 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Leveraging neural representations for facilitating access to untranscribed speech from endangered languages
Mar 26, 2021
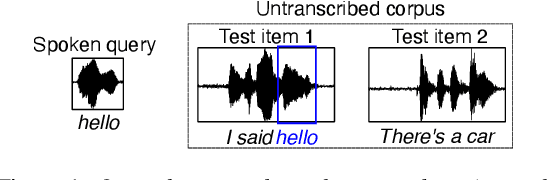
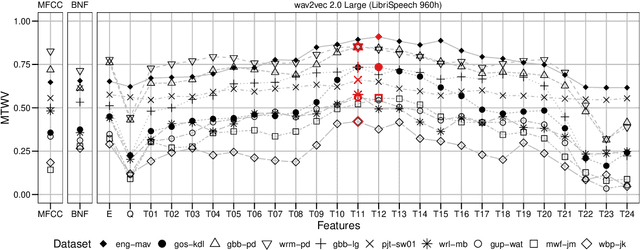
For languages with insufficient resources to train speech recognition systems, query-by-example spoken term detection (QbE-STD) offers a way of accessing an untranscribed speech corpus by helping identify regions where spoken query terms occur. Yet retrieval performance can be poor when the query and corpus are spoken by different speakers and produced in different recording conditions. Using data selected from a variety of speakers and recording conditions from 7 Australian Aboriginal languages and a regional variety of Dutch, all of which are endangered or vulnerable, we evaluated whether QbE-STD performance on these languages could be improved by leveraging representations extracted from the pre-trained English wav2vec 2.0 model. Compared to the use of Mel-frequency cepstral coefficients and bottleneck features, we find that representations from the middle layers of the wav2vec 2.0 Transformer offer large gains in task performance (between 56% and 86%). While features extracted using the pre-trained English model yielded improved detection on all the evaluation languages, better detection performance was associated with the evaluation language's phonological similarity to English.
Mutually-Constrained Monotonic Multihead Attention for Online ASR
Mar 26, 2021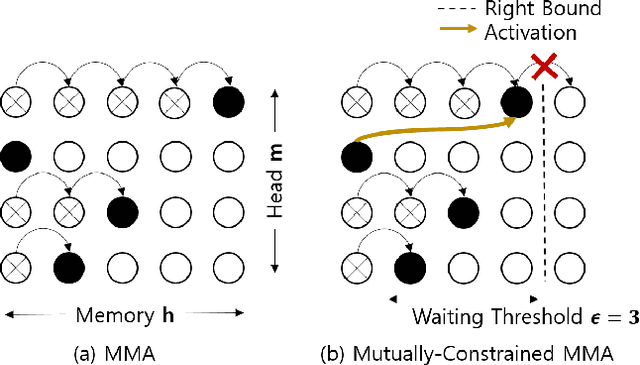
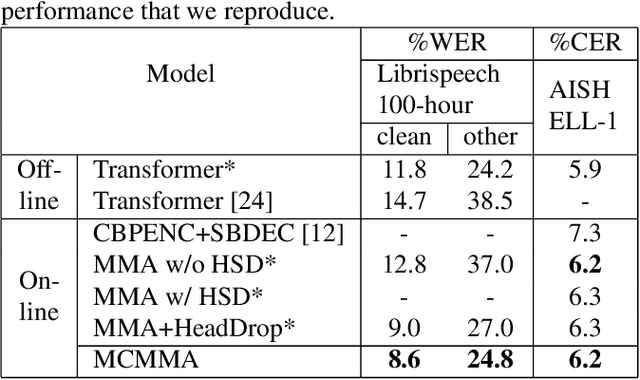
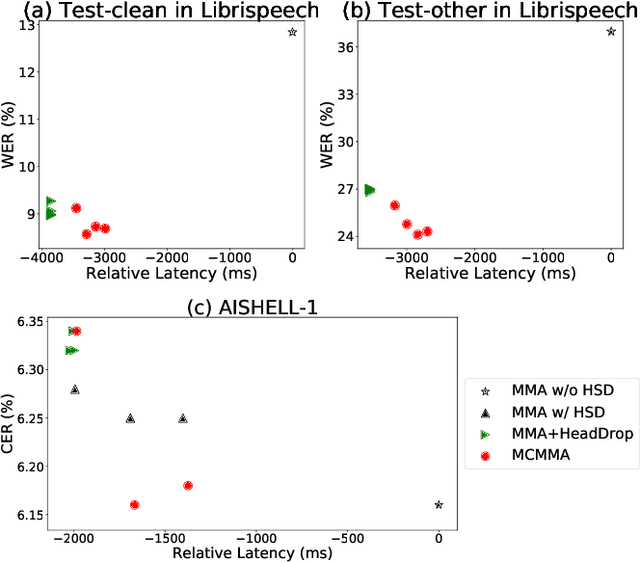
Despite the feature of real-time decoding, Monotonic Multihead Attention (MMA) shows comparable performance to the state-of-the-art offline methods in machine translation and automatic speech recognition (ASR) tasks. However, the latency of MMA is still a major issue in ASR and should be combined with a technique that can reduce the test latency at inference time, such as head-synchronous beam search decoding, which forces all non-activated heads to activate after a small fixed delay from the first head activation. In this paper, we remove the discrepancy between training and test phases by considering, in the training of MMA, the interactions across multiple heads that will occur in the test time. Specifically, we derive the expected alignments from monotonic attention by considering the boundaries of other heads and reflect them in the learning process. We validate our proposed method on the two standard benchmark datasets for ASR and show that our approach, MMA with the mutually-constrained heads from the training stage, provides better performance than baselines.
A Comparative Study of Self-supervised Speech Representation Based Voice Conversion
Jul 10, 2022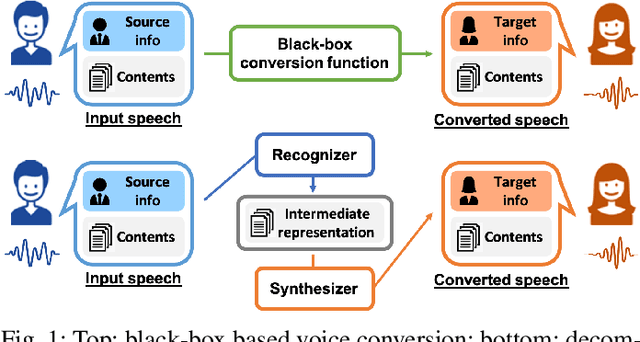
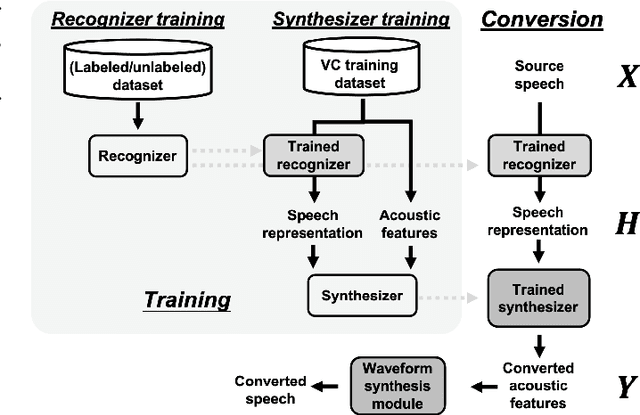
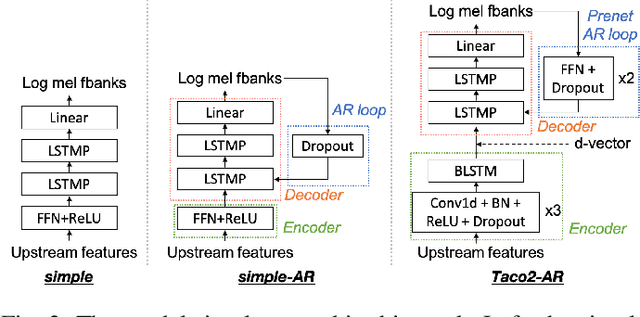
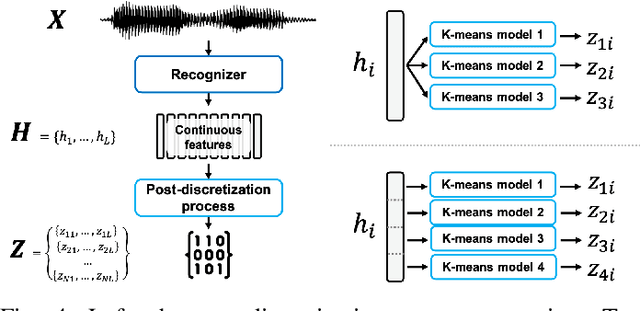
We present a large-scale comparative study of self-supervised speech representation (S3R)-based voice conversion (VC). In the context of recognition-synthesis VC, S3Rs are attractive owing to their potential to replace expensive supervised representations such as phonetic posteriorgrams (PPGs), which are commonly adopted by state-of-the-art VC systems. Using S3PRL-VC, an open-source VC software we previously developed, we provide a series of in-depth objective and subjective analyses under three VC settings: intra-/cross-lingual any-to-one (A2O) and any-to-any (A2A) VC, using the voice conversion challenge 2020 (VCC2020) dataset. We investigated S3R-based VC in various aspects, including model type, multilinguality, and supervision. We also studied the effect of a post-discretization process with k-means clustering and showed how it improves in the A2A setting. Finally, the comparison with state-of-the-art VC systems demonstrates the competitiveness of S3R-based VC and also sheds light on the possible improving directions.
CoVoST 2 and Massively Multilingual Speech-to-Text Translation
Aug 20, 2020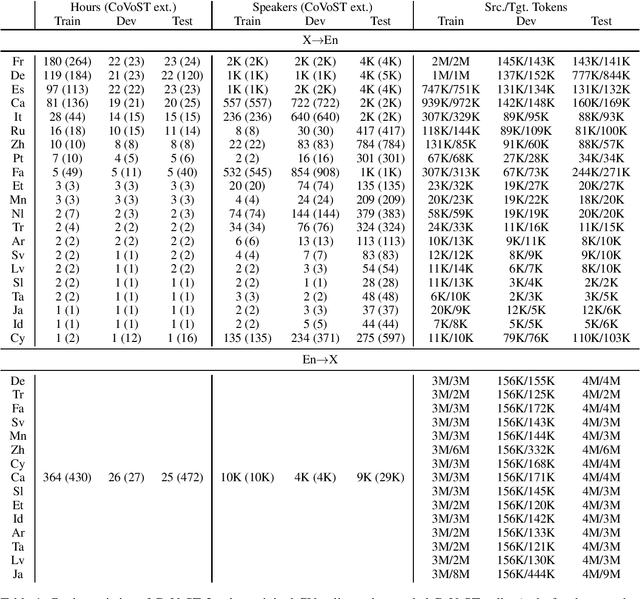
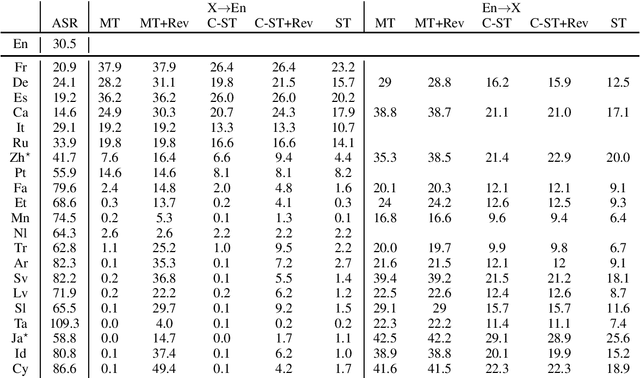
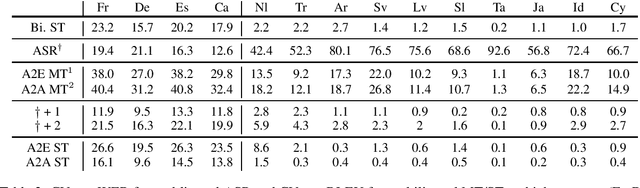
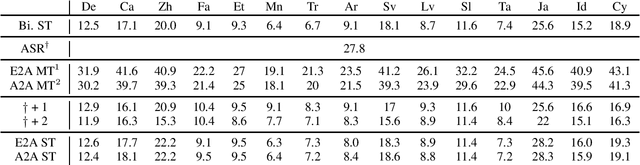
Speech translation has recently become an increasingly popular topic of research, partly due to the development of benchmark datasets. Nevertheless, current datasets cover a limited number of languages. With the aim to foster research in massive multilingual speech translation and speech translation for low resource language pairs, we release CoVoST 2, a large-scale multilingual speech translation corpus covering translations from 21 languages into English and from English into 15 languages. This represents the largest open dataset available to date from total volume and language coverage perspective. Data sanity checks provide evidence about the quality of the data, which is released under CC0 license. We also provide extensive speech recognition, bilingual and multilingual machine translation and speech translation baselines.
Implicit Channel Learning for Machine Learning Applications in 6G Wireless Networks
Jun 24, 2022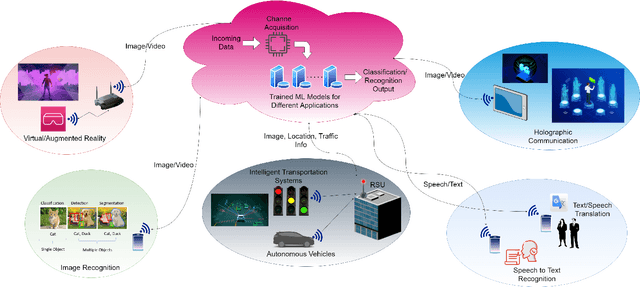
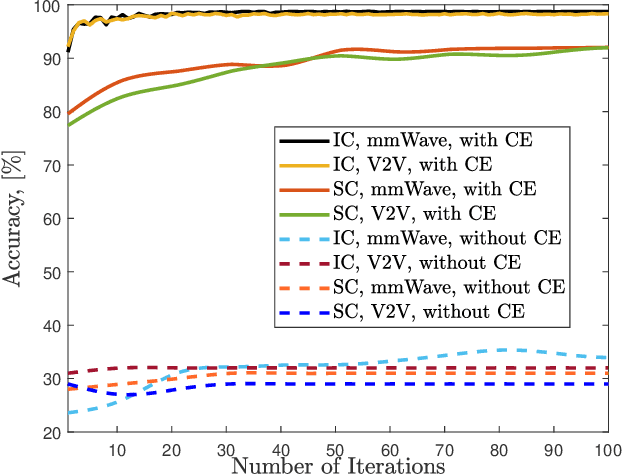
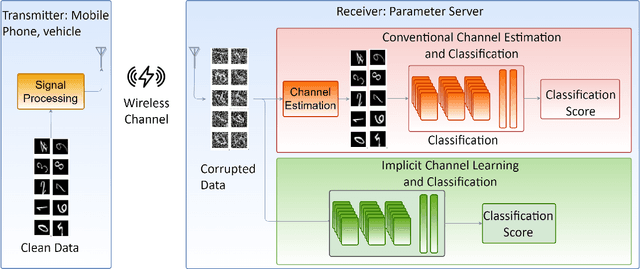
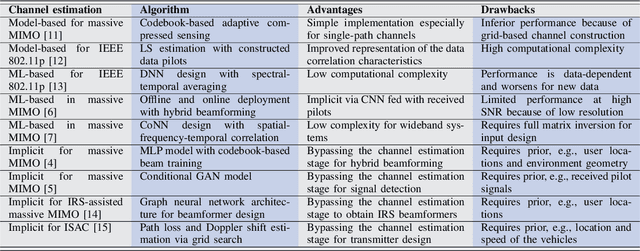
With the deployment of the fifth generation (5G) wireless systems gathering momentum across the world, possible technologies for 6G are under active research discussions. In particular, the role of machine learning (ML) in 6G is expected to enhance and aid emerging applications such as virtual and augmented reality, vehicular autonomy, and computer vision. This will result in large segments of wireless data traffic comprising image, video and speech. The ML algorithms process these for classification/recognition/estimation through the learning models located on cloud servers. This requires wireless transmission of data from edge devices to the cloud server. Channel estimation, handled separately from recognition step, is critical for accurate learning performance. Toward combining the learning for both channel and the ML data, we introduce implicit channel learning to perform the ML tasks without estimating the wireless channel. Here, the ML models are trained with channel-corrupted datasets in place of nominal data. Without channel estimation, the proposed approach exhibits approximately 60% improvement in image and speech classification tasks for diverse scenarios such as millimeter wave and IEEE 802.11p vehicular channels.
Bridging the gap between streaming and non-streaming ASR systems bydistilling ensembles of CTC and RNN-T models
Apr 25, 2021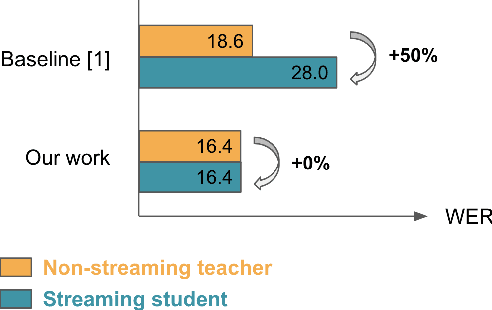
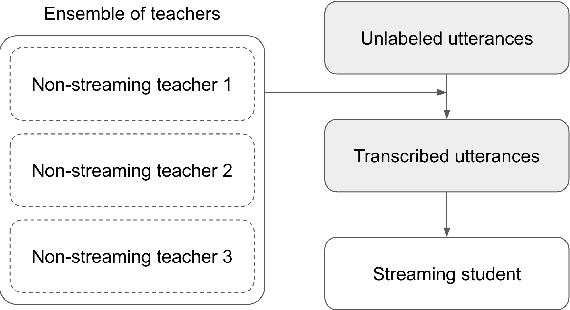

Streaming end-to-end automatic speech recognition (ASR) systems are widely used in everyday applications that require transcribing speech to text in real-time. Their minimal latency makes them suitable for such tasks. Unlike their non-streaming counterparts, streaming models are constrained to be causal with no future context and suffer from higher word error rates (WER). To improve streaming models, a recent study [1] proposed to distill a non-streaming teacher model on unsupervised utterances, and then train a streaming student using the teachers' predictions. However, the performance gap between teacher and student WERs remains high. In this paper, we aim to close this gap by using a diversified set of non-streaming teacher models and combining them using Recognizer Output Voting Error Reduction (ROVER). In particular, we show that, despite being weaker than RNN-T models, CTC models are remarkable teachers. Further, by fusing RNN-T and CTC models together, we build the strongest teachers. The resulting student models drastically improve upon streaming models of previous work [1]: the WER decreases by 41% on Spanish, 27% on Portuguese, and 13% on French.
Design and Optimization of a Speech Recognition Front-End for Distant-Talking Control of a Music Playback Device
May 05, 2014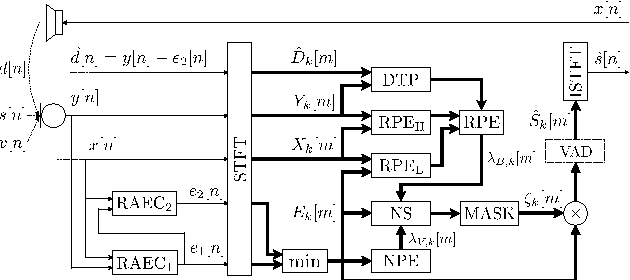

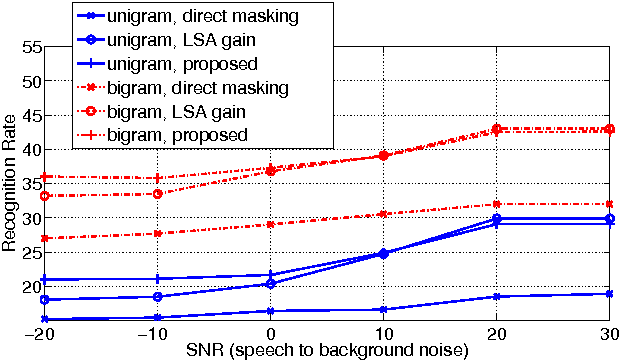
This paper addresses the challenging scenario for the distant-talking control of a music playback device, a common portable speaker with four small loudspeakers in close proximity to one microphone. The user controls the device through voice, where the speech-to-music ratio can be as low as -30 dB during music playback. We propose a speech enhancement front-end that relies on known robust methods for echo cancellation, double-talk detection, and noise suppression, as well as a novel adaptive quasi-binary mask that is well suited for speech recognition. The optimization of the system is then formulated as a large scale nonlinear programming problem where the recognition rate is maximized and the optimal values for the system parameters are found through a genetic algorithm. We validate our methodology by testing over the TIMIT database for different music playback levels and noise types. Finally, we show that the proposed front-end allows a natural interaction with the device for limited-vocabulary voice commands.
Multi-Speaker ASR Combining Non-Autoregressive Conformer CTC and Conditional Speaker Chain
Jun 16, 2021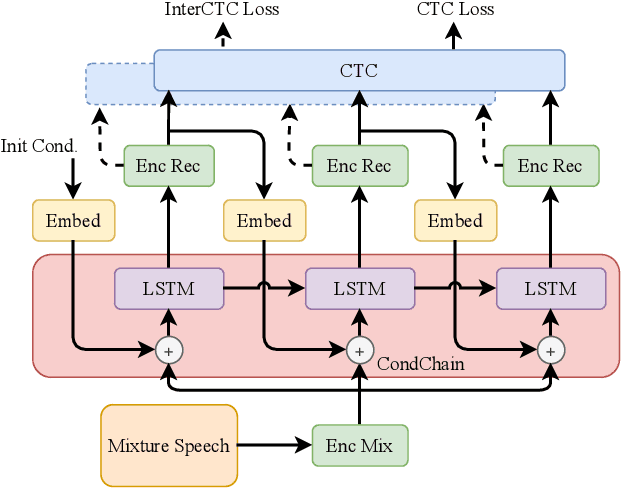



Non-autoregressive (NAR) models have achieved a large inference computation reduction and comparable results with autoregressive (AR) models on various sequence to sequence tasks. However, there has been limited research aiming to explore the NAR approaches on sequence to multi-sequence problems, like multi-speaker automatic speech recognition (ASR). In this study, we extend our proposed conditional chain model to NAR multi-speaker ASR. Specifically, the output of each speaker is inferred one-by-one using both the input mixture speech and previously-estimated conditional speaker features. In each step, a NAR connectionist temporal classification (CTC) encoder is used to perform parallel computation. With this design, the total inference steps will be restricted to the number of mixed speakers. Besides, we also adopt the Conformer and incorporate an intermediate CTC loss to improve the performance. Experiments on WSJ0-Mix and LibriMix corpora show that our model outperforms other NAR models with only a slight increase of latency, achieving WERs of 22.3% and 24.9%, respectively. Moreover, by including the data of variable numbers of speakers, our model can even better than the PIT-Conformer AR model with only 1/7 latency, obtaining WERs of 19.9% and 34.3% on WSJ0-2mix and WSJ0-3mix sets. All of our codes are publicly available at https://github.com/pengchengguo/espnet/tree/conditional-multispk.
Learning Discriminative features using Center Loss and Reconstruction as Regularizer for Speech Emotion Recognition
Jun 19, 2019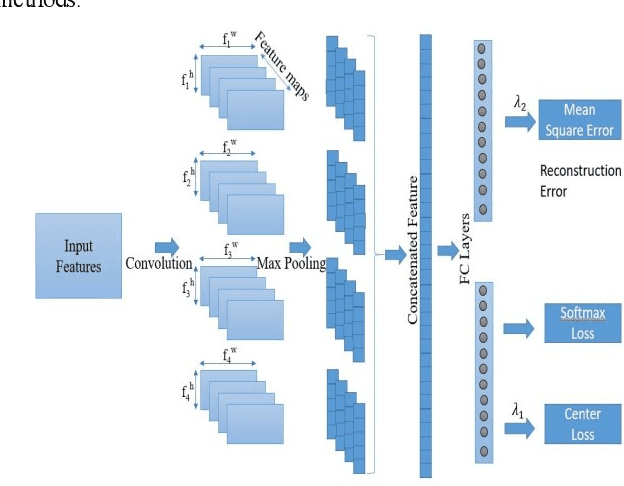
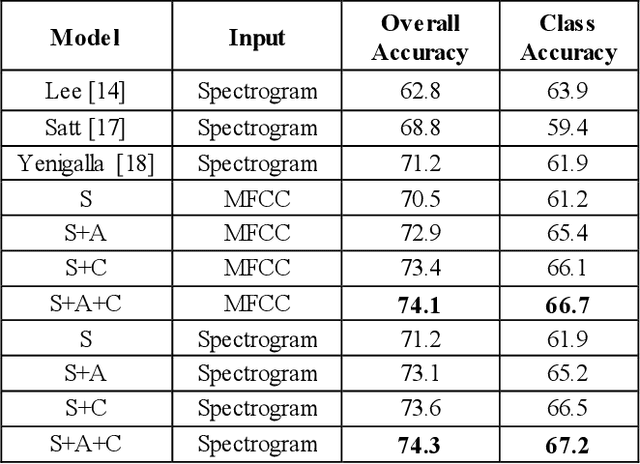
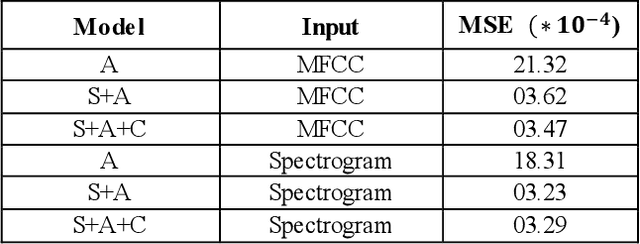
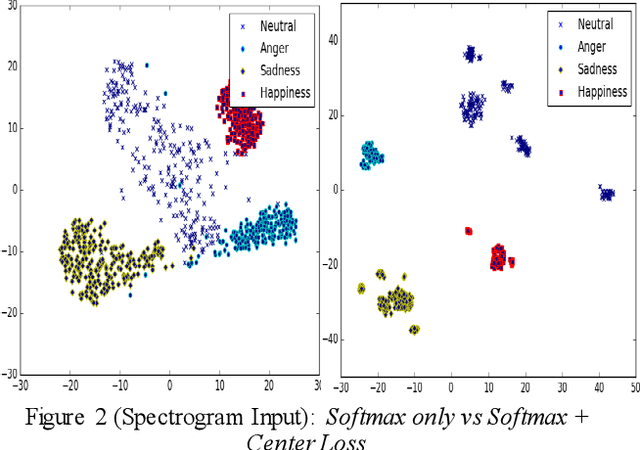
This paper proposes a Convolutional Neural Network (CNN) inspired by Multitask Learning (MTL) and based on speech features trained under the joint supervision of softmax loss and center loss, a powerful metric learning strategy, for the recognition of emotion in speech. Speech features such as Spectrograms and Mel-frequency Cepstral Coefficient s (MFCCs) help retain emotion-related low-level characteristics in speech. We experimented with several Deep Neural Network (DNN) architectures that take in speech features as input and trained them under both softmax and center loss, which resulted in highly discriminative features ideal for Speech Emotion Recognition (SER). Our networks also employ a regularizing effect by simultaneously performing the auxiliary task of reconstructing the input speech features. This sharing of representations among related tasks enables our network to better generalize the original task of SER. Some of our proposed networks contain far fewer parameters when compared to state-of-the-art architectures.
SDST: Successive Decoding for Speech-to-text Translation
Sep 21, 2020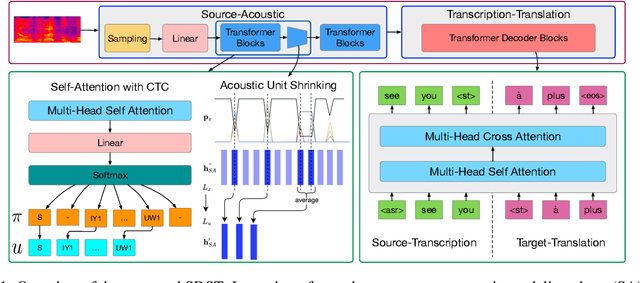

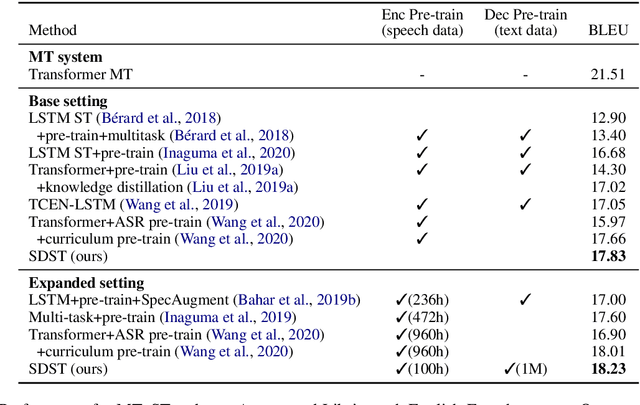
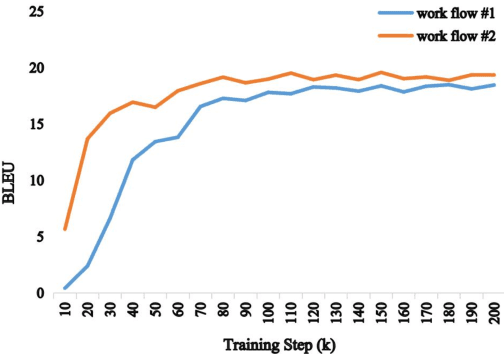
End-to-end speech-to-text translation (ST), which directly translates the source language speech to the target language text, has attracted intensive attention recently. However, the combination of speech recognition and machine translation in a single model poses a heavy burden on the direct cross-modal cross-lingual mapping. To reduce the learning difficulty, we propose SDST, an integral framework with \textbf{S}uccessive \textbf{D}ecoding for end-to-end \textbf{S}peech-to-text \textbf{T}ranslation task. This method is verified in two mainstream datasets. Experiments show that our proposed \method improves the previous state-of-the-art methods by big margins.