 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Exploring wav2vec 2.0 on speaker verification and language identification
Jan 14, 2021
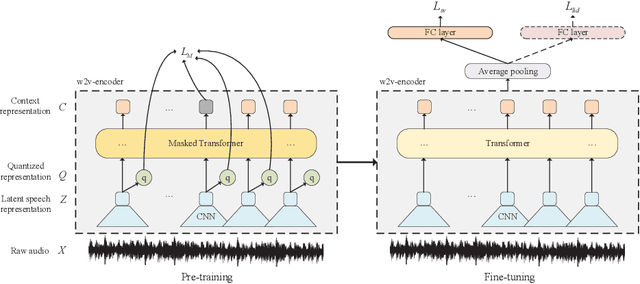



Wav2vec 2.0 is a recently proposed self-supervised framework for speech representation learning. It follows a two-stage training process of pre-training and fine-tuning, and performs well in speech recognition tasks especially ultra-low resource cases. In this work, we attempt to extend self-supervised framework to speaker verification and language identification. First, we use some preliminary experiments to indicate that wav2vec 2.0 can capture the information about the speaker and language. Then we demonstrate the effectiveness of wav2vec 2.0 on the two tasks respectively. For speaker verification, we obtain a new state-of-the-art result, Equal Error Rate (EER) of 3.61% on the VoxCeleb1 dataset. For language identification, we obtain an EER of 12.02% on 1 second condition and an EER of 3.47% on full-length condition of the AP17-OLR dataset. Finally, we utilize one model to achieve the unified modeling by the multi-task learning for the two tasks.
Affective Burst Detection from Speech using Kernel-fusion Dilated Convolutional Neural Networks
Oct 08, 2021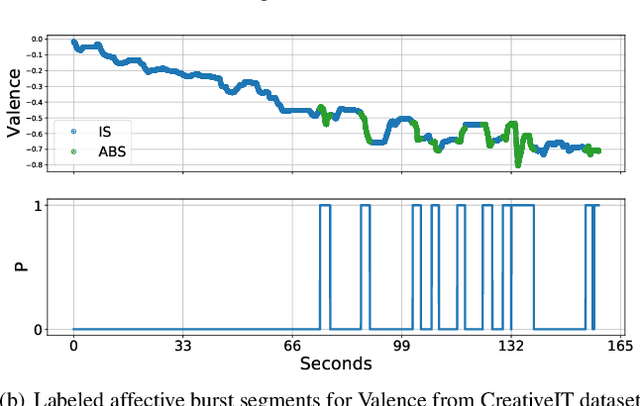
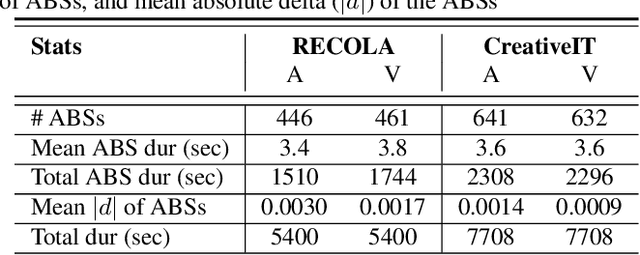
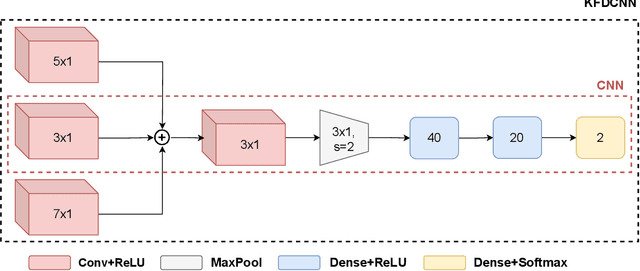
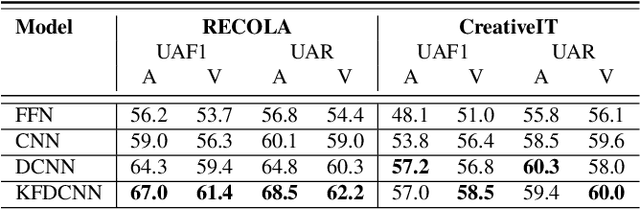
As speech-interfaces are getting richer and widespread, speech emotion recognition promises more attractive applications. In the continuous emotion recognition (CER) problem, tracking changes across affective states is an important and desired capability. Although CER studies widely use correlation metrics in evaluations, these metrics do not always capture all the high-intensity changes in the affective domain. In this paper, we define a novel affective burst detection problem to accurately capture high-intensity changes of the affective attributes. For this problem, we formulate a two-class classification approach to isolate affective burst regions over the affective state contour. The proposed classifier is a kernel-fusion dilated convolutional neural network (KFDCNN) architecture driven by speech spectral features to segment the affective attribute contour into idle and burst sections. Experimental evaluations are performed on the RECOLA and CreativeIT datasets. The proposed KFDCNN is observed to outperform baseline feedforward neural networks on both datasets.
Learning Efficient Representations for Keyword Spotting with Triplet Loss
Jan 12, 2021
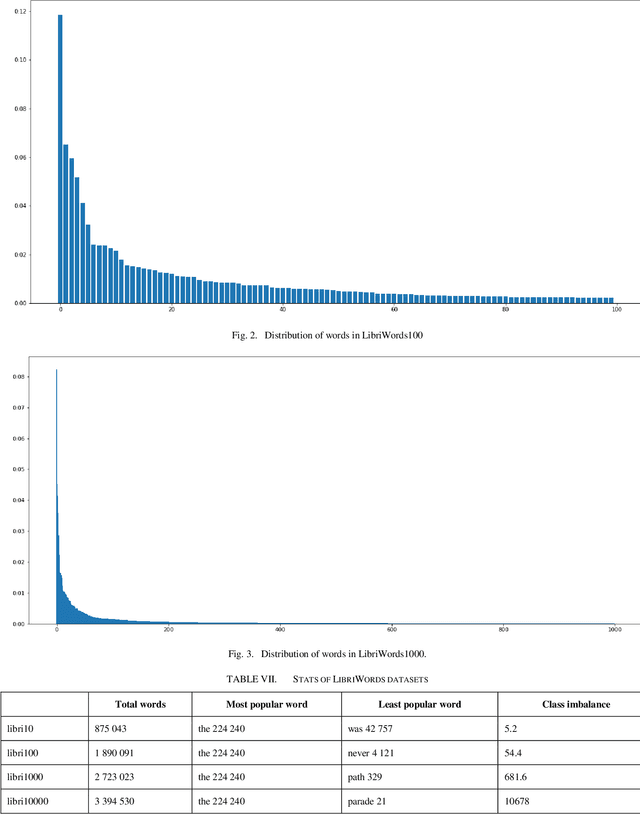
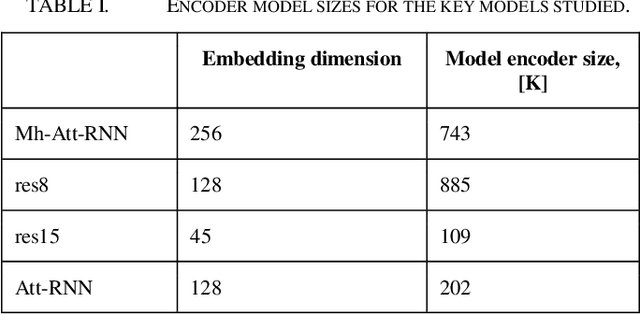
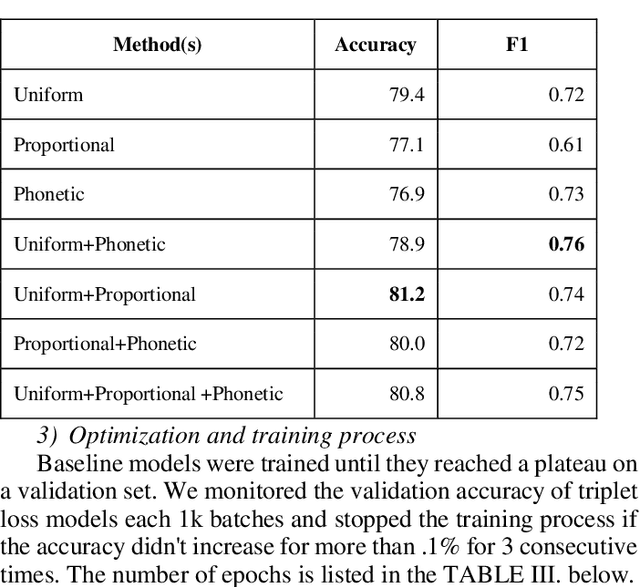
In the past few years, triplet loss-based metric embeddings have become a de-facto standard for several important computer vision problems, most notably, person reidentification. On the other hand, in the area of speech recognition the metric embeddings generated by the triplet loss are rarely used even for classification problems. We fill this gap showing that a combination of two representation learning techniques: a triplet loss-based embedding and a variant of kNN for classification instead of cross-entropy loss significantly (by 26% to 38%) improves the classification accuracy for convolutional networks on a LibriSpeech-derived LibriWords datasets. To do so, we propose a novel phonetic similarity based triplet mining approach. We also match the current best published SOTA for Google Speech Commands dataset V2 10+2-class classification with an architecture that is about 6 times more compact and improve the current best published SOTA for 35-class classification on Google Speech Commands dataset V2 by over 40%.
Bandwidth Embeddings for Mixed-bandwidth Speech Recognition
Sep 05, 2019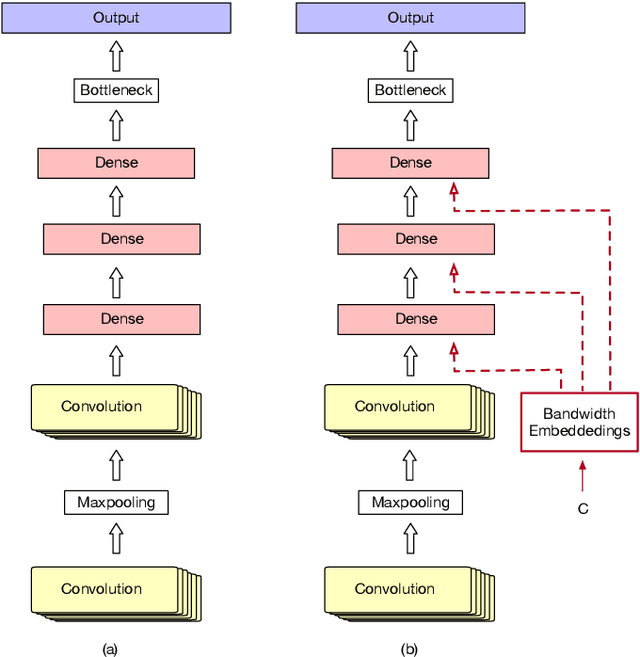
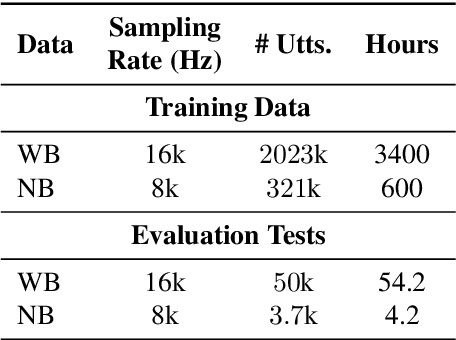
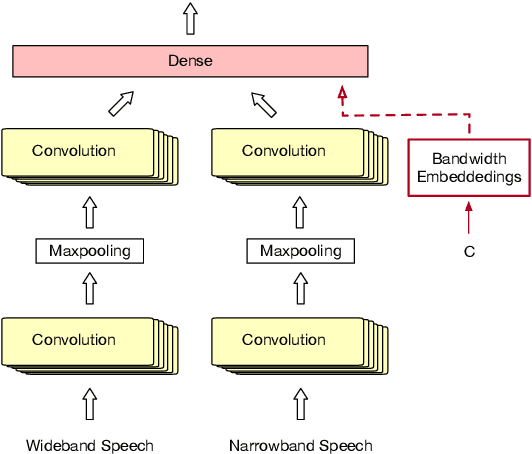
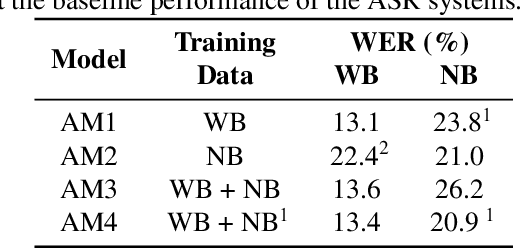
In this paper, we tackle the problem of handling narrowband and wideband speech by building a single acoustic model (AM), also called mixed bandwidth AM. In the proposed approach, an auxiliary input feature is used to provide the bandwidth information to the model, and bandwidth embeddings are jointly learned as part of acoustic model training. Experimental evaluations show that using bandwidth embeddings helps the model to handle the variability of the narrow and wideband speech, and makes it possible to train a mixed-bandwidth AM. Furthermore, we propose to use parallel convolutional layers to handle the mismatch between the narrow and wideband speech better, where separate convolution layers are used for each type of input speech signal. Our best system achieves 13% relative improvement on narrowband speech, while not degrading on wideband speech.
Fixing Errors of the Google Voice Recognizer through Phonetic Distance Metrics
Feb 18, 2021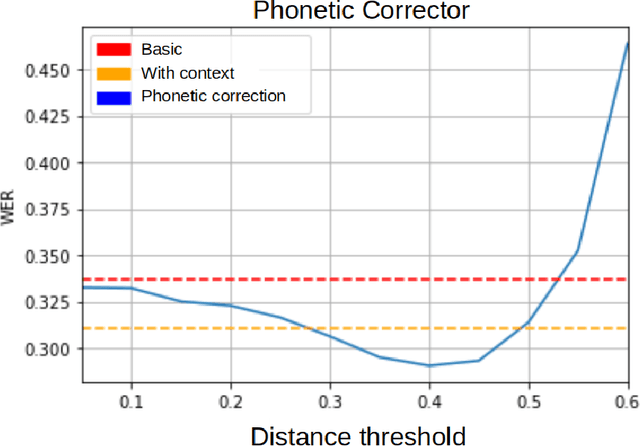

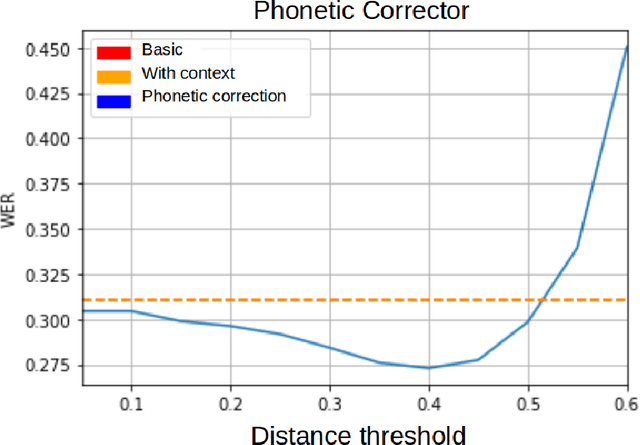
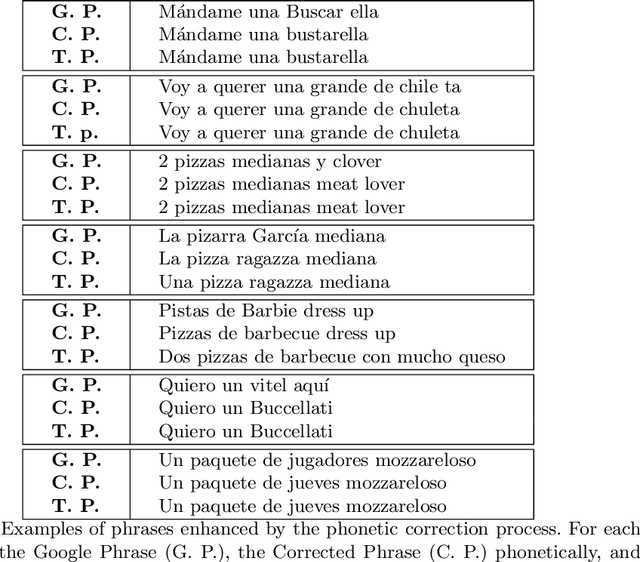
Speech recognition systems for the Spanish language, such as Google's, produce errors quite frequently when used in applications of a specific domain. These errors mostly occur when recognizing words new to the recognizer's language model or ad hoc to the domain. This article presents an algorithm that uses Levenshtein distance on phonemes to reduce the speech recognizer's errors. The preliminary results show that it is possible to correct the recognizer's errors significantly by using this metric and using a dictionary of specific phrases from the domain of the application. Despite being designed for particular domains, the algorithm proposed here is of general application. The phrases that must be recognized can be explicitly defined for each application, without the algorithm having to be modified. It is enough to indicate to the algorithm the set of sentences on which it must work. The algorithm's complexity is $O(tn)$, where $t$ is the number of words in the transcript to be corrected, and $n$ is the number of phrases specific to the domain.
* 13 pages, 4 figures. This article is a translation of the paper "Correcci\'on de errores del reconocedor de voz de Google usando m\'etricas de distancia fon\'etica" presented in COMIA 2018
Impact of ASR on Alzheimer's Disease Detection: All Errors are Equal, but Deletions are More Equal than Others
Apr 08, 2019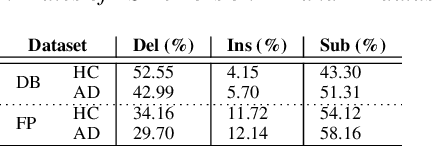
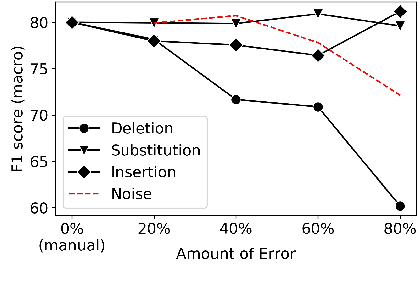
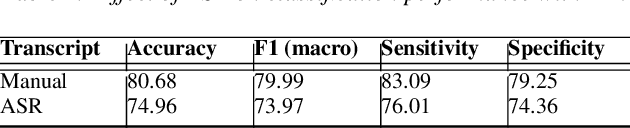
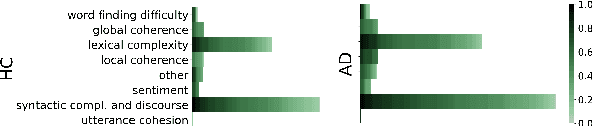
Automatic Speech Recognition (ASR) is a critical component of any fully-automated speech-based Alzheimer's disease (AD) detection model. However, despite years of speech recognition research, little is known about the impact of ASR performance on AD detection. In this paper, we experiment with controlled amounts of artificially generated ASR errors and investigate their influence on AD detection. We find that deletion errors affect AD detection performance the most, due to their impact on the features of syntactic complexity and discourse representation in speech. We show the trend to be generalisable across two different datasets and two different speech-related tasks. As a conclusion, we propose changing the ASR optimization functions to reflect a higher penalty for deletion errors when using ASR for AD detection.
Libri-Adapt: A New Speech Dataset for Unsupervised Domain Adaptation
Sep 06, 2020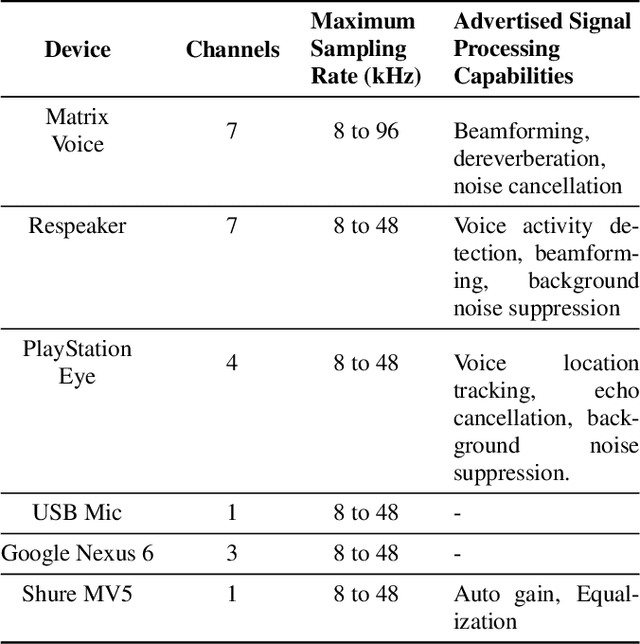
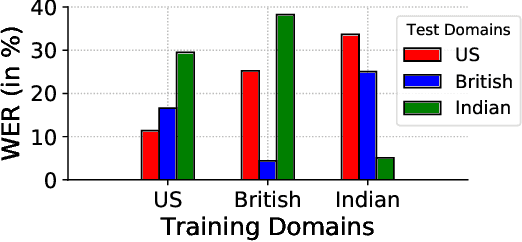
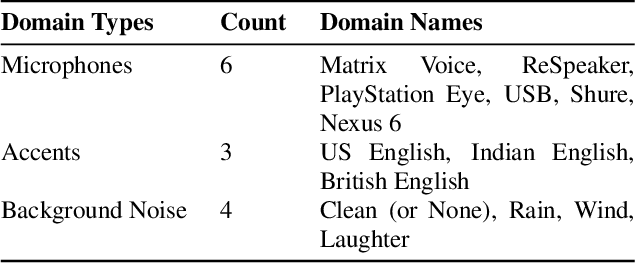
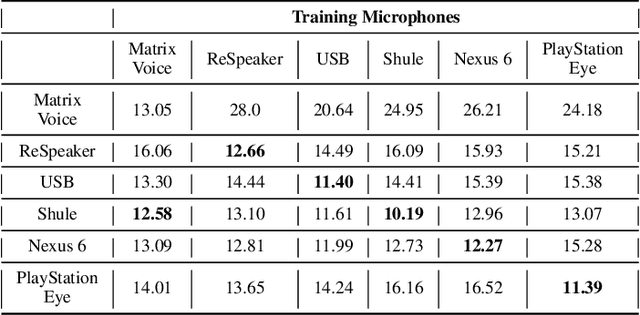
This paper introduces a new dataset, Libri-Adapt, to support unsupervised domain adaptation research on speech recognition models. Built on top of the LibriSpeech corpus, Libri-Adapt contains English speech recorded on mobile and embedded-scale microphones, and spans 72 different domains that are representative of the challenging practical scenarios encountered by ASR models. More specifically, Libri-Adapt facilitates the study of domain shifts in ASR models caused by a) different acoustic environments, b) variations in speaker accents, c) heterogeneity in the hardware and platform software of the microphones, and d) a combination of the aforementioned three shifts. We also provide a number of baseline results quantifying the impact of these domain shifts on the Mozilla DeepSpeech2 ASR model.
* 5 pages, Published at IEEE ICASSP 2020
PhyAug: Physics-Directed Data Augmentation for Deep Sensing Model Transfer in Cyber-Physical Systems
Apr 19, 2021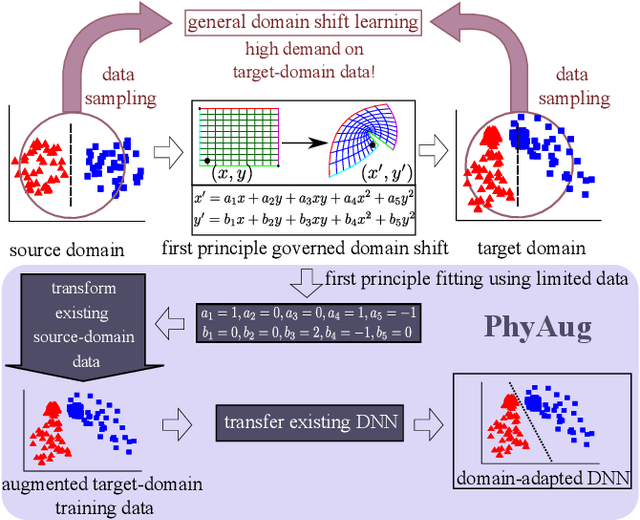
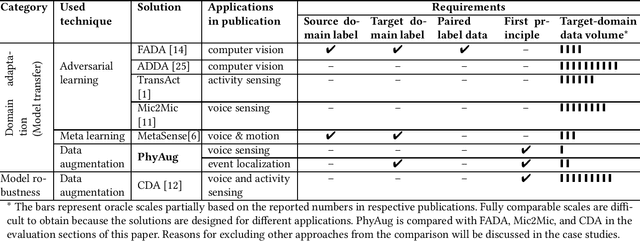
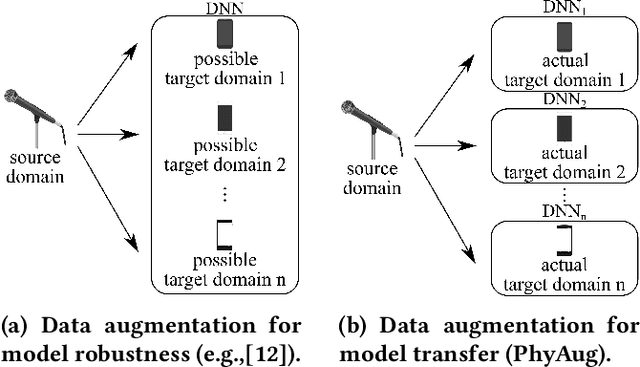

Run-time domain shifts from training-phase domains are common in sensing systems designed with deep learning. The shifts can be caused by sensor characteristic variations and/or discrepancies between the design-phase model and the actual model of the sensed physical process. To address these issues, existing transfer learning techniques require substantial target-domain data and thus incur high post-deployment overhead. This paper proposes to exploit the first principle governing the domain shift to reduce the demand on target-domain data. Specifically, our proposed approach called PhyAug uses the first principle fitted with few labeled or unlabeled source/target-domain data pairs to transform the existing source-domain training data into augmented data for updating the deep neural networks. In two case studies of keyword spotting and DeepSpeech2-based automatic speech recognition, with 5-second unlabeled data collected from the target microphones, PhyAug recovers the recognition accuracy losses due to microphone characteristic variations by 37% to 72%. In a case study of seismic source localization with TDoA fngerprints, by exploiting the frst principle of signal propagation in uneven media, PhyAug only requires 3% to 8% of labeled TDoA measurements required by the vanilla fingerprinting approach in achieving the same localization accuracy.
BRDS: An FPGA-based LSTM Accelerator with Row-Balanced Dual-Ratio Sparsification
Jan 07, 2021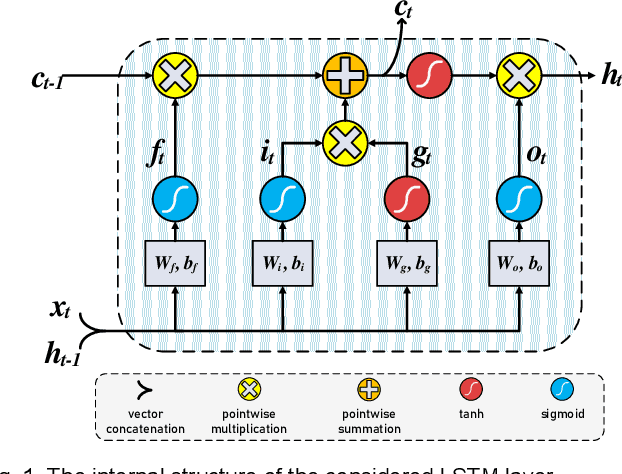

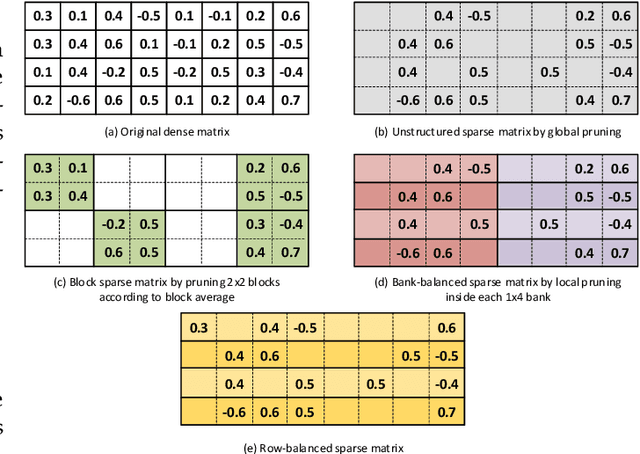
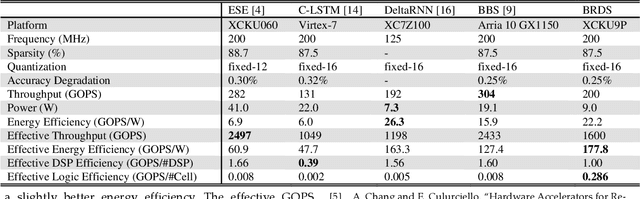
In this paper, first, a hardware-friendly pruning algorithm for reducing energy consumption and improving the speed of Long Short-Term Memory (LSTM) neural network accelerators is presented. Next, an FPGA-based platform for efficient execution of the pruned networks based on the proposed algorithm is introduced. By considering the sensitivity of two weight matrices of the LSTM models in pruning, different sparsity ratios (i.e., dual-ratio sparsity) are applied to these weight matrices. To reduce memory accesses, a row-wise sparsity pattern is adopted. The proposed hardware architecture makes use of computation overlapping and pipelining to achieve low-power and high-speed. The effectiveness of the proposed pruning algorithm and accelerator is assessed under some benchmarks for natural language processing, binary sentiment classification, and speech recognition. Results show that, e.g., compared to a recently published work in this field, the proposed accelerator could provide up to 272% higher effective GOPS/W and the perplexity error is reduced by up to 1.4% for the PTB dataset.
Joint Masked CPC and CTC Training for ASR
Oct 30, 2020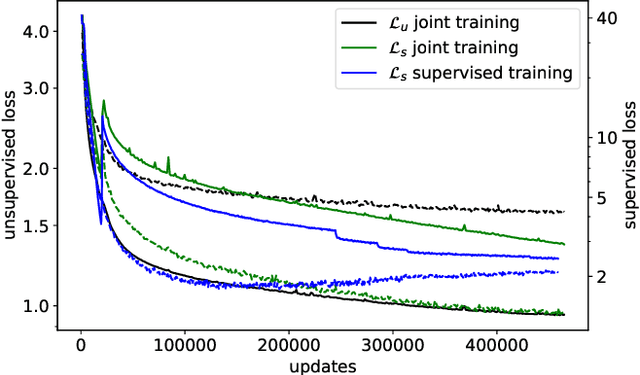
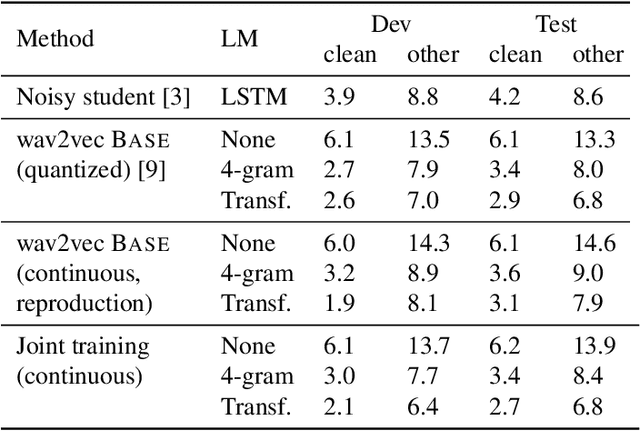
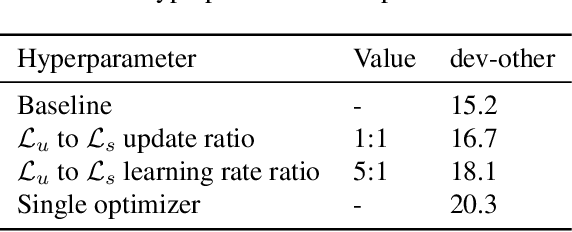
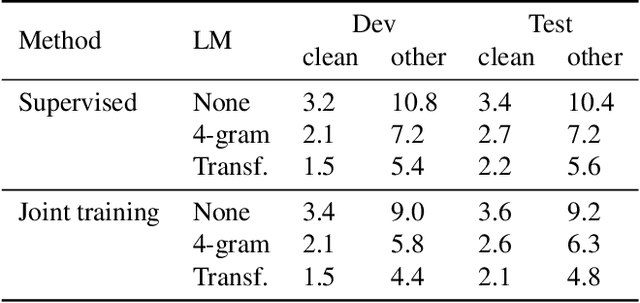
Self-supervised learning (SSL) has shown promise in learning representations of audio that are useful for automatic speech recognition (ASR). But, training SSL models like wav2vec~2.0 requires a two-stage pipeline. In this paper we demonstrate a single-stage training of ASR models that can utilize both unlabeled and labeled data. During training, we alternately minimize two losses: an unsupervised masked Contrastive Predictive Coding (CPC) loss and the supervised audio-to-text alignment loss Connectionist Temporal Classification (CTC). We show that this joint training method directly optimizes performance for the downstream ASR task using unsupervised data while achieving similar word error rates to wav2vec~2.0 on the Librispeech 100-hour dataset. Finally, we postulate that solving the contrastive task is a regularization for the supervised CTC loss.