 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Building Intelligent Autonomous Navigation Agents
Jun 25, 2021
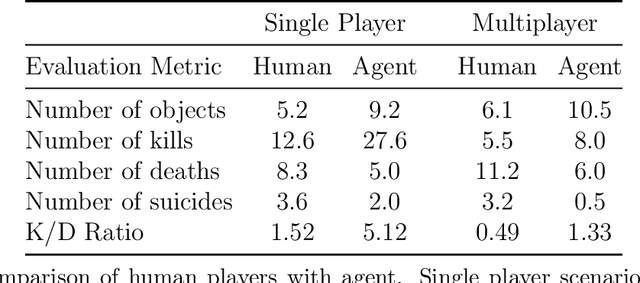
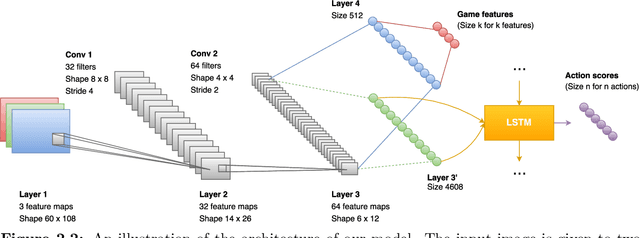
Breakthroughs in machine learning in the last decade have led to `digital intelligence', i.e. machine learning models capable of learning from vast amounts of labeled data to perform several digital tasks such as speech recognition, face recognition, machine translation and so on. The goal of this thesis is to make progress towards designing algorithms capable of `physical intelligence', i.e. building intelligent autonomous navigation agents capable of learning to perform complex navigation tasks in the physical world involving visual perception, natural language understanding, reasoning, planning, and sequential decision making. Despite several advances in classical navigation methods in the last few decades, current navigation agents struggle at long-term semantic navigation tasks. In the first part of the thesis, we discuss our work on short-term navigation using end-to-end reinforcement learning to tackle challenges such as obstacle avoidance, semantic perception, language grounding, and reasoning. In the second part, we present a new class of navigation methods based on modular learning and structured explicit map representations, which leverage the strengths of both classical and end-to-end learning methods, to tackle long-term navigation tasks. We show that these methods are able to effectively tackle challenges such as localization, mapping, long-term planning, exploration and learning semantic priors. These modular learning methods are capable of long-term spatial and semantic understanding and achieve state-of-the-art results on various navigation tasks.
Searchable Hidden Intermediates for End-to-End Models of Decomposable Sequence Tasks
May 02, 2021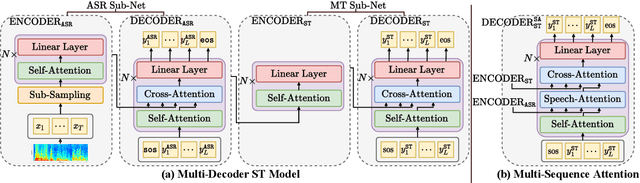
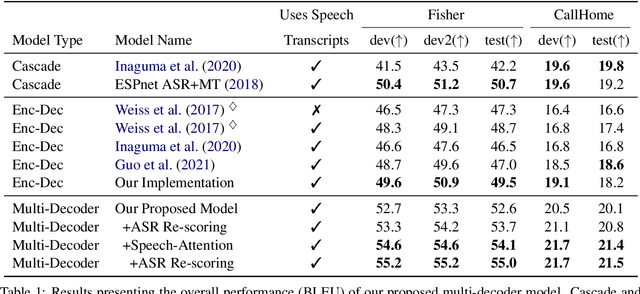
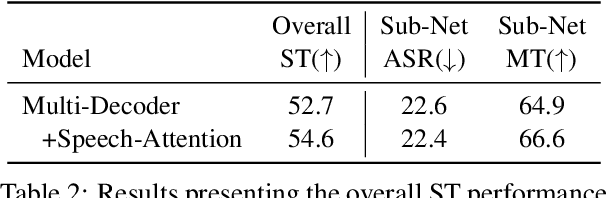
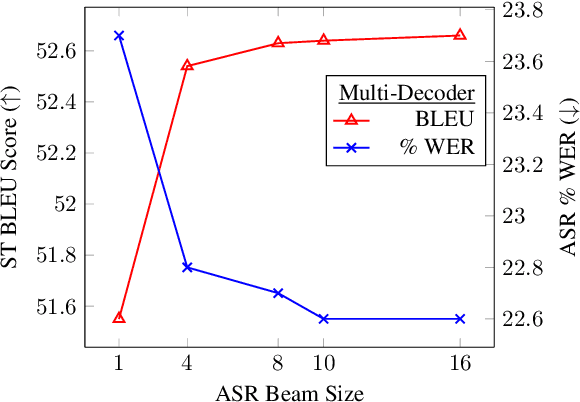
End-to-end approaches for sequence tasks are becoming increasingly popular. Yet for complex sequence tasks, like speech translation, systems that cascade several models trained on sub-tasks have shown to be superior, suggesting that the compositionality of cascaded systems simplifies learning and enables sophisticated search capabilities. In this work, we present an end-to-end framework that exploits compositionality to learn searchable hidden representations at intermediate stages of a sequence model using decomposed sub-tasks. These hidden intermediates can be improved using beam search to enhance the overall performance and can also incorporate external models at intermediate stages of the network to re-score or adapt towards out-of-domain data. One instance of the proposed framework is a Multi-Decoder model for speech translation that extracts the searchable hidden intermediates from a speech recognition sub-task. The model demonstrates the aforementioned benefits and outperforms the previous state-of-the-art by around +6 and +3 BLEU on the two test sets of Fisher-CallHome and by around +3 and +4 BLEU on the English-German and English-French test sets of MuST-C.
Relative Positional Encoding for Speech Recognition and Direct Translation
May 20, 2020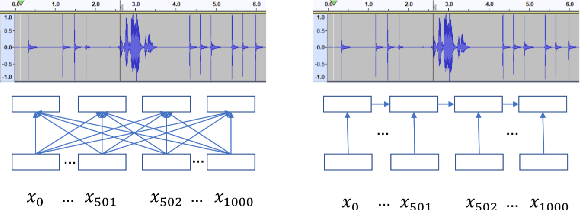
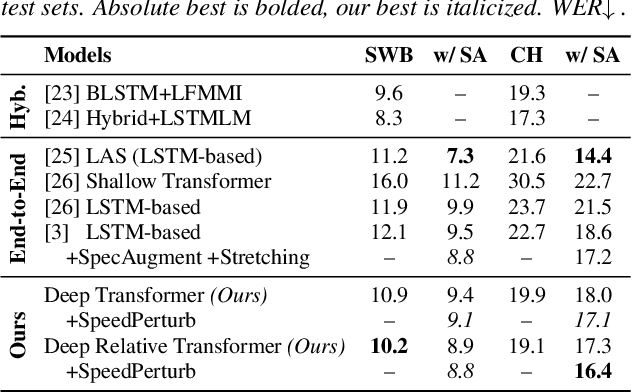


Transformer models are powerful sequence-to-sequence architectures that are capable of directly mapping speech inputs to transcriptions or translations. However, the mechanism for modeling positions in this model was tailored for text modeling, and thus is less ideal for acoustic inputs. In this work, we adapt the relative position encoding scheme to the Speech Transformer, where the key addition is relative distance between input states in the self-attention network. As a result, the network can better adapt to the variable distributions present in speech data. Our experiments show that our resulting model achieves the best recognition result on the Switchboard benchmark in the non-augmentation condition, and the best published result in the MuST-C speech translation benchmark. We also show that this model is able to better utilize synthetic data than the Transformer, and adapts better to variable sentence segmentation quality for speech translation.
Investigations on Phoneme-Based End-To-End Speech Recognition
May 19, 2020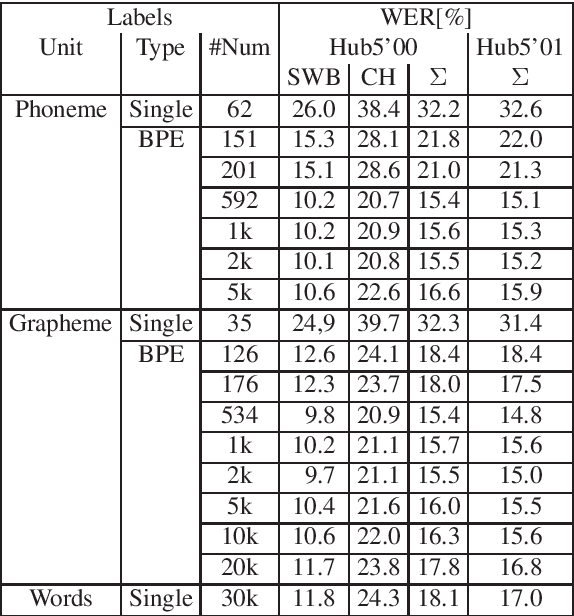
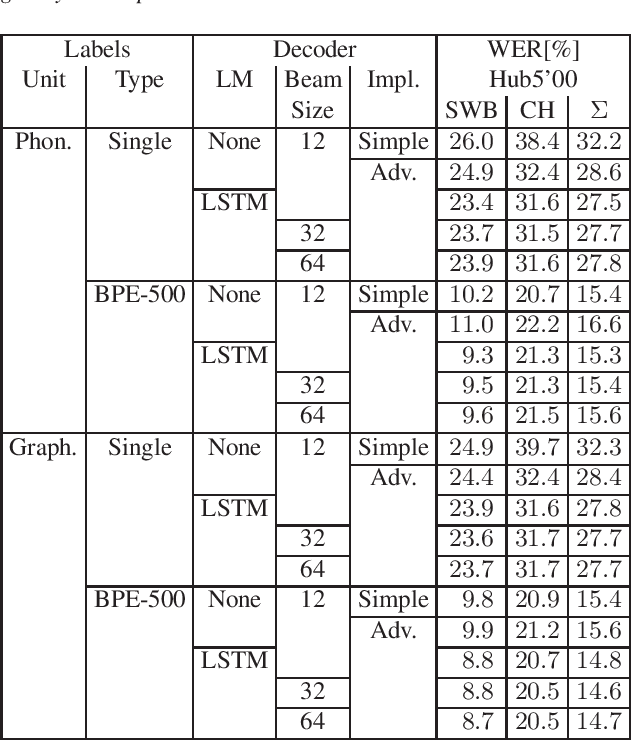
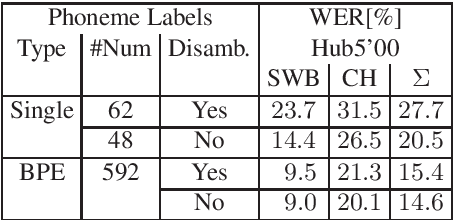
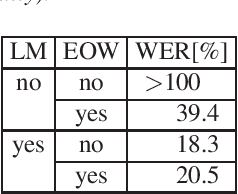
Common end-to-end models like CTC or encoder-decoder-attention models use characters or subword units like BPE as the output labels. We do systematic comparisons between grapheme-based and phoneme-based output labels. These can be single phonemes without context (~40 labels), or multiple phonemes together in one output label, such that we get phoneme-based subwords. For this purpose, we introduce phoneme-based BPE labels. In further experiments, we extend the phoneme set by auxiliary units to be able to discriminate homophones (different words with same pronunciation). This enables a very simple and efficient decoding algorithm. We perform the experiments on Switchboard 300h and we can show that our phoneme-based models are competitive to the grapheme-based models.
Libri-adhoc40: A dataset collected from synchronized ad-hoc microphone arrays
Mar 30, 2021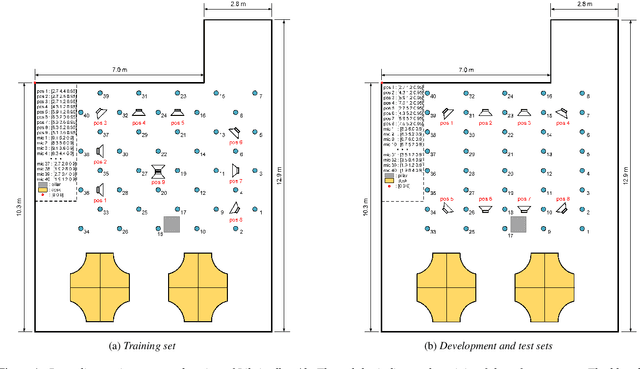
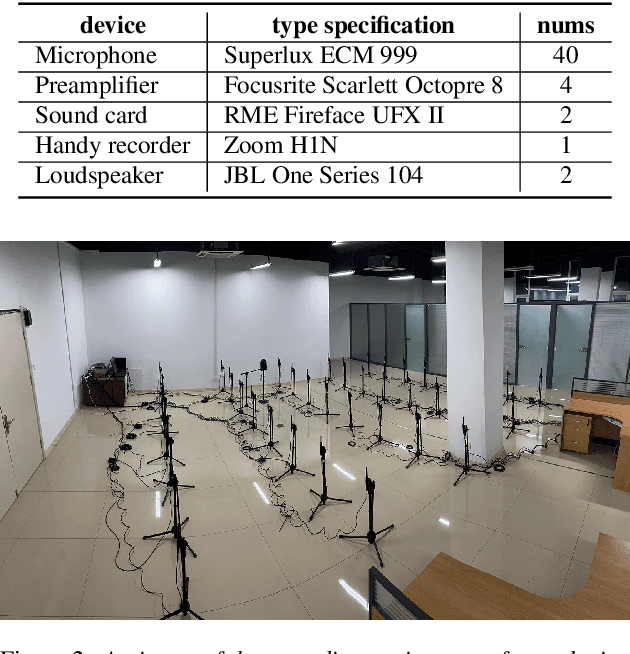
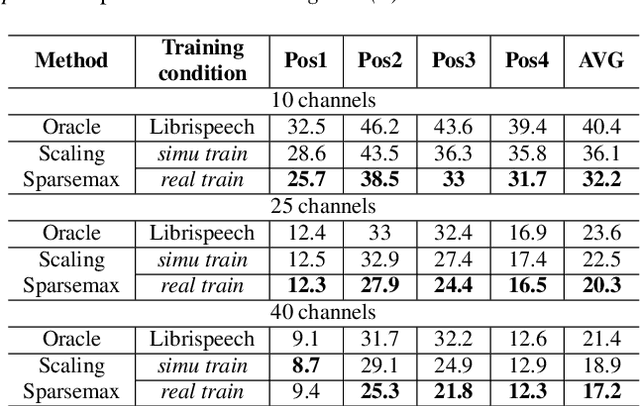
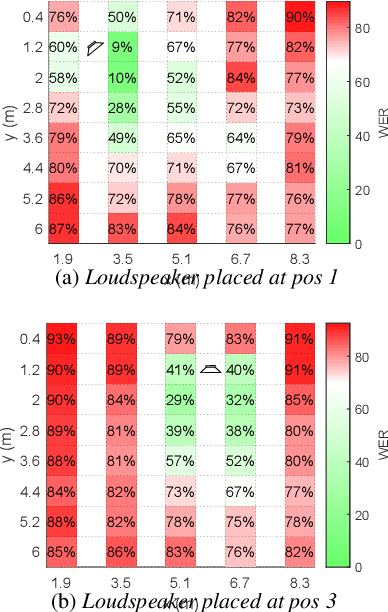
Recently, there is a research trend on ad-hoc microphone arrays. However, most research was conducted on simulated data. Although some data sets were collected with a small number of distributed devices, they were not synchronized which hinders the fundamental theoretical research to ad-hoc microphone arrays. To address this issue, this paper presents a synchronized speech corpus, named Libri-adhoc40, which collects the replayed Librispeech data from loudspeakers by ad-hoc microphone arrays of 40 strongly synchronized distributed nodes in a real office environment. Besides, to provide the evaluation target for speech frontend processing and other applications, we also recorded the replayed speech in an anechoic chamber. We trained several multi-device speech recognition systems on both the Libri-adhoc40 dataset and a simulated dataset. Experimental results demonstrate the validness of the proposed corpus which can be used as a benchmark to reflect the trend and difference of the models with different ad-hoc microphone arrays. The dataset is online available at https://github.com/ISmallFish/Libri-adhoc40.
Improved Meta-learning training for Speaker Verification
Mar 29, 2021
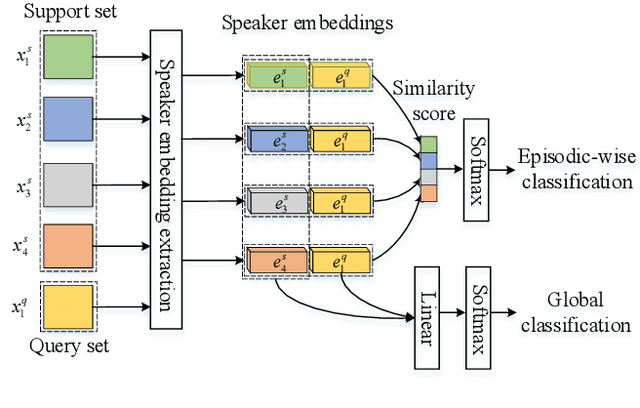
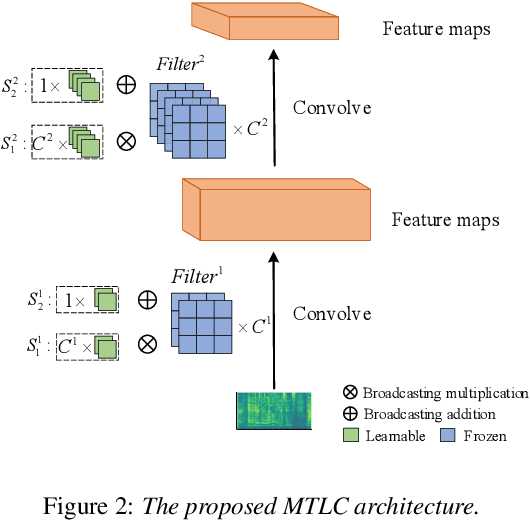
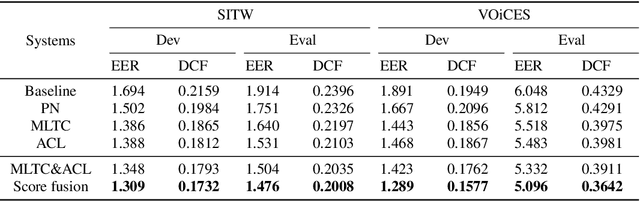
Meta-learning (ML) has recently become a research hotspot in speaker verification (SV). We introduce two methods to improve the meta-learning training for SV in this paper. For the first method, a backbone embedding network is first jointly trained with the conventional cross entropy loss and prototypical networks (PN) loss. Then, inspired by speaker adaptive training in speech recognition, additional transformation coefficients are trained with only the PN loss. The transformation coefficients are used to modify the original backbone embedding network in the x-vector extraction process. Furthermore, the random erasing (RE) data augmentation technique is applied to all support samples in each episode to construct positive pairs, and a contrastive loss between the augmented and the original support samples is added to the objective in model training. Experiments are carried out on the Speaker in the Wild (SITW) and VOiCES databases. Both of the methods can obtain consistent improvements over existing meta-learning training frameworks. By combining these two methods, we can observe further improvements on these two databases.
Using Transformers to Provide Teachers with Personalized Feedback on their Classroom Discourse: The TalkMoves Application
Apr 29, 2021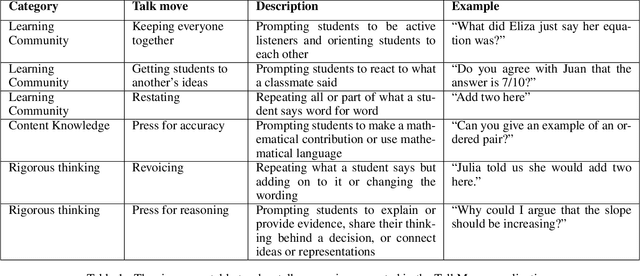

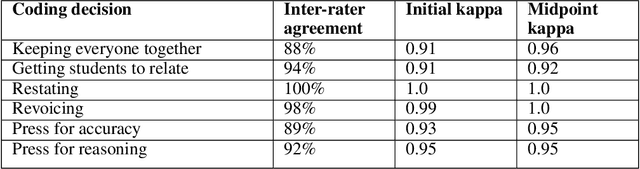
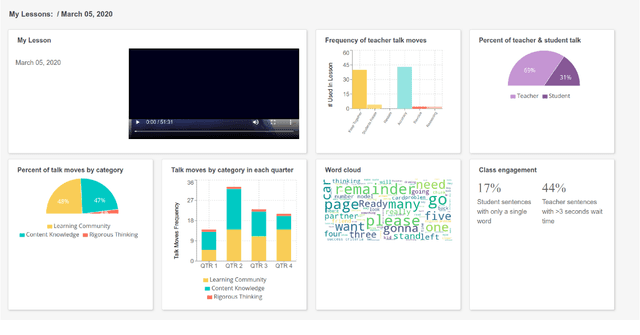
TalkMoves is an innovative application designed to support K-12 mathematics teachers to reflect on, and continuously improve their instructional practices. This application combines state-of-the-art natural language processing capabilities with automated speech recognition to automatically analyze classroom recordings and provide teachers with personalized feedback on their use of specific types of discourse aimed at broadening and deepening classroom conversations about mathematics. These specific discourse strategies are referred to as "talk moves" within the mathematics education community and prior research has documented the ways in which systematic use of these discourse strategies can positively impact student engagement and learning. In this article, we describe the TalkMoves application's cloud-based infrastructure for managing and processing classroom recordings, and its interface for providing teachers with feedback on their use of talk moves during individual teaching episodes. We present the series of model architectures we developed, and the studies we conducted, to develop our best-performing, transformer-based model (F1 = 79.3%). We also discuss several technical challenges that need to be addressed when working with real-world speech and language data from noisy K-12 classrooms.
Learnable Frequency Filters for Speech Feature Extraction in Speaker Verification
Jun 15, 2022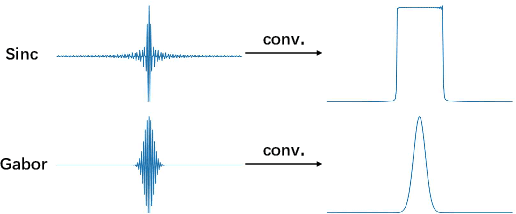
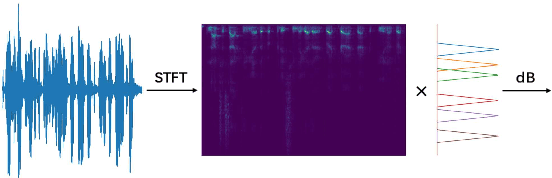
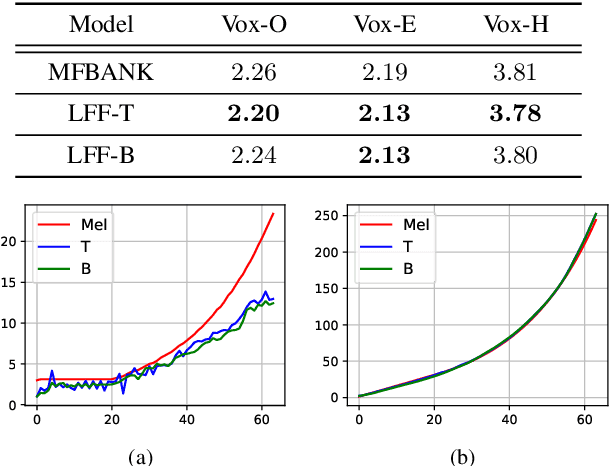
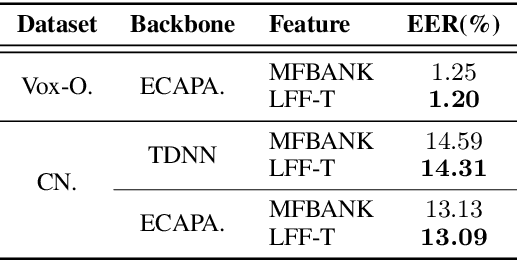
Mel-scale spectrum features are used in various recognition and classification tasks on speech signals. There is no reason to expect that these features are optimal for all different tasks, including speaker verification (SV). This paper describes a learnable front-end feature extraction model. The model comprises a group of filters to transform the Fourier spectrum. Model parameters that define these filters are trained end-to-end and optimized specifically for the task of speaker verification. Compared to the standard Mel-scale filter-bank, the filters' bandwidths and center frequencies are adjustable. Experimental results show that applying the learnable acoustic front-end improves speaker verification performance over conventional Mel-scale spectrum features. Analysis on the learned filter parameters suggests that narrow-band information benefits the SV system performance. The proposed model achieves a good balance between performance and computation cost. In resource-constrained computation settings, the model significantly outperforms CNN-based learnable front-ends. The generalization ability of the proposed model is also demonstrated on different embedding extraction models and datasets.
CAT: CRF-based ASR Toolkit
Nov 20, 2019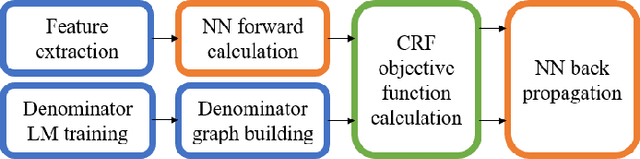

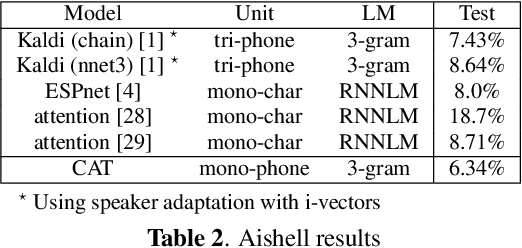
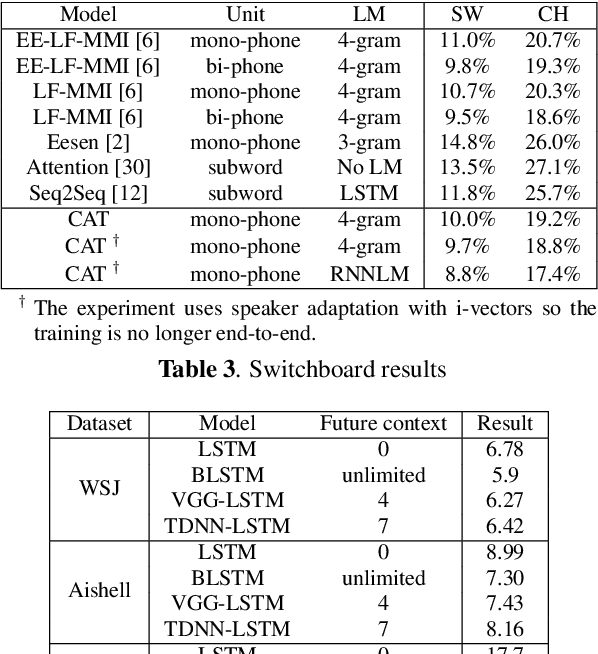
In this paper, we present a new open source toolkit for automatic speech recognition (ASR), named CAT (CRF-based ASR Toolkit). A key feature of CAT is discriminative training in the framework of conditional random field (CRF), particularly with connectionist temporal classification (CTC) inspired state topology. CAT contains a full-fledged implementation of CTC-CRF and provides a complete workflow for CRF-based end-to-end speech recognition. Evaluation results on Chinese and English benchmarks such as Switchboard and Aishell show that CAT obtains the state-of-the-art results among existing end-to-end models with less parameters, and is competitive compared with the hybrid DNN-HMM models. Towards flexibility, we show that i-vector based speaker-adapted recognition and latency control mechanism can be explored easily and effectively in CAT. We hope CAT, especially the CRF-based framework and software, will be of broad interest to the community, and can be further explored and improved.
BCN2BRNO: ASR System Fusion for Albayzin 2020 Speech to Text Challenge
Jan 29, 2021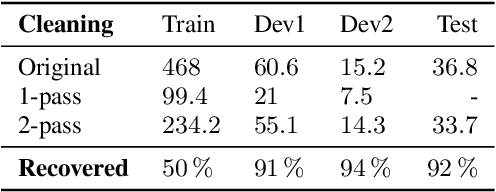
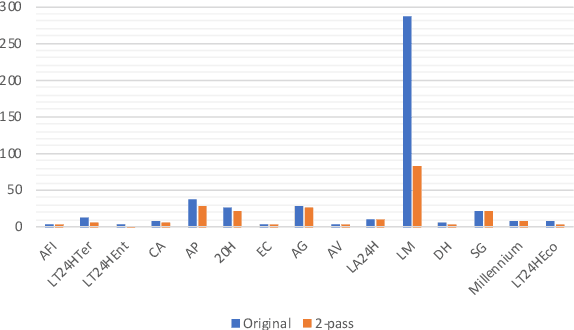
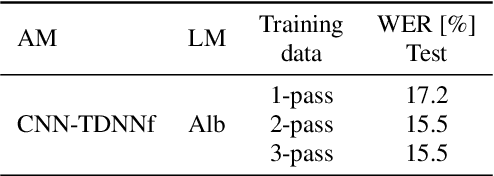
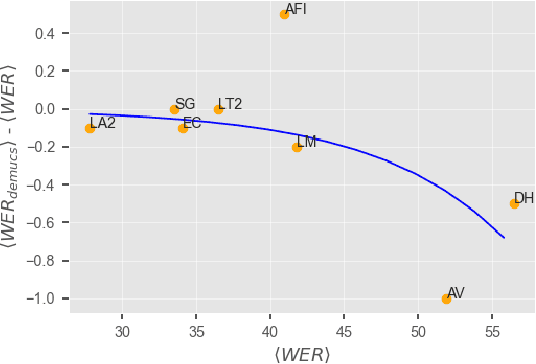
This paper describes joint effort of BUT and Telef\'onica Research on development of Automatic Speech Recognition systems for Albayzin 2020 Challenge. We compare approaches based on either hybrid or end-to-end models. In hybrid modelling, we explore the impact of SpecAugment layer on performance. For end-to-end modelling, we used a convolutional neural network with gated linear units (GLUs). The performance of such model is also evaluated with an additional n-gram language model to improve word error rates. We further inspect source separation methods to extract speech from noisy environment (i.e. TV shows). More precisely, we assess the effect of using a neural-based music separator named Demucs. A fusion of our best systems achieved 23.33% WER in official Albayzin 2020 evaluations. Aside from techniques used in our final submitted systems, we also describe our efforts in retrieving high quality transcripts for training.