case, the upstream perturbations, e.g. ASR errors, environmental noise and careless user speaking, will propagate to the ID and SF models, thus deteriorating the system performance. Therefore, the well-performing SF and ID models are expected to be noise resistant to some extent. However, existing models are trained on clean data, which causes a \textit{gap between clean data training and real-world inference.} To bridge the gap, we propose a method from the perspective of domain adaptation, by which both high- and low-quality samples are embedding into similar vector space. Meanwhile, we design a denoising generation model to reduce the impact of the low-quality samples. Experiments on the widely-used dataset, i.e. Snips, and large scale in-house dataset (10 million training examples) demonstrate that this method not only outperforms the baseline models on real-world (noisy) corpus but also enhances the robustness, that is, it produces high-quality results under a noisy environment. The source code will be released.
Experiments of ASR-based mispronunciation detection for children and adult English learners
Apr 13, 2021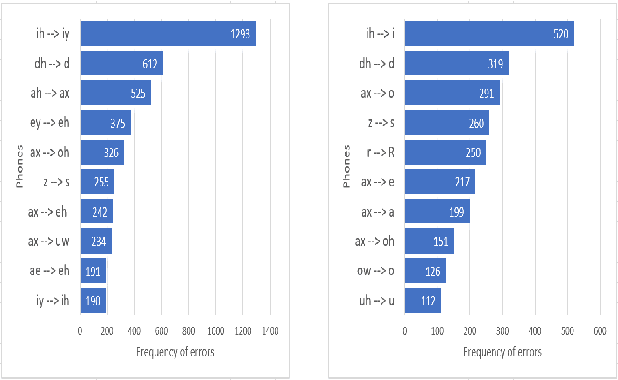
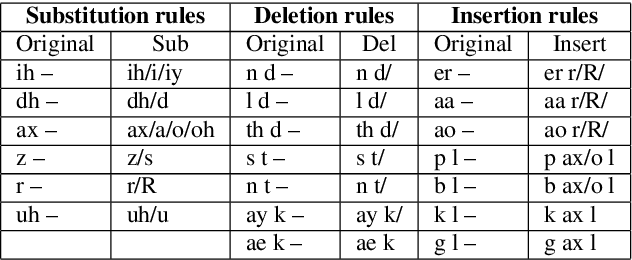
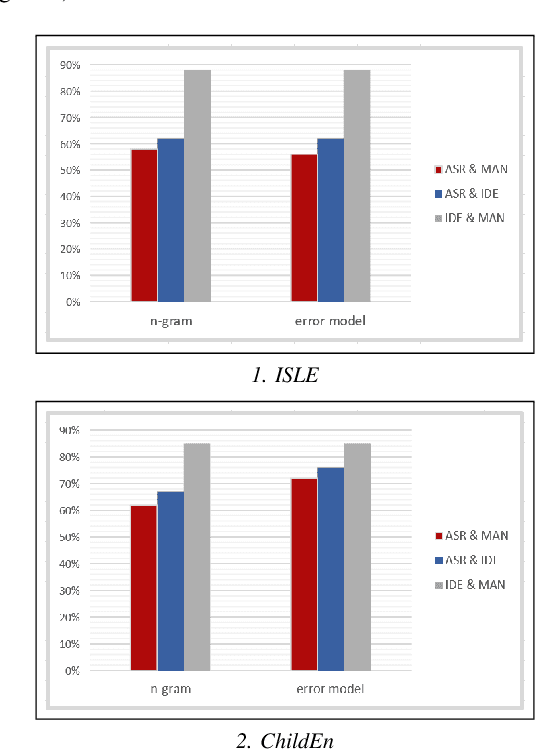
Pronunciation is one of the fundamentals of language learning, and it is considered a primary factor of spoken language when it comes to an understanding and being understood by others. The persistent presence of high error rates in speech recognition domains resulting from mispronunciations motivates us to find alternative techniques for handling mispronunciations. In this study, we develop a mispronunciation assessment system that checks the pronunciation of non-native English speakers, identifies the commonly mispronounced phonemes of Italian learners of English, and presents an evaluation of the non-native pronunciation observed in phonetically annotated speech corpora. In this work, to detect mispronunciations, we used a phone-based ASR implemented using Kaldi. We used two non-native English labeled corpora; (i) a corpus of Italian adults contains 5,867 utterances from 46 speakers, and (ii) a corpus of Italian children consists of 5,268 utterances from 78 children. Our results show that the selected error model can discriminate correct sounds from incorrect sounds in both native and nonnative speech, and therefore can be used to detect pronunciation errors in non-native speech. The phone error rates show improvement in using the error language model. The ASR system shows better accuracy after applying the error model on our selected corpora.
Lexical Access Model for Italian -- Modeling human speech processing: identification of words in running speech toward lexical access based on the detection of landmarks and other acoustic cues to features
Jun 24, 2021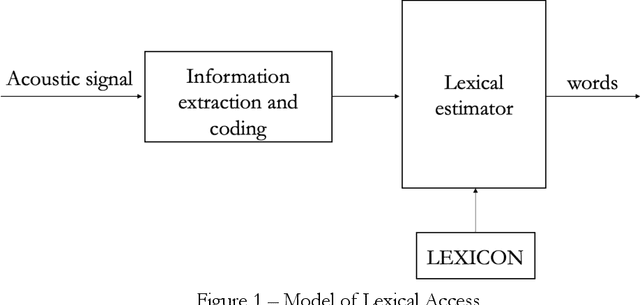
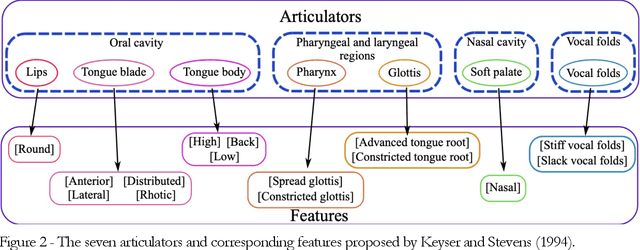
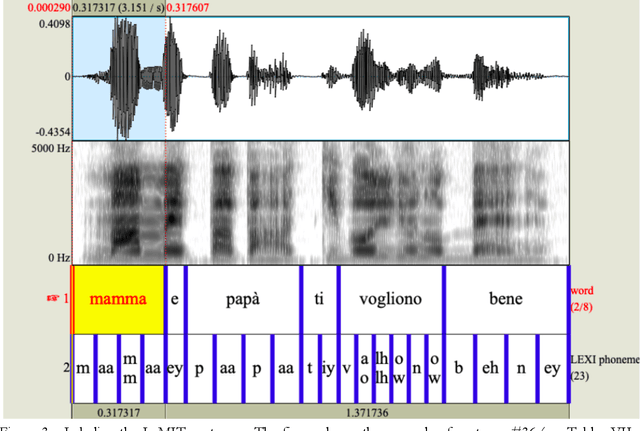
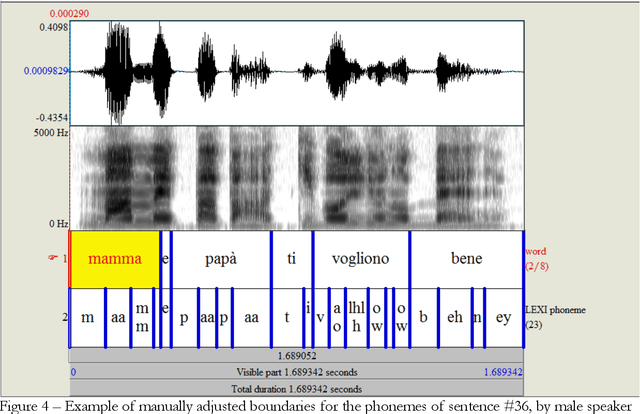
Modelling the process that a listener actuates in deriving the words intended by a speaker requires setting a hypothesis on how lexical items are stored in memory. This work aims at developing a system that imitates humans when identifying words in running speech and, in this way, provide a framework to better understand human speech processing. We build a speech recognizer for Italian based on the principles of Stevens' model of Lexical Access in which words are stored as hierarchical arrangements of distinctive features (Stevens, K. N. (2002). "Toward a model for lexical access based on acoustic landmarks and distinctive features," J. Acoust. Soc. Am., 111(4):1872-1891). Over the past few decades, the Speech Communication Group at the Massachusetts Institute of Technology (MIT) developed a speech recognition system for English based on this approach. Italian will be the first language beyond English to be explored; the extension to another language provides the opportunity to test the hypothesis that words are represented in memory as a set of hierarchically-arranged distinctive features, and reveal which of the underlying mechanisms may have a language-independent nature. This paper also introduces a new Lexical Access corpus, the LaMIT database, created and labeled specifically for this work, that will be provided freely to the speech research community. Future developments will test the hypothesis that specific acoustic discontinuities - called landmarks - that serve as cues to features, are language independent, while other cues may be language-dependent, with powerful implications for understanding how the human brain recognizes speech.
Knowledge Distillation for Improved Accuracy in Spoken Question Answering
Oct 21, 2020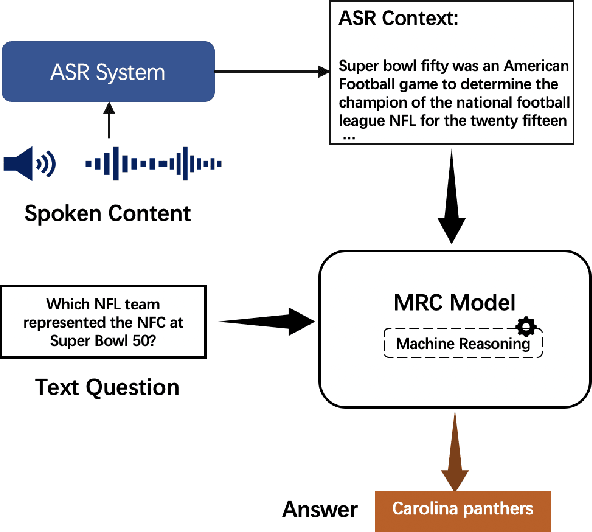
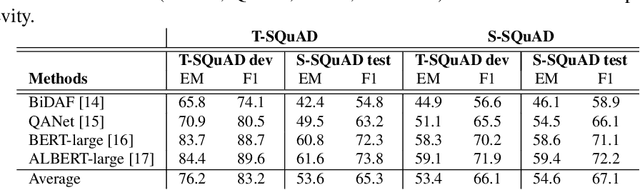
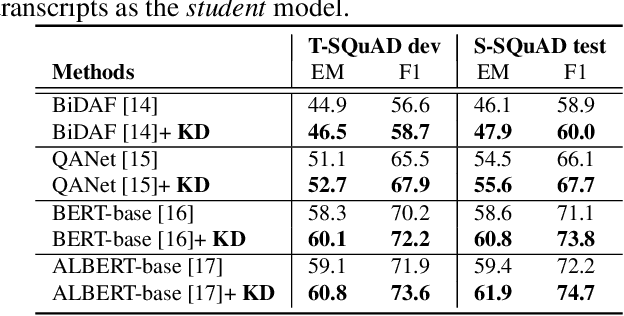
Spoken question answering (SQA) is a challenging task that requires the machine to fully understand the complex spoken documents. Automatic speech recognition (ASR) plays a significant role in the development of QA systems. However, the recent work shows that ASR systems generate highly noisy transcripts, which critically limit the capability of machine comprehension on the SQA task. To address the issue, we present a novel distillation framework. Specifically, we devise a training strategy to perform knowledge distillation (KD) from spoken documents and written counterparts. Our work makes a step towards distilling knowledge from the language model as a supervision signal to lead to better student accuracy by reducing the misalignment between automatic and manual transcriptions. Experiments demonstrate that our approach outperforms several state-of-the-art language models on the Spoken-SQuAD dataset.
Contextual Semi-Supervised Learning: An Approach To Leverage Air-Surveillance and Untranscribed ATC Data in ASR Systems
Apr 08, 2021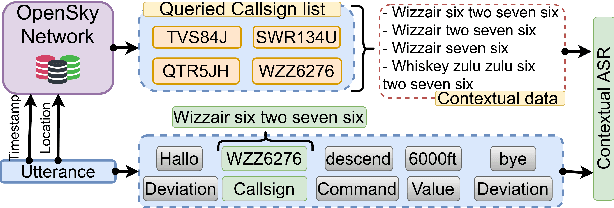
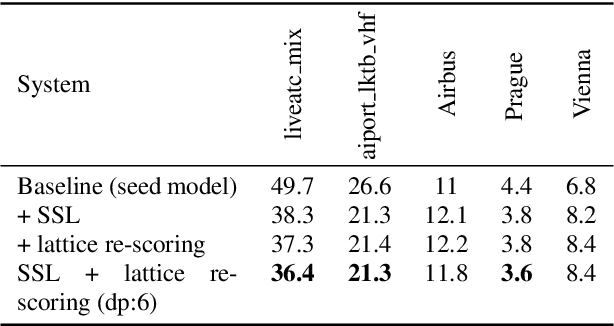
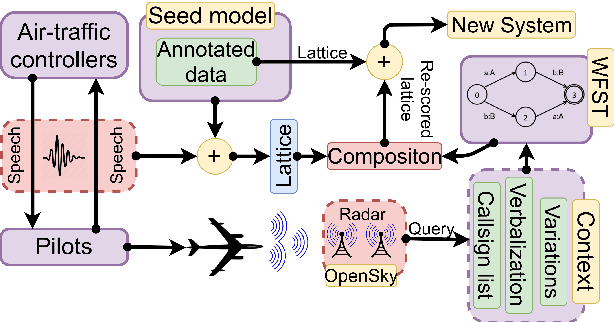
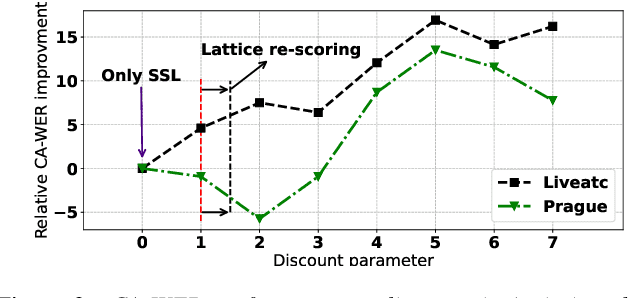
Air traffic management and specifically air-traffic control (ATC) rely mostly on voice communications between Air Traffic Controllers (ATCos) and pilots. In most cases, these voice communications follow a well-defined grammar that could be leveraged in Automatic Speech Recognition (ASR) technologies. The callsign used to address an airplane is an essential part of all ATCo-pilot communications. We propose a two-steps approach to add contextual knowledge during semi-supervised training to reduce the ASR system error rates at recognizing the part of the utterance that contains the callsign. Initially, we represent in a WFST the contextual knowledge (i.e. air-surveillance data) of an ATCo-pilot communication. Then, during Semi-Supervised Learning (SSL) the contextual knowledge is added by second-pass decoding (i.e. lattice re-scoring). Results show that `unseen domains' (e.g. data from airports not present in the supervised training data) are further aided by contextual SSL when compared to standalone SSL. For this task, we introduce the Callsign Word Error Rate (CA-WER) as an evaluation metric, which only assesses ASR performance of the spoken callsign in an utterance. We obtained a 32.1% CA-WER relative improvement applying SSL with an additional 17.5% CA-WER improvement by adding contextual knowledge during SSL on a challenging ATC-based test set gathered from LiveATC.
Layer Reduction: Accelerating Conformer-Based Self-Supervised Model via Layer Consistency
Apr 08, 2021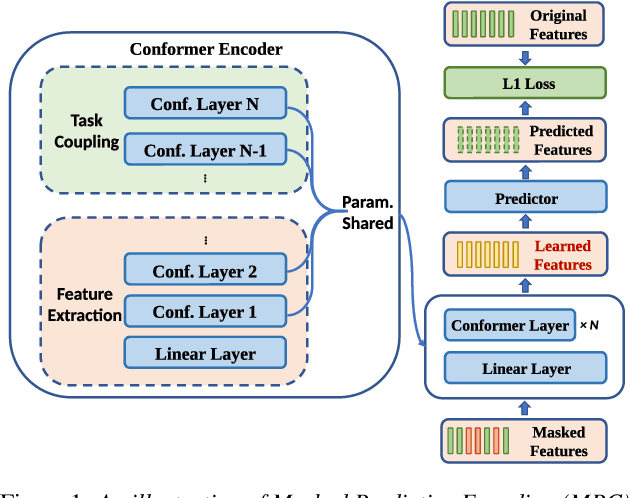
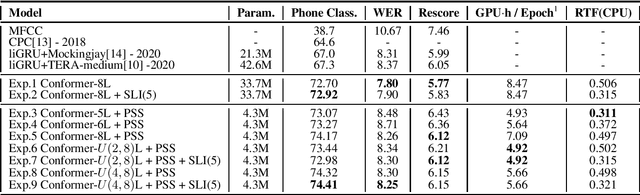
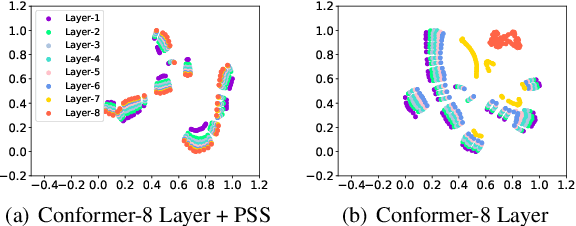
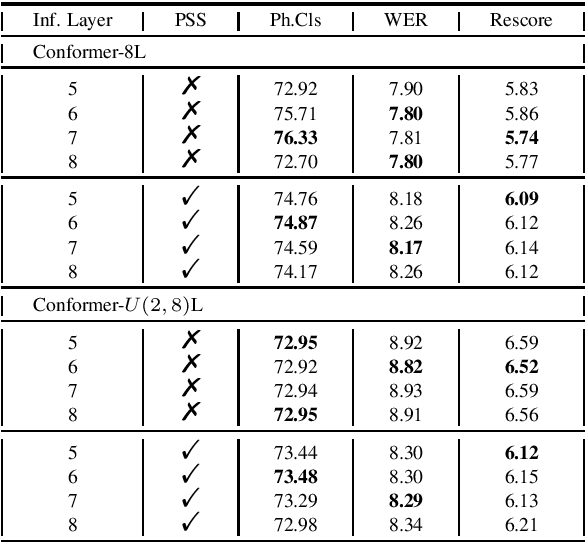
Transformer-based self-supervised models are trained as feature extractors and have empowered many downstream speech tasks to achieve state-of-the-art performance. However, both the training and inference process of these models may encounter prohibitively high computational cost and large parameter budget. Although Parameter Sharing Strategy (PSS) proposed in ALBERT paves the way for parameter reduction, the computation required remains the same. Interestingly, we found in experiments that distributions of feature embeddings from different Transformer layers are similar when PSS is integrated: a property termed as Layer Consistency (LC) in this paper. Given this similarity of feature distributions, we assume that feature embeddings from different layers would have similar representing power. In this work, Layer Consistency enables us to adopt Transformer-based models in a more efficient manner: the number of Conformer layers in each training iteration could be uniformly sampled and Shallow Layer Inference (SLI) could be applied to reduce the number of layers in inference stage. In experiments, our models are trained with LibriSpeech dataset and then evaluated on both phone classification and Speech Recognition tasks. We experimentally achieve 7.8X parameter reduction, 41.9% training speedup and 37.7% inference speedup while maintaining comparable performance with conventional BERT-like self-supervised methods.
An Ultra-low Power RNN Classifier for Always-On Voice Wake-Up Detection Robust to Real-World Scenarios
Mar 08, 2021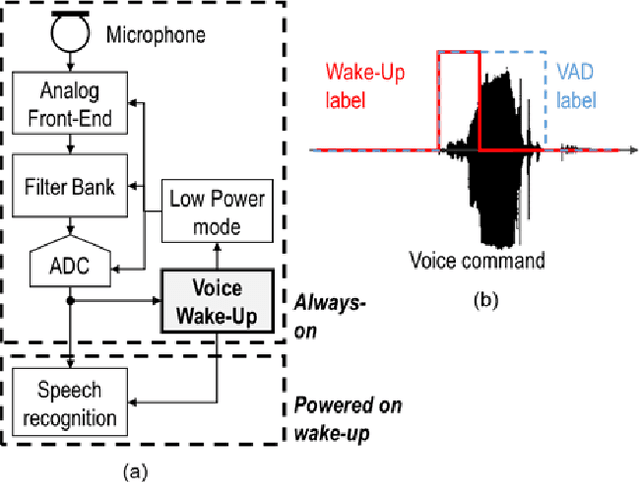
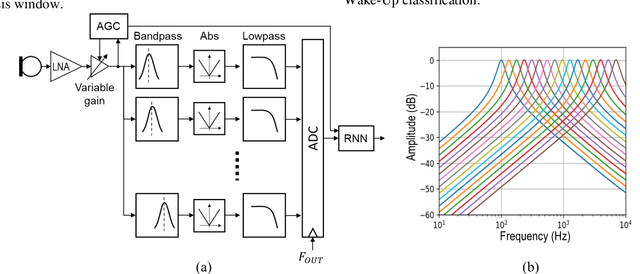
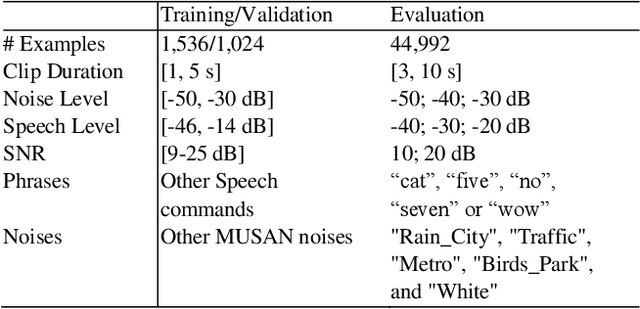
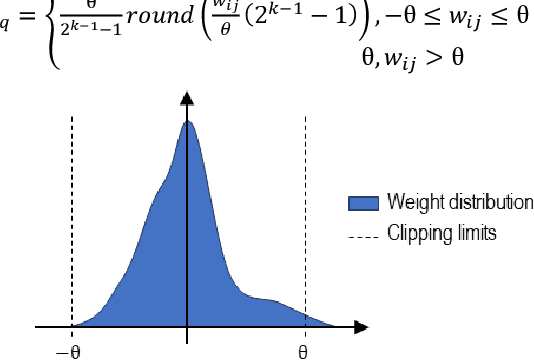
We present in this paper an ultra-low power (ULP) Recurrent Neural Network (RNN) based classifier for an always-on voice Wake-Up Sensor (WUS) with performances suitable for real-world applications. The purpose of our sensor is to bring down by at least a factor 100 the power consumption in background noise of always-on speech processing algorithms such as Automatic Speech Recognition, Keyword Spotting, Speaker Verification, etc. Unlike the other published approaches, we designed our wake-up sensor to be robust to unseen real-world noises for realistic levels of speech and noise by carefully designing the dataset and the loss function. We also specifically trained it to mark only the speech start rather than adopting a traditional Voice Activity Detection (VAD) approach. We achieve less than 3% No Trigger Rate (NTR) for a duty cycle less than 1% in challenging background noises pooled using a model of an analogue front-end. We demonstrate the superiority of RNNs on this task compared to the other tested approaches, with an estimated power consumption of 45 nW for the RNN itself in 65nm CMOS and a minimal memory footprint of 0.52 kB.