 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
NUVA: A Naming Utterance Verifier for Aphasia Treatment
Feb 10, 2021
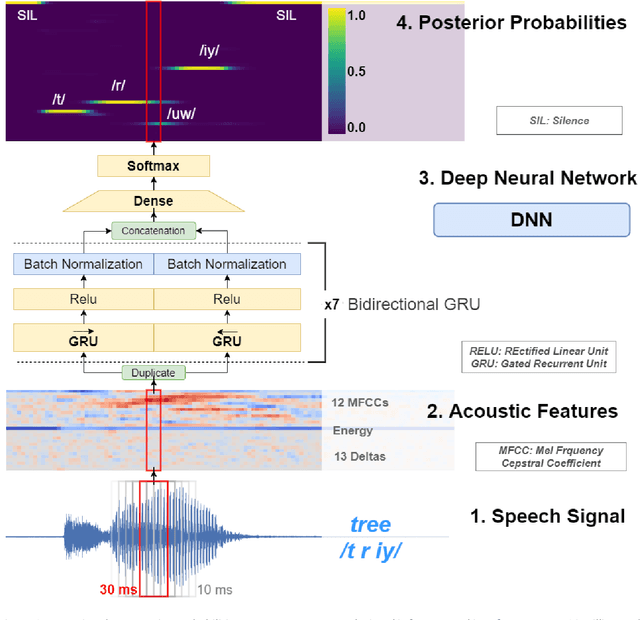
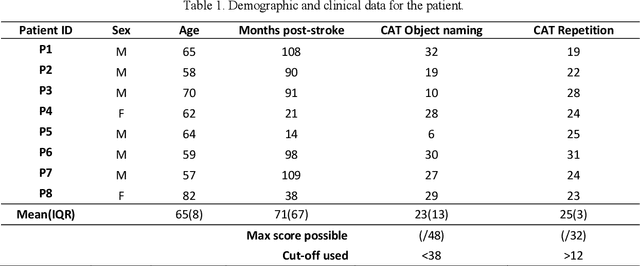
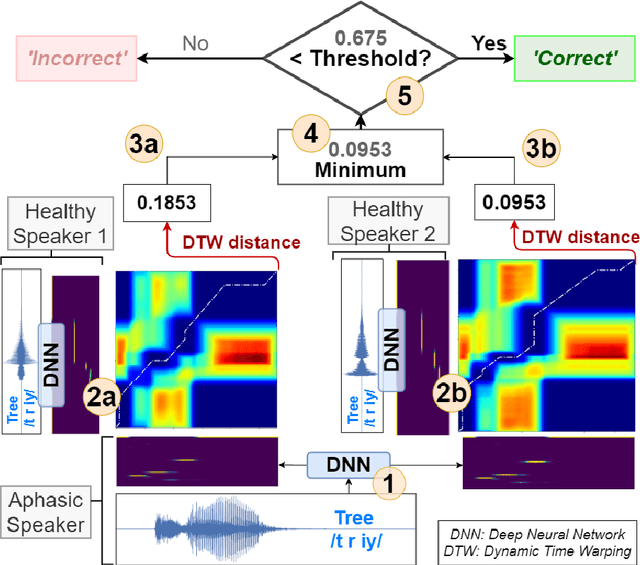
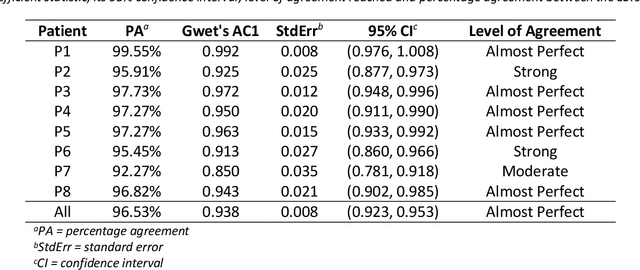
Anomia (word-finding difficulties) is the hallmark of aphasia, an acquired language disorder most commonly caused by stroke. Assessment of speech performance using picture naming tasks is a key method for both diagnosis and monitoring of responses to treatment interventions by people with aphasia (PWA). Currently, this assessment is conducted manually by speech and language therapists (SLT). Surprisingly, despite advancements in automatic speech recognition (ASR) and artificial intelligence with technologies like deep learning, research on developing automated systems for this task has been scarce. Here we present NUVA, an utterance verification system incorporating a deep learning element that classifies 'correct' versus' incorrect' naming attempts from aphasic stroke patients. When tested on eight native British-English speaking PWA the system's performance accuracy ranged between 83.6% to 93.6%, with a 10-fold cross-validation mean of 89.5%. This performance was not only significantly better than a baseline created for this study using one of the leading commercially available ASRs (Google speech-to-text service) but also comparable in some instances with two independent SLT ratings for the same dataset.
Speech2Slot: An End-to-End Knowledge-based Slot Filling from Speech
May 10, 2021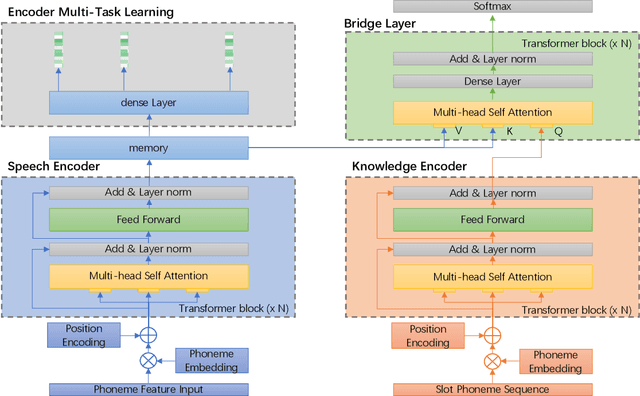
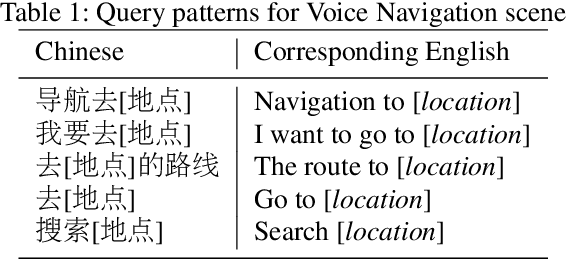
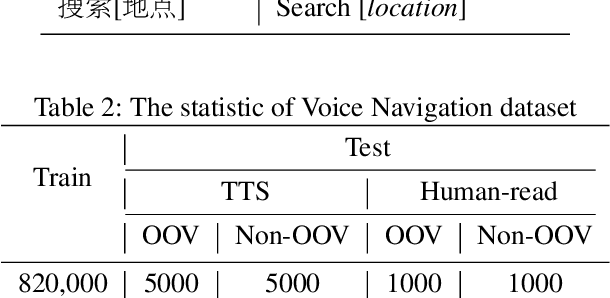
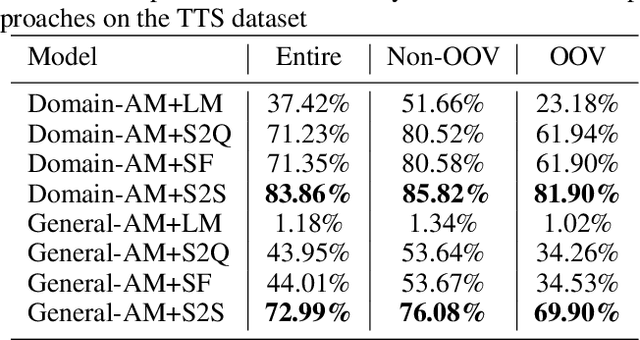
In contrast to conventional pipeline Spoken Language Understanding (SLU) which consists of automatic speech recognition (ASR) and natural language understanding (NLU), end-to-end SLU infers the semantic meaning directly from speech and overcomes the error propagation caused by ASR. End-to-end slot filling (SF) from speech is an essential component of end-to-end SLU, and is usually regarded as a sequence-to-sequence generation problem, heavily relied on the performance of language model of ASR. However, it is hard to generate a correct slot when the slot is out-of-vovabulary (OOV) in training data, especially when a slot is an anti-linguistic entity without grammatical rule. Inspired by object detection in computer vision that is to detect the object from an image, we consider SF as the task of slot detection from speech. In this paper, we formulate the SF task as a matching task and propose an end-to-end knowledge-based SF model, named Speech-to-Slot (Speech2Slot), to leverage knowledge to detect the boundary of a slot from the speech. We also release a large-scale dataset of Chinese speech for slot filling, containing more than 830,000 samples. The experiments show that our approach is markedly superior to the conventional pipeline SLU approach, and outperforms the state-of-the-art end-to-end SF approach with 12.51% accuracy improvement.
Lexical Access Model for Italian -- Modeling human speech processing: identification of words in running speech toward lexical access based on the detection of landmarks and other acoustic cues to features
Jun 24, 2021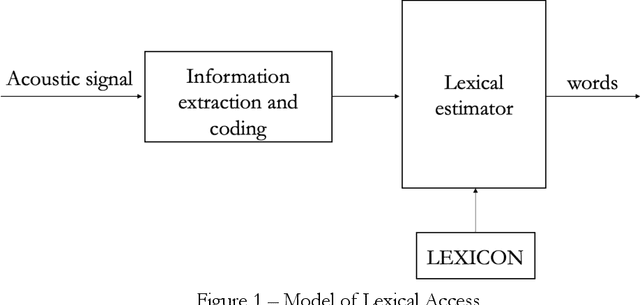
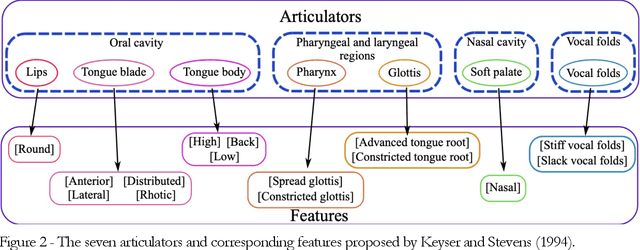
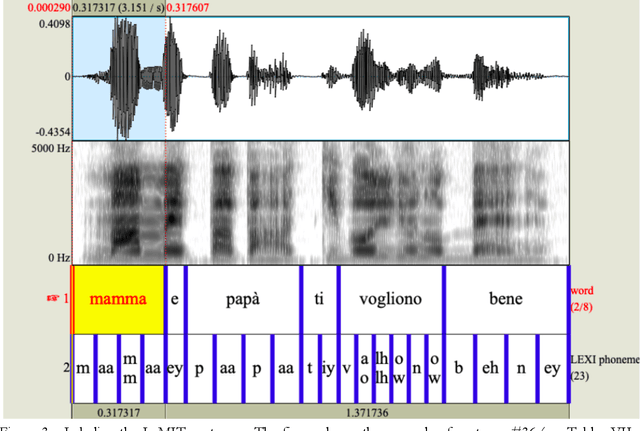
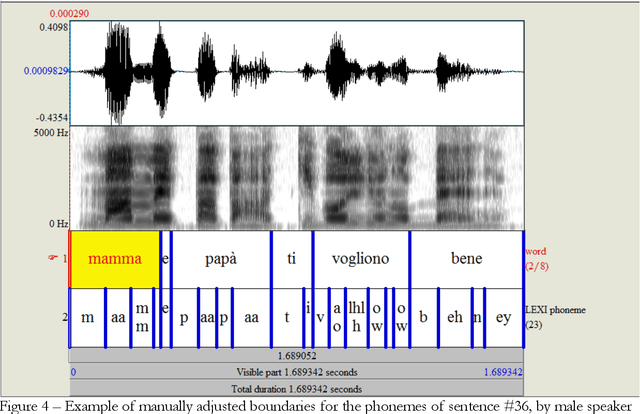
Modelling the process that a listener actuates in deriving the words intended by a speaker requires setting a hypothesis on how lexical items are stored in memory. This work aims at developing a system that imitates humans when identifying words in running speech and, in this way, provide a framework to better understand human speech processing. We build a speech recognizer for Italian based on the principles of Stevens' model of Lexical Access in which words are stored as hierarchical arrangements of distinctive features (Stevens, K. N. (2002). "Toward a model for lexical access based on acoustic landmarks and distinctive features," J. Acoust. Soc. Am., 111(4):1872-1891). Over the past few decades, the Speech Communication Group at the Massachusetts Institute of Technology (MIT) developed a speech recognition system for English based on this approach. Italian will be the first language beyond English to be explored; the extension to another language provides the opportunity to test the hypothesis that words are represented in memory as a set of hierarchically-arranged distinctive features, and reveal which of the underlying mechanisms may have a language-independent nature. This paper also introduces a new Lexical Access corpus, the LaMIT database, created and labeled specifically for this work, that will be provided freely to the speech research community. Future developments will test the hypothesis that specific acoustic discontinuities - called landmarks - that serve as cues to features, are language independent, while other cues may be language-dependent, with powerful implications for understanding how the human brain recognizes speech.
Bridging the Gap Between Clean Data Training and Real-World Inference for Spoken Language Understanding
Apr 13, 2021
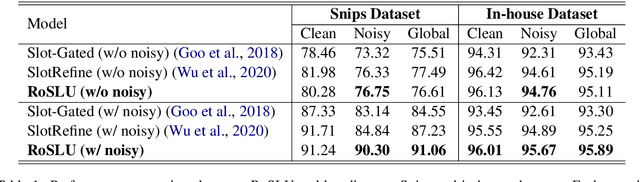
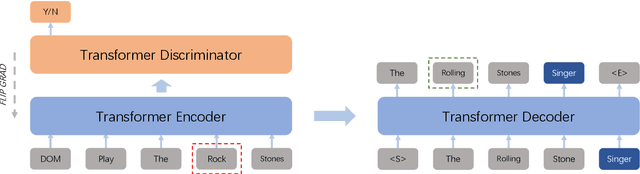
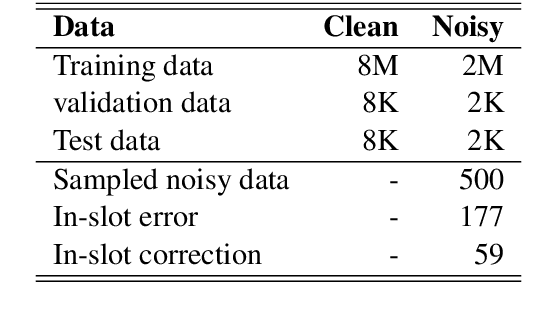
Spoken language understanding (SLU) system usually consists of various pipeline components, where each component heavily relies on the results of its upstream ones. For example, Intent detection (ID), and slot filling (SF) require its upstream automatic speech recognition (ASR) to transform the voice into text. In this case, the upstream perturbations, e.g. ASR errors, environmental noise and careless user speaking, will propagate to the ID and SF models, thus deteriorating the system performance. Therefore, the well-performing SF and ID models are expected to be noise resistant to some extent. However, existing models are trained on clean data, which causes a \textit{gap between clean data training and real-world inference.} To bridge the gap, we propose a method from the perspective of domain adaptation, by which both high- and low-quality samples are embedding into similar vector space. Meanwhile, we design a denoising generation model to reduce the impact of the low-quality samples. Experiments on the widely-used dataset, i.e. Snips, and large scale in-house dataset (10 million training examples) demonstrate that this method not only outperforms the baseline models on real-world (noisy) corpus but also enhances the robustness, that is, it produces high-quality results under a noisy environment. The source code will be released.
Utterance-Wise Meeting Transcription System Using Asynchronous Distributed Microphones
Jul 31, 2020
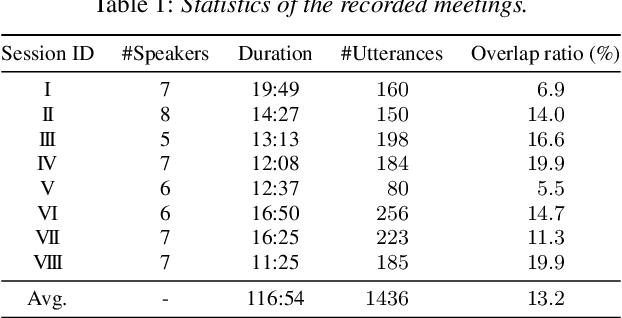
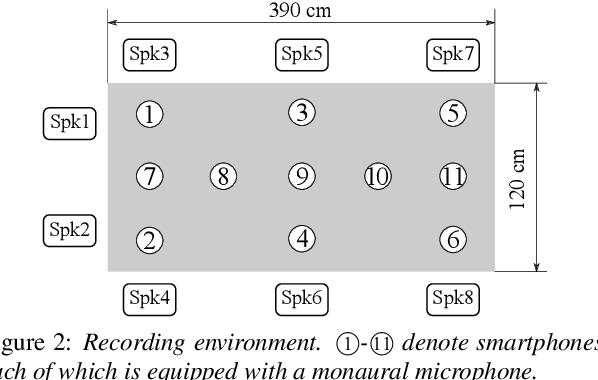
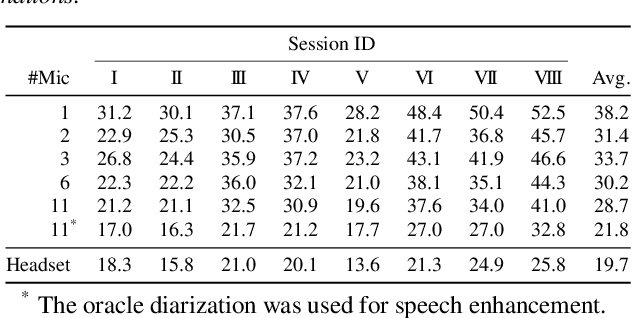
A novel framework for meeting transcription using asynchronous microphones is proposed in this paper. It consists of audio synchronization, speaker diarization, utterance-wise speech enhancement using guided source separation, automatic speech recognition, and duplication reduction. Doing speaker diarization before speech enhancement enables the system to deal with overlapped speech without considering sampling frequency mismatch between microphones. Evaluation on our real meeting datasets showed that our framework achieved a character error rate (CER) of 28.7 % by using 11 distributed microphones, while a monaural microphone placed on the center of the table had a CER of 38.2 %. We also showed that our framework achieved CER of 21.8 %, which is only 2.1 percentage points higher than the CER in headset microphone-based transcription.
Experiments of ASR-based mispronunciation detection for children and adult English learners
Apr 13, 2021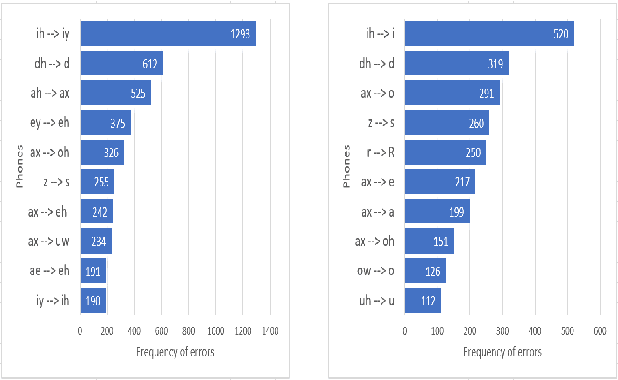
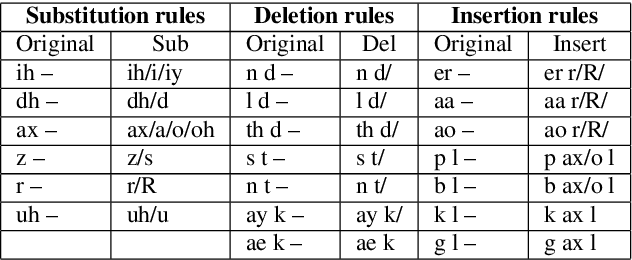
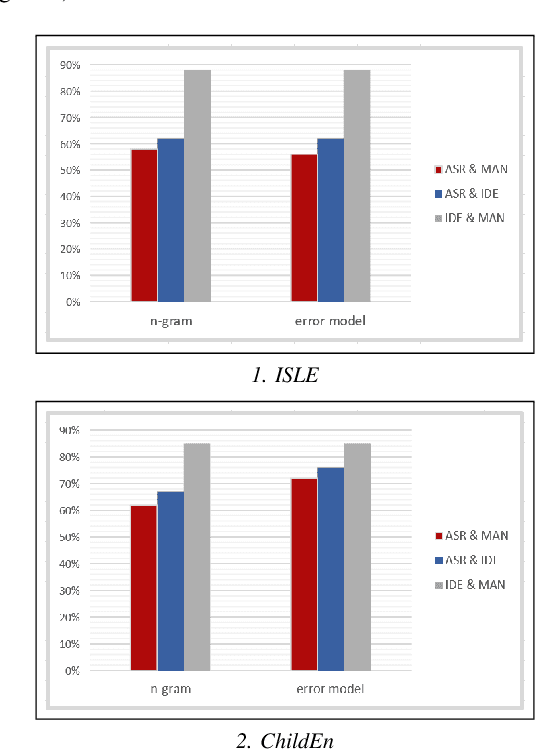
Pronunciation is one of the fundamentals of language learning, and it is considered a primary factor of spoken language when it comes to an understanding and being understood by others. The persistent presence of high error rates in speech recognition domains resulting from mispronunciations motivates us to find alternative techniques for handling mispronunciations. In this study, we develop a mispronunciation assessment system that checks the pronunciation of non-native English speakers, identifies the commonly mispronounced phonemes of Italian learners of English, and presents an evaluation of the non-native pronunciation observed in phonetically annotated speech corpora. In this work, to detect mispronunciations, we used a phone-based ASR implemented using Kaldi. We used two non-native English labeled corpora; (i) a corpus of Italian adults contains 5,867 utterances from 46 speakers, and (ii) a corpus of Italian children consists of 5,268 utterances from 78 children. Our results show that the selected error model can discriminate correct sounds from incorrect sounds in both native and nonnative speech, and therefore can be used to detect pronunciation errors in non-native speech. The phone error rates show improvement in using the error language model. The ASR system shows better accuracy after applying the error model on our selected corpora.
Large scale evaluation of importance maps in automatic speech recognition
May 21, 2020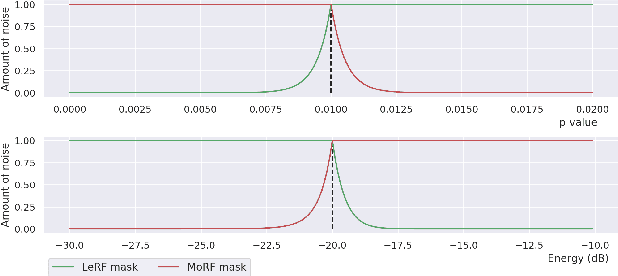
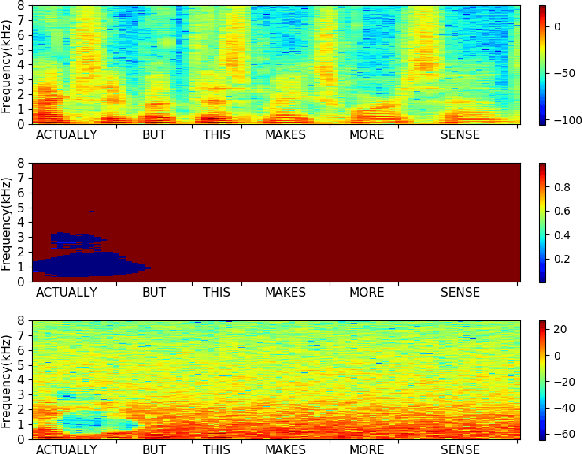
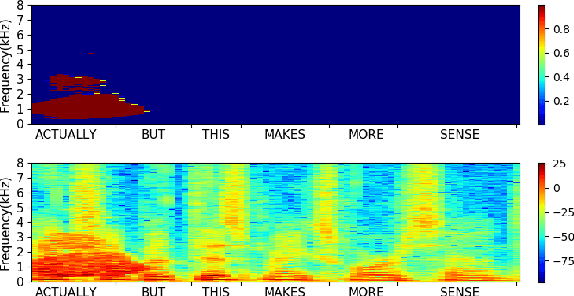
In this paper, we propose a metric that we call the structured saliency benchmark (SSBM) to evaluate importance maps computed for automatic speech recognizers on individual utterances. These maps indicate time-frequency points of the utterance that are most important for correct recognition of a target word. Our evaluation technique is not only suitable for standard classification tasks, but is also appropriate for structured prediction tasks like sequence-to-sequence models. Additionally, we use this approach to perform a large scale comparison of the importance maps created by our previously introduced technique using "bubble noise" to identify important points through correlation with a baseline approach based on smoothed speech energy and forced alignment. Our results show that the bubble analysis approach is better at identifying important speech regions than this baseline on 100 sentences from the AMI corpus.
Visual-Only Recognition of Normal, Whispered and Silent Speech
Feb 18, 2018
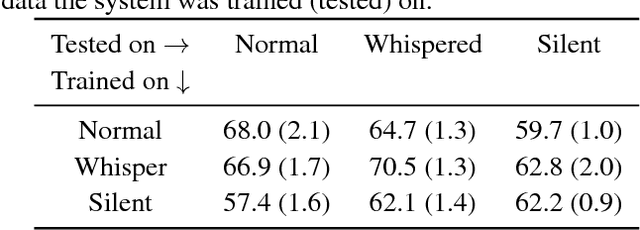
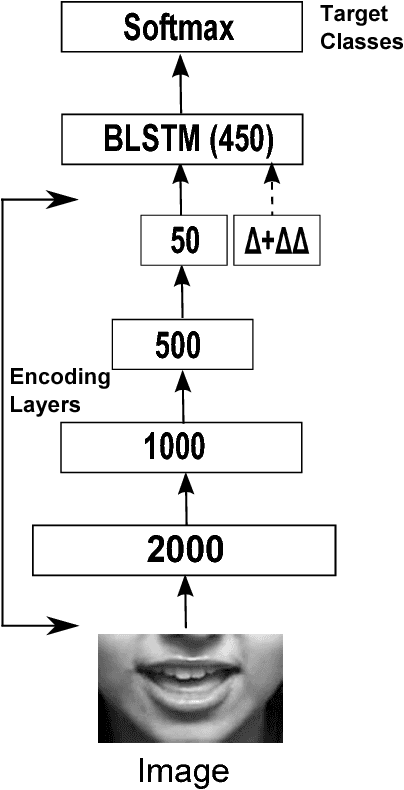
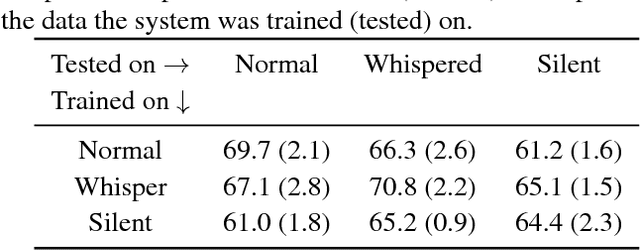
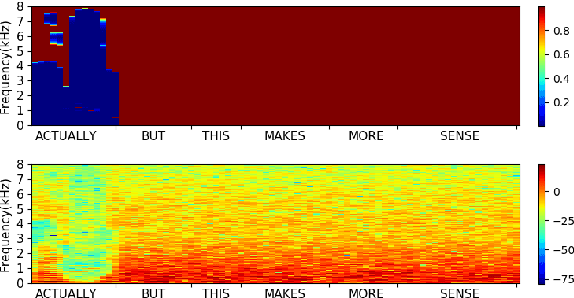
Silent speech interfaces have been recently proposed as a way to enable communication when the acoustic signal is not available. This introduces the need to build visual speech recognition systems for silent and whispered speech. However, almost all the recently proposed systems have been trained on vocalised data only. This is in contrast with evidence in the literature which suggests that lip movements change depending on the speech mode. In this work, we introduce a new audiovisual database which is publicly available and contains normal, whispered and silent speech. To the best of our knowledge, this is the first study which investigates the differences between the three speech modes using the visual modality only. We show that an absolute decrease in classification rate of up to 3.7% is observed when training and testing on normal and whispered, respectively, and vice versa. An even higher decrease of up to 8.5% is reported when the models are tested on silent speech. This reveals that there are indeed visual differences between the 3 speech modes and the common assumption that vocalized training data can be used directly to train a silent speech recognition system may not be true.
Cumulative Adaptation for BLSTM Acoustic Models
Jun 14, 2019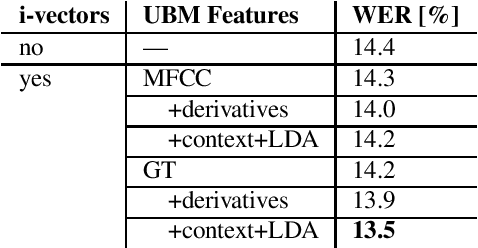
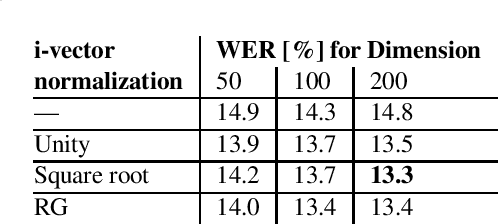
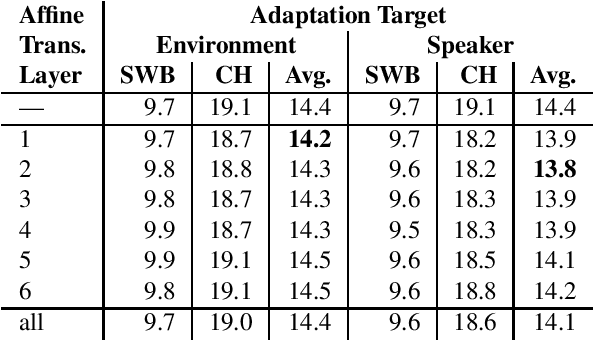
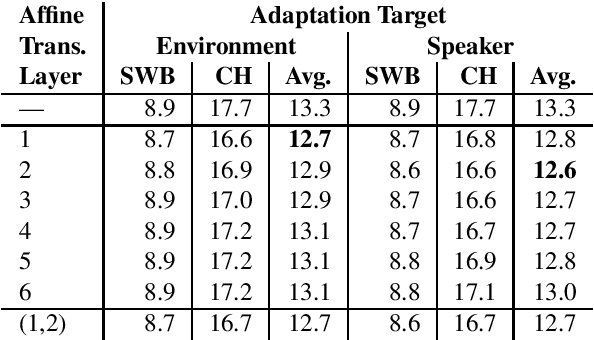
This paper addresses the robust speech recognition problem as an adaptation task. Specifically, we investigate the cumulative application of adaptation methods. A bidirectional Long Short-Term Memory (BLSTM) based neural network, capable of learning temporal relationships and translation invariant representations, is used for robust acoustic modelling. Further, i-vectors were used as an input to the neural network to perform instantaneous speaker and environment adaptation, providing 8\% relative improvement in word error rate on the NIST Hub5 2000 evaluation test set. By enhancing the first-pass i-vector based adaptation with a second-pass adaptation using speaker and environment dependent transformations within the network, a further relative improvement of 5\% in word error rate was achieved. We have reevaluated the features used to estimate i-vectors and their normalization to achieve the best performance in a modern large scale automatic speech recognition system.
Decoupling Pronunciation and Language for End-to-end Code-switching Automatic Speech Recognition
Oct 28, 2020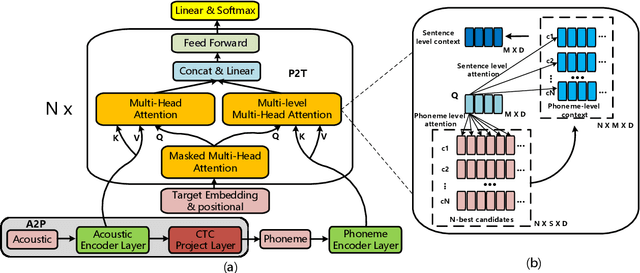
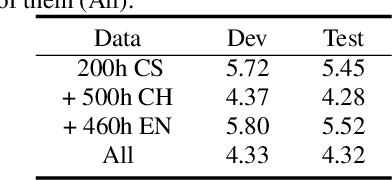
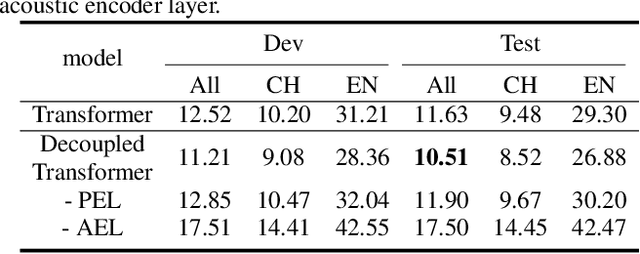
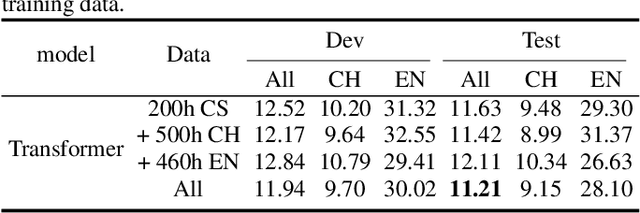
Despite the recent significant advances witnessed in end-to-end (E2E) ASR system for code-switching, hunger for audio-text paired data limits the further improvement of the models' performance. In this paper, we propose a decoupled transformer model to use monolingual paired data and unpaired text data to alleviate the problem of code-switching data shortage. The model is decoupled into two parts: audio-to-phoneme (A2P) network and phoneme-to-text (P2T) network. The A2P network can learn acoustic pattern scenarios using large-scale monolingual paired data. Meanwhile, it generates multiple phoneme sequence candidates for single audio data in real-time during the training process. Then the generated phoneme-text paired data is used to train the P2T network. This network can be pre-trained with large amounts of external unpaired text data. By using monolingual data and unpaired text data, the decoupled transformer model reduces the high dependency on code-switching paired training data of E2E model to a certain extent. Finally, the two networks are optimized jointly through attention fusion. We evaluate the proposed method on the public Mandarin-English code-switching dataset. Compared with our transformer baseline, the proposed method achieves 18.14% relative mix error rate reduction.